企业部门级本地知识库搭建方案【通义千问QwQ32B大模型+BGE-M3向量模型+Open-WebUI】+【x99+Tesla T10】_tesla t10 ubuntu
一、方案设计
1、基本测试
通义千问QwQ32B,Q4量化,部署框架Vllm。
测试结果:
a、默认设置下,24GB显存运行比较吃紧,上下文以4096大小偶尔都不能启动服务,没有资源再稳定加载向量模型。
b、3090显卡单任务大约十几个token每秒。
c、Q4模型用于知识库,其生成速度和质量基本够用。
d、内存和CPU虽然消耗不大,但对服务器的多任务能力要求较高,核心数多一点更好。
2、硬件方案设计
目标:单台主机,散热好但噪音要小,相对稳定,性能满足3人并发访问,性价比高。
a、处理器:采用E5 2673v3 处理器 2颗,共24核心,配利民单塔12cm双风扇散热器;
b、主板:杂牌 x99 DDR3双路主板,三条PCIE3.0 x16插槽;
c、内存:ECC DDR3 1866 16GB*4;
c、算力卡:Tesla T10 16GB 2片,直列外接涡轮风扇2个,涡轮风扇大一点,以方便在调低转速情况下,保证散热;

d、硬盘:240GB SATA;
e、显卡:R5 240亮机卡,支持uefi启动,与x99兼容良好;
f、 机箱:支持EATX规格的大机箱一个,前后12cm风扇4个;
g、电源:850W;
h、风扇集线器:Sata电源接口,可连接多个风扇,可调速控制噪音。

硬件总成本不超过4500元。
3、软件方案设计
目标:知识库需本地搭建,无代码部署,运行效率高,支持知识库创建、管理,支持用户和权限管理;
a、操作系统:Ubuntu 24.04桌面版;
b、部署方式:统一采用Docker部署;
c、知识库前端:Open-WebUI;
d、基础大模型:QwQ32B、4Bit量化,基于Vllm部署,进行双卡张量计算,T10算力卡虽然双精度性能低,但运行4bit量化模型效率足够,双卡性能优于单卡3090;
e、向量模型:采用BGE-M3,基于Ollama部署;
f、外网访问:将Open-WebUI的Http服务,通过Nginx转发为Https,通过防火墙映射到互联网,绑定二级域名和证书,实现Https安全访问;
g、Docker管理:采用portainer图形化管理Docker。
二、安装过程
1、硬件安装避坑
a、板、U、内存、显卡等无问题,机箱宽大,操作整体便利。
b、主板具备三条PCIE 16倍速插槽,远离CPU的一条,因与主板元器件干涉,不能安装T10计算卡和外接直列涡轮,因此用来安装显卡。
c、T10算力卡长度较长,安装直列涡轮后更长,即使机箱较大,也与机箱前置风扇略有干涉,通过整理插线,调整安装角度克服;如缝隙较大,风扇转接套边缘用胶带封一下可提高散热效果。
d、BIOS中必需打开“Above 4G”选项;可选打开“Re-Size BAR”选项,可以提高一点性能。

2、软件安装步骤
以下每个分解步骤都能查到大量历史文案,因此仅描述关键问题。
a、初次安装,为便于桌面维护,采用Ubuntu24.04桌面版操作系统,下载ISO镜像,使用rufus软件写入U盘,基于uefi启动安装,硬盘较小,默认分区,数据准备放在Home分区。
b、更新系统,包括nvidia显卡驱动,安装、检查Docker环境。
c、QwQ32B部署:经尝试,直接拉取部署好vllm的Docker镜像(vllm-openai:v0.8.5),基于本镜像再进行配置,比较简便且不容易遇到问题,注意docker镜像的cuda支持要低于宿主机的cuda支持版本。
在宿主机下载QwQ32B的4bit量化版本,我是用modelscope下载的,先安装modelscope,然后执行:
modelscope download --model Qwen/QwQ-32B-GGUF qwq-32b-q4_k_m.gguf --local_dir /home/test/docker/vllm/QWQ-32B-AWQ
建议手动拉取模型,稍后docker启动时,映射成卷给它,启动命令参考:
docker run -d --name vllm-server --gpus all --ipc=host -p 8000:8000 -v /home/test/docker/vllm/QWQ-32B-AWQ:/vllm/model 镜像名称或ID --model /vllm/model --host 0.0.0.0 --tensor-parallel-size 2 --served-model-name QwQ-32B --max-model-len=4096 --api-key 123 --port=8000 --gpu-memory-utilization 0.85
d、部署Open-WebUI:
启动容器时进行卷的映射,建议之后把“_data”这个文件夹进行备份,升级版本时可以直接删除原容器,用新版本的镜像挂载此文件夹为卷,则知识库和登录用户等内容都可以保存。
容器启动命令参考:
docker run -d -p 3000:8080 -v /home/test/docker/open-webui/_data:/app/backend/data --name open-webui open-webui:main
e、ollama部署:
直接拉取镜像并运行容器:
docker run -d --privileged --gpus=all -v /home/test/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
进入容器:
docker exec -it ollama /bin/bash
拉取BGE-M3模型:
ollama pull bge-m3:latest
##完成后可以检查一下
ollama list
f、部署Nginx容器,修改配置文件,转发Open-WebUI服务,绑定证书和二级域名,不再赘述。注意“client_max_body_size 100m”,这个参数要大一些,倒也用不到100兆,知识库网站通讯有时需要大一些,比如导入文件的时候。
g、部署Portainer图形化Docker管理工具,有中文的,可自行查找镜像并部署,比较简单。操作清晰明了,简便快捷。
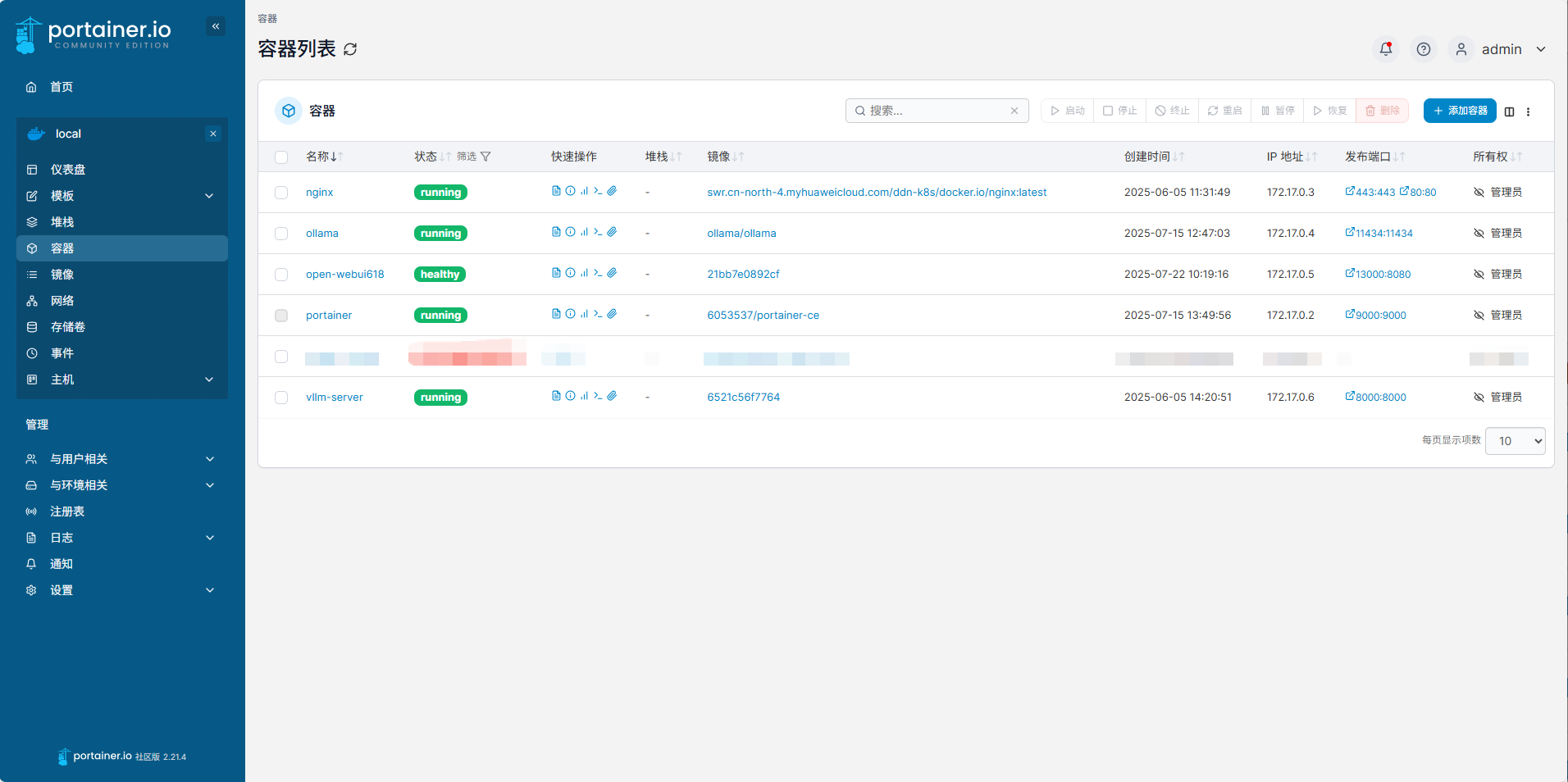
三、系统使用
1、账户和权限、其它配置
登录Open-WebUI,默认采用邮箱做用户名,可设置权限组的各种权限,并将用户加入权限组。支持批量用户导入,可下载csv模板,填好后一次性建立账户。
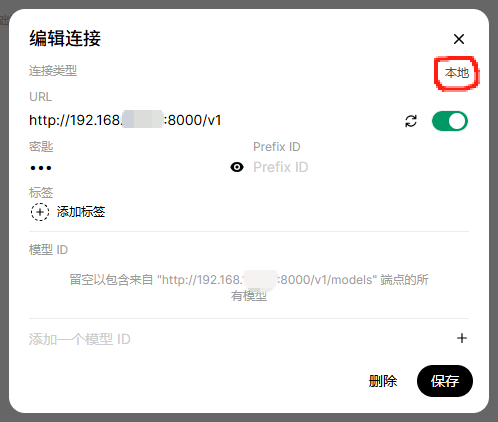
配置大模型,在“管理员面板”——“设置”——“外部连接”中,设置大模型服务连接地址,注意右侧齿轮配置按钮,可以切换“本地”和“外部”,此方案应选择“本地”,如果购买了外部的API,可以按需配置。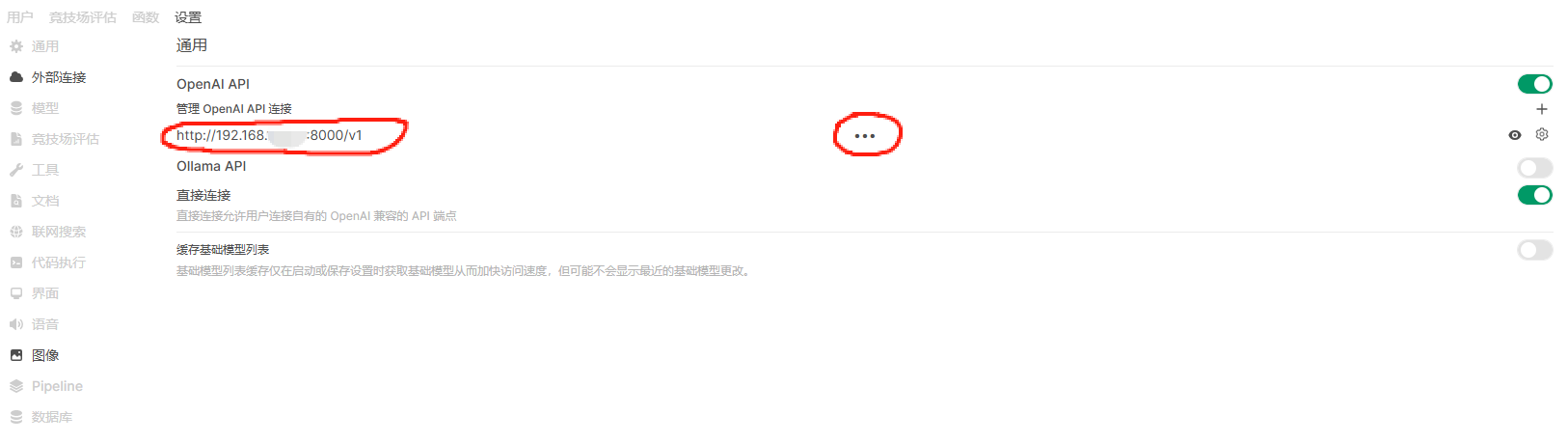
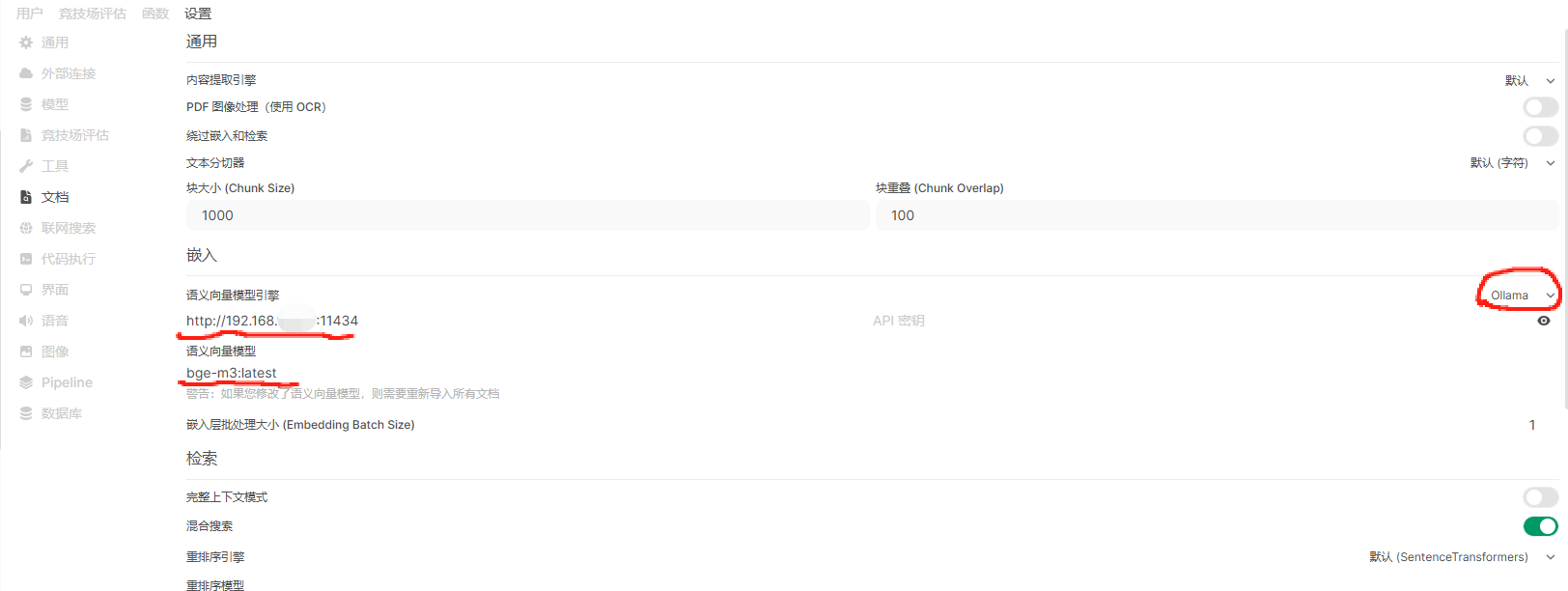
配置ollama支持的向量模型连接,在“管理员面板”——“设置”——“文档”中进行设置,语义向量模型引擎选择“ollama”,下方地址和模型名称填好:
2、知识库创建
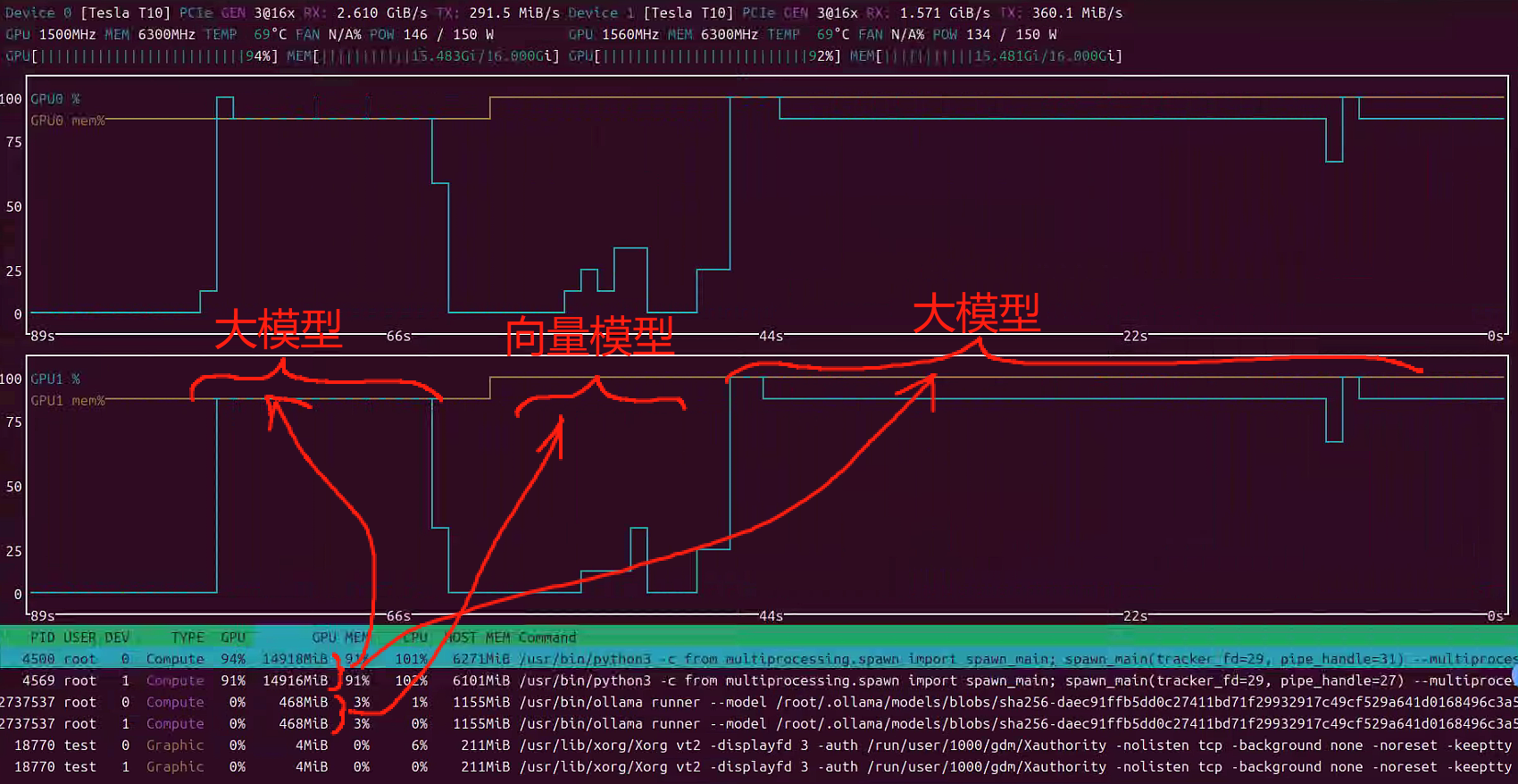
合理的归纳整理知识库,合理的建立分片文件。导入知识库比较慢,注意观察GPU是否参与了工作,推荐一个监控工具nvtop用于监控GPU状态,多数情况比nvidia-smi更好用。每导入一个文件时,GPU占用会上涨一些,之后回落。选择文件夹导入时不按照文件名顺序,因此注意一次不要导入太多文件,避免失败后重复操作。
3、知识库使用
在工作空间新建模型,选择基础模型,附加知识库,之后选择该模型,便可以使用了。
查询问题时,观察GPU占用状态状态,可观察到大模型先工作,然后向量模型工作,最后大模型再工作。留意GPU温度,合理调整风扇转速,通常全载十分钟低于80℃就比较理想。
其它调优工作基本需要更系统化的对大模型生成和知识库原理进行学习,能力和情况所限,无法逐一列举。
总结
至此主要工作完成,全部基于开源程序,软件模块化部署;服务器噪音可控,适合放置于办公区域,硬件成本低,未来升级方便。


