视觉学习yolo+OpenCV(电赛准备)
YOLO(You Only Look Once)是一种实时目标检测系统,它是一种基于深度学习的目标检测算法,具有速度快、易于集成和部署、对小目标检测效果好等优点。
一、yolo和opencv的安装
打开anaconda,切换到自己所需要的环境,然后输入下面的代码就能够安装了
pip install ultralytics opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple二、修改yolo环境配置
笔者不喜欢很多东西都塞到C盘,所以一开始就修改了部分的默认设置,不过不知道后面会不会有啥影响,但是目前为止,暂时没有啥影响。
使用Python 通过导入 settings 对象的 ultralytics 模块。使用这些命令打印和返回设置:
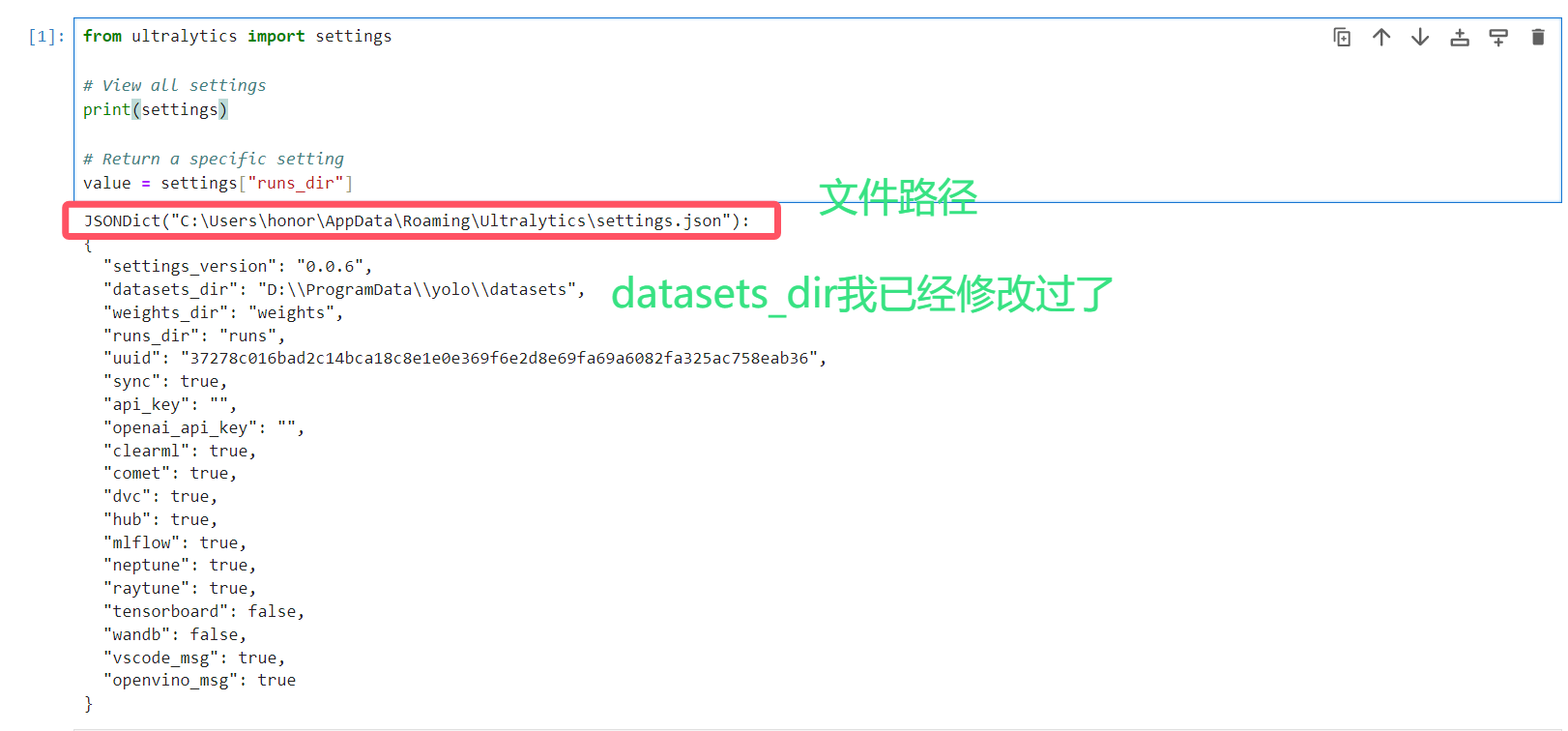
from ultralytics import settings# View all settingsprint(settings)# Return a specific settingvalue = settings[\"runs_dir\"]返回如下:
下表是关于参数的介绍
settings_version\'0.0.6\'strdatasets_dir\'/path/to/datasets\'strweights_dir\'/path/to/weights\'strruns_dir\'/path/to/runs\'struuid\'a1b2c3d4\'strsyncTrueboolapi_key\'\'strclearmlTrueboolcometTruebooldvcTrueboolhubTrueboolmlflowTrueboolneptuneTrueboolraytuneTruebooltensorboardTrueboolwandbTrueboolvscode_msgTruebool需要修改可以在json文件直接修改或者python输入以下代码
from ultralytics import settings# Update a settingsettings.update({\"runs_dir\": \"/path/to/runs\"})# Update multiple settings#settings.update({\"runs_dir\": \"/path/to/runs\", \"tensorboard\": False})# Reset settings to default values#settings.reset()三、yolo部分python的快速使用
1、加载预训练模型进行照片和视频流的预测
首次运行自动下载,也可以看官方文档用v11,这里作者后面想移植到树莓派上结合opencv。
from ultralytics import YOLO#首次运行自动下载,也可以看官方文档用v11,这里主包后面想移植到树莓派a1 = YOLO(\'yolov5n.pt\')
之后作者随便找了一张图片

这个也是官方教程里下载下来的图片,然后运行下面的代码
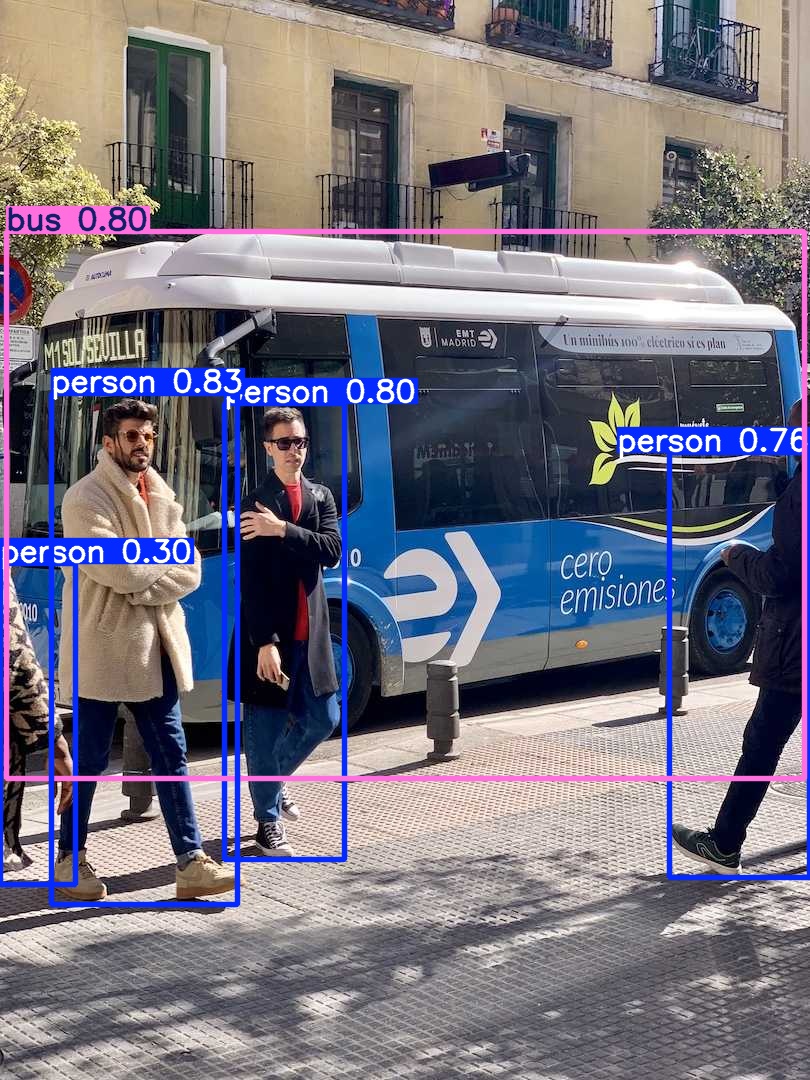
model(\'bus.jpg\',show=True,save=True)之后这个预测的图片就会保存到你的run下的文件夹

预测的效果如下:
接下来做的是视频流的追踪,不过作者忘记下载视频,就附上一段爬虫代码下载b站上的视频,爬取汽车流的代码如下:
#b站爬取代码# 导入数据请求模块import requests# 导入正则表达式模块import re# 导入json模块import json# TODO 记得更改你要的url和你自己的cookieurl = \'https://www.bilibili.com/video/BV1uS4y1v7qN/?spm_id_from=333.337.search-card.all.click&vd_source=f4f695a55bf2a7e583ebd8706d656a4f\'cookie = \"buvid3=2844B77E-F527-FB05-1DF5-9FDF834AE3E888277infoc; b_nut=1709986388; i-wanna-go-back=-1; b_ut=7; _uuid=6577D687-BED9-9AE2-106A10-551210627F5AC88087infoc; enable_web_push=DISABLE; buvid4=5ED5B3A0-A998-7D47-3815-9AD9A1B27A4989131-024030912-0Fw3r6dKwZLwPoWOl%2F8HuA%3D%3D; CURRENT_FNVAL=4048; rpdid=|(u|Jmkkuukk0J\'u~u|ulR~)~; header_theme_version=CLOSE; fingerprint=c27c0b59dd10dcdc4c14701a58f49669; buvid_fp_plain=undefined; buvid_fp=c27c0b59dd10dcdc4c14701a58f49669; LIVE_BUVID=AUTO6217111182462626; FEED_LIVE_VERSION=V_WATCHLATER_PIP_WINDOW3; bp_video_offset_691902317=925084214145056785; DedeUserID=691902317; DedeUserID__ckMd5=ead312019baad7ed; CURRENT_QUALITY=80; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MTYwNDM3MDgsImlhdCI6MTcxNTc4NDQ0OCwicGx0IjotMX0.Rdjc9F5oiEXSn_GylRWm3s2L-Pn8GYfyQS5IZt_Y3-8; bili_ticket_expires=1716043648; SESSDATA=3d6f944f%2C1731336513%2C491d2%2A51CjD5jp6zedAz4nQallTN_akUjFzg2LzJhdKMiJbI1nnw2bs5sp8Y09F7Jj4PofjUyfsSVlktMkF0aDRLN196dVNTeWh0czllbFZTWDlidWRpcnFnaENSNVVNbGNFMGR5bFBqYkcwalhuVklyUGJLVHJtYXo3TVpaTENqQ21rS0RPbldWTDUzRFp3IIEC; bili_jct=2975523315e5bccfa606ac286df61f36; home_feed_column=4; browser_resolution=1396-639; sid=6gr3y4l0; PVID=4; bp_t_offset_691902317=932475264446758937; b_lsid=5E9C415B_18F86EC150D\"headers = { # Referer 防盗链 告诉服务器你请求链接是从哪里跳转过来的 # \"Referer\": \"https://www.bilibili.com/video/BV1454y187Er/\", \"Referer\": url, # User-Agent 用户代理, 表示浏览器/设备基本身份信息 \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36\", \"Cookie\": cookie}# 发送请求response = requests.get(url=url, headers=headers)html = response.text# 解析数据: 提取视频标题title = re.findall(\'title=\"(.*?)\"\', html)[0]print(title)# 提取视频信息info = re.findall(\'window.__playinfo__=(.*?)\', html)[0]# info -> json字符串转成json字典json_data = json.loads(info)# 提取视频链接video_url = json_data[\'data\'][\'dash\'][\'video\'][0][\'baseUrl\']print(video_url)video_content = requests.get(url=video_url, headers=headers).content# 保存数据with open(title + \'.mp4\', mode=\'wb\') as v: v.write(video_content)爬取完视频后,再进行检测

进行检测,之后再进行识别
model(\'车辆检测和交通流量测试视频.mp4\',show=True,save=True)
2、构建自己的数据集并训练
接下来,做完基础的trace任务,开始训练自己的模型。
首先在自己的项目下创建文件夹如下:
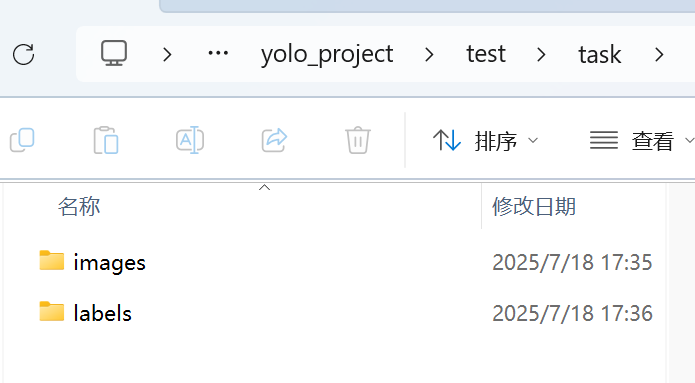
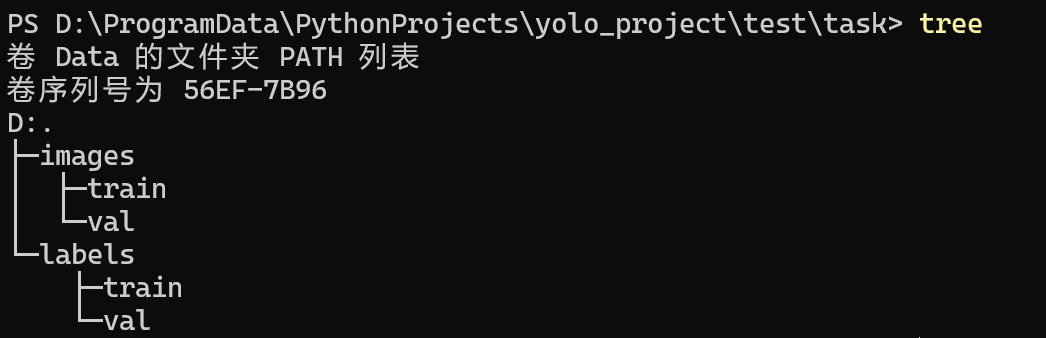
同时我的py文件与task是同一个层级的
接下来先给大家介绍一下几个常见的标注工具
- label studio:这是一款灵活的工具,支持多种标注任务,并具有管理项目和质量控制功能。
- CVAT:功能强大的工具,支持各种注释格式和可定制的工作流程,适用于复杂的项目。
- labelme:这是一款简单易用的工具,可使用多边形快速标注图像,非常适合完成简单的任务。
- labelImg:易于使用的图形图像注释工具,尤其适合创建YOLO 格式的边界框注释。
这里作者最后使用了labelme这个工具进行数据标注(你可以直接点击上面的访问GitHub链接,查看如何下载)
作者这里是用pip下载的,但是由于自己电脑是win系统,所以可能只安装pyqt5不够的,还得多安装一个PyQt5-tools才能打开GUI
pip install labelme PyQt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple如果还有啥其他的问题,读者可以留言或者自己debug,毕竟作者也是边学边记录。安装好后,也是如愿打开了GUI界面
之后作者决定抓取chiikawa的图片和视频进行训练。
这里先列一下labelme的一些指令参数(ps:可以用labelme -h查看),直接终端打labelme再选择文件也问题不大。
filename--output/-O/-o--labels--flags--labelflags--nodata--autosave--keep-prev--nosortlabels--validatelabel exact--epsilon--logger-level--logger-level debug--reset-config--version/-V常见组合示例如下:
# 1) 单张图片,预设标签,结果保存同级目录labelme cat.jpg --labels \"cat,eye,nose\" --output cat.json --autosave# 2) 批量图片,预定义标签集文件,统一输出目录labelme imgs/ -o labels/ --labels mylabels.txt --nodata --autosave# 3) 视频帧继承标注,带复选属性labelme frames/ --labels person.txt --flags occluded,truncated --keep-prev之后将labelme的标注保存在label文件下,并且需要把json文件格式转化成txt文件格式。
先在anaconda prompt环境下输入
pip install labelme2yolo -i https://pypi.tuna.tsinghua.edu.cn/simple之后输入
labelme2yolo --json_dir labels/train --output_format bboxlabelme2yolo --json_dir labels/val --output_format bbox脚本会在原目录旁自动生成 YOLODataset/labels/train|val/*.txt,再把生成的 txt 拷回 labels/train 和 labels/val 即可训练
准备好数据集。
接下来创建一个yaml格式的文件
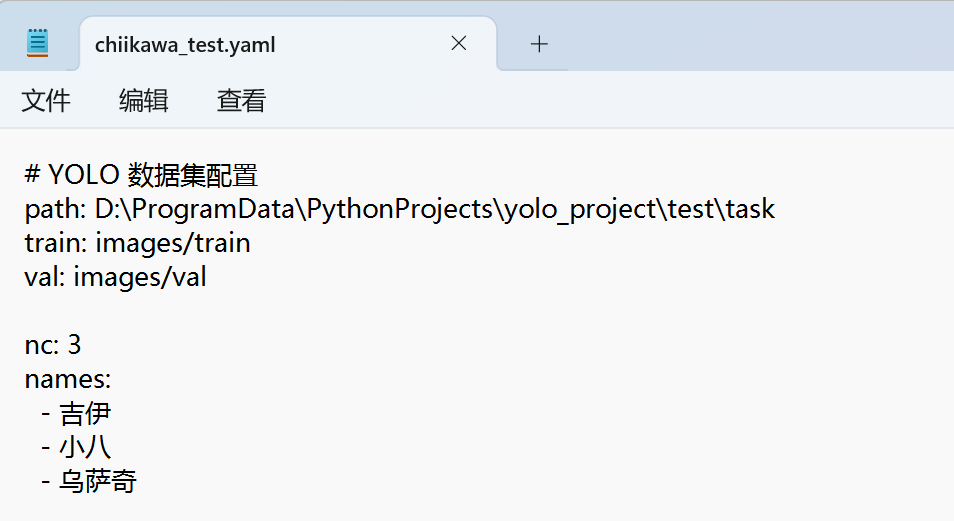
之后输入以下代码:
from ultralytics import YOLOmodel = YOLO(\'yolov5nu.pt\')model.train( data = \'chiikawa_test.yaml\', #数据集配置文件路径 epochs = 100, #训练轮次 imgsz=640, #官方推荐640 batch=16, #每次训练的批量)就可以开始训练了,不过应该还是gpu训练比较快,建议自己的电脑上训练完模型,把模型拷到树莓派玩。
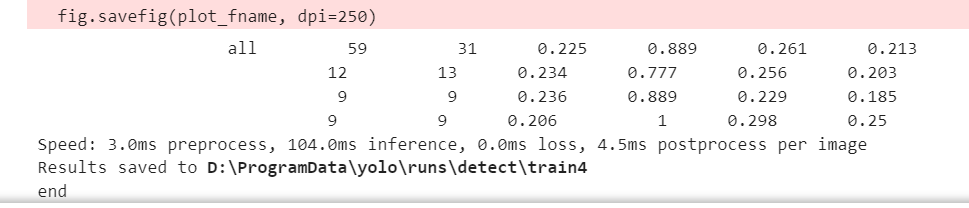
作者的训练效果不大好,还需要调参一下,但是一个是数据集只有50个,另一个是我训练集和验证集都是一起的,还有标注可能不大行,还是得调参。
但是最后文件保存在train4文件夹下,看看有什么东西。

有一些曲线图,还有相关的权重文件,接下来,我们使用权重文件进行检测。
chiikawa_model = YOLO(r\'D:\\ProgramData\\yolo\\runs\\detect\\train4\\weights\\best.pt\')chiikawa_model(\'小八ai还原Chiikawa259话.mp4\',show = True,save=True)最后识别出来的效果如下:

四、OpenCV快速应用
首先的话先补充一部分摄像头前端参数的知识,之后的OpenCV大部分是进行前端处理的作用。
背光补偿:也称为逆光补偿,是早期应对强光或强逆光视频监控环境的方法
如果一个场景既有非常明亮的物体,也有非常黑暗的物体,亮度跨度很大,我们就称之为“高动态范围 High Dynamic Range(HDR)”场景。
下面的是一些之前为了准备电赛的代码:
1、色域追踪
通过鼠标GUI的点击,从而获取点击位置hsv属性。
import numpy as npimport cv2 as cv#鼠标寻找色域函数def nothing(x): passdef show_hsv(event,x,y,flags,param): global ix, iy, drawing,mode if event == cv.EVENT_LBUTTONDOWN: ix,iy = x,y elif event ==cv.EVENT_LBUTTONUP: pixel_hsv = hsv[y, x] # 打印HSV值 print(f\"HSV pixel value at ({x}, {y}): Hue={pixel_hsv[0]}, Saturation={pixel_hsv[1]}, Value={pixel_hsv[2]}\") #print(type(pixel_hsv),pixel_hsv)# 创建一个VideoCapture对象cap = cv.VideoCapture(0)print(cap.get(cv.CAP_PROP_FRAME_WIDTH),cap.get(cv.CAP_PROP_FRAME_HEIGHT))while(True): ret, frame = cap.read() cv.namedWindow(\'image\') hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV) cv.imshow(\'image\',frame) #设置鼠标状态 cv.setMouseCallback(\'image\',show_hsv) #按q推出 if cv.waitKey(1) & 0xFF ==ord(\'q\'): break #释放VideoCapture对象cap.release()cv.destroyAllWindows()通过鼠标GUI的点击,从而获取点击位置bgr属性。
import numpy as npimport cv2 as cv# 鼠标寻找色域函数def nothing(x): passdef show_bgr(event, x, y, flags, param): global ix, iy, drawing, mode if event == cv.EVENT_LBUTTONDOWN: ix, iy = x, y elif event == cv.EVENT_LBUTTONUP: bgr_pixel = frame[y, x] # 获取BGR像素值 # 打印BGR值 print(f\"BGR pixel value at ({x}, {y}): Blue={bgr_pixel[0]}, Green={bgr_pixel[1]}, Red={bgr_pixel[2]}\")# 创建一个VideoCapture对象cap = cv.VideoCapture(0)print(cap.get(cv.CAP_PROP_FRAME_WIDTH), cap.get(cv.CAP_PROP_FRAME_HEIGHT))while (True): ret, frame = cap.read() if not ret: break cv.namedWindow(\'image\') hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV) # 转换为HSV空间,虽然我们不需要显示它 cv.imshow(\'image\', frame) # 显示BGR图像 # 设置鼠标状态 cv.setMouseCallback(\'image\', show_bgr) # 按 \'q\' 退出 if cv.waitKey(1) & 0xFF == ord(\'q\'): break# 释放VideoCapture对象cap.release()cv.destroyAllWindows()2、设置ROI
通过顺时针点击一个矩形的四个角确定ROI的大小
import cv2 as cvimport numpy as np# 初始化点的列表points = []# 定义鼠标回调函数def set_ROI(event, x, y, flags, param): global points if event == cv.EVENT_LBUTTONDOWN and len(points)<=4: points.append((x, y))# 读取视频cap = cv.VideoCapture(0)while True: # 读取视频帧 ret, frame = cap.read() if not ret: break # 显示视频帧 img = frame.copy() if len(points)==4: cv.imshow(\'Video\',img[points[0][0]:points[2][0],points[0][1]:points[2][1]]) if len(points)!=4: cv.imshow(\'Video\', img) # 鼠标回调函数 #顺时针设置ROI cv.setMouseCallback(\'Video\', set_ROI) # 等待按键,退出循环 k = cv.waitKey(1) & 0xFF if k == 27: # 按下ESC键退出 break# 释放视频捕获对象cap.release()cv.destroyAllWindows()五、OpenCV视频流显示yolo检测的操作
原本想介绍一点opencv的知识,但是后面想了想,还是由读者自己去学习(如果有需要或者重新温习的话,还会更新这部分),可以看这个网址的知识https://apachecn.github.io/opencv-doc-zh/#/去学习
import cv2from ultralytics import YOLO# 加载 YOLOv8 模型model = YOLO(\"yolov8n.pt\")# 打开视频文件# cap = cv2.VideoCapture(\"path/to/your/video/file.mp4\")# 或使用设备“0”打开视频捕获设备读取帧cap = cv2.VideoCapture(0)# 设置视频帧大小cap.set(cv2.CAP_PROP_FRAME_WIDTH, 200)cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 200)title = \"YOLOv8 Inference\"# 设置窗口位置cv2.namedWindow(title, cv2.WINDOW_NORMAL)cv2.moveWindow(title, 200, 200)# 循环播放视频帧while cap.isOpened(): # 从视频中读取一帧 success, frame = cap.read() if success: # 在框架上运行 YOLOv8 推理 results = model(frame) # 在框架上可视化结果 annotated_frame = results[0].plot() # 显示带标注的框架 cv2.imshow(title, annotated_frame) # 如果按下“q”,则中断循环 if cv2.waitKey(1) & 0xFF == ord(\"q\"): break else: # 如果到达视频末尾,则中断循环 break# 释放视频捕获对象并关闭显示窗口cap.release()cv2.destroyAllWindows()后续接下来做电赛的识别激光的训练,用树莓派试试
参考链接:
yolo文档
https://zhuanlan.zhihu.com/p/371756150
Labelme json文件转换为yolo标签格式文件_lableme json转yolo格式-CSDN博客
使用 OpenCV 和 YOLO 模型进行实时目标检测并在视频流中显示检测结果_yolo实时视频流检测-CSDN博客
海康培训--基础技术课程前端-摄像机常见参数解读_哔哩哔哩_bilibili
OpenCV中文文档

