Emotion-LLaMA: 用于多模态情感识别与推理的创新模型(python代码已实现)_emotion llama
1.1 研究背景
摘要:本文详细介绍 Emotion-LLaMA 项目,准确的情绪感知对于各种应用至关重要,包括人机交互、教育和咨询。然而,传统的单模态方法往往无法捕捉到现实世界情感表达的复杂性,而这些情感表达本质上是多模态的。此外,现有的多模态大型语言模型 (MLLM) 在集成音频和识别细微的面部微表情方面面临挑战。为了解决这些问题,我们引入了 MERR 数据集,其中包含 28618 个粗粒度和 4487 个细粒度注释样本,涵盖不同的情感类别。此数据集使模型能够从各种场景中学习并推广到实际应用程序。此外,我们还提出了 Emotion-LLaMA,这是一种通过特定于情感的编码器无缝集成音频、视觉和文本输入的模型。通过将特征对齐到共享空间中并采用改进的 LLaMA 模型和指令调整,Emotion-LLaMA 显着增强了情感识别和推理能力。广泛的评估表明,Emotion-LLaMA 的表现优于其他 MLLM,在 EMER 的线索重叠 (7.83) 和标签重叠 (6.25) 中取得了最高分,在 MER2023 挑战中取得了 0.9036 的 F1 分数,在 DFEW 数据集的零镜头评估中获得了最高的 UAR (45.59) 和 WAR (59.37)。
有关 Emotion-LLaMA 的更多详细信息,请参阅此论文。https://arxiv.org/pdf/2406.11161
1.2 研究目标
为了解决上述问题,本项目提出了 Emotion-LLaMA 模型,并构建了 MERR 数据集。目标是开发一个能够有效集成音频、视觉和文本信息的多模态模型,提高情感识别和推理的准确性和鲁棒性。具体来说,我们希望 Emotion-LLaMA 能够在各种情感场景中准确识别情感类别,并对情感产生的原因进行合理推理。
1.3 研究贡献
- MERR 数据集
:我们构建了 MERR 数据集,包含 28,618 个粗粒度和 4,487 个细粒度标注样本,涵盖了多样化的情感类别。该数据集为多模态情感识别和推理研究提供了丰富的资源。
- Emotion-LLaMA 模型
:提出了 Emotion-LLaMA 模型,通过情感特定编码器将音频、视觉和文本输入集成到一个共享空间,并采用改进的 LLaMA 模型进行指令调优,显著提升了模型的情感识别和推理能力。
- 实验评估
:通过广泛的实验评估,证明了 Emotion-LLaMA 在多个情感识别和推理任务上优于其他 MLLMs,取得了优异的成绩。
二、相关工作
2.1 单模态情感识别方法
传统的单模态情感识别方法主要基于文本、图像或音频进行情感分析。在文本情感分析方面,常用的方法包括基于机器学习的分类器(如支持向量机、朴素贝叶斯等)和深度学习模型(如循环神经网络、卷积神经网络等)。这些方法通过分析文本中的词汇、语法和语义信息来判断情感倾向。
在图像情感识别方面,研究主要集中在面部表情识别上。常用的方法包括基于特征提取(如 HOG、SIFT 等)和机器学习分类器的方法,以及基于深度学习的卷积神经网络(如 VGG、ResNet 等)。这些方法通过分析面部表情的特征来识别情感类别。
在音频情感识别方面,主要通过分析音频的声学特征(如音高、音量、语速等)来判断情感状态。常用的方法包括基于机器学习的分类器和深度学习模型(如循环神经网络、卷积神经网络等)。
2.2 多模态大语言模型
近年来,多模态大语言模型取得了显著进展,如 MiniGPT-v2、AffectGPT 和 LLaVA 等。这些模型通过将图像、文本等多模态信息融合在一起,实现了更强大的语言理解和生成能力。然而,这些模型在处理音频信息和识别微妙的面部微表情方面仍存在不足。
2.3 情感数据集
目前已经存在一些情感数据集,如 MER2023 等。这些数据集为情感识别研究提供了重要的资源,但它们在情感类别覆盖范围、标注粒度等方面存在一定的局限性。我们的 MERR 数据集旨在弥补这些不足,提供更丰富、更细粒度的标注样本。
📊 MERR 数据集
📈 情感数据集的比较
MERR 数据集扩展了情感类别和注释的范围,超出了现有数据集中的范围。每个样本都用情感标签进行注释,并根据其情感表达进行描述。下载 MERR 数据集的标注内容。
https://drive.google.com/drive/folders/1LSYMq2G-TaLof5xppyXcIuWiSN0ODwqG?usp=sharing

📝 MERR 数据集示例
该数据集最初使用粗粒度标签对来自大量未注释数据的 28618 个样本进行自动注释,后来经过优化以包括 4487 个具有精细注释的样本。有关数据标注过程的更多详细信息,请参阅 MERR 数据集构建(如下)。
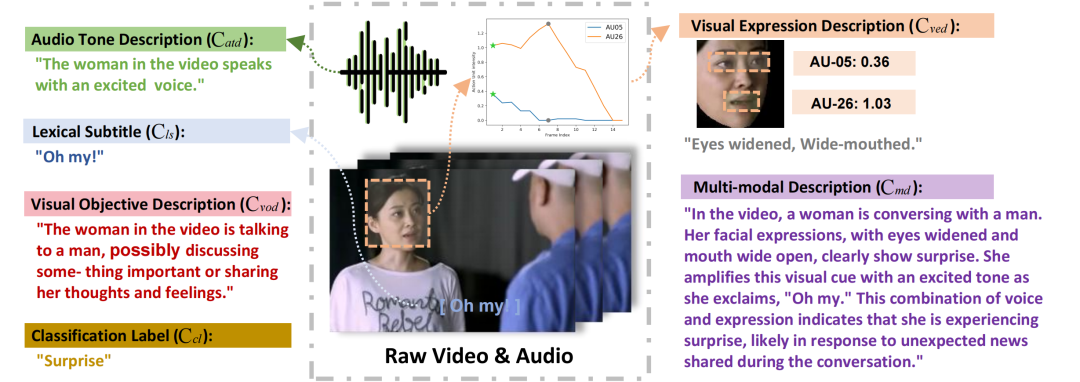
我们在 MER-Dataset-Builder 上发布了 MERR 数据集构建策略。
数据源
MER2023-SEMI 包含超过 70,000 个未标记的视频剪辑。我们利用几个强大的多模态模型从不同的模态中提取情绪线索,然后使用最新的 LLaMA-3 模型总结所有情绪线索进行推理,从而得出最终的多模态描述。
MERR 数据集构建
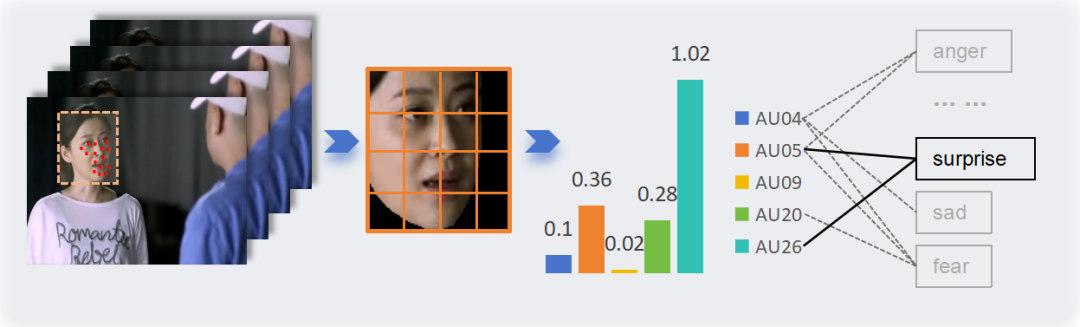
1. 数据过滤
我们使用 OpenFace 从视频片段中提取人脸,然后对齐以识别各种面部肌肉运动,从而检测动作单元。这些肌肉运动的某些组合与特定情绪相关。例如,惊讶的情绪是通过 Action Unit 05(上眼睑提升器)和 26(下巴下垂)的组合来识别的。行动单元的每个特定组合都被分配了一个伪标签,表示样本被选中并表现出强烈的情绪表达特征。总共选择了 28,618 个样本并分配了伪标签。
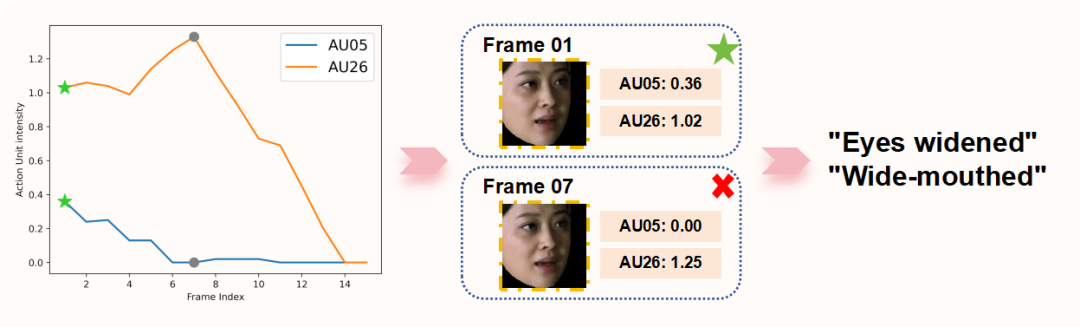
2. 视觉表情描述
由于视频中的自然动作(例如眨眼和说话),因此从不同的帧中提取了动作单元 (AU) 的不同组合。因此,确定最准确地代表当前情绪的 AU 至关重要。我们的方法包括分析动作单元的振幅值,以确定情绪表达的峰值,称为 “情绪峰值框架”。具体步骤包括:(1) 确定所有帧中出现频率最高的 Action Unit;(2) 对它们的值求和,最高的总数表示情绪峰值框架。然后,此帧的 Action Units 将映射到其相应的视觉表达式描述。
3. 视觉目标描述
我们将完整的情感峰值帧输入到 MiniGPT-v2 模型中,使其能够描述视频的场景、角色手势和其他方面。
4. 音频音调描述
我们使用音频作为 Qwen-Audio 模型的输入,然后描述说话者的语气和语调,从而产生对理解情绪同样重要的音频线索。
5. 粗粒度合成
通过将视觉和音频描述与词汇字幕集成在一个模板化序列中,我们生成了一个粗粒度的情感描述。总共制作了 28,618 份此类描述。
6. 细粒度生成
仅仅连接组件并不能真正解释情绪背后的触发因素。因此,我们将所有情感线索输入到 LLaMA-3 模型中,筛选并正确识别相关线索,结合不同的线索进行推理,从而得出全面的情感描述。
由于之前收集的情感线索未经证实,因此包含了一些错误或矛盾的描述。使用 LLaMA-3 的输出,我们可以轻松过滤掉这些样本。此外,由于样本过多,我们删除了一些样本,这通常是由原始数据集中的重复项引起的。我们还从中性样本中随机选择了一些来丰富我们的数据集。
通过这些过程,最终的 MERR 数据集包含 4,487 个样本及其相应的详细多模态描述。一个样本的注释示例如下所示:

局限性
-
在数据注释过程中,仅确定了两个 “厌恶” 样本。由于它们的数量有限,我们选择不将它们包含在 MERR 数据集中。我们计划探索更有效的数据过滤技术,以发现更多不太常见的情绪样本。
-
在我们的测试和使用中,Qwen-Audio 在各种大型音频模型中表现异常出色。但是,由于这些模型没有专门针对情感内容进行训练,因此情感描述中存在许多错误。需要进一步研究大型音频模型在情感识别中的应用。
MER-数据集生成器
特征
- AU 管道
:提取面部作单元并生成自然语言描述
- Audio Pipeline
:提取音频、转录语音和分析语气
- Video Pipeline
:生成全面的视频内容描述
- Image Pipeline
:通过图像描述和情感合成实现端到端的情感识别
- MER Pipeline
:完整的端到端多模态情绪识别,具有峰值帧检测和情绪合成功能
不同 MLLM 的 MERR 示例可以在 llava-llama3:latest_llama3.2_merr_data.json 中找到gemini_merr.json
三、MERR 数据集
3.1 数据集概述
MERR 数据集是为了支持多模态情感识别和推理研究而构建的。该数据集包含 28,618 个粗粒度和 4,487 个细粒度标注样本,涵盖了多样化的情感类别。每个样本都标注了情感标签,并对其情感表达进行了描述。
3.2 数据来源
MERR 数据集的数据主要来源于 MER2023-SEMI,该数据集包含超过 70,000 个未标注的视频片段。我们利用多个强大的多模态模型从不同模态中提取情感线索,并使用最新的 LLaMA-3 模型对所有情感线索进行总结和推理,最终得到多模态描述。
3.3 数据标注过程
3.3.1 视觉表达描述
由于视频中存在自然动作(如眨眼、说话等),我们通过特定方法提取面部动作单元(AU),并将其映射到自然语言描述中。例如,通过分析面部肌肉的运动来识别不同的 AU 组合,并根据预先定义的规则将其转换为相应的文本描述。
3.3.2 视觉客观描述
我们将完整的情感峰值帧输入到 MiniGPT-v2 模型中,该模型能够描述视频中的场景、人物手势等方面的信息。具体来说,MiniGPT-v2 模型通过对图像的特征提取和分析,生成关于图像内容的自然语言描述。
3.3.3 音频语调描述
我们使用音频作为输入,将其输入到 Qwen-Audio 模型中,该模型能够描述说话者的语调、语气等信息,为理解情感提供重要的音频线索。Qwen-Audio 模型通过对音频信号的特征提取和分析,生成关于音频语调的自然语言描述。
3.3.4 粗粒度合成
通过将视觉和音频描述与词汇字幕按照模板序列进行集成,我们生成了粗粒度的情感描述。总共生成了 28,618 个这样的描述。具体来说,我们定义了一些模板,将视觉、音频和文本信息按照一定的规则填充到模板中,生成粗粒度的情感描述。
3.3.5 细粒度生成
由于之前收集的情感线索可能存在错误或矛盾的描述,我们将所有情感线索输入到 LLaMA-3 模型中,对其进行筛选和推理,得到全面的情感描述。同时,我们还对样本进行了筛选和处理,去除了一些错误或重复的样本,并随机选择了一些中性样本以丰富数据集。最终,MERR 数据集包含 4,487 个样本及其对应的详细多模态描述。
3.4 数据集比较
与现有情感数据集相比,MERR 数据集扩展了情感类别和标注范围。每个样本都标注了情感标签,并对其情感表达进行了详细描述。通过比较不同数据集的情感类别覆盖范围、标注粒度等方面,我们可以发现 MERR 数据集具有更丰富的信息,能够为多模态情感识别和推理研究提供更好的支持。
四、Emotion-LLaMA 模型
4.1 模型架构
Emotion-LLaMA 模型通过情感特定编码器将音频、视觉和文本输入无缝集成到一个共享空间,并采用改进的 LLaMA 模型进行指令调优。具体来说,模型架构包括以下几个部分:
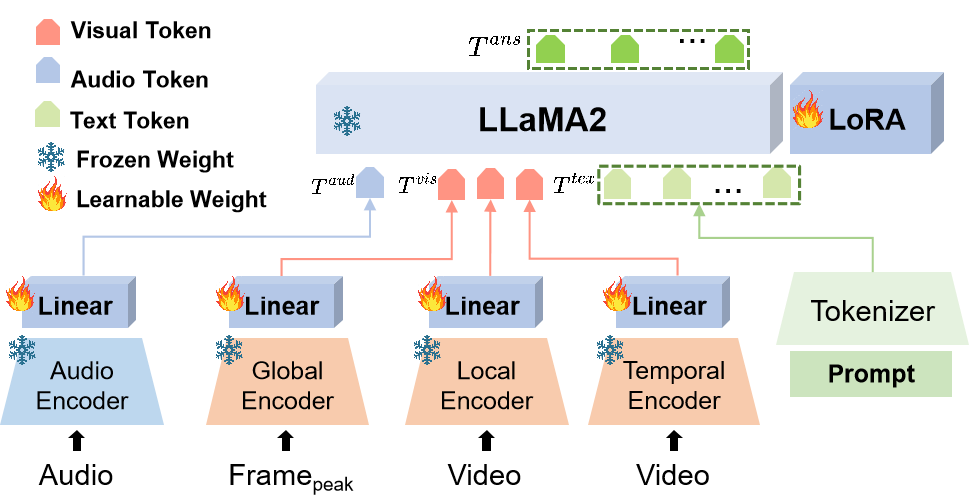
4.1.1 多模态编码器
- 音频编码器
:使用 HuBERT 模型作为音频编码器,该模型能够提取音频的特征表示。HuBERT 模型是一种基于自监督学习的音频模型,通过对大量音频数据的学习,能够自动发现音频中的语义信息。
- 全局编码器
:采用 EVA 模型作为全局编码器,用于提取图像的全局特征。EVA 模型是一种基于视觉 Transformer 的模型,能够捕捉图像的全局语义信息。
- 局部编码器
:使用 MAE 模型作为局部编码器,提取图像的局部特征。MAE 模型是一种基于自编码器的模型,通过对图像的掩码重建,能够学习到图像的局部结构信息。
- 时间编码器
:采用 VideoMAE 模型作为时间编码器,处理视频序列的时间特征。VideoMAE 模型是一种基于 Transformer 的视频模型,能够捕捉视频中的时间动态信息。
4.1.2 特征对齐模块
特征对齐模块的作用是将音频、视觉和文本特征对齐到一个共享空间。通过将不同模态的特征映射到同一个特征空间,使得模型能够更好地融合多模态信息。具体来说,我们可以使用线性变换或非线性变换将不同模态的特征进行对齐。
4.1.3 改进的 LLaMA 模型
我们采用改进的 LLaMA 模型进行指令调优。在原始 LLaMA 模型的基础上,我们引入了一些改进措施,如增加情感特定的注意力机制、调整模型的架构参数等,以提高模型的情感识别和推理能力。
4.2 技术原理
4.2.1 多模态特征提取
多模态编码器通过对音频、视觉和文本输入进行特征提取,将不同模态的信息转换为数值特征表示。例如,音频编码器将音频信号转换为特征向量,视觉编码器将图像或视频转换为特征矩阵,文本编码器将文本转换为词向量序列。
4.2.2 特征对齐
特征对齐模块通过学习不同模态特征之间的映射关系,将它们对齐到一个共享空间。在共享空间中,不同模态的特征具有相似的语义表示,使得模型能够更好地进行信息融合。
4.2.3 指令调优
改进的 LLaMA 模型通过指令调优来学习情感识别和推理的任务。在指令调优过程中,我们使用 MERR 数据集作为训练数据,为模型提供大量的多模态情感样本和相应的指令。模型通过学习这些样本和指令,不断调整自身的参数,以提高情感识别和推理的准确性。
4.3 公式定义
4.3.1 多模态特征提取

4.3.2 特征对齐

4.3.3 指令调优

五、项目实现
准备代码和环境
git clone https://github.com/ZebangCheng/Emotion-LLaMA.gitcd Emotion-LLaMA conda env create -f environment.yaml conda activate llama
准备预训练的 LLM 权重
将 Llama-2-7b-chat-hf 模型从 Huggingface 下载到 :Emotion-LLaMA/checkpoints/
> https://huggingface.co/meta-llama/Llama-2-7b-chat-hf 在模型配置文件中指定 Llama-2 的路径:
# Set Llama-2-7b-chat-hf pathllama_model: \"/home/user/project/Emotion-LLaMA/checkpoints/Llama-2-7b-chat-hf\"
在配置文件中指定 MiniGPT-v2 的路径:
# Set MiniGPT-v2 pathckpt: \"/home/user/project/Emotion-LLaMA/checkpoints/minigptv2_checkpoint.pth\"
您可以参考 Project Overview 中显示的路径来存储下载的文件。
🎬 演示
在线演示
您可以通过在线演示体验 Emotion-LLaMA 强大的情感识别能力。
https://huggingface.co/spaces/ZebangCheng/Emotion-LLaMA
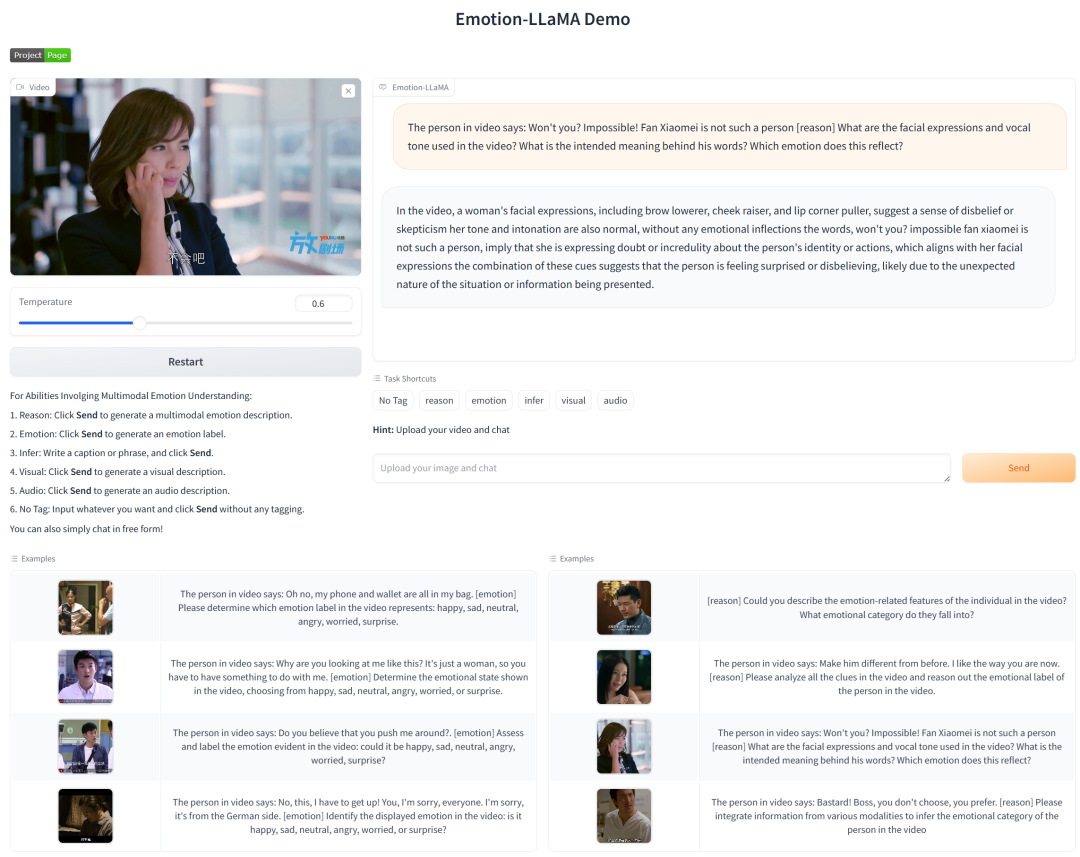

本地演示
1.从 Huggingface 下载 HuBERT-large 模型到:Emotion-LLaMA/checkpoints/transformer/
https://huggingface.co/TencentGameMate/chinese-hubert-large
2.在对话文件中指定 HuBERT-large 的路径:
# Set HuBERT-large model pathmodel_file = \"checkpoints/transformer/chinese-hubert-large\"3.从 Googel Drive 下载 Emotion-LLaMA 演示模型到:Emotion-LLaMA/checkpoints/save_checkpoint/
https://drive.google.com/file/d/1pNngqXdc3cKr9uLNW-Hu3SKvOpjzfzGY/view?usp=sharing
4.在 demo 配置文件中指定 Emotion-LLaMA 的路径:
# Set Emotion-LLaMA pathckpt: \"/home/user/project/Emotion-LLaMA/checkpoints/save_checkpoint/Emoation_LLaMA.pth\"
5.安装所需的软件包:
pip install moviepy==1.0.3pip install soundfile==0.12.1pip install opencv-python==4.7.0.726.本地启动 Demo
python app.py# After running the code, click the following link to experience the demo webpage: # Running on local URL: http://127.0.0.1:7860Gradio API - 本地推理 API
详细的 Gradio API 文档请参考:
-
📖 英文 README
-
📖 中文 README
💡 训练
1. 下载数据集 由于版权限制,我们无法提供原始视频或提取的图像。请访问 MER2023 官方网站申请访问数据集。
http://merchallenge.cn/datasets
然后在 dataset 配置文件中指定 Dataset 的路径:
# Set Dataset video pathimage_path: /home/czb/big_space/datasets/Emotion/MER2023/video
2. 准备多模态编码器为了提取丰富而全面的情感特征,我们使用 HuBERT 模型作为音频编码器,使用 EVA 模型作为全局编码器,使用 MAE 模型作为本地编码器,使用 VideoMAE 模型作为时间编码器。在实践中,为了节省 GPU 内存,我们不会将所有 Encoder 直接加载到 GPU 上,而是加载提取的特征。您可以通过以下 Google Drive 链接下载已处理的特征文件,并将其保存到数据集文件夹。
https://drive.google.com/drive/folders/1DqGSBgpRo7TuGNqMJo9BYg6smJE20MG4?usp=drive_link
请修改数据集文件中的函数,设置读取特征的路径。get()
可以在 “feature_extract” 文件夹的内容中引用特定的特征提取过程。详细说明将很快发布。
https://drive.google.com/drive/folders/1d-Sg5fAskt2s6OOEUNXFaM2u-C055Whj?usp=sharing
3. 设置数据集配置在数据集配置文件中,选择使用 MERR_coarse_grained.txt。第一阶段的训练总共有 28,618 个粗粒度视频样本。
4. 准备多任务指令
首先,在数据集文件中设置任务类型:
self.task_pool= [ \"emotion\", \"reason\", # \"reason_v2\",]
这里,“情绪”任务表示多模态情绪识别任务,而“reason”任务表示多模态情绪推理任务。不同的任务将从不同的指令池中随机选择不同的提示。
5. 运行运行以下代码以预训练 Emotion-LLaMA:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc-per-node 4 train.py --cfg-path train_configs/Emotion-LLaMA_finetune.yaml
6. 下一步如果您想体验指令调整过程,并查看 Emotion-LLaMA 在 EMER 数据集的情绪推理测试中的表现,请参阅第 2 阶段。
六、实验评估
6.1 实验设置
我们在多个数据集上对 Emotion-LLaMA 进行了实验评估,包括 EMER、MER2023 和 DFEW 等。实验中使用的评估指标包括 Clue Overlap、Label Overlap、F1 分数、UAR 和 WAR 等。
6.2 实验结果
6.2.1 在 EMER 数据集上的表现
Emotion-LLaMA 在 EMER 数据集上取得了 Clue Overlap 为 7.83 和 Label Overlap 为 6.25 的成绩,表明模型在情感线索识别和情感标签匹配方面具有较好的性能。
Method
Modality
F1 Score
wav2vec 2.0
A
0.4028
VGGish
A
0.5481
HuBERT
A
0.8511
ResNet
V
0.4132
MAE
V
0.5547
VideoMAE
V
0.6068
RoBERTa
T
0.4061
BERT
T
0.4360
MacBERT
T
0.4632
MER2023-Baseline
A, V
0.8675
MER2023-Baseline
A, V, T
0.8640
Transformer
A, V, T
0.8853
FBP
A, V, T
0.8855
VAT
A, V
0.8911
Emotion-LLaMA (ours)
A, V
0.8905
6.2.2 在 MER2023 挑战中的表现
在 MER2023 挑战中,Emotion-LLaMA 取得了 0.9036 的 F1 分数,显示了模型在多模态情感识别任务上的优异性能。
Models
Clue Overlap
Label Overlap
VideoChat-Text
6.42
3.94
Video-LLaMA
6.64
4.89
Video-ChatGPT
6.95
5.74
PandaGPT
7.14
5.51
VideoChat-Embed
7.15
5.65
Valley
7.24
5.77
6.2.3 在 DFEW 数据集上的零样本评估
在 DFEW 数据集上的零样本评估中,Emotion-LLaMA 取得了最高的 UAR(45.59)和 WAR(59.37),证明了模型在未见过数据上的泛化能力。
Teams
Score
SZTU-CMU
0.8530 (1)
BZL arc06
0.8383 (2)
VIRlab
0.8365 (3)
T_MERG
0.8271 (4)
AI4AI
0.8128 (5)
USTC-IAT
0.8066 (6)
fzq
0.8062 (7)
BUPT-BIT
0.8059 (8)
Soul AI
0.8017 (9)
NWPU-SUST
0.7972 (10)
iai-zjy
0.7842 (11)
SJTU-XLANCE
0.7835 (12)
ILR
0.7833 (13)
ACRG_GL
0.7782 (14)
6.3 结果分析
通过与其他 MLLMs 的比较,我们发现 Emotion-LLaMA 在多个评估指标上都取得了更好的成绩。这表明我们提出的 MERR 数据集和 Emotion-LLaMA 模型能够有效提高多模态情感识别和推理的性能。
七、结论与展望
7.1 研究成果总结
本项目提出了 Emotion-LLaMA 模型和 MERR 数据集,通过情感特定编码器和指令调优,显著提高了多模态情感识别和推理的能力。实验评估结果表明,Emotion-LLaMA 在多个数据集上优于其他 MLLMs,取得了优异的成绩。
7.2 研究局限性
-
在数据标注过程中,仅识别出两个 “厌恶” 样本,由于数量有限,未将其包含在 MERR 数据集。未来需要探索更有效的数据过滤技术,以发现更多不常见情感的样本。
-
虽然 Qwen-Audio 在各种大型音频模型中表现出色,但由于这些模型未专门针对情感内容进行训练,情感描述中存在许多错误。需要进一步研究大型音频模型在情感识别中的应用。
7.3 未来研究方向
- 数据增强
:探索更多的数据增强技术,以增加不常见情感样本的数量,提高模型对各种情感的识别能力。
- 模型改进
:进一步改进 Emotion-LLaMA 模型的架构和训练方法,提高模型的性能和效率。
- 应用拓展
:将 Emotion-LLaMA 模型应用到更多的实际场景中,如智能客服、情感教育等,验证模型的实用性和有效性。
综上所述,Emotion-LLaMA 项目为多模态情感识别和推理研究提供了新的思路和方法,具有重要的理论和实践意义。未来的研究将进一步完善该项目,推动多模态情感识别技术的发展。
附录:代码框架结构
📦Emotion-LLaMA ┣ 📂Dataset ┃ ┗ 📦Emotion ┃ ┃ ┗ 📂MER2023 ┃ ┃ ┃ ┣ 📂video # 存放 MER2023 数据集的视频文件 ┃ ┃ ┃ ┣ 📂HL-UTT # 语音相关的特定特征或数据文件夹 ┃ ┃ ┃ ┣ 📂mae_340_UTT # 音频或视频特征提取后的结果文件夹 ┃ ┃ ┃ ┣ 📂maeV_399_UTT # 是另一种音频或视频特征提取后的结果文件夹 ┃ ┃ ┃ ┣ 📄transcription_en_all.csv # 包含所有视频的英文转录文本数据 ┃ ┃ ┃ ┣ 📄MERR_coarse_grained.txt # MERR 数据集的粗粒度标注文本文件 ┃ ┃ ┃ ┣ 📄MERR_coarse_grained.json # MERR 数据集的粗粒度标注 JSON 文件 ┃ ┃ ┃ ┣ 📄MERR_fine_grained.txt # MERR 数据集的细粒度标注文本文件 ┃ ┃ ┃ ┗ 📄MERR_fine_grained.json # MERR 数据集的细粒度标注 JSON 文件 ┣ 📂checkpoints ┃ ┣ 📂Llama-2-7b-chat-hf # 存放 Llama - 2 - 7b - chat - hf 模型的检查点文件 ┃ ┣ 📂save_checkpoint ┃ ┃ ┣ 📂stage2 ┃ ┃ ┃ ┣ 🔖checkpoint_best.pth # 第二阶段训练的最佳检查点文件 ┃ ┃ ┃ ┗ 📄log.txt # 第二阶段训练的日志文件 ┃ ┃ ┗ 🔖Emoation_LLaMA.pth # Emotion - LLaMA 模型的检查点文件 ┃ ┣ 📂transformer ┃ ┃ ┗ 📂chinese-hubert-large # 存放中文 Hubert 大模型的相关文件 ┃ ┗ 🔖minigptv2_checkpoint.pth # MiniGPT - v2 模型的检查点文件 ┣ 📂eval_configs ┃ ┣ 📜demo.yaml # 演示评估的配置文件 ┃ ┣ 📜eval_emotion.yaml # 情感评估的配置文件 ┃ ┗ 📜eval_emotion_EMER.yaml # EMER 相关情感评估的配置文件 ┣ 📂train_configs ┃ ┣ 📜Emotion-LLaMA_finetune.yaml # Emotion - LLaMA 微调训练的配置文件 ┃ ┗ 📜minigptv2_tuning_stage_2.yaml # MiniGPT - v2 第二阶段调优的配置文件 ┣ 📂minigpt4 ┃ ┣ 📂common ┃ ┃ ┣ 📂vqa_tools ┃ ┃ ┃ ┗ 📂VQA ┃ ┃ ┃ ┃ ┣ 📂Images # 存放 VQA 相关的图像文件 ┃ ┃ ┃ ┃ ┃ ┣ 📂mscoco ┃ ┃ ┃ ┃ ┃ ┃ ┣ 📂train2014 # MSCOCO 训练集 2014 年的图像文件夹 ┃ ┃ ┃ ┃ ┃ ┃ ┣ 📂val2014 # MSCOCO 验证集 2014 年的图像文件夹 ┃ ┃ ┃ ┃ ┃ ┃ ┗ 📂test2015 # MSCOCO 测试集 2015 年的图像文件夹 ┃ ┃ ┃ ┃ ┃ ┗ 📂abstract_v002 ┃ ┃ ┃ ┃ ┃ ┃ ┣ 📂train2015 # 抽象数据集 2015 年训练集的图像文件夹 ┃ ┃ ┃ ┃ ┃ ┃ ┣ 📂val2015 # 抽象数据集 2015 年验证集的图像文件夹 ┃ ┃ ┃ ┃ ┃ ┃ ┗ 📂test2015 # 抽象数据集 2015 年测试集的图像文件夹 ┃ ┃ ┃ ┃ ┣ 📂PythonHelperTools # 包含读取和可视化 VQA 数据集的 Python API ┃ ┃ ┃ ┃ ┃ ┣ 📜vqaDemo.py # VQA 演示脚本 ┃ ┃ ┃ ┃ ┃ ┗ 📂vqaTools # VQA 数据读取和可视化的工具包 ┃ ┃ ┃ ┃ ┣ 📂PythonEvaluationTools # 包含 VQA 评估的 Python 代码 ┃ ┃ ┃ ┃ ┃ ┣ 📜vqaEvalDemo.py # VQA 评估演示脚本 ┃ ┃ ┃ ┃ ┃ ┗ 📂vqaEvaluation # VQA 评估代码包 ┃ ┃ ┃ ┃ ┣ 📂Results # 存放 VQA 评估结果的文件夹 ┃ ┃ ┃ ┃ ┃ ┗ 📜OpenEnded_mscoco_train2014_fake_results.json # VQA v1.0 假结果示例文件 ┃ ┃ ┃ ┃ ┣ 📂QuestionTypes # 存放 VQA 问题类型相关文件的文件夹 ┃ ┃ ┃ ┃ ┗ 📜README.md # VQA 相关的说明文件 ┃ ┃ ┣ 📜config.py # 通用配置文件 ┃ ┃ ┗ 📜registry.py # 通用注册表文件 ┃ ┣ 📂conversation ┃ ┃ ┗ 📜conversation.py # 对话相关的代码文件 ┃ ┣ 📂datasets ┃ ┃ ┗ 📂datasets ┃ ┃ ┃ ┗ 📜first_face.py # 处理人脸相关数据集的代码文件 ┃ ┣ 📂models ┃ ┃ ┗ 📜minigpt_base.py # MiniGPT 基础模型的代码文件 ┣ 📑app.py # 项目的应用程序入口文件 ┣ 📜environment.yml # 项目的环境配置文件 ┣ 📑eval_emotion.py # 情感评估的脚本文件 ┣ 📑eval_emotion_EMER.py # EMER 相关情感评估的脚本文件 ┣ 📑train.py # 模型训练的脚本文件 ┣ 📜README.md # 项目的说明文档 ┣ 📜Overview.md # 项目的概述文档 ┣ 📂MERR ┃ ┗ 📜README.md # MERR 数据集相关的说明文档 ┣ 📂api_en.md # 英文的 API 文档 ┗ 📂api_zh.md # 中文的 API 文档
