基于YOLOv11算法的无人机影像小目标检测CF-YOLO
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
https://www.nature.com/articles/s41598-025-99634-0
计算机视觉研究院专栏
Column of Computer Vision Institute
从无人机视角捕获的图像中,目标尺度差异显著且存在大量缺乏细节信息的小目标物体,这对目标检测算法的性能产生了显著影响。

PART/1
概述
针对小目标检测的挑战,本文提出了一种基于YOLOv11模型的遥感小目标检测器(CF-YOLO)。首先,针对分层卷积结构可能导致的小目标信息丢失问题,我们对路径聚合网络(PAN)进行了深入研究,并创新性地提出了跨尺度特征金字塔网络(CS-FPN)。其次,为解决多尺度特征融合过程中位置信息偏差和特征冗余的问题,我们设计了特征重校准模块(FRM)和三明治融合模块。我们主张通过FRM模块进行初始特征融合,然后利用三明治模块进行特征增强。最后,我们使用RFAConv模块和LSDECD检测头对模型进行了优化和重构。实验表明,在公开的VisDrone数据集、TinyPerson数据集和HIT-UAV数据集上,CF-YOLO相较于基线模型,mAP50分别提升了12.7%、10.1%和3.5%。与其他方法相比,CF-YOLO表现出更优越的性能。
PART/2
背景
无人机技术的快速发展正在深刻改变传统遥感监测的范式。凭借灵活性、低成本和抗云层干扰等优势,无人机航拍图像已广泛应用于安全监控、智能交通、农业管理等地方,成为卫星遥感的重要补充。在计算机视觉领域,尽管深度学习驱动的遥感目标检测技术在交通监控、灾害响应和军事行动等应用中取得了显著进展,但无人机航拍图像中的目标检测仍面临诸多挑战。首先,由于典型成像高度在100至500米范围内,图像中约60%-80%的目标尺寸小于32×32像素。这些小目标通常特征信息有限、对比度低且有效特征点稀疏——约70%的小目标仅包含10-20个有效特征点。其次,成像条件复杂且多变,平台运动、光照变化和复杂背景等因素会导致目标与背景的混叠,增加了小目标的区分难度。最后,随着相机带宽和分辨率的持续提升,管理和处理从无人机传输至地面的海量数据也成为一项重大挑战。
因此,在保持检测速度的同时实现快速且准确的小目标检测具有重要的理论意义和实用价值。近年来,针对小目标检测的挑战,研究人员提出了多种解决方案。Crowd-SAM是基于分割一切模型(SAM)构建的增强框架,通过优化提示生成和掩码选择来提升拥挤场景下的目标检测性能。GAN-STD利用生成对抗网络(GAN)在特征提取过程中增强小目标与大目标的相似表示,使小目标能够像大目标一样易于检测。MENet引入了基于中心的标签分配策略,为极小目标提供了更多正样本。Li等人采用Transformer来捕获与目标相关的长距离全局依赖关系,从而提升模型的全局感知能力。YOLOv8-QSD从多尺度融合的角度改善了小目标的检测性能。尽管这些方法在小目标检测方面取得了显著进展,但它们仍然面临着小目标信息丢失以及多尺度信息潜力未被充分挖掘等问题。

因此,本研究不同于上述工作,专注于解决小目标检测中的特征信息丢失问题,并系统探索多尺度特征融合的优化潜力。为此,我们提出了CF-YOLO——一种高分辨率遥感目标检测方法,旨在构建高效且精准的检测器。该方法的主要创新体现在以下四个方面:
第一,为缓解遥感影像中小目标特征传输过程中常见的信息衰减问题,我们引入了跨尺度特征金字塔网络(CS-FPN)。该结构建立了跨分辨率的特征交互路径,在高分辨率层级保留细粒度的目标特征,同时通过多尺度深度架构确保检测精度。
第二,为提升多尺度特征融合的效率,我们提出了双模块协同机制。特征重校准模块(FRM)提取并整合边界敏感特征与纹理特征,实现精准的空间对齐;而三明治融合模块采用自适应加权策略,有效解决浅层网络语义不足与深层网络细节丢失的矛盾。
第三,考虑到无人机影像中严重的背景干扰和稀疏的小目标特征带来的挑战,我们将感受野注意力卷积(RFAConv)集成到主干网络中。该模块动态分配感受野权重,使模型在复杂光照条件和多变场景环境下保持稳定性能。
第四,为克服YOLOv11检测头中信息交互不足的局限,我们引入了轻量级空间-深度增强交叉检测头(LSDECD)。该结构通过跨层级特征聚合机制,同步优化空间定位精度和语义表征能力。本研究的主要贡献如下:
l我们提出CS-FPN以有效缓解深度网络中的特征衰减问题,为小目标检测保留关键信息。
l为增强模型的全局感知能力并突出感受野内不同特征的重要性,本研究引入感受野注意力卷积(RFAConv)模块对主干网络进行重构。
l通过将感受野注意力卷积(RFAConv)集成到主干网络中,我们在提升模型全局感知能力的同时,有效凸显了感受野内不同特征的重要性。
通过引入LSDECD检测头——该结构聚合跨层级的空间与语义特征——我们缓解了YOLOv11检测头中信息交互不足的局限,从而提升了检测精度。
小目标检测
无人机航拍图像中的目标检测属于典型的小目标检测任务,具有小目标占比高、分布密集的特点。YOLO框架因能在实时应用中有效平衡精度与效率而被广泛使用。部分研究者将Transformer与YOLO结合,旨在增强网络捕获更广泛信息性和多样性特征的能力。与原始基线相比,这些方法提升了模型建立长距离依赖关系的能力,在精度上表现出优势。FFCA-YOLO提出了一种新型的上下文感知检测器用于遥感图像检测,增强了模型感知上下文信息的能力。SFFEF-YOLO引入细粒度信息提取模块替代标准卷积,减少了采样过程中的信息丢失。Li等人通过引入Bi-PAN-FPN概念改进YOLOv8-s的颈部结构,解决了航拍图像中小目标常见的误检和漏检问题,实现了更先进的特征融合。FENet在FPN中嵌入高分辨率块以保留小目标的细节特征,YOLO-SSFS改进BiFPN以集成更多浅层信息。DSP-YOLO提出用于小目标检测的轻量级细节敏感型PAN(DsPAN)。SOD-YOLO引入平衡空间与语义信息融合的金字塔网络(BSSI-FPN),而EL-YOLO提出稀疏连接渐近特征金字塔网络(SCAFPN)以消除特征融合过程中的层间干扰,提升模型性能。尽管这些方法在小目标检测中取得了显著成果,但未进一步探索多尺度信息。当面对包含复杂背景的特征图时,这些方法仍可能存在精度和鲁棒性问题。
PART/3
新算法框架解析
YOLOv11模型概述
Ultralytics团队提出的YOLOv11目标检测模型采用典型的三阶段架构,其基础组件包括主干网络、颈部网络和检测头。该模型引入了多项创新特性:C3k2卷积模块、空间金字塔池化(SPPF)结构,以及带有并行空间注意力机制的C2PSA模块,显著提升了特征提取性能。为满足不同应用场景的需求,YOLOv11已发布多个版本,包括YOLOv11n、YOLOv11s、YOLOv11m、YOLOv11l和YOLOv11x,各版本在模型深度和通道维度上呈梯度配置。
CF-YOLO模型概述
为解决YOLOv11在遥感小目标检测中存在的特征信息丢失和多尺度融合不足的问题,本研究提出CF-YOLO——一种基于YOLOv11n架构的遥感小目标检测增强算法。
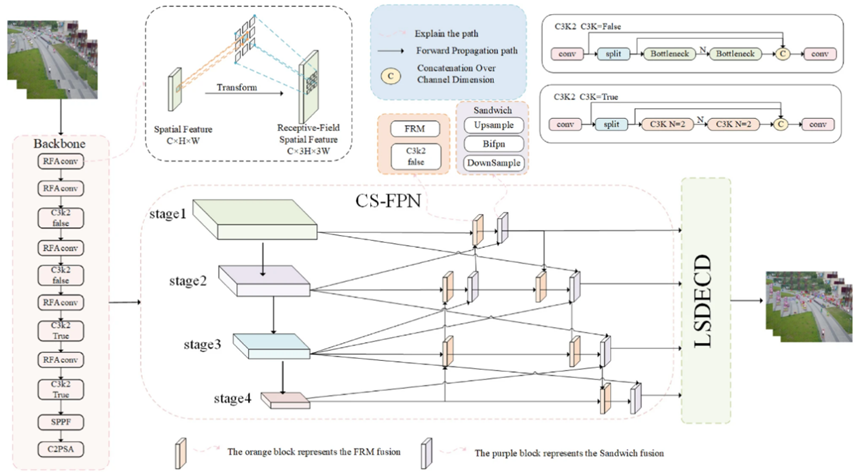
CF-YOLO的整体结构如上图所示,主要由以下三个模块组成:(1)具有感受野自适应注意力机制的主干网络,负责多级特征提取;(2)跨尺度特征金字塔(CS-FPN)和双模块协同特征融合策略,实现特征融合与增强;(3)轻量级检测头(LSDECD),用于最终的目标预测。具体而言,CF-YOLO的主干网络采用分层特征提取架构。首先,使用感受野注意力卷积(RFAConv)对640×640的输入图像进行多阶段下采样,生成分辨率递减、通道数递增的特征图。随后,C3K2模块通过并行卷积层逐步提取特征,捕获图像中的局部细节。深层特征图经SPPF模块进行串行多尺度池化,并通过C2PSA双注意力机制与全局上下文信息融合。最终,网络输出四个不同尺度的特征图,传递至CS-FPN进行跨尺度特征融合。
接下来,主干网络输出的四个不同尺度特征图进入CS-FPN,采用双向(自下而上+自上而下)跨尺度协同融合策略。首先通过特征重校准模块(FRM)进行空间位置校准,随后进行三明治融合操作,实现语义信息与细粒度细节的自适应集成。最终,多阶段融合的特征图被送入LSDECD检测头,在空间和通道维度上协同优化特征表征,生成精准的目标检测输出。
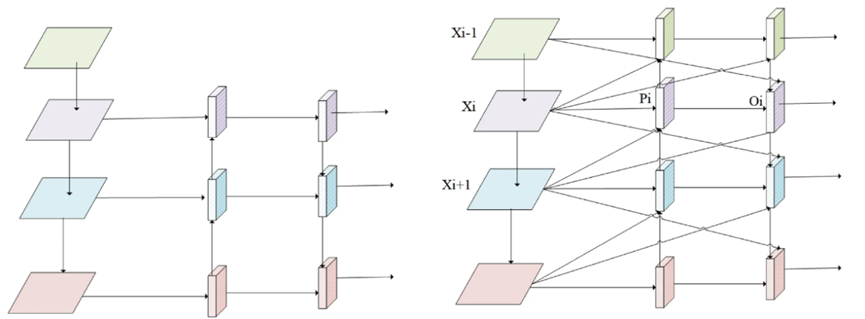
CS-FPN研究动机:如上图a所示,传统PANet采用分步融合策略,将来自FPN的深层语义特征与浅层细节特征相结合。然而,这种架构在多次上采样和下采样过程中会导致显著的细粒度信息丢失,这对小目标检测尤为关键。我们认为,有效信息必须满足两个基本条件:(1)必须包含高级语义信息以确保分类准确性;(2)必须保留足够的空间细节以保证定位精度。现有研究表明,尽管深度网络可以提取丰富的语义特征,但不可避免地会遭受空间分辨率的损失。为解决这一问题,受密集嵌套注意力机制的启发,本研究引入了跨尺度特征金字塔网络(CS-FPN),如上图b所示。
我们对深层特征进行上采样,并逐步将其融合到浅层特征中,以增强浅层特征的目标定位能力。其次,考虑到PAN网络在自上而下和自下而上的特征提取过程中频繁使用卷积和上采样/下采样操作,这不可避免地会导致不同尺度信息的丢失或退化。根据奈奎斯特-香农采样定理,当信号频率超过奈奎斯特频率(即采样率的一半)时,这些高频信息在降采样过程中会永久丢失。
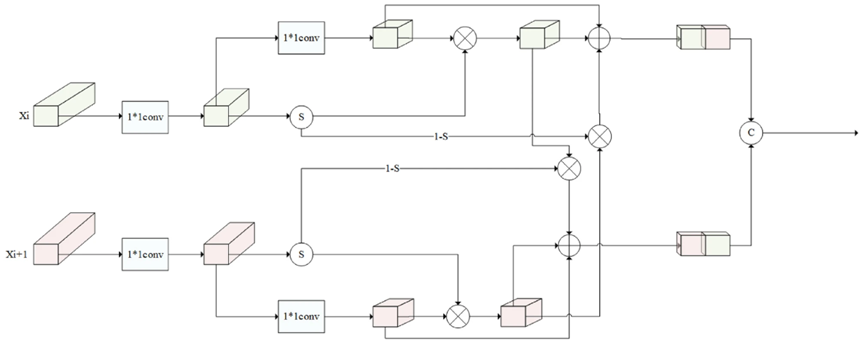
如上图b所示,为缓解多次卷积后特征层中的信息衰减和丢失,我们对骨干网络输出的特征(stage1至stage3)进行下采样,并将其与语义丰富的特征融合。在此过程中,不仅保留了自身特征,还融入了相邻层的跨尺度特征。然而,由于不同的输入特征对网络的贡献不同,我们使用三明治融合模块对每个特征分支进行加权融合,使模型能够根据特征的重要性自主选择,并有效整合上下文信息。此外,考虑到特征图越大,包含的小目标信息越丰富,我们专门添加了一个小目标检测头,将原来的3个检测头扩展到4个,以进一步提高检测性能。
LSDECD
在YOLOv11中,每个检测头都有独立的特征输入。这种设计缺乏检测头之间的信息交互,可能导致检测性能下降。为解决该问题,我们引入了轻量级高效检测头——LSDECD,以提升检测效率。LSDECD的结构如下图所示。
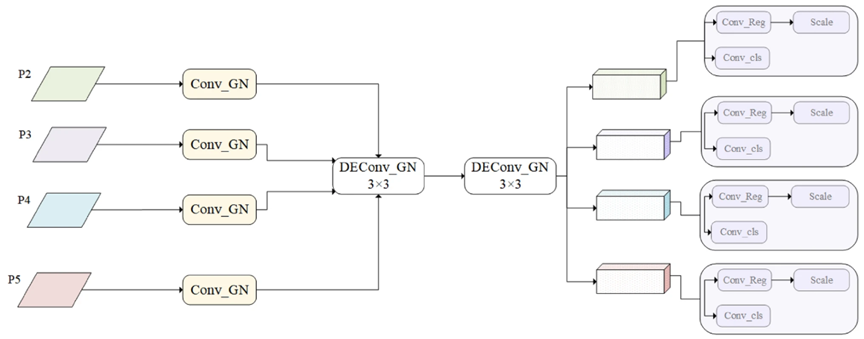
LSDECD
它将来自第P2层到第P5层的特征输入检测头。首先,基于组归一化(GN)通过1×1卷积调整通道数。然后,使用基于组归一化的细节增强卷积(DEConv)来聚合跨层级的空间和语义信息。DEConv53通过中心差分卷积、角度差分卷积、水平差分卷积和垂直差分卷积,将传统局部描述符融入卷积层,从而增强表征与泛化能力,确保检测精度。最后,共享卷积提取的信息被送入分类头和回归头。为处理检测头之间目标尺寸不一致的问题,并避免小目标特征信息丢失,我们采用包含可学习缩放因子的缩放层。该层对回归头中的特征进行调整,进而增强多尺度特征的保留能力。
PART/4
新算法框架解析
VisDrone数据集是从无人机视角专门设计的高质量目标检测数据集。它包含6,471张训练图像、3,190张测试图像和548张验证图像。
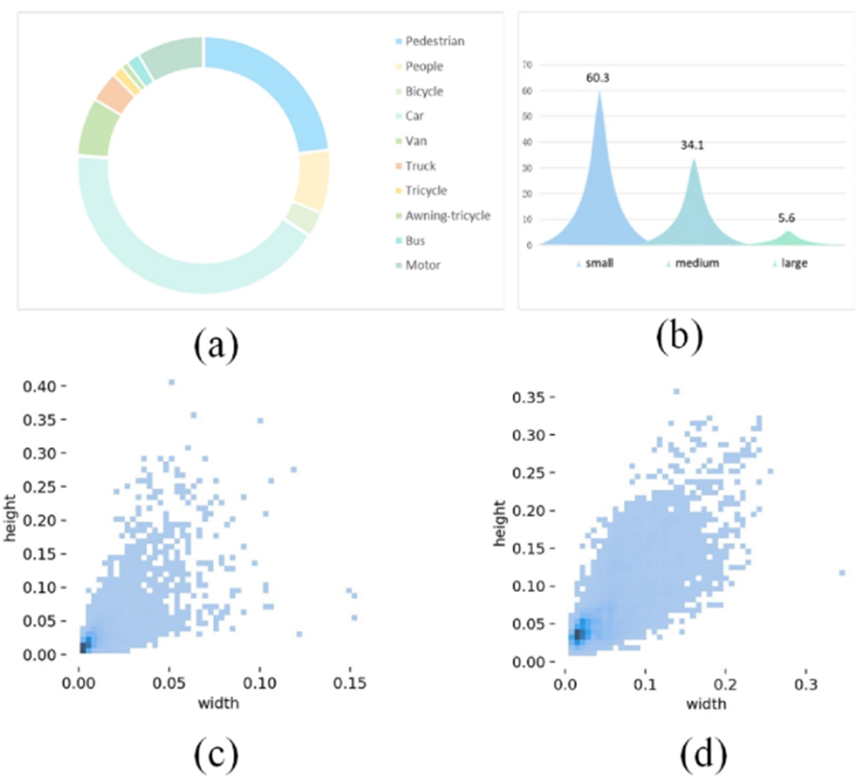
各类别的数据分布如上图a所示,包含行人、汽车、自行车和三轮车等10个类别。上图b展示了数据集中目标尺寸的分布情况,约60%的目标尺寸小于20×20像素,近90%的目标被归类为小目标(尺寸≤32×32像素)。由于其多样性和对小目标检测的关注,该数据集是复杂场景下目标检测研究的理想选择。

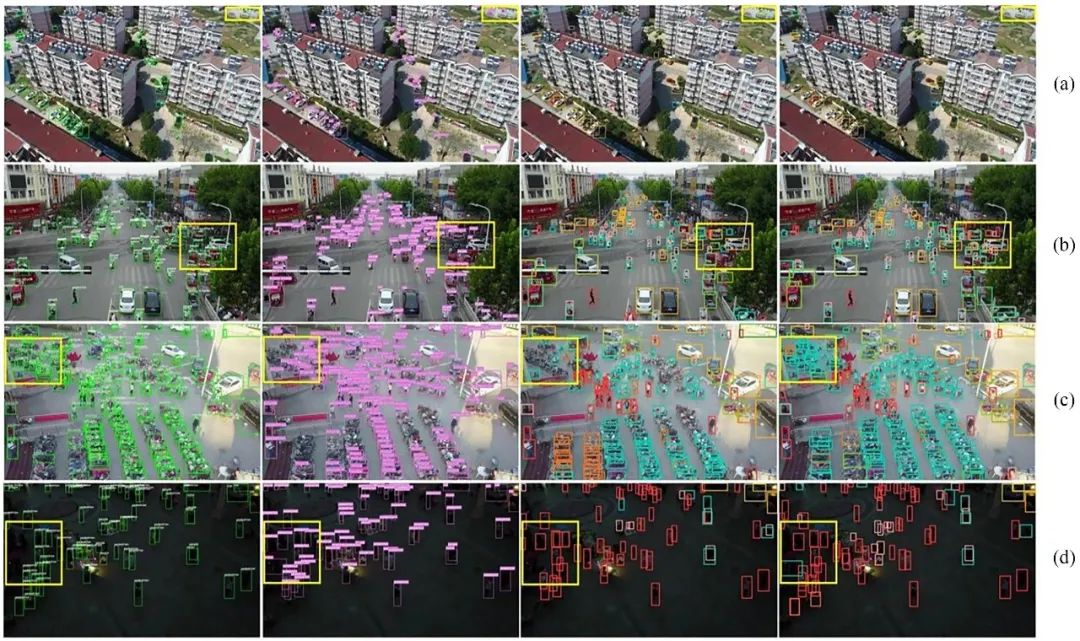
可视化分析(上图)进一步揭示,标准融合(a)和三明治融合(b)在检测远距离小目标时均存在明显不足。FRM校准(c)大幅提升了对远距离小型车辆的定位精度,而两阶段融合策略(d)成功检测到了70米距离处小至4×4像素的车辆。该方法以增加23%的计算开销为代价,实现了4.5个百分点的精度提升,使其特别适用于无人机视觉任务。这种“校准-增强”级联设计为小目标检测中的特征融合提供了一种新颖的技术思路。
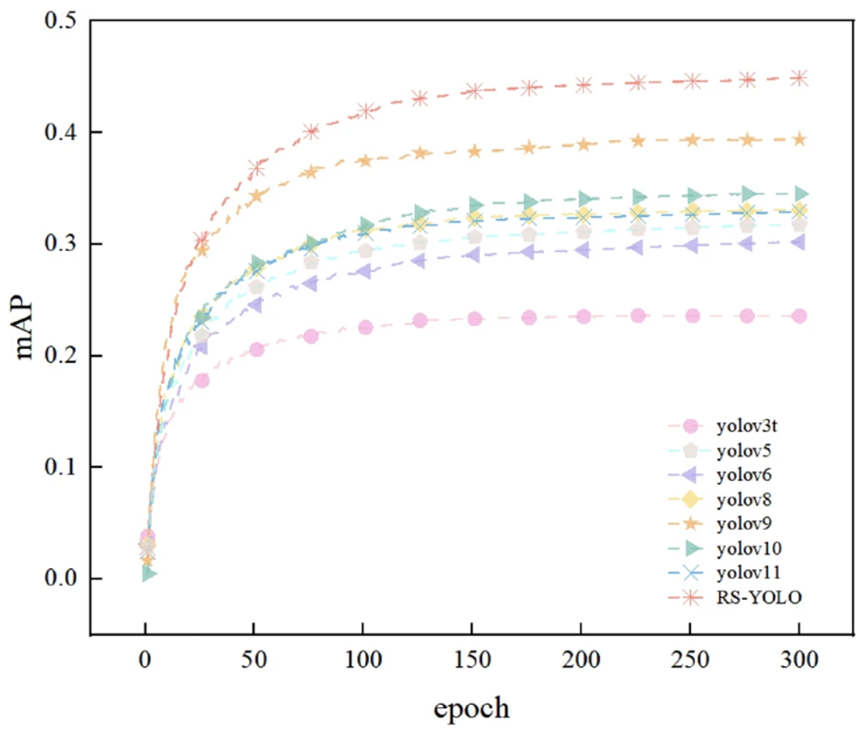
橙色星号曲线代表CF-YOLO,显然可见,CF-YOLO在mAP50上显著高于其他模型,表现最为出色。这些数据清晰地证明了CF-YOLO在处理复杂场景和小目标检测问题方面的优势,且在检测精度上,CF-YOLO始终展现出其优越性。

如上图所示,CF-YOLO展现出卓越的多尺度目标检测能力:在远距离小目标检测中(红色标记(a)-1、(b)-1/2、(c)-2),CF-YOLO成功识别出平均尺寸小于20×20像素的目标,而对比模型则出现了漏检情况(对应黄色标记)。在部分遮挡处理方面((a)-2/3),CF-YOLO准确检测出被树木遮挡的摩托车和截断的卡车,展现出更优的遮挡鲁棒性。在具有挑战性的弱光密集场景中(样本(b)-3、(c)-1/3、(d)-1),CF-YOLO展现出出色的小目标检测能力。定量分析表明,对于平均尺寸小于20×20像素的密集行人与车辆目标,CF-YOLO实现了更高的定位精度,显著优于对比模型的平均检测性能。
小行人检测结果可视化

如上图所示,本研究使用TinyPerson数据集,对CF-YOLO和主流检测模型(YOLOv5/YOLOv8/YOLOv11)进行了系统的视觉对比分析。采用标准化标注方案,红色虚线框表示正确检测到的目标(真阳性),黄色虚线框表示未检测到的目标(假阴性)。实验评估涵盖四种具有代表性的场景:第一组(图(a))为海上游泳者的中距离检测场景,CF-YOLO成功识别出多个平均尺寸仅为8-16像素的游泳目标,而对比模型存在不同程度的漏检情况。第二组(图(b))呈现远距离海滩场景,CF-YOLO准确捕捉到不同姿态的日光浴者,与基准模型相比,检测完整性显著更优。第三组(图(c))聚焦中距离密集人群场景,尽管存在大量目标遮挡,CF-YOLO仍保持稳定的检测性能。第四组(图(d))考查远距离海岸活动场景,CF-YOLO在具有挑战性的远距离条件下实现了可靠的检测性能,与对比模型中观察到的高漏检率形成鲜明对比。综合分析表明,CF-YOLO在三个关键方面具有显著优势:(1)对极小目标(<16像素)的持续检测能力;(2)对多尺度场景的出色适应性;(3)对高密度目标的卓越辨别能力。尤其在目标尺度极端的场景中,与基准模型相比,CF-YOLO的漏检率大幅降低。这些视觉结果有力地验证了该模型在微小目标检测任务中的出色性能。
有相关需求的你可以联系我们!


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗
-
YOLO-TLA:一种基于 YOLOv5 的高效轻量级小目标检测模型
-
ViT-YOLO:基于Transformer的用于目标检测的YOLO算法
-
SSMA-YOLO:一种轻量级的 YOLO 模型,具备增强的特征提取与融合能力,适用于无人机航拍的船舶图像检测
-
LUD-YOLO:一种用于无人机的新型轻量级目标检测网络
-
Gold-YOLO:基于聚合与分配机制的高效目标检测器
-
Drone-YOLO:一种有效的无人机图像目标检测
-
「无人机+AI」“空中城管”
-
无人机+AI:光伏巡检自动化解决方案
-
无人机视角下多类别船舶检测及数量统计
-
机场项目:解决飞行物空间大小/纵横比、速度、遮挡等问题引起的实时目标检测问题
-
2PCNet:昼夜无监督域自适应目标检测(附原代码)
-
YOLO-S:小目标检测的轻量级、精确的类YOLO网络
-
大改Yolo框架 | 能源消耗极低的目标检测新框架(附论文下载)
-
改进的检测算法:用于高分辨率光学遥感图像目标检测

