双目视频3D采集与显示技术项目实操指南
本文还有配套的精品资源,点击获取 
简介:本项目深入探讨了3D采集与显示技术在虚拟现实和增强现实中的应用。采用C#语言在Visual Studio 2010环境下开发,使用双目摄像头技术实现立体视觉效果,为用户提供实时3D体验。项目涵盖了从摄像头同步、图像采集、特征匹配、视差计算、深度恢复到3D显示等多个关键步骤,并注重实时处理优化,以实现高效的3D视频处理和显示。
1. 双目视频3D采集原理
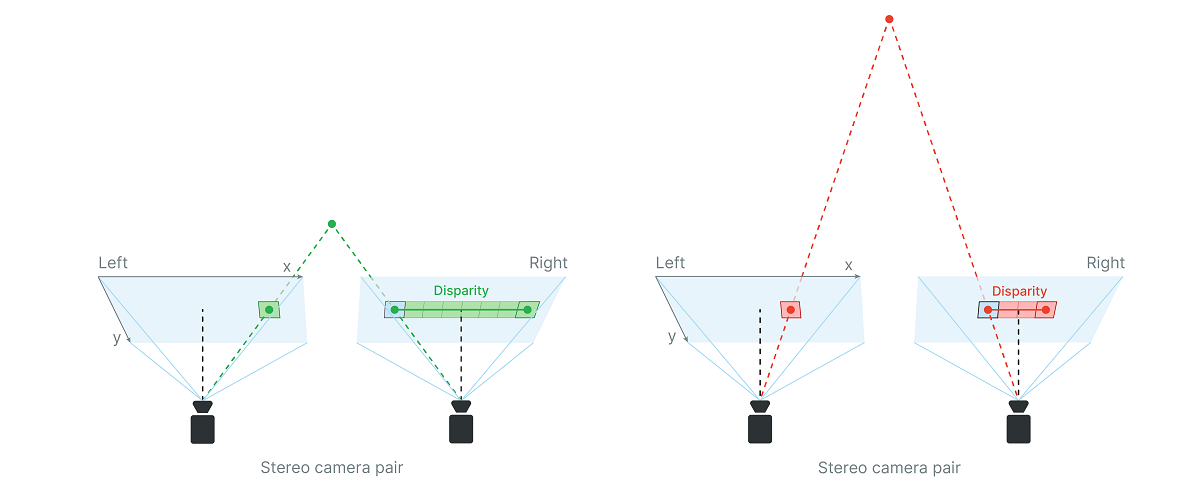
3D视频技术的核心在于模拟人类的双眼视觉系统,通过双目摄像机同时捕捉两幅从不同视角拍摄的图像,进而对两幅图像进行分析以生成具有深度信息的3D视觉效果。双目视频3D采集原理主要涉及到图像的获取、图像的校正、特征点匹配、视差计算以及深度信息的恢复。
在获取图像的过程中,需要确保两个摄像头同步工作,捕捉到的时间戳接近的图像对。接着,图像的校正是关键一步,它通过几何变换等手段修正由于摄像头位置差异所带来的图像偏差,为后续的处理工作提供准确的图像对。
特征点匹配阶段,算法需要找出两幅图像中的对应点,这是计算视差的基础。通过比较左右图像同一物体的特征点位置差异,我们能够获得视差图,进而推算出每个像素点的深度信息。最终,深度信息的恢复利用视差信息,构建出3D场景模型。这一过程是双目视频3D采集原理的核心内容,需要准确、高效的算法来实现。
2. C#在3D视频技术中的应用
2.1 C#开发环境与3D视频技术的结合
2.1.1 C#语言特性与3D技术的融合
C#作为一门现代编程语言,其在3D视频技术中的应用体现了多种语言特性与3D技术的融合。首先,C#的面向对象编程(OOP)特性使得复杂的3D场景可以被模块化和封装成易于管理的类和对象。这样不仅提高了代码的可重用性,也便于维护和扩展。
其次,C#的内存管理机制,包括自动垃圾回收和类型安全,允许开发者专注于算法和创意实现,而不必担心底层内存管理问题。此外,.NET Framework以及.NET Core平台提供了大量的类库支持,如System.Drawing和System.Windows.Media,这些库极大地简化了图像处理和3D渲染任务。
2.1.2 C#开发环境搭建及配置
搭建一个合适的C#开发环境对于3D视频技术的开发至关重要。首先,需要安装Visual Studio,这是微软官方的集成开发环境(IDE),支持C#语言开发。在Visual Studio中,开发者可以创建、编辑、编译和调试C#程序。
在搭建开发环境时,还应该考虑安装DirectX SDK或安装Windows SDK来获取与图形处理相关的API和工具。确保.NET Framework或.NET Core运行时环境已经安装,这样可以运行用C#编写的3D视频应用程序。Visual Studio中的NuGet包管理器也可以用来安装第三方库,以进一步支持3D图形和视频处理的功能。
2.2 C#在双目视频采集中的应用实例
2.2.1 视频捕获的编程接口
C#通过Emgu CV等库可以访问OpenCV的全部功能,为视频捕获提供了强大的编程接口。以下代码展示了如何使用Emgu CV在C#中捕获视频帧:
// 创建视频捕获对象,参数为视频源地址或摄像头IDusing var capture = new Capture(0);// 释放资源try{ while (true) { // 从视频捕获对象中获取下一帧 using var frame = capture.QueryFrame(); if (frame == null) break; // 如果没有获取到帧,则退出循环 // 显示帧 CvInvoke.Imshow(\"Video Capture\", frame); // 等待按键,参数为等待时间(毫秒),这里设置为无限等待 if (CvInvoke.WaitKey(0) >= 0) break; }}finally{ capture.Dispose(); // 释放视频捕获对象资源}2.2.2 实时视频流处理技术
在处理实时视频流时,C#结合Emgu CV可以进行高效的帧处理。对于双目视频系统,我们需要同步两个摄像头的视频流,计算每一帧的视差,并最终生成3D场景。以下是一个简化示例,展示如何同步两个视频流,并计算视差:
// 此段代码仅为示例,并非完整可运行代码using var leftCapture = new Capture(leftCamId);using var rightCapture = new Capture(rightCamId);try{ while (true) { using var leftFrame = leftCapture.QueryFrame(); using var rightFrame = rightCapture.QueryFrame(); // 确保左右帧都成功获取 if (leftFrame == null || rightFrame == null) break; // 进行帧的预处理和视差计算 var disparity = ComputeDisparity(leftFrame, rightFrame); // 显示帧和视差图 CvInvoke.Imshow(\"Left Frame\", leftFrame); CvInvoke.Imshow(\"Disparity\", disparity); if (CvInvoke.WaitKey(0) >= 0) break; }}// ... 其他异常处理和资源释放代码 ...此代码段通过调用Emgu CV的函数来处理视频帧,包括查询和显示视频帧以及计算视差。
2.3 C#在3D显示技术中的应用实例
2.3.1 3D图形界面的开发
Windows Presentation Foundation(WPF)是.NET框架的一部分,提供了用于构建富客户端应用程序的用户界面框架。使用WPF,可以创建具有高度交互性和3D效果的图形界面。以下是使用WPF创建一个简单3D图形界面的示例:
上述XAML代码定义了一个3D场景,其中包含了摄像机、光源和一个3D模型。开发者可以在C#后端代码中进一步编程以创建具体的3D模型,并将其赋值给 cubeModel 。
2.3.2 3D渲染技术与C#结合的技巧
为了实现高质量的3D渲染,C#可以利用WPF的3D图形功能进行高级渲染技术的开发。例如,可以结合XAML和C#代码来动态创建3D对象,并利用WPF的渲染管道进行渲染。这不仅包括了简单的几何体,还包括了复杂的模型和材质的处理。
此外,借助于DirectX技术的封装和集成,C#开发者可以使用WPF结合Direct3D来实现更为高级和性能优越的3D渲染。以下是一个C#代码示例,展示了如何在WPF应用程序中使用Direct3D进行3D渲染:
// 此代码段展示了如何在WPF应用中初始化Direct3D渲染public MainWindow(){ InitializeComponent(); var d3dImage = new D3DImage(); // 设置D3DImage的渲染回调函数 d3dImage.Lock(); // 在这里调用Direct3D的渲染方法,渲染图像到d3dImage d3dImage.Unlock(); // 将渲染好的图像赋值给一个Image控件的Source属性,从而显示在界面上 MyImage.Source = d3dImage;}此代码段仅为示例,详细实现会涉及到Direct3D的初始化、渲染循环、资源管理和渲染技术等复杂的内容。
以上就是C#在双目视频采集和3D显示技术应用中的部分实例,通过这些实例,我们可以看到C#在3D视频技术领域中所扮演的重要角色,它为开发者提供了一个强大、灵活且易于使用的平台,以实现高质量的3D视频应用。
3. 摄像头同步技术
3.1 同步技术的基本原理与重要性
3.1.1 摄像头同步的定义和目的
摄像头同步指的是在双目或更多摄像头的系统中,通过某种机制确保每个摄像头捕获的图像数据在时间上保持一致性的过程。这种同步对于生成高质量的3D图像至关重要,因为任何时间上的偏差都会导致视差计算错误,进而影响深度信息的准确性。
同步技术可以应用于不同的层面,包括图像捕获、图像传输、图像处理等。在捕获层面,确保了摄像头在相同的时间点开始曝光,捕获对应帧。在传输层面,保证了图像数据在传输过程中的顺序和时间间隔的一致性。在处理层面,则需要确保图像数据被正确地对齐并同时处理。
3.1.2 同步技术对3D采集质量的影响
同步技术的实施直接影响到3D视频采集的质量。若同步控制不当,可能会导致采集的视频帧之间存在时间上的差异,进而产生“鬼影”或图像错位现象。这会严重影响3D视频的观看体验,特别是在快速移动的场景中。
举一个简单的例子,如果一组摄像头在捕获运动物体时不同步,那么运动物体在每一帧中的位置将不同,导致视差计算结果错误。这样的错误视差数据会导致深度映射失真,最终影响3D模型的构建质量。因此,实施精确的同步技术对于生成高质量的3D内容是必不可少的。
3.2 摄像头同步的实现方法
3.2.1 硬件同步技术的原理与实现
硬件同步技术通常依赖于摄像头硬件本身或外部硬件设备提供的同步信号。最常见的一种硬件同步是使用红外或可见光同步脉冲信号,通过这种方式,所有的摄像头都能够在接收到同步脉冲时同时触发曝光和捕获过程。
还有一种同步方法是使用专用的同步设备,如Genlock(时钟锁定)和Tri-Level Sync(三电平同步信号),这些设备可以确保视频信号在多个摄像头间保持严格的时序一致性。这些硬件同步技术虽然成本较高,但能够提供非常精确的时间对齐,特别是在需要高精度3D重建的应用场合。
3.2.2 软件同步技术的原理与实现
软件同步技术是通过软件层面控制和管理图像捕获与处理的过程来实现的。这种同步方式通常依赖于摄像头驱动提供的接口,或者是操作系统层面的支持。
一种常见的软件同步方法是利用摄像头的帧捕捉事件来触发其他摄像头的捕获过程。通过编程控制,当主摄像头捕获到新帧时,其他摄像头立即开始捕获下一帧,这样可以保证所有摄像头捕获的帧序列具有相似的时序特性。
另一个软件同步技术的实现途径是使用高精度时钟计数器。通过记录每帧图像捕获的确切时间,软件可以对图像进行排序和时间校正,以消除时间上的差异。这种方法对硬件的时间戳精度和软件的处理能力要求较高,但对于降低硬件成本有显著优势。
摄像头同步技术是3D视频采集系统中不可或缺的一环。硬件同步技术能够提供精确的时间对齐,但其成本较高;软件同步技术虽然成本较低,但可能依赖于特定的硬件和软件环境,并且可能需要更多的优化来达到相似的精度。无论采用哪种方法,同步技术都对保证最终3D视频的质量具有决定性作用。
4. 图像采集与处理流程
4.1 图像采集的基础知识
在3D视频技术中,图像采集是一个至关重要的步骤。它不仅影响到最终图像的质量,也决定了后续处理流程的有效性。图像采集过程涉及到对现实世界中场景的物理光线进行数字化,这一过程涉及到像素与帧的捕获。
4.1.1 像素与帧的采集原理
图像采集设备如摄像头通过其感光元件(例如CCD或CMOS传感器)捕获外部光线,并将其转换为电信号,这些电信号经过模数转换器(ADC)转化为数字信号,形成图像数据。每个数字信号都对应图像中的一个像素点,而连续的帧构成了动态视频。
在双目视频采集系统中,两个摄像头同时捕获的两帧图像必须保持时间上和空间上的对齐,以便于后续的视差计算和深度信息恢复。为了达到这一目标,图像采集设备的选择和设置就显得尤为重要。
4.1.2 图像采集设备的选择与设置
选择合适的图像采集设备是实现高质量3D视频采集的前提。理想情况下,摄像头应该具备高分辨率、高帧率、低噪声特性,并支持精确的硬件同步功能。而设置方面,需要调整摄像头的焦距、亮度、对比度等参数,确保双目摄像头在拍摄过程中获得最佳的同步效果和图像质量。
例如,通过调整焦距可以改变视野范围,影响视差的大小;通过调整亮度和对比度可以改善图像质量,便于特征点检测和匹配。对于设备的具体设置,需根据实际场景的需求和设备的性能进行综合考量。
4.2 图像预处理技术
图像采集后通常会伴随着各种噪声和失真,因此在进行进一步的特征点检测和视差计算之前,需要对图像进行预处理。预处理的目标是增强图像质量,减少后续处理流程中可能出现的错误。
4.2.1 噪声去除与对比度增强
噪声去除是图像预处理中的一个基础步骤,它能减少随机的信号变化,提升图像的清晰度。常见的噪声去除方法有高斯滤波、中值滤波等。高斯滤波通过平滑处理,可以有效地减少随机噪声,但同时也会模糊边缘细节;中值滤波则能较好地保持边缘信息,同时去除椒盐噪声。
对比度增强是指调整图像的亮度和对比度,使图像的细节更加突出。可以通过直方图均衡化或局部对比度增强技术来实现。直方图均衡化是一种简单有效的增强方法,它通过对图像的全局直方图进行操作,使得图像的亮度分布更加均匀。
4.2.2 图像的校正与几何变换
图像校正通常指的是解决图像中的失真问题,例如镜头畸变。几何变换则涉及到图像的旋转、缩放等操作。校正和变换能够帮助将双目摄像头采集到的图像对齐到一个共同的参考平面,便于后续的深度信息计算。
几何变换通常使用仿射变换、透视变换等数学方法。仿射变换可以实现图像的旋转、缩放、平移等操作,而透视变换则可以校正由于摄像头位置和角度不同造成的图像变形问题。
4.3 图像处理的高级技术
图像采集与预处理之后,便可以使用高级的图像处理技术对图像进行进一步的分析和处理。这一部分的技术能够极大地提升3D视频的质量,是实现高质量3D显示的关键环节。
4.3.1 图像增强算法
图像增强算法主要用于提升图像的视觉效果,加强图像的某些特征,如边缘、纹理等。其中,边缘检测是一个重要的图像增强技术,它通过提取图像中的边缘信息来增强视觉效果,常用的方法有Sobel算子、Canny边缘检测算子等。
4.3.2 图像压缩与存储技术
随着双目视频采集数据量的增加,存储和传输成为了一个挑战。因此,高效且损失可控的图像压缩技术成为了一种必要。目前,主流的图像压缩方法有JPEG、PNG和WebP等。它们通过不同的编码和解码算法来减少图像数据的大小,同时尽量保持图像质量。
在图像压缩的同时,还必须考虑存储的优化问题。选择合适的存储介质、存储格式和存储协议,可以大幅提升3D视频数据的存取效率和稳定性。
通过以上章节的介绍,我们可以看到图像采集与处理流程涉及了从原始图像捕获到图像质量提升的一系列过程。接下来的章节将探讨如何在图像处理中进一步提取3D信息,实现3D视频的深度感知。
5. 特征点检测与匹配方法
在3D视频技术中,特征点检测与匹配方法是实现准确三维重建的关键步骤。这一过程涉及从不同视角拍摄的图像中识别和匹配共同的特征点,为之后的视差计算提供基础数据。
5.1 特征点检测技术概述
5.1.1 特征点检测的理论基础
特征点检测是指在图像中识别具有显著特征的点,如角点、边缘、纹理等。这些点应具备足够的区分度,能够在不同图像中被稳定地识别和匹配。常用的理论基础包括Harris角点检测、Shi-Tomasi角点检测以及基于尺度不变特征变换(SIFT)和加速稳健特征(SURF)的方法。
5.1.2 常用的特征点检测算法
Harris角点检测算法 是一种经典的角点检测方法,它基于图像梯度信息,通过计算像素点邻域内梯度的乘积矩阵来识别角点。Harris角点检测的优点在于其对图像旋转、尺度变化的不变性,以及对局部光照变化的鲁棒性。
SIFT特征检测算法 通过提取局部特征描述符,能够实现图像之间的特征匹配。SIFT特征具有尺度不变性、旋转不变性,并且对仿射变换和光照变化有很强的鲁棒性。
// 示例代码:Harris角点检测实现void HarrisCornerDetection(const cv::Mat &inputImage) { cv::Mat grayImage; cv::cvtColor(inputImage, grayImage, cv::COLOR_BGR2GRAY); cv::Mat corners = cv::Mat::zeros(grayImage.size(), CV_32FC1); // 使用Harris角点检测函数 cv::cornerHarris(grayImage, corners, 2, 3, 0.04); // 对结果进行膨胀,便于角点的提取和可视化 cv::Mat dilatedCorners; cv::dilate(corners, dilatedCorners, cv::Mat()); // 根据阈值来提取角点 double threshold = 0.01 * dilatedCorners.max(); cv::Mat corners_binary; dilatedCorners > threshold ? (corners_binary = 255) : (corners_binary = 0); // 显示结果 cv::imshow(\"Harris Corners\", corners_binary); cv::waitKey(0);} 代码分析:上述代码使用了OpenCV库来实现Harris角点检测。首先将输入的彩色图像转换为灰度图像,然后通过调用 cornerHarris 函数计算角点。之后使用 dilate 函数对检测到的角点进行膨胀,以便能够更容易地提取和可视化角点。最后,根据设定的阈值来区分角点和非角点区域,并显示结果。
5.2 特征匹配的策略与实现
5.2.1 匹配算法的选择与原理
特征匹配是指找到两幅图像中相对应的特征点的过程。常用的匹配算法有暴力匹配法、基于距离的匹配、FLANN匹配器以及基于机器学习的方法等。暴力匹配法简单直接,但效率较低;而FLANN(Fast Library for Approximate Nearest Neighbors)匹配器则适合大数据集的快速匹配。
5.2.2 实际应用中的特征匹配技术
在实际应用中,特征匹配的准确性直接影响到三维重建的质量。SIFT或SURF等算法不仅可以检测特征点,还可以生成用于特征匹配的描述符。通过计算不同图像间特征描述符的相似度,可以实现精确的特征点匹配。
// 示例代码:使用SIFT进行特征匹配void SIFTMatching(const cv::Mat &img1, const cv::Mat &img2) { // 使用SIFT检测器 cv::Ptr detector = cv::xfeatures2d::SIFT::create(); std::vector keypoints1, keypoints2; cv::Mat descriptors1, descriptors2; // 检测并计算特征描述符 detector->detectAndCompute(img1, cv::noArray(), keypoints1, descriptors1); detector->detectAndCompute(img2, cv::noArray(), keypoints2, descriptors2); // 使用FLANN进行匹配 cv::FlannBasedMatcher matcher; std::vector matches; matcher.match(descriptors1, descriptors2, matches); // 选择最佳匹配点 double max_dist = 0; double min_dist = 100; for (int i = 0; i < descriptors1.rows; i++) { double dist = matches[i].distance; if (dist max_dist) max_dist = dist; } // 绘制匹配结果 cv::Mat img_matches; cv::drawMatches(img1, keypoints1, img2, keypoints2, matches, img_matches); cv::imshow(\"SIFT Matching\", img_matches); cv::waitKey(0);} 代码分析:示例代码使用了OpenCV的xfeatures2d模块中的SIFT算法进行特征检测和描述符计算。在两幅图像上分别检测特征点并计算描述符后,使用FLANN匹配器找到匹配点。然后通过计算匹配点之间的距离,选择出最佳匹配对,并使用 drawMatches 函数在原图上绘制匹配结果。
通过上述章节内容的介绍,我们深入探讨了特征点检测与匹配方法在3D视频技术中的作用和应用实例。下一章节将继续探讨视差计算与深度信息恢复的高级技术,敬请期待。
6. 视差计算与深度信息恢复
6.1 视差计算的数学模型
6.1.1 视差的定义及其计算方法
视差是指同一场景中,两个摄像机因位置不同所拍摄的图像间像素位置的差异。在双目视觉系统中,视差计算是关键步骤,是实现深度信息恢复的基础。通过计算左右相机图像之间的视差,我们可以推算出场景中物体的距离信息。
为了理解视差的计算方法,我们先需要熟悉一些基础概念。对于双目系统中的两个摄像机,我们将它们的对极几何约束作为计算视差的基础。对极几何关系说明了两个视点之间的几何约束,其本质是一个线性关系,可以由基础矩阵(F Matrix)或本质矩阵(E Matrix)来表示。在理想情况下,当两个摄像机的内参和外参都已知时,可以精确地计算出每个像素点的视差值。
在实际操作中,视差的计算方法包括局部匹配和全局优化两大类。局部匹配方法以块匹配(Block Matching)算法为代表,这类算法简单快捷,但在无纹理区域或者重复纹理区域容易产生错误匹配。全局优化方法如图割(Graph Cuts)和置信传播(Belief Propagation)算法,通过能量最小化的方式进行视差计算,通常可以获得更准确的结果,但计算开销较大。
代码块示例:块匹配算法实现视差计算的基本步骤
public class BlockMatching{ // 参数说明:leftImage 和 rightImage 是左右图像; // blockSize 表示匹配块的大小;maxDisparity 是最大视差值。 public int[,] ComputeDisparity(Image leftImage, Image rightImage, int blockSize, int maxDisparity) { int[,] disparityMap = new int[leftImage.Width, leftImage.Height]; for (int y = blockSize; y < leftImage.Height - blockSize; y++) { for (int x = blockSize; x < leftImage.Width - blockSize; x++) { int bestDisparity = -1; int bestMatch = int.MaxValue; // ...此处省略了匹配块计算最佳视差值的细节... } } return disparityMap; }}6.1.2 视差图的生成技术
视差图是表示图像中每个像素点视差值的二维数组,通过将视差值映射到不同的颜色上,可以直观地观察到图像的深度信息。生成视差图的常见技术包括半全局匹配(Semi-Global Matching, SGM)算法和深度学习方法。
SGM算法结合了局部匹配和全局优化的优势,它将二维图像的匹配问题转化为沿多个一维路径的匹配问题,然后将这些路径的匹配代价进行组合,得到最终的视差值。SGM算法在准确度和鲁棒性方面表现优秀,但计算复杂度较高。
近年来,随着深度学习技术的发展,基于深度学习的视差图生成方法逐渐成为研究热点。通过训练深度卷积神经网络(CNN),可以让网络学习到从图像到视差图的映射关系,这类方法在某些场景下可以取得超越传统算法的效果。
mermaid流程图:SGM算法处理流程示例
graph LR A[开始] --> B[图像预处理] B --> C[初始化路径匹配代价] C --> D[沿路径计算累积代价] D --> E[应用Potts势优化累积代价] E --> F[路径间代价组合] F --> G[视差计算与优化] G --> H[生成视差图] H --> I[结束]6.2 深度信息的恢复与应用
6.2.1 深度信息与视差的关系
深度信息是指场景中每个点到摄像机的距离,视差与深度之间存在反比的关系。具体来说,当视差值越大,说明物体离摄像机越近;反之,则越远。这一关系可以用以下公式描述:
Z = (f * B) / D
其中,Z是物体到摄像机的距离(深度信息),f是摄像机的焦距,B是摄像机之间的基线距离(即左右摄像机镜头中心之间的距离),D是视差值。通过这个公式,我们可以看到,要获取准确的深度信息,我们需要知道摄像机的焦距和基线距离,以及计算出准确的视差值。
6.2.2 深度图的生成与应用实例
深度图是将深度信息可视化的一种方式,通常通过颜色编码来表示不同深度的值。深度图可以帮助我们直观地理解场景的三维结构,是三维重建、机器人导航、增强现实(AR)和虚拟现实(VR)等地方的重要技术基础。
生成深度图通常基于视差图,根据视差与深度的关系,我们可以将每个像素点的视差值转换成深度值。以下是使用C#实现深度图生成的一个简单示例:
代码块示例:生成深度图
public Image GenerateDepthMap(int[,] disparityMap, double focalLength, double baseline){ int width = disparityMap.GetLength(0); int height = disparityMap.GetLength(1); Bitmap depthMap = new Bitmap(width, height); for (int y = 0; y < height; y++) { for (int x = 0; x < width; x++) { int disparity = disparityMap[x, y]; double depth = (focalLength * baseline) / disparity; // ...此处省略了将深度值映射到颜色的过程... depthMap.SetPixel(x, y, Color.FromArgb(depthColor)); } } return depthMap;}在实际应用中,深度图可以用于许多领域。例如,在自动驾驶汽车中,深度图可以帮助识别前方障碍物的距离,从而做出避障决策。在3D重建中,深度图可以结合三角测量法,恢复出物体的三维模型。在AR应用中,深度图可以辅助虚拟物体与真实世界场景的准确叠加。
在本章中,我们详细介绍了视差计算的数学模型和深度信息的恢复方法。通过这些技术,我们可以有效地从双目视频中提取出3D结构信息,并将其应用到各种实际问题中去。下一章将介绍摄像头同步技术,这是实现高质量3D视频采集的又一关键技术。
7. 3D显示技术实施
随着双目视频3D采集技术的发展,3D显示技术也日渐成熟,它为用户带来了更加生动、立体的视觉体验。了解3D显示技术的基本概念和实际应用对于构建一个完整的3D视频系统至关重要。
7.1 3D显示技术的基本概念
7.1.1 3D显示的分类与原理
3D显示技术可以分为两大类:有眼镜的3D显示技术和裸眼3D显示技术。有眼镜的3D显示技术主要是通过特殊的3D眼镜(如偏光眼镜或快门眼镜)来实现立体视觉,而裸眼3D显示则利用视差屏障、柱状透镜或全息技术来直接呈现3D图像,无需佩戴特殊眼镜。
有眼镜的3D技术原理包括:
- 偏光式3D :使用偏光眼镜和偏光显示器,左右眼分别接收不同极化的图像,由于两眼的视点不同,从而产生立体感。
- 快门式3D :通过快速交替左右眼的图像,并使用电子快门眼镜同步地遮挡另一只眼,从而让每只眼睛只看到对应的图像。
裸眼3D技术原理包括:
- 视差屏障 :在屏幕前放置具有小孔或条纹的屏障,控制每个像素点的可见区域,使左右眼只能看到对应的图像。
- 柱状透镜 :利用柱状透镜阵列来引导光线,为每个视点生成不同的图像,每个视点的图像对应不同的观看角度。
- 全息技术 :通过记录和再现光线波前信息,用户可以从不同角度看到不同的图像,从而产生3D效果。
7.1.2 3D显示对观看体验的影响
3D显示技术不仅增加了视觉深度,还提升了观看的沉浸感。与传统2D显示相比,3D技术可以更好地模拟现实世界的三维空间,使得观看体验更接近于真实世界。然而,3D显示技术也带来了一些挑战,如观看角度的限制、长时间观看可能导致的视觉疲劳等。
7.2 3D显示技术的实际应用
7.2.1 3D显示器的工作原理与选择
3D显示器根据显示技术的不同,其工作原理也有所差异。例如,快门式3D显示器通常拥有高刷新率,以确保左右眼图像交替的流畅性;而视差屏障式3D显示器则通过特殊面板技术实现3D效果。在选择3D显示器时,需要考虑显示器的分辨率、可视角度、刷新率、是否支持3D眼镜以及价格等因素。
7.2.2 3D内容的制作与播放技术
制作3D内容需要对每一帧进行立体渲染,确保左右眼视图有恰当的视差。现代3D制作软件提供了方便的工具,帮助内容创作者构建3D场景。而在播放3D内容时,重要的是要保证播放设备支持3D内容的解码和输出。例如,一些3D蓝光播放器和游戏主机能够直接播放3D蓝光电影或运行3D游戏内容。
此外,为了获得更好的用户体验,开发者和制造商也在不断创新,例如开发能够自动追踪用户头部位置的显示器,从而无需佩戴眼镜即可享受3D效果。
3D显示技术的应用正逐渐扩展到各个领域,包括电影娱乐、游戏、教育、医疗等,这为用户带来前所未有的视觉体验。随着技术的不断进步,我们可以预见未来3D显示技术将变得更加高效、便携且具有更高的用户体验度。
通过以上的分析,我们可以看到第七章从3D显示技术的分类、原理到实际应用,为读者提供了一个全面的认识。在下一章节中,我们将深入探讨实时3D处理面临的挑战及优化策略。
本文还有配套的精品资源,点击获取
简介:本项目深入探讨了3D采集与显示技术在虚拟现实和增强现实中的应用。采用C#语言在Visual Studio 2010环境下开发,使用双目摄像头技术实现立体视觉效果,为用户提供实时3D体验。项目涵盖了从摄像头同步、图像采集、特征匹配、视差计算、深度恢复到3D显示等多个关键步骤,并注重实时处理优化,以实现高效的3D视频处理和显示。
本文还有配套的精品资源,点击获取


