论文阅读|CVPR 2025|视觉语言模型|MMRL: Multi-Modal Representation Learning for Vision-Language Models_cvpr2025论文

论文地址:https://arxiv.org/abs/2503.08497
代码地址:https://github.com/yunncheng/MMRL
文章目录
- 1. 研究主张
-
- 1.1 创新点
- 1.2 整体架构
- 2. 研究背景
- 3. 方法论
-
- 3.1 预备知识:CLIP基础公式
- 3.2 MMRL核心公式
- 4. 结果与分析
1. 研究主张
1.1 创新点
-
共享可学习表示空间
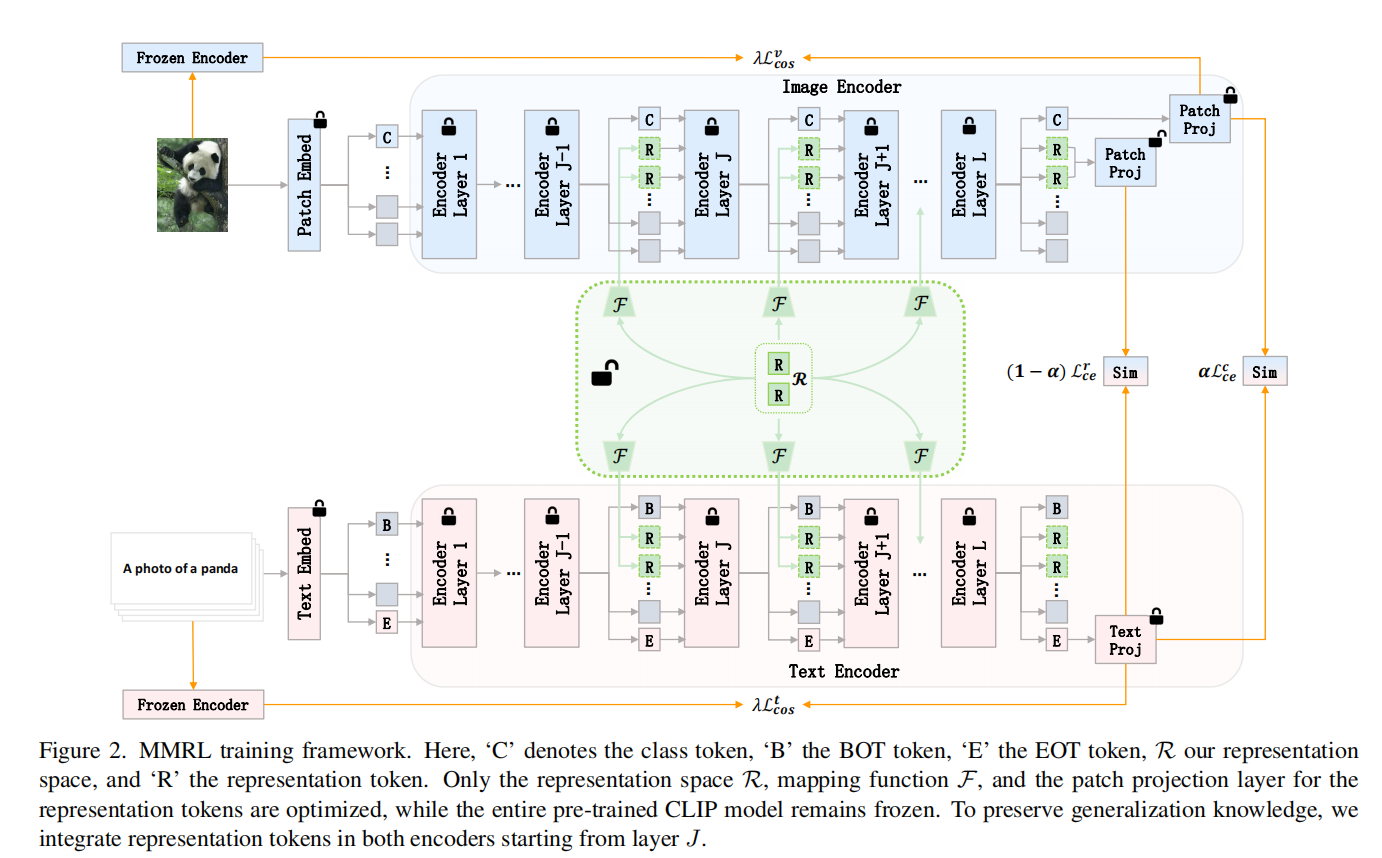
引入跨模态共享的可学习空间 R,通过线性映射生成图像 / 文本表示标记(Rv/Rt),集成于编码器高层(第 J 层起)。
作用:作为多模态交互桥梁,避免文本中心偏差;高层捕捉任务特异性特征,低层保留通用知识,平衡适配与泛化。 -
解耦训练与推理策略
训练:表示标记(R) 可学习以捕捉任务特征,类别标记(C) 冻结并通过余弦正则化对齐预训练特征,保留泛化能力。
推理:基类融合两类特征提升性能,新类仅用类别特征避免过拟合。
意义:分离 “适配” 与 “泛化” 目标,动态选择特征增强新任务泛化。 -
高层集成与正则化
表示标记仅注入高层,避免浅层干扰通用特征(如边缘语义)。
余弦正则化约束类别标记与预训练特征对齐,防止泛化能力下降。
1.2 整体架构
2. 研究背景
-
过拟合问题:微调 VLMs 大规模参数需大量计算资源,且在少样本下易过拟合,导致新任务泛化能力下降。
-
传统方法缺陷:
-
提示学习(如 CoOp)仅优化文本提示或浅层特征,以文本为中心且易干扰预训练的通用知识。
举例:
-
适配器方法(如 MMA)虽引入多模态交互,但仅优化类别标记特征,缺乏对任务特定表示的显式建模。
举例:
-
-
多模态交互不足:现有方法未充分利用图像与文本的深层协同,导致特征对齐不充分或依赖单一模态(如文本主导)。
tip:
提示学习与适配器方法:核心介绍与对比
一、提示学习(Prompt Learning)
- 核心思想:通过可学习的连续向量或离散文本模板(提示)引导模型关注特定任务,冻结模型主体参数以实现轻量级适配。
- 典型方法:
- CoOp:优化文本编码器中的连续提示,保持CLIP参数冻结,适用于少样本分类。
- MaPLe:提出多模态深层提示,通过文本提示映射视觉提示,嵌入编码器低层以增强跨模态对齐。
- 优势:
- 轻量级(参数仅数万到百万级别),适配速度快;
- 无需修改模型结构,兼容预训练VLMs。
- 局限:
- 依赖文本模态,多模态交互不平衡(如文本主导);
- 浅层提示可能干扰预训练的通用特征(如边缘、基础语义)。
二、适配器方法(Adapter Methods)
- 核心思想:在模型高层插入轻量级模块(如MLP),对任务特定特征进行非线性变换,模型主体参数冻结。
- 典型方法:
- CLIP-Adapter:在图像编码器后添加MLP适配器,通过残差连接优化特征,适用于图像任务适配。
- MMA:引入多模态适配器,聚合图像和文本特征到共享空间,支持跨分支梯度流动以增强对齐。
- 优势:
- 高层模块聚焦任务特异性(如细粒度特征),保留低层通用知识;
- 多模态适配器支持图像-文本深度交互。
- 局限:
- 参数略多(百万级别),需正则化防止过拟合;
- 单模态适配器缺乏跨模态协同(如CLIP-Adapter独立处理图像特征)。
三、核心对比
3. 方法论
以下是论文中核心公式的整理与说明(按章节顺序):
3.1 预备知识:CLIP基础公式
-
图像编码器输出
[ c i , E i ] = V i ( [ c i − 1 , E i − 1 ] ) , i = 1 , 2 , … , L [c_i, E_i] = \\mathcal{V}_i([c_{i-1}, E_{i-1}]), \\quad i=1,2,\\dots,L [ci,Ei]=Vi([ci−1,Ei−1]),i=1,2,…,L
- 含义:图像编码器第 i i i层处理输入序列(含类别标记 c c c和补丁嵌入 E E E),输出更新后的标记和特征。
-
图像特征投影
f = P v c ( c L ) f = P_v^c(c_L) f=Pvc(cL)- 含义:将最后一层的类别标记 c L c_L cL通过投影层 P v c P_v^c Pvc映射为图像特征 f f f。
-
文本编码器输出
[ b i , T i , e i ] = W i ( [ b i − 1 , T i − 1 , e i − 1 ] ) , i = 1 , … , L [b_i, T_i, e_i] = \\mathcal{W}_i([b_{i-1}, T_{i-1}, e_{i-1}]), \\quad i=1,\\dots,L [bi,Ti,ei]=Wi([bi−1,Ti−1,ei−1]),i=1,…,L- 含义:文本编码器第 i i i层处理输入序列(含起始标记 b b b、文本标记 T T T、结束标记 e e e)。
-
文本特征投影
w = P t ( e L ) w = P_t(e_L) w=Pt(eL)- 含义:将文本编码器最后一层的结束标记 e L e_L eL投影为文本特征 w w w。
-
余弦相似度与分类概率
sim ( f , w c ) = f ⋅ w c ∣ f ∣ ∣ w c ∣ , p ( y = c ∣ f ) = exp ( sim ( f , w c ) / τ ) ∑ i = 1 C exp ( sim ( f , w i ) / τ ) \\text{sim}(f, w_c) = \\frac{f \\cdot w_c}{|f||w_c|}, \\quad p(y=c|f) = \\frac{\\exp(\\text{sim}(f, w_c)/\\tau)}{\\sum_{i=1}^C \\exp(\\text{sim}(f, w_i)/\\tau)} sim(f,wc)=∣f∣∣wc∣f⋅wc,p(y=c∣f)=∑i=1Cexp(sim(f,wi)/τ)exp(sim(f,wc)/τ)- 含义:计算图像特征与类别文本特征的相似度,通过Softmax得到分类概率。
3.2 MMRL核心公式
-
表示空间投影
R i v = F i v ( R ) , R i t = F i t ( R ) R_i^v = \\mathcal{F}_i^v(R), \\quad R_i^t = \\mathcal{F}_i^t(R) Riv=Fiv(R),Rit=Fit(R)- 含义:将共享表示空间 R R R通过映射函数 F \\mathcal{F} F投影为图像表示标记 R i v R_i^v Riv和文本表示标记 R i t R_i^t Rit。
-
图像编码器高层集成
[ c i , E i ] = V i ( [ c i − 1 , R i − 1 v , E i − 1 ] ) , i = J , … , L − 1 [c_i, E_i] = \\mathcal{V}_i([c_{i-1}, R_{i-1}^v, E_{i-1}]), \\quad i=J,\\dots,L-1 [ci,Ei]=Vi([ci−1,Ri−1v,Ei−1]),i=J,…,L−1
[ c i , R i v , E i ] = V i ( [ c i − 1 , R i − 1 v , E i − 1 ] ) , i = L [c_i, R_i^v, E_i] = \\mathcal{V}_i([c_{i-1}, R_{i-1}^v, E_{i-1}]), \\quad i=L [ci,Riv,Ei]=Vi([ci−1,Ri−1v,Ei−1]),i=L- 含义:从第 J J J层开始,将图像表示标记 R i v R_i^v Riv与类别标记、补丁嵌入拼接后输入Transformer层。
-
文本编码器高层集成
[ b i , T i , e i ] = W i ( [ b i − 1 , R i − 1 t , T i − 1 , e i − 1 ] ) , i = J , … , L [b_i, T_i, e_i] = \\mathcal{W}_i([b_{i-1}, R_{i-1}^t, T_{i-1}, e_{i-1}]), \\quad i=J,\\dots,L [bi,Ti,ei]=Wi([bi−1,Ri−1t,Ti−1,ei−1]),i=J,…,L- 含义:从第 J J J层开始,将文本表示标记 R i t R_i^t Rit插入文本序列前,保留原始文本标记 T i T_i Ti。
-
表示特征计算
r L = Mean ( R L v ) , f r = P v r ( r L ) r_L = \\text{Mean}(R_L^v), \\quad f_r = P_v^r(r_L) rL=Mean(RLv),fr=Pvr(rL)- 含义:对图像表示标记求平均得到 r L r_L rL,通过可训练投影层 P v r P_v^r Pvr生成表示特征 f r f_r fr。
-
损失函数
L MMRL = α L ce c + ( 1 − α ) L ce r + λ ( L cos v + L cos t ) \\mathcal{L}_{\\text{MMRL}} = \\alpha \\mathcal{L}_{\\text{ce}}^c + (1-\\alpha) \\mathcal{L}_{\\text{ce}}^r + \\lambda (\\mathcal{L}_{\\text{cos}}^v + \\mathcal{L}_{\\text{cos}}^t) LMMRL=αLcec+(1−α)Lcer+λ(Lcosv+Lcost)- 组成部分:
- 交叉熵损失: L ce c \\mathcal{L}_{\\text{ce}}^c Lcec(类别特征)、 L ce r \\mathcal{L}_{\\text{ce}}^r Lcer(表示特征)
- 余弦正则化损失: L cos v = 1 − f c ⋅ f 0 ∣ f c ∣ ∣ f 0 ∣ \\mathcal{L}_{\\text{cos}}^v = 1 - \\frac{f_c \\cdot f_0}{|f_c||f_0|} Lcosv=1−∣fc∣∣f0∣fc⋅f0, L cos t = 1 − 1 C ∑ c = 1 C w c ⋅ w 0 c ∣ w c ∣ ∣ w 0 c ∣ \\mathcal{L}_{\\text{cos}}^t = 1 - \\frac{1}{C} \\sum_{c=1}^C \\frac{w^c \\cdot w_0^c}{|w^c||w_0^c|} Lcost=1−C1∑c=1C∣wc∣∣w0c∣wc⋅w0c
- 参数: α \\alpha α平衡两类特征的损失权重, λ \\lambda λ控制正则化强度。
- 组成部分:
-
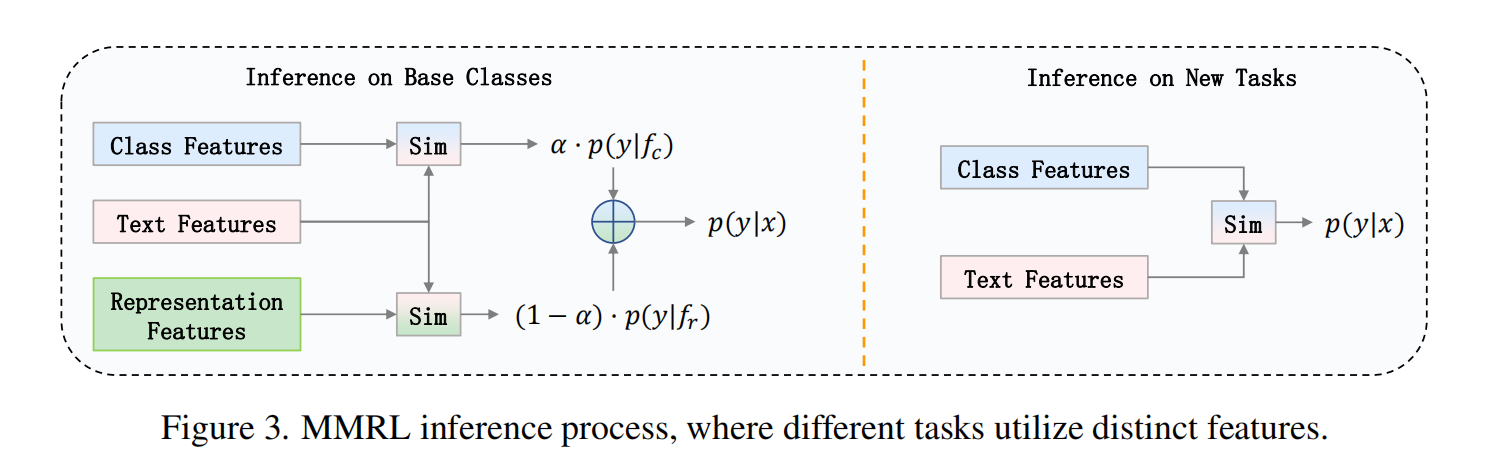
推理阶段概率计算
- 基类:
p ( y = c ∣ x ) = α ⋅ p ( y = c ∣ f c ) + ( 1 − α ) ⋅ p ( y = c ∣ f r ) p(y=c|x) = \\alpha \\cdot p(y=c|f_c) + (1-\\alpha) \\cdot p(y=c|f_r) p(y=c∣x)=α⋅p(y=c∣fc)+(1−α)⋅p(y=c∣fr) - 新类:
p ( y = c ∣ x ) = p ( y = c ∣ f c ) p(y=c|x) = p(y=c|f_c) p(y=c∣x)=p(y=c∣fc)
- 基类:
关键符号说明
- R R R:共享可学习表示空间,维度 K × d r K \\times d_r K×dr
- J J J:表示标记开始集成的编码器层索引(高层层,如 J = 6 J=6 J=6)
- P v c P_v^c Pvc:冻结的类别标记投影层, P v r P_v^r Pvr:可训练的表示标记投影层
- f 0 , w 0 f_0, w_0 f0,w0:冻结CLIP模型的图像和文本特征(用于正则化参考)
4. 结果与分析
- 对比试验
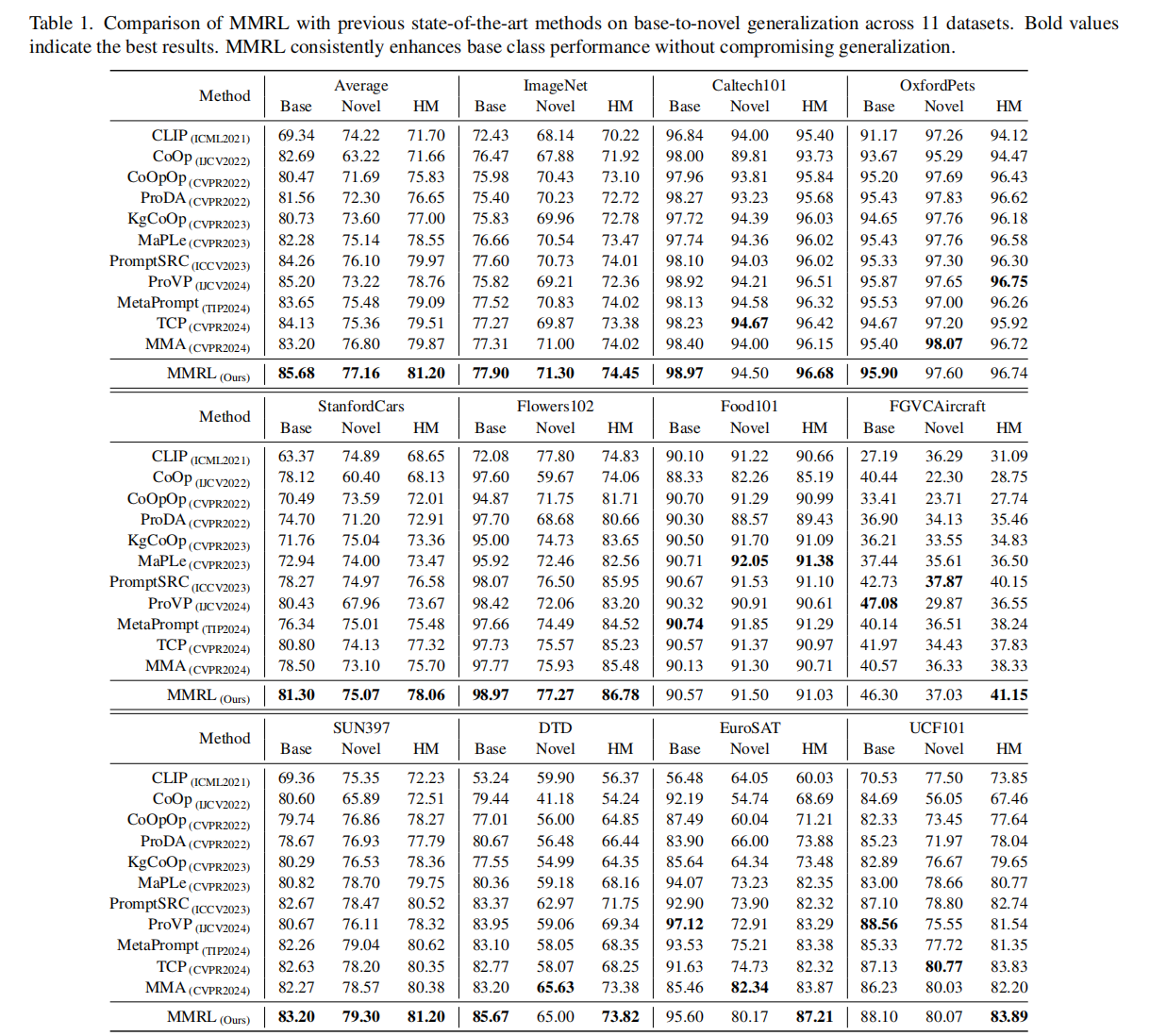
整体性能对比:MMRL全面领先
- 优势显著:MMRL的平均HM达81.20%,比此前SOTA方法MMA提升1.33%,在所有11个数据集上均实现HM最优,展现全面领先性。
- 鲁棒性:在图像分类(ImageNet)、细粒度分类(StanfordCars)、场景分类(SUN397) 等不同类型任务中均表现优异,说明其泛化能力不依赖特定数据类型。
基类性能:任务特定适配能力强
- 关键发现:
- 细粒度任务优势:在StanfordCars(汽车型号分类)、FGVCAircraft(飞机型号) 等细粒度数据集MMRL基类准确率分别达81.30%和46.30% ,远超MMA的78.50%和40.57%,表明其高层表示标记能有效捕捉细粒度差异。
- 领域差异鲁棒性:在卫星图像数据集EuroSAT中,MMRL基类提升超10%,说明其对特殊领域(如遥感图像)的适配能力更强。
新类性能:泛化能力与预训练知识保留
- 关键发现:
- 平衡能力:MMRL在提升基类性能的同时,新类准确率平均提升0.36%,未出现传统方法(如CoOp)因过拟合导致的新类下降(如CoOp在ImageNet新类仅63.22%)。
- 领域泛化差异:在纹理分类DTD数据集上,MMRL新类略低于MMA,可能因纹理特征更依赖低层通用信息,而MMRL高层集成策略对低层扰动较小,需结合更多低层特征优化(未来可探索分层集成)。
调和均值(HM):基类与新类的均衡指标
- 均衡性验证:
MMRL的HM在ImageNet、StanfordCars、SUN397等差异较大的数据集上均超过80%,且与MMA的平均差距达1.33%,证明其有效平衡了任务适配与泛化能力,避免了“基类强、新类弱”的 trade-off。
与提示学习/适配器方法的对比启示
- 核心差异:
MMRL通过高层多模态表示学习+类别标记正则化,既利用表示标记捕捉任务特异性(类似适配器),又通过冻结类别标记并对齐预训练特征(类似提示学习的泛化保留),实现两类方法的优势融合。
- 消融实验
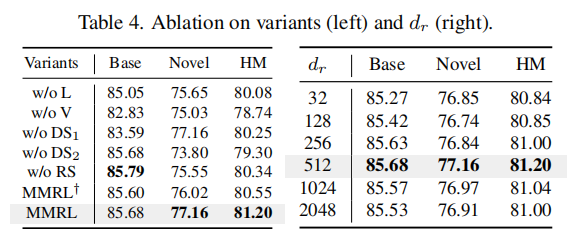
核心消融项分析
文本表示标记(L)的必要性:w/o L
- 操作:移除文本模态的表示标记 R t R^t Rt,仅保留图像表示标记 R v R^v Rv。
- 性能变化:
- 调和均值(HM)下降 1.64%(81.20% → 79.56%),新类准确率下降 1.81%(82.84% → 81.03%)。
- 基类准确率下降 1.44%(79.56% → 78.12%)。
- 原因:
- 文本表示标记是跨模态交互的核心载体,缺失后模型难以将文本语义(如类别描述)与图像特征对齐,导致新类(依赖文本描述的少样本分类)泛化能力显著下降。
- 基类性能下降表明,文本标记对巩固基类知识(如CLIP预训练的语义先验)也有辅助作用。
图像表示标记(V)的必要性:w/o V
- 操作:移除图像模态的表示标记 R v R^v Rv,仅保留文本表示标记 R t R^t Rt。
- 性能变化:
- HM下降 2.72%(81.20% → 78.48%),基类准确率下降 2.67%(79.56% → 76.89%)。
- 新类准确率下降 2.73%(82.84% → 80.11%)。
- 原因:
- 图像表示标记是捕捉任务特定视觉特征的关键组件,缺失后模型过度依赖文本先验,在视觉主导的任务(如细粒度图像分类)中易出现语义偏差,导致基类过拟合、新类泛化不足。
共享表示空间(RS)的必要性:w/o RS
- 操作:图像和文本表示标记独立初始化(非共享空间),放弃多模态协同学习。
- 性能变化:
- HM下降 3.52%(81.20% → 77.68%),新类准确率大幅下降 6.52%(82.84% → 76.32%)。
- 基类准确率仅下降 0.46%(79.56% → 79.10%)。
- 原因:
- 共享表示空间是实现图像-文本平衡交互的基础,独立初始化会导致模态特征分布差异显著(如文本空间偏语义、图像空间偏视觉),模型难以在新类中建立跨模态关联,尤其在少样本场景下泛化能力暴跌。
解耦策略₁(DS₁)的必要性:w/o DS₁
- 操作:解冻类别标记投影层 P v c P_v^c Pvc(默认冻结),与表示标记共同优化。
- 性能变化:
- HM下降 4.12%(81.20% → 77.08%),基类准确率下降 4.33%(79.56% → 75.23%)。
- 新类准确率下降 3.82%(82.84% → 79.02%)。
- 原因:
- 类别标记(如CLIP预训练的类别嵌入)存储了通用语义知识,解冻后模型在训练中过度拟合基类数据,丢失预训练的泛化能力(如零样本迁移能力),导致基类和新类性能双降。
- 验证了解耦策略(冻结类别标记+正则化表示标记)的必要性,避免“旧知识遗忘”和“新知识过拟合”。
解耦策略₂(DS₂)的必要性:w/o DS₂
- 操作:移除表示标记的正交正则化约束(默认通过正交损失强制表示标记互不干扰)。
- 性能变化:
- HM下降 3.28%(81.20% → 77.92%),新类准确率下降 4.30%(82.84% → 78.54%)。
- 基类准确率下降 2.25%(79.56% → 77.31%)。
- 原因:
- 无正交约束时,表示标记之间可能产生语义冗余或冲突(如不同标记编码相似特征),导致模型难以有效区分任务相关特征,尤其在新类(样本少、特征区分度要求高)中表现恶化。
有偏多模态对照(MMRL†)
- 操作:强制模型优先依赖图像特征(如增大图像分支权重),模拟实际应用中可能的模态偏差。
- 性能变化:
- HM下降 2.37%(81.20% → 78.83%),新类准确率下降 3.63%(82.84% → 79.21%)。
- 原因:
- 多模态偏差会破坏图像-文本的语义平衡,模型过度依赖视觉特征,忽略文本描述的细粒度语义(如类别间的细微差异),导致新类(依赖文本语义的少样本分类)性能下降。
总结:消融实验的核心结论
- 表示标记(L/V)是MMRL的核心组件:
- 文本标记驱动跨模态语义对齐,图像标记捕捉视觉特征,缺一不可,缺失任意一方均导致HM下降超1.5%。
- 共享表示空间(RS)是跨模态协同的基础:
- 独立模态空间会导致语义鸿沟,新类准确率暴跌6.52%,证明多模态统一建模的必要性。
- 解耦策略(DS₁/DS₂)是性能保障:
- 冻结类别标记(DS₁)避免预训练知识污染,正交正则化(DS₂)提升表示标记的特征区分度,两者共同作用使HM提升3-4%。
- 模态平衡至关重要:
- 有偏多模态设计(MMRL†)验证了模型对模态均衡性的敏感性,强调图像-文本需协同优化而非单一模态主导。

