OpenWebUI 上使用Vllm部署的模型_openwebui vllm
1. 安装 vLLM 和依赖
首先,确保你已经安装了 vLLM 和相关依赖。你可以通过以下命令安装:
bash复制
pip install vllm2. 下载并准备模型
假设你已经下载了模型文件(如 DeepSeek-R1-Distill-Qwen-7B),并将其放在 /root/model/ 目录下。
3. 启动 vLLM 服务
在终端中运行以下命令来启动 vLLM 服务。这里我们假设模型路径为 /root/model/DeepSeek-R1-Distill-Qwen-7B,并指定服务端口为 6001:
bash复制
python -m vllm.entrypoints.openai.api_server \\--model /root/model/DeepSeek-R1-Distill-Qwen-7B \\--served-model-name DeepSeek-R1-Distill-Qwen-7B \\--port 6001 \\--api-key token-abc123-
--model:指定模型路径。 -
--served-model-name:指定模型的名称,用于在 API 中引用。 -
--port:指定服务运行的端口。 -
--api-key:设置 API 密钥,用于验证请求。
4. 使用 OpenWebUI
OpenWebUI 是一个基于 Web 的界面,用于与模型进行交互。你可以通过以下步骤将其与 vLLM 服务连接:
安装 OpenWebUI
如果你还没有安装 OpenWebUI,可以通过以下命令安装:
bash复制
pip install open-webui启动 OpenWebUI
运行以下命令启动 OpenWebUI:
bash复制
python -m open_webui默认情况下,OpenWebUI 会启动在 http://localhost:7860。
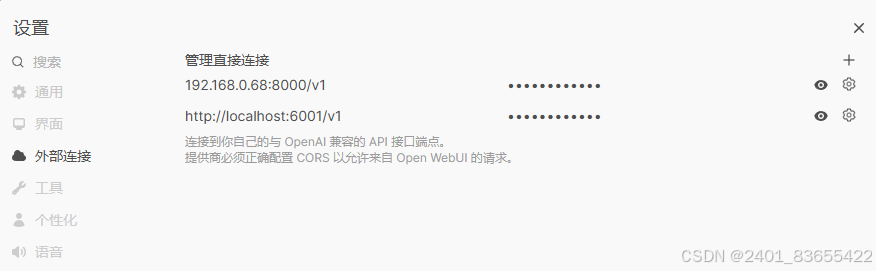
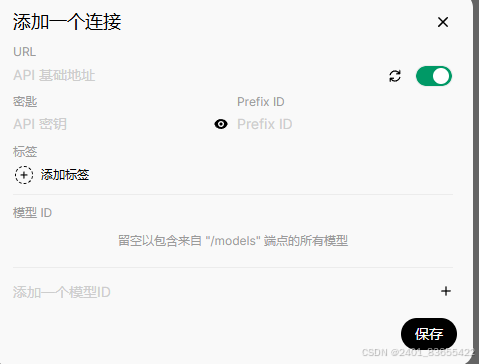
配置 OpenWebUI
在 OpenWebUI 的界面中,找到 API 配置 部分,输入以下信息:
-
API URL:
http://localhost:6001/v1 -
API Key:
token-abc123
保存配置后,你就可以通过 OpenWebUI 与 vLLM 服务进行交互了。
5. 验证模型是否成功加载
通过以下命令验证模型是否成功加载:
bash复制
curl http://localhost:6001/v1/models -H \"Authorization: Bearer token-abc123\"如果返回类似以下内容,说明模型已成功加载:
JSON复制
{\"object\":\"list\",\"data\":[{\"id\":\"/root/model/DeepSeek-R1-Distill-Qwen-7B\",\"object\":\"model\",\"created\":1744010129,\"owned_by\":\"vllm\",\"root\":\"/root/model/DeepSeek-R1-Distill-Qwen-7B\",\"parent\":null,\"max_model_len\":131072,\"permission\":[{\"id\":\"modelperm-40bf7adc43ff458098e594f24905be7e\",\"object\":\"model_permission\",\"created\":1744010129,\"allow_create_engine\":false,\"allow_sampling\":true,\"allow_logprobs\":true,\"allow_search_indices\":false,\"allow_view\":true,\"allow_fine_tuning\":false,\"organization\":\"*\",\"group\":null,\"is_blocking\":false}]}]}6. 使用代码与模型交互
以下是一个 Python 示例代码,展示如何通过代码与 vLLM 服务进行交互:
Python复制
from openai import OpenAI# 初始化 OpenAI 客户端client = OpenAI( base_url=\"http://localhost:6001/v1\", api_key=\"token-abc123\",)# 创建聊天完成请求completion = client.chat.completions.create( model=\"/root/model/DeepSeek-R1-Distill-Qwen-7B\", messages=[ {\"role\": \"user\", \"content\": \"Hello!\"} ])# 打印返回的消息print(completion.choices[0].message.content)7. 测试和验证
运行上述代码后,如果一切正常,你应该会看到模型的回复,例如:
Hello! How can I assist you today?
总结
通过上述步骤,你已经成功:
-
使用 vLLM 部署并启动了模型。
-
通过 OpenWebUI 配置了与 vLLM 服务的连接。
-
验证了模型是否成功加载。
-
使用 Python 代码与模型进行了交互。

