Gartner《Operationalizing Big Data Workloads》学习笔记
概述
随着大数据的分析工作负载变得日益复杂,技术专业人员必须采用DevOps和DataOps实践来构建端到端、自动化的、可扩展的数据管道。本研究提供了一系列指导,帮助克服在构建流处理和批处理数据平台时所面临的挑战。
问题陈述
现代数据平台面临诸多挑战:
-
缺乏单一产品或框架,导致组织不得不拼凑不同的产品和框架来构建解决方案。
-
大数据生态系统迅猛发展,工具、框架、库和产品众多,选择困难。
-
分布式架构的复杂性使得构建可靠、自动化、健壮的端到端数据管道变得困难。
-
数据湖变成数据沼泽,数据难以消化。
-
大数据项目失败率高,仅有17%的Apache Hadoop部署投入生产。
-
Gartner方法论
Gartner方法论为解决大数据项目中的复杂性和挑战提供了一个结构化的框架。
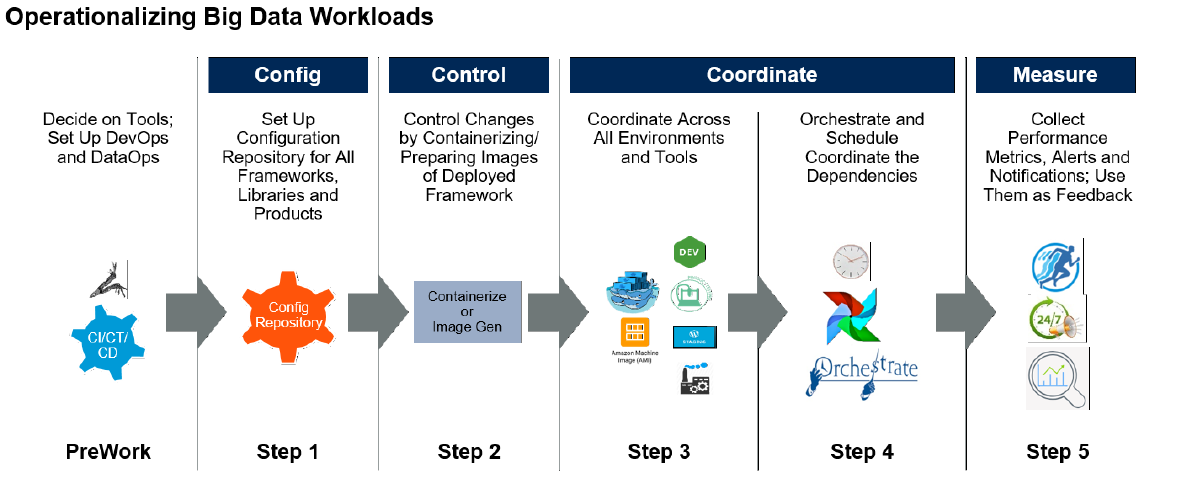 以下是对其核心组成部分的深入探讨:
以下是对其核心组成部分的深入探讨:
三个C的原则(配置、控制和协调)
-
配置(Configure)
-
配置驱动的设计:在大数据项目中,配置管理是实现系统可维护性和可扩展性的关键。配置驱动的设计意味着将系统的所有配置参数化,使得系统能够在不同环境中快速部署和调整。例如,在开发、测试和生产环境中,大数据框架如Apache Spark可能需要不同的配置参数(如内存分配、执行器数量等)。通过将这些配置集中管理在一个配置仓库中,可以确保每个环境的一致性和可重复性。
-
配置仓库的建立:配置仓库不仅是存储配置文件的地方,还需要具备版本控制和审计功能。这允许团队成员查看配置的历史变更记录,回滚到之前的稳定版本,并确保配置的透明性和可追溯性。工具如Puppet、Chef和Ansible可以帮助自动化配置管理过程,确保配置的一致性和准确性。
-
-
控制(Control)
-
控制技术变动:大数据生态系统中的技术栈不断演变,新的框架和工具层出不穷。为了应对这种变化,组织需要建立严格控制的开发和执行环境。通过容器化技术(如Docker),可以将应用程序及其依赖打包成一个可移植的容器,确保在不同环境中的行为一致。这减少了因环境差异导致的错误和故障,提高了系统的稳定性和可靠性。
-
管理各种漂移现象:在大数据环境中,代码漂移、配置漂移、基础设施漂移等都是常见的问题。例如,当团队成员对代码进行修改时,如果没有有效的版本控制和代码审查流程,可能会导致代码漂移。同样,配置漂移可能发生在不同的部署环境中,导致系统行为不一致。通过自动化工具和流程,可以监控和控制这些漂移现象,确保系统的稳定性和一致性。
-
-
协调(Coordinate)
-
跨组件协调:大数据解决方案通常由多个组件组成,如数据摄取、存储、处理和分析等。这些组件之间的协调和通信至关重要。通过编排工具(如Apache Ai
-

