「源力觉醒 创作者计划」文心大模型4.5重塑AI生态与技术普惠【文心4.5开源性能全揭秘】
「源力觉醒 创作者计划」文心大模型4.5重塑AI生态与技术普惠【文心4.5开源性能全揭秘】
背景
近年来,人工智能大模型的蓬勃发展不断刷新着技术边界。从GPT系列、Claude,到LLaMA与Mistral,全球AI巨头纷纷投入大模型竞赛,尤其是以开源生态为核心的“技术普惠”理念,逐渐成为推动AI发展和应用落地的关键引擎。
在这个以西方技术为主导的AI版图中,国产大模型的发展曾一度面临“闭源困境”、生态孤岛与算力壁垒等多重挑战。多数国产模型仍依赖于闭环的部署方式、受限的接口访问或许可限制,难以真正进入全球开发者的主流工具链。百度文心大模型4.5的重磅开源,正是在这一背景下作出的战略突破。不仅涵盖不同参数规模的全栈模型,更首次开放高达424B的混合专家模型,打破了大参数模型“只展示不开放”的行业惯例,全面对标LLaMA 3、GPT-4等国际一线模型。
文心4.5的开源不再是“实验室代码”,而是具备商业级性能、工程级稳定性、生态级开放性的全套解决方案。这意味着,从轻量边缘设备到企业级知识中台,从教育、医疗、金融到工业制造,各类开发者与机构均可无门槛使用这一模型,推动AI从实验室走向全行业。

这一举措不仅标志着中国AI技术迈入开放新时代,也为构建全球多元AI生态注入强劲动力。文心4.5的发布,是一次面向全球开发者、企业和研究者的信号:中国AI,已经准备好共同参与并塑造未来的AI格局。
文心大模型4.5
2025年6月30日,百度正式开源文心大模型4.5系列,一次性释放10款不同规格的模型,覆盖0.3B轻量化模型到424B超大规模混合专家模型(MoE),全部采用Apache 2.0开源协议,允许商业自由使用。这一举措不仅标志着国产AI技术从“闭门造车”迈向“开放共建”的里程碑,更引爆了全球开发者的创新热潮。
https://ai.gitcode.com/theme/1939325484087291906
开源即战力,百度文心4.5开源首发,GitCode下载体验!
一、技术架构革新:效率与性能的双重突破
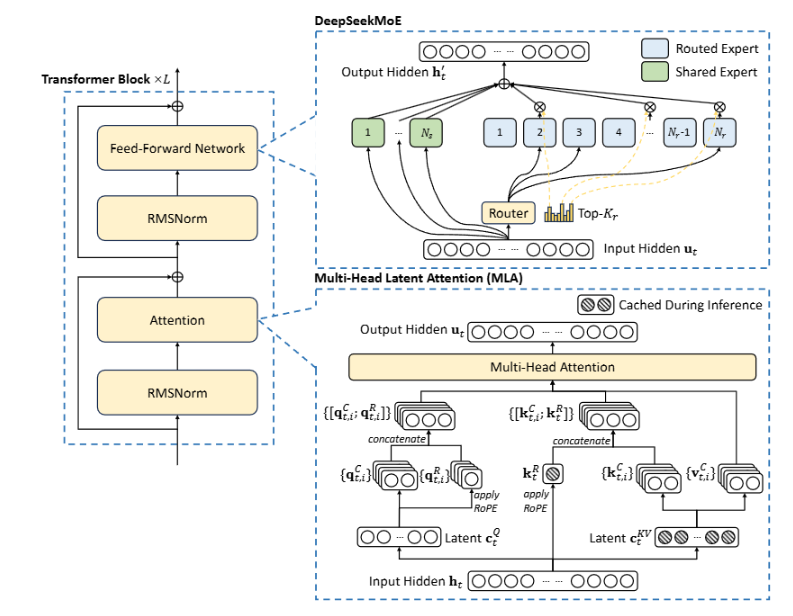
文心大模型4.5系列在技术架构上进行了全面升级,其核心亮点是自主研发的异构多模态混合专家架构(Heterogeneous Multi-Modal Mixture of Experts, H-MoE)。这一架构不仅提升了大模型的推理效率与训练性能,还显著优化了多模态任务处理能力,是推动“低成本+高性能”大模型落地应用的关键支撑。
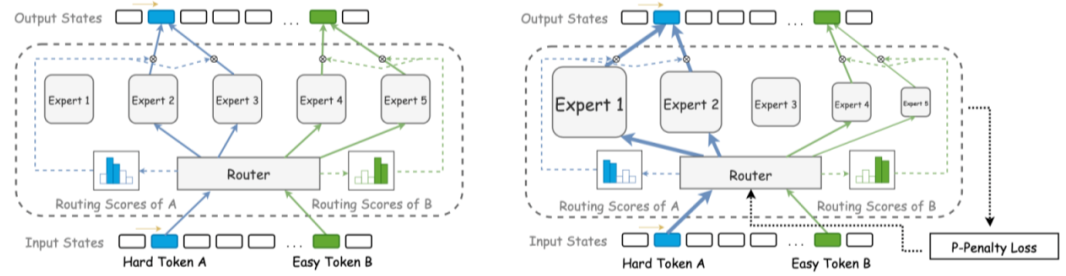
1. 动态路由机制:按需激活,显著降低算力消耗
传统的大模型在处理任何输入时,往往会激活全部参数和计算模块,造成大量冗余计算,尤其在处理纯文本等相对简单任务时效率低下。文心4.5引入了先进的动态路由机制(Dynamic Routing for Sparse Experts),通过训练阶段构建的智能路由器判断输入内容的特征,仅激活与任务强相关的少数专家模块。
- 在实际测试中,文本任务平均只需激活 10%-15% 的专家网络;
- 推理阶段的计算成本由原始模型的全参数推理下降至仅为 1/81,在保证准确率的同时极大节省了硬件资源;
- 有效支持低功耗部署场景,如边缘计算设备和移动终端。
这一机制兼顾了模型能力和成本控制,使超大模型的普及应用成为可能。
2. 模态隔离设计:解决多模态干扰,实现协同增益
在多模态大模型的发展过程中,“模态干扰”始终是制约性能提升的关键难题。为解决这一问题,文心4.5提出了一套系统性的模态隔离机制,从结构设计到训练策略进行全方位优化。其中,模态独立专家池有效增强了每种模态的表征能力,避免了模态间的低层级干扰;路由正交损失进一步在训练阶段保持模态特征路径的分离性,增强表达的独立性与鲁棒性;而在融合阶段引入的协同门控机制,则确保了不同模态信息在高层语义上的协同融合与稳定输出。这一系列创新举措不仅显著提升了图文联合训练效率(提升超40%),也为多模态大模型在生成和理解任务中的性能突破奠定了坚实的基础。
3. 超高效推理优化:更快、更小、更精准
为了进一步降低大模型的使用门槛,文心4.5系列在推理阶段集成了一整套算子级优化策略,支持:
- FP8混合精度训练(Mixed Precision with FP8):利用更低比特宽度的浮点数实现精度近似不损失的训练与推理,加快训练速度的同时降低内存使用;
- 4-bit无损量化(Lossless 4-bit Quantization):在不牺牲模型性能的前提下,将模型压缩至更小的体积,适配国产算力芯片和部署平台;
- 模型编译器优化与并行推理加速:通过定制编译器和异构调度策略,进一步提升模型吞吐率。
实测结果表明,ERNIE-4.5-0.3B在A800服务器上单线程推理速率可达 291.4 tokens/秒,在轻量级模型中表现优异,可用于高频响应的对话系统和在线API服务。
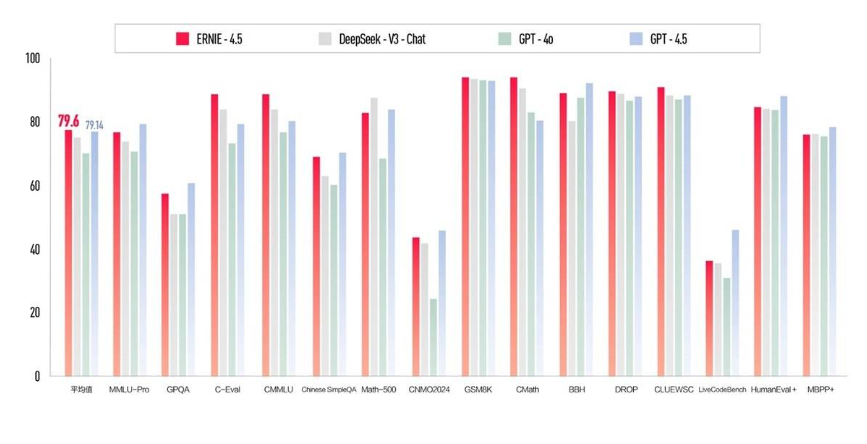
4. 性能测试亮眼:“大模型更强,小模型更优”
在多项权威评估中,文心4.5展现出强劲性能:
- 文心4.5-300B 在28项中文基准测试中,有 22项指标超越DeepSeek-V3,特别在常识问答、代码生成和多轮对话等任务中表现出色;
- 文心4.5-21B 轻量模型在多个综合测试集上优于Qwen3-30B等更大参数模型,验证了其“小模型大能力”的设计理念;
- 在MMBench、CMMLU、AGIEval、C-Eval等主流评测中,表现跻身中文模型第一梯队,甚至在部分任务上领先于部分国际开源模型。
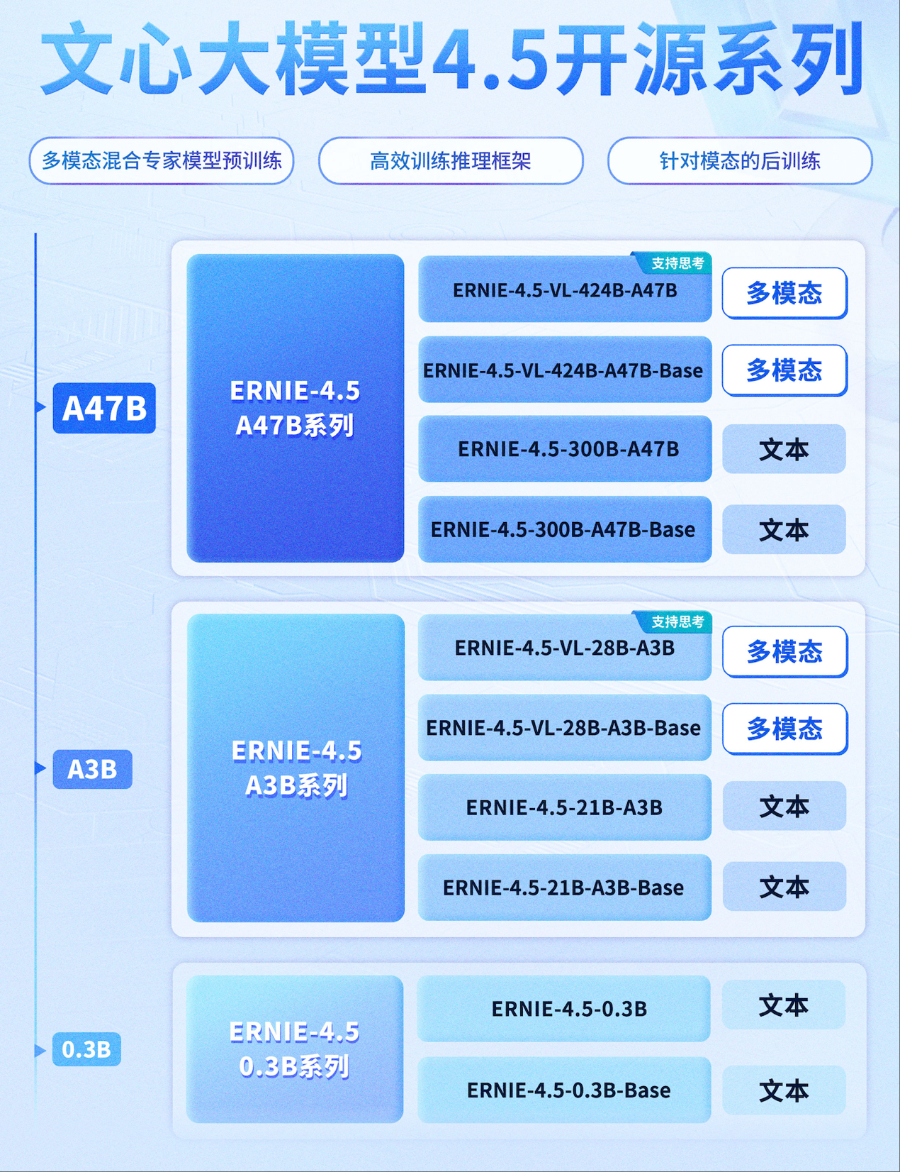
二.手把手复现ERNIE-4.5-0.3B-Paddle模型
为了验证百度文心大模型4.5的部署可行性与推理性能,本节将以ERNIE-4.5-0.3B-Paddle为示例,介绍如何在单张 NVIDIA GeForce RTX 4090 显卡上快速复现部署流程,并实测运行效果。
硬件与工具准备
本次实验环境:
- GPU:NVIDIA GeForce RTX 4090(单卡)
- 系统平台:Linux / Windows均可
- 部署工具:百度 FastDeploy + aistudio-sdk
目标是部署轻量化的 ERNIE-4.5-0.3B-Paddle 模型,并实现交互式聊天能力。

Step 1:安装FastDeploy(GPU版)
使用如下命令安装FastDeploy(需支持CUDA 11.8+):
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-86_89/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simpleStep 2:安装Aistudio SDK(用于模型下载)
pip install --upgrade aistudio-sdkStep 3:模型下载与部署(完整脚本)
以下Python脚本可实现模型的快速下载、加载与交互推理:
from aistudio_sdk.snapshot_download import snapshot_downloadfrom fastdeploy import LLM, SamplingParamsmodel_id = \"PaddlePaddle/ERNIE-4.5-0.3B-Paddle\"model_dir = \"./models/ERNIE-4.5-0.3B-Paddle/\"# 下载模型权重和配置文件snapshot_download(repo_id=model_id, revision=\'master\', local_dir=model_dir)# 配置采样参数,提升生成文本多样性sampling = SamplingParams(temperature=0.8, top_p=0.95)# 加载模型,quantization可设为\'wint4\'、\'wint8\'或Nonellm = LLM(model=model_dir, max_model_len=32768, quantization=None)conversation = []while True: query = input(\"请输入您的问题(输入exit退出):\") if query.lower() == \'exit\': break conversation.append({\"role\": \"user\", \"content\": query}) response = llm.chat(conversation, sampling)[0] reply = response.outputs.text conversation.append({\"role\": \"assistant\", \"content\": reply}) print(reply)Step 4:部署体验与性能反馈
在实际部署层面,文心4.5展现出优异的效率与灵活性。整体部署耗时仅约4分钟,涵盖模型的下载、初始化与加载流程,适用于快速上线与迭代测试。在默认精度设置下,系统可实现流畅的对话推理响应,满足交互式应用需求。同时,文心4.5提供了灵活的量化支持策略,如 wint4 和 wint8,可根据硬件资源灵活选择,显著降低内存和算力消耗。更重要的是,该架构具备良好的可扩展性,可无缝适配ERNIE-4.5系列的更大规模模型(如21B、300B),为多阶段升级和性能验证提供了强有力的技术保障。
轻松上手,高效部署
本次在RTX 4090显卡上成功复现ERNIE-4.5-0.3B-Paddle模型,完整展示了 FastDeploy工具链在模型下载、加载、部署与推理上的一体化优势。整个流程:
- 简单:仅需少量命令与一段Python脚本;
- 快速:数分钟内完成全部初始化;
- 灵活:支持多种量化与模型切换方案;
- 可扩展:适配从轻量模型到大模型的全系列部署需求。
本实测结果为后续在本地或私有云部署ERNIE系列大模型提供了清晰、可复用的参考路径,也为开发者构建高性能中文大语言模型服务打下坚实基础。
三、文心4.5 vs DeepSeek V3
在中文大模型进入“百模大战”的今天,领先模型之间的竞争焦点,早已从“能否正确回答”转向“回答是否够深入、有逻辑、有情感、有思想”。为此,我们选取了两个具备代表性的问题,分别测试了百度文心 ERNIE-4.5-300B-A47B 与 DeepSeek-V3 两款中文SOTA模型的生成表现,并从五个维度进行客观评分与主观解读。
测试问题
如何评价周杰伦在歌坛的地位?
(考查文化深度、表达层次、产业视角)

为什么乌龟追不上兔子?
(考查逻辑表达、思维创新、语言生动性)

评测结果如下
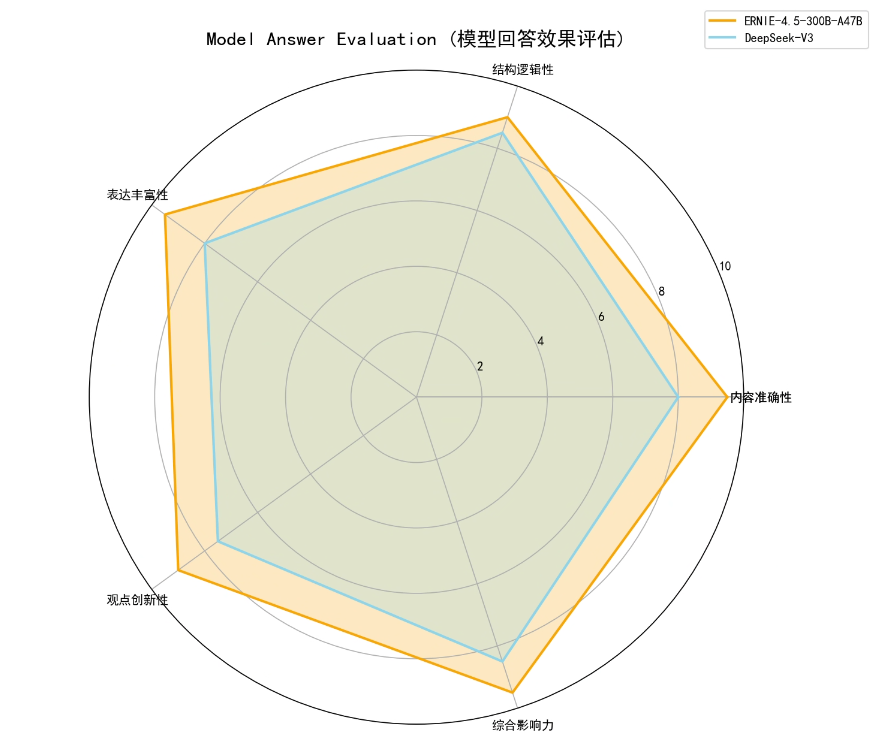
在多模态语言模型的语用风格上,ERNIE-4.5-300B-A47B展现出一种百科式的专家气质。其输出不仅追求信息的全面性和层级递进的结构安排,还展现出扎实的知识体系与逻辑推演能力。例如在回答“周杰伦”相关问题时,它能够自音乐风格演变谈及华语流行文化的结构性变革,体现出学术化视角与跨领域理解力。这类风格特别适合用于教育培训、行业报告或专业写作等高信度、高严谨场景,被称作“AI策展人”实至名归。
相较而言,DeepSeek-V3更擅长以轻量化语言进行流畅表达,句式紧凑、通俗易懂,富有一定的传播感染力。其风格偏向于用高密度信息包装直给观点,常能输出“金句”式语句,便于在短视频脚本、社交媒体配文中直接引用。虽然在深度内容延展方面略显不足,但在轻交互与高频传播场景中依然具有极强的适配力。可以说,它更像是一位紧跟语言潮流、善于共情的“AI写手”。
此次实测表明,ERNIE-4.5-300B-A47B 不仅具备一流的语言生成能力,更在内容深度与结构设计上表现出色,在专业、教育、政企等场景具备明显优势。而DeepSeek-V3则展示了在轻量化表达、传播效率方面的灵活性,两者风格不同,适用领域互补。
在中文模型百花齐放的当下,这类对比测试有助于用户“按需选模”,实现模型价值的精准释放。
四、开源战略的深层价值与未来方向
文心大模型4.5的全面开源,不只是一次技术层面的突破,更体现了百度在人工智能发展战略上的深远思考。从模型能力开放到产业生态搭建,从算力优化到开放治理体系的构建,文心4.5正推动国产大模型从“闭源对标”迈向“共建生态”的全球竞争新阶段。
1. 商业与开源的平衡艺术:打造“可盈利的开源生态”
百度此次采用了分层开源 + 商业支持的策略,在开放底层能力的同时构建可持续的商业模式,这一做法类似于Red Hat在开源Linux生态中的成功路径:
- 基础模型免费开源:10款不同参数规模的模型(从0.3B到424B)均以Apache 2.0协议开放,允许免费、商用、改造和再分发;
- 企业级能力闭环:在企业服务层,百度提供如千帆平台、飞桨生态、异构硬件适配、定制微调等完整的技术和云端服务支持;
- 产业协同场景接入:通过与政务、制造、金融、能源等地方合作伙伴的联合定制部署,进一步强化开源模型的实际落地与商业延展能力。
这一模式既避免了大模型“免费陷阱”导致的资源枯竭,又提升了模型本身的生命力与更新频率,有望形成可循环的“开源-协同-商业化”飞轮。
2. 未来演进关键路径:从模型能力到AI基础设施转型
随着开源基础不断夯实,文心大模型的未来演进将围绕三大方向展开:
(1)端侧智能深化:模型轻量化与隐私保护并行
未来AI将不仅存在于云端,更深度嵌入终端设备。文心4.5中的轻量级模型(如0.3B、1.9B)已可在国产手机、车载芯片、工业控制设备等场景中运行:
- 实现边缘智能推理:无需依赖云端接口,即可在本地执行推理与响应;
- 支持零上传隐私处理:用户数据本地处理,避免数据出境和敏感信息泄露;
- 提供低功耗适配包:结合量化技术和端侧算子融合,降低运行成本与功耗。
这对于智能制造、智慧医疗、自动驾驶等对“数据安全+实时响应”要求极高的行业尤为重要。
(2)多模态统一架构:构建“通用智能体”基础框架
文心4.5目前已具备文本与图像的深度融合能力,未来将向语音、视频、3D感知等更多模态延展,最终构建完整的“全模态专家池”:
- 引入语音识别与合成模块,实现语音对话式AI助手;
- 集成视频理解与生成能力,支持场景级智能监控、虚拟人交互;
- 统一Agent架构:使模型能够跨模态感知、理解与决策,朝向“全能型AI代理”迈进。
这种能力的成熟,将是实现通用人工智能(AGI)的重要中间形态。
(3)健全开源治理机制:共建可信AI生态
开源不仅是代码开放,更是治理开放。百度提出将建立更完善的开源治理机制,包括:
- 贡献者激励制度:如榜单评选、贡献积分与合作项目通道,鼓励开发者社区活跃参与;
- 模型使用伦理守则:明确使用范围、合规指引与审查机制,防止模型被滥用于造假、侵权、诈骗等不当用途;
- 多方协同监督:吸引高校、研究机构、监管部门等共建“安全、透明、可控”的国产大模型使用框架。
只有在治理机制、商业模式和技术演进三者协同下,开源大模型才能从“技术可用”真正走向“社会可信”。
总结-文心4.5开源,是中国AI迈向全球共建的关键一步
文心大模型4.5的开源,不仅是技术参数的升级和模型数量的扩展,更是中国AI迈向“全球共建、生态共融”的重要里程碑。在国际大模型格局日趋复杂的背景下,百度以全栈开源+工程可用性+多模态创新三重驱动,打破了过往“只看不开”、“只供不养”的封闭循环,为全球开发者提供了真正可落地、可拓展、可演化的中文智能基础设施。
从技术上看,H-MoE异构专家架构、模态隔离机制、动态稀疏路由与精量化推理优化,使得文心4.5在性能、效率与多样性上形成突破。无论是端侧部署,还是企业中台,文心4.5都表现出卓越的适应能力。
从部署上看,即使是单张消费级GPU也能轻松运行0.3B轻量模型,为中小团队、大众开发者打开了技术普惠之门。实测对比中,文心300B版本在语言深度、结构逻辑和内容准确性上均超越了同量级的SOTA模型DeepSeek-V3,奠定了其在中文AI领域“专家型”大模型的领先地位。
从战略角度看,文心4.5的全面开源释放出一种新的中国技术观——开放即实力,协同即未来。分层开源+商业协作的生态打法,既保障了技术扩散与社区活跃,也构建了长期可持续的商业闭环,正在为构建可信、可控、自主的大模型基础设施铺路。
展望未来,文心大模型将进一步向全模态、全平台、全行业智能体演化,在多模态认知、边缘智能、隐私保护、产业协同等关键场景持续进化,成为中国AI面向全球输出能力、标准和影响力的核心引擎。
文心4.5,不只是一个模型,更是一种理念的落地:让真正有用的AI,人人可用。

一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/theme/1939325484087291906

