【基础篇二】深入理解HTTP协议与Web通信:从基础到现代化演进
目录
一、HTTP协议基础:Web通信语言
1.1 HTTP消息结构
1.2 核心工作原理
编辑
二、HTTP版本演进:解决性能瓶颈
2.1 版本特性对比
2.2 性能演进实例
三、连接管理:短连接、长连接、连接复用
3.1 三种连接模式
1. 短连接 (HTTP/1.0默认)
2. 长连接 (HTTP/1.1默认)
3. 连接复用 (HTTP/2)
3.2 连接管理实践
四、RESTful API设计原则
4.1 REST核心概念
4.2 HTTP方法语义
4.3 RESTful API设计实例
4.4 状态码
五、请求-响应模型的局限性
5.1 核心局限性分析
1. 单向通信限制
2. 连接开销问题
3. 状态管理复杂
4. 实时性不足
5.2 解决方案演进
六、总结
HTTP协议是Web的基石,从1991年的 HTTP/0.9 到如今的 HTTP/3 ,每一次演进都在解决实际的性能和功能问题。本文将深入剖析 HTTP 协议的工作原理、版本演进,以及传统请求-响应模型的局限性,为理解现代异步Web开发奠定基础。
一、HTTP协议基础:Web通信语言
1.1 HTTP消息结构
# HTTP请求示例GET /api/users/123 HTTP/1.1Host: api.example.comAuthorization: Bearer token123Accept: application/json# HTTP响应示例 HTTP/1.1 200 OKContent-Type: application/jsonContent-Length: 85{ \"id\": 123, \"name\": \"Alice\", \"email\": \"alice@example.com\"}1.2 核心工作原理
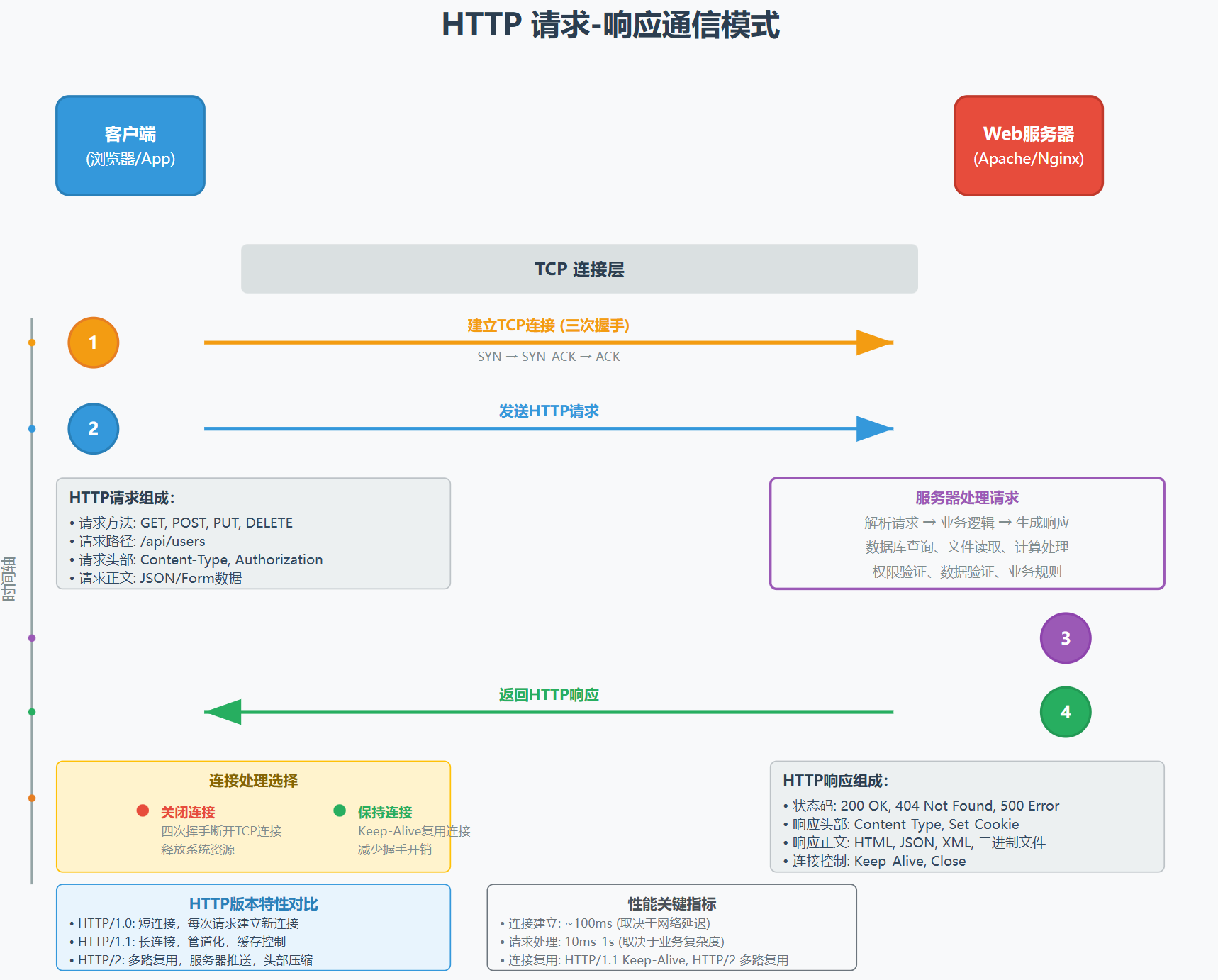
HTTP通信遵循简单的请求-响应模式:
客户端发起TCP连接
发送HTTP请求(方法、路径、头部、正文)
服务器处理请求
返回HTTP响应(状态码、头部、正文)
关闭或保持连接
重要特性:HTTP是无状态协议,服务器不会记住之前的请求。这意味着每个请求都是独立的,需要通过Cookie、Session或Token等机制来维护状态。
二、HTTP版本演进:解决性能瓶颈
2.1 版本特性对比
2.2 性能演进实例
假设加载一个网页需要10个资源文件,不同HTTP版本的表现:
# 性能对比计算resources = 10connection_time = 100 # TCP连接时间 (ms)transfer_time = 50 # 单个资源传输时间 (ms)# HTTP/1.0: 每个资源都要新建连接http_1_0_time = resources * (connection_time + transfer_time) # 1500ms# HTTP/1.1: 复用连接,但串行传输http_1_1_time = connection_time + resources * transfer_time # 600ms# HTTP/2: 并行传输http_2_time = connection_time + transfer_time # 150msprint(f\"HTTP/1.0: {http_1_0_time}ms\")print(f\"HTTP/1.1: {http_1_1_time}ms\") print(f\"HTTP/2: {http_2_time}ms\")print(f\"HTTP/2相比HTTP/1.1提升: {(http_1_1_time-http_2_time)/http_1_1_time*100:.1f}%\")结果:HTTP/2相比HTTP/1.1性能提升了75%!
三、连接管理:短连接、长连接、连接复用
3.1 三种连接模式
1. 短连接 (HTTP/1.0默认)
- 工作方式:请求 → 建立连接 → 传输数据 → 关闭连接
- 优点:简单,服务器资源占用少
- 缺点:连接开销大,不适合频繁请求
- 适用场景:偶发的API调用、批处理任务
2. 长连接 (HTTP/1.1默认)
- 工作方式:建立连接 → 多次请求/响应 → 超时或主动关闭
- 优点:减少连接开销,提高效率
- 缺点:服务器需要管理更多连接状态
- 适用场景:Web浏览器访问、移动应用API调用
3. 连接复用 (HTTP/2)
- 工作方式:单个连接 → 多个并行流 → 真正的并发
- 优点:最大化连接利用率,消除队头阻塞
- 缺点:实现复杂度高
- 适用场景:现代Web应用、高并发API服务
3.2 连接管理实践
import asyncioimport aiohttp# HTTP/1.1 长连接示例async def http_1_1_example(): \"\"\"HTTP/1.1长连接的使用\"\"\" async with aiohttp.ClientSession() as session: # 同一个session会复用连接 async with session.get(\'https://api.example.com/users\') as resp: users = await resp.json() async with session.get(\'https://api.example.com/posts\') as resp: posts = await resp.json() # 连接在session关闭时才断开# HTTP/2 连接复用示例async def http_2_example(): \"\"\"HTTP/2连接复用的优势\"\"\" connector = aiohttp.TCPConnector(force_close=False, enable_cleanup_closed=True) async with aiohttp.ClientSession(connector=connector) as session: # 多个请求可以在同一连接上并行处理 tasks = [ session.get(\'https://httpbin.org/delay/1\'), session.get(\'https://httpbin.org/delay/1\'), session.get(\'https://httpbin.org/delay/1\') ] responses = await asyncio.gather(*tasks) # 三个请求并行执行,而不是串行四、RESTful API设计原则
4.1 REST核心概念
REST (Representational State Transfer) 是一种架构风格,强调:
- 资源导向:一切都是资源,用URL标识
- 统一接口:使用标准HTTP方法
- 无状态:每个请求包含完整信息
- 可缓存:响应应明确是否可缓存
- 分层系统:客户端无需知道中间层
4.2 HTTP方法语义
GET /api/users/123POST /api/usersPUT /api/users/123PATCH /api/users/123DELETE /api/users/1234.3 RESTful API设计实例
# 用户管理API的RESTful设计class UserAPI: \"\"\"RESTful用户API设计示例\"\"\" def get_users(self): \"\"\"GET /api/users?page=1&limit=10&status=active\"\"\" return { \"method\": \"GET\", \"url\": \"/api/users\", \"query_params\": [\"page\", \"limit\", \"status\"], \"response\": \"200 OK + 用户列表\" } def get_user(self, user_id): \"\"\"GET /api/users/{id}\"\"\" return { \"method\": \"GET\", \"url\": f\"/api/users/{user_id}\", \"response\": \"200 OK + 用户详情 | 404 Not Found\" } def create_user(self): \"\"\"POST /api/users\"\"\" return { \"method\": \"POST\", \"url\": \"/api/users\", \"body\": {\"name\": \"Alice\", \"email\": \"alice@example.com\"}, \"response\": \"201 Created + 新用户信息\" } def update_user(self, user_id): \"\"\"PUT /api/users/{id}\"\"\" return { \"method\": \"PUT\", \"url\": f\"/api/users/{user_id}\", \"body\": {\"name\": \"Alice Updated\", \"email\": \"alice.new@example.com\"}, \"response\": \"200 OK + 更新后用户信息\" } def delete_user(self, user_id): \"\"\"DELETE /api/users/{id}\"\"\" return { \"method\": \"DELETE\", \"url\": f\"/api/users/{user_id}\", \"response\": \"204 No Content | 404 Not Found\" }4.4 状态码
五、请求-响应模型的局限性
5.1 核心局限性分析
1. 单向通信限制
- 问题:只能客户端主动发起请求,服务器无法主动推送
- 影响:实时性差,无法及时通知客户端
- 典型场景:实时通知、股价更新、聊天消息
2. 连接开销问题
- 问题:每次通信都要完整的请求-响应周期
- 影响:延迟高,资源浪费
- 典型场景:频繁的小数据交互
3. 状态管理复杂
- 问题:HTTP无状态,需要额外机制维护状态
- 影响:增加复杂度,性能开销
- 典型场景:用户会话、购物车状态
4. 实时性不足
- 问题:只能通过轮询方式实现伪实时
- 影响:资源浪费,延迟不可控
- 典型场景:实时游戏、协作编辑
5.2 解决方案演进
六、总结
过去 (HTTP/1.x):
- 解决了基本的Web通信需求
- 建立了请求-响应模型标准
- 但存在性能和实时性局限
现在 (HTTP/2/3):
- 大幅提升了传输性能
- 解决了队头阻塞问题
- 但仍基于请求-响应模型
未来趋势:
- 更多实时通信协议 (WebSocket, WebRTC)
- 边缘计算和CDN优化
- HTTP/3普及和新协议探索

