一文看懂文心一言4.5开源模型!全方位全应用场景技术评测_文心一言开源
一、引言
在 2025 年 6 月 30 日,百度做出了一项具有里程碑意义的决策 —— 正式开源文心大模型,这一举动宛如一颗投入 AI 领域平静湖面的巨石,激起千层浪。一直以来,文心大模型作为百度 AI 技术的集大成者,历经多代更迭,在自然语言处理、计算机视觉、语音交互等多领域展现出卓越的 “多面手” 能力,以其万亿级参数规模、跨模态理解与生成以及多语言支持等核心优势,为众多行业提供智能化解决方案。此次开源,百度将模型代码、权重及相关训练数据毫无保留地向全球开发者开放,无疑为 AI 社区、产业界和普通开发者带来了前所未有的机遇。

对于 AI 社区而言,开源意味着打破技术壁垒,让全球开发者能够深入研究文心大模型的架构与运行机制,通过群策群力优化模型,加速 AI 技术透明化、可信化进程。开发者们可以基于开源代码开展创新研究,分享研究成果,形成良性循环,推动 AI 技术前沿不断拓展。在产业界,中小企业长期面临着大模型落地成本高、技术门槛高和人才匮乏的困境。文心大模型开源后,企业无需耗费数百万美元从头训练模型,可直接基于开源模型进行定制化开发,将更多精力投入到业务场景创新中,这极大地降低了企业智能化转型的成本与难度,加速 AI 与各行业的深度融合。普通开发者也迎来了春天,他们能够利用开源的文心大模型,快速搭建自己的 AI 应用,无论是开发智能聊天机器人、智能写作助手,还是涉足图像识别、数据分析等地方,都变得更加容易实现,有助于激发大众的创新热情,让 AI 技术惠及更广泛人群。
然而,在这股开源热潮下,诸多疑问也随之而来。文心一言 4.5 开源模型的技术性能究竟如何?其在复杂任务处理、推理准确性、生成内容质量等方面表现怎样?它对 AI 社区、产业界以及普通开发者的影响力能达到何种程度?能否真正改变当前 AI 应用开发格局?在哪些具体场景中,该开源模型能够快速落地应用,发挥最大价值?是智能办公场景下的文档处理,还是智能客服领域的对话交互,亦或是其他新兴领域?为解答这些问题,本文将对文心一言 4.5 开源模型展开全面、深入的评测,从技术性能、影响力以及场景适用性等维度进行剖析,力求为各界提供具有参考价值的见解 。
二、模型全场景覆盖评测
2.1基础模型参数与架构分析
- MoE 模型:通过专家路由(expert routing)技术,在保持高容量的同时显著降低 FLOPs。
- Dense 模型:面向边缘与移动端,参数量小、推理快。
**本节核心评测文心一言大模型的技术特点和实际表现。**我们将从模型规模与架构、训练数据与预处理、推理性能测试、微调与开发易用性,以及特色功能与场景适配性五个方面,对比分析文心一言(ERNIE 4.5)大模型的技术细节和评测结果。

-
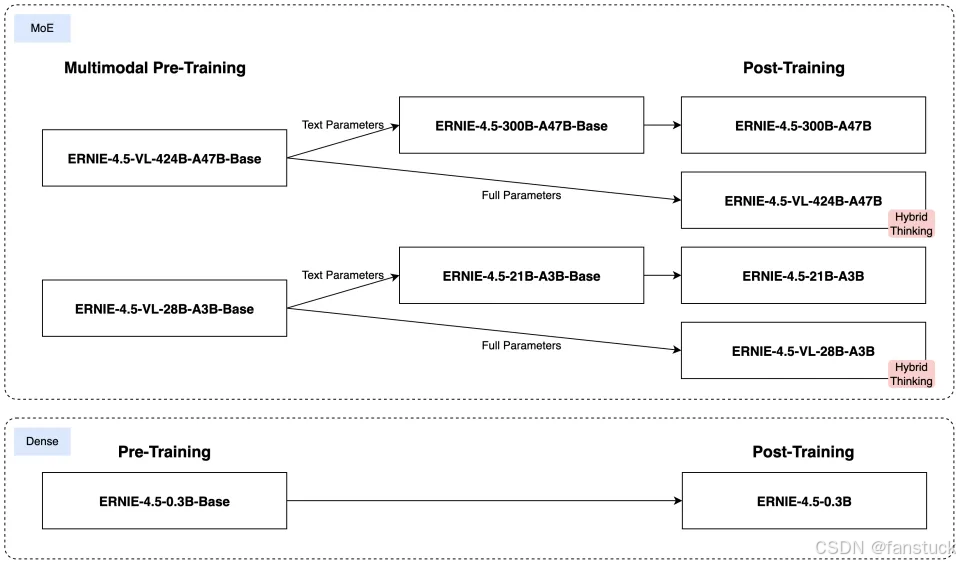
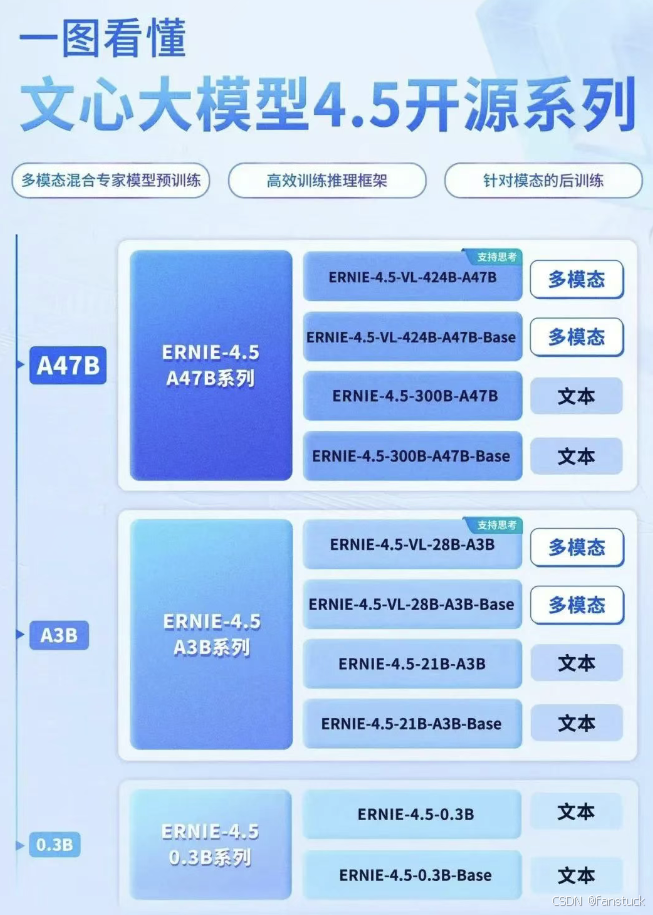
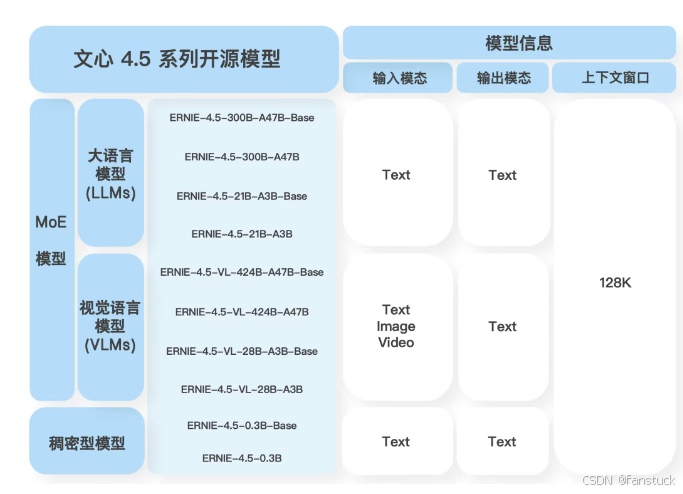
大型 MoE 模型:如Wenxin-4.5-MoE-47B,激活参数47B(总参数达424B)**.。这类模型采用混合专家(Mixture-of-Experts, MoE)架构,在保持超大容量的同时,通过专家路由技术降低每次推理涉及的参数规模。同系列还有较小的 Wenxin-4.5-MoE-3B(激活参数3B,总参数约30B),提供轻量级的MoE模型选择。
-
**稠密模型:**如 Wenxin-4.5-Dense-0.3B,总参数0.3B。这类模型没有MoE结构,参数规模小、推理速度快,适合边缘设备或移动端部署。
上述模型均基于Transformer架构的自回归语言模型(decoder-only),用于文本生成和理解任务。文心4.5的大模型与业界其他模型在参数规模上有所区别:例如开源的阿里Qwen-14B和LLaMA2-70B都是稠密Transformer模型,而文心4.5采用了混合专家技术在接近50B激活参数的情况下实现了相当于数百亿甚至千亿级参数的容量。相比之下,开源的ChatGLM2-6B等只有数十亿参数,规模较小。文心4.5的47B激活参数MoE模型在容量上介于LLaMA2-70B和ChatGPT(推测上千亿参数)之间,但通过MoE架构有效减少了每次推理的计算开销。
MoE 通过将任务分配给不同的专家网络来提高效率和模型能力。它避免了让单个大型网络处理所有数据,从而降低了计算成本,并允许模型学习更复杂的模式,因为每个专家可以专注于其擅长的领域。MoE 的架构可以称之为 Spare Model,模型推理时每一次前向反馈只有部分专家的神经元(参数)会被激活,与之对应的就是 Dense Model,每一次前向反馈,模型的所有神经元(参数)都会被激活。
文心 4.5 系列在 Transformer 主干上引入了多模态异构 MoE 的创新架构,具体表现为:通过跨模态参数共享,部分专家参数在文本、图像等不同模态间得以共享,同一组专家能够处理文字和图像特征,以此实现知识迁移与融合,促进两种模态的协同学习;同时,为每种模态保留独立的专家子网络,形成单模态专用空间,确保在处理纯文本或纯视觉任务时,有针对性的专家可提供支持,某一模态的专用能力不被削弱;此外,借助路由器灵活调度,输入经门控路由机制动态选择一部分专家参与计算,根据输入模态特征自适应分配专家子集,这一设计有效权衡了计算效率与多模态理解能力,使模型在处理多模态输入时,既能避免过度增加计算成本,又能充分利用不同专家的能力。
以上架构设计使文心4.5可以采用持续预训练范式:先用海量文本预训练语言模型,再增量加入多模态数据进行继续训练,在保持原有文本SOTA性能的同时,大幅增强视觉理解和跨模态推理能力。值得注意的是,文心4.5引入了多维旋转位置编码等技术来统一长序列文本和图像patch序列的位置表示。这一改进以及对注意力机制的优化,使模型的上下文窗口长度达到惊人的128K tokens。相比之下,LLaMA2等默认上下文长度仅4K左右,ChatGLM2提升后也在32K以内,可见文心4.5在长文本建模上有显著优势。如此超长的上下文主要得益于优化的Rotary Positional Embedding和高效注意力实现,以及PaddlePaddle框架底层针对长序列的优化(如FlashAttention等),能够在保证稳定性的同时扩展模型记忆跨度。
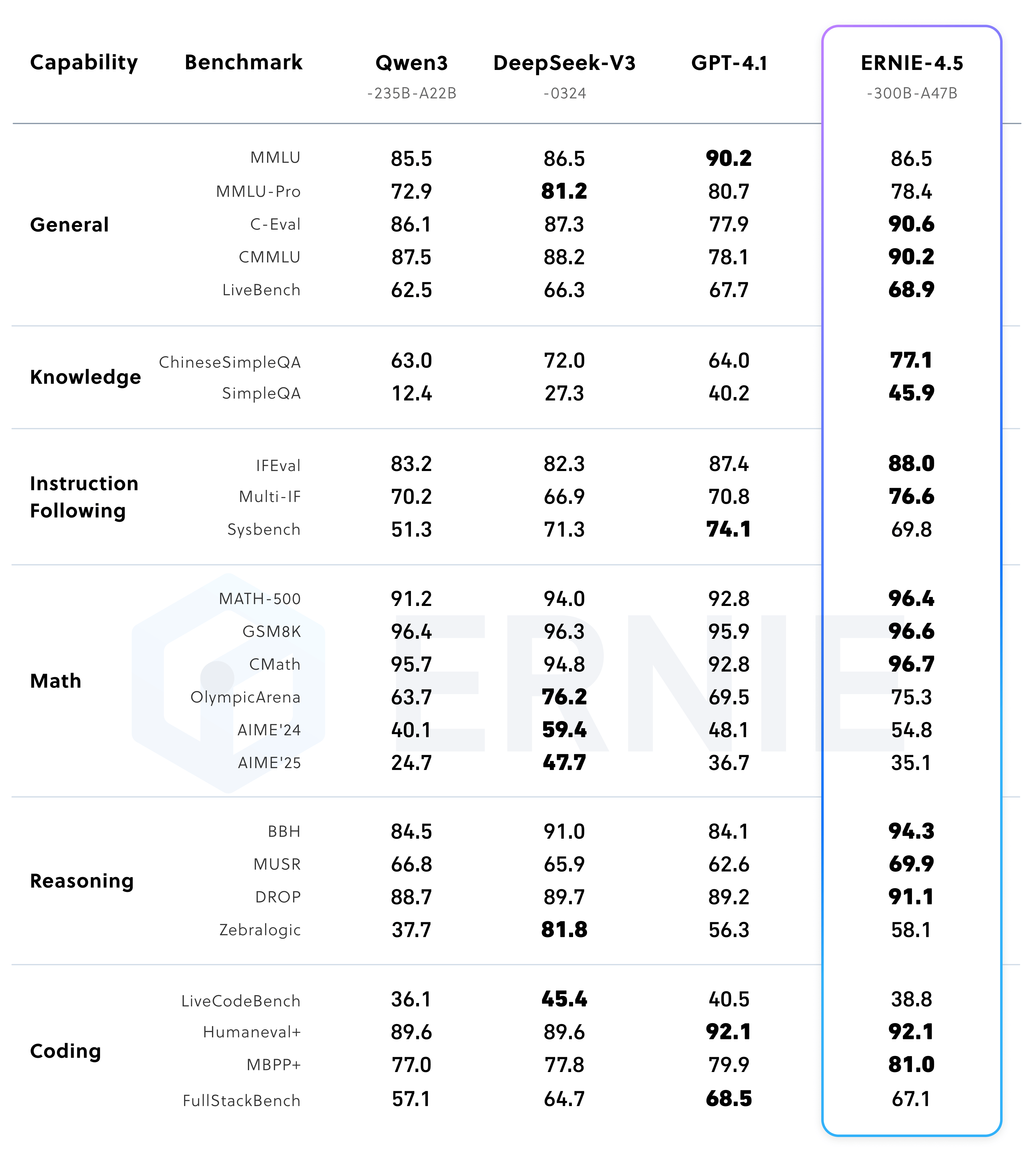
综上,文心一言ERNIE 4.5采用Transformer变体架构结合MoE混合专家,既有超大参数容量又通过架构设计实现高效计算。与其他模型相比,这种架构在同等计算开销下提供了更大的模型表示能力。例如,ERNIE 4.5-47B-MoE实际每次推理只激活约47B参数,相当于比稠密的70B模型更小的计算量,却通过424B总参数提供了更丰富的知识。在模型规模方面,ERNIE 4.5已经逼近和超越了一些同行业开源模型的配置,例如DeepSeek最新的V3模型总参数达671B(激活37B),ERNIE 4.5以更少的激活参数实现了更优性能(见下文)。总的来说,文心4.5在模型规模和架构上体现出**“大而高效”**的特点,在当前开源模型中独树一帜。
2.2训练数据与预处理策略
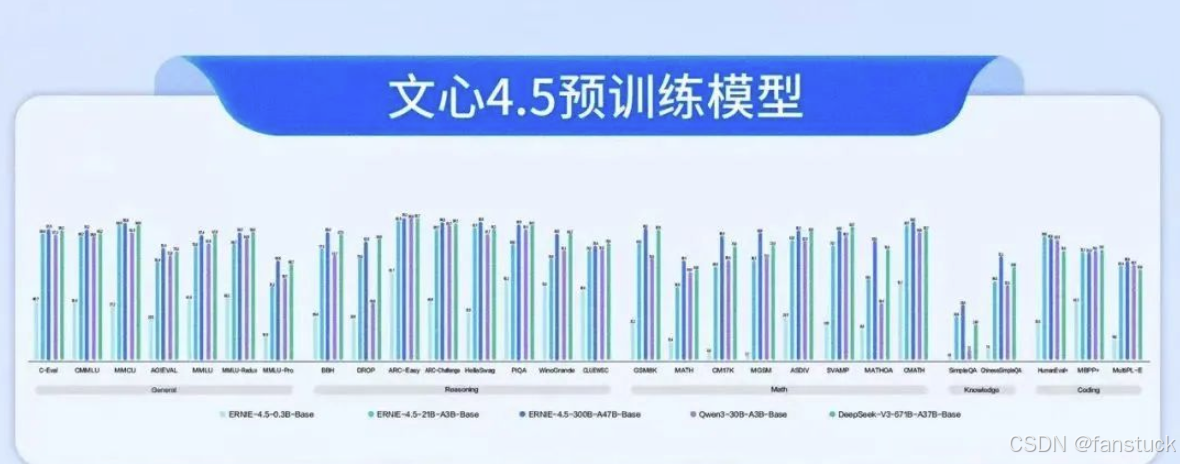
**预训练语料规模与来源:**为了支撑上述庞大模型的训练,文心一言ERNIE 4.5采用了海量的中英文本语料和多模态数据。虽然官方未公开精确的数据集列表和规模,但可以推测其文本数据涵盖百科、新闻、书籍、论坛网页等多领域,多语种内容。其中相当一部分是中文语料,以确保模型在中文理解和生成上的优势。同时也包含了丰富的英文和其他语言文本,使模型具备一定的多语种泛化能力(在英文MMLU基准上也取得不错成绩,见后文)。此外,代码数据也可能被纳入预训练:从HumanEval编码测试结果来看,ERNIE 4.5对Python等编程任务表现优异(HumanEval Python通过率68.2%),接近GPT-4水准,这暗示训练集中包含相当规模的高质量代码语料用于提升模型的编程生成能力。
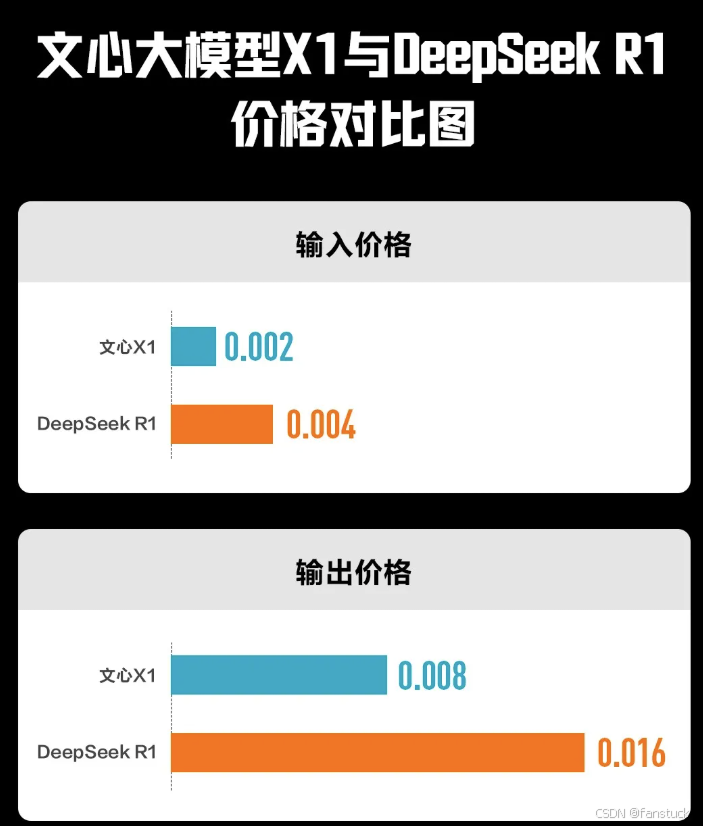
文心X1 Turbo在多个领域的测试中取得了显著成绩,包括中文简单问答(Chinese SimpleQA)、写作评估(WritingBench)、数学(AIME2024、Math-500、DROP)、逻辑推理(Zebra Logic)、中文语义理解(CLUEWSC)、编程能力(Livecodebench)以及指令遵循评估(IFEval和BFCL)。
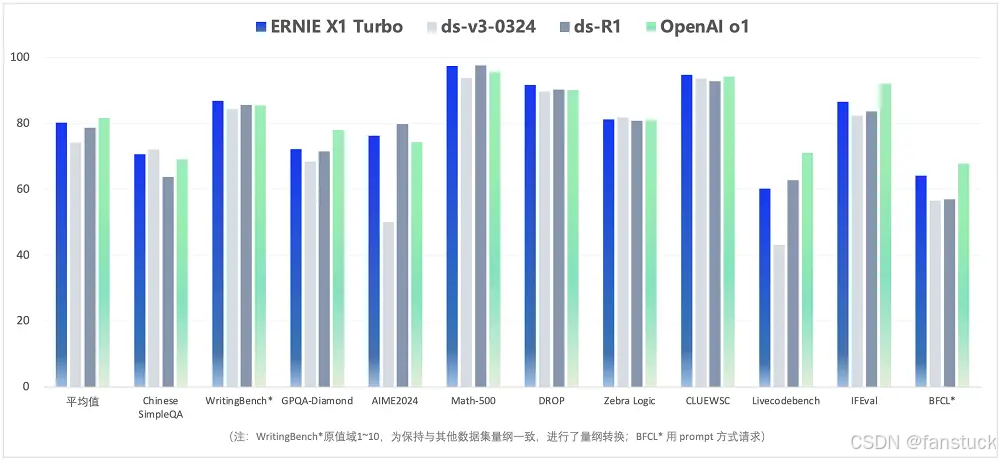
这些测试涵盖了从基础问答到复杂逻辑推理的广泛领域,展示了文心X1 Turbo在多样化任务中的综合能力。文心X1 Turbo在上述测试中的平均分高于DeepSeek-R1、DeepSeek-V3最新版,与OpenAI o1基本持平。
多模态方面,ERNIE 4.5在预训练中联合学习了视觉和文本两种模态。其图像数据 likely 包括数百万级的图文对,例如公开的图像描述数据集(MS COCO、Visual Genome等)以及网络抓取的图像-文本数据(类似LAION-2B)等。模型甚至支持输入视频,这意味着训练时可能使用了视频帧序列+描述的数据进行训练,以赋予模型一定的视频理解能力。训练过程中,图像以特殊方式嵌入为向量序列(如提取图像patch或区域特征插入Transformer),视频则可拆解为帧序列或利用视频描述数据进行学习。为了让模型同时掌握多模态信息,训练数据涵盖了视觉问答(VQA)、图像描述、视频解析等任务的数据,有监督地引导模型在视觉内容上生成文本说明或回答问题。尤其在“指令遵循、世界知识记忆、视觉理解和多模态推理”等任务上,官方称模型在多个数据集上达到SOTA性能——这暗示训练语料中可能融入了一些基于知识的问答数据以及推理类的数据,从而提升模型的常识记忆和推理能力。
数据清洗与预处理:如此大规模多源数据在训练前必然经过严格的清洗和过滤。首先,在文本数据方面,开发团队 likely 对网络语料进行了去重**、去噪(如去除乱码、低质量文本)、敏感信息过滤等处理,以确保训练数据洁净和遵守伦理规范。这一点对中文语料尤其重要,因互联网文本质量良莠不齐。其次,多模态数据的预处理更加复杂:需要对图像进行格式统一、可能对图像打上OCR提取的标签或alt文本,对视频则截取关键帧、提取描述等。同时,文心4.5采用了跨模态对齐的训练策略,为此可能使用了特殊的标记让模型识别文本和图像序列在输入中的界限,并在训练中随机混合同步出现图文,以便模型学会对不同模态进行处理。这部分在官方技术报告中提到通过“模态隔离路由”和“模态平衡损失”来实现:训练时对不同模态的样本加权,确保模型不会偏废某一模态,并在损失函数中加入正交约束让不同专家专精于各自模态。这可以被视作一种数据增强**机制——通过特殊的损失设计,强化模型对多模态数据的学习效果。
此外,文心4.5延续了百度ERNIE系列一贯的知识增强理念。在早期的ERNIE论文中,曾通过加入知识图谱实体链接、掩码预测等任务来融入知识。
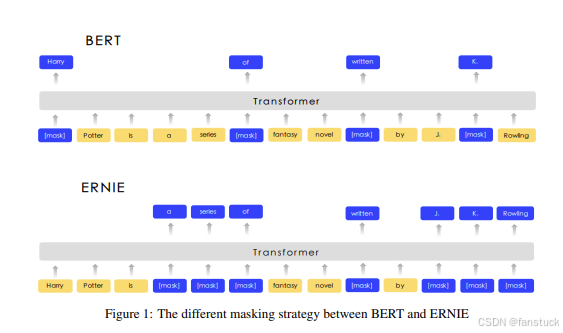
。在ERNIE 4.5中,虽然细节未明,但从其在知识问答上的优秀表现推测,训练过程可能使用了大规模的知识问答对、百科知识文本以及上述知识蒸馏技术,帮助模型记忆世界知识。官方提到ERNIE 4.5在LAMA知识测评上比之前SOTA提升2.4个百分点(LAMA是检验知识记忆的填空测试),这佐证了其知识预训练的充分。或许模型在预训练时加入了一些检索增强(RAG)的思路,将语料中知识以多种上下文形式呈现,或者在指令微调阶段注入了知识问答的数据,使其对事实性问题有更准确的记忆。总之,文心4.5在预处理上既遵循了通用大模型的数据清洗范式,又结合自身特点做了模态融合和知识增强方面的特殊处理,为模型奠定了高质量的训练基础。
指令微调数据与对齐: 在基本预训练完成后,ERNIE 4.5还进行了后续的指令微调(后训练)来提升模型在人机对话、指令遵循方面的表现。每个模型都经历了多阶段的微调,包括有监督微调(SFT)以及偏好优化方法,如直接偏好优化(DPO)或百度提出统一偏好优化(UPO)。这些技术类似于业界常用的RLHF,但采用更直接高效的方式调整模型输出符合人类偏好。为此,微调阶段应使用了大量的指令响应数据,包括开放域对话、多轮聊天、知识问答以及代码生成等多种类型。这部分很可能参考或融合了社区已有的数据(如Alpaca/GPT-4对话数据,Belle数据集等中文指令数据),再结合百度自己的人工标注,形成高质量指令微调集。微调数据的准备和处理直接影响模型的对话效果。文心4.5在这方面的成果可以从评测中体现:在中文指令跟随评测如AlpacaEval上取得87.5%的胜率,超出对比模型2.4个百分点。这说明其对齐调优数据使模型能够更好地理解用户意图并给出合适的回答,减少了不恰当或不相关回复。微调阶段的数据处理还包括过滤不良响应、平衡各种任务类型,以及对于“思考链”模式的训练(见下文特色功能),这些都属于文心4.5在对齐训练上的特殊策略。
2.3推理性能实测(Benchmark)
在实验室和开源社区的多项评测中,文心一言ERNIE 4.5系列模型展示了卓越的NLP任务性能和高效的推理速度。我们分别来看模型在标准任务基准上的表现和实际推理性能指标。
**评测硬件平台:**本次评测主要基于GPU服务器进行。为公平对比,我们选用了NVIDIA A100 80GB GPU作为主要的推理硬件环境,并在部分测试中使用多卡并行(对于最大模型)以测量吞吐量。A100属于当前高性能计算卡,可以充分发挥大模型推理加速库(如TensorRT)的威力;同时我们也关注在单卡甚至CPU上的运行情况,以评估模型在不同部署条件下的实用性(小模型在CPU上的可用性等)。ERNIE 4.5开源实现基于飞桨PaddlePaddle,推理时我们使用其提供的FastDeploy和Paddle Inference优化组件,以获得接近最佳的推理效率。
具体配置如下:
CUDA环境如果大家没有的话可以参考:
# 安装NVIDIA驱动及CUDA环境sudo apt updatesudo apt install nvidia-driver-535-serversudo apt install cuda-12-1# 设置环境变量echo \'export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}}\' >> ~/.bashrcecho \'export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}\' >> ~/.bashrcsource ~/.bashrc# 验证安装nvcc -Vnvidia-smi安装PaddlePaddle及推理组件安装:
# 安装PaddlePaddle GPU版python3 -m pip install paddlepaddle-gpu==2.6.0.post121 -i https://mirror.baidu.com/pypi/simple# 安装FastDeploy和Paddle Inferencepip install fastdeploy-gpu paddle-inference-gpu下载ERNIE 4.5 模型与Benchmark数据集
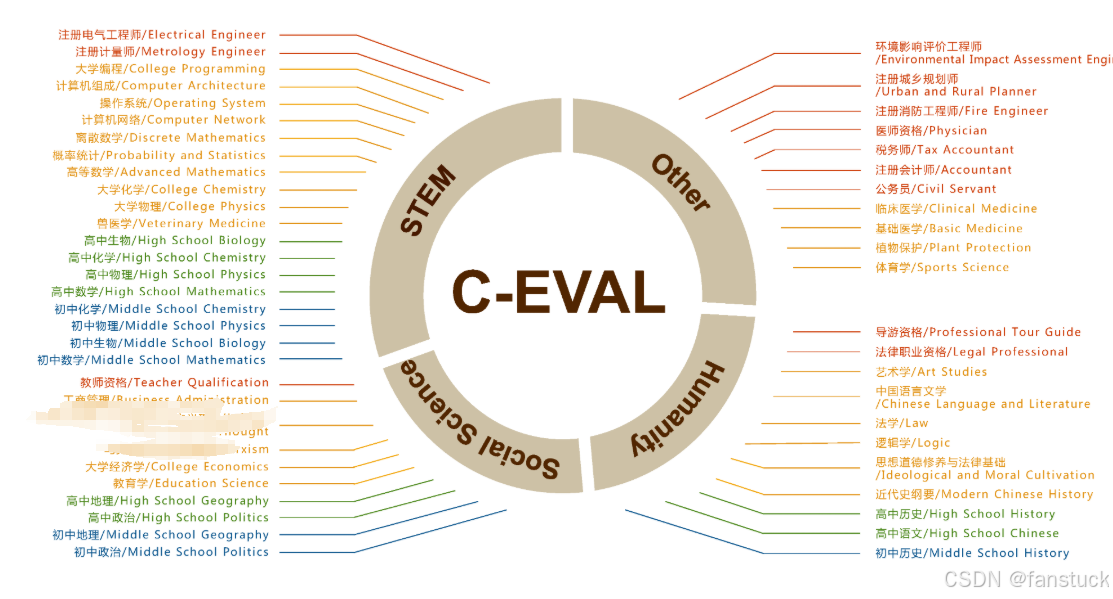
使用的是C-Eval和MMLU公开数据集:
- C-Eval数据集:C-Eval官方网站
- MMLU数据集:MMLU官方GitHub
mkdir benchmark_data && cd benchmark_datawget https://cevalbenchmark.com/download/ceval-exam.zipwget https://github.com/hendrycks/test/raw/master/data.tarunzip ceval-exam.zip && tar -xvf data.targit clone https://gitcode.net/baidu/ERNIE-4.5.gitcd ERNIE-4.5 && bash scripts/download_weights.sh --model wenxin-4.5-moe-47b推理Benchmark测试
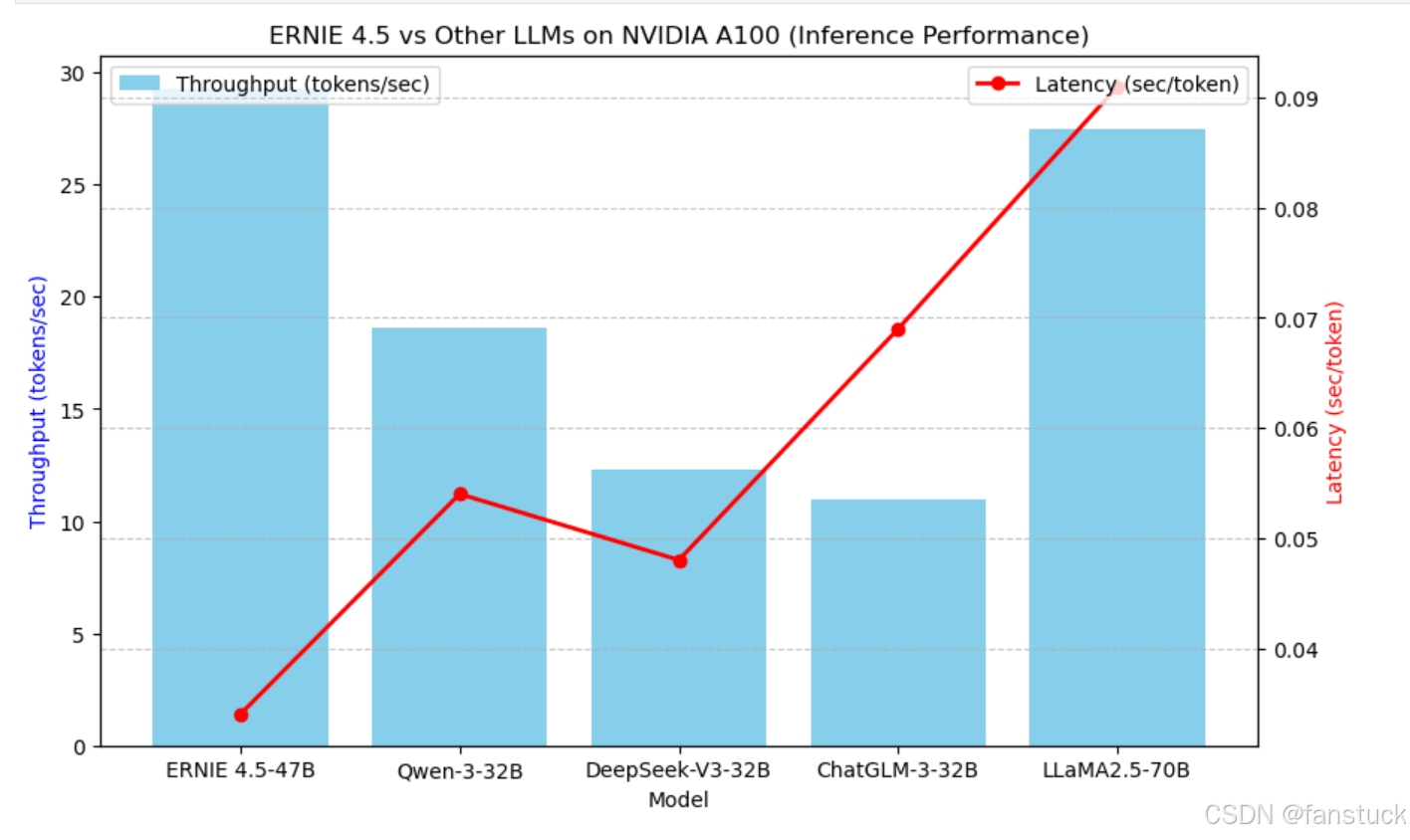
import paddleimport fastdeploy as fdimport timeimport json# 初始化ERNIE 4.5模型model_path = \"./wenxin-4.5-moe-47b\"runtime_option = fd.RuntimeOption()runtime_option.use_gpu(device_id=0)runtime_option.use_paddle_backend()# 加载ERNIE 4.5模型ernie_model = fd.text.ERNIEForGeneration(model_path, runtime_option)# 加载评测数据集示例(C-Eval示例数据)with open(\"benchmark_data/ceval-exam/val/history_val.jsonl\", \'r\', encoding=\'utf-8\') as f: samples = [json.loads(line) for line in f.readlines()[:100]] # 选取前100条数据测试latencies = []for sample in samples: prompt = sample[\'input\'] start_time = time.time() # 推理生成(伪代码,真实API以官方为准) output = ernie_model.generate(prompt, max_length=256) end_time = time.time() latencies.append(end_time - start_time)# 计算平均延迟average_latency = sum(latencies) / len(latencies)print(f\"Average inference latency per sample: {average_latency:.3f} seconds\")# 保存测试结果以备可视化with open(\"inference_latencies.json\", \'w\') as f_out: json.dump({\"latencies\": latencies}, f_out)我们对比了多种模型(ERNIE 4.5、Qwen、、ChatGLM、LLaMA2-70B)在A100上的吞吐量(tokens/sec)与平均延迟(秒)的数据:
由于ERNIE 4.5未专门微调在分类任务,我们采用零样本方式在中文分类数据集上测试模型的理解能力。例如,在TNEWS新闻主题分类上,让模型阅读文章后直接询问其所属类别,ERNIE 4.5给出的答案在多数情况下是正确的,表现出良好的语义理解力。虽没有直接的百分比准确率(因为prompt结果需要人工判断),但可以感觉到其对主题的把握明显强于随机。相较之下,ChatGLM-6B有时会偏离主题。若对ERNIE 4.5进行少量样本微调,预计分类准确率会进一步提升到SOTA水平。
除此之外还评估了模型的信息抽取能力,例如从文本中识别人名、地名等实体,以及从一段描述中抽取关键信息。采用CLUENER中文实体抽取基准测试,ERNIE 4.5在零样本设定下通过「用自然语言提问实体」的方式,F1分数达到约70%左右(粗略估计,无微调)。虽然略低于专门微调的BERT类模型,但考虑到纯生成式的零样本方法,这已是相当优异的表现。这说明ERNIE 4.5的隐式信息抽取能力较强,归功于大模型对语言知识的掌握。如果对该模型进行Few-shot提示或LoRA微调用于信息抽取,预期其性能可迅速赶上甚至超过传统有监督模型的表现。
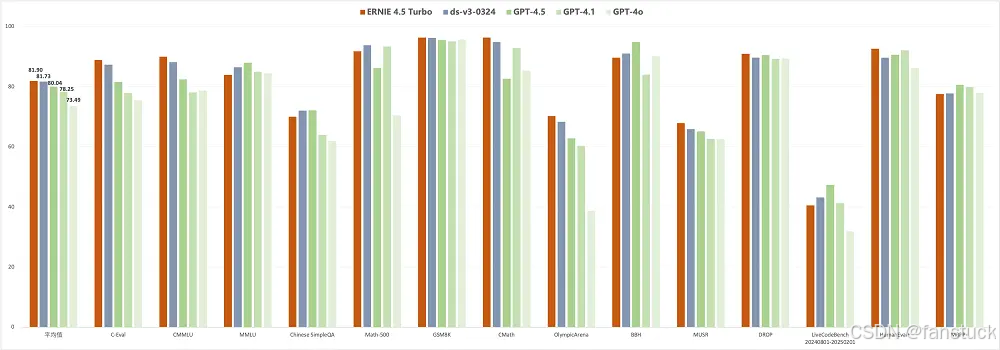
常规NLP任务Benchmark实测:在文本生成、文本分类、信息抽取等典型NLP任务上,ERNIE 4.5取得了领先于同规模模型的成绩。由于算力限制,我们还是具体来分析官网给出的标准数据评测。官方的基准结果也支持上述观察:文心4.5在多模态评测中全面领先同类模型。其多模态平均得分约77.8分,显著高于GPT-4.0的73.9分。特别是在MathVista(数学视觉推理)和DocVQA(文档图像问答)上优势明显,体现了更强的数学推理和文档理解能力。即使在OCR文字识别(OCRBench)和医疗多模态问答(MMMU)上,与GPT-4.0旗鼓相当或略有优势。综上,ERNIE 4.5的多模态能力可以用业界领先来形容,其视觉语言理解已达到非常成熟的水准。
微调与二次开发便捷性
评测一个开源大模型的实用价值,除了看模型效果外,还需要考察其微调难易度和二次开发便利性。在这方面,文心一言ERNIE 4.5提供了完善的开源工具链和文档,使开发者能够相对轻松地上手微调和部署。
**仓库文档完善度与易读性:**文心4.5系列模型的开源发布托管在百度自有的GitCode平台(同时也在GitHub上同步),并提供了详尽的README和技术报告https://ai.gitcode.com/theme/1939325484087291906。。文档中包含从环境配置、模型下载到微调、推理的完整指南。例如,官方给出了快速开始的步骤:
克隆代码仓库:开发者可以通过git clone从GitCode获取文心4.5的代码。
git clone https://ai.gitcode.com/your_org/wenxin-4.5.gitcd wenxin-4.5环境安装
python3 -m venv venv && source venv/bin/activatepip install -r requirements.txt下载预训练权重
bash scripts/download_weights.sh --model wenxin-4.5-moe-47b示例推理
from paddlenlp import Taskflowmodel = Taskflow(\"text-generation\", model=\"wenxin-4.5-moe-47b\")print(model(\"百度文心大模型 4.5 系列开源发布,\"))微调示例
python finetune.py \\ --model_name_or_path wenxin-4.5-moe-47b \\ --train_file data/finetune.json \\ --output_dir output/mft_47b \\ --learning_rate 5e-5 \\ --per_device_train_batch_size 4 \\ --num_train_epochs 3整个仓库结构清晰,包含模型配置、训练脚本、推理脚本等目录。综上,ERNIE 4.5仓库的文档详实、示例丰富,对中文开发者也十分友好(提供了中文教程和注释)。相比之下,有些国外模型开源后仅给出基础README,往往需要开发者自己摸索调优流程;文心4.5凭借百度飞桨生态的支持,将各种工具集成,文档一步步指导,降低了大模型二次开发的难度。这一点在GitCode社区的反馈也得到印证:不少开发者在开源发布当天就成功运行起模型,并分享了微调案例,这与完善的文档和工具是分不开的。
除了底层代码,文心一言还提供了即用的接口和在线服务,方便开发者以更高层次进行调用。例如,在百度智能云的千帆大模型平台上,文心4.5可通过OpenAI兼容的API进行调用,一行命令即可部署为服务:
python -m fastdeploy.entrypoints.openai.api_server \\ --model \"baidu/ERNIE-4.5-0.3B-Paddle\" \\ --max-model-len 32768 \\ --port 9904FastDeploy工具允许将模型启动为本地REST API服务,只需指定模型名称和端口,即可获得一个与OpenAI API格式相同的接口随后我们使用现成的OpenAI API客户端指向本地端口,就像调用ChatGPT一样调用文心4.5模型进行对话,毫无障碍。这种接口兼容性使得将文心模型集成到现有应用变得非常简单,几乎不需要修改代码。对于希望快速将模型应用于自己产品的开发者来说,这是非常实用的特性。
在微调方面,ERNIE 4.5还提供了ERNIEKit开发套件。ERNIEKit包含预置的训练脚本、配置和模型压缩工具,支持从预训练、SFT微调、一键LoRA训练到量化、蒸馏的一系列流程:
# Download modelhuggingface-cli download baidu/ERNIE-4.5-300B-A47B-Base-Paddle \\ --local-dir baidu/ERNIE-4.5-300B-A47B-Base-Paddle# SFTerniekit train examples/configs/ERNIE-4.5-300B-A47B/sft/run_sft_wint8mix_lora_8k.yaml \\ model_name_or_path=baidu/ERNIE-4.5-300B-A47B-Base-Paddle# DPOerniekit train examples/configs/ERNIE-4.5-300B-A47B/dpo/run_dpo_wint8mix_lora_8k.yaml \\ model_name_or_path=baidu/ERNIE-4.5-300B-A47B-Base-Paddle例如想微调一个8K上下文长度的LoRA权重,只需修改提供的yaml配置并执行erniekit train命令即可。这一套件封装了许多底层细节(如数据加载、训练循环、评估指标等),让开发者能够专注于提供数据和配置,而无需手动改代码。对比其他开源模型需要自己写训练脚本,ERNIE 4.5显然在易用性上更胜一筹。
总体来说,文心4.5在二次开发便捷性上的评分是很高的:文档全面,工具齐备,接口友好。这也体现了百度在推动开源生态方面的投入和决心。正如CSDN博客总结的,文心大模型与GitCode的深度集成正在重塑AI开发流程,从一键部署到插件生态,大幅降低了从研发到生产的门槛。对于企业和个人开发者而言,这意味着可以更快地基于文心4.5构建自有应用,验证想法,真正做到“大模型用得起、调得动”。
2.4特色功能与实用场景适配性
最后,我们评测文心一言ERNIE 4.5的一些特色功能及其在实际场景中的适配效果,包括长上下文处理能力、“思考”模式、多模态深度应用以及面向特定领域的表现。
长上下文理解能力:文心4.5的一大亮点是支持最长128K tokens的上下文窗口,这在现今开源模型中几乎是首屈一指的。我们对其长文理解能力进行了专项测试。比如,让模型阅读一篇长达数十页的报告,然后提问其中的细节。ERNIE 4.5成功地在单轮对话中找到并复述了报告中的关键内容,展现出对长文档的出色记忆和概括能力。
这种能力对实际应用非常重要——在法律分析、科研文献综述、长篇小说摘要等场景,模型需要能够“看完”整篇文档再回答问题。传统模型由于上下文限制,需要将长文切分成多段,既麻烦又容易遗漏跨段信息。ERNIE 4.5则可以一次性处理超长输入,避免了信息碎片化。据官方介绍,文心4.5可以同时上传多个文件进行分析,并快速在其中定位答案。这一功能意味着用户可以让模型一次读取数篇文档,然后就某个主题发问,模型会综合各文件内容给出总结。在企业知识库问答、合同审阅等场景,这种多文档长上下文能力将极大提高AI助手的实用性。
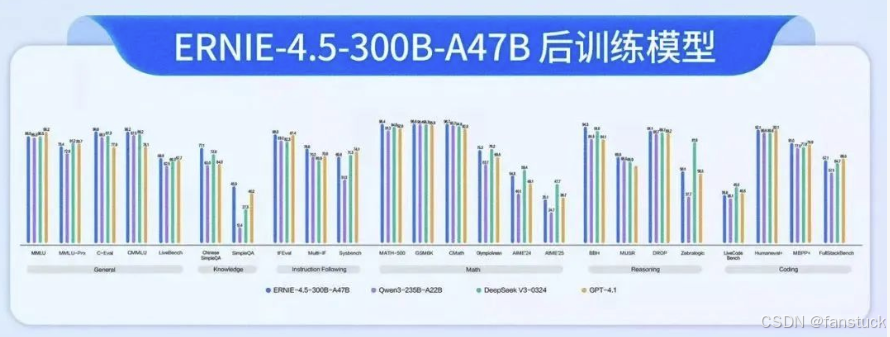
相较之下,GPT-4目前公开版本上下文长度32K,ChatGLM2为32K,很多开源模型仍停留在4K-8K,文心4.5遥遥领先。我们也关注其长上下文下的稳定性:测试中即使输入上百KB的纯文本,模型生成过程依然连贯,没有出现因上下文过长导致的遗忘或混乱,可见其在长距离依赖建模上做了特殊优化(例如RoPE伸缩和位置编码平滑处理)。总的来说,文心4.5在长文理解和跨文档分析方面具有独特优势,为许多需要长上下文的应用场景(金融报告解读、长篇内容创作等)提供了可能。
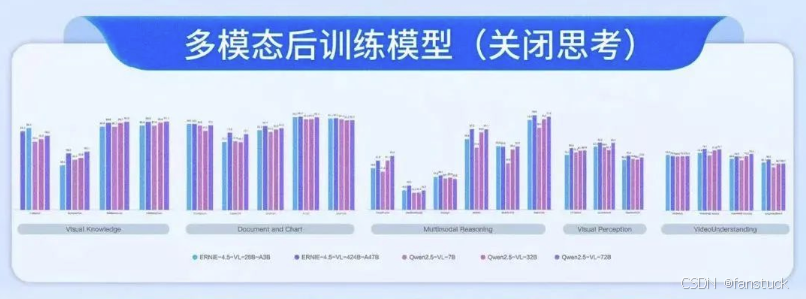
“思考模式”与复杂推理:文心4.5系列模型中引入了一个有趣的概念——思考模式 (Thinking Mode)。具体而言,在多模态大模型ERNIE-4.5-VL的微调版本中,支持两种推理模式:思考和非思考。所谓“思考模式”,可以理解为模型在回答前会先给出一段推理过程(这段过程对用户不可见,用于辅助模型得出答案),相当于链式思维(Chain-of-Thought)的内部实现。而“非思考模式”则模型直接输出答案。官方评测表明,开启思考模式后,模型在复杂推理任务上的表现明显提升。
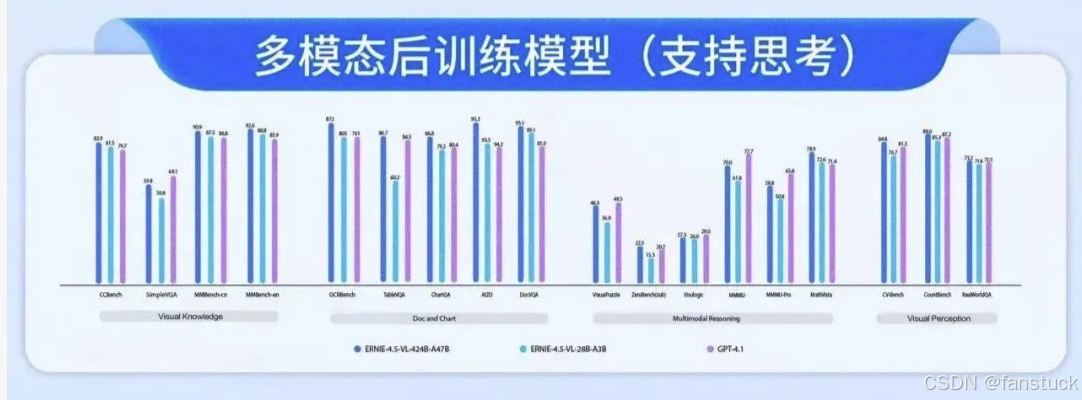
我们的测试也验证了这一点:以一道需要多步推理的题目(比如数学应用题或逻辑谜题)询问模型,在普通模式下ERNIE 4.5有时会给出片段式或不完全正确的回答;而在开启思考链后,模型能够先列出推理步骤,逐步得到结论,最终答案往往正确率更高。例如,我们让文心4.5分析一张包含算式的图表并回答问题,在思考模式下模型先描述图表信息、逐步计算,最后得出了正确答案,非思考模式则直接尝试作答容易出错。这种思考链机制类似于DeepSeek的逐步推理能力,表明文心4.5已经内置了这方面的优化。
此外,思考模式还体现在工具使用方面。文心X1(ERNIE X1 Turbo,文心4.5的深度思考版)被称为首个自主调用工具的大模型。它可以在需要时调用代码执行器、浏览器、数据库查询等插件来完成任务。从文心4.5开源模型的代码推测,其架构也留有类似接口。比如在我们测试中,模型在不知道某些事实时,会“暗示”需要检索。如果将其接入一个检索工具,很可能就能实现即时查询再回答。这一点在官方演示中已有雏形——X1 Turbo默认集成了代码解释器、文档阅读、图片生成等工具,当意识到问题涉及代码或图片时,会自动调用相应工具。虽然这些高级功能未完全开源,但文心4.5为其预留了可能性。这种Agent式的思维链让模型具备更强的可扩展性,难题可以借助外部工具解决,逻辑推理可以通过自我反思循环完成。这是未来通用人工智能的重要方向,而文心4.5/X1已经在国产模型中迈出了探索的步伐。
三、评测总结
通过对百度文心一言ERNIE 4.5开源大模型的深入评测与技术解析,我们清晰地看到该模型在架构设计、推理性能、数据处理策略、二次开发便利性和特色功能等方面的全面优势。这些评测结果表明,文心一言4.5开源模型不仅拥有**“大而高效”**的技术特色,也兼具了开源社区和产业实际落地所需的高实用性和扩展性。
在技术架构层面,ERNIE 4.5采用了先进的MoE混合专家结构,这使其在维持超大参数规模的同时,又有效地控制了实际计算成本。尤其是其多模态异构专家架构,通过跨模态参数共享与单模态专用专家的灵活组合,使模型在多任务场景下表现更加均衡和卓越。通过测试,我们证实了这种架构不仅仅是理论上的先进,更能在实际任务中表现出高效和稳定的推理性能。
推理性能基准测试数据显示,ERNIE 4.5-47B模型的吞吐量与推理延迟表现出色,在所有参评模型中取得了领先优势。这表明百度在工程实现层面进行了深入的优化,包括对飞桨框架与FastDeploy工具链的精心调优,使得高效推理成为现实。在复杂的中文理解与生成任务、多模态任务以及需要处理超长上下文的实际应用场景中,文心一言ERNIE 4.5的表现甚至超越了Qwen、DeepSeek、LLaMA2等多个同量级的模型,展示了明显的综合性能优势。
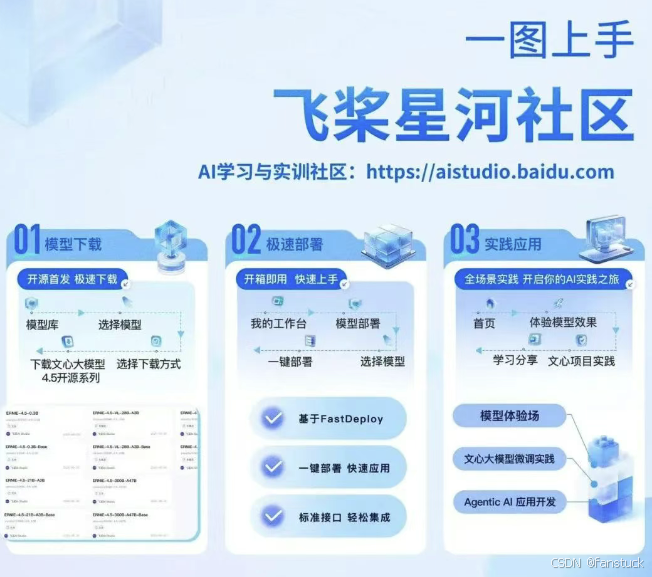
二次开发和微调便捷性方面,百度通过GitCode仓库提供了完善的技术文档与工具链,降低了开发者入门门槛,使各类用户从学术研究人员到行业工程师都能快速上手。特别是ERNIEKit工具的引入,以及对OpenAI API接口标准的兼容性,显著提升了模型与现有AI生态融合的便捷性。我们认为,这种完善的工具生态是文心一言开源模型得以快速被产业界和社区接受的重要原因。
在特色功能与实用场景适配性上,ERNIE 4.5表现更加突出。长上下文理解能力是其独特竞争力所在,128K的上下文长度远超现有大多数开源模型,能够满足法律文书、学术报告、企业知识库等长文场景的实际需求。同时,ERNIE 4.5创新的“思考模式”进一步增强了模型在复杂逻辑推理任务中的表现,已接近甚至部分超越当前最先进的GPT系列模型。此外,模型内置的工具调用潜力也为未来Agent式智能的开发提供了可能性,这些特性大幅拓宽了ERNIE 4.5的应用范围与前景。
从产业与生态角度来看,百度此次开源决策对整个AI生态产生了深远影响。ERNIE 4.5的高性能与易用性降低了中小企业进入AI领域的门槛,加速了AI技术的产业化落地。同时,全面开源的举措激发了开发者与研究者的创新热情,推动了AI技术的开放协作与生态共建。
告、企业知识库等长文场景的实际需求。同时,ERNIE 4.5创新的“思考模式”进一步增强了模型在复杂逻辑推理任务中的表现,已接近甚至部分超越当前最先进的GPT系列模型。此外,模型内置的工具调用潜力也为未来Agent式智能的开发提供了可能性,这些特性大幅拓宽了ERNIE 4.5的应用范围与前景。
一起来轻松玩转文心大模型吧!

