Windows系统下复现PointNet++算法_pointnet++复现
写在前面的话:
复现PointNet++算法并不难,大家动手做就会成功!复现过程中有很多报错问题,解决过程中主要参考了这篇文章:Windows系统保姆级复现Pointnet++算法教程笔记(基于Pytorch),在此表示感谢!
一、程序下载
官方下载地址为:https://github.com/yanx27/Pointnet_Pointnet2_pytorch
也可用网盘下载:https://pan.quark.cn/s/555b5649d013
网盘中的程序已将报错解决且含有三类任务对应的数据集,可一键运行。
二、环境配置
为方便,环境配置也同上述参考文章。
1. 创建名为pointnet的虚拟环境,python版本为3.8
conda create -n pointnet python=3.8.02.激活虚拟环境
conda activate pointnet3.下载安装pytorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116环境配置完成后,若在程序运行过程中缺少xxx模块的话,可conda install xxx或者pip install xxx安装相应模块即可。
如:ModuleNotFoundError: No module named \'tqdm\'
解决方法:conda install tqdm或pip install tqdm
以下内容均以官方程序为例,尽量详细!
三、语义分割任务
语义分割用到的数据集为:Stanford3dDataset_v1.2_Aligned_Version
该数据集以 .txt 文件格式存储,分为 6 个区域(Area_1 到 Area_6),每个区域包含多个房间,每个房间包含一个 Annotations 文件夹和一个整体点云文件(如 conferenceRoom_1.txt)。每个点包含 6 个维度的信息,分别是三维坐标(x, y, z)和颜色信息(r, g, b),每个点都被标注了语义类别,共有 13 个类别。
数据集下载地址:https://www.kaggle.com/datasets/ggulmira/stanford3ddataset-v12-aligned-version?resource=download-directory
网盘下载地址:https://pan.quark.cn/s/2d25db0160ca
1.train_semseg.py
报错1:FileNotFoundError: [WinError 3] 系统找不到指定的路径。: \'data/stanford_indoor3d/\'
解决方法:(1)在Pointnet_Pointnet2_pytorch-master\\data路径下新建文件夹s3dis,然后将Stanford3dDataset_v1.2_Aligned_Version移动到s3dis路径下,如图所示:
 (2)在Pointnet_Pointnet2_pytorch-master\\data_utils路径找到collect_indoor3d_data.py,点击运行;在Pointnet_Pointnet2_pytorch-master\\data\\s3dis\\Stanford3dDataset_v1.2_Aligned_Version路径下会生成.npy文件,同时Pointnet_Pointnet2_pytorch-master\\data路径下会生成stanford_indoor3d文件夹,将Stanford3dDataset_v1.2_Aligned_Version文件夹下的所有.npy文件复制到stanford_indoor3d文件夹中。
(2)在Pointnet_Pointnet2_pytorch-master\\data_utils路径找到collect_indoor3d_data.py,点击运行;在Pointnet_Pointnet2_pytorch-master\\data\\s3dis\\Stanford3dDataset_v1.2_Aligned_Version路径下会生成.npy文件,同时Pointnet_Pointnet2_pytorch-master\\data路径下会生成stanford_indoor3d文件夹,将Stanford3dDataset_v1.2_Aligned_Version文件夹下的所有.npy文件复制到stanford_indoor3d文件夹中。
此时,data目录如下:
报错2:EOFError: Ran out of input
解决方法:将train_semseg.py中第101和104行的num_workers设置为0即可。
成功运行!
训练的日志文件以及权重文件保存在Pointnet_Pointnet2_pytorch-master\\log\\sem_seg路径下以时间命名的文件夹中。
2.test_semseg.py
训练完成后直接运行test_semseg.py
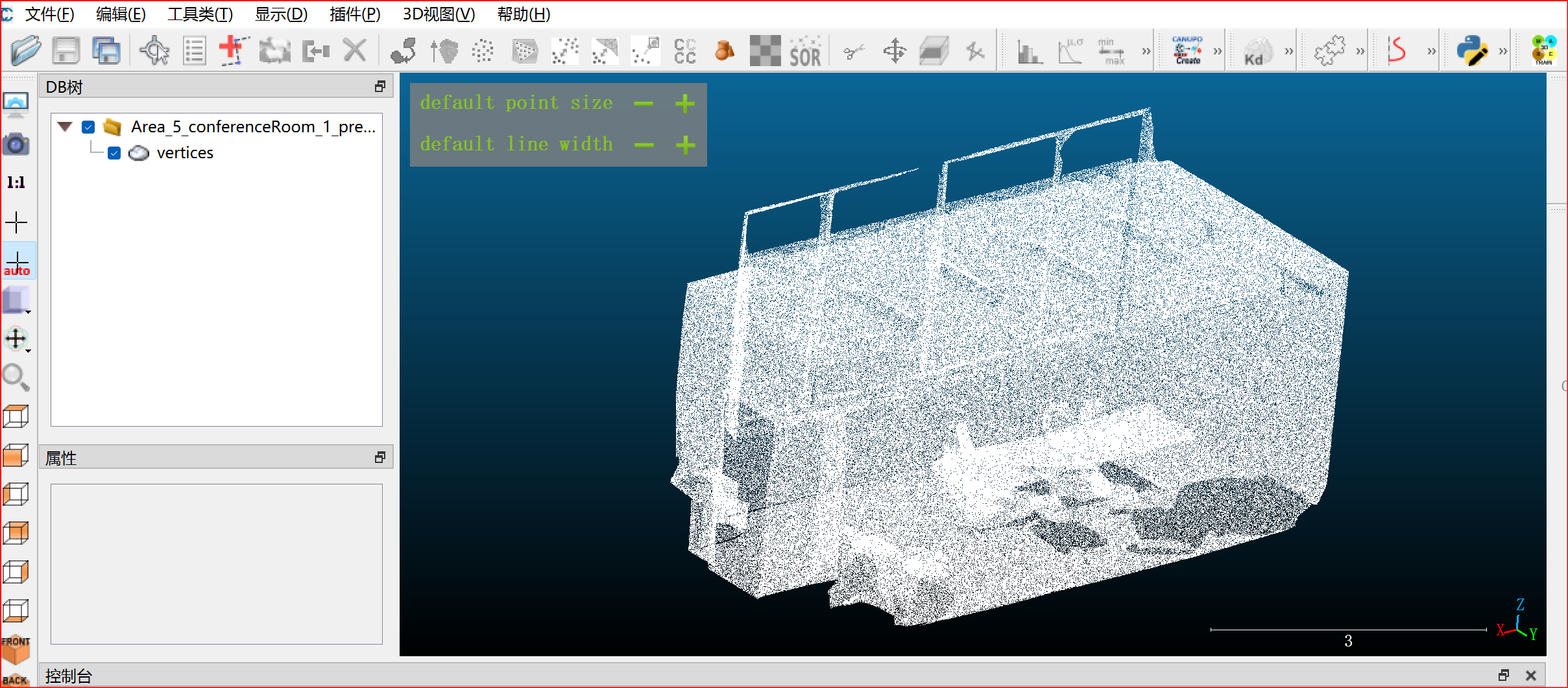
运行前须知:语义分割结果可视化,在代码第38行中将\'--visual\'的值设为True,测试完成后在存放权重文件的路径下会生成visual文件夹,里边的测试数据以.obj形式存在,使用CloudCompare软件可查看,同时点云数据集以.txt形式存储的数据也可使用该软件查看。
CloudCompare官方地址:https://www.cloudcompare.org/,进入后点击Download,可下载不同版本。
网盘地址:https://pan.quark.cn/s/a969b9e706da(截止目前最新版)
parser.add_argument(\'--visual\', action=\'store_true\', default=True, help=\'visualize result [default: False]\')
CloudCompare查看.txt格式的点云数据:
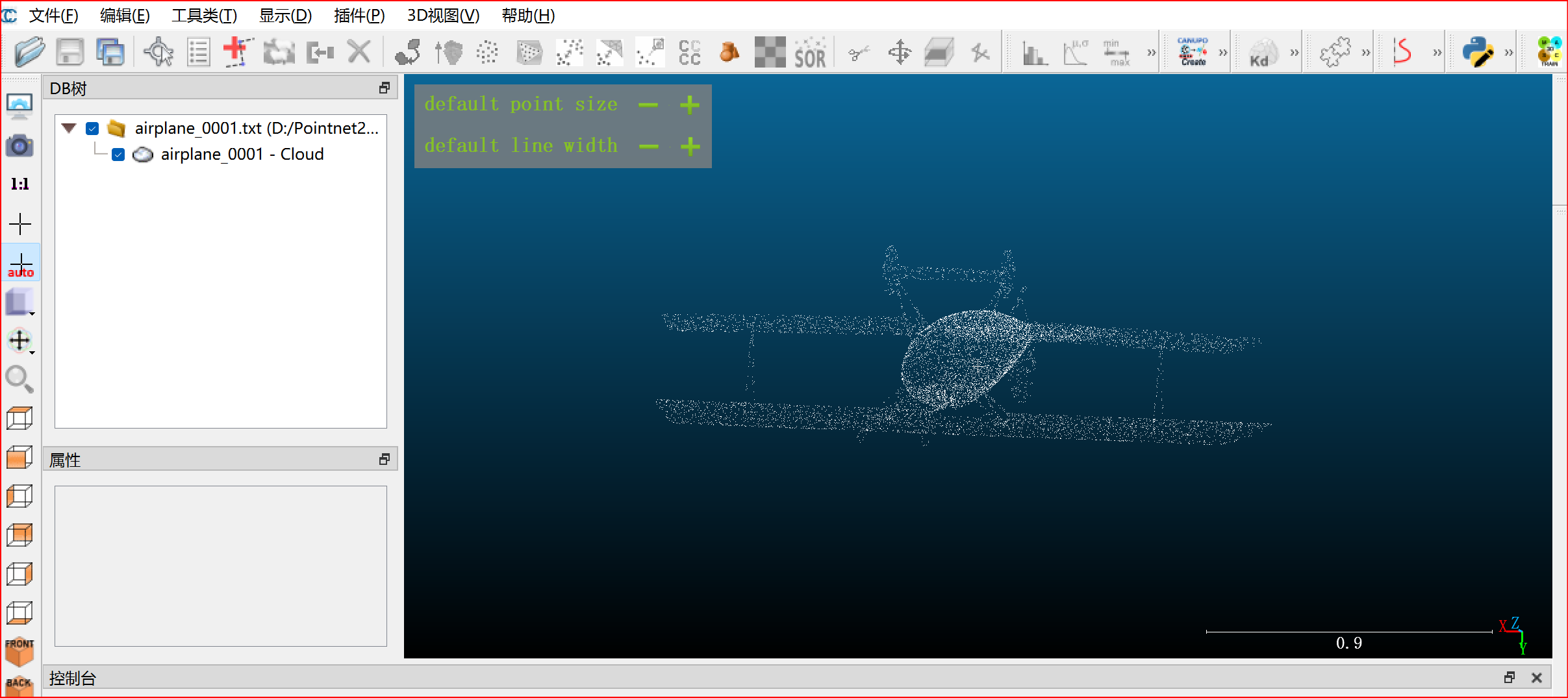
CloudCompare查看语义分割测试结果.obj文件:
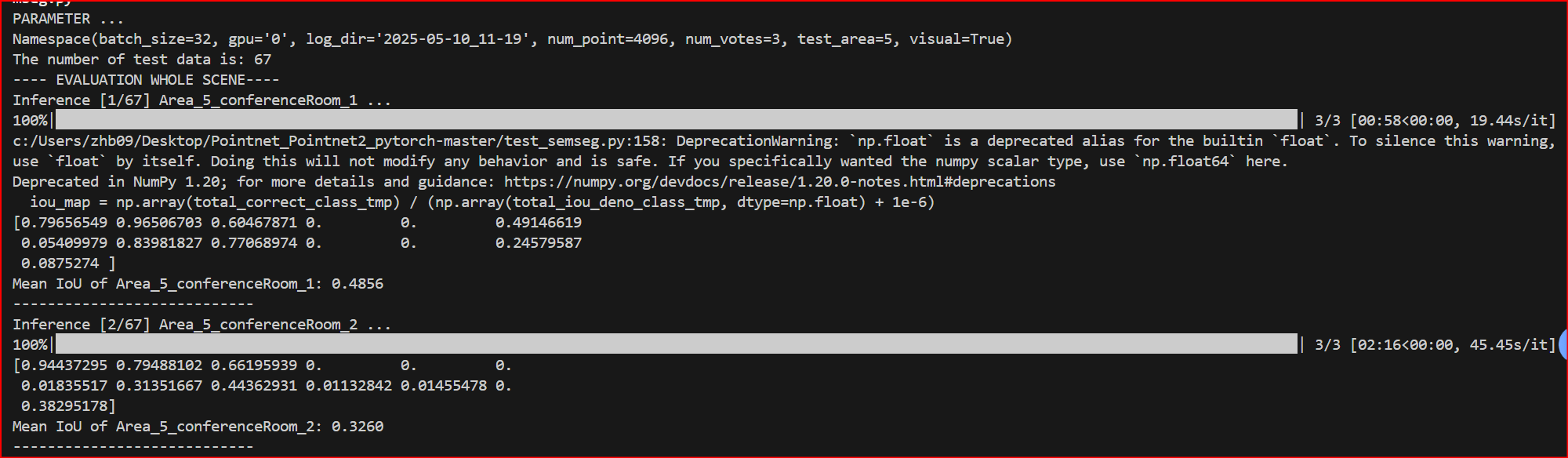
报错1:Model: error: the following arguments are required: --log_dir
解决方法:修改第37行代码
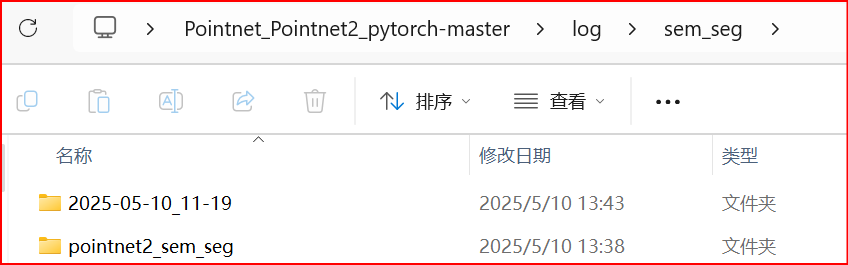
# 修改前parser.add_argument(\'--log_dir\', type=str, required=True, help=\'experiment root\')# 此处修改方法有两种,两种方法取其一即可\"\"\"方法1:训练的权重文件存储在Pointnet_Pointnet2_pytorch-master\\log\\sem_seg路径下以训练时间命名的文件夹中,如下图所示,若将此处\'--log_dir\'路径修改为\'pointnet2_sem_seg\',则需将以训练时间命名的文件夹重命名为pointnet2_sem_seg。方法2:直接将此处\'--log_dir\'路径修改为\'2025-05-10_11-19\'。保存权重文件的路径与测试时读取权重文件的路径保持一致!\"\"\"parser.add_argument(\'--log_dir\', type=str,default=\'pointnet2_sem_seg\', help=\'experiment root\')parser.add_argument(\'--log_dir\', type=str,default=\'2025-05-10_11-19\', help=\'experiment root\')两种方法取其一即可!
报错2:FileNotFoundError: [WinError 3] 系统找不到指定的路径。\'data/s3dis/stanford_indoor3d/\'
解决方法:修改读取数据集的路径
# 修改前第82行root = \'data/s3dis/stanford_indoor3d/\'# 修改后root = \'data/stanford_indoor3d/\'成功运行!
四、分类任务
分类任务用到的数据集为:modelnet40_normal_resampled
该数据集包含了40个类别,点云数据格式为txt。每一个点云数据表示一个具体的类别对象,每个点包含6个维度的信息,分别是[x,y,z,nx,ny,nz],其中,(x,y,z)表示该点在空间中的坐标,(nx,ny,nz)表示该点在空间中的法向量。
\"filelist.txt\":记录着40个类别所有点云数据的路径,共12311个点云数据;
\"modelnet40_shape_names.txt\":记录着40个类别的名称;
\"modelnet40_test.txt\":记录着验证集的点云数据,共2468个点云数据;
\"modelnet40_train.txt\":记录着训练集的点云数据,共9843个点云数据
数据集下载地址:https://www.kaggle.com/datasets/chenxaoyu/modelnet-normal-resampled
网盘下载地址:modelnet40_normal_resampled.zip
将数据集下载后解压,在源码Pointnet_Pointnet2_pytorch-master路径下新建文件夹data,将解压的数据集移动到data路径下。(后续任务同样操作)。
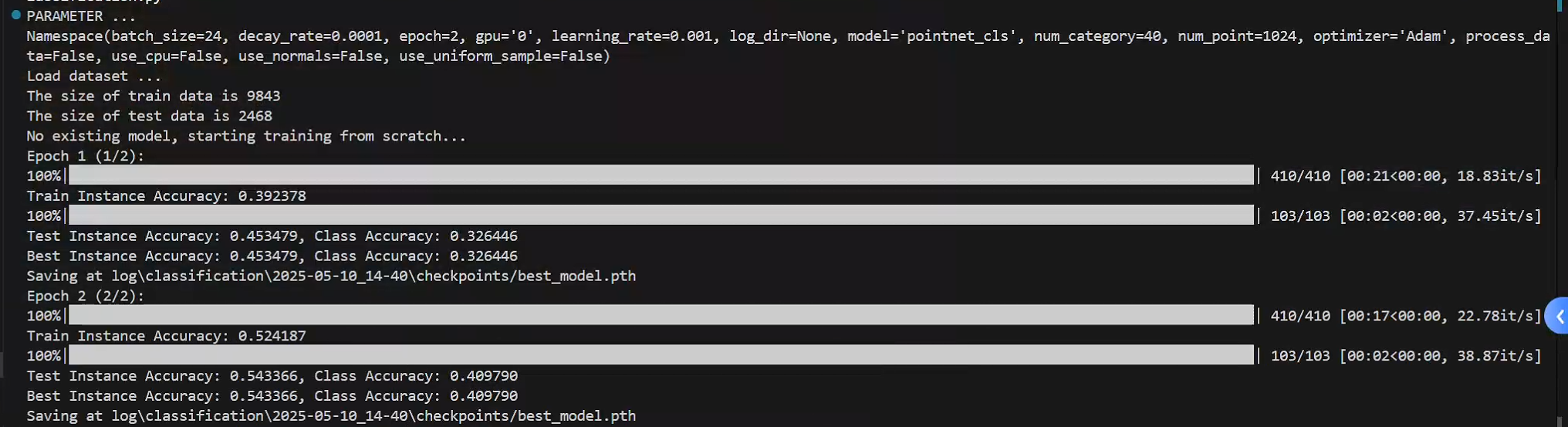
1.train_classification.py
运行时无报错!
2.test_classification.py
报错与语义分割任务中test_semseg.py的报错1相同,修改后成功运行!

五、部件分割任务
部件分割任务中用到的数据集为:shapenetcore_partanno_segmentation_benchmark_v0_normal
该数据集包含 16 个对象类别,每个 3D 模型的点云数据存储为 .txt 文件,每行表示一个点,包含 有7 列数据,分别为:
前 3 列:点的 3D 坐标(x, y, z);
中间 3 列:点的法线向量(nx, ny, nz);
最后 1 列:点的分割标签(segmentation label),表示该点所属的部件。
数据集分为训练集、验证集和测试集,划分信息存储在 train_test_split 文件夹中的 json 文件中。
synsetoffset2category.txt 文件中将类别名称与对应的文件夹名称进行映射。
数据集下载地址:https://www.kaggle.com/datasets/mitkir/shapenet
网盘下载地址:https://www.kaggle.com/datasets/mitkir/shapenet
1.train_partseg.py
同样无报错成功运行!
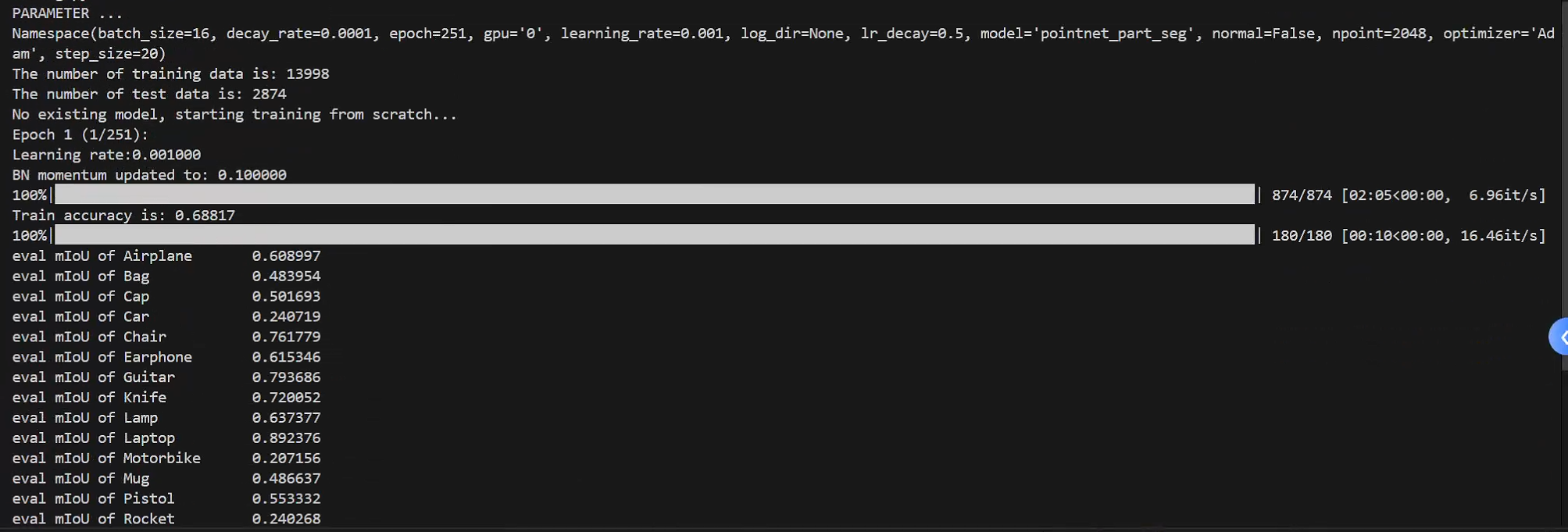
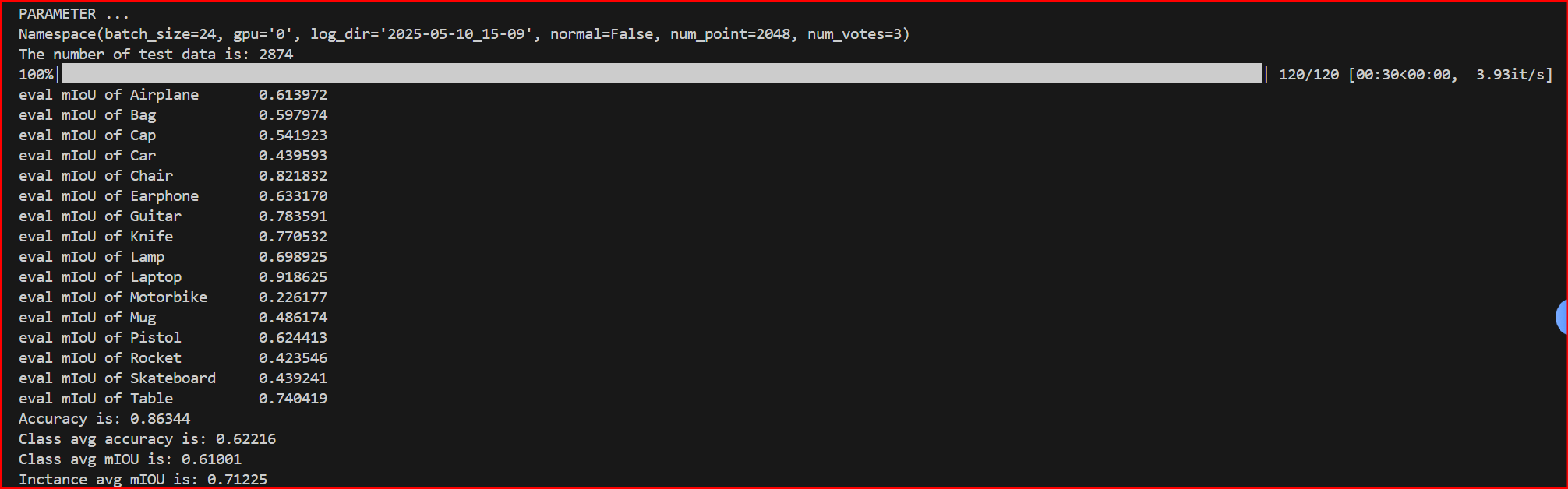
2.test_partseg.py
报错依旧与语义分割任务中test_semseg.py的报错1相同,修改后成功运行!
六、可能会出现的其他报错及解决方法
报错1:MP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. ……
解决方法:在使用的环境目录中搜索:libiomp5md.dll,会出现两个libiomp5md.dll文件,将第二个libiomp5md.dll文件剪切出去即可。
如图:使用的是pointnet环境,在pointnet路径下进行搜索,然后在/pointnet/Library/bin中将libiomp5md.dll移出去。

报错2:运行train_partseg.py时可能会出现
RuntimeError: Error(s) in loading state_dict for get_model:
size mismatch for sa1.mlp_convs.0.weight: copying a param with shape torch.Size([64, 3, 1, 1]) from checkpoint, the shape in current model is torch.Size([64, 6, 1, 1]).
原因:在训练时没有读取点云数据的法向量,即\'--normal\'设置为False,维度为3,用训练的权重文件测试时,测试程序中\'--normal\'设置成了True,即读取了点云数据的法向量,维度为6,两者不匹配。
解决方法:将训练程序和测试程序中的\'--normal\'设置一致即可(同False或同True)。

