MagicDrive: Street View Generation with Diverse 3D Geometry Control——具有多样化 3D 几何控制的街景生成
这篇文章介绍了一个名为 MAGICDRIVE 的新型街景生成框架,专门用于具有多样化 3D 几何控制的高质量街景图像和视频合成。以下是文章的主要研究内容总结:
研究背景
-
街景生成的重要性:街景图像和视频在自动驾驶、虚拟现实等地方有广泛应用,但真实数据的收集和标注成本高昂。因此,合成街景数据对于提升自动驾驶模型的性能具有重要意义。
-
现有方法的局限性:现有的街景生成方法主要依赖于 2D 控制(如 2D 边界框或分割图),难以精确控制 3D 几何信息(如高度、深度和遮挡)。这限制了生成图像在 3D 感知任务(如 BEV 分割和 3D 目标检测)中的应用。
MAGICDRIVE 框架
-
核心目标:MAGICDRIVE 旨在通过精确的 3D 几何控制生成高质量的街景图像和视频,支持多种条件(如相机姿态、道路地图、3D 边界框和文本描述)。
-
主要贡献:
-
提出了一种新的街景生成框架,能够根据 BEV 地图和 3D 数据生成多视角相机视图和视频。
-
开发了简单而有效的策略来管理 3D 几何数据,解决了多相机视图一致性的问题。
-
实验证明,MAGICDRIVE 在多维可控性方面优于现有技术,并且合成数据显著提升了 3D 感知任务的性能。
-
方法细节
-
3D 几何控制:MAGICDRIVE 将条件分为三个级别:
-
场景级:包括相机姿态和文本描述(如天气、时间)。
-
前景级:3D 边界框,用于控制目标的位置和形状。
-
背景级:道路地图,用于控制道路布局和环境。
-
-
跨视图注意力模块:为了确保多相机视图之间的一致性,MAGICDRIVE 引入了跨视图注意力模块,允许每个视图从相邻视图获取信息。
-
模型训练:使用分类器自由引导(CFG)技术,通过在训练中随机丢弃条件来增强模型的泛化能力。
实验结果
-
真实性:通过 Fréchet Inception Distance(FID)评估,MAGICDRIVE 生成的图像在质量上优于现有方法。
-
可控性:在 BEV 分割和 3D 目标检测任务中,使用 MAGICDRIVE 生成的数据作为增强,显著提升了模型的性能。
-
多级控制能力:MAGICDRIVE 能够根据场景级、背景级和前景级的条件进行灵活调整,生成多样化的街景。
未来工作
-
跨域泛化能力:当前方法在生成未见过的天气或极端条件下的街景时存在局限性,未来工作将致力于提升模型的跨域泛化能力。
-
更广泛的应用:探索如何将生成的街景数据用于更广泛的任务,如生成预训练、对比学习和与大语言模型结合等。
总之,MAGICDRIVE 通过其创新的 3D 几何控制和跨视图一致性设计,为街景生成领域带来了显著的改进,并为自动驾驶和相关领域的应用提供了高质量的合成数据支持。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

项目主页地址在这里,如下所示:
开源项目地址在这里,如下所示:
摘要
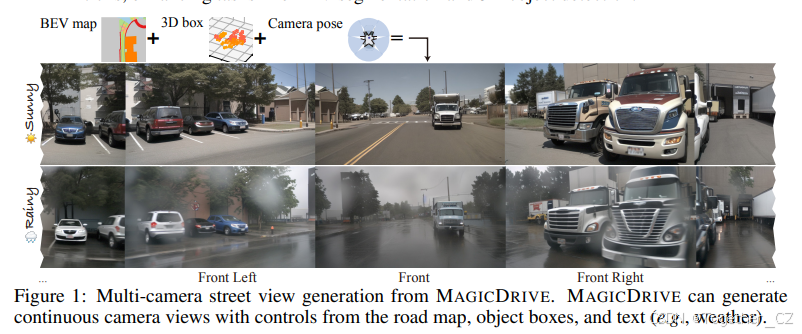
近期在扩散模型方面的进展显著提升了具有 2D 控制的数据合成能力。然而,在街景生成中实现精确的 3D 控制对于 3D 感知任务来说至关重要,但目前仍难以实现。特别是,使用鸟瞰图(BEV)作为主要条件时,常常会在几何控制方面(例如高度)遇到挑战,这会影响物体形状、遮挡模式以及路面高程的表示,而这些对于感知数据合成,尤其是 3D 目标检测任务来说都是必不可少的。在本文中,我们介绍了一种名为 MAGICDRIVE 的新型街景生成框架,它提供了多样化的 3D 几何控制,包括相机姿态、道路地图和 3D 边界框,以及通过量身定制的编码策略实现的文字描述。此外,我们的设计中还加入了一个跨视图注意力模块,以确保多个相机视图之间的一致性。借助 MAGICDRIVE,我们实现了高保真度的街景图像和视频合成,捕捉到了细腻的 3D 几何和各种场景描述,从而提升了诸如 BEV 分割和 3D 目标检测等任务的效果。
1 引言
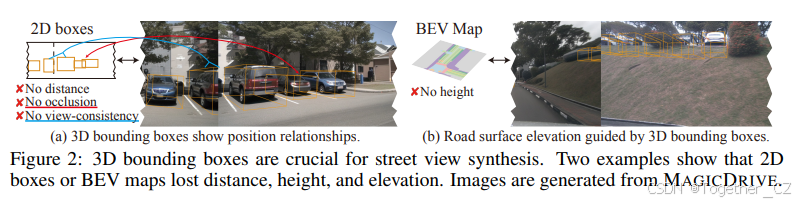
与数据收集和标注相关的高昂成本常常阻碍了深度学习模型的有效训练。幸运的是,尖端的生成模型已经表明,合成数据可以在诸如目标检测(Chen et al., 2023c)和语义分割(Wu et al., 2023b)等各种任务中显著提升性能。然而,现有的方法主要针对 2D 情境,主要依赖于 2D 边界框(Lin et al., 2014; Han et al., 2021)或分割图(Zhou et al., 2019)作为布局条件(Chen et al., 2023c; Li et al., 2023b)。 在自动驾驶应用中,对 3D 环境的全面掌握是必不可少的。这要求可靠的技术来完成诸如 BEV 地图分割(Zhou & Krähembühl, 2022; Ji et al., 2023)和 3D 目标检测(Chen et al., 2020; Huang et al., 2021; Liu et al., 2023a; Ge et al., 2023)等任务。对于从 3D 注释中捕捉复杂细节来说,真实的 3D 几何表示至关重要,例如道路高程、物体高度及其遮挡模式,如图 2 所示。
因此,根据 3D 注释生成多相机街景图像对于提升下游感知任务至关重要。 对于街景数据合成,有两个关键标准:真实性和可控性。真实性要求合成数据的质量应与真实数据的质量相匹配;并且在给定场景中,不同相机视角的视图应彼此保持一致(Mildenhall et al., 2020)。另一方面,可控性强调在生成街景图像时要精确地遵循提供的条件:BEV 地图、3D 目标边界框和用于视图的相机姿态。除了这些核心要求外,有效的数据增强还应提供调整更细微场景属性的灵活性,例如常见的天气状况或一天中的时间。现有的解决方案,如 BEVGen(Swerdlow et al., 2023)通过将所有语义封装在 BEV 中来接近街景生成。相反,BEVControl(Yang et al., 2023a)首先将 3D 坐标投影到图像视图中,随后使用 2D 几何引导。然而,这两种方法都牺牲了某些几何维度——BEVGen 中丢失了高度,而 BEVControl 中丢失了深度。 扩散模型的兴起显著推动了可控图像生成质量的边界。具体来说,ControlNet(Zhang et al., 2023a)提出了一个灵活的框架,用于在预训练的文本到图像(T2I)扩散模型(Rombach et al., 2022)的基础上整合 2D 空间控制。然而,3D 条件与像素级条件或文本不同。将它们与多相机视图一致性无缝整合在街景合成中的挑战仍然存在。 在本文中,我们介绍了一种名为 MAGICDRIVE 的新型框架,专门用于具有多样化 3D 几何控制的街景合成。为了实现真实性,我们利用了预训练的稳定扩散(Rombach et al., 2022),并进一步对其进行了街景生成的微调。我们框架的一个独特组成部分是跨视图注意力模块。这个简单而有效的组成部分通过相邻视图之间的交互提供了多视图一致性。与以前的方法相比,MAGICDRIVE 提出了一种针对物体和道路地图编码的独立设计,以提高对 3D 数据的可控性。更具体地说,鉴于 3D 边界框的序列式、可变长度特性,我们采用了类似于文本嵌入的交叉注意力来进行它们的编码。此外,我们提出一个类似于 ControlNet(Zhang et al., 2023a)的附加编码器分支可以对 BEV 中的地图进行编码,并且能够进行视图变换。因此,我们的设计在不诉诸于任何显式的几何变换或对多相机一致性施加几何约束的情况下实现了几何控制。最后,MAGICDRIVE 考虑了文字描述,提供了诸如天气条件和一天中的时间等属性控制。 尽管我们的 MAGICDRIVE 框架很简单,但它在生成与道路地图、3D 边界框和各种相机视角一致的惊人逼真图像和视频方面表现出色。此外,所产生的图像可以增强针对 BEV 分割和 3D 目标检测任务的训练。此外,MAGICDRIVE 在场景、背景和前景级别提供了全面的几何控制。这种灵活性使得可以创造出以前未曾见过的街景,适合用于模拟目的。我们总结了本工作的主要贡献如下:
-
引入了 MAGICDRIVE,这是一个创新的框架,它根据 BEV 和 3D 数据生成多视角相机视图和视频,专门用于自动驾驶。
-
开发了简单而强大的策略来管理 3D 几何数据,有效地解决了街景生成中多相机视图一致性方面的挑战。
-
通过严格的实验,我们证明了 MAGICDRIVE 在多维可控性方面优于以前的街景生成技术。此外,我们的结果表明,合成数据在 3D 感知任务中带来了显著的改进。
2 相关工作
扩散模型用于条件生成
扩散模型(Ho et al., 2020; Song et al., 2020; Zheng et al., 2023)通过学习从高斯噪声分布到图像分布的逐步去噪过程来生成图像。这些模型因其适应性和在处理各种形式的控制(Zhang et al., 2023a; Li et al., 2023b)和多种条件(Liu et al., 2022a; Gao et al., 2023)方面的出色能力,在诸如文本到图像合成(Rombach et al., 2022; Nichol et al., 2022; Yang et al., 2023b)、修复(Wang et al., 2023a)和指令性图像编辑(Zhang et al., 2023b; Brooks et al., 2023)等多样化任务中表现出色。此外,从几何注释中合成的数据可以帮助下游任务,例如 2D 目标检测(Chen et al., 2023c; Wu et al., 2023b)。因此,本文探索了 T2I 扩散模型在生成街景图像和为下游 3D 感知模型带来益处方面的潜力。
街景生成
许多街景生成模型以 2D 布局为条件,例如 2D 边界框(Li et al., 2023b)和语义分割(Wang et al., 2022)。这些方法利用直接对应于图像尺度的 2D 布局信息,而 3D 信息并不具备这一特性,因此这些方法不适合利用 3D 信息进行生成。对于带有 3D 几何的街景合成,BEVGen(Swerdlow et al., 2023)是第一个探索的。它使用 BEV 地图作为道路和车辆的条件。然而,遗漏了高度信息限制了其在 3D 目标检测中的应用。BEVControl(Yang et al., 2023a)通过高度提升过程修正了目标高度的丢失。同样,Wang et al.(2023b)也将 3D 边界框投影到相机视图中以指导生成。然而,从 3D 到 2D 的投影导致了诸如深度和遮挡等重要的 3D 几何信息的丢失。在本文中,我们提出分别对边界框和道路地图进行编码以实现更细腻的控制,并整合场景描述,提供对街景生成的增强控制。
多相机图像生成
多相机图像生成的一个 3D 场景从根本上需要视角一致性。一些研究在室内场景的背景下解决了这一问题。例如,MVDiffusion(Tang et al., 2023)使用全景图像和跨视图注意力模块来维持全局一致性,而 Tseng et al.(2023)则利用极线几何作为约束先验。然而,这些方法主要依赖于图像视图的连续性,这一条件在街景中并不总是满足,因为街景的相机重叠有限,且相机配置不同(例如曝光、内参)。我们的 MAGICDRIVE 引入了额外的跨视图注意力模块到 UNet 中,这显著增强了多相机视图之间的一致性。
3 预备知识
问题表述
在本文中,我们将激光雷达系统的坐标视为自车的坐标,并根据它对所有几何信息进行参数化。设 S = {M, B, L} 为围绕自车的驾驶场景描述,其中 M ∈ {0, 1}w×h×c 是一个二进制地图,表示一个 w×h 米的 BEV 道路区域,包含 c 个语义类别;B = {(ci, bi)}N i=1 表示场景中每个目标的 3D 边界框位置(bi = {(xj, yj, zj)}8 j=1 ∈ R8×3)和类别(ci ∈ C);L 是描述场景其他信息(例如天气和一天中的时间)的文本。给定一个相机姿态 P = [K, R, T](即内参、旋转和平移),街景图像生成的目标是学习一个生成器 G(·),它根据场景 S 和相机姿态 P 合成与之对应的逼真图像 I ∈ RH×W×3,即 I = G(S, P, z),其中 z ∼ N(0, 1) 是来自高斯分布的随机噪声。
条件扩散模型
扩散模型(Ho et al., 2020; Song et al., 2020)通过迭代去噪一个随机高斯噪声(xT)来生成数据(x0),共进行 T 步。通常,为了学习去噪过程,网络通过最小化均方误差来训练预测噪声: ℓsimple = Ex0,c,ϵ,t ||ϵ − ϵθ(√¯αtx0 + √1 − ¯αtϵ, t, c)||2,(1) 其中 ϵθ 是要训练的网络,参数为 θ,c 是可选条件,用于条件生成,t ∈ [0, T] 是时间步,ϵ ∈ N(0, I) 是加性高斯噪声,¯αt 是一个标量参数。潜在扩散模型(LDM)(Rombach et al., 2022)是一种特殊的扩散模型,它利用预训练的矢量量化变分自编码器(VQVAE)(Esser et al., 2021),并在潜在空间中进行扩散过程。给定 VQ-VAE 编码器为 z = E(x),可以将式(1)中的 ϵθ(·) 重写为 ϵθ(√¯αtE(x0) + √1 − ¯αtϵ, t, c),用于 LDM。此外,LDM 考虑将描述图像的文本作为条件 c。
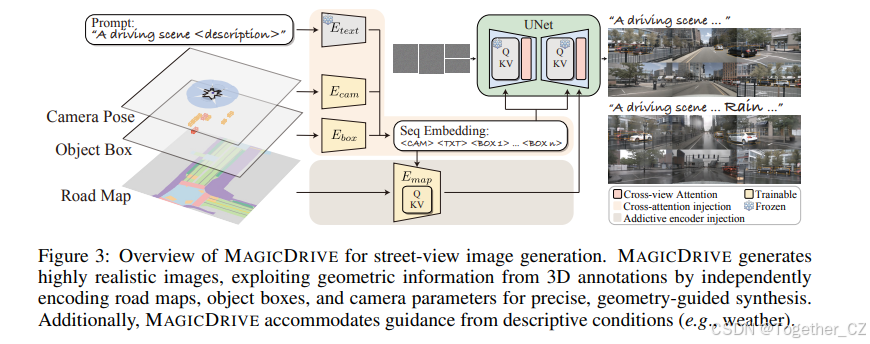
4 带有 3D 信息的街景生成
MAGICDRIVE 的概述如图 3 所示。MAGICDRIVE 基于 LDM 流程,根据场景注释(S)和每个视图的相机姿态(P)生成街景图像。鉴于场景注释中的 3D 几何信息,将所有信息投影到一个 BEV 地图上,类似于 BEVGen(Swerdlow et al., 2023)或 BEVControl(Yang et al., 2023a),并不能确保对街景生成的精确指导,如图 2 所示。因此,MAGICDRIVE 将条件分为三个级别:场景级(文本和相机姿态)、前景级(3D 边界框)和背景级(道路地图);并通过交叉注意力和附加编码器分支分别整合它们,详细内容在第 4.1 节中介绍。此外,保持不同相机之间的一致性对于合成街景至关重要。因此,我们在第 4.2 节中引入了一个简单而有效的跨视图注意力模块。最后,我们在第 4.3 节中阐述了训练策略,强调了在整合各种条件时使用分类器自由引导(CFG)。
几何条件编码
如图 3 所示,MAGICDRIVE 采用了两种策略将信息注入扩散模型的 UNet:交叉注意力和附加编码器分支。鉴于注意力机制(Vaswani et al., 2017)是为序列数据量身定制的,交叉注意力适用于处理像文本标记和边界框这样的可变长度输入。相反,对于像道路地图这样的网格状数据,附加编码器分支在信息注入方面更为有效(Zhang et al., 2023a)。因此,MAGICDRIVE 为各种条件采用了不同的编码模块。
场景级编码
场景级编码包括相机姿态 P = {K ∈ R3×3, R ∈ R3×3, T ∈ R3×1} 和文本序列 L。对于文本,我们使用模板“一个驾驶场景图像在 {location}。{description}”构建提示,并利用预训练的 CLIP 文本编码器(Etext)作为 LDM(Rombach et al., 2022),如公式(2)所示,其中 L 是 L 的标记长度。对于相机姿态,我们首先将每个参数按列连接,得到 ¯P = [K, R, T]T ∈ R7×3。由于 ¯P 包含来自正弦/余弦函数的值以及 3D 偏移量,为了使模型能够有效解释这些高频变化,我们在利用多层感知机(MLP,Ecam)嵌入相机姿态参数之前,对每个 3 维向量应用傅里叶嵌入,如公式(3)所示。为了保持一致性,我们将 hc 的维度设置为与 ht i 相同。通过 CLIP 文本编码器,每个文本嵌入 ht i 已经包含了位置信息(Radford et al., 2021)。因此,我们将相机姿态嵌入 hc 添加到文本嵌入的前面,得到场景级嵌入
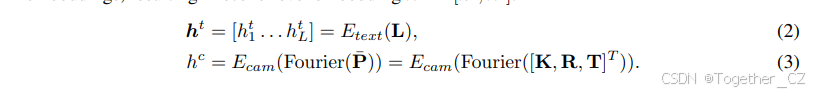
3D 边界框编码
由于每个驾驶场景都有可变长度的边界框,我们通过类似于场景级信息的交叉注意力机制将它们注入。具体来说,我们将每个边界框编码为一个隐藏向量 hb,其维度与 ht 相同。每个 3D 边界框(ci, bi)包含两种信息:类别标签 ci 和边界框位置 bi。对于类别标签,我们采用了类似于 Li et al.(2023b)的方法,将类别名称的池化嵌入(Lci)视为标签嵌入。对于边界框位置 bi ∈ R8×3,由其 8 个角点的坐标表示,我们对每个点应用傅里叶嵌入并通过 MLP 进行编码,如公式(4)所示。然后,我们使用 MLP 将类别和位置嵌入压缩成一个隐藏向量,如公式(5)所示。每个场景的所有边界框的最终隐藏状态表示为 hb = [hb 1 ... hb N],其中 N 是边界框的数量。 eb c(i) =
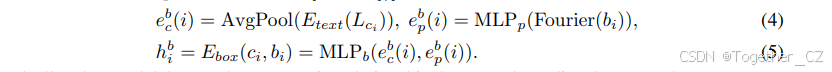
理想情况下,模型通过训练学习边界框与相机姿态之间的几何关系。然而,不同视图中可见边界框的数量分布是长尾的。因此,我们通过过滤每个视图(vi)的可见对象来引导学习,即公式(6)中的 fviz。此外,我们还添加不可见的边界框进行增强(更多细节见第 4.3 节)。
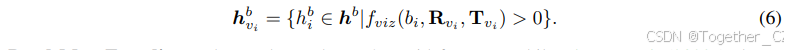
道路地图编码
道路地图具有 2D 网格格式。虽然 Zhang et al.(2023a)表明附加编码器可以整合这种数据用于 2D 指导,但道路地图的 BEV 与相机的 FPV 之间固有的视角差异会导致差异。BEVControl(Yang et al., 2023a)采用后投影从 BEV 转换到 FPV,但会使问题复杂化。在 MAGICDRIVE 中,我们认为显式的视图转换是不必要的,因为足够的 3D 线索(例如来自目标边界框的高度和相机姿态)允许附加编码器完成视图转换。具体来说,我们将场景级和 3D 边界框嵌入整合到地图编码器中(见图 3)。场景级嵌入提供相机姿态,边界框嵌入提供道路高程线索。此外,整合文字描述有助于在不同条件下(例如天气和一天中的时间)生成道路。因此,地图编码器可以与其他条件协同进行生成。
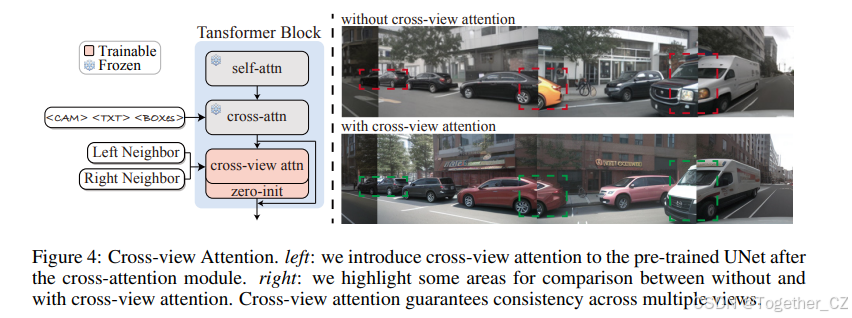
跨视图注意力模块
在多相机视图生成中,确保不同视角的图像合成保持一致至关重要。为了维持一致性,我们引入了一个跨视图注意力模块(见图 4)。鉴于驾驶场景中相机的稀疏排列,每个跨视图注意力允许目标视图访问其左右视图的信息,如公式(7)所示;这里,t、l 和 r 分别表示目标、左和右视图。然后,目标视图通过跳跃连接聚合这些信息,如公式(8)所示,其中 hv 表示目标视图的隐藏状态。
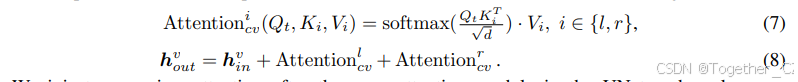
我们在 UNet 的交叉注意力模块之后注入跨视图注意力,并应用零初始化(Zhang et al., 2023a)以引导优化。跨视图注意力模块的效能如图 4 右侧、图 5 和图 6 所示。UNet 的多层结构使得在经过几个堆叠块后能够聚合来自长距离视图的信息。因此,在相邻视图上使用跨视图注意力就足以实现多视图一致性,这一结论也得到了附录 C 中消融研究的进一步证实。
模型训练
分类器自由引导(CFG)强化了条件引导的影响(Ho & Salimans, 2021; Rombach et al., 2022)。为了实现有效的 CFG,模型在训练过程中需要偶尔丢弃条件。鉴于每个条件的独特性,为多个条件应用丢弃策略较为复杂。因此,我们的 MAGICDRIVE 通过同时以 γs 的速率丢弃场景级条件(相机姿态和文本嵌入)来简化这一过程。对于具有语义表示空值(即边界框中的填充标记和地图中的 0)的边界框和地图,我们在整个训练过程中保持它们。在推理时,我们对所有条件使用空值,从而在引导生成时实现有意义的放大。
训练目标和增强
在将所有条件作为输入的情况下,我们将第 3 节中描述的训练目标适应于多条件场景,如公式(9)所示。
![]()
此外,我们在训练 MAGICDRIVE 时强调两种重要的策略。首先,为了抵消我们对可见边界框的过滤,我们随机添加 10% 的不可见边界框作为增强,增强模型的几何变换能力。其次,为了利用跨视图注意力,它促进不同视图之间的信息共享,我们在每个训练步骤中为不同视图应用独特的噪声,防止对公式(9)的平凡解(例如,输出不同视图之间的共享组件)。只有在推理时才保留相同的随机噪声。
5 实验
5.1 实验设置
数据集和基线
我们采用 nuScenes 数据集(Caesar et al., 2020),这是一个在自动驾驶领域用于 BEV 分割和检测的流行数据集,作为 MAGICDRIVE 的测试平台。我们遵循官方配置,使用 700 个街景场景进行训练,150 个用于验证。我们的基线是 BEVGen(Swerdlow et al., 2023)和 BEVControl(Yang et al., 2023a),它们都是最近提出的街景生成方法。我们的方法考虑了 10 个目标类别和 8 个道路类别,超过了基线模型的多样性。附录 B 中包含了更多细节。
评估指标
我们从真实性和可控性两个方面评估街景生成的效果。真实性主要通过 Fréchet Inception Distance(FID)来衡量,它反映了图像合成的质量。对于可控性,MAGICDRIVE 通过两个感知任务进行评估:BEV 分割和 3D 目标检测,分别使用 CVT(Zhou & Krähembühl, 2022)和 BEVFusion(Liu et al., 2023a)作为感知模型。这两个模型都以其在各自任务中的表现而闻名。首先,我们根据验证集注释生成与之对应的图像,并使用预先在真实数据上训练好的感知模型来评估图像质量和控制精度。然后,基于训练集生成数据,以检验作为数据增强对训练感知模型的支持。
模型设置
我们的 MAGICDRIVE 利用了 Stable Diffusion v1.5 的预训练权重,仅训练新添加的参数。根据 Zhang et al.(2023a),我们为 Emap 创建了一个可训练的 UNet 编码器。除了零初始化模块和类别标记外,所有新参数都是随机初始化的。我们采用了两种分辨率来协调感知任务和基线之间的差异:224×400(0.25× 下采样),遵循 BEVGen 并支持 CVT 模型;以及更高的 272×736(0.5× 下采样),用于支持 BEVFusion。除非另有说明,图像采样使用 UniPC(Zhao et al., 2023)调度器进行 20 步,CFG 为 2.0。
5.2 主要结果
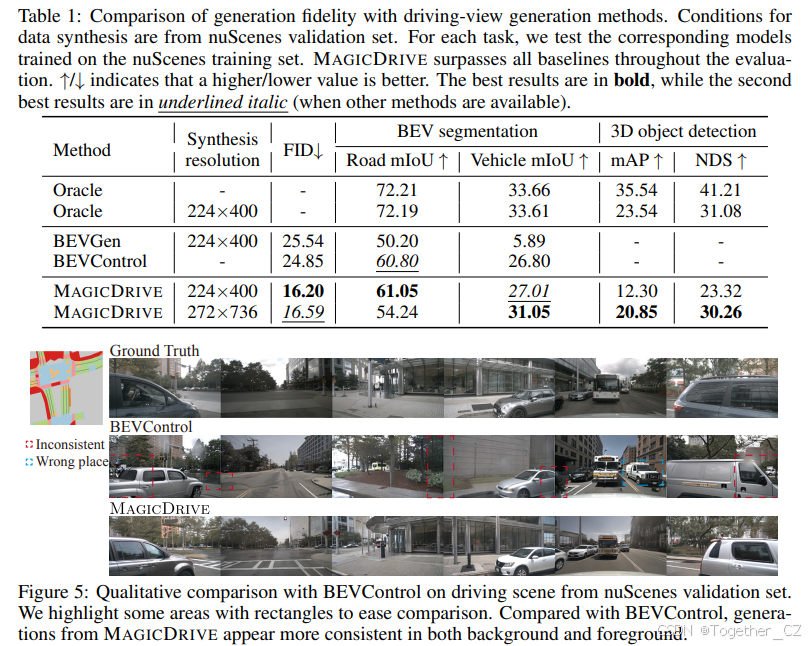
真实性和可控性验证
我们评估了 MAGICDRIVE 根据 nuScenes 验证集注释创建逼真街景图像的能力。如表 1 所示,MAGICDRIVE 在图像质量方面优于其他方法,得出了显著较低的 FID 分数。在可控性方面,通过 BEV 分割任务评估,MAGICDRIVE 在 224×400 分辨率下与基线结果持平或超过基线,这得益于其独特的编码设计,提高了车辆生成的精度。在 272×736 分辨率下,我们对编码策略的改进提高了车辆 mIoU 性能。在 CVT 上裁剪大面积区域对道路 mIoU 产生了负面影响。然而,我们对边界框编码的有效性得到了 BEVFusion 在 3D 目标检测中的结果支持。
为 BEV 分割和 3D 目标检测训练提供支持
MAGICDRIVE 可以产生具有准确注释控制的增强数据,从而增强对感知任务的训练。对于 BEV 分割,我们生成与原始数据集数量相等的图像,确保训练迭代和批量大小保持一致,以便与基线进行公平比较。如表 3 所示,MAGICDRIVE 显著提高了 CVT 在两种设置中的性能,超过了仅略微提高车辆分割性能的 BEVGen。对于 3D 目标检测,我们使用 MAGICDRIVE 的合成数据作为增强来训练 BEVFusion 模型。为了优化数据增强,我们在每个生成场景中随机排除 50% 的边界框。表 2 显示了 MAGICDRIVE 的数据在 CAM 仅(C)和 CAM+LiDAR(C+L)设置中的有利影响。需要注意的是,在 CAM+LiDAR 设置中,BEVFusion 利用两种模态进行目标检测,由于需要结合 LiDAR 数据,因此对图像生成的精度要求更高。尽管如此,MAGICDRIVE 的合成数据与 LiDAR 输入无缝集成,突显了数据的高保真度。

5.3 定性评估
与基线的比较
我们评估了 MAGICDRIVE 与两个基线(BEVGen 和 BEVControl)的性能,为相同的验证场景合成多相机视图(与 BEVGen 的比较在附录 D 中)。图 5 显示,与 BEVControl 相比,MAGICDRIVE 生成的图像质量明显更高,尤其是在准确的目标定位和保持街景背景和目标的一致性方面表现出色。这种性能主要归功于 MAGICDRIVE 的边界框编码器及其跨视图注意力模块。
多级控制
MAGICDRIVE 的设计通过分离编码引入了街景生成的多级控制。本节通过探索三个控制信号级别:场景级别(一天中的时间和天气)、背景级别(BEV 地图更改和条件视图)以及前景级别(目标方向和删除),来展示 MAGICDRIVE 的能力。如图 1、图 6 和附录 E 所示,MAGICDRIVE 熟练地适应了每个级别的更改,同时保持了多相机的一致性和生成的高真实性。
5.4 扩展到视频生成
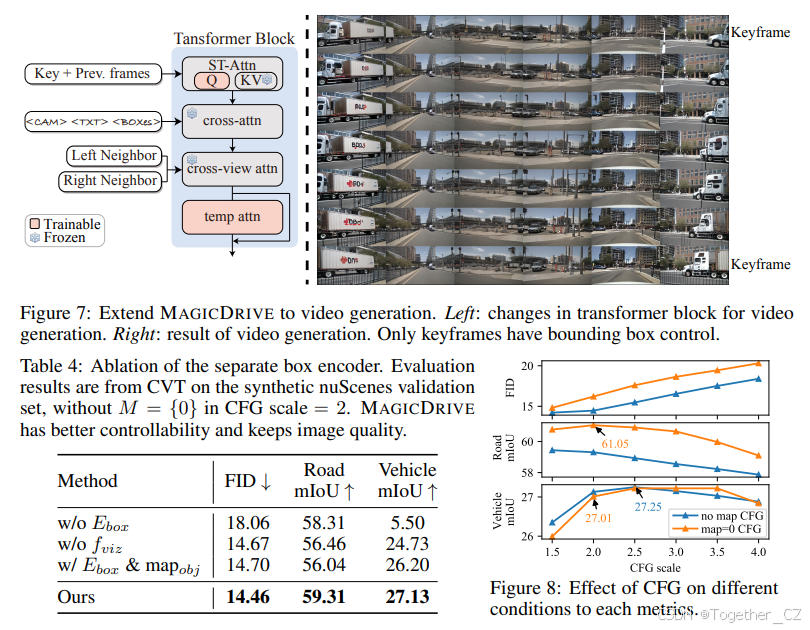
我们通过在 nuScenes 视频上对 MAGICDRIVE 进行微调,展示了其扩展到视频生成的能力。这涉及将自注意力修改为 ST-Attn(Wu et al., 2023a),在每个 Transformer 块中添加一个时间注意力模块(见图 7 左侧),并在 7 帧剪辑上对模型进行调整,其中只有第一帧和最后一帧有边界框。我们使用 UniPC(Zhao et al., 2023)采样器为每帧独立采样初始噪声,进行 20 步采样,并在图 7 右侧展示了一个示例。 此外,通过利用 ASAP(Wang et al., 2023c)的插值注释,类似于 DriveDreamer(Wang et al., 2023b),MAGICDRIVE 可以扩展到 16 帧视频生成,频率为 12Hz,并在 Nvidia V100 GPU 上进行训练。更多结果(例如视频可视化)可以在我们的网站上找到。
6 消融研究
边界框编码
MAGICDRIVE 为边界框和道路地图使用了独立的编码器。为了证明其有效性,我们训练了一个 ControlNet(Zhang et al., 2023a),它将包含道路和目标语义的 BEV 地图作为条件(类似于 BEVGen),在表 4 中记为“w/o Ebox”。由于 BEV 地图中的目标相对较小,因此需要单独的 Ebox 来实现准确的车辆注释,如车辆 mIoU 性能差距所示。应用可见目标过滤器 fviz 显著提高了道路和车辆 mIoU,通过减少优化负担来实现。一个包含 Ebox 和道路目标语义的 BEV 的 MAGICDRIVE 变体并没有提高性能,这强调了通过不同策略整合不同信息的重要性。
分类器自由引导的影响
我们关注两个最重要的条件,即目标边界框和道路地图,并分析 CFG 对生成性能的影响。我们从 1.5 到 4.0 改变 CFG 的规模,并绘制了从 CVT 验证结果的变化图,如图 8 所示。首先,随着 CFG 规模的增加,FID 由于对比度和锐度的显著变化而退化,这在先前的研究(Chen et al., 2023c)中也有观察到。其次,如果在条件和非条件推理中使用相同的地图,则消除了 CFG 对地图条件的影响。如图 8 中的蓝色线所示,随着 CFG 规模的增加,车辆 mIoU 在 CFG=2.5 时达到最高,但道路 mIoU 一直在下降。第三,当在 CFG 中使用 M = {0} 进行非条件推理时,道路 mIoU 显著增加。然而,它略微降低了对车辆生成的指导。如第 4.3 节所述,随着条件数量的增加,CFG 的复杂性也会增加。尽管简化了训练,但在推理过程中存在各种 CFG 选择。我们把深入研究这种情况作为未来的工作。

7 结论
本文介绍了 MAGICDRIVE,这是一个用于高质量多相机街景生成的新型框架,能够对多种几何条件进行编码。通过分离编码设计,MAGICDRIVE 充分利用了 3D 注释中的几何信息,并实现了对街景的准确语义控制。此外,所提出的跨视图注意力模块简单而有效,能够确保多相机视图之间的一致性。实验结果表明,MAGICDRIVE 生成的图像具有高真实性和对 3D 注释的高保真度。MAGICDRIVE 所具备的多种控制使其具有了生成新街景的更强泛化能力。同时,MAGICDRIVE 可以用于数据增强,有助于对 BEV 分割和 3D 目标检测任务的感知模型进行训练。
限制和未来工作
我们在图 9 中展示了 MAGICDRIVE 的失败案例。尽管 MAGICDRIVE 可以生成夜景,但它们并不像真实图像那样黑暗(如图 9a 所示)。这可能是因为扩散模型很难生成太暗的图像(Guttenberg, 2023)。图 9b 显示,MAGICDRIVE 无法为 nuScenes 生成未见过的天气。未来的工作可能会专注于如何提高街景生成的跨域泛化能力。
8 致谢
本研究由香港研究资助局(RGC)的 General Research Fund(GRF)资助,资助号为 14203521;由香港中文大学 SSFCRS 资助,资助号为 3136023;以及由 Research Matching Grant Scheme 资助,资助号为 7106937、8601130 和 8601440。我们衷心感谢 MindSpore、CANN(计算架构神经网络)和 Ascend AI 处理器为本研究提供的支持。本研究还得到了香港研究资助局通过研究影响力基金项目 R6003-21 提供的资金支持。


