数据结构的快速排序(c语言版)_c语言对结构体进行快速排序
一.快速排序的概念
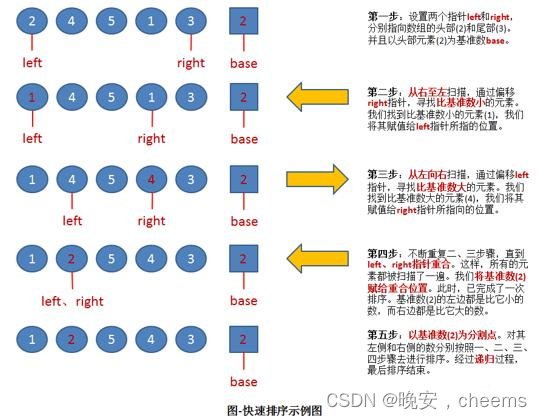
1.快排的基本概念
快速排序是一种常用的排序算法,它是基于分治策略的一种高效排序算法。它的基本思想如下:
- 从数列中挑出一个元素作为基准(pivot)。
- 将所有小于基准值的元素放在基准前面,所有大于基准值的元素放在基准后面。这个过程称为分区(partition)操作。
- 递归地应用上述步骤到左右两个子数列上,直到各个子数列只有一个元素为止。
这样通过不断的分割和排序,就可以实现整个数列的排序。快速排序的时间复杂度平均情况下为O(nlogn),虽然在最坏情况下会退化为O(n^2),但在实际应用中往往是一种高效的排序算法。
2.快排的适用场景
-
大规模数据排序:快速排序的平均时间复杂度为O(nlogn),在处理大规模数据时比其他算法如冒泡排序、插入排序更加高效。
-
内存受限的环境:快速排序是一种就地排序算法,不需要额外的存储空间,这在内存受限的环境(如嵌入式系统)中更有优势。
-
数据较为随机分布:快速排序的性能最佳情况发生在数据较为随机分布的情况下。如果数据已经基本有序或完全逆序,则会退化为O(n^2)的时间复杂度。
-
需要频繁排序的场景:由于快速排序的实现相对简单,且不需要额外空间,因此在需要频繁进行排序的场景中更有优势,如动态维护一个有序集合。
-
并行计算环境:快速排序可以很好地并行化,利用多核处理器可以大幅提高排序效率,


