Elasticsearch8(ES)保姆级菜鸟入门教程_elasticsearch菜鸟教程
ps:还没安装ES的可以查看,ES8下载安装教程
Elasticsearch8 Windows安装教程-CSDN博客
目录
1、Elasticsearch8的核心概念
2、Elasticsearch8的三个最核心的概念
3、中文分词插件:IK分词器
3.1 简介
3.2 两种分词模式
3.3 效果
3.4 安装配置
3.4.1 下载
3.4.2 压缩到新建的ik文件夹
3.4.3 重启Elasticsearch
3.4.4 查看是否安装成功
4、三巨头(index、mapping、document)的CRUD
4.1 索引(index)
4.1.1 创建索引
4.1.2 查询单个索引
4.1.3 查询全部索引
4.1.4 删除索引
4.2 映射(mapping)
4.2.1 创建映射
4.2.1.1 新建索引的同时新建映射(推荐)
4.2.1.2 新建索引后再新增映射
4.2.2 查询映射
4.2.3 删除映射
4.3 文档(documents)
4.3.1 创建文档
4.3.1.1 创建单个文档
4.3.1.2 创建单个文档,自定义ID
4.3.1.3 创建多个文档(批量创建)
4.3.1.4 创建多个文档,自定义ID
4.3.2 查询文档
4.3.2.1 查询单个文档
4.3.2.2 查询全部文档
4.3.3 修改文档
4.3.3.1 全量更新
4.3.3.2 局部更新
4.3.4 删除文档
4.3.4.1 删除单个文档
4.3.4.2 根据查询条件删除文档
4.3.4.3 批量删除文档
5、所有的Elasticsearch8常用查询
5.1 查询所有文档(match_all)
5.2 匹配查询(match)
5.3 多字段匹配查询(multi_match)
5.4 关键字精准查询(term)
5.5 多关键字精准查询(terms)
5.6 指定查询字段(_source)
5.7 过滤字段查询(includes、excludes)
5.8 组合查询(bool)
5.8.1 多条件筛选查询(must、should、must_not、filter)
5.9 范围查询(range)
5.10 模糊匹配查询(Fuzzy)
5.11 字段排序(sort)
5.11.1 单字段排序
5.11.2 多字段排序
5.11.3 多字段+得分(_score)排序
5.12 短语匹配查询(Match_phrase、slop)
5.13 高亮查询(highlight)
5.13.1 最常用的场景:搜索关键词,然后标题和内容都高亮
5.13.2 自定义高亮标签
5.14 分页查询(from、size)
5.15 聚合查询(aggs)
5.15.1 分桶聚合(Bucketing)
5.15.1.1 terms聚合(分组计数)
5.15.1.2 range聚合(区间分桶)
5.15.1.3 date_histogram聚合(时间分桶)
5.15.2 指标聚合(Metric)
5.15.2.1 平均值(avg)
5.15.2.2 总和(sum)
5.15.2.3 最小值(min)
5.15.2.4 最大值(max)
5.15.2.5 整合案例
5.16 非常用查询(Prefix、Wildcard、Exists、Script)
5.16.1 前缀匹配查询(Prefix)
5.16.2 通配符查询(Wildcard)
5.16.3 字段存在查询(Exists)
5.16.4 复杂脚本查询(Script)
6、Springboot3整合Elasticsearch8
1、Elasticsearch8的核心概念
elasticsearch)。_id。GROUP BY与聚合函数。2、Elasticsearch8的三个最核心的概念
我们结合mysql来理解,这最主要的三个概念:索引(index)、映射(mapping)、文档(document)
mysql的概念有:数据库、表、表结构、行
Elasticsearch7的概念有:索引、类型、映射、文档
Elasticsearch8的概念有:索引、映射、文档 (ES8中类型已经被废除了)
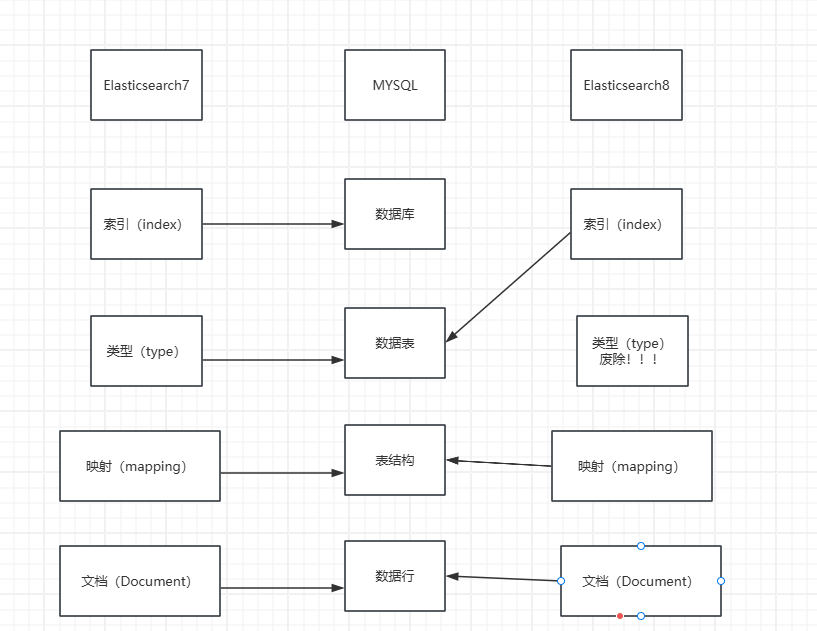
这里我们Elasticsearch8已经彻底废除type,所以结合mysql来理解的话:
ES的索引(index)相当于MYSQL的表
ES的映射(mappiing)相当于MYSQL的表结构
ES的文档(document)相当于MYSQL的数据行
3、中文分词插件:IK分词器
3.1 简介
IK 分词器(IK Analyzer)是 Elasticsearch 中非常常用的中文分词插件,它能让 Elasticsearch 对中文文本进行高效、智能的分词。
3.2 两种分词模式
3.3 效果
查询:中华人民共和国国歌
ik_max_word 分词:
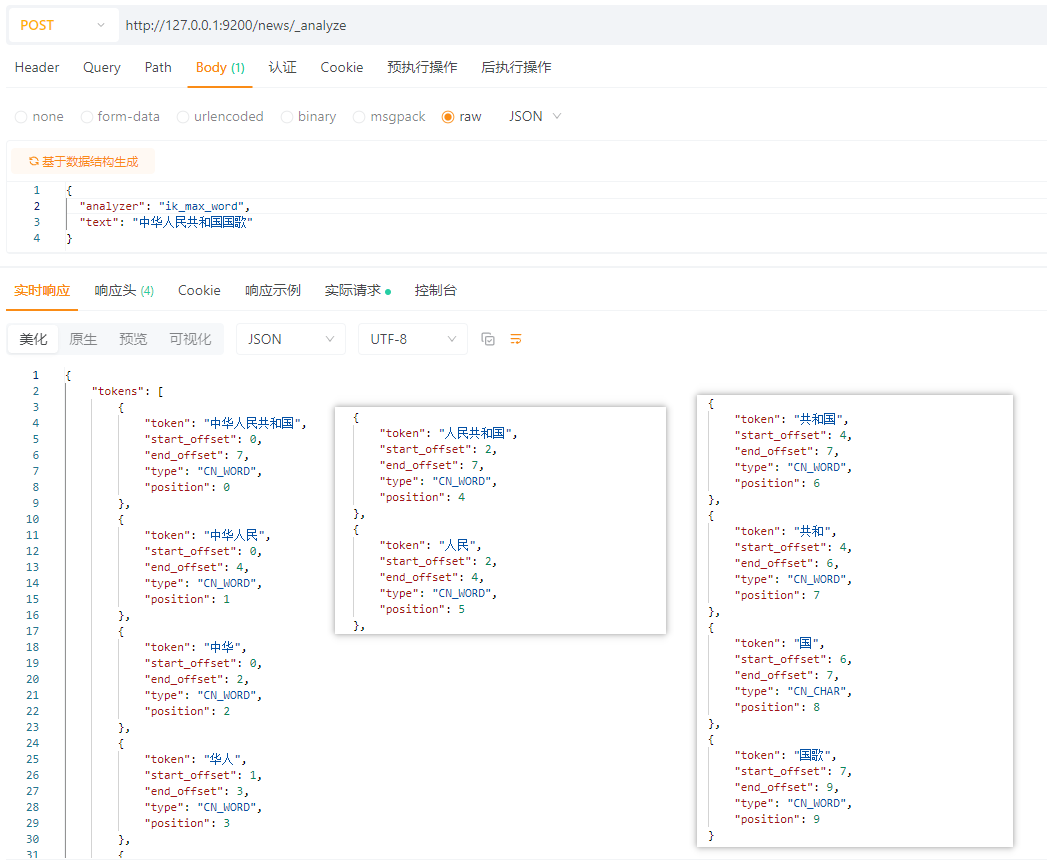
ik_smart 分词:
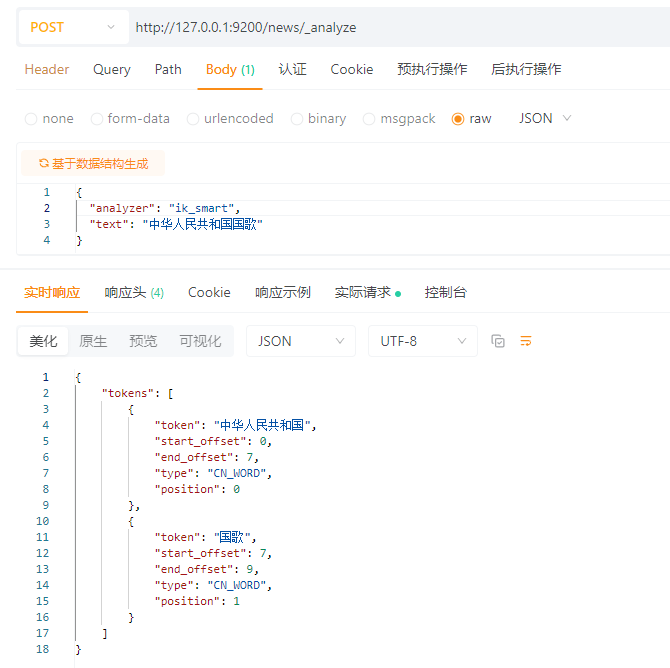
3.4 安装配置
3.4.1 下载
下载地址:Index of: analysis-ik/stable/
下载的ik分词器版本一定要对应你的es版本!!!我es客户端是8.18.2,所以我下载的ik分词器也是8.18.2
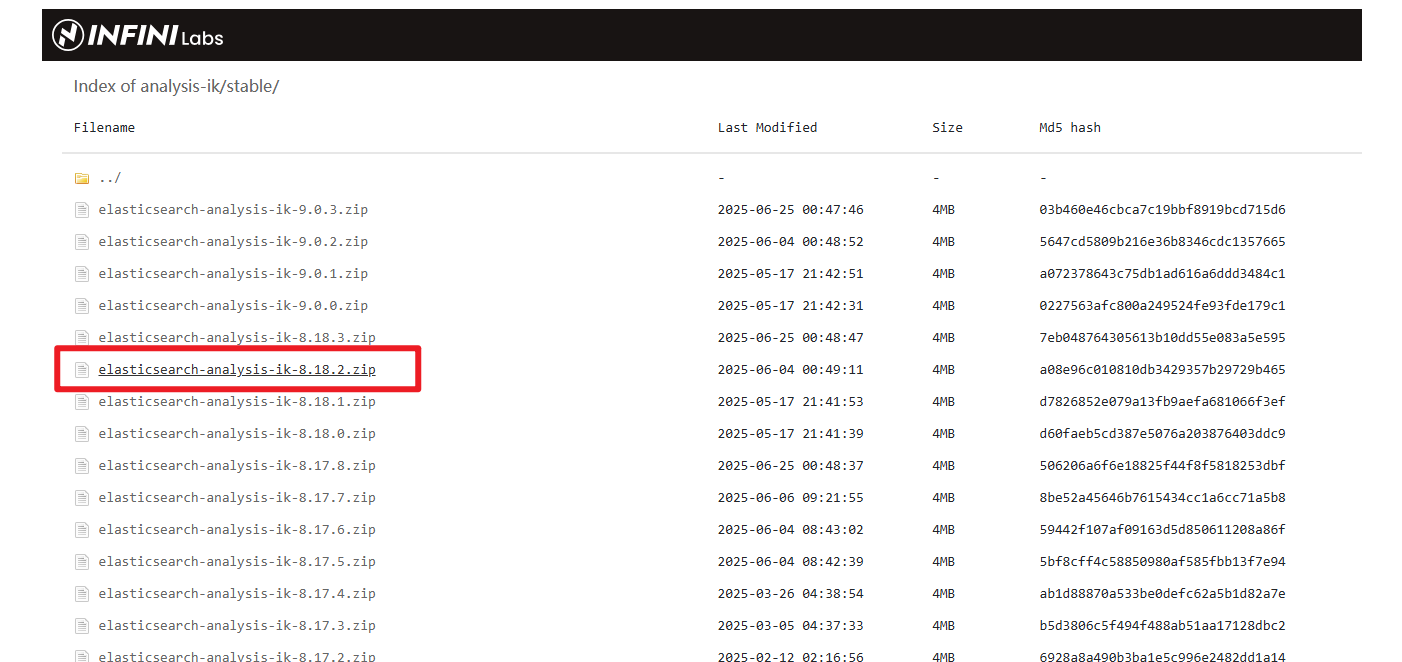
获取到的压缩文件:
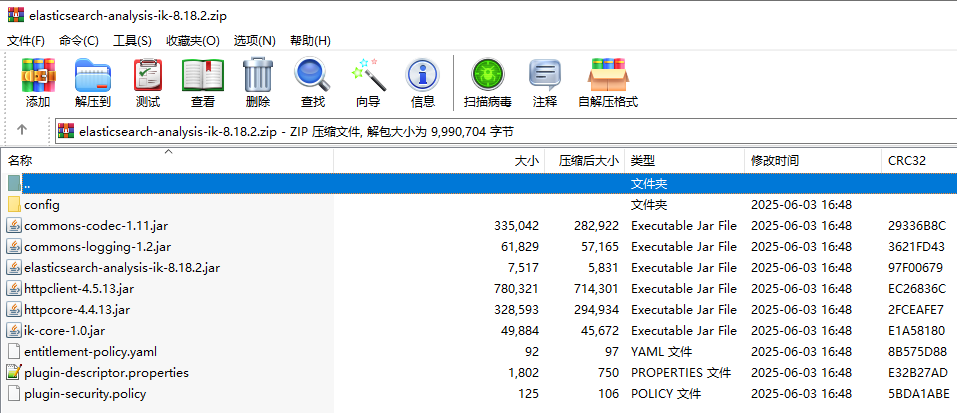
3.4.2 压缩到新建的ik文件夹
在es的plugins(插件)文件夹新增ik文件夹,并将获取到的压缩文件解压到ik文件里
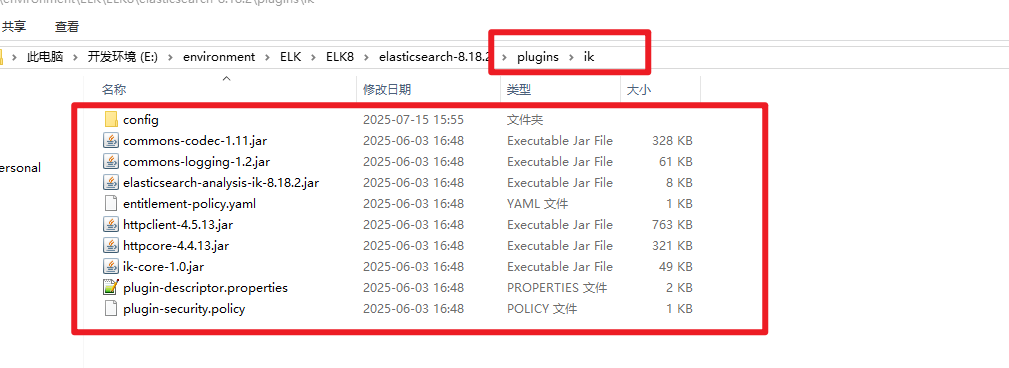
3.4.3 重启Elasticsearch
3.4.4 查看是否安装成功
elasticsearch-plugin list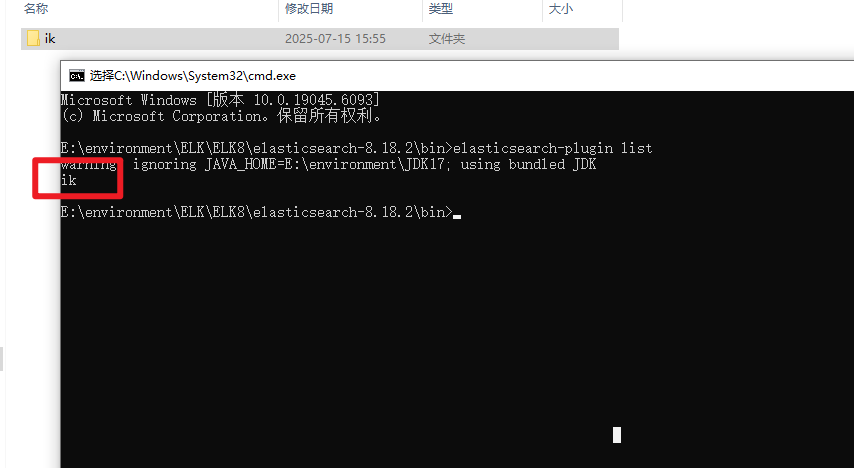
4、三巨头(index、mapping、document)的CRUD
ps:我这里使用的工具是Apipost
4.1 索引(index)
4.1.1 创建索引
PUT请求:http://127.0.0.1:9200/students
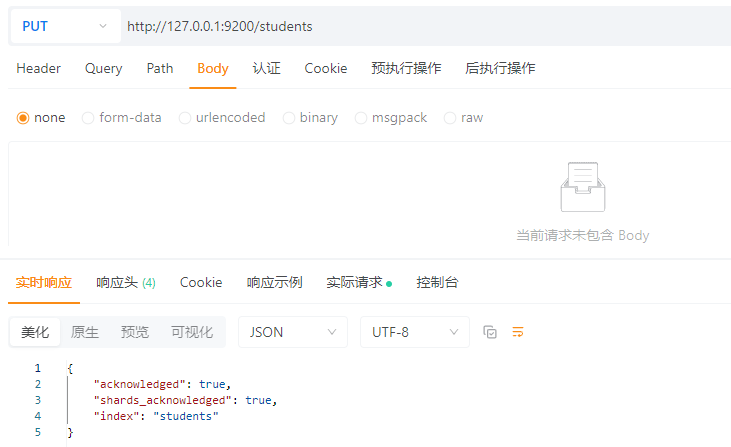
返回结果解释:
true,说明创建流程已开始。false,表示分片分配未全部完成(例如节点不足)。students。4.1.2 查询单个索引
GET请求:http://127.0.0.1:9200/students
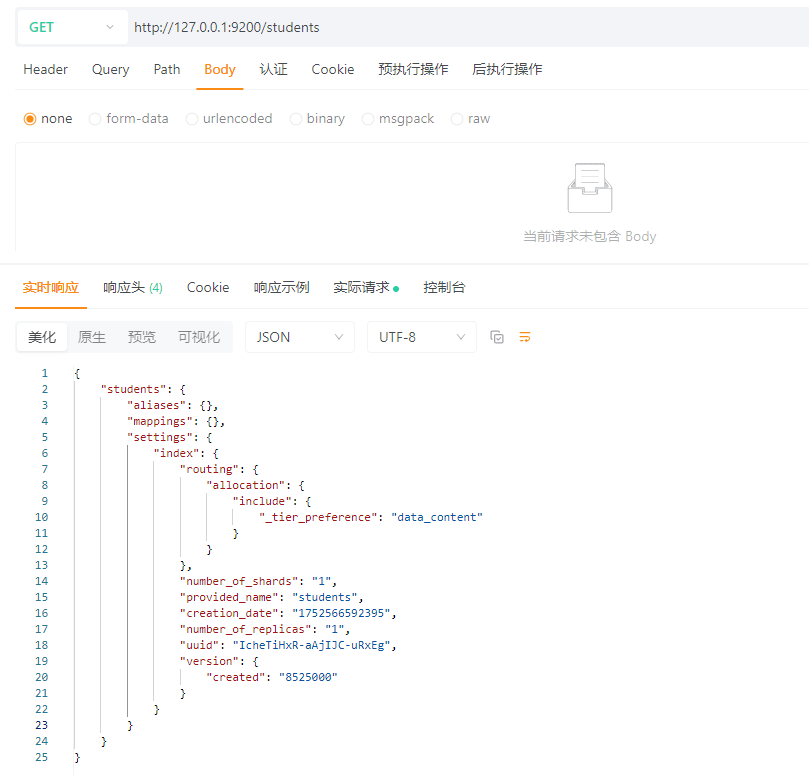
返回结果解析:
{}{}settings.index.routing.
allocation.include._tier_preference
\"data_content\"data_content类型的节点(8.x默认设置,用于冷热分层存储)。\"1\"\"1\"\"students\"\"1752566592395\"\"IcheTiHxR-aAjIJC-uRxEg\"\"8525000\"8525000 对应8.5.2(这是内部版本号编码)。4.1.3 查询全部索引
GET请求:http://127.0.0.1:9200/_cat/indices?v
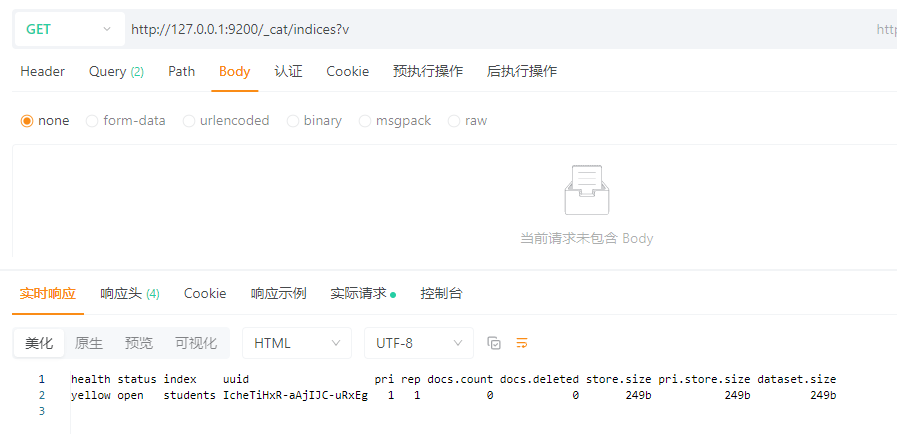
解析:
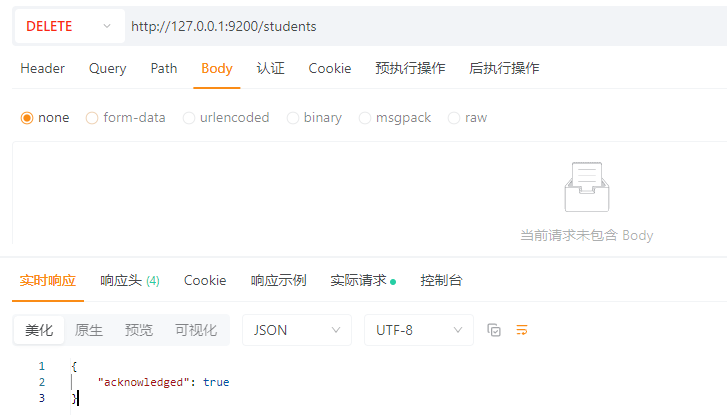
4.1.4 删除索引
DELETE请求:http://127.0.0.1:9200/students
4.2 映射(mapping)
4.2.1 创建映射
映射的字段(Fields)类型(type)分别有:
long/integer/short/byte/float/
double/half_float/scaled_float
创建映射有两种方式:
一种是在建索引的时候同时新建映射(推荐),另一个是新增完索引后再往索引里面新增映射。
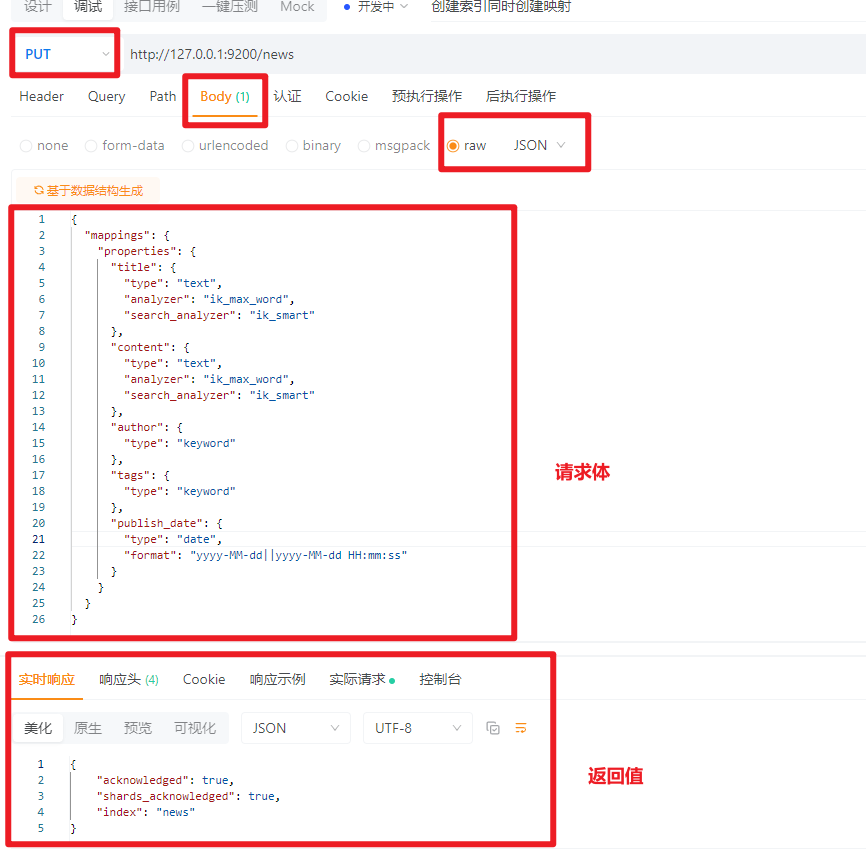
4.2.1.1 新建索引的同时新建映射(推荐)
需要用到中文分词器的字段也可以同时新建,记住映射一旦创建就不能删除或者修改,只能往里面新增
PUT请求:http://127.0.0.1:9200/news
请求体:JSON格式
{
\"mappings\": {
\"properties\": {
\"title\": {
\"type\": \"text\",
\"analyzer\": \"ik_max_word\",
\"search_analyzer\": \"ik_smart\"
},
\"content\": {
\"type\": \"text\",
\"analyzer\": \"ik_max_word\",
\"search_analyzer\": \"ik_smart\"
},
\"author\": {
\"type\": \"keyword\"
},
\"tags\": {
\"type\": \"keyword\"
},
\"publish_date\": {
\"type\": \"date\",
\"format\": \"yyyy-MM-dd||yyyy-MM-dd HH:mm:ss\"
}
}
}
}
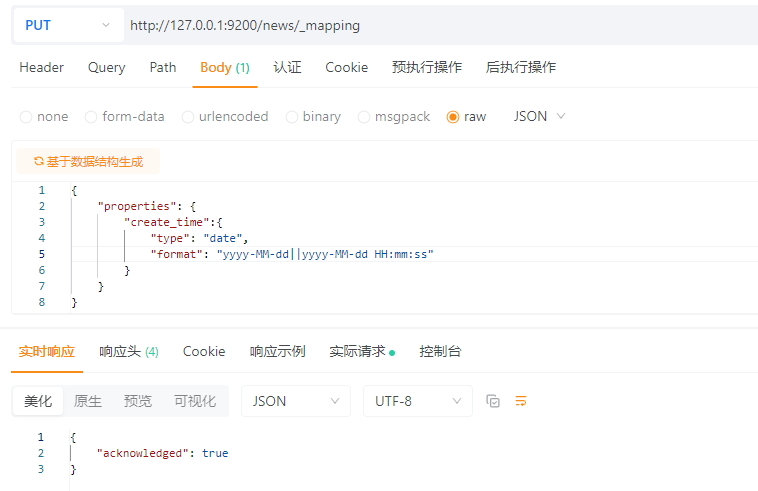
4.2.1.2 新建索引后再新增映射
PUT请求:http://127.0.0.1:9200/news/_mapping
请求体:JSON格式
{
\"properties\": {
\"create_time\":{
\"type\": \"date\",
\"format\": \"yyyy-MM-dd||yyyy-MM-dd HH:mm:ss\"
}
}
}
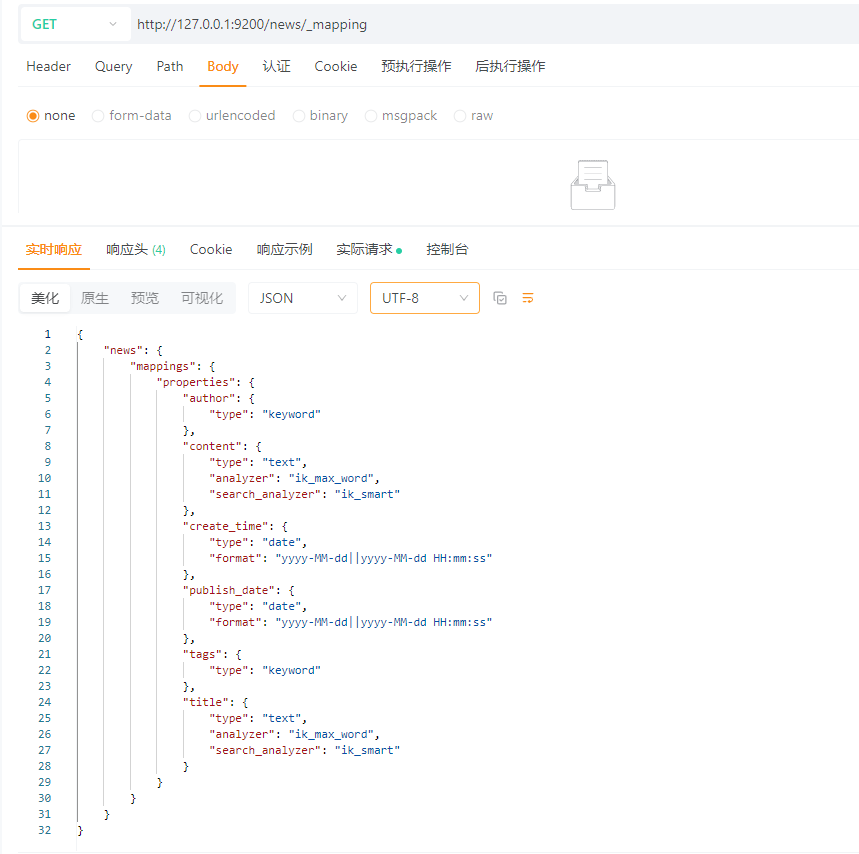
4.2.2 查询映射
GET请求:http://127.0.0.1:9200/news/_mapping
4.2.3 删除映射
重要的事情说三遍:映射一旦创建就不能删除!映射一旦创建就不能删除!映射一旦创建就不能删除!
当然如果你非看这个映射不爽,可以删除对应的索引,重新新增索引然后建立映射(删除索引在文章4.1.4)
4.3 文档(documents)
4.3.1 创建文档
4.3.1.1 创建单个文档
POST请求:http://127.0.0.1:9200/news/_doc
请求体:JSON格式
{
\"title\": \"苹果公司发布新款iPhone\",
\"content\": \"苹果公司今天在发布会上正式推出了新一代iPhone,引发全球媒体关注。\",
\"author\": \"张三\",
\"tags\": [\"科技\", \"手机\"],
\"create_time\": \"2025-07-15 09:00:00\",
\"publish_date\": \"2025-07-15\"
}
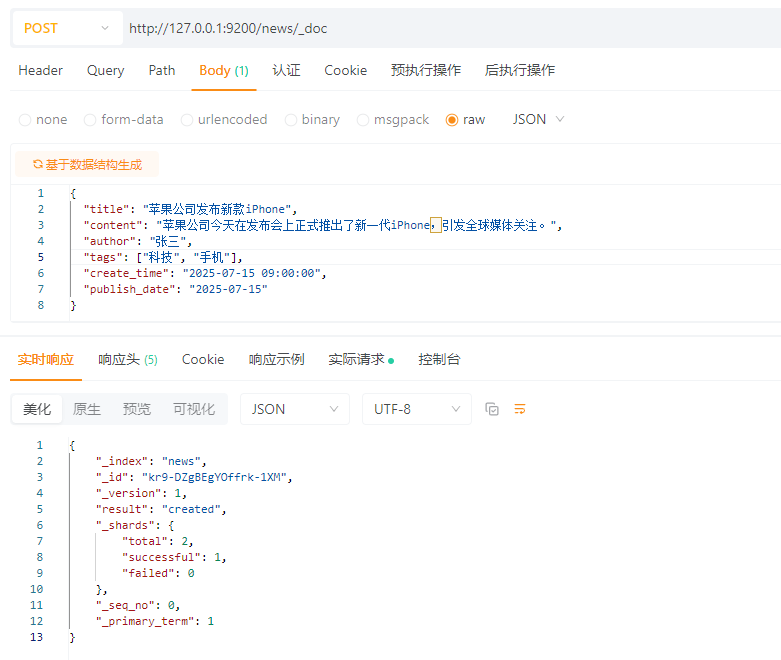
返回解析:
_indexnews_idkr9-DZgBEgYOffrk-1XM_versionresultcreated 表示新建了文档 - updated 表示更新了已存在文档_shardstotal: 2(主分片 + 副本分片) - successful: 1(写入主分片成功) - failed: 0(没有失败)_seq_no_primary_term4.3.1.2 创建单个文档,自定义ID
POST请求:http://127.0.0.1:9200/news/_doc/1
ps:只需要在url地址的后面加入/你所自定义的id
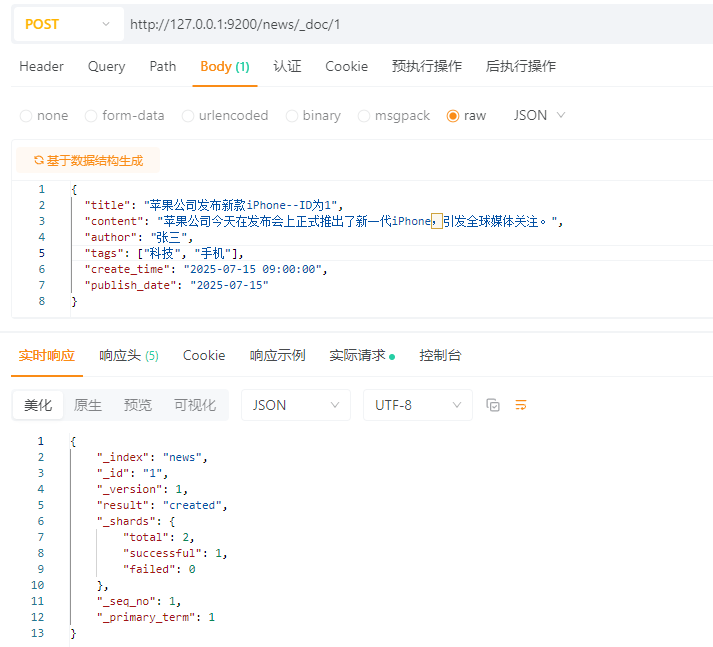
4.3.1.3 创建多个文档(批量创建)
使用_bulk接口进行批量创建,设置
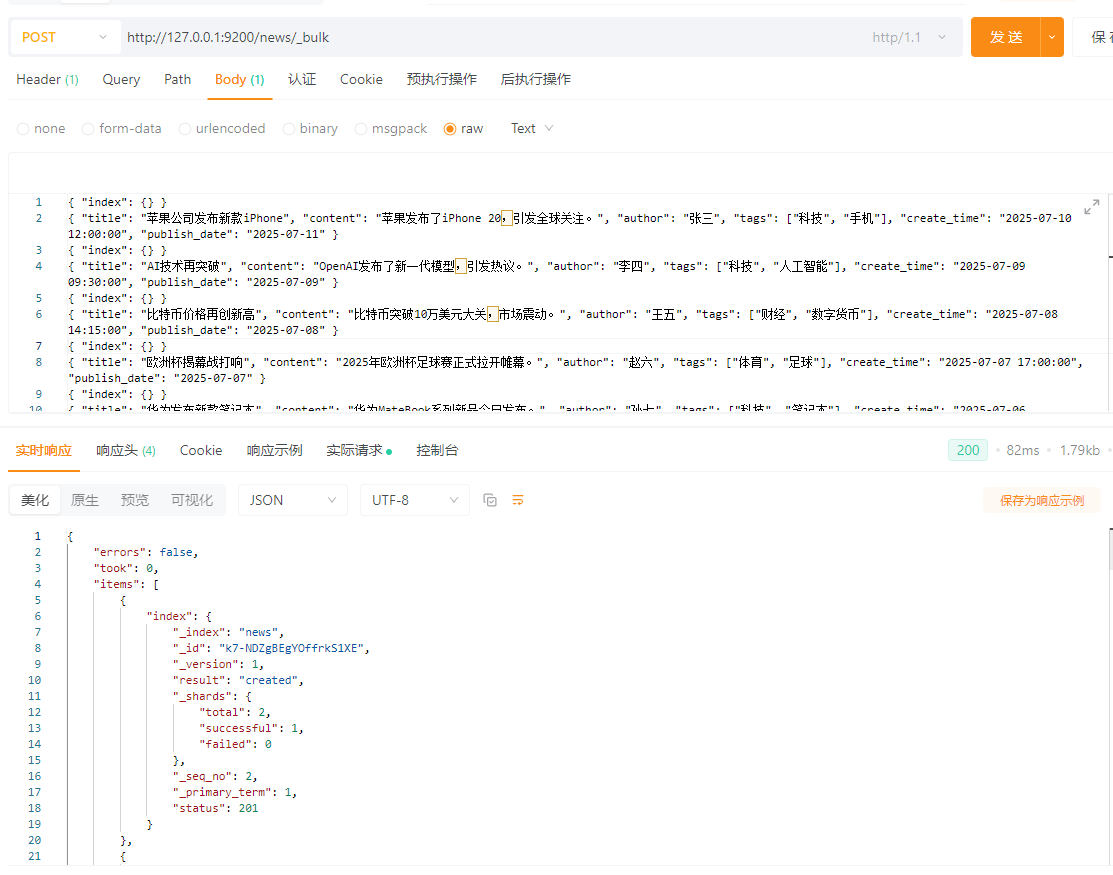
POST请求:http://127.0.0.1:9200/news/_bulk
请求头:Content-Type:application/x-ndjson
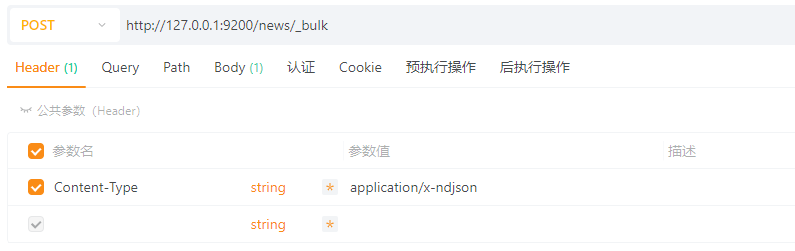
请求体:TEXT
{ \"index\": {} }
{ \"title\": \"苹果公司发布新款iPhone\", \"content\": \"苹果发布了iPhone 20,引发全球关注。\", \"author\": \"张三\", \"tags\": [\"科技\", \"手机\"], \"create_time\": \"2025-07-10 12:00:00\", \"publish_date\": \"2025-07-11\" }
{ \"index\": {} }
{ \"title\": \"AI技术再突破\", \"content\": \"OpenAI发布了新一代模型,引发热议。\", \"author\": \"李四\", \"tags\": [\"科技\", \"人工智能\"], \"create_time\": \"2025-07-09 09:30:00\", \"publish_date\": \"2025-07-09\" }
{ \"index\": {} }
{ \"title\": \"比特币价格再创新高\", \"content\": \"比特币突破10万美元大关,市场震动。\", \"author\": \"王五\", \"tags\": [\"财经\", \"数字货币\"], \"create_time\": \"2025-07-08 14:15:00\", \"publish_date\": \"2025-07-08\" }
{ \"index\": {} }
{ \"title\": \"欧洲杯揭幕战打响\", \"content\": \"2025年欧洲杯足球赛正式拉开帷幕。\", \"author\": \"赵六\", \"tags\": [\"体育\", \"足球\"], \"create_time\": \"2025-07-07 17:00:00\", \"publish_date\": \"2025-07-07\" }
{ \"index\": {} }
{ \"title\": \"华为发布新款笔记本\", \"content\": \"华为MateBook系列新品今日发布。\", \"author\": \"孙七\", \"tags\": [\"科技\", \"笔记本\"], \"create_time\": \"2025-07-06 11:00:00\", \"publish_date\": \"2025-07-06\" }
{ \"index\": {} }
{ \"title\": \"高温天气持续\", \"content\": \"全国多地发布高温红色预警,注意防暑。\", \"author\": \"周八\", \"tags\": [\"社会\", \"天气\"], \"create_time\": \"2025-07-05 08:00:00\", \"publish_date\": \"2025-07-05\" }
{ \"index\": {} }
{ \"title\": \"国产动画电影大热\", \"content\": \"《山海奇谭》票房突破10亿。\", \"author\": \"钱九\", \"tags\": [\"娱乐\", \"电影\"], \"create_time\": \"2025-07-04 19:00:00\", \"publish_date\": \"2025-07-04\" }
{ \"index\": {} }
{ \"title\": \"全国高考成绩放榜\", \"content\": \"多地考生取得优异成绩,北大清华竞争激烈。\", \"author\": \"郑十\", \"tags\": [\"教育\", \"高考\"], \"create_time\": \"2025-07-03 10:00:00\", \"publish_date\": \"2025-07-03\" }
{ \"index\": {} }
{ \"title\": \"新能源汽车销量大涨\", \"content\": \"6月新能源汽车销量同比增长120%。\", \"author\": \"冯十一\", \"tags\": [\"汽车\", \"新能源\"], \"create_time\": \"2025-07-02 13:00:00\", \"publish_date\": \"2025-07-02\" }
{ \"index\": {} }
{ \"title\": \"短视频平台政策收紧\", \"content\": \"监管部门发布新规加强内容审核。\", \"author\": \"陈十二\", \"tags\": [\"互联网\", \"政策\"], \"create_time\": \"2025-07-01 16:00:00\", \"publish_date\": \"2025-07-01\" }
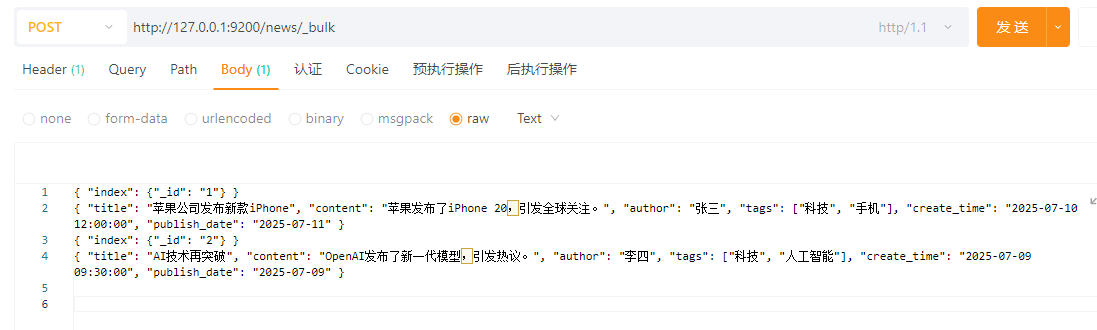
4.3.1.4 创建多个文档,自定义ID
只需要请求体的index里面加入_id,如
{ \"index\": {\"_id\": \"1\"} }
{ \"title\": \"苹果公司发布新款iPhone\", \"content\": \"苹果发布了iPhone 20,引发全球关注。\", \"author\": \"张三\", \"tags\": [\"科技\", \"手机\"], \"create_time\": \"2025-07-10 12:00:00\", \"publish_date\": \"2025-07-11\" }
{ \"index\": {\"_id\": \"2\"} }
{ \"title\": \"AI技术再突破\", \"content\": \"OpenAI发布了新一代模型,引发热议。\", \"author\": \"李四\", \"tags\": [\"科技\", \"人工智能\"], \"create_time\": \"2025-07-09 09:30:00\", \"publish_date\": \"2025-07-09\" }
4.3.2 查询文档
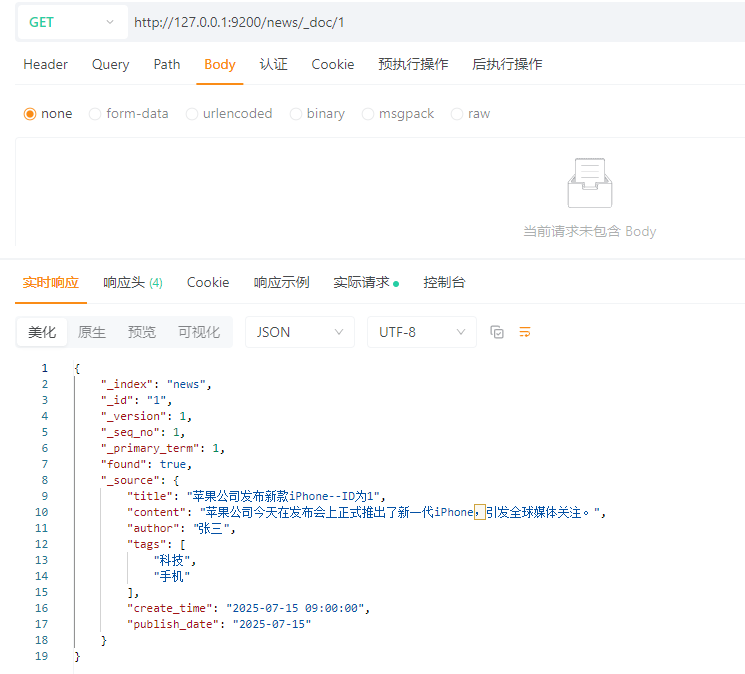
4.3.2.1 查询单个文档
GET请求:http://127.0.0.1:9200/news/_doc/1
查询索引news中_id为1的文档
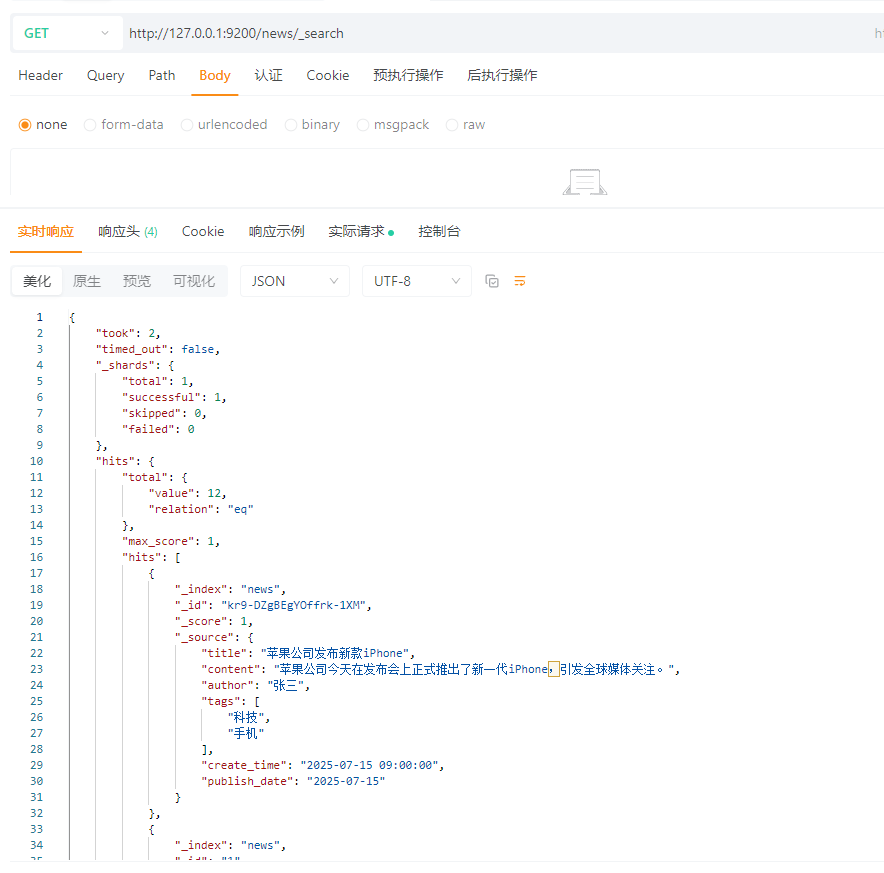
4.3.2.2 查询全部文档
GET请求:http://127.0.0.1:9200/news/_search
4.3.3 修改文档
修改文档有四种方式:1、全量更新 2、局部更新 3、upsert更新 4、脚本更新
这里主要讲最常用的两种方式:1、全量更新 2、局部更新
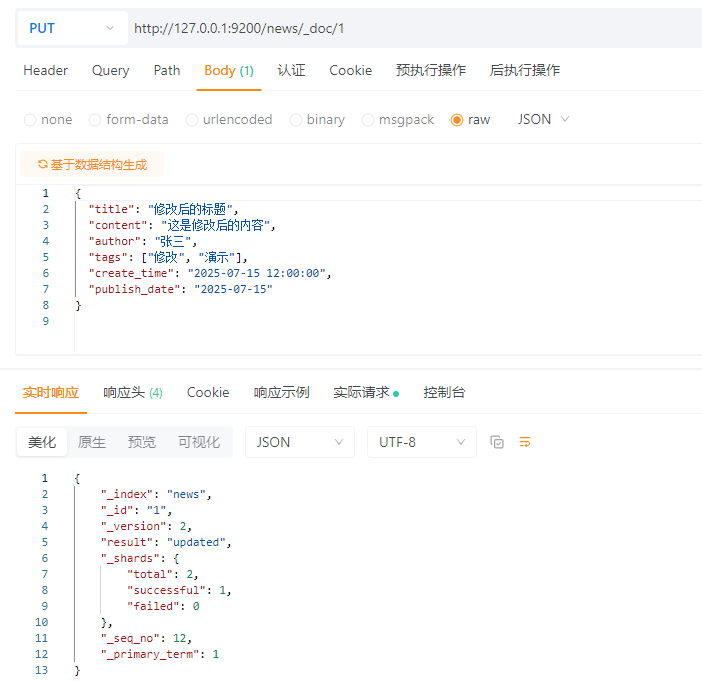
4.3.3.1 全量更新
PUT请求:http://127.0.0.1:9200/news/_doc/1
请求体:JSON
{
\"title\": \"修改后的标题\",
\"content\": \"这是修改后的内容\",
\"author\": \"张三\",
\"tags\": [\"修改\", \"演示\"],
\"create_time\": \"2025-07-15 12:00:00\",
\"publish_date\": \"2025-07-15\"
}
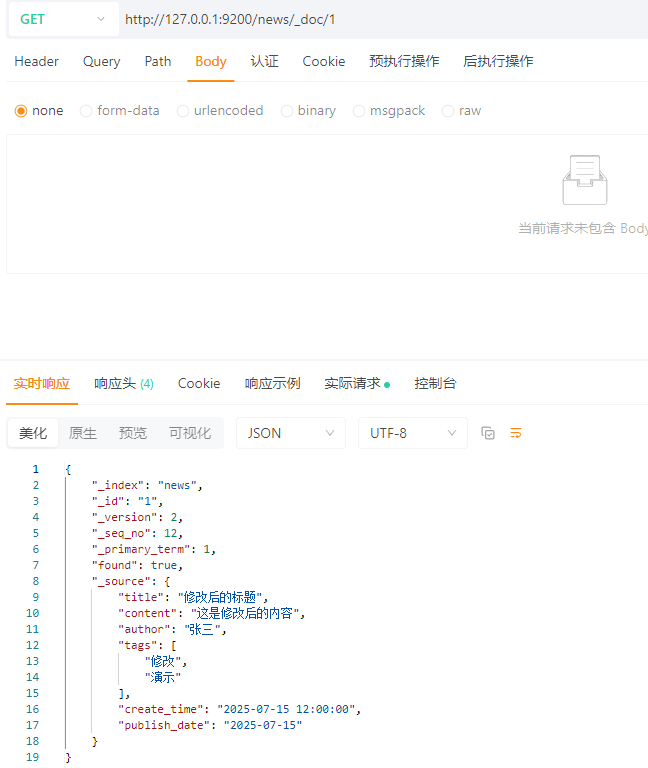
ps:如果ID存在则覆盖,如果ID不存在则新增
结果:
4.3.3.2 局部更新
使用_update接口进行局部更新
POST请求:http://127.0.0.1:9200/news/_update/1
请求体:JSON
{
\"doc\": {
\"title\": \"只改标题\",
\"tags\": [\"更新\"]
}
}
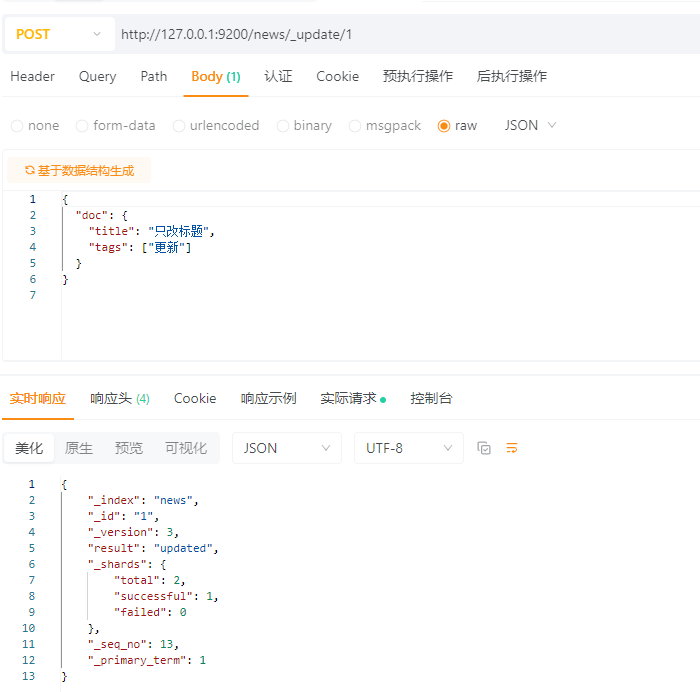
效果:
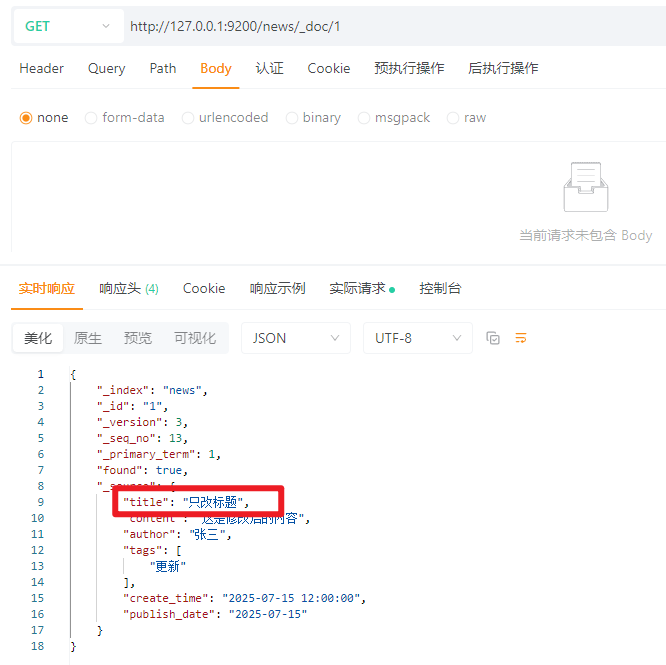
4.3.4 删除文档
4.3.4.1 删除单个文档
DELETE请求:http://127.0.0.1:9200/news/_doc/1
删除ID为1的文档
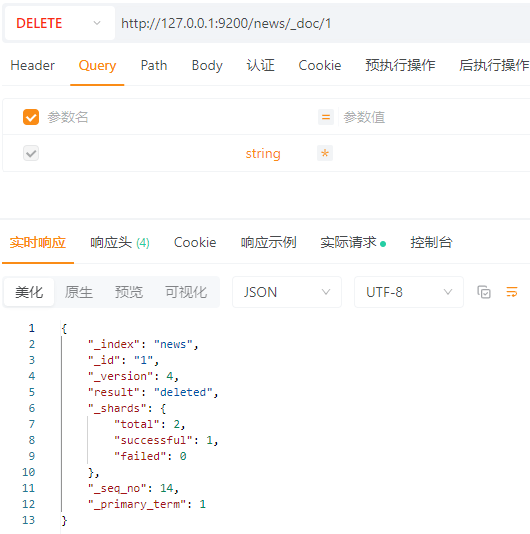
4.3.4.2 根据查询条件删除文档
首先,我们先根据条件查询到需要删除的数据,这里演示是所有作者名称为:张三的数据(所有查询在第五节会重点讲)
GET请求:http://127.0.0.1:9200/news/_search
请求体:JSON格式
{
\"query\": {
\"match\": {
\"author\": \"张三\"
}
}
}
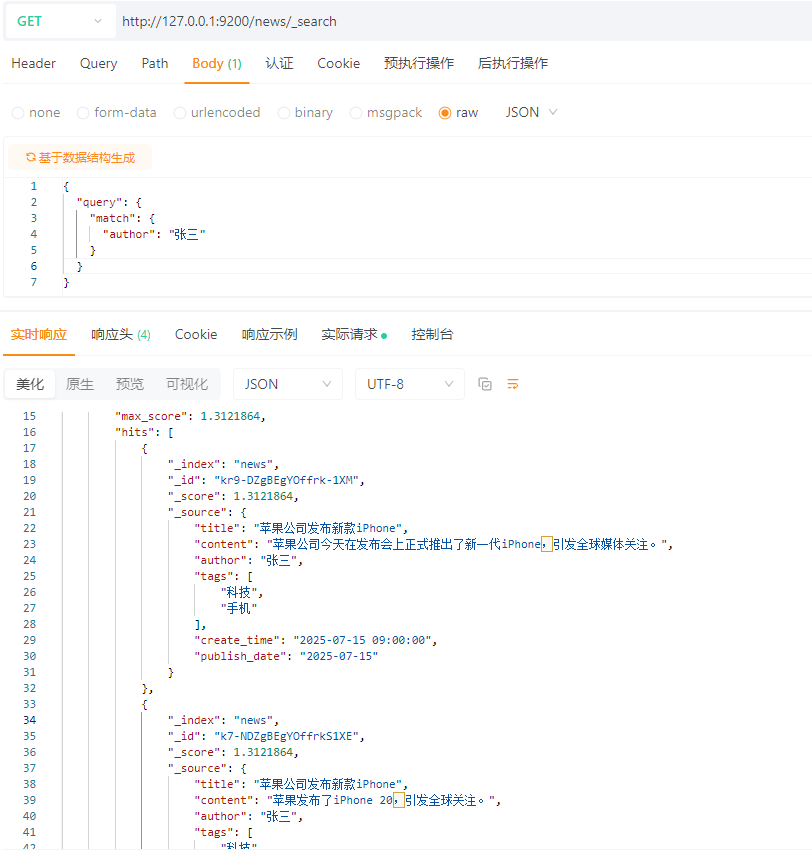
使用_delete_by_query接口,根据查询条件进行删除。
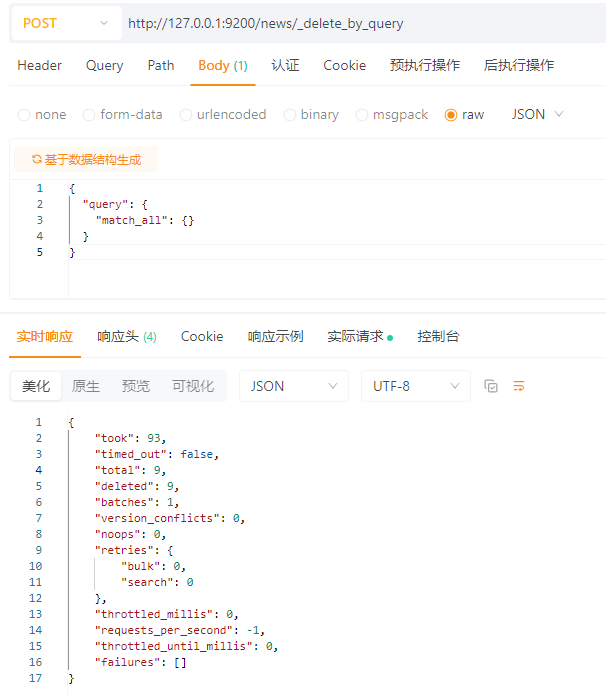
POST请求 :http://127.0.0.1:9200/news/_delete_by_query
请求体:JSON格式
{
\"query\": {
\"match\": {
\"author\": \"张三\"
}
}
}
结果:
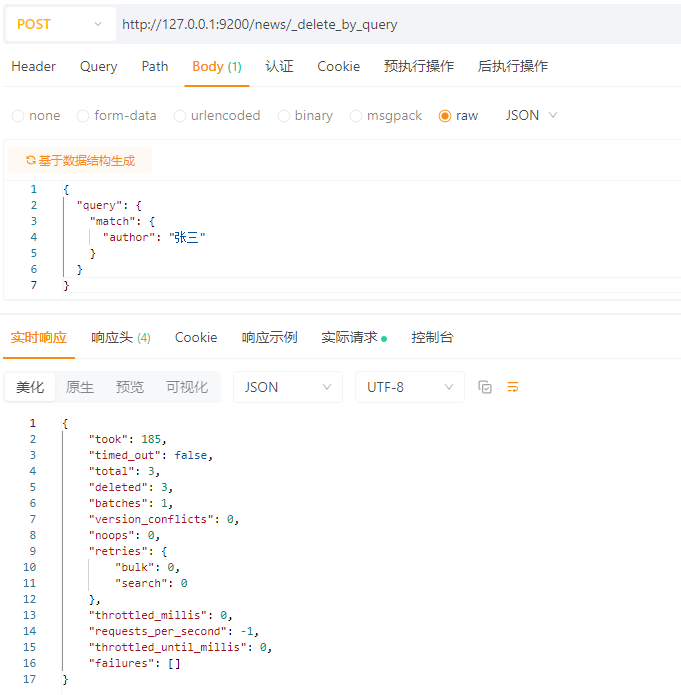
解析:
tooktimed_outfalse 表示没有超时totaldeletedbatchesversion_conflictsnoopsretries.bulkretries.searchthrottled_millisrequests_per_second-1表示不限速throttled_until_millisfailures拓展:当你的查询条件为:(查询当前索引下的全部文档)
{
\"query\": {
\"match_all\": {}
}
}
则会删除所有当前索引下的全部文档
4.3.4.3 批量删除文档
使用_bulk接口,根据id批量删除。(接口细节使用回顾4.3.1.4节,批量创建多个文档带ID)
POST请求:http://127.0.0.1:9200/news/_bulk
请求头:Content-Type:application/x-ndjson
请求体:TEXT
{ \"delete\": {\"_id\": \"1\"} }
{ \"delete\": {\"_id\": \"2\"} }
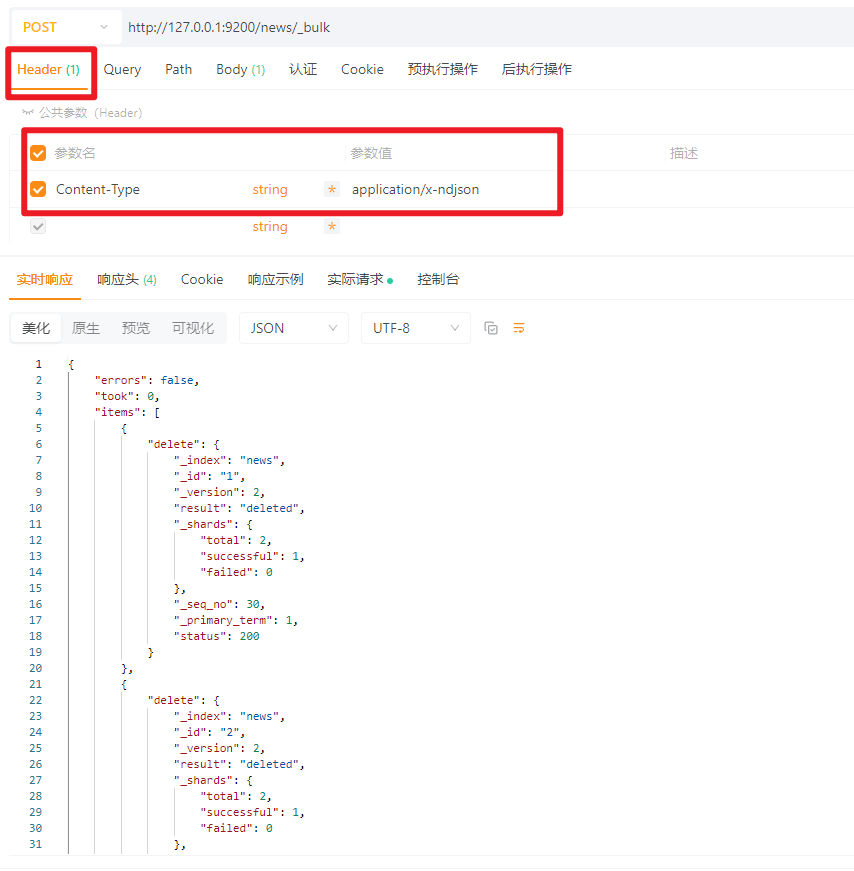
解析:
_indexnews_id1_versionresultdeleted 表示成功删除_shardstotal:2(主分片+副本)- successful:1(主分片写成功)- failed:0(没有失败)_seq_no_primary_termstatus200表示成功5、所有的Elasticsearch8常用查询
所有的查询都是GET请求,部分查询结合MYSQL进行快速理解,但是不一定完全是一个意思~
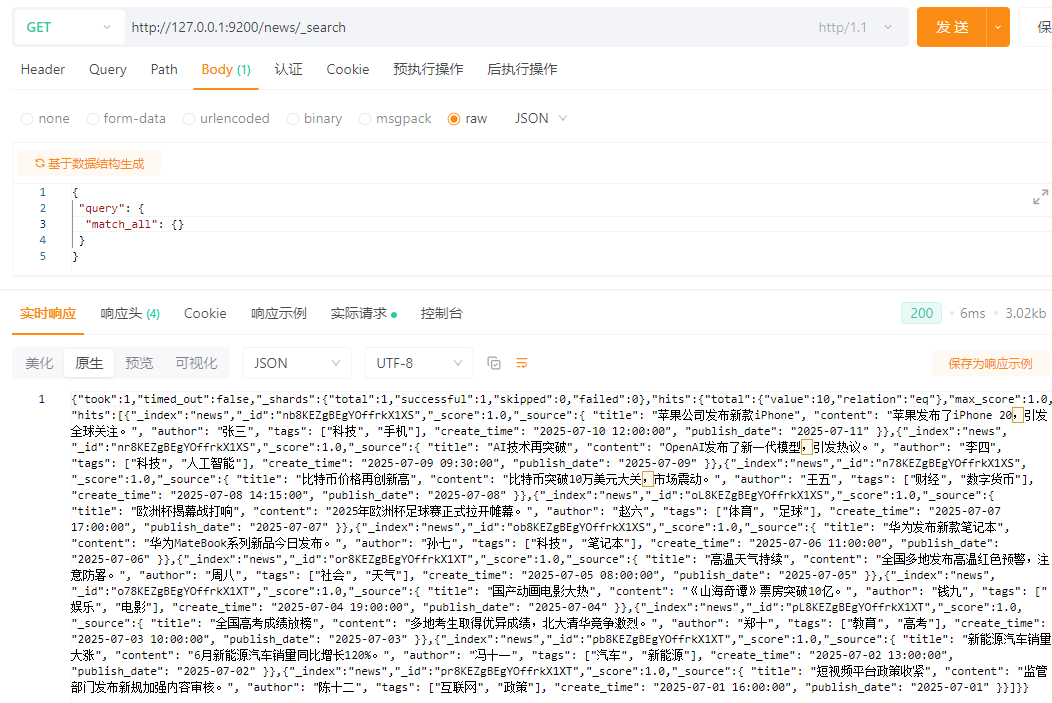
5.1 查询所有文档(match_all)
MYSQL:
select * from news;
ES:
{
\"query\": {
\"match_all\": {}
}
}
查询结果:
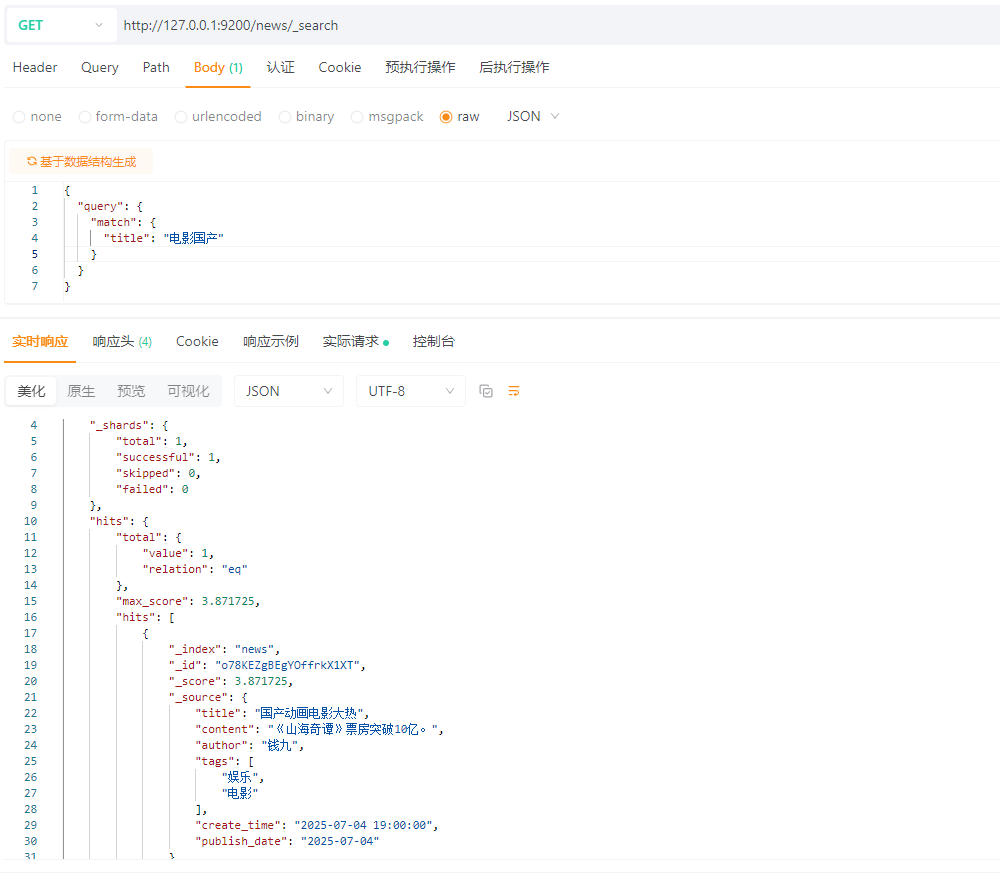
5.2 匹配查询(match)
match 匹配类型查询,会把查询条件进行 分词 ,然后进行查询,多个词条之间是 or 的关系。 MYSQL:
SELECT * FROM news WHERE title LIKE \'%电影%\' AND title LIKE \'%国产%\'
Elasticsearch:
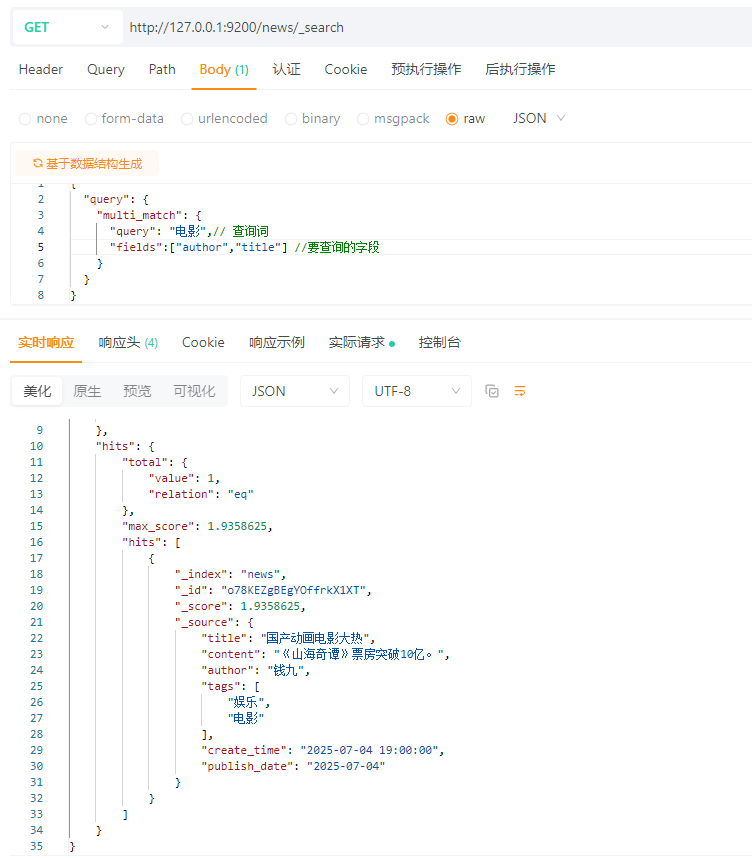
5.3 多字段匹配查询(multi_match)
注意:multi_match 和 match不同的是,multi_match可以在多个字段中进行查询,而match只能查询一个字段。
MYSQL:
SELECT * FROM news
WHERE title LIKE \'%电影%\' OR content LIKE \'%电影%\'
ES:
{
\"query\": {
\"multi_match\": {
\"query\": \"电影\",// 查询词
\"fields\":[\"author\",\"title\"] //要查询的字段
}
}
}
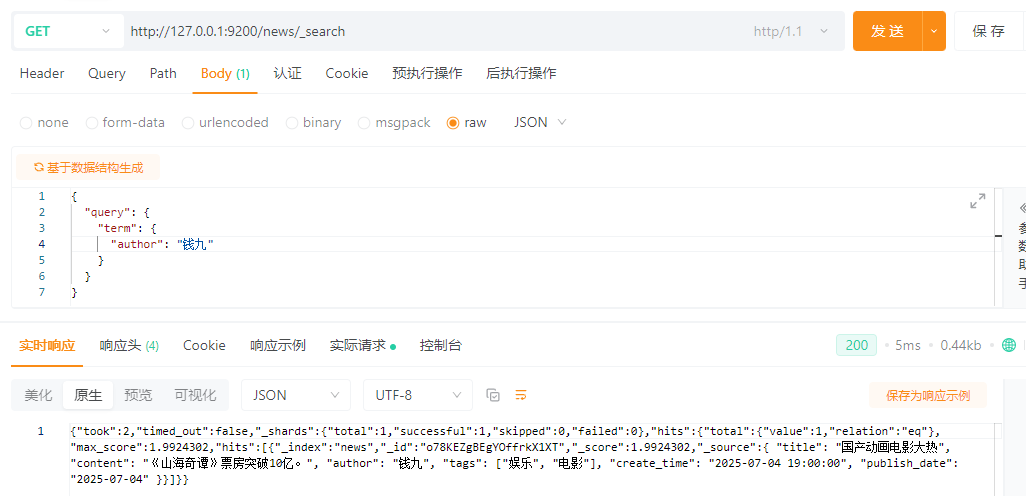
5.4 关键字精准查询(term)
term 查询,精确的关键词完全匹配查询, 不分词 。 MYSQL:
SELECT * FROM news WHERE author = \'钱九\';
ES:
{
\"query\": {
\"term\": {
\"author\": \"钱九\"
}
}
}
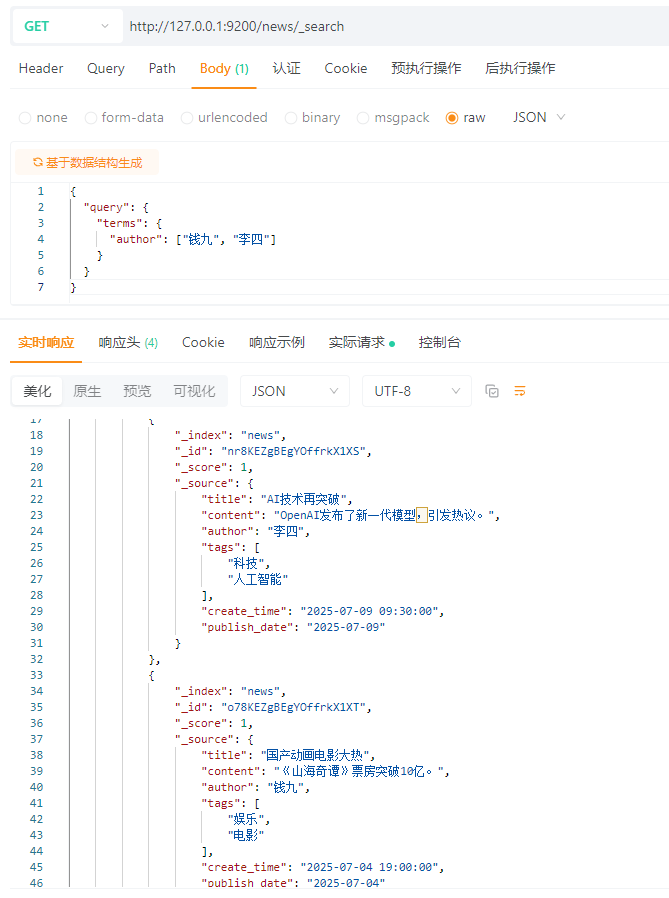
5.5 多关键字精准查询(terms)
MYSQL:
SELECT * FROM news WHERE author IN (\'钱九\', \'李四\');
ES:
{
\"query\": {
\"terms\": {
\"author\": [\"钱九\", \"李四\"]
}
}
}
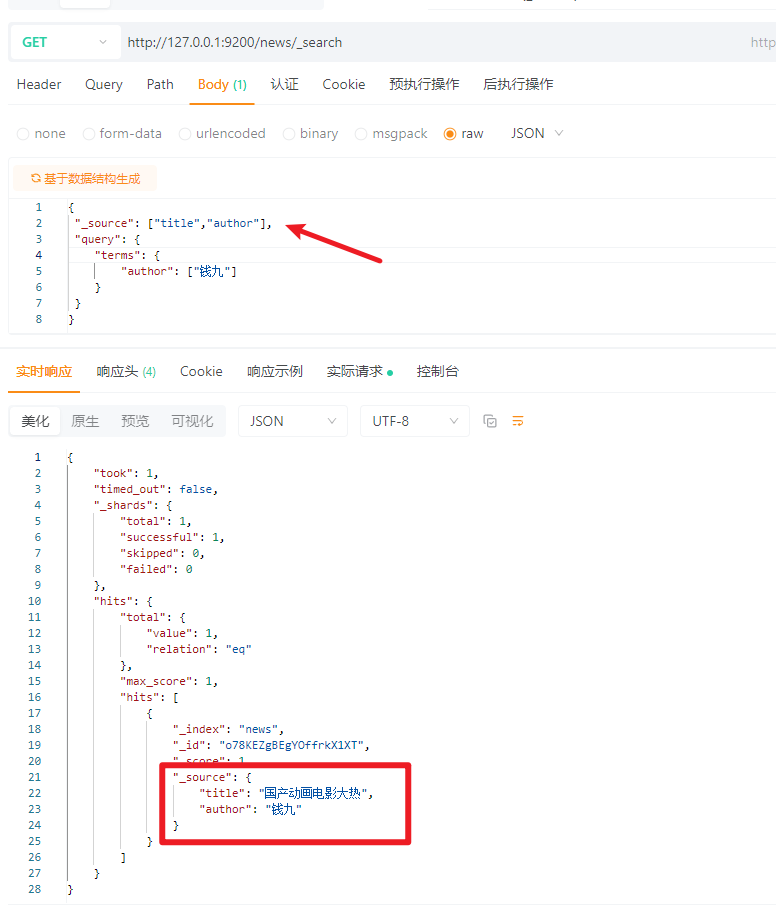
5.6 指定查询字段(_source)
MYSQL:
select title,author from news where author = \"钱九\";
ES:
{
\"_source\": [\"title\",\"author\"],
\"query\": {
\"terms\": {
\"author\": [\"钱九\"]
}
}
}
效果:
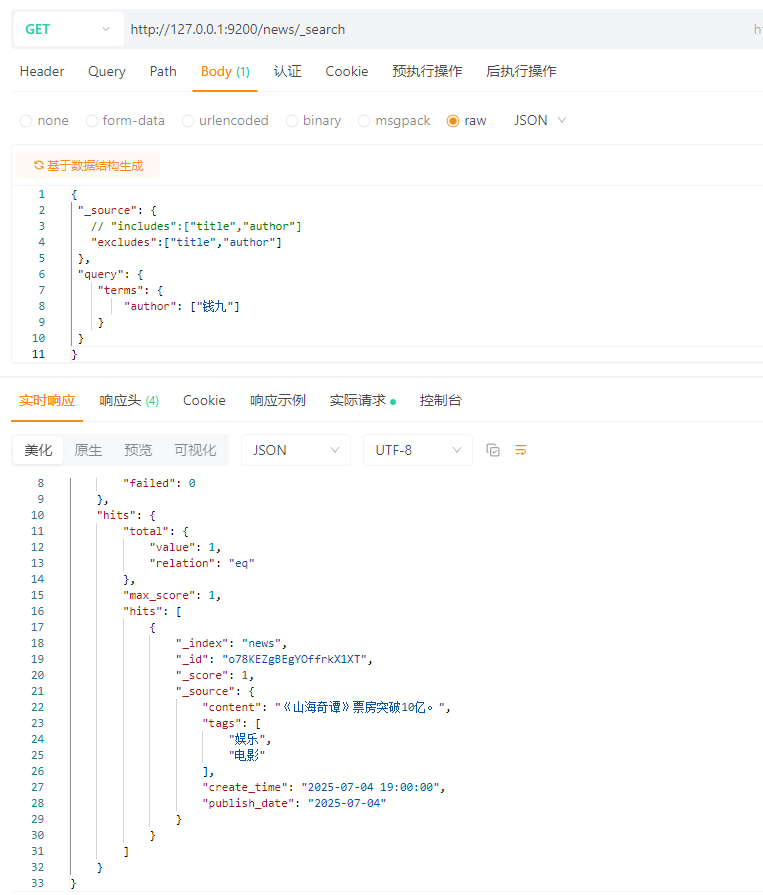
5.7 过滤字段查询(includes、excludes)
搭配_source使用:
includes:用来指定想要显示的字段
excludes:用来指定不想要显示的字段
{
\"_source\": {
// \"includes\":[\"title\",\"author\"]
\"excludes\":[\"title\",\"author\"]
},
\"query\": {
\"terms\": {
\"author\": [\"钱九\"]
}
}
}
5.8 组合查询(bool)
5.8.1 多条件筛选查询(must、should、must_not、filter)
最最最强大、最最最重要的查询来了!!多条件查询!!重点讲解
{
\"bool\": {
\"must\": [ ... ], // 相当于 SQL 的 AND
\"should\": [ ... ], // 相当于 SQL 的 OR(有时会影响 _score)
\"must_not\": [ ... ], // 相当于 SQL 的 NOT
\"filter\": [ ... ] // 也类似 AND,但不影响打分(性能更好)
}
}
数据依旧是我们前面导入的一条数据:
{
\"title\": \"国产动画电影大热\",
\"content\": \"《山海奇谭》票房突破10亿。\",
\"author\": \"钱九\",
\"tags\": [\"娱乐\", \"电影\"],
\"create_time\": \"2025-07-04 19:00:00\",
\"publish_date\": \"2025-07-04\"
}
📌 需求:找出作者是“钱九”并且标题中包含“动画”---must
{
\"query\": {
\"bool\": {
\"must\": [
{ \"term\": { \"author\": \"钱九\" } },
{ \"match\": { \"title\": \"动画\" } }
]
}
}
}
📌 需求:找出标题中包含“动画”或“电影”----should
{
\"query\": {
\"bool\": {
\"should\": [
{ \"match\": { \"title\": \"动画\" } },
{ \"match\": { \"title\": \"电影\" } }
],
\"minimum_should_match\": 1
}
}
}
📌 需求:找出作者不是“钱九”的文档----must_not
{
\"query\": {
\"bool\": {
\"must_not\": [
{ \"term\": { \"author\": \"钱九\" } }
]
}
}
}
📌 需求:找出 2025年7月发布的内容,作者是“钱九”----filter
{
\"query\": {
\"bool\": {
\"must\": [
{ \"term\": { \"author\": \"钱九\" } }
],
\"filter\": [
{
\"range\": {
\"publish_date\": {
\"gte\": \"2025-07-01\",
\"lte\": \"2025-07-31\"
}
}
}
]
}
}
}
📌 需求:找出作者为“钱九”、标题中 包含“动画”或“奇谭”、不要有tags字段 ----must、should、must_not
{
\"query\": {
\"bool\": {
\"must\": [
{ \"term\": { \"author\": \"钱九\" } }
],
\"should\": [
{ \"match\": { \"title\": \"动画\" } },
{ \"match\": { \"title\": \"奇谭\" } }
],
\"minimum_should_match\": 1,
\"must_not\": [
{ \"exists\": { \"field\": \"tags\" } }
]
}
}
}
对应的SQL语句:
SELECT * FROM news
WHERE author = \'钱九\'
AND (title LIKE \'%动画%\' OR title LIKE \'%奇谭%\')
AND tags IS NULL;
总结:
mustshouldminimum_should_match 控制must_notfilter5.9 范围查询(range)
相当于SQL中的between、>、>= 操作
{
\"query\": {
\"range\": {
\"字段名\": {
\"gte\": \"最小值\",
\"lte\": \"最大值\"
}
}
}
}
📌 示例 1:日期范围查询
🎯 查找 2025年7月发布的内容(使用 publish_date 字段)
{
\"query\": {
\"range\": {
\"publish_date\": {
\"gte\": \"2025-07-01\",
\"lte\": \"2025-07-31\"
}
}
}
}
📌 示例 2:数值范围查询
{
\"query\": {
\"range\": {
\"view_count\": {
\"gte\": 1000,
\"lt\": 10000
}
}
}
}
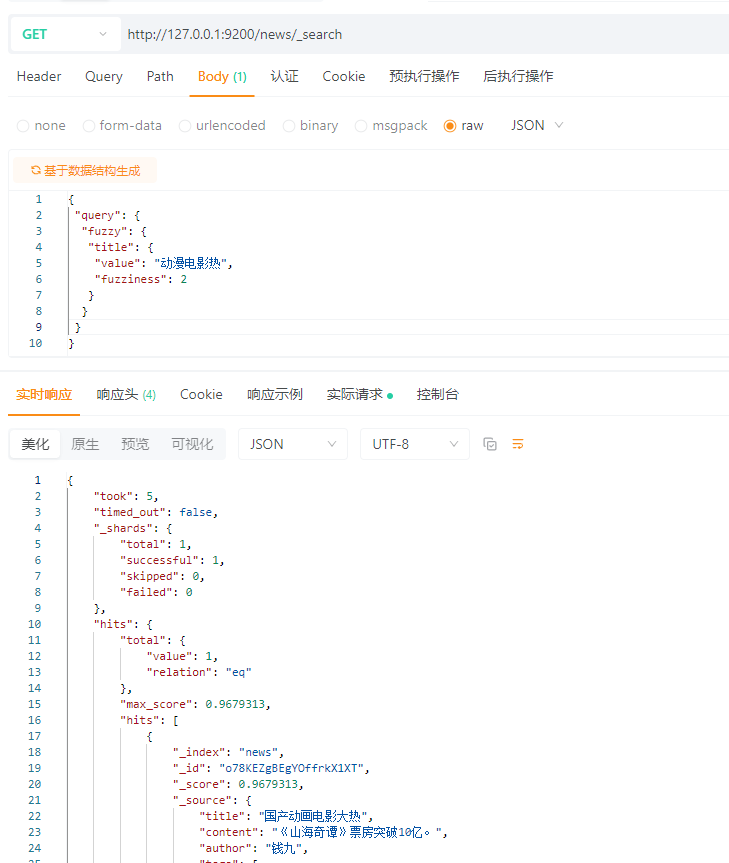
5.10 模糊匹配查询(Fuzzy)
Fuzzy(编辑距离),表示把一个词变成另外一个词需要多少步操作。这个操作可以是
1、插入 (sic - > sick)
2、删除 (black -> lack)
3、置换 (box -> fox)
4、转置 (act -> cat)
为了找到相似的术语,Fuzzy 查询会在指定的编辑距离内创建一组搜索词的所有可能的变体
或扩展。然后查询返回每个扩展的完全匹配。
通过 fuzziness 修改编辑距离。一般使用默认值 AUTO,根据术语的长度生成编辑距离。
{
\"query\": {
\"fuzzy\": {
\"title\": {
\"value\": \"动漫\",
\"fuzziness\": 1
}
}
}
}
{
\"query\": {
\"fuzzy\": {
\"title\": {
\"value\": \"动漫\",
\"fuzziness\": 1
}
}
}
}
5.11 字段排序(sort)
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。 desc 降序, asc 升序。
5.11.1 单字段排序
需求:按照发布日期倒序
{
\"query\": {
\"match\": {
\"title\": \"公司\"
}
},
\"sort\":[
{
\"publish_date\":\"desc\"
}
]
}
5.11.2 多字段排序
需求:按照发布日期倒序,排序后 如果有相同的日期则按照浏览量升序
{
\"query\": {
\"match\": {
\"title\": \"公司\"
}
},
\"sort\":[
{ \"publish_date\": { \"order\": \"desc\" } },
{ \"view_count\": { \"order\": \"asc\" } }
]
}
5.11.3 多字段+得分(_score)排序
需求:按照发布日期倒序,排序后 如果有相同的日期则按照浏览量升序,之后再按照得分倒序
{
\"query\": {
\"match\": {
\"title\": \"公司\"
}
},
\"sort\":[
{ \"publish_date\": { \"order\": \"desc\" } },
{ \"view_count\": { \"order\": \"asc\" } },
{ \"_score\":{\"order\": \"desc\"}}
]
}
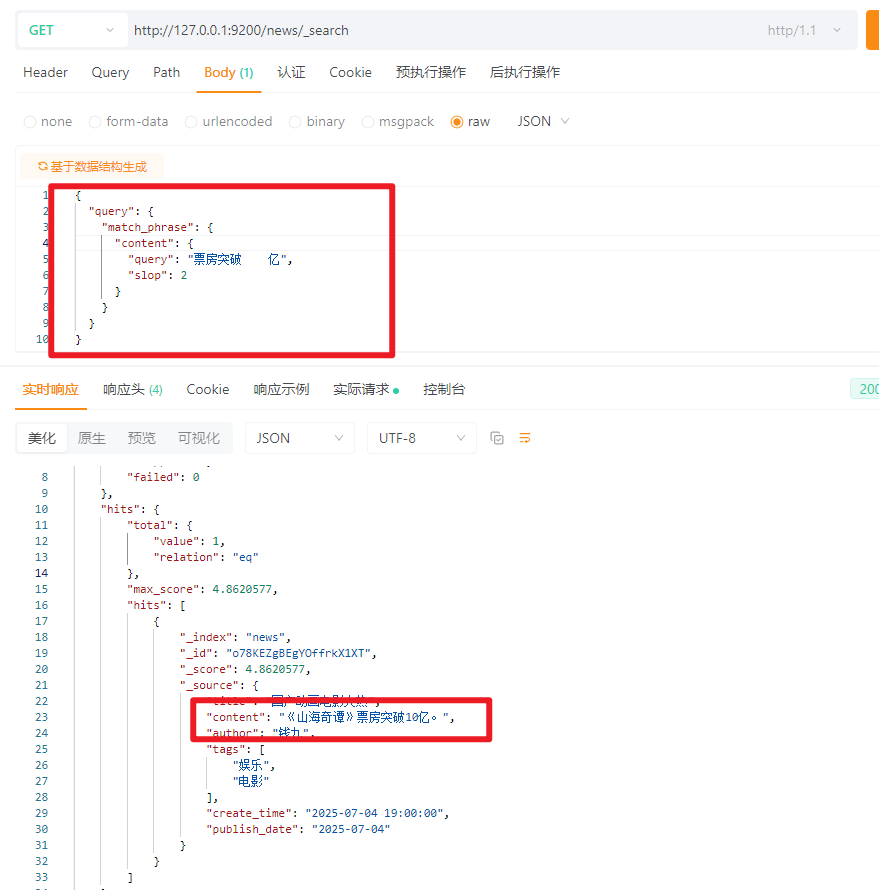
5.12 短语匹配查询(Match_phrase、slop)
Match_phrase = 匹配一个短语(多个词之间的顺序、位置都要一致) Match_phrase 和 Match的区别
matchmatch_phraseslop参数:允许词之间最多隔几个位置
{
\"query\": {
\"match_phrase\": {
\"content\": {
\"query\": \"票房突破 亿\",
\"slop\": 2
}
}
}
}
结果 :
5.13 高亮查询(highlight)
也是最最最常用的一个查询,当我们使用搜索引擎进行关键词搜索时,会凸显不同颜色,就称为高亮,例如下图:
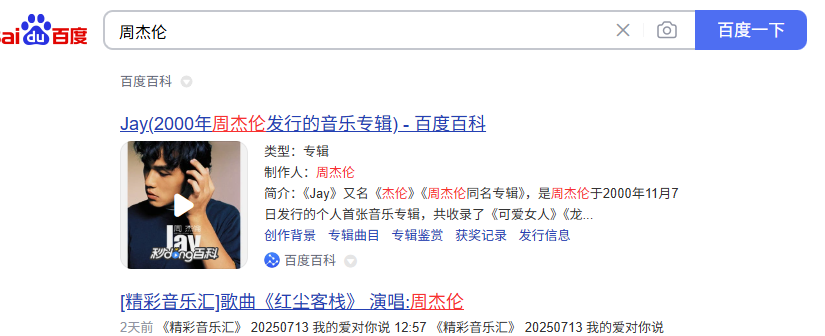
基本原理就是,除了返回的原始内容外,额外再返回highlight字段,highlight字段里包含了高亮后的字符串,默认是通过进行包括,例如:周杰伦
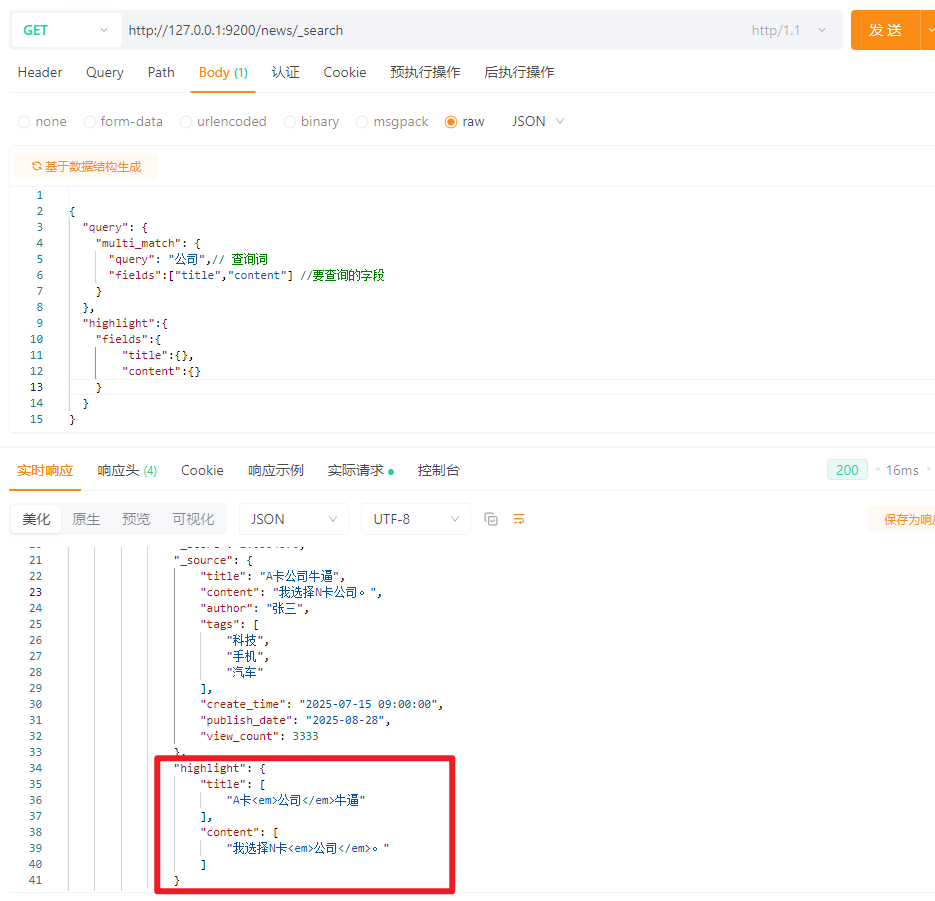
5.13.1 最常用的场景:搜索关键词,然后标题和内容都高亮
{
\"query\": {
\"multi_match\": {
\"query\": \"公司\",// 查询词
\"fields\":[\"title\",\"content\"] //要查询的字段
}
},
\"highlight\":{
\"fields\":{
\"title\":{},
\"content\":{}
}
}
}
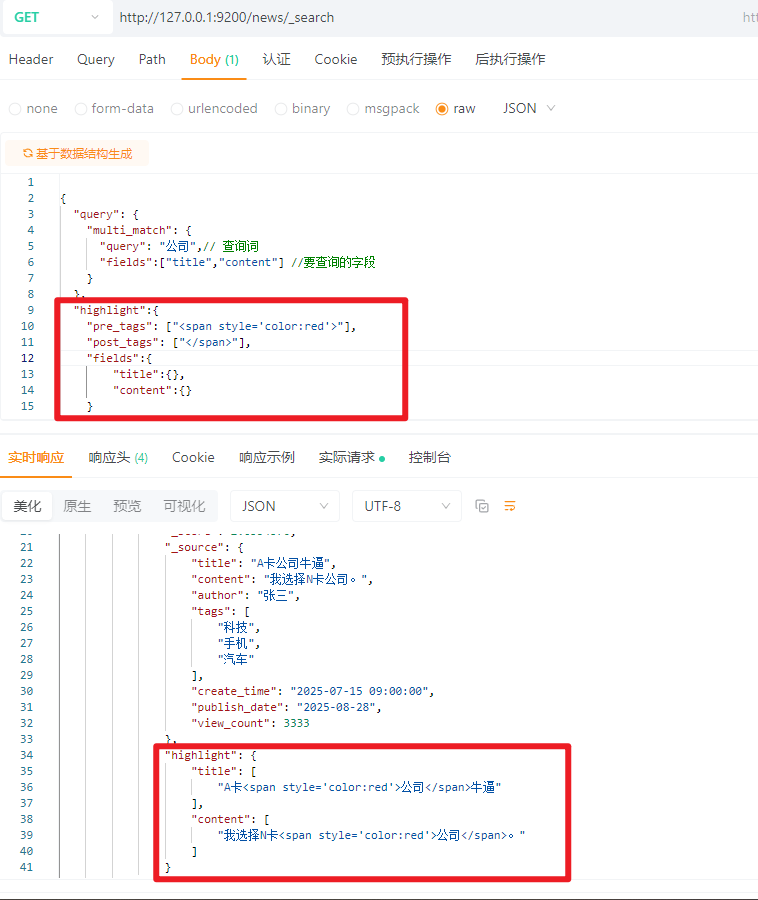
5.13.2 自定义高亮标签
highlight内置的参数:
pre_tags:前置标签
post_tags:后置标签
5.14 分页查询(from、size)
es自带的核心参数
fromsize结合mysql快速理解(limit、offset):
SELECT * FROM news
ORDER BY publish_date DESC
LIMIT 10 OFFSET 20;
ES:
{
\"query\": {
\"match_all\": {}
},
\"from\":10,
\"size\":20
}
需求:查询第二页的数据
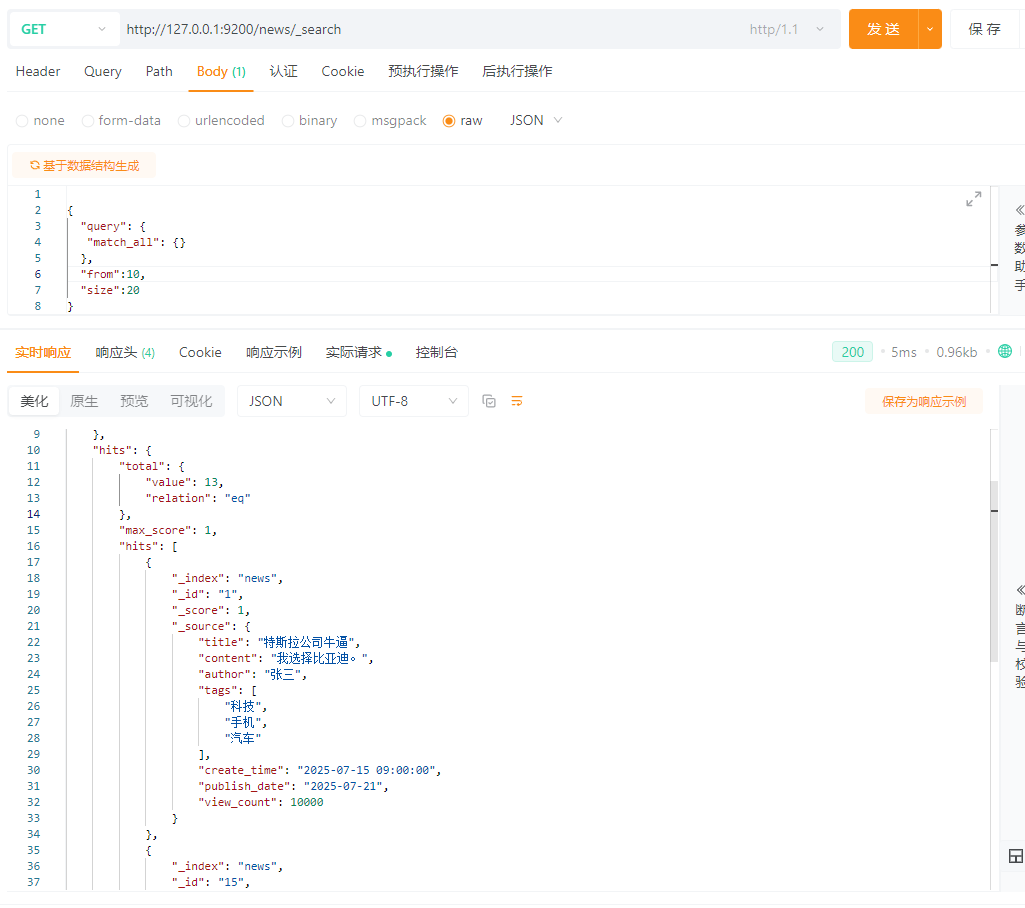
由上图也得hits.total = 13。为所有数据的总和
5.15 聚合查询(aggs)
聚合 = 在查询匹配到的结果集上进行统计/分组/计算,可以理解为 SQL里的
GROUP BY
COUNT
SUM
AVG
MAX
MIN
最常用到的就是分桶聚合和指标聚合
5.15.1 桶聚合(Bucketing)
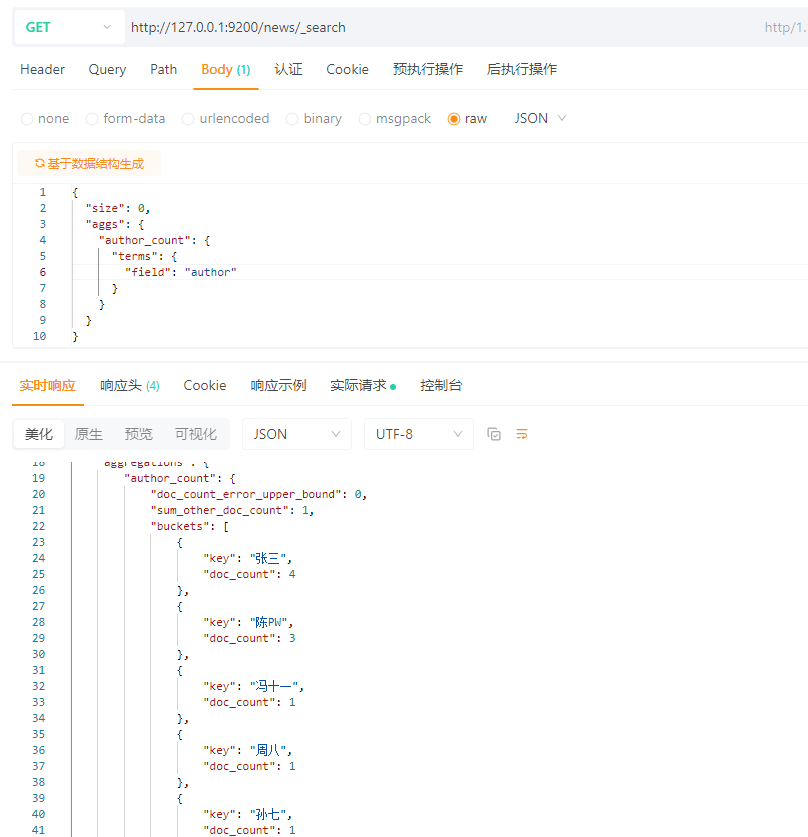
5.15.1.1 terms聚合(分组计数)
需求:统计每个author写了多少篇新闻
SQL语句快速理解:
SELECT author, COUNT(*) FROM news GROUP BY author;
ES:
{
\"size\": 0,
\"aggs\": {
\"author_count\": {
\"terms\": {
\"field\": \"author\"
}
}
}
}
ps:size=0是不返回文档,只返回聚合,author_count是随便起的名字
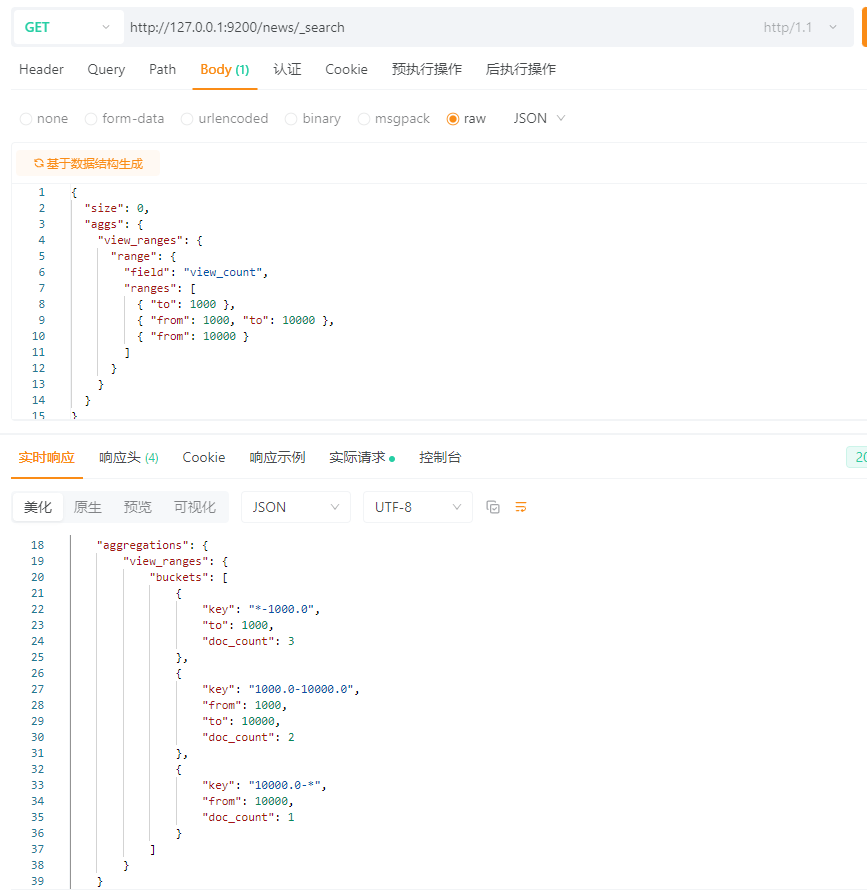
5.15.1.2 range聚合(区间分桶)
需求:浏览量区间统计
SQL语句快速理解:
SELECT
COUNT(*) WHERE view_count BETWEEN 0 AND 999,
COUNT(*) WHERE view_count BETWEEN 1000 AND 9999,
COUNT(*) WHERE view_count >= 10000;
ES:
{
\"size\": 0,
\"aggs\": {
\"view_ranges\": {
\"range\": {
\"field\": \"view_count\",
\"ranges\": [
{ \"to\": 1000 },
{ \"from\": 1000, \"to\": 10000 },
{ \"from\": 10000 }
]
}
}
}
}
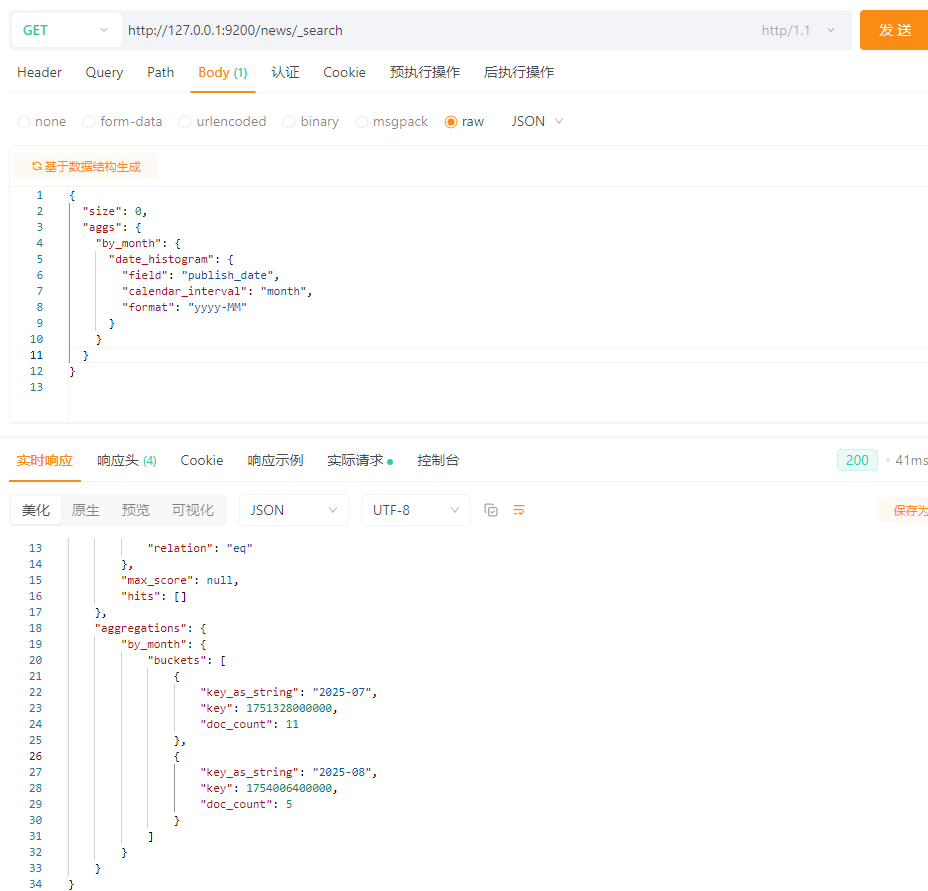
5.15.1.3 date_histogram聚合(时间分桶)
需求:按照月份统计文章的数量
SQL快速理解:
SELECT DATE_FORMAT(publish_date, \'%Y-%m\'), COUNT(*)
FROM news
GROUP BY DATE_FORMAT(publish_date, \'%Y-%m\');
ES:
{
\"size\": 0,
\"aggs\": {
\"by_month\": {
\"date_histogram\": {
\"field\": \"publish_date\",
\"calendar_interval\": \"month\",
\"format\": \"yyyy-MM\"
}
}
}
}
效果:
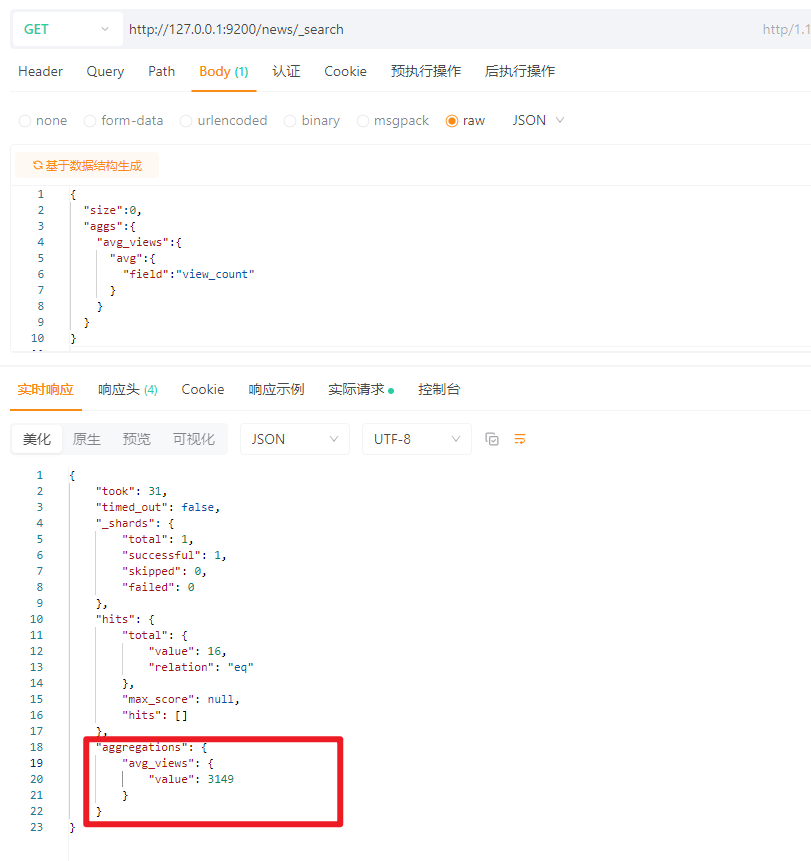
5.15.2 指标聚合(Metric)
5.15.2.1 平均值(avg)
SQL语句快速理解:
SELECT AVG(view_count) FROM news;
ES:
{
\"size\":0,
\"aggs\":{
\"avg_views\":{
\"avg\":{
\"field\":\"view_count\"
}
}
}
}
结果:
5.15.2.2 总和(sum)
{
\"size\":0,
\"aggs\":{
\"sum_views\":{
\"sum\":{
\"field\":\"view_count\"
}
}
}
}
5.15.2.3 最小值(min)
{
\"size\":0,
\"aggs\":{
\"min_date\":{
\"min\":{
\"field\":\"publish_date\"
}
}
}
}
5.15.2.4 最大值(max)
{
\"size\":0,
\"aggs\":{
\"max_date\":{
\"max\":{
\"field\":\"publish_date\"
}
}
}
}
5.15.2.5 整合案例
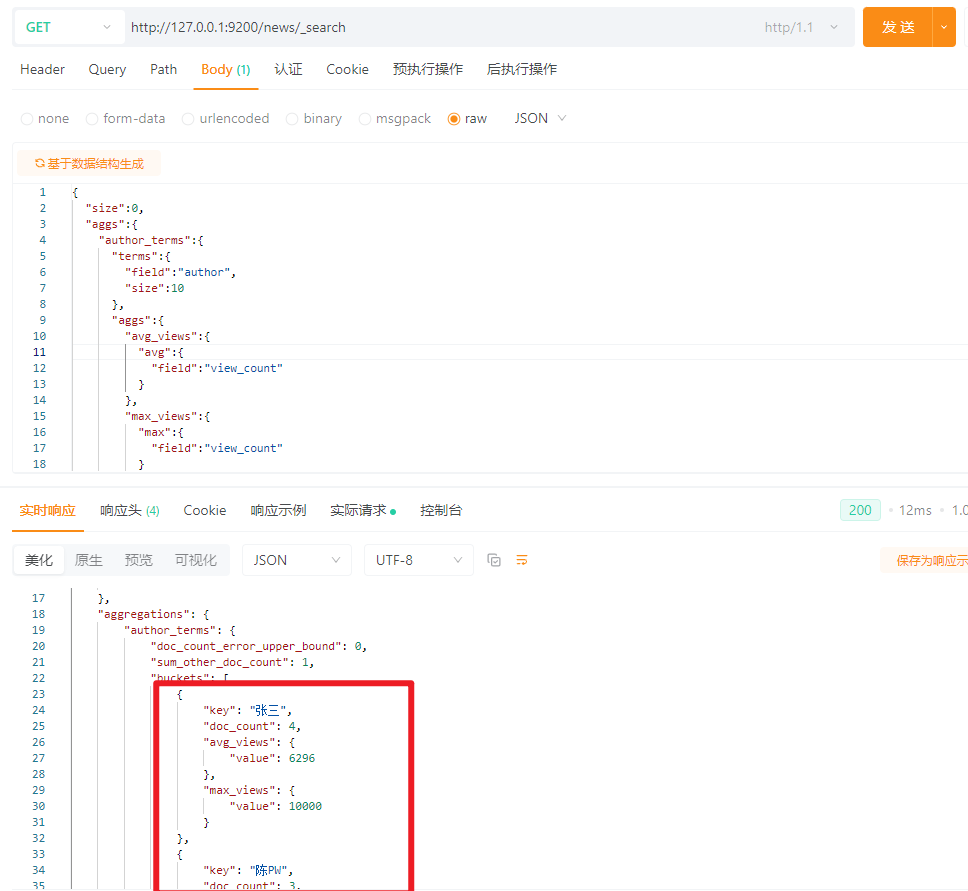
需求:按照作者分组,算出每组的平均浏览量和最大的浏览量,共返回10个分组
{
\"size\":0,
\"aggs\":{
\"author_terms\":{
\"terms\":{
\"field\":\"author\",
\"size\":10
},
\"aggs\":{
\"avg_views\":{
\"avg\":{
\"field\":\"view_count\"
}
},
\"max_views\":{
\"max\":{
\"field\":\"view_count\"
}
}
}
}
}
}
结果:
5.16 非常用查询(Prefix、Wildcard、Exists、Script)
5.16.1 前缀匹配查询(Prefix)
Prefix:只匹配开头是某个前缀的词
示例:
想找所有 title 以“国产”开头的文档
{
\"query\": {
\"prefix\": {
\"title\": \"国产\"
}
}
}
对应的SQL语句:
SELECT * FROM news WHERE title LIKE \'国产%\';
5.16.2 通配符查询(Wildcard)
Wildcard:支持通配符
1、*(任意字符,任意长度)
2、?(单个字符)
示例:
想找所有 title 结尾包含“电影”的标题
{
\"query\": {
\"wildcard\": {
\"title\": \"*电影\"
}
}
}
5.16.3 字段存在查询(Exists)
exists:寻找对应字段
示例:
想找所有 有tags字段的文档
{
\"query\": {
\"exists\": {
\"field\": \"tags\"
}
}
}
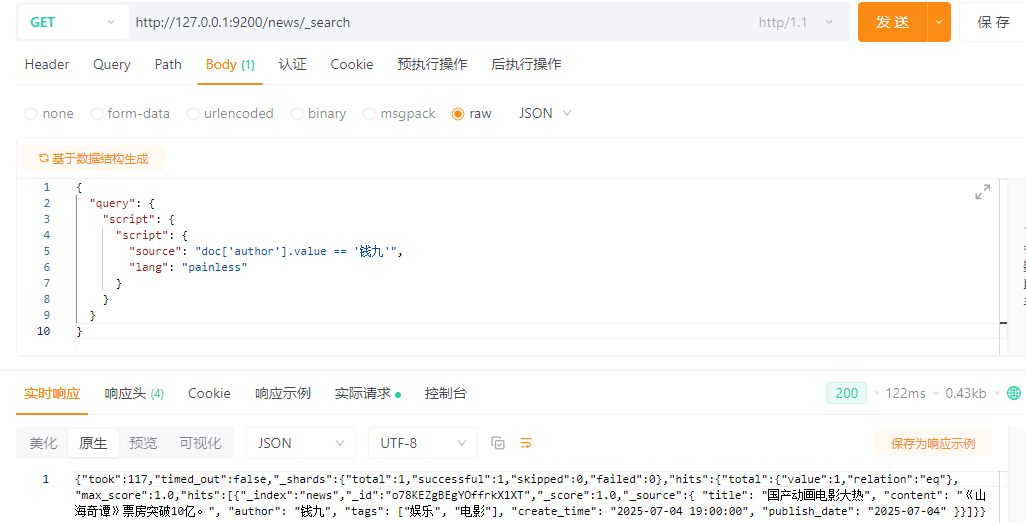
5.16.4 复杂脚本查询(Script)
需求:查询所有文档中,作者为“钱九”的文档
{
\"query\": {
\"script\": {
\"script\": {
\"source\": \"doc[\'author\'].value == \'钱九\'\",
\"lang\": \"painless\"
}
}
}
}
lang:表示脚本语言是painless(Elasticsearch官方内置脚本语言)
6、Springboot3整合Elasticsearch8实战
Springboot3整合Elasticsearch8实战:(文字太多了,另外写了一篇)
Springboot3整合Elasticsearch8(elasticsearch-java)-CSDN博客

