Learning PostgresSQL读书笔记: 第13章 Query Tuning, Indexes, and Performance Optimization
SQL是声明式语言,如何访问数据库取决于数据库引擎。
规划器,负责从所有可用的底层数据路径中确定最佳路径,优化器,负责使用这种特定的访问计划执行语句。
本章将学习以下主题:
- 语句的执行
- 索引
- EXPLAIN 语句
- 查询调优示例
- ANALYZE 以及如何更新统计信息
- 自动解释
语句的执行
规划器/优化器的任务是创建一个最优的执行计划。一个给定的 SQL 查询(以及查询树)实际上可以用多种不同的方式执行,每种方式都会产生相同的结果集。如果计算上可行,查询优化器将检查每个可能的执行计划,最终选择预期运行速度最快的执行计划。
规划器的搜索过程实际上与一种称为路径的数据结构协同工作,这些路径只是对计划的精简表示,仅包含规划器进行决策所需的信息。在确定了最便宜的路径后,将构建一个完整的计划树并将其传递给执行器。这足够详细地描述了所需的执行计划,以便执行器能够运行它。在本节的其余部分,我们将忽略路径和计划之间的区别。
找到数据的最快路径通常需要在搜索绝对最快路径和推理该路径所花费的时间之间取得平衡;换句话说,PostgreSQL 有时会选择一种折衷方案,以足够快的方式获取数据,即使这不是绝对最快的方式。
DBA需要做调优以让数据库做出最好的决定。
执行阶段
详见50.1. The Path of a Query。查询需要经过以下阶段才能获得结果:
- 应用程序连接到 PostgreSQL 服务器,将查询发送到服务器,并等待接收服务器返回的结果。
- 解析器(parser)阶段检查应用程序传输的查询是否语法正确,并创建查询树。
- 重写系统(rewrite system)接收解析器阶段创建的查询树,并查找任何可应用于该查询树的规则(存储在系统目录中)。它执行规则体中给出的转换。例如将查询视图转换为对基表的查询。
- 规划器/优化器(planner/optimizer)接收(重写的)查询树,并创建一个查询计划作为执行器的输入。(创建所有路径,如顺序扫描或通过索引;评估路径成本;选择最优路径)
- 执行器(executor)递归地遍历计划树,并按照计划所表示的方式检索行。执行器在扫描关系时利用存储系统,执行排序和连接,评估条件,并最终返回导出的行。
DBA唯一可以影响的是优化器阶段。
优化器
和oracle一样,PG的优化器基于成本选择查询计划(路径),因此也称为CBO(Cost Based Optimizer)。
选择路径也是需要成本的,因此有时也会在计算数据路径所花费的时间和找到不太糟糕的访问路径之间平衡。
优化器使用的节点
执行计划是树状结构,树中的节点即node。node有不同类型,对应一类操作。
例如,以下SQL有2个node,分别返回数据和排序:
select * from table_name order by column1;根据文档:
查询计划的结构是一个由计划节点组成的树。树底层的节点是扫描节点:它们返回表中的原始行。不同的表访问方法有不同类型的扫描节点:顺序扫描、索引扫描和位图索引扫描。
如果查询需要对原始行进行连接、聚合、排序或其他操作,则扫描节点上方会有其他节点来执行这些操作。如nested loop join,merge join和hash join节点。
以下是主要的节点:
- Sequential Scan
- Index Scan, Index-Only Scan, 和Bitmap Index Scan
- Nested Loop, Hash Join, 和Merge Join
- The Gather and Merge parallel
节点之间可以形成管道,即一个节点的输出可作为另一节点的输入。
SCAN节点
Sequential Scan
💡 总是存在对关系执行顺序扫描的可能性,因此总是会创建顺序扫描计划。
Index Scan
最经典方式。
在 PostgreSQL 中,所有索引都是辅助索引,这意味着它们与表并存;因此,您将在存储空间中为表创建一个数据文件,并在表上创建的每个索引都创建一个数据文件。这意味着索引扫描始终需要两次不同的存储访问:一次是读取磁盘并提取所请求元组在表中位置的信息,另一次是访问磁盘以查找索引指向的元组。
Index-Only Scan
由于经典的Index Scan涉及多个随机读取,因此可能会慢。而Index-Only Scan仅从索引响应查询,而无需任何堆访问。其基本思想是直接从每个索引条目返回值,而不是查询相关的堆条目。
有两点要求:
- 索引类型必须支持仅索引扫描。B 树索引始终支持此操作。
- 查询必须仅引用存储在索引中的列。
Bitmap Index Scan
为了合并多个索引,系统会扫描每个需要合并的索引,并在内存中准备一个位图,该位图包含符合该索引条件的表行的位置。
您可以将位图索引扫描视为顺序扫描和索引扫描之间的中间地带。与索引扫描类似,它扫描索引以确定需要获取的确切数据;但与顺序扫描类似,它利用了数据易于批量读取的优势。
Join节点
nested loop join
对于左关系中发现的每一行,右关系都会扫描一次。这种策略很容易实现,但可能非常耗时。(但是,如果右关系可以用索引扫描来扫描,这可能是一个不错的策略。可以使用左关系当前行的值作为右关系索引扫描的键。)
merge join
在连接开始之前,每个关系都会根据连接属性进行排序。然后并行扫描这两个关系,并将匹配的行合并成连接行。这种连接很有吸引力,因为每个关系只需扫描一次。所需的排序可以通过显式排序步骤实现,也可以通过使用连接键上的索引以正确的顺序扫描关系来实现。
hash join
首先扫描右关系并将其加载到哈希表中,使用其连接属性作为哈希键。接下来扫描左关系,并将找到的每一行的相应值用作哈希键,以在表中定位匹配的行。
上文中提到的左关系和右关系,以下面的SQL为例。A为左关系(因为在JOIN左侧),B为右关系。
SELECT * FROM A JOIN B ON A.id = B.id;在Nested Loop Join中,PG的左关系和右关系,对应Oracle的Outer table (驱动表)和Inner table (被探查表)。
在Hash Join中,PG的左关系和右关系,对应Oracle的Probe input(用来探测哈希表)和Build input(用来构建哈希表)。
Parallel节点
当优化器确定并行查询是特定查询的最快执行策略时,它将创建一个包含 Gather 或 Gather Merge 节点的查询计划。
根据文档:
PostgreSQL 可以设计出能够利用多个 CPU 的查询计划,以便更快地响应查询。此功能称为并行查询。许多查询无法从并行查询中受益,这要么是由于当前实现的限制,要么是因为没有比串行查询计划更快的查询计划。然而,对于能够受益的查询,并行查询带来的加速通常非常显著。许多查询在使用并行查询时可以运行得快两倍以上,有些查询的运行速度甚至可以快四倍甚至更多。那些涉及大量数据但只返回少量行数据的查询通常会受益最多。
💡 如果请求的数据集较小,PG 不会选择并行执行。
Gather节点
Gather节点负责从并行执行节点收集结果,并将它们组合在一起以产生最终结果。
Gather Merge节点
与Gather节点类似,但需要并行进程为其提供排序的输出,以便按照数据的顺序组装结果集。
Parallel scans
顺序访问方法中所有的主要节点都可以并行执行。因此,你可以找到并行序列扫描,或者像Parallel Index和Parallel Index-Only扫描这样的索引扫描,当然还有Parallel Bitmap Heap扫描。
Parallel joins
当 PostgreSQL 决定采用并行连接方法时,它会尝试以非并行的方式访问内表(假设这样的表足够小),并对外表执行并行访问。
Parallel aggregations
当最终结果集是由不同的并行子查询聚合而成时,必然存在一个并行聚合,即每一个单个并行部分的聚合。
优化器何时选择并行计划?
如果要查找数据的表的大小低于 min_parallel_table_scan_size 参数(默认为 8 MB),或者要遍历的索引小于 min_parallel_index_scan_size(默认为 512 kB),则 PostgreSQL 将不考虑并行计划。
将debug_parallel_query设为on,也可以强制执行并行,即使在不期望获得性能提升的情况下,通常用于测试。
demo=# show min_parallel_table_scan_size; min_parallel_table_scan_size------------------------------ 8MB(1 row)demo=# show min_parallel_index_scan_size; min_parallel_index_scan_size------------------------------ 512kB(1 row)demo=# show debug_parallel_query; debug_parallel_query---------------------- off(1 row)并行计划的应用还存在其他限制:PostgreSQL 必须确保不会生成过多的并行进程,因此,如果系统中已经有过多的并行进程在运行,则并行执行将不被视为可选项。此外,任何产生数据写入的语句(即任何不同于 SELECT 语句的语句)都不是并行计划的有效候选,任何可以暂停和恢复的语句(例如使用游标)也是如此。
最后,任何涉及调用标记为 PARALLEL UNSAFE 的函数的查询都不会生成并行计划候选。
Utility节点
这名字感觉是作者自己取的。
sort
ORDER BY
limit
SELECT … LIMIT n
append
UNION ALL
distinct
SELECT DISTINCT
GroupAggregate
GROUP BY
WindowAgg
window function
CTEScan
Common Table Expression (CTE)
Materialize
物化视图
节点成本
每个节点都会计算成本,成本与“单价”和“数量”(数据量)有关。
来看下单价:
SELECT name, settingFROM pg_settingsWHERE name LIKE \'cpu%\\_cost\' OR name LIKE \'%page\\_cost\'ORDER BY setting DESC; name | setting----------------------+--------- random_page_cost | 4 seq_page_cost | 1 cpu_tuple_cost | 0.01 cpu_index_tuple_cost | 0.005 cpu_operator_cost | 0.0025(5 rows)💡 所有优化器计算的基准都是顺序访问单个数据页的成本:该值被设置为成本单位(所以你看到seq_page_cost=1)。CPU 成本(即分析内存中已有元组的成本)远小于单位成本,而随机访问存储的成本则远高于顺序访问。
文档中说得更为明白:
成本以规划器成本参数确定的任意单位来衡量。传统做法是以磁盘页面读取次数为单位来衡量成本;也就是说,seq_page_cost 通常设置为 1.0,其他成本参数也相对于此设置。
💡 成本即“费用”,但其值与执行所需时间无关:成本表示为获取数据所必须付出的努力;因此,更高的成本必然需要更大的努力。
和成本相关的参数见这里。
索引
文档见这里。
索引是提升数据库性能的常用方法。索引使数据库服务器能够以比没有索引时更快的速度查找和检索特定行。但是,索引也会增加整个数据库系统的开销,因此应合理使用。
官网定义:
A relation that contains data derived from a table or materialized view. Its internal structure supports fast retrieval of and access to the original data.
索引类型
表的索引类似于书籍最后的索引部分(不是前面的目录部分)。
读者经常查找的术语和概念会被收集到书末的字母索引中。感兴趣的读者可以相对快速地浏览索引并翻到相应的页面,而不必阅读整本书来找到感兴趣的内容。
💡 正如作者的任务是预测读者可能查找的内容一样,数据库程序员的任务是预见哪些索引会很有用。
PG支持的索引类型:
- B-Tree
- Hash
- GiST
- SP-GiST
- GIN
- BRIN
PG支持多列索引,最多32列。不过多列索引不常用:
Multicolumn indexes should be used sparingly. In most situations, an index on a single column is sufficient and saves space and time. Indexes with more than three columns are unlikely to be helpful unless the usage of the table is extremely stylized.
B-Tree Index
B-Tree索引最常见,注意B表示Balanced,而非Binary。
任何能够按明确定义的线性顺序排序的数据类型都可以使用 B 树索引进行索引。唯一的限制是索引条目不能超过页面的三分之一。
btree 操作符类必须提供五个比较操作符,<、= 和 >。但没有。
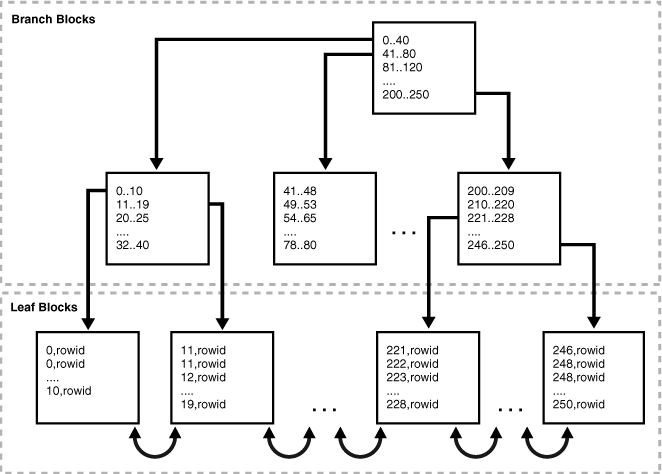
B-Tree 索引结构:
B-Tree 索引是多层树结构,其中树的每一层都可以用作页面的双向链表。单个元页面存储在索引第一个段文件开头的固定位置。所有其他页面要么是叶子页面,要么是内部页面。叶子页面是树的最底层页面。所有其他层级均由内部页面组成。每个叶子页面包含指向表行的元组。每个内部页面包含指向树中下一层级的元组。通常,超过 99% 的页面都是叶子页面。
以下借用Oracle的B-Tree图:
Hash Index
哈希索引存储从索引列的值派生出的 32 位哈希码。因此,此类索引只能处理简单的相等比较。
哈希索引是单列索引,哈希值是4个字节。
哈希索引最适合用于执行 SELECT 和 UPDATE 操作的工作负载,这些工作负载在较大的表上使用等值扫描。在 B 树索引中,搜索必须向下遍历树,直到找到叶子页。对于包含数百万行数据的表,这种向下遍历会增加数据访问时间。哈希索引中相当于叶子页的部分称为存储桶页。相比之下,哈希索引允许直接访问存储桶页,从而可以减少较大表中的索引访问时间。对于大于共享缓冲区/RAM 的索引/数据,这种“逻辑 I/O”的减少会更加明显。
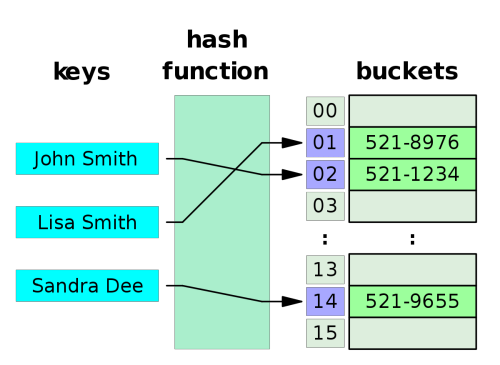
不过,哈希值若分布不均匀,则效果会打折。而B-Tree总是平衡的。
Gin Index
Gin索引,GIN(Generalized Inverted Index) 代表广义倒排索引。GIN 旨在处理以下情况:待索引项是复合值,并且索引处理的查询需要搜索复合项中出现的元素值。例如,项可以是文档,而查询可以是搜索包含特定关键词的文档。
我们使用“项”来指代待索引的复合值,使用“键”来指代元素值。GIN 始终存储和搜索键,而不是项值本身。
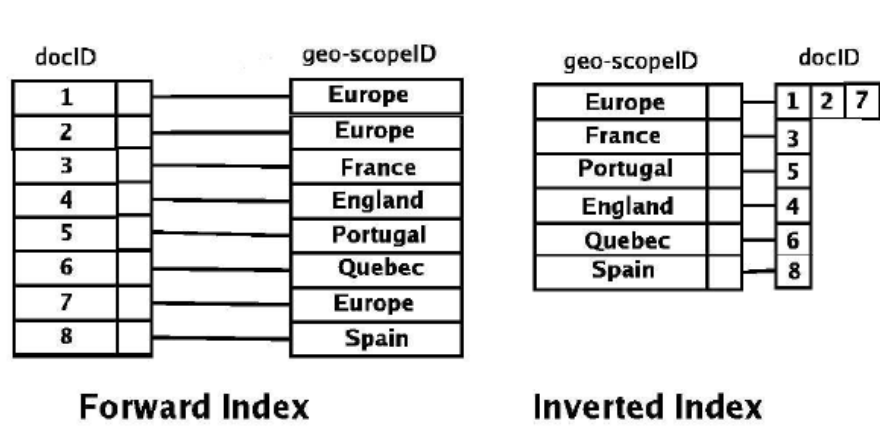
GIN 索引存储一组(键,倒排列表)对,其中倒排列表是键出现的行 ID 的集合。由于一个项可以包含多个键,因此相同的行 ID 可以出现在多个倒排列表中。每个键值只存储一次,因此对于相同键多次出现的情况,GIN 索引非常紧凑。
GiST Index
GiST 索引不是单一类型的索引,而是一种可以实现多种不同索引策略的基础结构。
GiST 代表广义搜索树 (Generalized Search Tree)。它是一种平衡的树形结构访问方法,可作为实现任意索引方案的基础模板。B+ 树、R 树以及许多其他索引方案都可以在 GiST 中实现。
GiST 的优势之一是,它允许特定数据类型领域的专家(而非数据库专家)开发具有适当访问方法的自定义数据类型。
创建索引
语法:
demo=# \\h create indexCommand: CREATE INDEXDescription: define a new indexSyntax:CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON [ ONLY ] table_name [ USING method ] ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] ) [ INCLUDE ( column_name [, ...] ) ] [ NULLS [ NOT ] DISTINCT ] [ WITH ( storage_parameter [= value] [, ... ] ) ] [ TABLESPACE tablespace_name ] [ WHERE predicate ]URL: https://www.postgresql.org/docs/16/sql-createindex.html其中method的说明:
The name of the index method to be used. Choices are btree, hash, gist, spgist, gin, brin, or user-installed access methods like bloom. The default method is btree.
索引与他索引的表总是在同一schema中,因此总是使用非限定名称(非限定名称)。不过索引可以与表在不同的表空间。
No schema name can be included here; the index is always created in the same schema as its parent table. The name of the index must be distinct from the name of any other relation (table, sequence, index, view, materialized view, or foreign table) in that schema. If the name is omitted, PostgreSQL chooses a suitable name based on the parent table’s name and the indexed column name(s).
💡 创建多列索引时,应始终将最具选择性的列放在第一位。(书中说的,文档中没看到)
demo=# create index empno_idx on empsalary(empno);CREATE INDEXdemo=# create index id_idx on empsalary using hash(id);CREATE INDEX检查索引
demo=# \\d empsalary; Table \"demo.empsalary\" Column | Type | Collation | Nullable | Default-------------+---------+-----------+----------+--------- id | integer | | not null | depname | text | | | empno | integer | | | salary | integer | | | enroll_date | date | | |Indexes: \"empno_idx\" btree (empno) \"id_idx\" hash (id)SELECT relname, relpages, reltuples, i.indisunique, i.indisclustered, i.indisvalid, pg_catalog.pg_get_indexdef(i.indexrelid, 0, TRUE)FROM pg_class c JOIN pg_index i ON c.oid = i.indrelidWHERE c.relname = \'empsalary\'; relname | relpages | reltuples | indisunique | indisclustered | indisvalid | pg_get_indexdef-----------+----------+-----------+-------------+----------------+------------+--------------------------------------------------------- empsalary | 1 | 10 | f | f | t | CREATE INDEX empno_idx ON empsalary USING btree (empno) empsalary | 1 | 10 | f | f | t | CREATE INDEX id_idx ON empsalary USING hash (id)(2 rows)使索引无效
使索引无效是一种不删除索引,而使优化器不选择此索引的方法。必须直接修改系统表。
UPDATE pg_indexSET indisvalid = FALSEWHERE indexrelid = ( SELECT oid FROM pg_class WHERE relkind = \'i\' AND relname = \'id_idx\');demo=# \\d empsalary; Table \"demo.empsalary\" Column | Type | Collation | Nullable | Default-------------+---------+-----------+----------+--------- id | integer | | not null | depname | text | | | empno | integer | | | salary | integer | | | enroll_date | date | | |Indexes: \"empno_idx\" btree (empno) \"id_idx\" hash (id) INVALID重建索引
demo=# \\h reindexCommand: REINDEXDescription: rebuild indexesSyntax:REINDEX [ ( option [, ...] ) ] { INDEX | TABLE | SCHEMA } [ CONCURRENTLY ] nameREINDEX [ ( option [, ...] ) ] { DATABASE | SYSTEM } [ CONCURRENTLY ] [ name ]where option can be one of: CONCURRENTLY [ boolean ] TABLESPACE new_tablespace VERBOSE [ boolean ]URL: https://www.postgresql.org/docs/16/sql-reindex.htmlREINDEX 使用存储在索引表中的数据重建索引,替换旧的索引副本。使用场景如下:
- 索引已损坏,不再包含有效数据。虽然理论上这种情况永远不会发生,但实际上,由于软件错误或硬件故障,索引可能会损坏。REINDEX 提供了一种恢复方法。
- 索引已变得“臃肿”,即包含许多空页或几乎空的页面。在某些不常见的访问模式下,PostgreSQL 中的 B 树索引可能会出现这种情况。REINDEX 提供了一种方法,即通过写入不包含死页(dead page)的新版本的索引来减少索引的空间消耗。
- 您已更改索引的存储参数(例如填充因子),并希望确保更改已完全生效。
- 如果使用 CONCURRENTLY 选项构建索引失败,则该索引将保留为“无效”。此类索引毫无用处,但使用 REINDEX 重建它们会很方便。
EXPLAIN 语句
demo=# \\h explainCommand: EXPLAINDescription: show the execution plan of a statementSyntax:EXPLAIN [ ( option [, ...] ) ] statementEXPLAIN [ ANALYZE ] [ VERBOSE ] statementwhere option can be one of: ANALYZE [ boolean ] VERBOSE [ boolean ] COSTS [ boolean ] SETTINGS [ boolean ] GENERIC_PLAN [ boolean ] BUFFERS [ boolean ] WAL [ boolean ] TIMING [ boolean ] SUMMARY [ boolean ] FORMAT { TEXT | XML | JSON | YAML }URL: https://www.postgresql.org/docs/16/sql-explain.html查询计划的结构是一个由计划节点组成的树。树底层的节点是扫描节点:它们返回表中的原始行。不同的表访问方法有不同类型的扫描节点:顺序扫描、索引扫描和位图索引扫描。
EXPLAIN 的输出为计划树中的每个节点各占一行,显示基本节点类型以及规划器为执行该计划节点所做的成本估算。可能会出现其他行,从节点的摘要行缩进(但是这些行不带成本,因此也不算单独的节点),以显示该节点的其他属性。
💡 第一行(最顶层节点的摘要行)包含该计划的预估总执行成本;规划者试图最小化这个数字。
示例:
demo=# explain select empno, salary from empsalary order by empno; QUERY PLAN---------------------------------------------------------------- Sort (cost=1.27..1.29 rows=10 width=8) Sort Key: empno -> Seq Scan on empsalary (cost=0.00..1.10 rows=10 width=8)(3 rows)由于此查询没有 WHERE 子句,它必须扫描表中的所有行,因此规划器选择使用简单的顺序扫描计划。括号中的数字从左到右依次为:
- 估计启动成本。这是输出阶段开始之前所花费的时间,例如,在排序节点中进行排序的时间。
- 估计总成本。这是基于计划节点运行完成(即检索到所有可用行)的假设。
- 此计划节点输出的估计行数。同样,假设该节点运行完成。
- 此计划节点输出的估计行平均宽度(以字节为单位)。
重要的是要理解,上层节点的成本包含其所有子节点的成本。同样重要的是要意识到,成本仅反映了规划器所关注的因素。具体而言,成本不考虑将输出值转换为文本形式或将其传输到客户端所花费的时间,而这些时间可能是实际耗时的重要因素;但规划器会忽略这些成本,因为它无法通过修改计划来改变这些成本。(我们相信,每个正确的计划都会输出相同的行集。)
rows的值有点棘手,因为它不是计划节点处理或扫描的行数,而是节点发出的行数。由于节点上应用了 WHERE 子句条件进行筛选,这个值通常小于扫描的行数。理想情况下,顶层行数的估计值应该接近查询实际返回、更新或删除的行数。
💡 EXPLAIN不会真执行查询,除非带ANALYZE参数。
EXPLAIN 输出格式
支持以下格式:
FORMAT { TEXT | XML | JSON | YAML }例如:
demo=# explain (format json) select empno, salary from empsalary order by empno; QUERY PLAN------------------------------------------- [ + { + \"Plan\": { + \"Node Type\": \"Sort\", + \"Parallel Aware\": false, + \"Async Capable\": false, + \"Startup Cost\": 1.27, + \"Total Cost\": 1.29, + \"Plan Rows\": 10, + \"Plan Width\": 8, + \"Sort Key\": [\"empno\"], + \"Plans\": [ + { + \"Node Type\": \"Seq Scan\", + \"Parent Relationship\": \"Outer\",+ \"Parallel Aware\": false, + \"Async Capable\": false, + \"Relation Name\": \"empsalary\", + \"Alias\": \"empsalary\", + \"Startup Cost\": 0.00, + \"Total Cost\": 1.10, + \"Plan Rows\": 10, + \"Plan Width\": 8 + } + ] + } + } + ](1 row)EXPLAIN ANALYZE
可以使用 EXPLAIN 的 ANALYZE 选项来检查规划器估算的准确性。使用此选项,EXPLAIN 会实际执行查询,然后显示每个计划节点中累积的真实行数和真实运行时间,以及与普通 EXPLAIN 相同的估算值。
💡 EXPLAIN ANALYZE不会显示SQL的结果集。这样输出很简洁。
示例,注意actual部分:
demo=# explain analyse select empno, salary from empsalary order by empno; QUERY PLAN----------------------------------------------------------------------------------------------------------- Sort (cost=1.27..1.29 rows=10 width=8) (actual time=0.028..0.030 rows=10 loops=1) Sort Key: empno Sort Method: quicksort Memory: 25kB -> Seq Scan on empsalary (cost=0.00..1.10 rows=10 width=8) (actual time=0.012..0.017 rows=10 loops=1) Planning Time: 0.059 ms Execution Time: 0.045 ms(6 rows)Planning Time是从解析后的查询生成查询计划并对其进行优化所花费的时间。它不包括解析或重写的时间。
Execution Time包括执行程序的启动和关闭时间,以及运行任何触发的触发器的时间,但不包括解析、重写或规划时间。
在某些查询计划中,子计划节点可能会执行多次。例如,在上述嵌套循环计划中,内层索引扫描将针对每个外层行执行一次。在这种情况下,loops值报告节点的总执行次数,而显示的实际时间和行数则是每次执行的平均值。
ANALYZE 选项会使语句真正执行,而不仅仅是进行计划。然后,实际运行时统计信息会被添加到显示中,包括每个计划节点内耗费的总时间(以毫秒为单位)以及实际返回的总行数。这有助于查看规划器的估算是否接近实际情况。
EXPLAIN 选项
ANALYZE也可以作为选项,除格式外,所有选项都是布尔值。
where option can be one of: ANALYZE [ boolean ] VERBOSE [ boolean ] COSTS [ boolean ] SETTINGS [ boolean ] GENERIC_PLAN [ boolean ] BUFFERS [ boolean ] WAL [ boolean ] TIMING [ boolean ] SUMMARY [ boolean ] FORMAT { TEXT | XML | JSON | YAML }选项说明见这里。
例如:
demo=# explain (verbose on) select empno, salary from empsalary order by empno; QUERY PLAN--------------------------------------------------------------------- Sort (cost=1.27..1.29 rows=10 width=8) Output: empno, salary Sort Key: empsalary.empno -> Seq Scan on demo.empsalary (cost=0.00..1.10 rows=10 width=8) Output: empno, salary(5 rows)demo=# explain select empno, salary from empsalary order by empno; QUERY PLAN---------------------------------------------------------------- Sort (cost=1.27..1.29 rows=10 width=8) Sort Key: empno -> Seq Scan on empsalary (cost=0.00..1.10 rows=10 width=8)(3 rows)复杂一点的例子:
demo=# explain (analyse on, verbose on, wal on, timing on, summary on) update empsalary set salary=salary * 1.1; QUERY PLAN----------------------------------------------------------------------------------------------------------------- Update on demo.empsalary (cost=0.00..1.18 rows=0 width=0) (actual time=0.125..0.126 rows=0 loops=1) WAL: records=10 fpi=1 bytes=1325 -> Seq Scan on demo.empsalary (cost=0.00..1.18 rows=10 width=10) (actual time=0.011..0.036 rows=10 loops=1) Output: ((salary)::numeric * 1.1), ctid Planning Time: 0.057 ms Execution Time: 0.184 ms(6 rows)demo=# explain (analyse on, verbose on, summary on, buffers on) select empno, salary from empsalary order by empno; QUERY PLAN---------------------------------------------------------------------------------------------------------------- Sort (cost=1.27..1.29 rows=10 width=8) (actual time=0.033..0.036 rows=10 loops=1) Output: empno, salary Sort Key: empsalary.empno Sort Method: quicksort Memory: 25kB Buffers: shared hit=1 -> Seq Scan on demo.empsalary (cost=0.00..1.10 rows=10 width=8) (actual time=0.015..0.021 rows=10 loops=1) Output: empno, salary Buffers: shared hit=1 Planning Time: 0.084 ms Execution Time: 0.052 ms(10 rows)查询调优示例
查询调优非常复杂,通常需要反复进行基于试验的优化。
创建2个示例表,users和posts。总共1000个用户,每用户500个帖子:
create table users(uid integer primary key, uname varchar(16));create table posts(post_id integer primary key, post_name varchar(32), uid integer, created_on timestamp);INSERT INTO users (uid, uname)SELECT uid, \'user_\' || uidFROM generate_series(1, 1000) AS uid;INSERT INTO posts (post_id, post_name, uid, created_on)SELECT (u.uid - 1) * 500 + p AS post_id, \'post_\' || ((u.uid - 1) * 500 + p) AS post_name, u.uid AS uid, NOW() - (TRUNC(RANDOM() * 365) || \' days\')::interval - (TRUNC(RANDOM() * 24) || \' hours\')::interval - (TRUNC(RANDOM() * 60) || \' minutes\')::interval - (TRUNC(RANDOM() * 60) || \' seconds\')::intervalFROM generate_series(1, 1000) AS u(uid) CROSS JOIN generate_series(1, 500) AS p;大致看下数据:
demo=# \\d users Table \"demo.users\" Column | Type | Collation | Nullable | Default--------+-----------------------+-----------+----------+--------- uid | integer | | not null | uname | character varying(16) | | |Indexes: \"users_pkey\" PRIMARY KEY, btree (uid)demo=# \\d posts Table \"demo.posts\" Column | Type | Collation | Nullable | Default------------+-----------------------------+-----------+----------+--------- post_id | integer | | not null | post_name | character varying(32) | | | uid | integer | | | created_on | timestamp without time zone | | |Indexes: \"posts_pkey\" PRIMARY KEY, btree (post_id)demo=# select count(*) from posts where uid=10; count------- 500(1 row)demo=# select * from users limit 10; uid | uname-----+--------- 1 | user_1 2 | user_2 3 | user_3 4 | user_4 5 | user_5 6 | user_6 7 | user_7 8 | user_8 9 | user_9 10 | user_10(10 rows)demo=# select * from posts where uid = 10 limit 10; post_id | post_name | uid | created_on---------+-----------+-----+---------------------------- 4501 | post_4501 | 10 | 2025-06-08 03:17:03.304012 4502 | post_4502 | 10 | 2024-11-16 12:19:06.304012 4503 | post_4503 | 10 | 2024-11-21 15:48:09.304012 4504 | post_4504 | 10 | 2024-12-11 13:05:28.304012 4505 | post_4505 | 10 | 2024-07-17 01:22:22.304012 4506 | post_4506 | 10 | 2024-10-15 03:18:04.304012 4507 | post_4507 | 10 | 2024-10-13 07:52:45.304012 4508 | post_4508 | 10 | 2024-11-27 08:21:14.304012 4509 | post_4509 | 10 | 2024-10-12 17:47:49.304012 4510 | post_4510 | 10 | 2024-09-10 17:06:14.304012(10 rows)表的大小:
demo=# SELECT reltuples, pg_size_pretty( pg_relation_size( oid ) ), relname FROM pg_classWHERE relname IN ( \'posts\', \'users\' ) AND relkind = \'r\'; reltuples | pg_size_pretty | relname-----------+----------------+--------- 1000 | 48 kB | users 500000 | 29 MB | posts(2 rows)示例1
第一个示例,按发帖时间排序显示所有帖子:
demo=# explain SELECT * FROM posts ORDER BY created_on; QUERY PLAN-------------------------------------------------------------------- Sort (cost=67968.92..69218.92 rows=500000 width=27) Sort Key: created_on -> Seq Scan on posts (cost=0.00..8677.00 rows=500000 width=27)(3 rows)因为没有where条件,并且列上也没有索引,因此选择Seq Scan。
实际执行时间:
demo=# explain analyse SELECT * FROM posts ORDER BY created_on; QUERY PLAN--------------------------------------------------------------------------------------------------------------------- Sort (cost=67968.92..69218.92 rows=500000 width=27) (actual time=656.684..1045.327 rows=500000 loops=1) Sort Key: created_on Sort Method: external merge Disk: 20616kB -> Seq Scan on posts (cost=0.00..8677.00 rows=500000 width=27) (actual time=0.011..132.352 rows=500000 loops=1) Planning Time: 0.064 ms Execution Time: 1123.466 ms(6 rows)如果在created_on列上建索引,会提升以上SQL的性能(从1123ms到892ms):
demo=# CREATE INDEX idx_posts_date ON posts (created_on);CREATE INDEXdemo=# explain analyse SELECT * FROM posts ORDER BY created_on; QUERY PLAN--------------------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_posts_date on posts (cost=0.42..27694.84 rows=500000 width=27) (actual time=0.120..818.330 rows=500000 loops=1) Planning Time: 0.301 ms Execution Time: 892.485 ms(3 rows)当然,索引是有成本的。其大小约为表的38%。成本是否值得取决于你执行此查询的频度:
demo=# SELECT pg_size_pretty( pg_relation_size( \'posts\' ) ) AS table_size, pg_size_pretty( pg_relation_size( \'idx_posts_date\' ) ) AS index_size; table_size | index_size------------+------------ 29 MB | 11 MB(1 row)示例2
找出某用户在某时间段内的所有帖子。
SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date; post_name | uname-------------+---------- post_443649 | user_888 post_443730 | user_888 post_443766 | user_888 post_443874 | user_888 post_443889 | user_888 post_443903 | user_888 post_443983 | user_888 post_443600 | user_888 post_443613 | user_888 post_443731 | user_888 post_443756 | user_888 post_443798 | user_888 post_443881 | user_888 post_443938 | user_888 post_443985 | user_888 post_443581 | user_888 post_443582 | user_888 post_443614 | user_888 post_443634 | user_888 post_443672 | user_888 post_443725 | user_888 post_443754 | user_888 post_443909 | user_888 post_443921 | user_888 post_443940 | user_888 post_443977 | user_888 post_443989 | user_888(27 rows)@>是array operator,说明见这里。
解释执行计划:
demo=# explain SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date; QUERY PLAN-------------------------------------------------------------------------------------------- Gather (cost=1018.51..9906.79 rows=2 width=19) Workers Planned: 2 -> Hash Join (cost=18.51..8906.59 rows=1 width=19) Hash Cond: (p.uid = u.uid) -> Parallel Seq Scan on posts p (cost=0.00..8885.33 rows=1042 width=15) Filter: (daterange((CURRENT_DATE - 20), CURRENT_DATE) @> (created_on)::date) -> Hash (cost=18.50..18.50 rows=1 width=12) -> Seq Scan on users u (cost=0.00..18.50 rows=1 width=12) Filter: ((uname)::text = \'user_888\'::text)(9 rows)顶端是Gather 节点,说明启用了并行。Workers Planned: 2说明并行度为2。
实际执行计划:
demo=# explain analyse SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date; QUERY PLAN---------------------------------------------------------------------------------------------------------------------------------- Gather (cost=1018.51..9906.79 rows=2 width=19) (actual time=123.654..571.029 rows=27 loops=1) Workers Planned: 2 Workers Launched: 2 -> Hash Join (cost=18.51..8906.59 rows=1 width=19) (actual time=134.466..535.107 rows=9 loops=3) Hash Cond: (p.uid = u.uid) -> Parallel Seq Scan on posts p (cost=0.00..8885.33 rows=1042 width=15) (actual time=1.040..529.555 rows=9202 loops=3) Filter: (daterange((CURRENT_DATE - 20), CURRENT_DATE) @> (created_on)::date) Rows Removed by Filter: 157464 -> Hash (cost=18.50..18.50 rows=1 width=12) (actual time=0.711..0.712 rows=1 loops=3) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Seq Scan on users u (cost=0.00..18.50 rows=1 width=12) (actual time=0.613..0.694 rows=1 loops=3) Filter: ((uname)::text = \'user_888\'::text) Rows Removed by Filter: 999 Planning Time: 9.774 ms Execution Time: 572.111 ms(15 rows)在posts表的uid列上建立索引:
demo=# CREATE INDEX idx_posts_author ON posts(uid);CREATE INDEXdemo=# explain analyse SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date; QUERY PLAN----------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=8.17..1413.95 rows=2 width=19) (actual time=1.481..3.367 rows=27 loops=1) -> Seq Scan on users u (cost=0.00..18.50 rows=1 width=12) (actual time=0.486..0.620 rows=1 loops=1) Filter: ((uname)::text = \'user_888\'::text) Rows Removed by Filter: 999 -> Bitmap Heap Scan on posts p (cost=8.17..1395.43 rows=2 width=15) (actual time=0.991..2.731 rows=27 loops=1) Recheck Cond: (uid = u.uid) Filter: (daterange((CURRENT_DATE - 20), CURRENT_DATE) @> (created_on)::date) Rows Removed by Filter: 473 Heap Blocks: exact=500 -> Bitmap Index Scan on idx_posts_author (cost=0.00..8.17 rows=500 width=0) (actual time=0.771..0.771 rows=500 loops=1) Index Cond: (uid = u.uid) Planning Time: 3.547 ms Execution Time: 3.427 ms(13 rows)提升非常明显(572.111到3.427)。刚建的索引用上了,并行变成了串行执行。
看下索引大小:
demo=# SELECT pg_size_pretty( pg_relation_size( \'posts\') ) AS table_size, pg_size_pretty( pg_relation_size( \'idx_posts_date\' ) ) AS idx_date_size, pg_size_pretty( pg_relation_size( \'idx_posts_author\' ) ) AS idx_author_size; table_size | idx_date_size | idx_author_size------------+---------------+----------------- 29 MB | 11 MB | 3600 kB(1 row)根据文档,pg_statio_all_indexes 视图将为当前数据库中的每个索引包含一行,显示该特定索引的 I/O 统计信息。pg_statio_user_indexes 和 pg_statio_sys_indexes 视图包含相同的信息,但分别经过筛选,仅显示用户索引和系统索引。
以下说明SQL没有用到索引idx_posts_date:
demo=# SELECT indexrelname, idx_scan, idx_tup_read, idx_tup_fetch FROM pg_stat_user_indexes WHERE relname = \'posts\'; indexrelname | idx_scan | idx_tup_read | idx_tup_fetch------------------+----------+--------------+--------------- posts_pkey | 0 | 0 | 0 idx_posts_date | 1 | 1500000 | 1500000 idx_posts_author | 9 | 1506 | 0(3 rows)demo=# SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date; post_name | uname-------------+---------- post_443581 | user_888 post_443582 | user_888 post_443600 | user_888 post_443613 | user_888...(27 rows)demo=# SELECT indexrelname, idx_scan, idx_tup_read, idx_tup_fetch FROM pg_stat_user_indexes WHERE relname = \'posts\'; indexrelname | idx_scan | idx_tup_read | idx_tup_fetch------------------+----------+--------------+--------------- posts_pkey | 0 | 0 | 0 idx_posts_date | 1 | 1500000 | 1500000 idx_posts_author | 12 | 2008 | 0(3 rows)如果idx_posts_date使用较少,就可以将其删除:
demo=# explain analyse SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date;... Planning Time: 0.683 ms Execution Time: 4.162 ms(13 rows)demo=# drop index idx_posts_date;DROP INDEXdemo=# explain analyse SELECT p.post_name, u.unameFROM posts pJOIN users u ON u.uid = p.uidWHERE u.uname = \'user_888\'AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date;... Planning Time: 0.569 ms Execution Time: 3.724 ms(13 rows)🤦,再建回来吧,下一个例子要用:
CREATE INDEX idx_posts_date ON posts (created_on);示例3
演示改写一个写得不好的SQL。
本例需要改下表结构:
alter table posts add column likes integer;update posts set likes = round(random()*10);select distinct likes from posts; likes------- 0 1 2 3 4 5 6 7 8 9 10(11 rows)原始SQL如下:
demo=# EXPLAIN ANALYSE SELECT u.unameFROM users u JOIN posts p ON p.uid = u.uidWHERE p.created_on::date = CURRENT_DATE - 5 AND u.uid IN ( SELECT pp.uid FROM posts pp WHERE likes = 5 AND p.created_on = created_on); QUERY PLAN------------------------------------------------------------------------------------------------------------------------------------ Hash Join (cost=1028.50..13300.18 rows=1250 width=8) (actual time=4.954..230.749 rows=135 loops=1) Hash Cond: (p.uid = u.uid) Join Filter: (SubPlan 1) Rows Removed by Join Filter: 1261 -> Gather (cost=1000.00..13260.67 rows=2500 width=12) (actual time=1.827..202.557 rows=1396 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on posts p (cost=0.00..12010.67 rows=1042 width=12) (actual time=0.506..196.148 rows=465 loops=3) Filter: ((created_on)::date = (CURRENT_DATE - 5)) Rows Removed by Filter: 166201 -> Hash (cost=16.00..16.00 rows=1000 width=12) (actual time=1.591..1.593 rows=1000 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 55kB -> Seq Scan on users u (cost=0.00..16.00 rows=1000 width=12) (actual time=0.035..0.724 rows=1000 loops=1) SubPlan 1 -> Index Scan using idx_posts_date on posts pp (cost=0.42..8.44 rows=1 width=4) (actual time=0.016..0.016 rows=0 loops=1396) Index Cond: (created_on = p.created_on) Filter: (likes = 5) Rows Removed by Filter: 1 Planning Time: 0.727 ms Execution Time: 230.846 ms(20 rows)注意到loops=1396。
为了去除loop,改写为以下:
demo=# EXPLAIN ANALYSEWITH likes AS ( SELECT pp.uid, pp.created_on FROM posts pp WHERE likes = 5 GROUP BY pp.uid, pp.created_on )SELECT u.unameFROM users u JOIN posts p ON p.uid = u.uidJOIN likes l ON l.created_on = p.created_on AND l.uid = u.uidWHERE p.created_on = CURRENT_DATE - 5; QUERY PLAN-------------------------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=9.16..25.24 rows=1 width=8) (actual time=0.022..0.024 rows=0 loops=1) Join Filter: (u.uid = p.uid) -> Nested Loop (cost=8.88..16.93 rows=1 width=8) (actual time=0.022..0.023 rows=0 loops=1) Join Filter: (p.uid = pp.uid) -> Group (cost=8.46..8.46 rows=1 width=12) (actual time=0.021..0.022 rows=0 loops=1) Group Key: pp.uid -> Sort (cost=8.46..8.46 rows=1 width=12) (actual time=0.021..0.021 rows=0 loops=1) Sort Key: pp.uid Sort Method: quicksort Memory: 25kB -> Index Scan using idx_posts_date on posts pp (cost=0.43..8.45 rows=1 width=12) (actual time=0.016..0.016 rows=0 loops=1) Index Cond: (created_on = (CURRENT_DATE - 5)) Filter: (likes = 5) -> Index Scan using idx_posts_date on posts p (cost=0.43..8.45 rows=1 width=12) (never executed) Index Cond: (created_on = (CURRENT_DATE - 5)) -> Index Scan using users_pkey on users u (cost=0.28..8.29 rows=1 width=12) (never executed) Index Cond: (uid = pp.uid) Planning Time: 1.019 ms Execution Time: 0.081 ms(18 rows)loop确实没了,而且快了很多。
其实最简捷的写法如下:
demo=# EXPLAIN ANALYZESELECT u.unameFROM users u JOIN posts p ON p.uid = u.uidWHERE p.created_on = CURRENT_DATE - 5AND p.likes = 5; QUERY PLAN------------------------------------------------------------------------------------------------------------------------------ Nested Loop (cost=0.70..16.76 rows=1 width=8) (actual time=0.017..0.017 rows=0 loops=1) -> Index Scan using idx_posts_date on posts p (cost=0.43..8.45 rows=1 width=4) (actual time=0.016..0.016 rows=0 loops=1) Index Cond: (created_on = (CURRENT_DATE - 5)) Filter: (likes = 5) -> Index Scan using users_pkey on users u (cost=0.28..8.29 rows=1 width=12) (never executed) Index Cond: (uid = p.uid) Planning Time: 0.422 ms Execution Time: 0.043 ms(8 rows)ANALYZE 以及如何更新统计信息
ANALYZE收集统计信息,最优的执行计划依赖准确的统计信息。
demo=# \\h analyzeCommand: ANALYZEDescription: collect statistics about a databaseSyntax:ANALYZE [ ( option [, ...] ) ] [ table_and_columns [, ...] ]ANALYZE [ VERBOSE ] [ table_and_columns [, ...] ]where option can be one of: VERBOSE [ boolean ] SKIP_LOCKED [ boolean ] BUFFER_USAGE_LIMIT sizeand table_and_columns is: table_name [ ( column_name [, ...] ) ]URL: https://www.postgresql.org/docs/16/sql-analyze.htmlANALYZE只针对单标,要搜集整个schema的统计信息,请参考这里。
示例:
demo=# \\timingTiming is on.demo=# analyze posts;ANALYZETime: 861.135 msdemo=# \\timingTiming is off.💡 目录 pg_statistic 存储了数据库内容的统计数据。这些条目由 ANALYZE 创建,随后供查询规划器使用。请注意,所有统计数据本质上都是近似值,即使假设它是最新的。
视图 pg_stats 提供对存储在 pg_statistic 目录中的信息的访问。
demo=# SELECT n_distinct FROM pg_stats WHERE attname = \'uid\' AND tablename = \'posts\'; n_distinct------------ 1000(1 row)查询点赞的分布,可以看出实际信息与统计信息有少许出入:
demo=# select most_common_vals, most_common_freqs from pg_stats where tablename = \'posts\' and attname = \'likes\'; most_common_vals | most_common_freqs--------------------------+----------------------------------------------------------------------------------------------------------- {3,6,1,7,9,8,5,4,2,10,0} | {0.10306667,0.101733334,0.1008,0.1006,0.10053334,0.10036667,0.0994,0.0989,0.0962,0.049533334,0.048866667}(1 row)demo=# select likes, count(*) from posts group by 1 order by 2; likes | count-------+------- 10 | 24676 0 | 25091 8 | 49675 2 | 49874 7 | 49890 9 | 50011 3 | 50055 4 | 50112 6 | 50157 1 | 50197 5 | 50262(11 rows)统计信息由VACUUM定期自动搜集:
$ ps -ef|grep vacuumpostgres 1041 957 0 Jun24 ? 00:00:00 postgres: autovacuum launcher自动解释
auto_explain 模块提供了一种自动记录慢速语句执行计划的方法,无需手动运行 EXPLAIN。这对于追踪大型应用程序中未优化的查询尤其有用。详见文档。
示例,假设我们知道此SQL执行通常在2毫秒以下:
demo=# show auto_explain.log_min_duration; auto_explain.log_min_duration------------------------------- 0(1 row)demo=# SET auto_explain.log_analyze = true;SETdemo=# SET auto_explain.log_min_duration = 2;SETdemo=# SELECT p.post_name, u.uname...demo=# show log_directory; log_directory--------------- log(1 row)demo=# SHOW log_filename; log_filename------------------- postgresql-%a.log(1 row)查看日志文件:
$ dateWed Jun 25 05:56:37 AM UTC 2025$ ls -lttotal 128-rw-------. 1 postgres postgres 13859 Jun 25 05:54 postgresql-Wed.log-rw-------. 1 postgres postgres 11274 Jun 24 23:43 postgresql-Tue.log-rw-------. 1 postgres postgres 13151 Jun 23 11:00 postgresql-Mon.log-rw-------. 1 postgres postgres 20504 Jun 22 23:59 postgresql-Sun.log-rw-------. 1 postgres postgres 14928 Jun 21 13:53 postgresql-Sat.log-rw-------. 1 postgres postgres 27959 Jun 20 10:38 postgresql-Fri.log-rw-------. 1 postgres postgres 14498 Jun 19 23:58 postgresql-Thu.log$ cat postgresql-Wed.log...2025-06-25 05:54:58.427 UTC [13590] LOG: duration: 3.531 ms plan: Query Text: SELECT p.post_name, u.uname FROM posts p JOIN users u ON u.uid = p.uid WHERE u.uname = \'user_888\' AND daterange( CURRENT_DATE - 20, CURRENT_DATE ) @> p.created_on::date; Nested Loop (cost=12.17..1622.65 rows=2 width=19) (actual time=1.378..3.492 rows=27 loops=1) -> Seq Scan on users u (cost=0.00..18.50 rows=1 width=12) (actual time=0.569..0.631 rows=1 loops=1) Filter: ((uname)::text = \'user_888\'::text) Rows Removed by Filter: 999 -> Bitmap Heap Scan on posts p (cost=12.17..1604.13 rows=2 width=15) (actual time=0.801..2.839 rows=27 loops=1) Recheck Cond: (uid = u.uid) Filter: (daterange((CURRENT_DATE - 20), CURRENT_DATE) @> (created_on)::date) Rows Removed by Filter: 473 Heap Blocks: exact=500 -> Bitmap Index Scan on idx_posts_author (cost=0.00..12.17 rows=500 width=0) (actual time=0.134..0.134 rows=500 loops=1)Index Cond: (uid = u.uid)总结
略。
验证你的知识
- 如何查看执行计划?
- EXPLAIN 和 EXPLAIN ANALYZE的区别?
- PG如何保证统计信息的准确?
- 优化器如何决定选择哪条访问路径?
- auto_explain 模块/扩展的作用?
参考文献
- 19.7. Query Planning
- 50.5. Planner/Optimizer
- Postgres Indexes Deep dive


