funasr语音识别docker部署——并基于qt开发_funasr websocket
开发要求
a. 在ubuntu安装布署语音识别框架Funasr;
b. 编写接口测试代码,熟悉开发流程及函数
c. 开发基于QT的最终测试案例
开发效果:实现出现一个ui界面,当点下按钮后,开始录制语音,松开后开始识别并在界面上显示语音识别结果。
1. 在ubuntu安装布署语音识别框架Funasr
Funasr介绍:
Funasr是阿里达摩院的开源大型端到端(语音信号直接映射到文本技术)语音识别工具包,提供了在大规模工业语料库上训练的模型,并能够将其部署到应用程序中。
工具包的核心模型是Paraformer,结合了语音端点检测、语音识别、标点等模型,为构建高精度的长音频语音识别服务提供了坚实的基础。
与在公开数据集上训练的其它模型相比,Paraformer展现出了更卓越的性能, FunASR 的中文语音转写效果比openai的开源框架 Whisper 更优秀,因此本项目考虑使用FunASR。
1.1在Ubuntu2204中安装docker
Docker介绍:Docker 是一个开源的应用容器,可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上。容器是完全使用沙箱机制,相互之间不会有任何接口,更重要的是容器性能开销极低。
安装原因: 阿里开发团队在Docker上上传了Funasr镜像,Funasr框架在Docker容器上下载运行更为方便高效。
1.1.1更新Ubuntu的镜像源
sudo apt updatesudo apt upgrade1.1.2安装必要的证书并允许apt包管理器使用以下命令通过https使用存储库。
sudo apt install apt-transport-https ca-certificates curl software-properties-common gnupg lsb-release1.1.3添加Docker的官方GPG密钥、添加Docker官方库、更新Ubuntu源列表
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgsudo echo \"deb[arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable\" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullsudo apt update1.1.4安装Docker
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin1.1.5启动后查看状态、设为开机自启动
sudo systemctl start dockersystemctl status dockersudo systemctl enable docker1.2 funasr镜像和容器下载
1.2.1在Docker获取镜像
---------------------------------------------------------------------------------------------------------------------------------
- Docker 镜像(Images):是用于创建 Docker 容器的模板,比如 Ubuntu 系统。
- Docker 容器(Container):是独立运行的一个或一组应用,是镜像运行时的实体。
镜像和容器的关系就像从c++中类和对象的关系,要想使用镜像就要先创建一个对应的容器
Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。
Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。
一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 : 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
---------------------------------------------------------------------------------------------------------------------------------
下载funasr : funasr-runtime-sdk-online-cpu-0.1.12(: )的镜像:
sudo docker pull \\registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.12mkdir -p ./funasr-runtime-resources/models列出镜像列表
docker images :列出本地主机上的镜像

TAG:镜像的标签IMAGE ID:镜像IDCREATED:镜像创建时间SIZE:镜像大小
1.2.2根据镜像启动一个容器
一定要加-p 10096:10095 ,否则容器启动后容器外无法访问容器内服务,容器内外是相当于两个不同系统,两边端口号没有任何关联,要通过启动时-p 10096:10095映射
-i: 交互式操作。-t: 终端。
sudo docker run -p 10096:10095 -it --privileged=true \\ -v $PWD/funasr-runtime-resources/models:/workspace/models \\ registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.12执行以上命令后该终端会进入容器内部,因为启动时加入参数-it,进行终端交互
![]()
打开另一个终端
查看所有的容器命令如下:
docker ps -a(在容器外的终端输入)![]()
1.2.3容器内启动和关闭funasr服务端(以下部分在容器内终端操作)
进入该目录
cd FunASR/runtime![]()
执行以下命令:
bash run_server.sh \\ --certfile 0 \\ --download-model-dir /workspace/models \\ --vad-dir damo/speech_fsmn_vad_zh-cn-8k-common-onnx \\ --model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-8k-common-vocab8404-onnx \\ --online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-8k-common-vocab8404-online-onnx \\ --punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \\ --lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \\ --itn-dir thuduj12/fst_itn_zh命令参数说明:
- # 如果您想关闭ssl,增加参数:--certfile 0
- # 如果您想使用SenseVoiceSmall模型、时间戳、nn热词模型进行部署,请设置--model-dir为对应模型:iic/SenseVoiceSmall-onnx、 damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx(时间戳)、 damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404-onnx(nn热词)
- # 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
- # 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)
- # SenseVoiceSmall-onnx识别结果中“ ”分别为对应的语种、情感、事件信息
如果该容器的服务已经运行过上面的命令一次了,也就是曾经启动过该服务,已经完成模型下载,可以直接运行下面命令启动:
bash run_server.sh update --ssl 0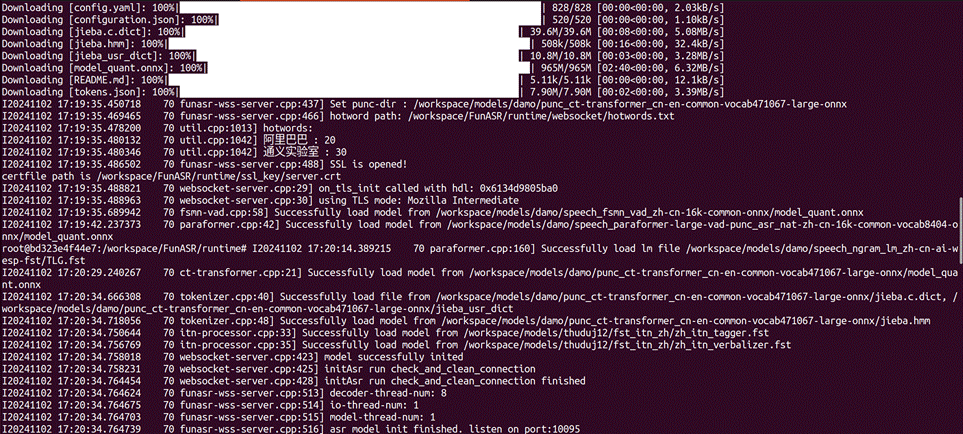
当出现监听端口时即成功部署funasr服务端
1.2.4关闭服务端
查看 funasr-wss-server 对应的PID
ps -x | grep funasr-wss-server-2passkill -9 PID
关闭容器命令:exit

(容器只是退出关闭,还能再启动)
1.2.5 docker容器的其他基本操作
停止容器
停止容器的命令如下(在容器外停止):
$ docker stop 停止的容器可以通过 docker restart 重启:
$ docker restart 进入容器
容器再启动后会进入后台。此时想要进入容器,可以通过以下指令进入:
$ docker attach $ docker exec 推荐使用 docker exec 命令,因为此命令会退出容器终端,但不会导致容器的停止。
导出容器
如果要导出本地某个容器,可以使用 docker export 命令。
$ docker export 1e560fca3906 > ubuntu.tar导出容器 1e560fca3906 快照到本地文件 ubuntu.tar。
这样将导出容器快照到本地文件。
导入容器快照
可以使用 docker import 从容器快照文件中再导入为镜像,以下实例将快照文件 ubuntu.tar 导入到镜像 test/ubuntu : v1(: ):
$ cat docker/ubuntu.tar | docker import - test/ubuntu:v1删除容器
删除容器使用 docker rm 命令:
$ docker rm -f 1e560fca3906下面的命令可以清理掉所有处于终止状态的容器。
$ docker container prune删除镜像
删除镜像使用 docker rmi 命令:
$ docker rmi 2. 编写接口测试代码,熟悉开发流程及函数
2.1接口测试
执行一下命令下载解压官方客户端案例
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gztar -xvf funasr_samples.tar.gz在服务器已经运行的情况下,进入samples/cpp目录,执行以下语句
./funasr-wss-client --server-ip 127.0.0.1 --port 10096 --wav-path ../audio/asr_example.wav可以看到以下结果则已经完成接口测试

ubuntu2204本身不带libssl库,会报错,可以用一下命令下载(该网址库有时效性,过期了会下载失败):
wget http://security.ubuntu.com/ubuntu/pool/main/o/openssl/libssl1.1_1.1.1-1ubuntu2.1~18.04.23_amd64.debsudo dpkg -i libssl1.1_1.1.1-1ubuntu2.1~18.04.23_amd64.deb2.2解析官方案例代码
接下来对funasr-wss-client.cpp代码进行分析:
由主函数看代码可以发现:
TCLAP: 用于命令行参数解析。
websocketpp: 用于WebSocket通信。
-------------------------------------------------------------------------------
TCLAP通过ValueArg定义多个参数:
server_ip: 服务器IP地址(必需,默认值为127.0.0.1)。
port: 服务器端口(必需,默认值为10095)。
wav_path: 输入音频文件路径,可以是WAV文件、PCM文件或Kaldi风格的WAV列表。
audio_fs: 音频采样率(可选,默认值为16000)。
thread_num: 使用的线程数(可选,默认值为1)。
is_ssl: 是否使用SSL(可选,默认值为1,表示使用WSS)。
use_itn: 是否使用ITN(可选,默认值为1)。
hotword: 热词文件路径(可选)。
所有参数都通过cmd.add()方法添加到命令行解析器中,并通过cmd.parse(argc, argv)解析。
由于在qt开发客户端,可以自己设定参数,所以不采用TCLAP。
接下来重点分析websocket通信。
-------------------------------------------------------------------------------
2.2.1 WebSocket 协议
WebSocket 协议是一种基于TCP的网络层协议,用于在客户端和服务器之间建立持久连接,并且可以在这个连接上实时地交换数据。WebSocket协议有自己的握手协议,用于建立连接,也有自己的数据传输格式。与http关系如下:
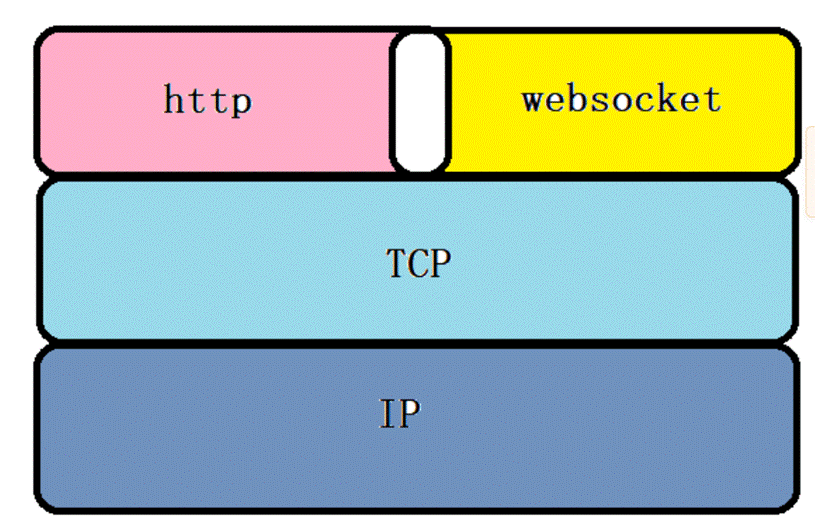
区别:WebSocket是双向通信协议,模拟Socket协议,可以双向发送或接受信息,HTTP是单向的。WebSocket在建立握手时,数据是通过HTTP传输的,但是建立之后,在真正传输时候是不需要HTTP协议的。
2.2.2 WebsocketClient类
在funasr-wss-client.cpp中,定义了一个专门的类class WebsocketClient
在主函数中,主要的数据传输代码为以下
if (is_ssl == 1){ WebsocketClient c(is_ssl); c.m_client.set_tls_init_handler(bind(&OnTlsInit, ::_1)); c.run(uri, wav_list, wav_ids, audio_fs, hws_map, use_itn);} else { WebsocketClient c(is_ssl); c.run(uri, wav_list, wav_ids, audio_fs, hws_map, use_itn);}可以看到主要是实例化对象c,然后进行连接和通信,而开启ssl模式则在连接前进行set_tls_init_handler(bind(&OnTlsInit, ::_1))的初始化,由于qt自带ssl通信证书类,所以不进行分析。
分析WebsocketClient的run函数:
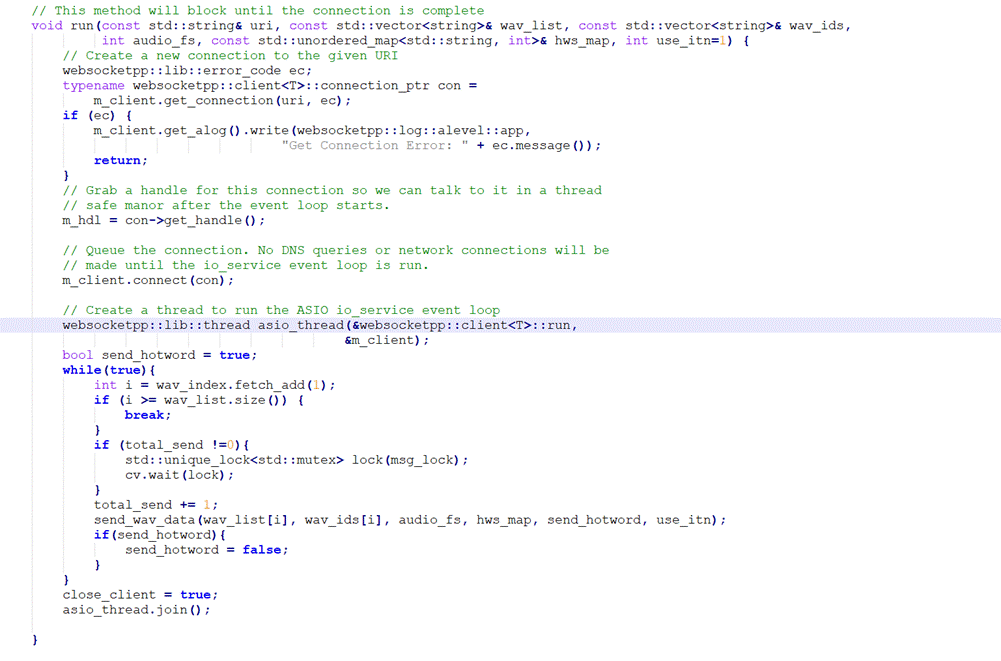
由m_client.get_connection(uri, ec);进行连接,send_wav_data(wav_list[i], wav_ids[i], audio_fs, hws_map, send_hotword, use_itn);进行数据的发送。
2.2.3 WebsocketClient类的send_wav_data函数
经分析,客户端对于json数据的发送包括音频的解析传输都在send_wav_data函数中。
函数void send_wav_data(string wav_path, string wav_id, int audio_fs,
const std::unordered_map& hws_map,
bool send_hotword, bool use_itn)
参数如下:
- string wav_path:音频文件的路径。
- string wav_id:音频文件的唯一标识符。
- int audio_fs:音频文件的采样率。
- const std::unordered_map& hws_map:热词映射表,包含热词及其对应的权重。
- bool send_hotword:是否发送热词信息。
- bool use_itn:是否使用说话人识别技术(ITN)。
函数内容分析:
一、初始化:
使用 funasr::Audio 类创建一个音频对象,并设置采样率为 audio_fs。
根据 wav_path 的文件扩展名,确定音频文件的格式(PCM或其他)。
如果是PCM文件,使用 LoadPcmwav 方法加载PCM格式的WAV文件;
如果不是PCM文件,使用 LoadOthers2Char 方法加载其他格式的音频文件。
PCM:PCM(脉冲编码调制,Pulse Code Modulation)是一种用于数字音频信号的编码方式,通常用于将模拟音频信号转换为数字信号。
音频编码:在PCM中,模拟音频信号被定期采样,每个样本的幅度被量化并编码为数字值。这些数字值表示特定时间点上的音频幅度。
采样率:PCM的一个重要参数是采样率,表示每秒钟采样多少次音频信号。常用的采样率包括44.1 kHz(CD音质)和48 kHz(视频音频标准)。更高的采样率可以捕捉更多的声音细节,但也会生成更大的文件。
二、发送音频数据前的准备:
等待WebSocket连接打开,如果连接已关闭,则停止发送数据。
构建JSON对象 jsonbegin,包含音频分块大小、间隔、文件名、格式、采样率和ITN设置。
如果 use_itn 为 false,则在JSON对象中设置ITN为 false。
如果 send_hotword 为 true 且 hws_map 不为空,则将热词信息添加到JSON对象中。
三、数据发送:(案例使用 nlohmann::json 库来构建和发送JSON数据。)
- 发送JSON开始信息:使用 m_client.send 方法发送构建好的JSON对象 jsonbegin 到服务器。

- 发送音频数据:如果音频格式是PCM,循环获取音频数据,并将浮点数转换为短整型,然后分块发送;如果音频格式不是PCM,直接发送整个音频数据。在发送每个数据块后,打印已发送数据的长度。


3.发送JSON结束信息:构建一个JSON对象 jsonresult,表示音频数据发送完成,并发送到服务器。

3.开发基于QT的最终测试案例
3.1 qt的websocket连接
3.1.1 库准备
在qt中,有qwebsocket库专门实现websocket连接的方法,在终端下载qwebsocket
sudo apt-get install libqt5websockets5-dev然后在qt工程的.pro文件添加如下:
QT += websocketsQT += network
3.1.2 实现qt客户端的简单连接
在qt构建实现websocket的类
class WebsocketClient : public QObject{ Q_OBJECTpublic: explicit WebsocketClient(int is_ssl, QObject *parent = nullptr); ~WebsocketClient(); void connectToServer(const QUrl& url); void sendWavFile(const QString &filePath); void send_JsonData (const QString &wavId, int audioFs, bool useItn, const QJsonObject &hotwords); void send_jsonresult(); QWebSocket m_client; //主要的QWebSocket对象 QString text;signals: void messageReceived(const QString &message); void connected(); void disconnected();private slots: void onConnected(); void onDisconnected(); void onTextMessageReceived(const QString &message); void onSslErrors(const QList& errors);private: bool m_is_ssl; bool connect_stutas;};其中构造函数主要为进行信号与槽的绑定:
connect(&m_client, &QWebSocket::disconnected, this, &WebsocketClient::onDisconnected); connect(&m_client, &QWebSocket::textMessageReceived, this, &WebsocketClient::onTextMessageReceived);connect(&m_client, &QWebSocket::sslErrors, this, &WebsocketClient::onSslErrors); // 处理 SSL 错误利用QWebSocket对象连接服务器:
m_client.open(url);然后发现本地上的服务器并不能接受ssl关闭的连接,即使服务器已经关闭了ssl服务还是会有以下报错:

报错内容提示ssl错误。
搜集资料,多次尝试,发现qt上websocket有自带的ssl证书
结果成功:

此时客户端已经实现初步连接,等待发送数据。
3.2 qt的json构建
在事例代码中,运用了nlohmann::json 库来构建json头和尾,而在qt中,有相应的json数据处理函数,要使用如下头文件:
#include #include #include 对于json头的构建,参照事例:
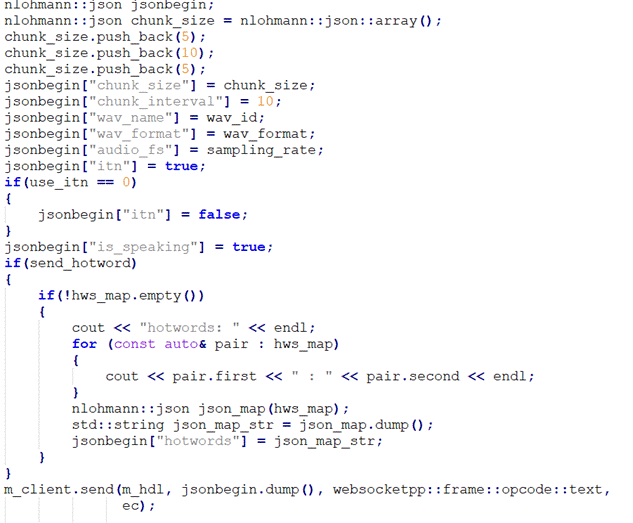
以下为json头构建发送函数,传入四个参数,分别为wav文件名、音频的采样频率、是否使用ITN、包含热词映射的字符串。
另外由于我的工程默认为pcm 格式,所以默认。\"is_speaking\"为告诉服务器是否传数据的参数,\"chunk_size\"可能代表了音频数据在发送给服务器时被分成的块的大小,这里照抄事例格式。
void WebsocketClient::send_JsonData(const QString &wavId, int audioFs, bool useItn, const QJsonObject &hotwords){ QJsonObject jsonBegin; QJsonArray chunkSize; chunkSize.append(5); chunkSize.append(10); chunkSize.append(5); jsonBegin[\"chunk_size\"] = chunkSize; jsonBegin[\"chunk_interval\"] = 10; jsonBegin[\"wav_name\"] = wavId; jsonBegin[\"wav_format\"] = \"pcm\"; jsonBegin[\"audio_fs\"] = audioFs; jsonBegin[\"itn\"] = useItn; jsonBegin[\"is_speaking\"] = true; if (!hotwords.isEmpty()) { jsonBegin[\"hotwords\"] = hotwords; }//sendTextMessage 函数需要一个字符串作为参数doc QJsonDocument doc(jsonBegin) ;//通过调用 doc.toJson(QJsonDocument::Compact),得到一个紧凑格式的 JSON 字 符串,便于传输。 QString jsonString = doc.toJson(QJsonDocument::Compact); if (connect_stutas) { m_client.sendTextMessage(jsonString); //m_client是类的QWebSocket成员 } else { qDebug() << \"WebSocket is not connect!\"; } return;}同理,json尾根据事例构建发送如下:

void WebsocketClient::send_jsonresult(){ QJsonObject jsonresult; jsonresult[\"is_speaking\"] = false; QJsonDocument doc(jsonresult); QString jsonString = doc.toJson(QJsonDocument::Compact); if (connect_stutas) { m_client.sendTextMessage(jsonString); } else { qDebug() << \"WebSocket is not connect!\"; } return;}3.3 音频的处理和发送
3.3.1 音频下载
在示例代码中,对于音频的处理方法主要集成在了audio.cpp和resample.cpp中。
在qt工程当中我打算直接调用两个文件的api接口对音频进行处理。
此处还要对官方的示例代码进行详细分析:
对于案例中音频,在确定了音频文件的路径和文件名后,是先对文件进行加载,然后再根据设定的采样率,位深等参数进行采样分割,最后才会发送给服务端。
具体的加载文件操作如下:

在确认了音频文件是PCM编码后,主要用Audio::LoadPcmwav函数进行文件的加载,
该函数的传参分别为:音频文件名、采样率、是否进行重采样

在Audio::LoadPcmwav函数中,有
void WebsocketClient::send_jsonresult(){ QJsonObject jsonresult; jsonresult[\"is_speaking\"] = false; QJsonDocument doc(jsonresult); QString jsonString = doc.toJson(QJsonDocument::Compact); if (connect_stutas) { m_client.sendTextMessage(jsonString); } else { qDebug() << \"WebSocket is not connect!\"; } return;}这里就是从文件中读取音频数据,并将其转换为浮点数格式存入Audio对象的speech_data成员中,随后有:
if (resample && *sampling_rate != 16000) { WavResample(*sampling_rate, speech_data, speech_len);}这里如果传参为重采样同时采样率不是16000,会进行重采样,以满足服务器的需要。后续为了提高效率以及尽量不失真,我的录音参数采样率和客户端处理采样率都是16000
最后,利用frame_queue.push(frame),将处理后的数据存入音频帧队列,以便后续处理。
以上为音频的下载,案例中还用到了audio.Fetch函数

Fetch 函数检查 frame_queue 是否有 AudioFrame 对象。如果有,它取出队列前面的 AudioFrame 对象,更新 dout 指向该帧的开始,len 设置为帧的长度,并删除该 AudioFrame 对象,然后返回 1 并设置 flag 为 S_END。
如果 frame_queue 为空,它直接返回 0。
掌握了以上两个函数,我模仿官方案例完成了基于qt的音频处理和发送,以下是我的代码:
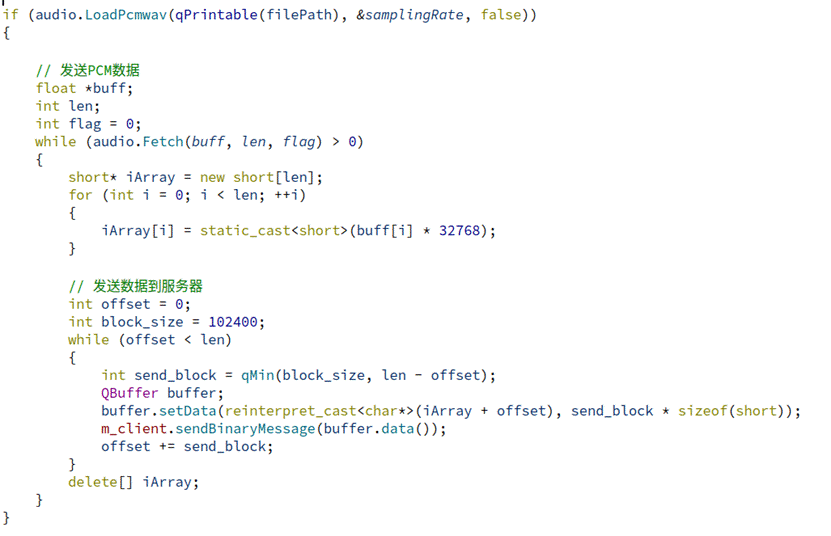
这里buff拿下来的数据并不能直接发送给服务器,要将 float 数组转换为 short 数组,通过乘以 32768 来进行缩放,最后将short 数组分块发送到服务器,每块大小为 102400 字节。
查阅资料后明白将 float 数据乘以一个缩放因子,以将其映射到 short 数据的范围,是对于16位PCM的处理,这个缩放因子是 32768(即 2^15),而对应的 short 数据的范围是 -32768 到 32767。

连接上服务器后,发送json头再发送音频,最后再加上json尾。此时已经能实现现有音频的识别。
3.4回复数据的处理
以下为服务器对于长音频识别后返回的结果:
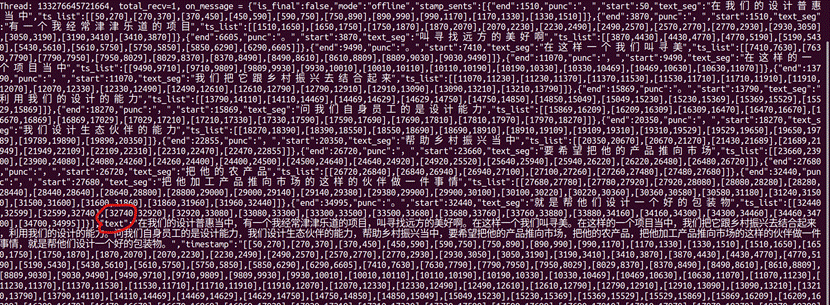
分析服务器回复的json可以看出最后识别出的结果都放在了text下,所以在qt中直接直接取json中的text字段作为识别结果就可以了

3.5实现录音并且生成wav文件
由上面的开发我实现了对现有音频的识别,但是qt开发的客户端仅实现了对默认格式的处理,并不能如同官方案例一样对各种文件都能实现识别,我的客户端对音频作出了以下限定:pcm编码的wav文件,单音道,采样率为16000,位深为16。
录音功能我采取了利用ubuntu内的alsa库编程实现录音并存为音频文件,qt内实现调用并控制外部录音程序的方案。
3.5.1 在ubuntu终端中实现录音并保存为wav文件
定义wav头(固定格式):

文件类型、采样率、通道数、数据大小等信息都包含在里面
设置音频硬件参数

音频参数(如格式、采样率、通道数、帧大小等)通过 snd_pcm_hw_params 进行配置。
打开WAV文件并写入头部

录音循环

当键盘输入q时会自动退出录音循环。
3.5.2 实现qt对外部录音程序的调用与控制

3.5.3 录音程序完整代码:
#include #include #include #include #define PCM_DEVICE \"plughw:0,0\"#define FORMAT SND_PCM_FORMAT_S16_LE#define CHANNELS 1#define SAMPLE_RATE 16000#define BITS_PER_SAMPLE 16#define WAV_HEADER_SIZE 44// WAV 文件头typedef struct { char riff[4]; // \"RIFF\" unsigned int overall_size; // 文件大小 - 8 char wave[4]; // \"WAVE\" char fmt_chunk_marker[4]; // \"fmt \" unsigned int length_of_fmt; // 格式数据块大小 unsigned short format_type; // 格式类别 (PCM = 1) unsigned short channels; // 通道数 unsigned int sample_rate; // 采样率 unsigned int byterate; // 每秒字节数 unsigned short block_align; // 一个样本的字节数 unsigned short bits_per_sample; // 每个样本的位数 char data_chunk_header[4]; // \"data\" unsigned int data_size; // 音频数据大小} wav_header_t;// 生成WAV文件头void write_wav_header(FILE *file, int channels, int sample_rate, int bits_per_sample, int data_size) { wav_header_t header; memcpy(header.riff, \"RIFF\", 4); header.overall_size = data_size + WAV_HEADER_SIZE - 8; memcpy(header.wave, \"WAVE\", 4); memcpy(header.fmt_chunk_marker, \"fmt \", 4); header.length_of_fmt = 16; header.format_type = 1; // PCM header.channels = channels; header.sample_rate = sample_rate; header.byterate = sample_rate * channels * bits_per_sample / 8; header.block_align = channels * bits_per_sample / 8; header.bits_per_sample = bits_per_sample; memcpy(header.data_chunk_header, \"data\", 4); header.data_size = data_size; fwrite(&header, 1, sizeof(wav_header_t), file);}// 检查键盘输入的函数int kbhit() { struct termios oldt, newt; int ch; int oldf; tcgetattr(STDIN_FILENO, &oldt); newt = oldt; newt.c_lflag &= ~(ICANON | ECHO); tcsetattr(STDIN_FILENO, TCSANOW, &newt); oldf = fcntl(STDIN_FILENO, F_GETFL, 0); fcntl(STDIN_FILENO, F_SETFL, oldf | O_NONBLOCK); ch = getchar(); tcsetattr(STDIN_FILENO, TCSANOW, &oldt); fcntl(STDIN_FILENO, F_SETFL, oldf); if (ch != EOF) { ungetc(ch, stdin); return 1; } return 0;}// 主函数int main() { unsigned int sample_rate = SAMPLE_RATE; int channels = CHANNELS; snd_pcm_uframes_t frames = 32; // 每次读取32帧 // 打开 ALSA PCM 设备 snd_pcm_t *pcm_handle; snd_pcm_hw_params_t *params; snd_pcm_uframes_t frames_per_period; int pcm; pcm = snd_pcm_open(&pcm_handle, PCM_DEVICE, SND_PCM_STREAM_CAPTURE, 0); if (pcm < 0) { fprintf(stderr, \"ERROR: Can\'t open \\\"%s\\\" PCM device. %s\\n\", PCM_DEVICE, snd_strerror(pcm)); return -1; } // 设置硬件参数 snd_pcm_hw_params_malloc(¶ms); snd_pcm_hw_params_any(pcm_handle, params); snd_pcm_hw_params_set_access(pcm_handle, params, SND_PCM_ACCESS_RW_INTERLEAVED); snd_pcm_hw_params_set_format(pcm_handle, params, FORMAT); snd_pcm_hw_params_set_channels(pcm_handle, params, channels); snd_pcm_hw_params_set_rate_near(pcm_handle, params, &sample_rate, 0); snd_pcm_hw_params_set_period_size_near(pcm_handle, params, &frames, 0); pcm = snd_pcm_hw_params(pcm_handle, params); if (pcm < 0) { fprintf(stderr, \"ERROR: Can\'t set hardware parameters. %s\\n\", snd_strerror(pcm)); return -1; } snd_pcm_hw_params_get_period_size(params, &frames_per_period, 0); // 打开WAV文件并写入头部 FILE *file = fopen(\"test.wav\", \"wb\"); if (!file) { fprintf(stderr, \"ERROR: Can\'t open output file.\\n\"); return -1; } write_wav_header(file, channels, sample_rate, BITS_PER_SAMPLE, 0); // 先写入空的WAV头 // 分配缓冲区 int buffer_size = frames_per_period * channels * BITS_PER_SAMPLE / 8; char *buffer = (char *) malloc(buffer_size); // 录音循环 int total_bytes = 0; int running = 1;printf(\"begin-----\"); while (running) { if (kbhit()) { char c = getchar(); if (c == \'q\') { running = 0; } } pcm = snd_pcm_readi(pcm_handle, buffer, frames_per_period); if (pcm == -EPIPE) { fprintf(stderr, \"XRUN.\\n\"); snd_pcm_prepare(pcm_handle); } else if (pcm < 0) { fprintf(stderr, \"ERROR: Can\'t read from PCM device. %s\\n\", snd_strerror(pcm)); } else { fwrite(buffer, 1, buffer_size, file); total_bytes += buffer_size; } } // 更新 WAV 头部文件大小信息 fseek(file, 0, SEEK_SET); write_wav_header(file, channels, sample_rate, BITS_PER_SAMPLE, total_bytes); // 清理 free(buffer); fclose(file); snd_pcm_drain(pcm_handle); snd_pcm_close(pcm_handle); return 0;}编译:
gcc recorder.c -o recorder -lasound开发总结
1.问题与解决
1、由于ubuntu2204本身系统较大并且docket下语音模型较大,要时刻注意系统磁盘空间,否则容易造成虚拟机卡顿并且重启无法开机,虚拟机在系统内分盘比较麻烦,因此调试过程中重装了两次虚拟机(建议新建虚拟机时分盘30G)
运用df -h 命令查看磁盘空间剩余

2、Ubuntu2204下安装qt,一开始是在ubuntu 自带的software安装qt,但在新建项目中kits套件是没得选的,即使后来另外下载qt库也无法解决,查阅资料发现推荐在qt官网下载离线安装包(.run文件)进行安装,里面有专门的大安装包,包含开发需要的东西,并且能自动配置好。
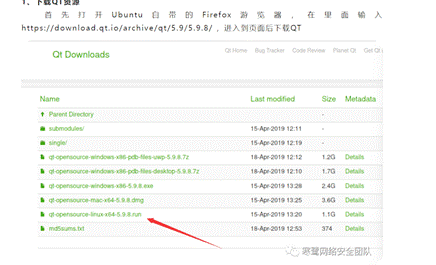
但是官网qt5.15以下版本都无法访问,而5.15及6版本都取消了离线安装,只支持在线(在线及其不稳定要梯子)
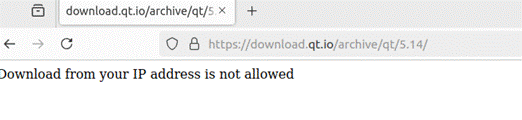
最后选择通过命令行下载
3、ssl是一种加密协议,用于通过互联网保护数据的传输安全。即使在启动服务是加入相关代码,funasr服务器的ssl无法关闭,无论是浏览器的网页访问还是官方客户端的--is_ssl 0连接命令,服务器都会报错

问题原因可能在于服务端代码是wss版本,不允许客户端的无ssl 访问。
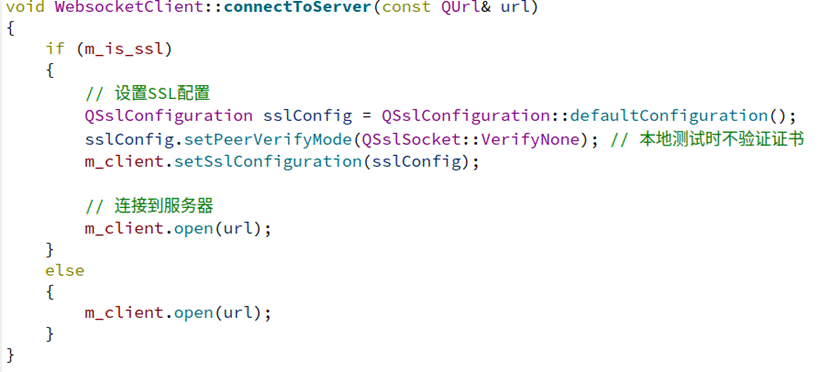
解决办法是在qt客户端的连接时也使用qssl 类来建立自签名的证书QSslSocket::VerifyNone 表示在本地测试时,不验证服务器的 SSL 证书。似乎仅仅只能在本地连接时使用,而不使用这个参数时进行qssl连接会失败。

4、在实现音频数据的发送时,一开始没有考虑pcm的数据格式问题,直接发送了 float 数据,这可能导致服务器端处理数据的方式不同,使得服务器应答成功但是返回了一个空的文本结果。
while (audio.Fetch(buff, len, flag) > 0) { QBuffer buffer; buffer.setData(reinterpret_cast(buff), len * sizeof(float)); m_client.sendBinaryMessage(buffer.data()); }
解决:在进行排错检查以及与原来示例代码研究发现,将 float 数组转换为 short 数组,通过乘以 32768 来进行缩放,最后将short 数组分块发送到服务器,每块大小为 102400 字节。

随后对qt的处理方式进行更改,结果成功出来结果,查阅资料明白,是要将 float 数据乘以一个缩放因子,以将其映射到 short 数据的范围。对于16位PCM,这个缩放因子通常是 32768(即 2^15),因为 float 数据的范围是 -1.0 到 1.0,而 short 数据的范围是 -32768 到 32767。
5.在开发录音功能时一开始考虑使用qt内库实现功能,需要qt的multimedia库,通过命令下载:
apt-get install qtmultimedia5-dev提示找不到这个包,更新软件包列表也用。
原因与解决:因为qt5multimedia软件包位于Universe仓库中,而我的ubuntu系统的软件源列表中没有这个Universe仓库,所以找不到。解决方法为运行sudo add-apt-repository universe命令添加这个软件源,再下载multimedia库。
6.在进行服务器的部署时需要启动服务,直接运行github官方的启动命令
然后没有结果产生,然后再多次重复输入启动,导致直接卡死。
原因:运行该命令已经开始启动服务并下载模型,但由于其中有参数:nohup以及--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &,使得所有的日志输出到了log.txt当中,终端是不会产生输出,在调试时建议去除这行参数。
7.在qt与外部录音程序的交互时有外部录音程序可执行文件没问题,qt内用qprocess打开却报错如下
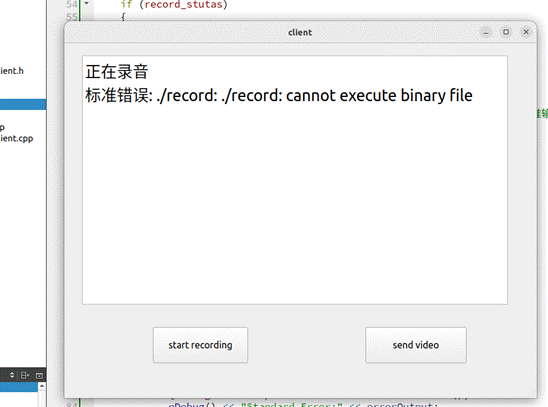
原因:由于我的qt只有用户权限,对文件的读写和文件的操作都有限制
解决方法:把wav和 可执行文件record执行chmod 777

8.在解决上面问题后,在qt中却无法结束录音,在录音程序中我通过 termios 和 fcntl 系统调用设置终端模式,允许非阻塞的键盘输入检测。当键盘点击q时结束录音。在qt中我试图通过对qprocess对象cmd写入q安全结束录音程序。
结果录音程序推出失败。
原因:cmd->write(\"q\\n\");是qprocess通过写一个q进去,并不触发键盘事件,两者并不一样。
解决:使用了有名管道实现进程间的通信,发现还是不能正常退出,qt进程会报错强制退出,而录音进程还在自己跑,最后我直接用qprocess的start启动了录音程序,kill结束录音程序,相当于强行退出,但最终功能实现了。
2.开发总结
对于funasr的运用开发开始时十分困难,由于这一语音识别框架还在不断更新,我用的0.1.12版本更是当天发布当天进行部署测试,网上的参考资料参差不齐,只能靠自己不断测试不断进行探究错误,是十分需要耐心以及消耗时间的,不过当自己写的qt客户端能够实现语音识别功能时,那种感觉还是很爽的。
这次开发遇到的困难我也并非全部解决,有不少都是直接绕过去,有的就算是解决了也不太清楚为什么会这样,有很多涉及更深层的知识还需要以后不断探究的,就像是ssl这一协议,如果我的连接不在本地又要如何解决,是要注册自签名证书吗,还有为什么在火狐浏览器上仍然不能网页连接我启动的服务器,是浏览器没有自己的ssl协议证书吗。想这些问题还是有挺多没有彻底搞明白的,以后或许会找到答案。

