JB3-6-ElasticSearch(二)
Java道经第3卷 - 第6阶 - ElasticSearch(二)
传送门:JB3-6-ElasticSearch(一)
传送门:JB3-6-ElasticSearch(二)
文章目录
- S03. Logstash
-
- E01. ELK收集系统日志
-
- 1. Logstash单机容器搭建
- 2. 搭建ELK收集日志系统
- E02. ELK同步MySQL
-
- 1. MySQL全量同步
- 2. MySQL增量同步
- S04. ElasticsearchRepository
-
- E01. 基础使用流程
-
- 1. 对属性配置IK分词
- 2. 开发类型转换器
- 3. 开发Doc实体类
- E02. 常用API方法
-
- 1. 客户端 - 添加API
- 2. 客户端 - 查询API
- 3. 客户端 - 修改API
- 4. 客户端 - 删除API
S03. Logstash
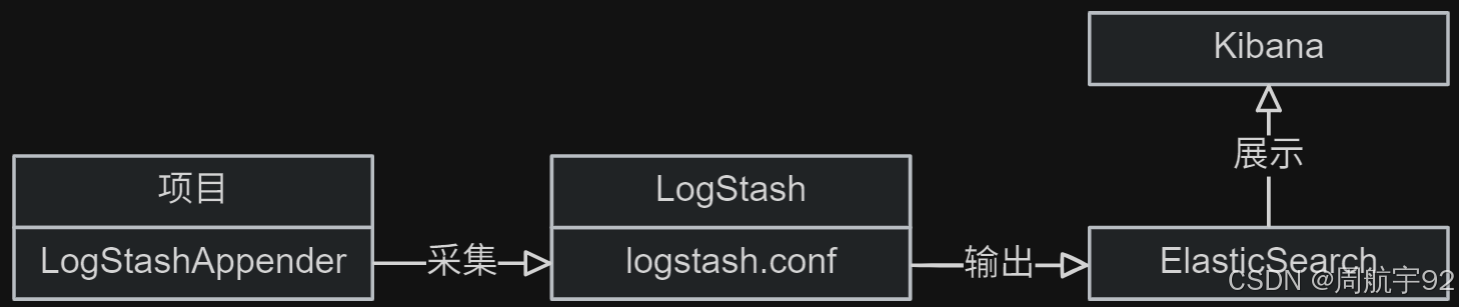
心法:ELK = ElasticSearch + Logstash + Kibana
ELK 组件:三个开源工具的版本号必须保持一致:
- 收集过滤
Logstash:数据收集处理引擎,负责收集和过滤项目日志数据。 - 搜索分析
Elasticsearch:分布式搜索引擎,负责存储和分析日志数据。 - 展示操作
Kibana:数据可视化平台,负责展示日志数据。
E01. ELK收集系统日志
心法:本集内容的前提是成功搭建了 elasticsearch(9200) 和 kibana(5601) 容器。
1. Logstash单机容器搭建
武技:在 Docker 中搭建专门负责日志收集的单机 Logstash 容器
- 创建相关目录:
# 创建Logstash相关目录mkdir -p /opt/logstash/conf;- 创建
/opt/logstash/conf/logstash.yml配置文件:
touch /opt/logstash/conf/logstash.yml填写内容如下:
# 允许任意主机访问http.host: \"0.0.0.0\"# 服务端口号http.port: 4560# ES服务地址xpack.monitoring.elasticsearch.hosts: [\"http://192.168.40.77:9200\"] - 创建
/opt/logstash/conf/logstash.conf配置文件:
touch /opt/logstash/conf/logstash.conf填写内容如下:
# logstash 输入模块,从日志或数据库中采集数据input { tcp { # 服务器模式 mode => \"server\" # 允许任意主机发送日志 host => \"0.0.0.0\" # 连接端口号 port => 5000 # 数据格式 codec => \"json_lines\" }}# logstash 输出模块,将采集好的数据同步至 ESoutput { elasticsearch { # ES主机地址 hosts => [\"http://192.168.40.77:9200\"] # ES索引名称,名称随意 index => \"elk-log-%{+yyyy.MM.dd}\" # 数据格式 codec => \"json\" }}- 提升两个配置文件的权限:
# 提升两个配置文件权限chmod -R 777 /opt/logstash;- 创建运行容器:
# 拉取镜像(二选一)docker pull logstash:8.4.0;docker pull registry.cn-hangzhou.aliyuncs.com/joezhou/logstash:8.4.0;# 创建并运行Logstash容器docker run -d --name elk-log --network my-net -p 5000:5000 -p 4560:4560 \\-v /opt/logstash/conf/logstash.yml:/usr/share/logstash/config/logstash.yml \\-v /opt/logstash/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \\registry.cn-hangzhou.aliyuncs.com/joezhou/logstash:8.4.0;# 查看运行的容器docker ps --format \"{{.ID}}\\t{{.Names}}\\t{{.Ports}}\"docker logs elk-log --tail 30# 永久开放4560服务端口和5000TCP连接端口firewall-cmd --add-port=4560/tcp --permanentfirewall-cmd --add-port=5000/tcp --permanentfirewall-cmd --reload- 访问单机容器 http://192.168.40.77:4560:预期结果如下:
{ \"host\": \"3a861446033a\", \"version\": \"8.4.0\", \"http_address\": \"0.0.0.0:4560\", \"id\": \"3a8114ce-81df-4675-be08-e2b4b2734813\", \"name\": \"3a861446033a\", \"ephemeral_id\": \"a030a55b-dbca-4ba9-8d4a-348e33ed042b\", \"status\": \"green\", \"snapshot\": false, \"pipeline\": { \"workers\": 4, \"batch_size\": 125, \"batch_delay\": 50 }, \"build_date\": \"2022-08-19T19:24:47Z\", \"build_sha\": \"68d2c67222de5ff08adc99e491ce5cc23f0d003b\", \"build_snapshot\": false}2. 搭建ELK收集日志系统
武技:创建 v3-6-ssm-elasticsearch/elasticsearch-elk 子项目,并使用 Logstash 收集项目日志。
- 添加三方依赖:
<dependencies> <dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>${logstash-logback-encoder.version}</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency></dependencies>- 开发启动类:
package com.joezhou;/** @author 周航宇 */@SpringBootApplicationpublic class ELKApp { public static void main(String[] args) { SpringApplication.run(ELKApp.class, args); }}- 在子项目的日志配置文件
logback.xml中添加一个指向 logstash 的 Appender:
<configuration> <property name=\"LOG_PATTERN\" value=\"%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p %4.15(%t) %c{1}.%M:%L %msg%n\"/> <appender name=\"CONSOLE\" class=\"ch.qos.logback.core.ConsoleAppender\"> <encoder> <pattern>${LOG_PATTERN}</pattern> </encoder> </appender> <appender name=\"LOGSTASH\" class=\"net.logstash.logback.appender.LogstashTcpSocketAppender\"> <destination>192.168.40.77:5000</destination> <encoder charset=\"UTF-8\" class=\"net.logstash.logback.encoder.LogstashEncoder\"> <customFields>{\"app\": \"elasticsearch-elk\"}</customFields> </encoder> <filter class=\"ch.qos.logback.classic.filter.LevelFilter\"> <level>INFO</level> <onMatch>DENY</onMatch> <onMismatch>ACCEPT</onMismatch> </filter> </appender> <root level=\"INFO\"> <appender-ref ref=\"CONSOLE\"/> <appender-ref ref=\"LOGSTASH\"/> </root></configuration>- 开发测试类:
package logstash;/** @author 周航宇 */@Slf4j@RunWith(SpringRunner.class)@SpringBootTest(classes = ELKLogApp.class)public class LogStashTest { @SneakyThrows @Test public void logstash() { log.debug(\"一条DEBUG级别日志测试记录\"); log.info(\"一条INFO级别日志测试记录\"); log.warn(\"一条WARN级别日志测试记录\"); log.error(\"一条ERROR级别日志测试记录\"); // 保证Logstash在项目运行结束前完成日志采集工作 TimeUnit.SECONDS.sleep(2L); } }- 在 Windows 机器上访问 Kibana 容器 http://192.168.40.77:5601。
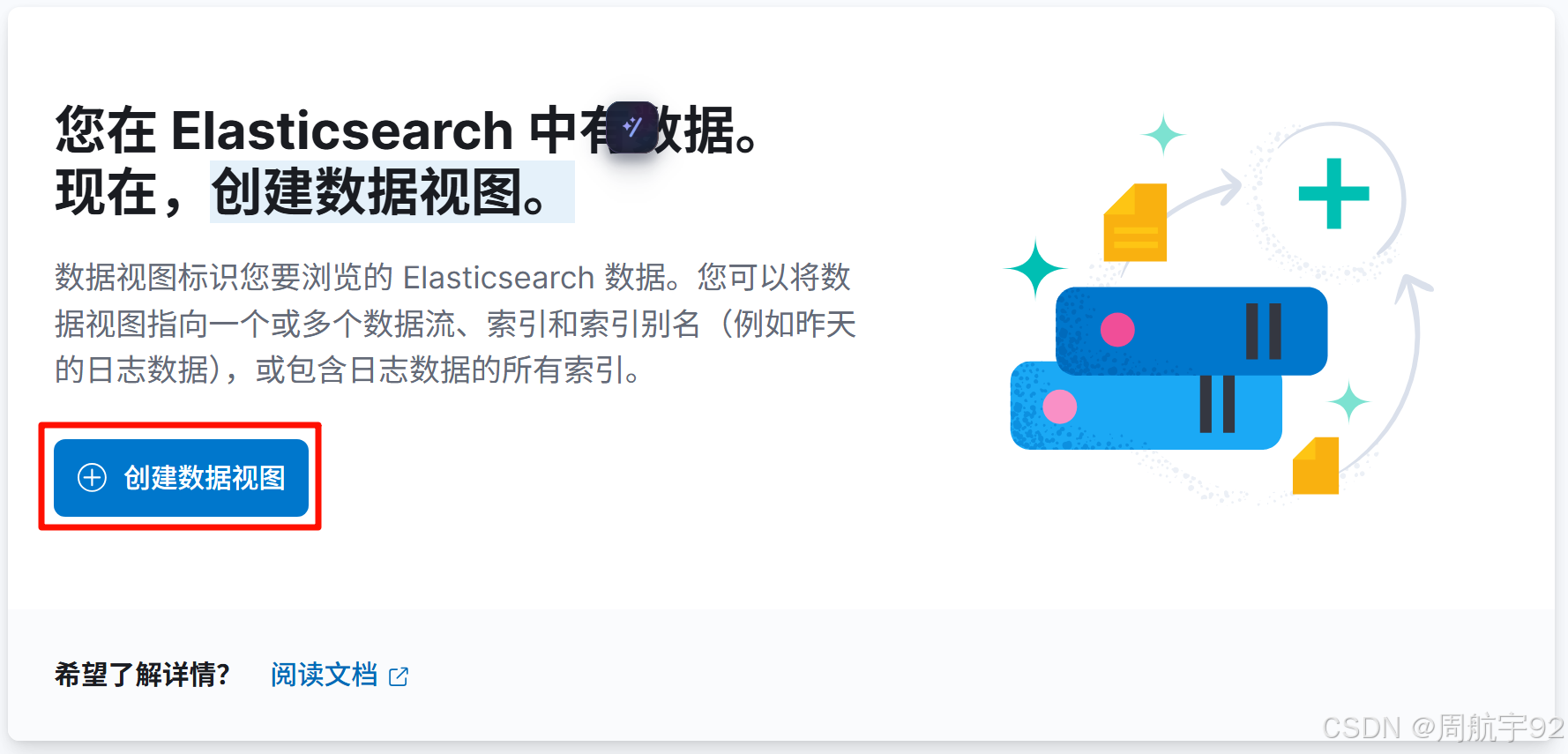
- 点击左上角三横线图片进入
Discover页面。 - 点击 创建数据视图 按钮:
- 填写名称,索引模式和时间戳字段:
- 名称:唯一标识,随意输入,如
elk-log等。 - 索引模式:模糊匹配索引,如
elk-log-*等。 - 时间戳字段:选择
@timestamp作为全局时间筛选的主要时间字段。
- 名称:唯一标识,随意输入,如
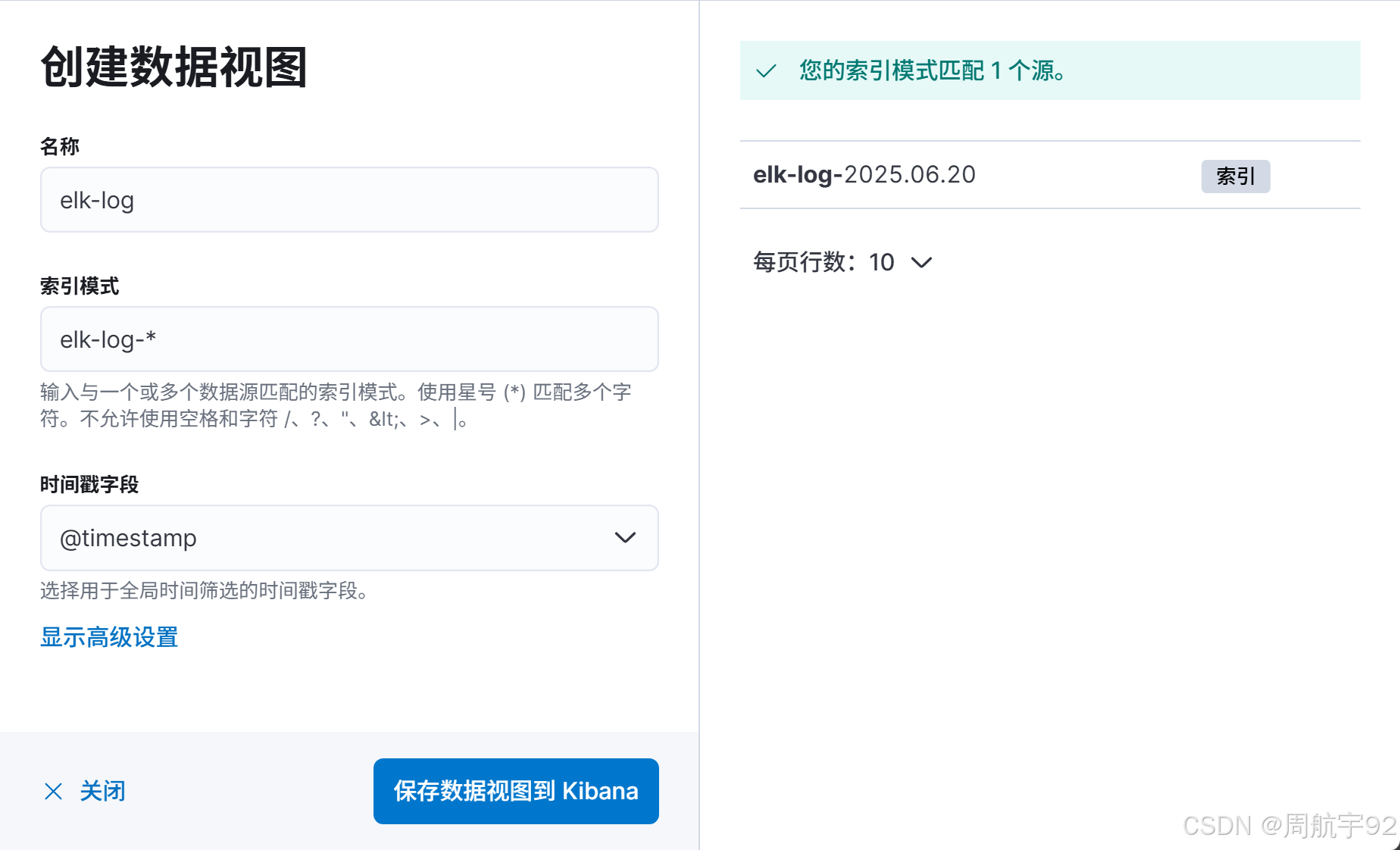
- 点击 保存数据到视图 按钮。
E02. ELK同步MySQL
心法:ELK 系统可以将 MySQL 数据和 ES 数据进行同步,数据同步会增加 MySQL 的负载,可能会对 MySQL 正常的数据读写造成影响,此时建议在 MySQL 集群中增加一个专用的只读节点,该节点尽可能与 ELK 同在一个机房。
同步 MySQL 数据方案:
- 全量同步:每次都将 MySQL 中的数据全部同步到 ES 中,数据一致性高,但效率低。
- 增量同步:每次只将 MySQL 中新增的数据同步到 ES 中,数据一致性低,但效率高(首次执行仍可视为是一次全量同步)。
同步 MySQL 数据流程:
- Logstash 执行
select count(*)获得总条目数。 - Logstash 根据
statement配置的 SQL 语句来拉取数据,若配置了分页,则 Logstatsh 通过 Limit 语句分批从 MySQL 拉取数据,默认是每次 10 万条。 - 数据拉取完毕后,Logstash 将最后一条数据的
updated写入到lastRun文件中(全量同步不需要记录),若数据拉取过程中下次拉取调度已经到达,则会将下次拉取调度的任务放到任务执行堆栈中。 - Logstash 会根据
schedule配置来执行下一次数据拉取任务(只有updated > lastRun的记录会被拉取),但被删除掉的 SQL 记录,不会被拉取到 ES 中,需要在业务逻辑中进行相关删除或使用逻辑删除。
武技:创建测试数据库并引入员工和部门表
create database es default charset utf8mb4;use es;-- 部门表 CREATE TABLE dept ( deptno INT PRIMARY KEY, -- 部门编号 dname VARCHAR(14), -- 部门名称 loc VARCHAR(13), -- 部门地址 created datetime, -- 创建时间 updated datetime -- 修改时间 ); INSERT INTO dept VALUES (10, \'ACCOUNTING\', \'NEW YORK\', now(), now()), (20, \'RESEARCH\', \'DALLAS\', now(), now()), (30, \'SALES\', \'CHICAGO\', now(), now()), (40, \'OPERATIONS\', \'BOSTON\', now(), now()); -- 员工表 CREATE TABLE emp ( empno INT PRIMARY KEY, -- 员工编号 ename VARCHAR(10), -- 员工名称 job VARCHAR(9), -- 工作 mgr INT, -- 直属领导编号 hiredate DATE, -- 入职时间 sal DOUBLE, -- 工资 comm DOUBLE, -- 奖金 deptno INT, -- 部门号 created datetime, -- 创建时间 updated datetime, -- 修改时间 FOREIGN KEY (deptno) REFERENCES dept (deptno) ); INSERT INTO emp VALUES (7369, \'SMITH\', \'CLERK\', 7902, \'1980-12-17\', 800, NULL, 20, now(), now()), (7499, \'ALLEN\', \'SALESMAN\', 7698, \'1981-02-20\', 1600, 300, 30, now(), now()), (7521, \'WARD\', \'SALESMAN\', 7698, \'1981-02-22\', 1250, 500, 30, now(), now()), (7566, \'JONES\', \'MANAGER\', 7839, \'1981-04-02\', 2975, NULL, 20, now(), now()), (7654, \'MARTIN\', \'SALESMAN\', 7698, \'1981-09-28\', 1250, 1400, 30, now(), now()), (7698, \'BLAKE\', \'MANAGER\', 7839, \'1981-05-01\', 2850, NULL, 30, now(), now()), (7782, \'CLARK\', \'MANAGER\', 7839, \'1981-06-09\', 2450, NULL, 10, now(), now()), (7788, \'SCOTT\', \'ANALYST\', 7566, \'1987-07-13\', 3000, NULL, 20, now(), now()), (7839, \'KING\', \'PRESIDENT\', NULL, \'1981-11-17\', 5000, NULL, 10, now(), now()), (7844, \'TURNER\', \'SALESMAN\', 7698, \'1981-09-08\', 1500, 0, 30, now(), now()), (7876, \'ADAMS\', \'CLERK\', 7788, \'1987-07-13\', 1100, NULL, 20, now(), now()), (7900, \'JAMES\', \'CLERK\', 7698, \'1981-12-03\', 950, NULL, 30, now(), now()), (7902, \'FORD\', \'ANALYST\', 7566, \'1981-12-03\', 3000, NULL, 20, now(), now()), (7934, \'MILLER\', \'CLERK\', 7782, \'1982-01-23\', 1300, NULL, 10, now(), now());1. MySQL全量同步
武技:使用 Logstash 全量同步 MySQL 中的部门表
- 创建相关目录:
# 创建Logstash相关目录mkdir -p /opt/elk-dept/conf;- 将 mysql-connector-java-8.0.16.jar 拷贝到
/opt/elk-dept/目录下。 - 创建
/opt/elk-dept/conf/logstash.yml配置文件:
touch /opt/elk-dept/conf/logstash.yml;填写内容如下:
# 允许任意主机访问http.host: \"0.0.0.0\" # 服务端口号http.port: 4560# ES服务地址xpack.monitoring.elasticsearch.hosts: [ \"http://192.168.40.77:9200\" ] - 创建
/opt/elk-dept/conf/logstash.conf配置文件:
touch /opt/elk-dept/conf/logstash.conf;填写内容如下:
# logstash 输入模块,从日志或数据库中采集数据input { jdbc { # MySQL驱动包:地址相对容器内部jdbc_driver_library => \"/data/mysql-connector-java-8.0.16.jar\"# MySQL数据源jdbc_driver_class => \"com.mysql.cj.jdbc.Driver\" jdbc_connection_string => \"jdbc:mysql://192.168.40.77:3306/es?characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai\"jdbc_user => \"root\" jdbc_password => \"root\"# 数据库重连尝试次数 connection_retry_attempts => \"3\"# 是否校验数据库连接:默认false不校验 jdbc_validate_connection => \"true\" # 校验数据库连接的超时时间:默认3600ms jdbc_validation_timeout => \"3600\"# 查询语句:通过哪条SQL语句采集数据库记录 statement => \"select * from es.dept d order by d.updated asc\" # 开启分页查询:默认false不开启 jdbc_paging_enabled => \"true\" # 单次分页查询条数:默认100000 jdbc_page_size => \"500\"# 同步频率:默认 \"* * * * *\",表示每分钟同步一次# CRON表达式:\"分 时 天 月 年\" schedule => \"* * * * *\" # SQL日志等级: 可选 fatal, error, warn, info, debug,默认info sql_log_level => warn # 是否将字段名转换为小写:默认true # 如果有数据序列化、反序列化需求,建议改为false lowercase_column_names => false }}# 过滤移除 @timestamp 和 @version 属性filter {mutate {remove_field => [\"@timestamp\"]}mutate {remove_field => [\"@version\"]}}# logstash 输出模块,将采集好的数据同步至 ESoutput { elasticsearch { # ES主机地址 hosts => [\"http://192.168.40.77:9200\"] # ES索引名称:名称随意 index => \"dept\" # 数据格式 codec => \"json\" # 文档索引:建议使用数据库表主键,该值会注入文档的 _id 字段,缺省时随机生成,会造成数据重复 document_id => \"%{deptno}\" }}- 提升两个配置文件的权限:
# 提升两个配置文件权限chmod -R 777 /opt/elk-dept;- 创建运行容器:
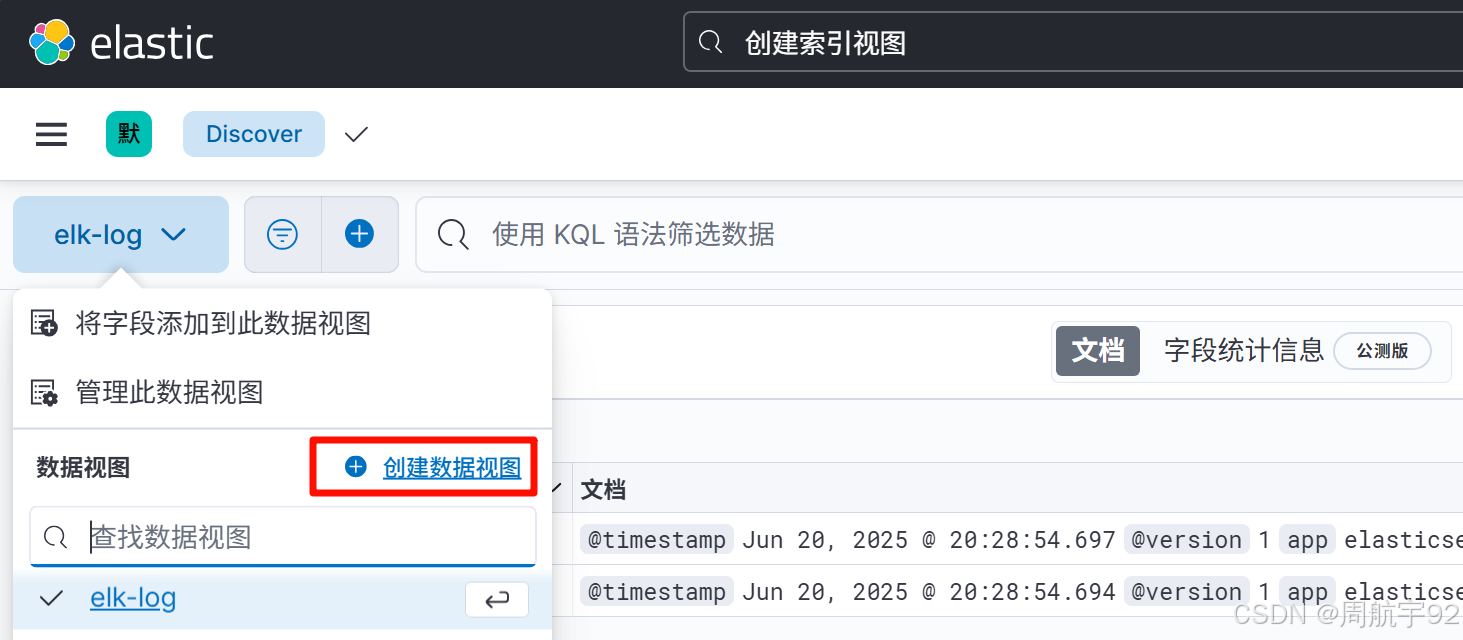
# 创建并运行Logstash容器docker run -d --name elk-dept --network my-net -p 4660:4560 \\-v /opt/elk-dept/conf/logstash.yml:/usr/share/logstash/config/logstash.yml \\-v /opt/elk-dept/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \\-v /opt/elk-dept:/data \\registry.cn-hangzhou.aliyuncs.com/joezhou/logstash:8.4.0;# 查看运行的容器docker ps --format \"{{.ID}}\\t{{.Names}}\\t{{.Ports}}\"docker logs elk-dept --tail 30# 永久开放4660端口firewall-cmd --add-port=4660/tcp --permanentfirewall-cmd --reload- 等待 1 分钟后,在 Kibana 的 Discover 中查看数据是否已经同步到 ES 中:
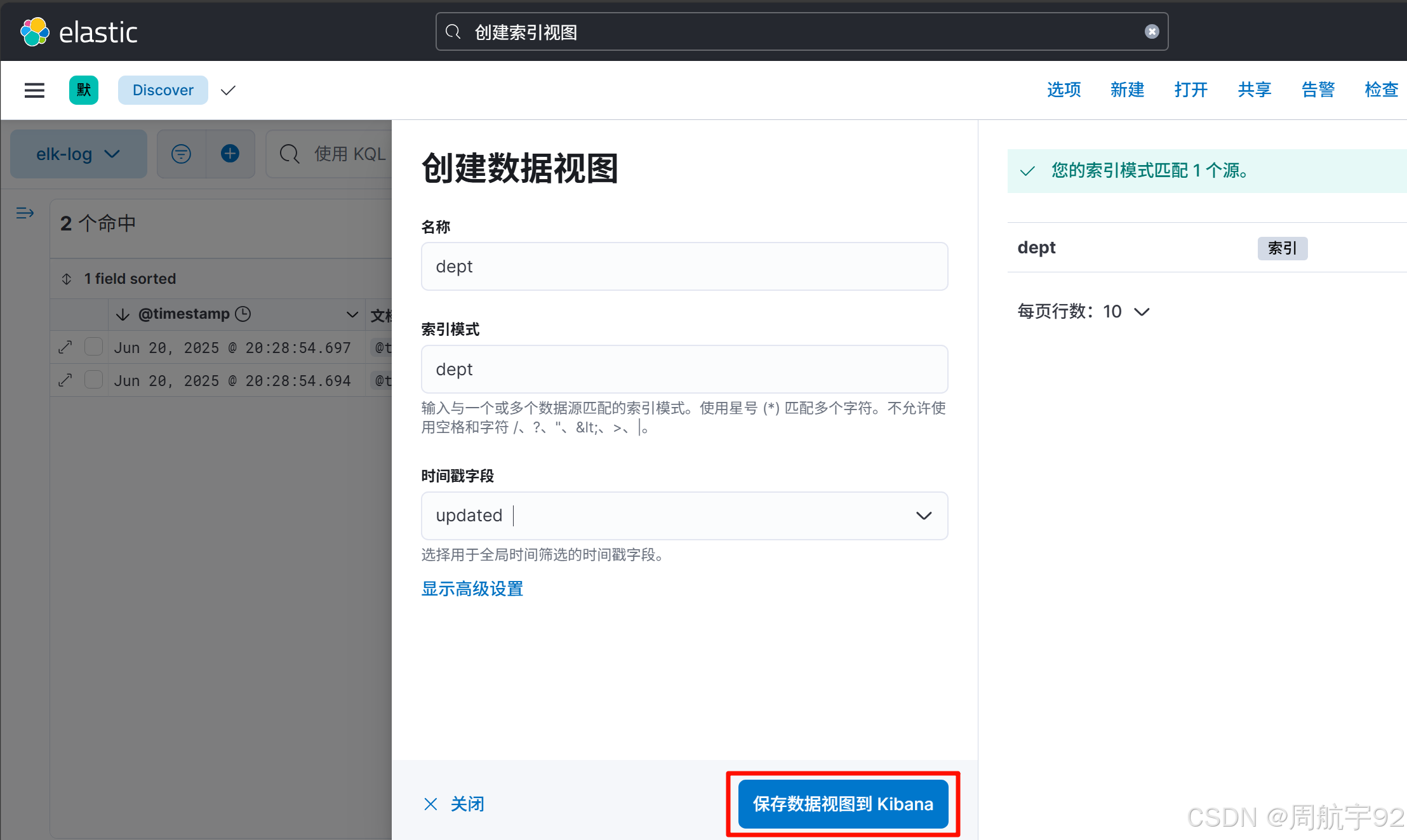
- 对 MySQL 进行一些 DML 操作,等待 1 分钟,查看是否发生同步:
insert into es.dept (deptno, dname, updated) values (50, \'开发部\', now());update es.dept set dname = \'销售部\', updated = now() where deptno = 10;-- 删除掉的SQL记录,不会被拉取到ES中,需要在业务逻辑中进行相关删除或使用逻辑删除。delete from es.dept where deptno = 40;2. MySQL增量同步
武技:使用 Logstash 增量同步 MySQL 中的员工表
- 创建相关目录:
# 创建Logstash相关目录mkdir -p /opt/elk-emp/conf;- 将 mysql-connector-java-8.0.16.jar 拷贝到
/opt/elk-emp/下。 - 创建
/opt/elk-emp/conf/logstash.yml配置文件:
touch /opt/elk-emp/conf/logstash.yml;填写内容如下:
# 允许任意主机访问http.host: \"0.0.0.0\"# 服务端口号http.port: 4560# ES服务地址xpack.monitoring.elasticsearch.hosts: [\"http://192.168.40.77:9200\"]- 创建
/opt/elk-emp/conf/logstash.conf配置文件:
touch /opt/elk-emp/conf/logstash.conf;填写内容如下:
# logstash 输入模块,从日志或数据库中采集数据input {jdbc { # MySQL驱动包:地址相对容器内部jdbc_driver_library => \"/data/mysql-connector-java-8.0.16.jar\"# MySQL数据源jdbc_driver_class => \"com.mysql.cj.jdbc.Driver\" jdbc_connection_string => \"jdbc:mysql://192.168.40.77:3306/es?characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai\"jdbc_user => \"root\" jdbc_password => \"root\" # 数据库重连尝试次数 connection_retry_attempts => \"3\"# 是否校验数据库连接:默认false不校验 jdbc_validate_connection => \"true\" # 校验数据库连接的超时时间:默认3600ms jdbc_validation_timeout => \"3600\"# 查询语句:通过哪条SQL语句采集数据库记录 statement => \"select * from es.emp e where e.updated > :sql_last_value order by e.updated asc\" # 开启分页查询:默认false不开启 jdbc_paging_enabled => \"true\" # 单次分页查询条数:默认100000 jdbc_page_size => \"500\"# 同步频率:默认 \"* * * * *\",表示每分钟同步一次# CORN表达式:\"分 时 天 月 年\" schedule => \"* * * * *\" # SQL日志等级: 可选 fatal, error, warn, info, debug,默认info; sql_log_level => warn # 是否将字段名转换为小写:默认true # 如果有数据序列化、反序列化需求,建议改为false lowercase_column_names => false############## 增量同步相关配置 ############### 开启自定义标识列:false时,标识列默认为当前timestamp的值 use_column_value => true# 标识列:用于增量同步,需是数据库字段,不用添加别名tracking_column => \"updated\"# 标识列类型:可选 numeric 和 timestamp,默认numeric tracking_column_type => timestamp # true:将上次执行结果中的最后一条SQL记录的 updated 字段的值记录在TXT文件中 # false:不记录 record_last_run => true# TXT文件:地址相对容器内部 last_run_metadata_path => \"/data/last_id.txt\"# 是否清除TXT文件记录:增量同步时此配置字段必须设置为false clean_run => false }}# 过滤移除 @timestamp 和 @version 属性filter {mutate {remove_field => [\"@timestamp\"]}mutate {remove_field => [\"@version\"]}}# logstash 输出模块,将采集好的数据同步至 ESoutput {elasticsearch {# ES主机地址hosts => [\"http://192.168.40.77:9200\"] # ES索引名称:名称随意index => \"emp\"# 文档索引:建议使用数据库表主键,该值会注入文档的 _id 字段,缺省时随机生成,会造成数据重复document_id => \"%{empno}\"}stdout {codec => json_lines}}- 提升两个配置文件的权限:
# 提升两个配置文件权限chmod -R 777 /opt/elk-emp;- 创建运行容器:
# 创建并运行Logstash容器docker run -d --name elk-emp --network my-net -p 4760:4560 \\-v /opt/elk-emp/conf/logstash.yml:/usr/share/logstash/config/logstash.yml \\-v /opt/elk-emp/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \\-v /opt/elk-emp:/data \\registry.cn-hangzhou.aliyuncs.com/joezhou/logstash:7.11.2;# 查看运行的容器docker ps --format \"{{.ID}}\\t{{.Names}}\\t{{.Ports}}\"docker logs elk-emp --tail 30# 永久开放4760端口firewall-cmd --add-port=4760/tcp --permanentfirewall-cmd --reload- 等待 1 分钟后,在 Kibana 中查看数据是否已经同步到 ES 中:
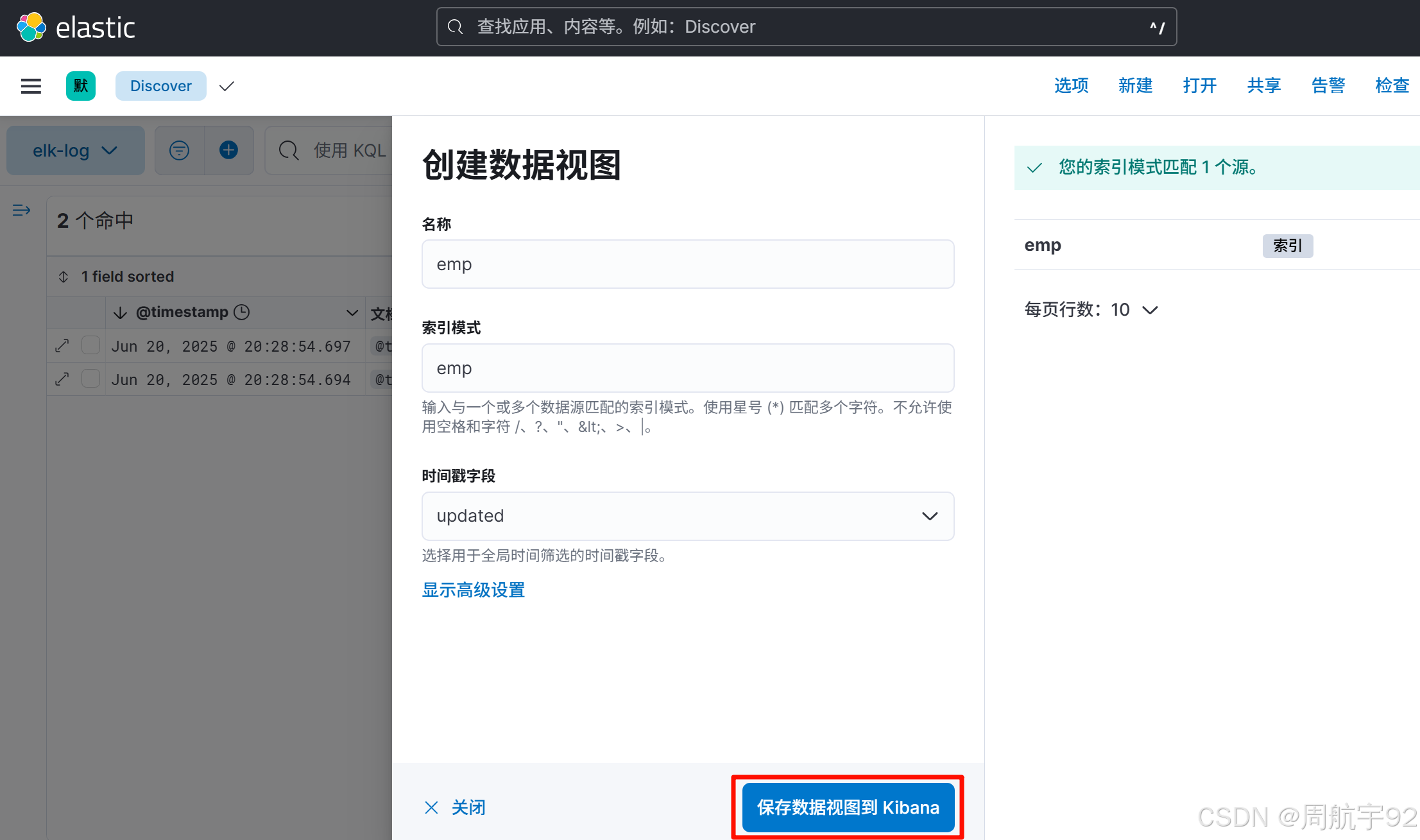
- 对 MySQL 进行一些 DML 操作,等待 1 分钟,查看是否发生同步:
insert into es.emp (empno, ename, updated) values (9999, \'赵四\', now());update es.emp set ename = \'刘能\', updated = now() where empno = 6379;-- 删除掉的SQL记录,不会被拉取到ES中,需要在业务逻辑中进行相关删除或使用逻辑删除。delete from es.emp where empno = 7654;S04. ElasticsearchRepository
心法:org.springframework.data.elasticsearch.repository.ElasticsearchRepository 是 Spring Data Elasticsearch 提供的一个接口数据访问接口,旨在简化在 Spring 应用中对 Elasticsearch 的操作,使得开发者可以像操作传统数据库一样方便地操作 Elasticsearch 中的数据。
武技:创建 v3-6-ssm-elasticsearch/elasticsearch-template 子项目,用于测试 ElasticsearchRepository 客户端。
- 添加三方依赖:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies>- 开发主配文件:
server: port: 13602 # 端口号spring: elasticsearch: uris: http://192.168.40.77:9200 # 指定ES服务器,集群用数组logging: level: org.springframework.data.convert.CustomConversions: ERROR # 忽略CustomConversions警告- 开发启动类:
package com.joezhou;/** @author 周航宇 */@SpringBootApplicationpublic class EsTemplateApp { public static void main(String[] args) { SpringApplication.run(EsTemplateApp.class, args); }}- 启动项目,只要不报错,就说明项目连接 ES 容器大概率成功。
E01. 基础使用流程
1. 对属性配置IK分词
心法:对指定索引中的指定属性字段设置 IK 分词,需要手动更改该索引库的 mapping 内容。
- 拷贝 ES 索引库的 mapping 内容到记事本:
# 拷贝 dept 索引库中的 `mapping{}` 配置到记事本,注意末尾逗号不需要GET dept# 拷贝 emp 索引中库的 `mapping{}` 配置到记事本,注意末尾逗号不需要GET emp- 删除 ES 索引:
# 删除 dept 索引库DELETE dept# 删除 emp 索引库DELETE emp- 重建 ES 索引库(重建时在 body 中粘贴备份的 mapping 内容):
# 重建 dept 索引库,在 body 中粘贴 `mapping{}` 内容# `dname` 字段需要在 `fields` 同级额外添加 `\"analyzer\" : \"ik_max_word\"` 配置# `dname` 字段需要在 `fields` 同级额外添加 `\"search_analyzer\" : \"ik_smart\"` 配置PUT dept{ \"mappings\": { \"properties\": { \"_class\": { \"type\": \"text\", \"fields\": { \"keyword\": { \"type\": \"keyword\", \"ignore_above\": 256 } } }, \"dname\": { \"type\": \"text\", \"fields\": { \"keyword\": { \"type\": \"keyword\", \"ignore_above\": 256 } },\"analyzer\" : \"ik_max_word\", \"search_analyzer\" : \"ik_smart\" }, \"loc\": { \"type\": \"text\", \"fields\": { \"keyword\": { \"type\": \"keyword\", \"ignore_above\": 256 } } }, \"created\": { \"type\": \"date\" }, \"deptno\": { \"type\": \"long\" }, \"updated\": { \"type\": \"date\" } } }}# 重建 emp 索引库,在 body 中粘贴 `mapping{}` 内容# `ename` 字段需要在 `fields` 同级额外添加 `\"analyzer\" : \"ik_max_word\"` 配置# `ename` 字段需要在 `fields` 同级额外添加 `\"search_analyzer\" : \"ik_smart\"` 配置PUT emp{ \"mappings\": { \"properties\": { \"ename\": { \"type\": \"text\", \"fields\": { \"keyword\": { \"type\": \"keyword\", \"ignore_above\": 256 } },\"analyzer\" : \"ik_max_word\", \"search_analyzer\" : \"ik_smart\" }, \"job\": { \"type\": \"text\", \"fields\": { \"keyword\": { \"type\": \"keyword\", \"ignore_above\": 256 } } }, \"deptno\": { \"type\": \"long\" }, \"empno\": { \"type\": \"long\" }, \"mgr\": { \"type\": \"long\" }, \"comm\": { \"type\": \"float\" }, \"sal\": { \"type\": \"float\" }, \"hiredate\": { \"type\": \"date\" }, \"created\": { \"type\": \"date\" }, \"updated\": { \"type\": \"date\" } } }}- 测试分词效果:
# 测试 dept 索引中,dname字段的分词效果POST /dept/_analyze{ \"field\": \"dname\", \"text\": \"我是一个善良的中国人\"}# 测试 emp 索引中,ename字段的分词效果POST /emp/_analyze{ \"field\": \"ename\", \"text\": \"我是一个善良的中国人\"}2. 开发类型转换器
心法:ES 支持自定义转换器,在将数据写入 ES 前,或读取 ES 数据后,对数据的类型进行转换。
自定义类型转换器类要求:
- 需要实现 org.springframework.data.elasticsearch.core.mapping.PropertyValueConverter 接口。
- 需要重写
write()方法:该方法在 APP 向 ElasticSearch 写入数据前执行。 - 需要重写
read()方法:该方法在 APP 从 ElasticSearch 中读取数据后执行。
武技:自定义类型转换器类,负责将 LocalDateTime 类型转为字符串。
package com.joezhou.converter;/** @author 周航宇 */public class MyLocalDateTimeConverter implements PropertyValueConverter { /** LocalDateTime类型转换的日期模板 */ private final String PATTERN = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\"; /** * APP 向 ElasticSearch 写入数据前执行,将 LocalDateTime 类型数据转为 String 类型 * * @param value 写入的原数据 * @return 处理后的值 */ @Override public Object write(Object value) { if (value instanceof LocalDateTime localDateTime) { return localDateTime.format(DateTimeFormatter.ofPattern(PATTERN)); } throw new RuntimeException(\"数据类型有误\"); } /** * APP 从 ElasticSearch 中读取数据后执行,将 String 类型数据转为 LocalDateTime 类型 * * @param value 读取的原数据 * @return 处理后的值 */ @Override public Object read(Object value) { if (value instanceof String str) { return LocalDateTime.parse(str, DateTimeFormatter.ofPattern(PATTERN)); } throw new RuntimeException(\"数据类型有误\"); }}3. 开发Doc实体类
心法:Doc 实体类用于映射 ES 数据,相当于 ORM 映射数据库数据的 Entity 实体类。
Doc 实体类开发要求如下:
- 实体类使用 @Document(indexName = “索引库名”) 标记,一个实体类对应一条 ES 文档,索引自动创建。
- 实体类主键属性使用 @Id 标记,可以提高按主键查询时的效率。
- 实体类非主键属性使用 @Field 标记,对应 ES 字段。
- 若需要使用自定义转换器类,则可以使用 @ValueConverter(xxx.class) 标记。
@Field 常用属性如下:
type = FieldType.Text analyzer = \"ik_max_word\"searchAnalyzer = \"ik_smart\"type = FieldType.KeyWordtype = FieldType.Bytetype = FieldType.Shorttype = FieldType.Integertype = FieldType.Longtype = FieldType.Floattype = FieldType.Doubletype = FieldType.Booleantype = FieldType.Datepattern = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\"武技:开发对应 dept 和 emp 索引库的两个 Doc 实体类
package com.joezhou.doc;/** @author 周航宇 */ @AllArgsConstructor@NoArgsConstructor@Data@Document(indexName = \"dept\")public class DeptDoc { @Id private Long deptno; @Field(type = FieldType.Text, analyzer = \"ik_max_word\", searchAnalyzer = \"ik_smart\") private String dname; @Field(type = FieldType.Keyword) private String loc; @Field(type = FieldType.Date, pattern = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\") @ValueConverter(MyLocalDateTimeConverter.class) private LocalDateTime updated; @Field(type = FieldType.Date, pattern = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\") @ValueConverter(MyLocalDateTimeConverter.class) private LocalDateTime created;}package com.joezhou.doc;/** @author 周航宇 */ @AllArgsConstructor@NoArgsConstructor@Data@Document(indexName = \"emp\")public class EmpDoc { @Id private Long empno; @Field(type = FieldType.Text, analyzer = \"ik_max_word\", searchAnalyzer = \"ik_smart\") private String ename; @Field(type = FieldType.Keyword) private String job; @Field(type = FieldType.Long) private Long mgr; @Field(type = FieldType.Date, pattern = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\") @ValueConverter(MyLocalDateTimeConverter.class) private LocalDateTime hiredate; @Field(type = FieldType.Float) private Float sal; @Field(type = FieldType.Float) private Float comm; @Field(type = FieldType.Long) private Long deptno; @Field(type = FieldType.Date, pattern = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\") @ValueConverter(MyLocalDateTimeConverter.class) private LocalDateTime created; @Field(type = FieldType.Date, pattern = \"yyyy-MM-dd\'T\'HH:mm:ss.SSS\'Z\'\") @ValueConverter(MyLocalDateTimeConverter.class) private LocalDateTime updated;}E02. 常用API方法
武技:开发客户端接口
package com.joezhou.dao;/** @author 周航宇 */public interface DeptRepository extends ElasticsearchRepository<DeptDoc, Long> {}1. 客户端 - 添加API
武技:测试 ElasticSearchRepository 客户端的添加操作相关的 API 方法。
package dao;/** @author 周航宇 */@RunWith(SpringRunner.class)@SpringBootTest(classes = EsTemplateApp.class)public class DeptRepositoryTest { @Resource private DeptRepository deptRepository; @Test public void save() { LocalDateTime now = LocalDateTime.now(); DeptDoc deptDoc = new DeptDoc(1000L, \"设计部\", \"北京\", now, now); // 单条插入 DeptDoc result = deptRepository.save(deptDoc); System.out.println(result); } @Test public void saveAll() { LocalDateTime now = LocalDateTime.now(); List<DeptDoc> deptDocs = new ArrayList<>(); deptDocs.add(new DeptDoc(1001L, \"产品部NEW\", \"上海\", now, now)); deptDocs.add(new DeptDoc(1002L, \"后勤部NEW\", \"杭州\", now, now)); deptDocs.add(new DeptDoc(1003L, \"就业部NEW\", \"广州\", now, now)); deptDocs.add(new DeptDoc(1004L, \"市场部NEW\", \"辽宁\", now, now)); deptDocs.add(new DeptDoc(1005L, \"市场部OLD\", \"广西\", now, now)); deptDocs.add(new DeptDoc(1006L, \"商品部NEW\", \"深圳\", now, now)); deptDocs.add(new DeptDoc(1007L, \"研发部NEW\", \"铁岭\", now, now)); // 批量插入 Iterable<DeptDoc> results = deptRepository.saveAll(deptDocs); results.forEach(System.out::println); }}2. 客户端 - 查询API
武技:测试 ElasticSearchRepository 客户端的查询操作相关的 API 方法。
- 开发数据接口:
package com.joezhou.dao;/** @author 周航宇 */public interface DeptRepository extends ElasticsearchRepository<DeptDoc, Long> { /** * 根据部门名计数 * * @param dname 部门名 * @return 部门数量 */ int countByDname(String dname); /** * 根据部门名搜索 * * @param dname 部门名 * @return 部门列表 */ List<DeptDoc> searchByDname(String dname); /** * 根据部门名搜索,并按部门编号降序 * * @param dname 部门名 * @return 部门列表 */ List<DeptDoc> searchByDnameOrderByDeptnoDesc(String dname); /** * 根据部门名分页搜索,并按部门编号降序 * * @param dname 部门名 * @param pageable 分页条件 * @return 部门列表 */ Page<DeptDoc> searchByDnameOrderByDeptnoDesc(String dname, Pageable pageable);}- 测试数据接口:
package dao;/** @author 周航宇 */@RunWith(SpringRunner.class)@SpringBootTest(classes = EsTemplateApp.class)public class DeptRepositoryTest { @Resource private DeptRepository deptRepository; @Test public void existsById() { // 按主键查询一条文档记录是否存在,存在返回true,不存在返回false System.out.println(deptRepository.existsById(1000L)); System.out.println(deptRepository.existsById(9999L)); } @Test public void findById() { // 按主键查询一条文档记录 Optional<DeptDoc> optional$1000 = deptRepository.findById(1000L); if (optional$1000.isPresent()) { System.out.println(optional$1000.get()); } else { System.out.println(\"数据不存在\"); } // 按主键查询一条文档记录 Optional<DeptDoc> optional$9999 = deptRepository.findById(9999L); if (optional$9999.isPresent()) { System.out.println(optional$9999.get()); } else { System.out.println(\"数据不存在\"); } } @Test public void findAllById() { List<Long> ids = List.of(1000L, 1001L, 9999L); // 按主键列表查询多条文档记录 Iterable<DeptDoc> results = deptRepository.findAllById(ids); results.forEach(System.out::println); } @Test public void findAll() { // 查询全部文档记录 Iterable<DeptDoc> results = deptRepository.findAll(); results.forEach(System.out::println); } @Test public void count() { // 查询全部文档数量 long result = deptRepository.count(); System.out.println(result); } @Test public void countByDname() { // 根据部门名查询文档数量 long result = deptRepository.countByDname(\"市场部\"); System.out.println(result); } @Test public void searchByDname() { String keyword = \"NEW\"; // 查询部门名包含 \"NEW\" 的全部文档 List<DeptDoc> result = deptRepository.searchByDname(keyword); result.forEach(System.out::println); } @Test public void searchByDnameOrderByDeptnoDesc() { String keyword = \"NEW\"; // 查询部门名包含 \"NEW\" 的全部文档,并按部门编号降序 List<DeptDoc> result = deptRepository.searchByDnameOrderByDeptnoDesc(keyword); result.forEach(System.out::println); } @Test public void pageByDnameOrderByDeptnoDesc() { int page = 2; int size = 3; String keyword = \"NEW\"; // 查询第 1 页的两条数据(ES 分页的 page 是从 0 开始的) Pageable pageable = PageRequest.of(page - 1, size); Page<DeptDoc> result = deptRepository.searchByDnameOrderByDeptnoDesc(keyword, pageable); System.out.printf(\"page=%s, size=%s, pages=%s, total=%s\\n\", result.getNumber() + 1, result.getSize(), result.getTotalPages(), result.getTotalElements()); result.getContent().forEach(System.out::println); System.out.println(); }}3. 客户端 - 修改API
武技:测试 ElasticSearchRepository 客户端的修改操作相关的 API 方法。
package dao;/** @author 周航宇 */@RunWith(SpringRunner.class)@SpringBootTest(classes = EsTemplateApp.class)public class DeptRepositoryTest { @Resource private DeptRepository deptRepository; @Test public void update() { LocalDateTime now = LocalDateTime.now(); // 主键重复时的添加视为修改 System.out.println(deptRepository.save(new DeptDoc(1008L, \"OLD培训部\", \"佳木斯\", now, now))); System.out.println(deptRepository.save(new DeptDoc(1008L, \"NEW培训部\", \"哈尔滨\", now, now))); }}4. 客户端 - 删除API
武技:测试 ElasticSearchRepository 客户端的删除操作相关的 API 方法。
package dao;/** @author 周航宇 */@RunWith(SpringRunner.class)@SpringBootTest(classes = EsTemplateApp.class)public class DeptRepositoryTest { @Resource private DeptRepository deptRepository; @Test public void deleteById() { // 按主键删除一条文档 deptRepository.deleteById(1001L); } @Test public void deleteAllById() { // 按主键列表批量删除多条文档 deptRepository.deleteAllById(List.of(1002L, 1003L, 1004L)); }}Java道经第3卷 - 第6阶 - ElasticSearch(二)
传送门:JB3-6-ElasticSearch(一)
传送门:JB3-6-ElasticSearch(二)

