【机器学习】随机森林+决策树 原理透析 + 示例代码_决策树、随机森林
本文内容参考了多篇相关文章,旨在进行学习与总结。如涉及版权问题,请作者及时联系删除,本人将不胜感激并深表歉意。
目录
背景
学习资料:
原理
随机性
1. 数据样本的随机性(Bootstrap Sampling)
2. 特征选择的随机性(Random Feature Selection)
结果
熵
信息增益
构建流程
代码示例
背景
随机森林(Random Forest)是一种基于集成学习(Ensemble Learning)思想的机器学习算法,由 Leo Breiman 和 Adele Cutler 在 2001 年提出。它通过构建多个决策树(Decision Trees)并将它们的预测结果进行集成,从而提升模型的准确性和鲁棒性。
随机森林的核心思想是“博采众长”——通过训练多个弱学习器(即决策树),并结合它们的预测结果形成一个更强的预测模型。在训练过程中,每棵决策树都使用从原始数据集中有放回抽样得到的子样本进行训练,同时在每个分裂节点上随机选择一部分特征进行最优划分,这种“随机性”使得整个模型具有良好的泛化能力。
在预测阶段,随机森林根据任务类型采用不同的集成策略:对于分类任务,采用多数投票法选择预测类别;对于回归任务,则取所有决策树预测值的平均值作为最终输出。因此,随机森林既可以用于分类问题,也能很好地处理回归问题,例如预测连续数值(如房价、温度、经纬度等)。
学习资料:
10分钟让你明白决策树_哔哩哔哩_bilibili更多视频在油管 ID同名, 视频播放量 61372、弹幕量 158、点赞数 1913、投硬币枚数 967、收藏人数 1902、转发人数 507, 视频作者 Shady的混乱空间, 作者简介 主玩油管 吹逼裙 967553282,相关视频:决策树例题讲解,【五分钟机器学习】可视化的决策过程:决策树 Decision Tree,[5分钟学算法] #03 决策树 小明毕业当行长,决策树系列【6】剪枝,【预测模型自学教程3】深入浅出!一个视频20分钟带你吃透决策树,十分钟快速掌握决策树与随机森林原理,决策树的基本原理,机器学习算法--决策树的超生动简单演示,12-1 信息熵与决策树(信息熵),【强推!】不愧是B站最详细的决策树零基础入门教程!博士大佬手把手带你一小时学完决策树!最通俗的讲解,简单易懂!隔壁大爷也看懂了!|人工智能|机器学习|深度学习![]() https://www.bilibili.com/video/BV1Ne411y7wW?t=551.212 随机森林回归算法 基本原理|代码演示|案例解析 | 快速入门_哔哩哔哩_bilibili12 随机森林回归算法 基本原理|代码演示|案例解析 | 快速入门, 视频播放量 5036、弹幕量 1、点赞数 58、投硬币枚数 50、收藏人数 114、转发人数 24, 视频作者 蚂蚁期末, 作者简介 对【蚂蚁期末】任意视频一键三连保留截图,免费领取期末讲义+视频哦~,相关视频:什么是随机森林?【知多少】,SPSS随机森林知识点+案例实操,2025新版【机器学习十大算法全集】17分钟让你看懂所有机器学习算法!一口学透回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机、神经网络等,集成算法:决策树和随机森林的原理介绍,十分钟掌握matlab实现随机森林代码(新手超友好!),69(附代码)RF随机森林机器学习重新精讲,一键出图,带你零基础学生信~,随机森林评估变量重要性并作图,6、基于随机森林的时间序列预测模型-预测未来新数据代码详细教程,57. 随机森林(Random Forest,RF)筛选核心基因,特征基因,30-4-随机森林原理和应用
https://www.bilibili.com/video/BV1Ne411y7wW?t=551.212 随机森林回归算法 基本原理|代码演示|案例解析 | 快速入门_哔哩哔哩_bilibili12 随机森林回归算法 基本原理|代码演示|案例解析 | 快速入门, 视频播放量 5036、弹幕量 1、点赞数 58、投硬币枚数 50、收藏人数 114、转发人数 24, 视频作者 蚂蚁期末, 作者简介 对【蚂蚁期末】任意视频一键三连保留截图,免费领取期末讲义+视频哦~,相关视频:什么是随机森林?【知多少】,SPSS随机森林知识点+案例实操,2025新版【机器学习十大算法全集】17分钟让你看懂所有机器学习算法!一口学透回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机、神经网络等,集成算法:决策树和随机森林的原理介绍,十分钟掌握matlab实现随机森林代码(新手超友好!),69(附代码)RF随机森林机器学习重新精讲,一键出图,带你零基础学生信~,随机森林评估变量重要性并作图,6、基于随机森林的时间序列预测模型-预测未来新数据代码详细教程,57. 随机森林(Random Forest,RF)筛选核心基因,特征基因,30-4-随机森林原理和应用![]() https://www.bilibili.com/video/BV1rMCRYMEWC?t=311.53分钟搞定随机森林_哔哩哔哩_bilibili更多视频在油管 id同名, 视频播放量 12916、弹幕量 7、点赞数 588、投硬币枚数 323、收藏人数 239、转发人数 42, 视频作者 Shady的混乱空间, 作者简介 主玩油管 吹逼裙 967553282,相关视频:十分钟快速掌握决策树与随机森林原理,20230630_3分钟让你看懂逻辑回归_连小学生都能看懂的算法科普_Shady的混乱空间,决策树案例详解,决策树系列【6】剪枝,这也太全了!回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机等十大机器学习算法一口气学完!,集成算法:决策树和随机森林的原理介绍,决策树,【强推!】不愧是B站最详细的决策树零基础入门教程!博士大佬手把手带你一小时学完决策树!最通俗的讲解,简单易懂!隔壁大爷也看懂了!|人工智能|机器学习|深度学习,AI用决策树学习人类经验玩游戏,【机器学习】动画讲解随机森林
https://www.bilibili.com/video/BV1rMCRYMEWC?t=311.53分钟搞定随机森林_哔哩哔哩_bilibili更多视频在油管 id同名, 视频播放量 12916、弹幕量 7、点赞数 588、投硬币枚数 323、收藏人数 239、转发人数 42, 视频作者 Shady的混乱空间, 作者简介 主玩油管 吹逼裙 967553282,相关视频:十分钟快速掌握决策树与随机森林原理,20230630_3分钟让你看懂逻辑回归_连小学生都能看懂的算法科普_Shady的混乱空间,决策树案例详解,决策树系列【6】剪枝,这也太全了!回归算法、聚类算法、决策树、随机森林、神经网络、贝叶斯算法、支持向量机等十大机器学习算法一口气学完!,集成算法:决策树和随机森林的原理介绍,决策树,【强推!】不愧是B站最详细的决策树零基础入门教程!博士大佬手把手带你一小时学完决策树!最通俗的讲解,简单易懂!隔壁大爷也看懂了!|人工智能|机器学习|深度学习,AI用决策树学习人类经验玩游戏,【机器学习】动画讲解随机森林![]() https://www.bilibili.com/video/BV1Tu4y1H7Vy?t=127.8
https://www.bilibili.com/video/BV1Tu4y1H7Vy?t=127.8
原理
随机性
随机森林的随机是指两点:
1. 数据样本的随机性(Bootstrap Sampling)
在构建每棵决策树时,随机森林使用**自助采样法(Bootstrap Sampling)从原始数据集中有放回地抽取样本,形成不同的训练集,这个操作也叫做 bagging 。这意味着每棵树的训练数据都是原始数据集的一个随机子集。
- 作用:通过这种方式,不同的树可以基于略有差异的数据集进行训练,增加了树之间的多样性,从而提高了整个森林的预测性能。
- 效果:即使某些训练样本中包含噪声或异常值,由于不是所有树都使用了这些样本,因此它们对整体预测的影响会被削弱。
- 具体做法:加入有一个2000行10列的数据(10个特征),如果初始化选取特征数是3,样本数是30,决策树数量是100,则会有放回抽取30行3列的数据抽取100次,每次抽取的数据用于构建一棵决策树。
2. 特征选择的随机性(Random Feature Selection)
在每个节点上分裂时,随机森林不会考虑所有的特征,而是从所有可能的特征中随机选择一个特征子集,并从中挑选最佳分裂点。
- 具体做法:例如,在二分类问题中,如果总共有 p 个特征,则在每个节点上,随机森林可能会随机选择
个特征来寻找最佳分裂;对于回归任务,通常会选择 p/3 个特征。
- 作用:这种方法进一步增加了树之间的多样性,使得单个特征对最终结果的影响减小,增强了模型的稳定性。
结果
随机森林是由多个决策树组成的集成学习模型。在预测过程中,随机森林通过综合每棵决策树的预测结果来进行最终判断:
设每个决策树的预测结果如下:
-
在分类任务中,每棵决策树会输出一个类别预测,随机森林通过统计所有树中预测类别出现的频率,选择票数最多的类别作为最终预测结果(即“多数投票法”)。
-
-
在回归任务中,每棵决策树都会输出一个具体的数值预测,随机森林将这些数值的平均值作为最终的预测结果(即“平均法”),从而得到一个连续的输出。
-
这种方式不仅提高了模型的泛化能力,还有效降低了单一决策树可能存在的过拟合风险。
决策树
前面讲了如何抽取数据和如何生成最后的结果,那中间怎么构建决策树呢?
构建决策树会遵循一个指标,常见的有信息增益比(C4.5)、信息增益(ID3)、基尼系数(CART),我们主要基于 ID3 进行讲解。
要理解 ID3 ,首先要理解什么是熵。
熵
熵是表示随机变量的不确定性,比如一场羽毛球赛,刚开始比分 0:0,谁都无法确定哪位运动员能拿下这场比赛,但是打到后面,比分差越来越大,无论是选手 1 优势还是选手 2 优势,都能大致确定某位运动员能赢得本场比赛,最后比赛结束,确定赢家。在这个过程中,最开始无法判断选手输赢情况,不确定性最大,熵的值是最大的;到后面比分越拉越大,不确定性越来越小,熵值也越来越小,到最后完全确定后,熵值为 0.
公式如下:
如果特征有两个,即未知数有两个,则联合概率分布如下:
此时时间 X 发生的前提下,时间 Y 发生的的熵叫做条件熵,此时条件熵的公式如下:
信息增益
信息增益是条件熵的减少程度
把特征 A 对训练集 D 的信息增益记作 ,则其计算公式如下:
即信息增益 = 总的熵值 - 条件熵
具体如何计算呢,比如如下数据集:
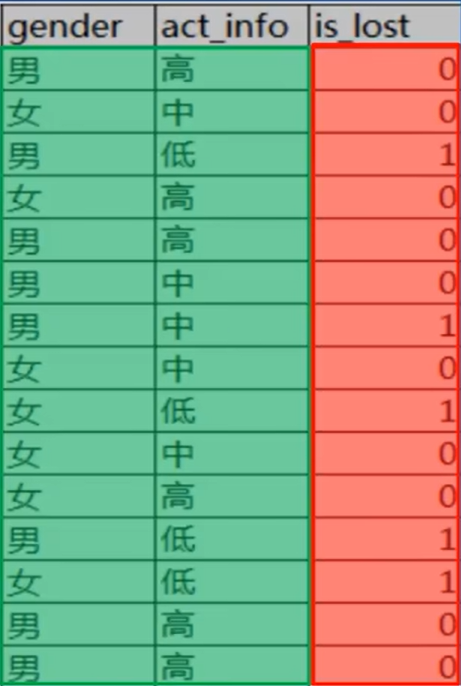
要计算性别和活跃度这两个特征的信息增益,根据上面的公式计算即可:
总的熵
15 条数据中,类别为 1 的有 5 条,类别为 0 的有 10 条
性别为男的熵
男性中类别为 1 的有 3 个,类别为 0 的有 5 个
性别为女的熵
女性中类别为 1 的有 2 个,类别为 0 的有 5 个
活跃度为低的熵
低活跃度中类别为 0 的有 4 个,类别为 1 的有 0 个
活跃度为中的熵
中活跃度中类别为 0 的有 1 个,类别为 1 的有 4 个
活跃度为高的熵
高活跃度中类别为 0 的有 0 个,类别为 1 的有 4 个
性别的信息增益 = 总的熵 - (8/15)*性别为男的熵 - (7/15)*性别为女的熵 = 0.0426
活跃度的信息增益 = 总的熵 - (6/15)*活跃度为高的熵 - (5/15)*活跃度为中的熵 - (4/15)*活跃度为低的熵 = 0.6776
构建流程
根据每个特征的信息增益进行选择节点,这就是 ID3 算法的思想。有了上述知识,就能构建出一颗完整的决策树。
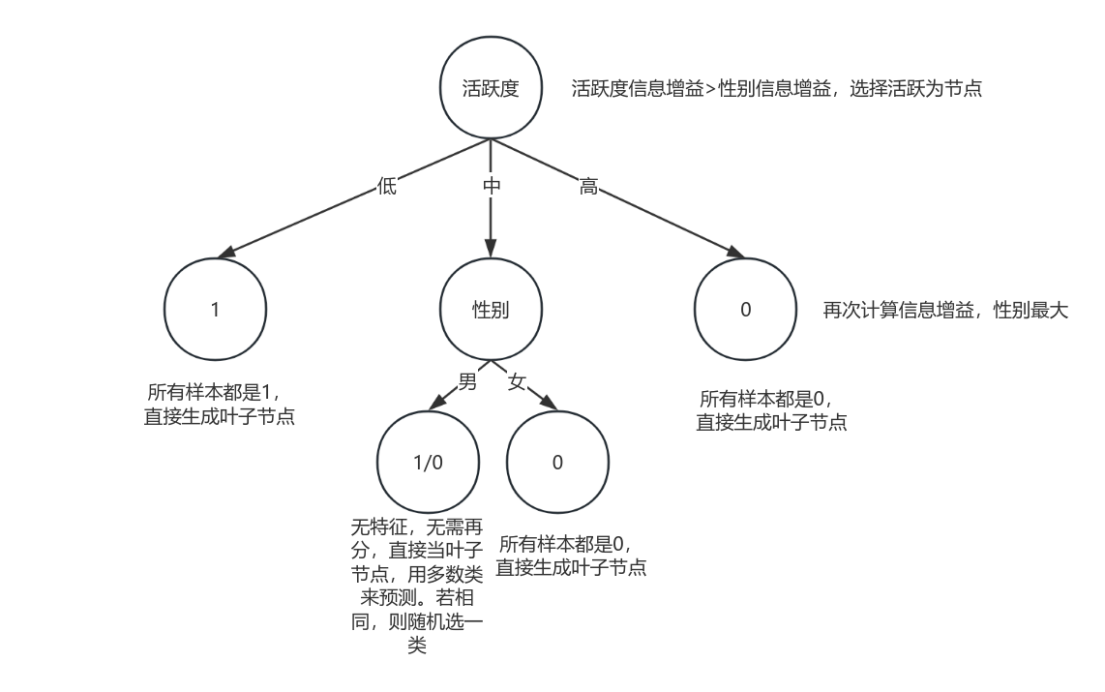
按照上面计算示例,我们来构建一颗决策树:
先从训练集中计算每个特征的信息,按照上面方式计算每个特征的信息增益,看哪个最大,选取信息增益最大的作为当前节点,按照该特征不同进行分类;然后以每个子节点继续重复上面的操作;直到能全部归为一类或者无特征后,归为叶子节点,从而构建出决策树。实际上每次选择节点是选择区分或预测目标变量的最有效的特征。
流程图如下:
注意如果无特征选择并且两类或者多类剩下的样本数一致,则随机选择一类作为叶子节点
代码示例
我这里使用如图数据:

共有 23 个特征,预测是否在业,1 为在业,0 为失业,总共 4980 行数据。数据可在文末下载
分类预测代码:
import numpy as npimport pandas as pdimport matplotlibmatplotlib.use(\'TkAgg\')import matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import OneHotEncoderfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, classification_report# 支持中文plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 用来正常显示中文标签plt.rcParams[\'axes.unicode_minus\'] = False # 用来正常显示负号# 加载数据集df = pd.read_excel(r\"C:\\Users\\ch011\\Desktop\\cleaned_data.xlsx\")# 编码 \'专业\' 列gender_encoder = OneHotEncoder()gender_encoded = gender_encoder.fit_transform(df[[\'专业\']]).toarray()encoded_features = gender_encoder.get_feature_names_out([\'专业\'])# 合并编码后的列data_encoded = pd.DataFrame(gender_encoded, columns=encoded_features, index=df.index)data = pd.concat([df.drop(\'专业\', axis=1), data_encoded], axis=1)# 准备特征和目标X = data.drop(columns=[\'是否在业\']) # 使用编码后的 datay = data[\'是否在业\']# 划分数据集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用分类器rf = RandomForestClassifier(n_estimators=100, random_state=42)rf.fit(X_train, y_train)# 预测与评估y_pred = rf.predict(X_test)y_proba = rf.predict_proba(X_test)[:, 1]print(f\"Accuracy: {accuracy_score(y_test, y_pred):.4f}\")print(classification_report(y_test, y_pred))# 可视化 1:预测值 vs 真实值散点图plt.figure(figsize=(8, 6))sns.scatterplot(x=y_test, y=y_pred, alpha=0.6)plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color=\'red\', linestyle=\'--\')plt.xlabel(\"真实值\")plt.ylabel(\"预测值\")plt.title(\"真实值 vs 预测值\")plt.grid(True)plt.tight_layout()plt.show()# 可视化 2:特征重要性(排序 + 显示特征名称)feature_importances = rf.feature_importances_features = X.columnsindices = np.argsort(feature_importances)plt.figure(figsize=(10, 6))plt.title(\"特征重要性\")plt.barh(range(len(indices)), feature_importances[indices], align=\'center\', color=\'teal\')plt.yticks(range(len(indices)), [features[i] for i in indices])plt.xlabel(\"相对重要性\")plt.tight_layout()plt.show()# 可视化 3:预测值分布(用于判断是否适合分类任务)plt.figure(figsize=(8, 6))sns.histplot(y_pred, bins=30, kde=True, color=\'skyblue\')plt.title(\"预测值分布\")plt.xlabel(\"预测概率\")plt.ylabel(\"频数\")plt.axvline(0.5, color=\'red\', linestyle=\'--\', label=\"阈值 0.5\")plt.legend()plt.tight_layout()plt.show()最后结果:
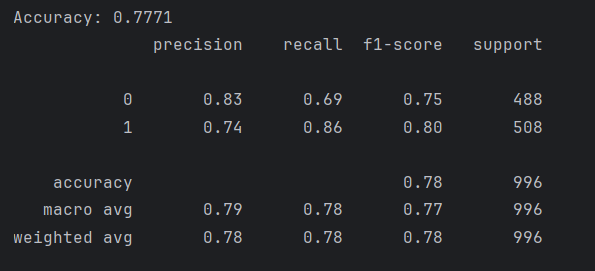

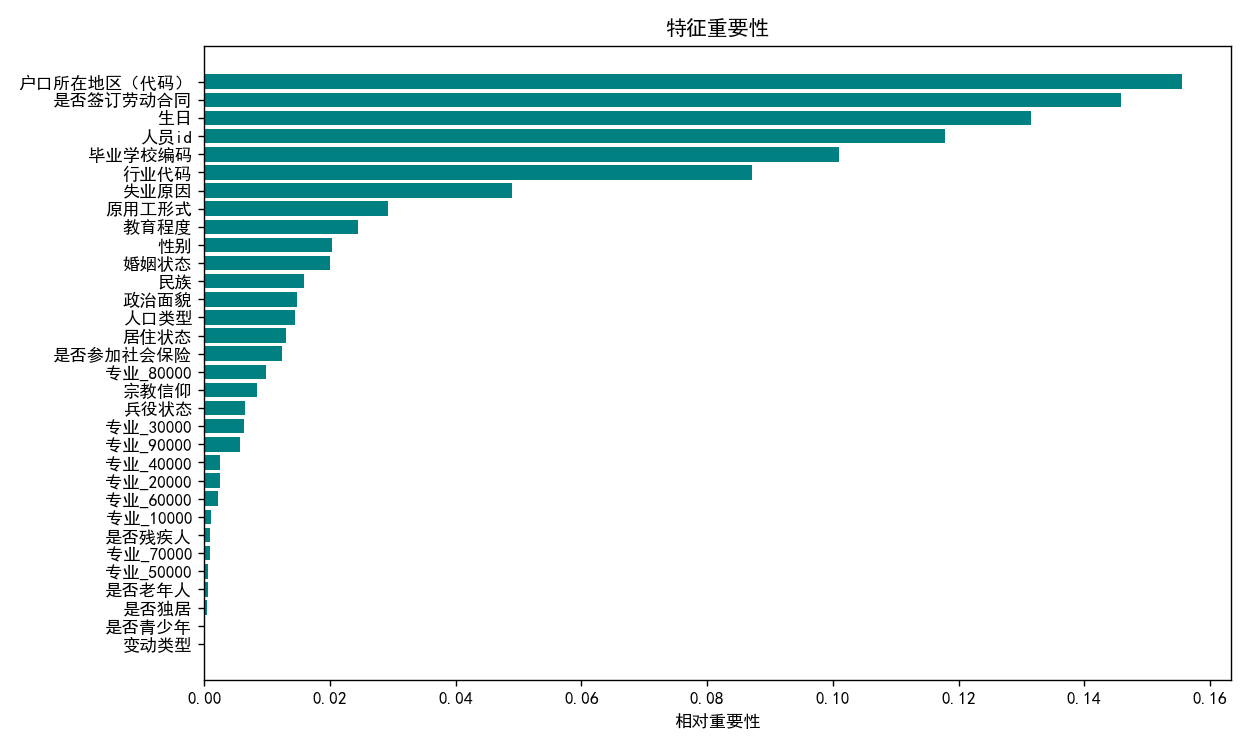
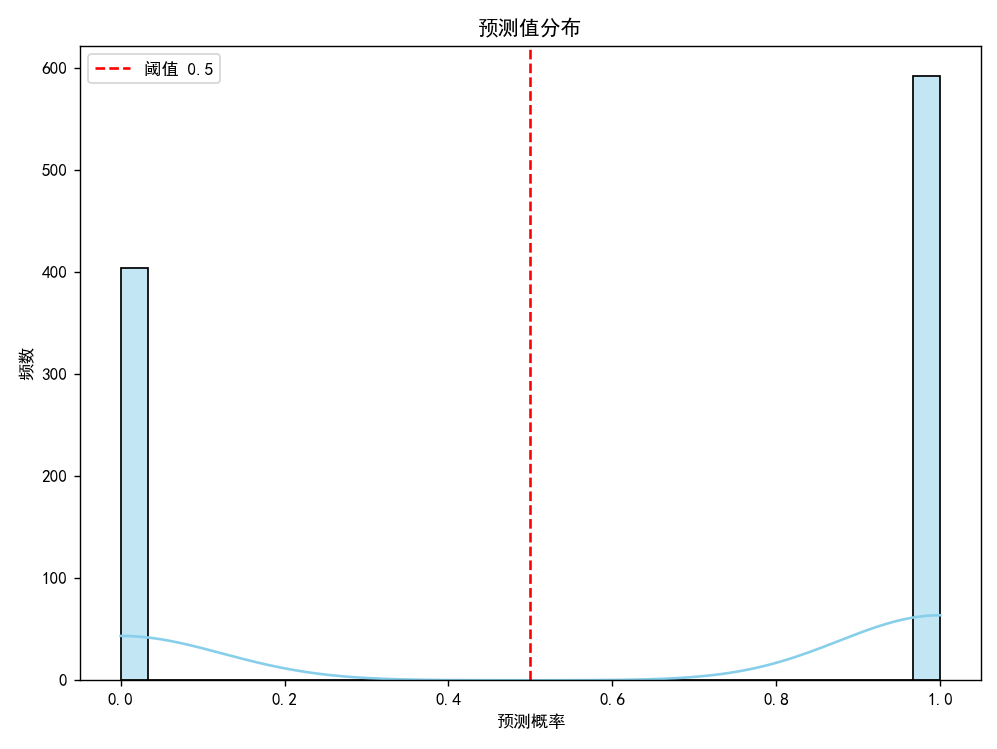
可以看到,准确率为 77,7%,影响最大的特征是户口所在地,预测值分布也没问题。
如今,人工智能技术日益强大,很多任务的基础代码都可以由 AI 自动生成,开发者不再需要从零开始编写每一行代码,更多地是进行参数调整、模型优化以及结果评估等操作。就像上面这段代码,完全由 AI 生成,已经能够满足实际应用的需求。
但这并不意味着我们可以忽视背后的原理。相反,理解算法的本质和模型的工作机制变得更加重要。只有真正掌握其原理,才能在面对问题时更有底气地做出判断与决策,才能更好地调参、优化,并提升模型性能。
AI 是工具,懂原理的人才是核心。
示例代码和数据附下:
随机森林预测代码和数据资源-CSDN下载![]() https://download.csdn.net/download/2403_83182682/91461440
https://download.csdn.net/download/2403_83182682/91461440
本文内容参考了多篇相关文章,旨在进行学习与总结。如涉及版权问题,请作者及时联系删除,本人将不胜感激并深表歉意。
感谢您的观看!!!

