一文教你快速上手ElasticSearch_elasticsearch 创建、插入、检索
文章目录
一、前言
本文介绍了Elasticsearch中索引和文档的基本CRUD操作,包括索引的创建、别名设置与删除,以及文档的插入、查询、更新和删除方法。还详细讲解了简单搜索和复杂搜索的实现,涵盖模糊匹配、字段筛选、排序和分页等功能。通过具体示例展示了API调用方式和返回结果,帮助用户快速掌握ES的基础操作技巧。
二、索引操作
2.1 创建索引
- 单独创建索引
PUT /index_for_test?pretty{ \"acknowledged\" : true, \"shards_acknowledged\" : true, \"index\" : \"index_for_test\"}- 创建索引和分片数
PUT /index_for_test?pretty{ \"settings\": { \"number_of_shards\": 3, \"number_of_replicas\": 2 }}{ \"index_for_test\" : { \"aliases\" : { }, \"mappings\" : { }, \"settings\" : { \"index\" : { \"creation_date\" : \"1653186417869\", \"number_of_shards\" : \"3\", \"number_of_replicas\" : \"2\", \"uuid\" : \"DguQ--FTQSmbKizqctxNPA\", \"version\" : { \"created\" : \"7060199\" }, \"provided_name\" : \"index_for_test\" } } }}- 创建索引的别名
POST /_aliases{\"actions\": [ { \"add\": { \"index\": \"index_for_test\", \"alias\": \"index_for_test_alias\" } } ]}还可以使用通配符,将一类索引用一个别名,创建了三个索引index_for_test,index_for_test2
,index_for_test3,然后通过通配符增加别名,如:
POST /_aliases{\"actions\": [ { \"add\": { \"index\": \"index_for_test*\", \"alias\": \"index_for_test_alias\" } } ]}查看别名:
GET /index_for_test_alias{ \"index_for_test\" : { \"aliases\" : { \"index_for_test_alias\" : { } }, \"mappings\" : { }, \"settings\" : { \"index\" : { \"creation_date\" : \"1653186417869\", \"number_of_shards\" : \"3\", \"number_of_replicas\" : \"2\", \"uuid\" : \"DguQ--FTQSmbKizqctxNPA\", \"version\" : { \"created\" : \"7060199\" }, \"provided_name\" : \"index_for_test\" } } }, \"index_for_test2\" : { \"aliases\" : { \"index_for_test_alias\" : { } }, \"mappings\" : { }, \"settings\" : { \"index\" : { \"creation_date\" : \"1653187323418\", \"number_of_shards\" : \"3\", \"number_of_replicas\" : \"2\", \"uuid\" : \"F3L4-koIRRq4Oc1mpIxGKQ\", \"version\" : { \"created\" : \"7060199\" }, \"provided_name\" : \"index_for_test2\" } } }, \"index_for_test3\" : { \"aliases\" : { \"index_for_test_alias\" : { } }, \"mappings\" : { }, \"settings\" : { \"index\" : { \"creation_date\" : \"1653187327181\", \"number_of_shards\" : \"3\", \"number_of_replicas\" : \"2\", \"uuid\" : \"ygKXJQ2bSfmEgL_30xWtSA\", \"version\" : { \"created\" : \"7060199\" }, \"provided_name\" : \"index_for_test3\" } } }}删除索引的时候,自动会将别名对应的索引,从列表中删除
2.2 删除索引
DELETE /index_for_test?pretty三、文档操作
3.1 插入
es可以指定id存储,也可以不指定id自动生成。自动生成的id是 URL-safe、基于Base64编码且长度为20个字符的GUID字符串。这些GUID字符串由可
修改的FlakeID模式生成,这种模式允许多个节点并行生成唯一ID且互相之间的冲突概率几乎为零。
PUT /wangzhe/_doc/1{ \"name\":\"夏侯惇\", \"age\":26, \"role\":\"上单\", \"tags\":[\"战士\",\"肉\"]}依次添加鲁班、王昭君,结果如下:
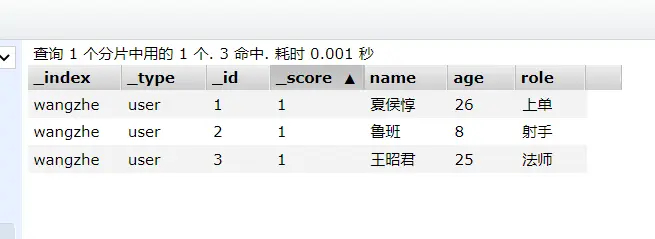
3.2 查询
对于一个查询请求,Elasticsearch 的工程师偏向于使用 GET 方式,因为他们觉得它比 POST 能更好的描述信息检索(retrieving information)的行为。然而,因为带请求体的 GET 请求并不被广泛支持,所以 search API同时支持 POST 请求。
3.2.1 简单查询
GET /wangzhe/_doc/1如下:
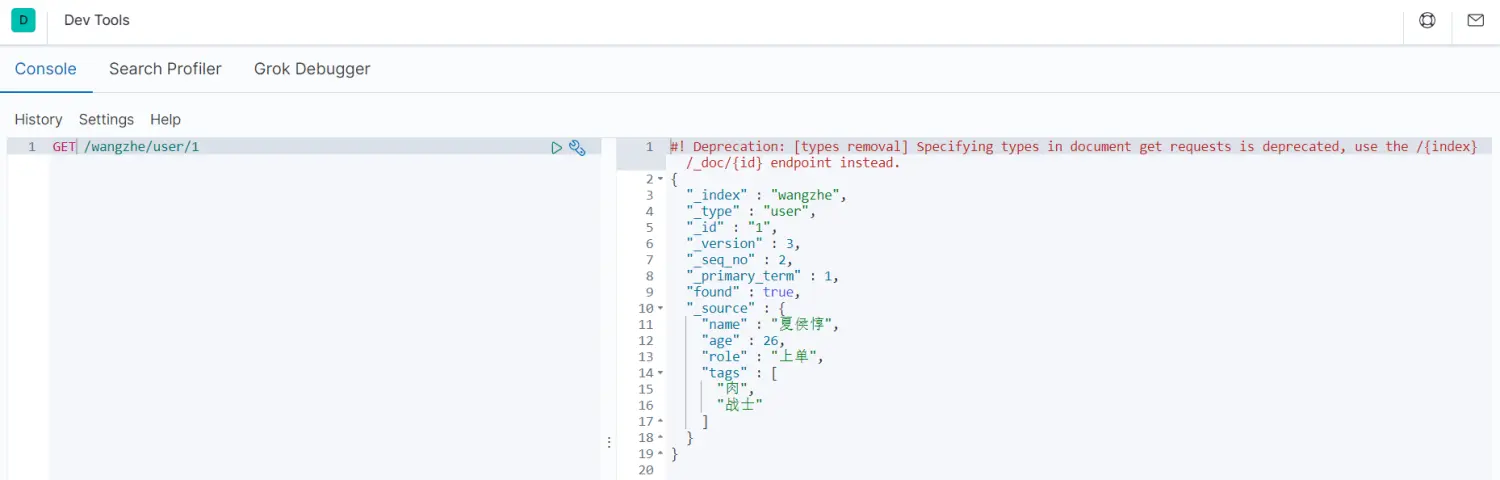
3.2.2 返回文档的一部分数据
GET /wangzhe/_doc/1?_source=name,age3.2.3 只要 _source字段
GET /wangzhe/_doc/1?_source=name,age3.3 更新
3.3.1 PUT操作全量修改
PUT /wangzhe/_doc/1{ \"name\":\"孙策\", \"age\":26, \"role\":\"上单\", \"tags\":[\"战士\",\"船夫\"]}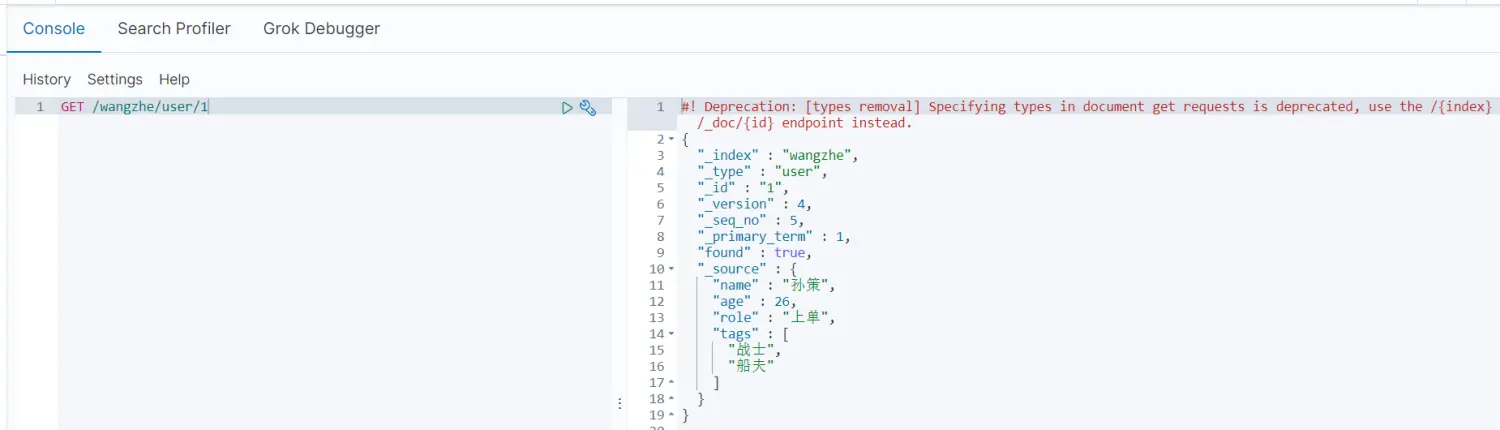
3.3.2 POST+_update局部更新修改
POST /wangzhe/_update/1{ \"doc\": { \"tags\": [ \"战士\", \"船夫\", \"肉\" ] }}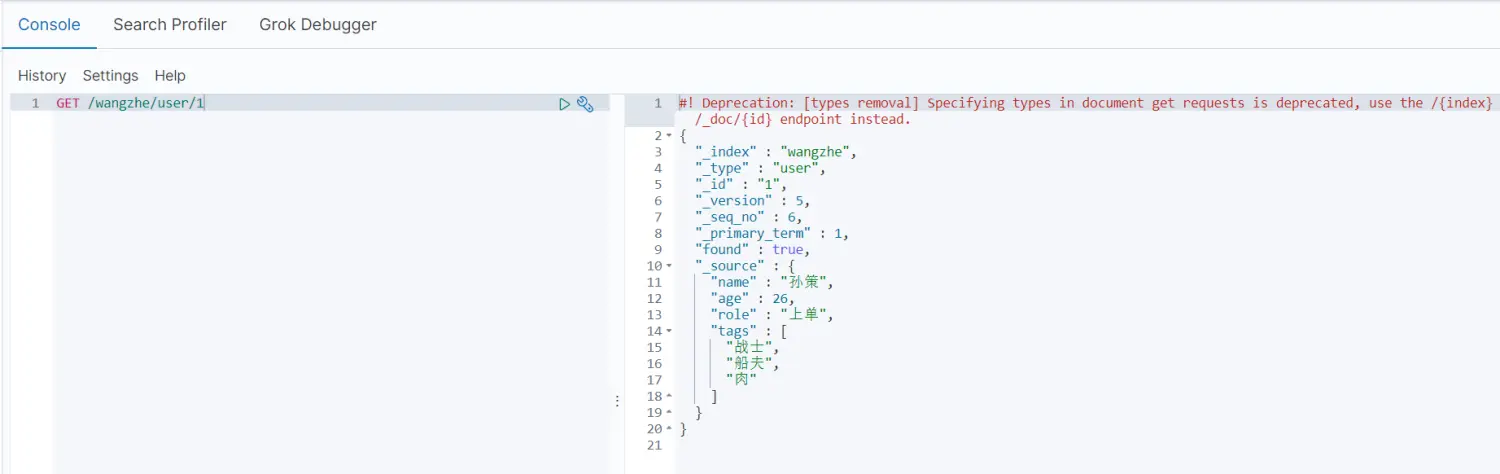
3.4 删除
删除id为1的文档
DELETE /wangzhe/_doc/1删除之后_version 值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
四、搜索
4.1 简单搜索
GET /wangzhe/_search?q=name:孙//q表示query//字段是name//匹配的值是鲁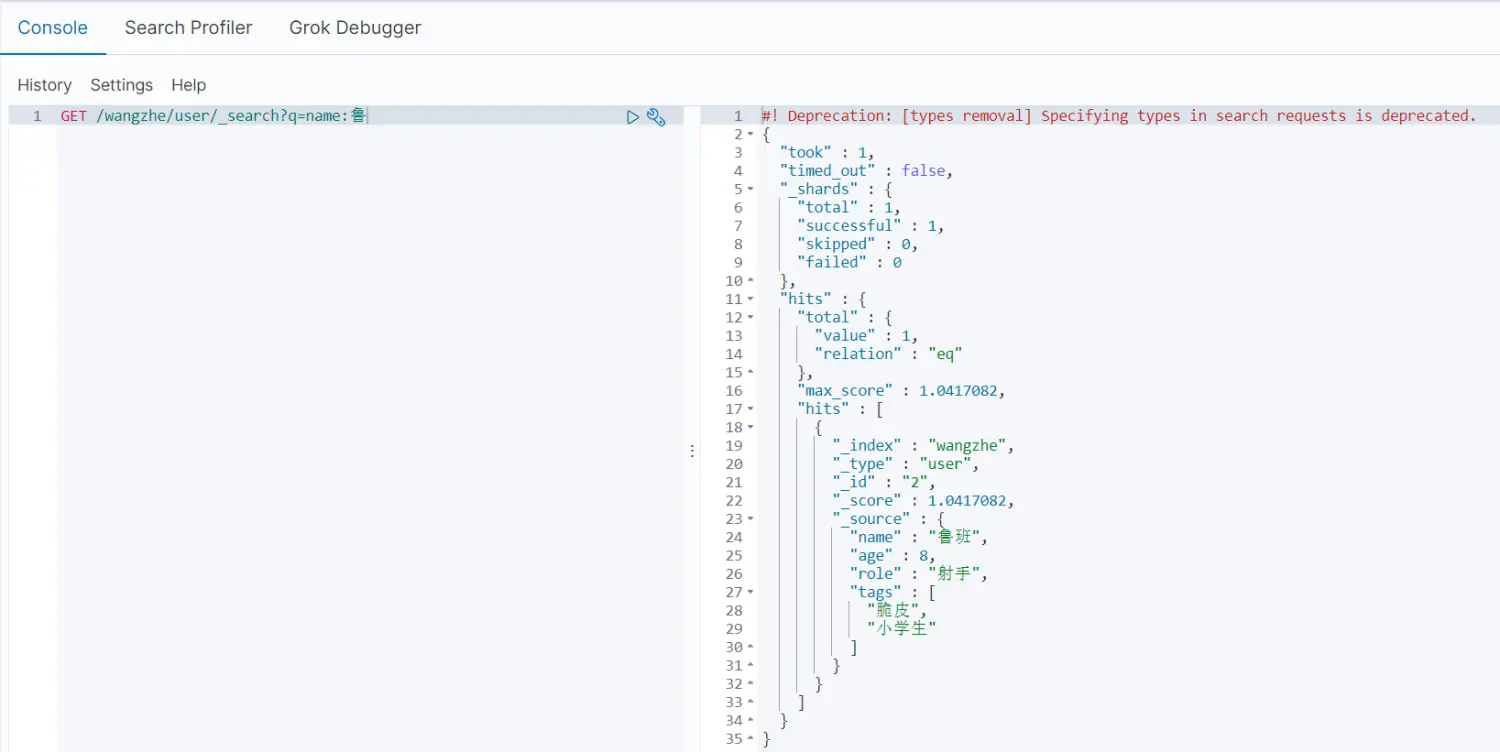
4.2 复杂搜索
ES比较复杂的是查询操作,包括排序、分页、高亮、模糊查询、精准查询等
- 查询名称包含鲁班的数据
语法
GET /wangzhe/_search{ \"query\": { \"match\": { \"name\": \"孙\" } }}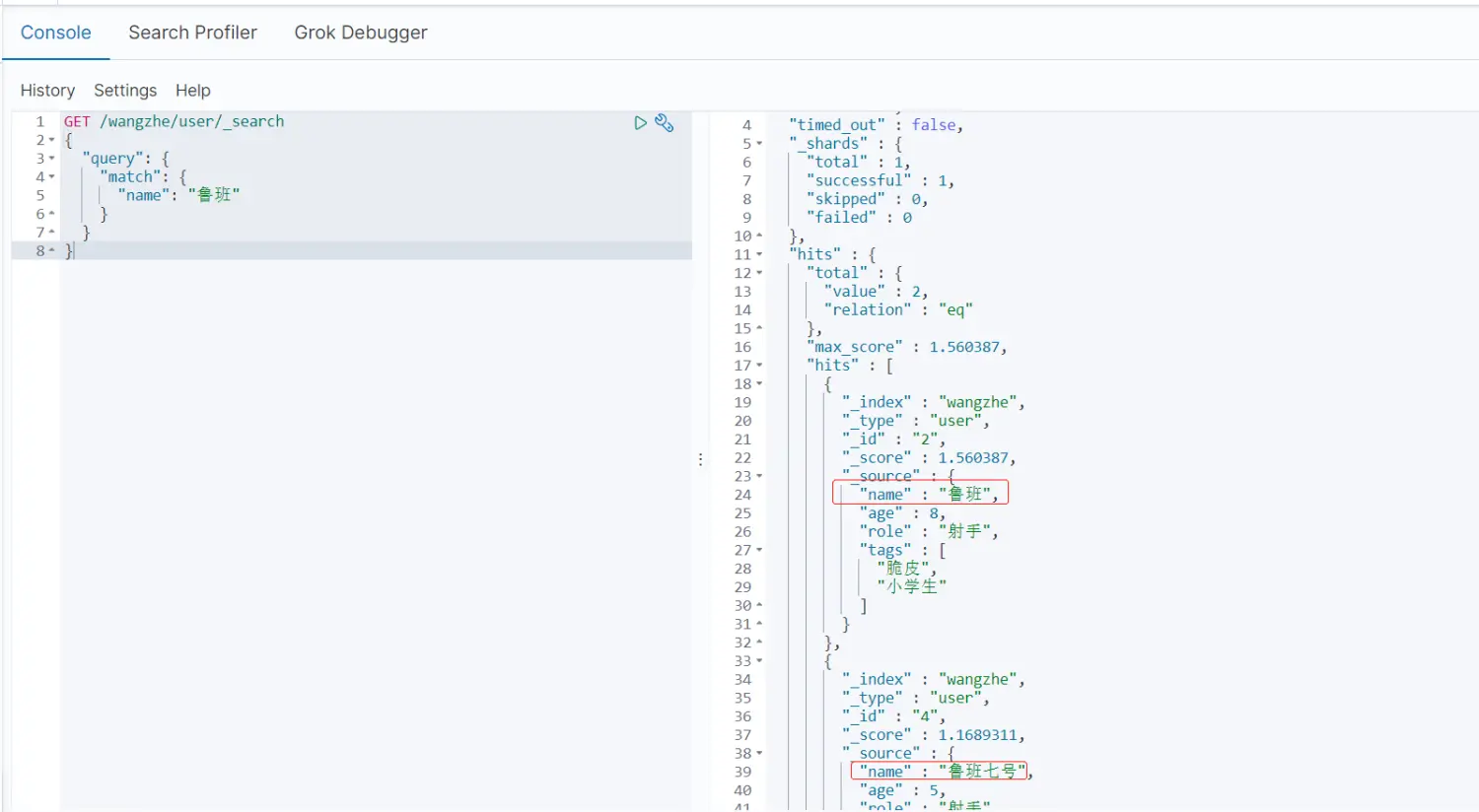
hit:包含了索引和文档的信息、查询的结果总数、查询出来的具体的文档、分数(通过分数可以判断哪个更符合)
- 查询结果返回固定字段(类似于mongo中的倒影查询)
GET /wangzhe/_search{ \"query\": { \"match\": { \"name\": \"鲁班\" } }, \"_source\": [\"name\",\"role\"]}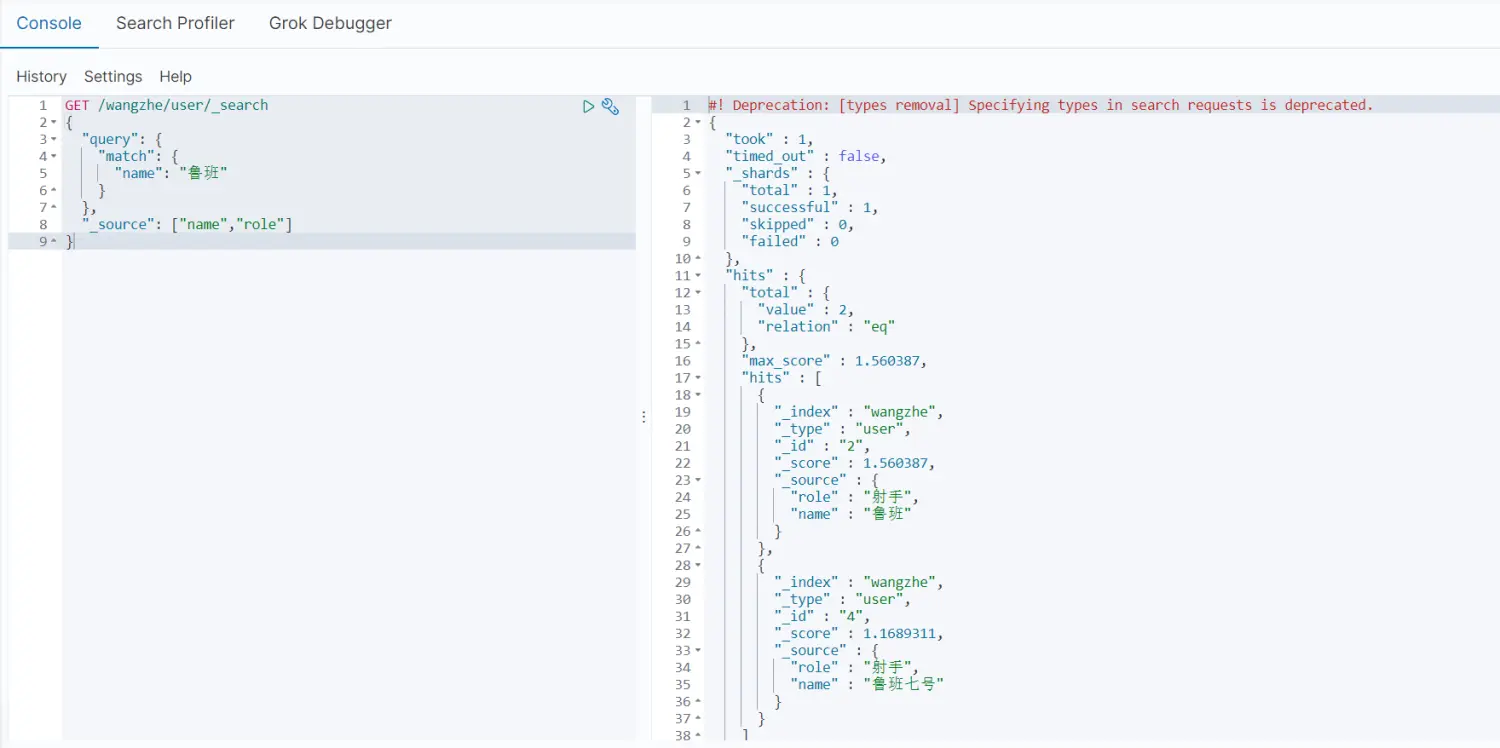
- 排序
根据关键字符合鲁班,age排序,asc:升序,desc:降序
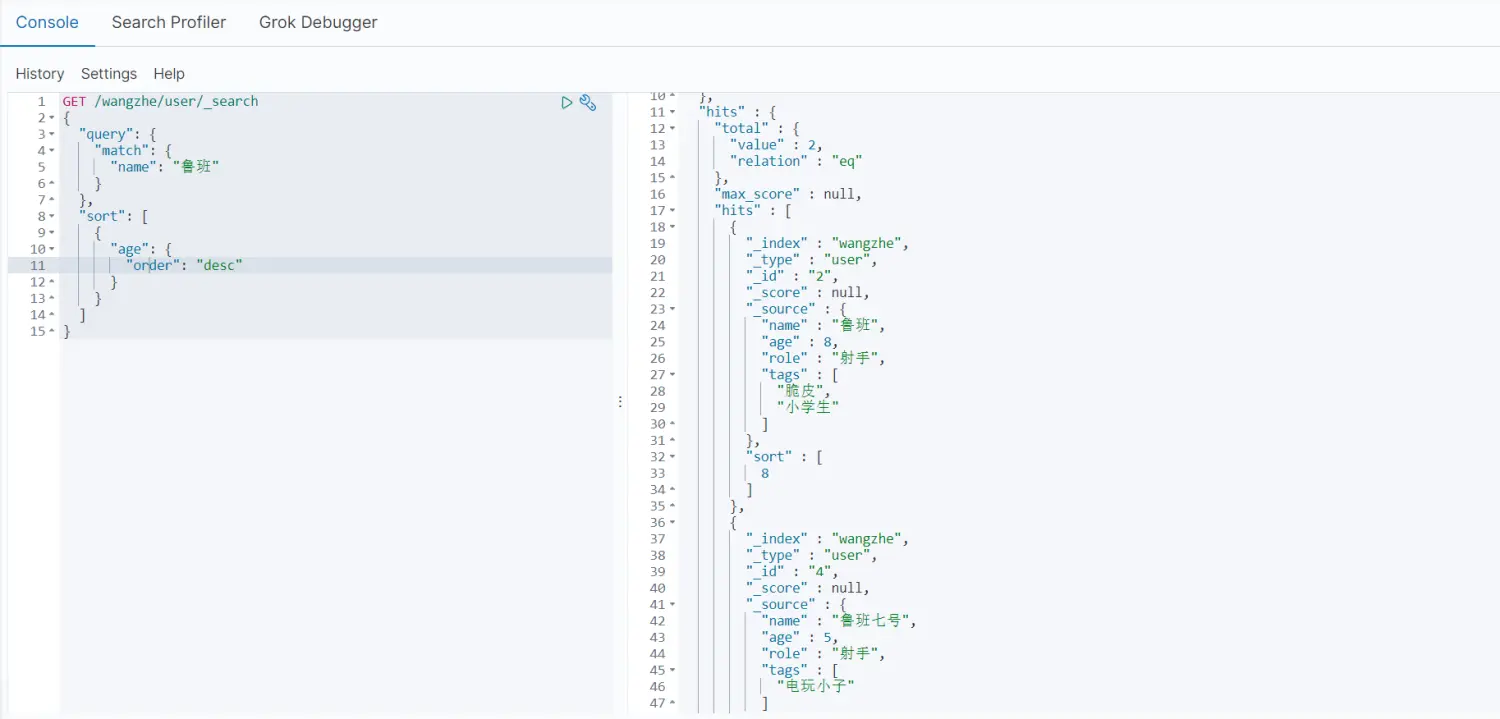
- 分页查询
from:从第几条数据开始,size:返回多少条数据
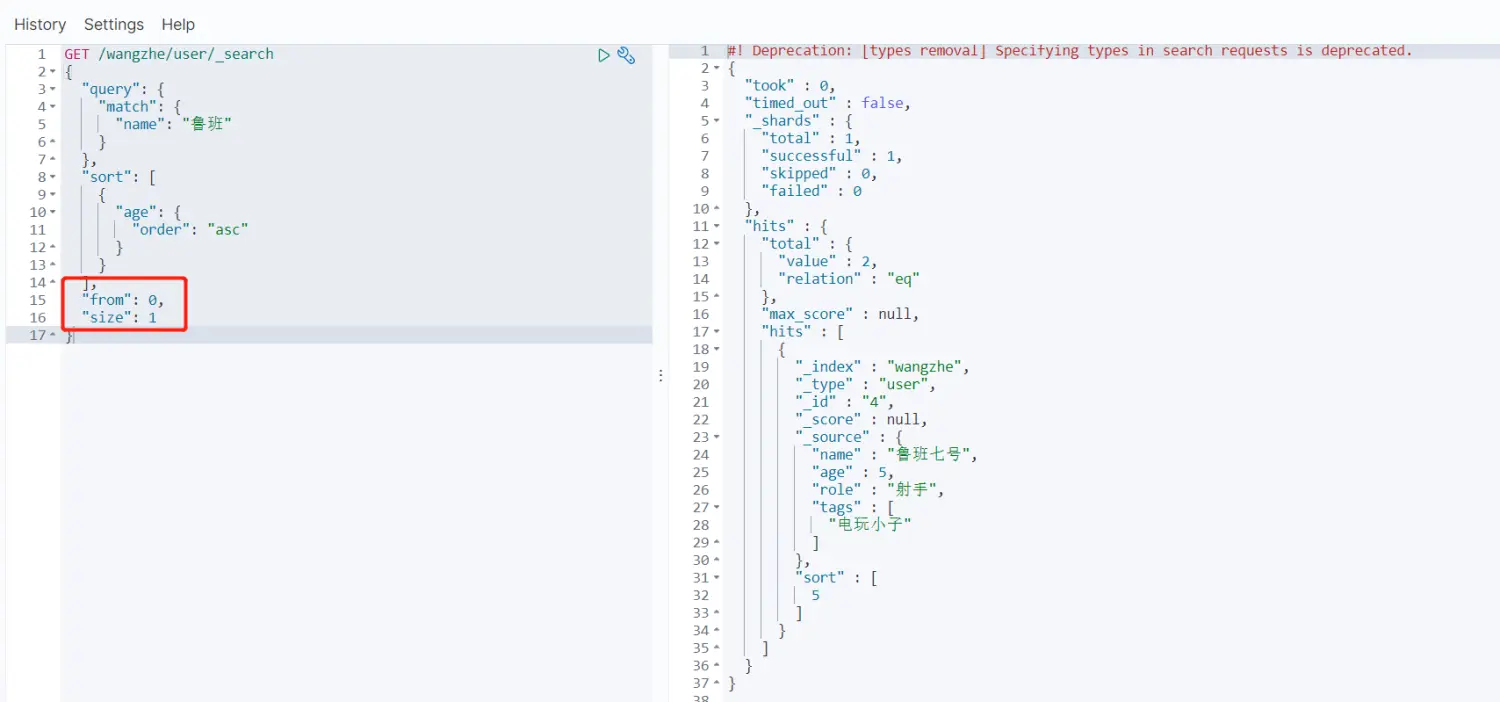
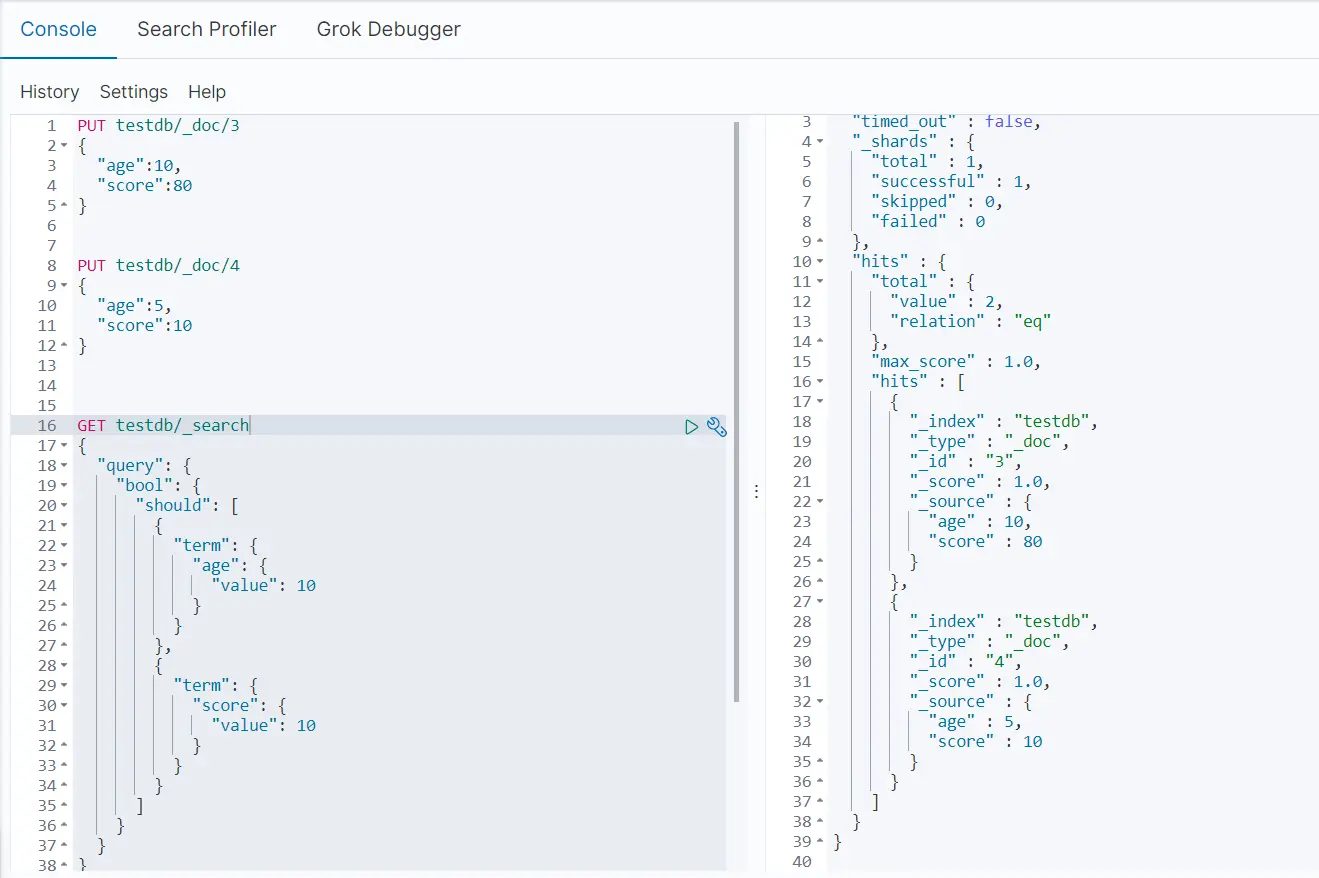
- 通过bool进行多条件的匹配查询
must(相当于MySQL中的and),所有条件都要符合
must_not(相当于MySQL中的!=)
GET /wangzhe/_search{ \"query\": { \"bool\": { \"must\": [ { \"match\": { \"name\": \"鲁班\" } }, { \"match\": { \"age\": 5 } } ] } }}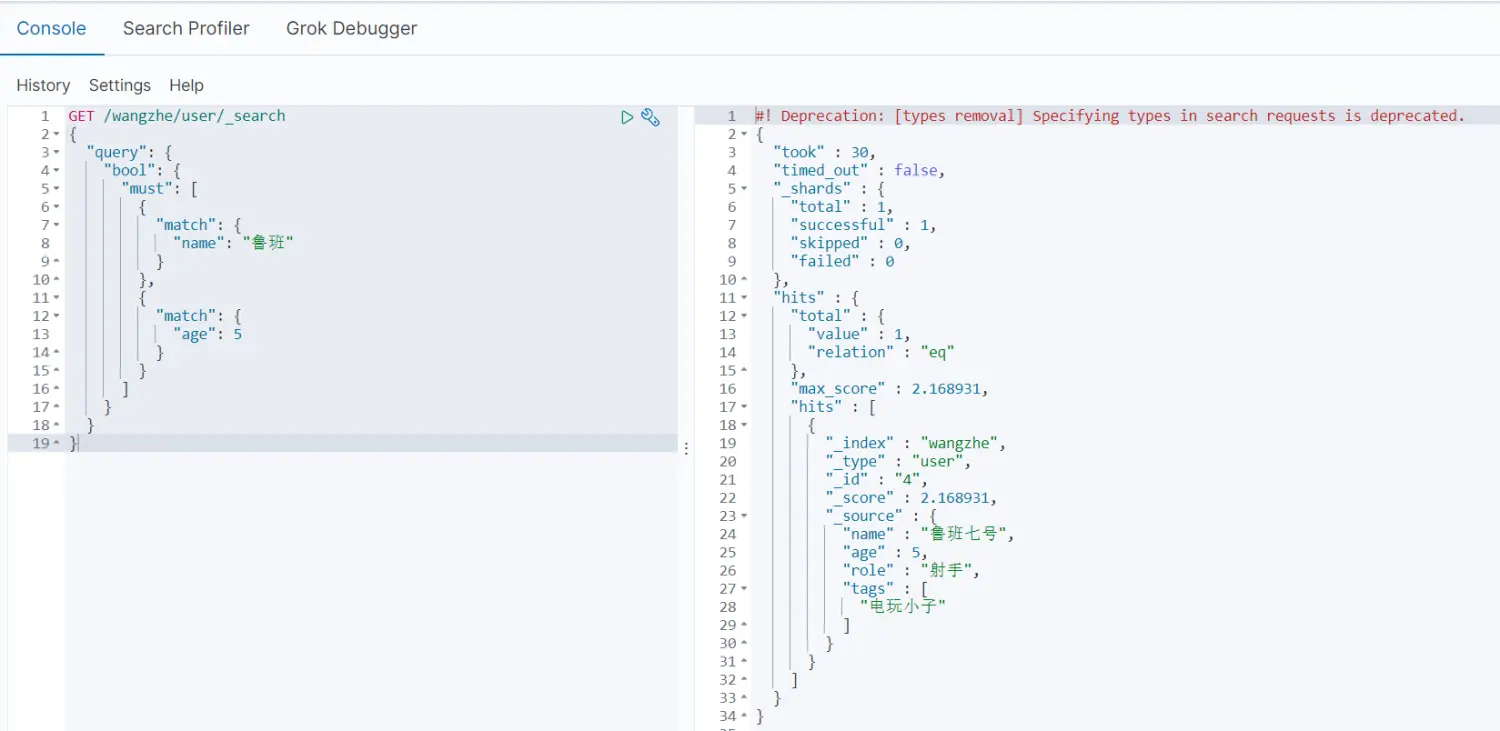
should(相当于MySQL中的or),所有条件或的查询
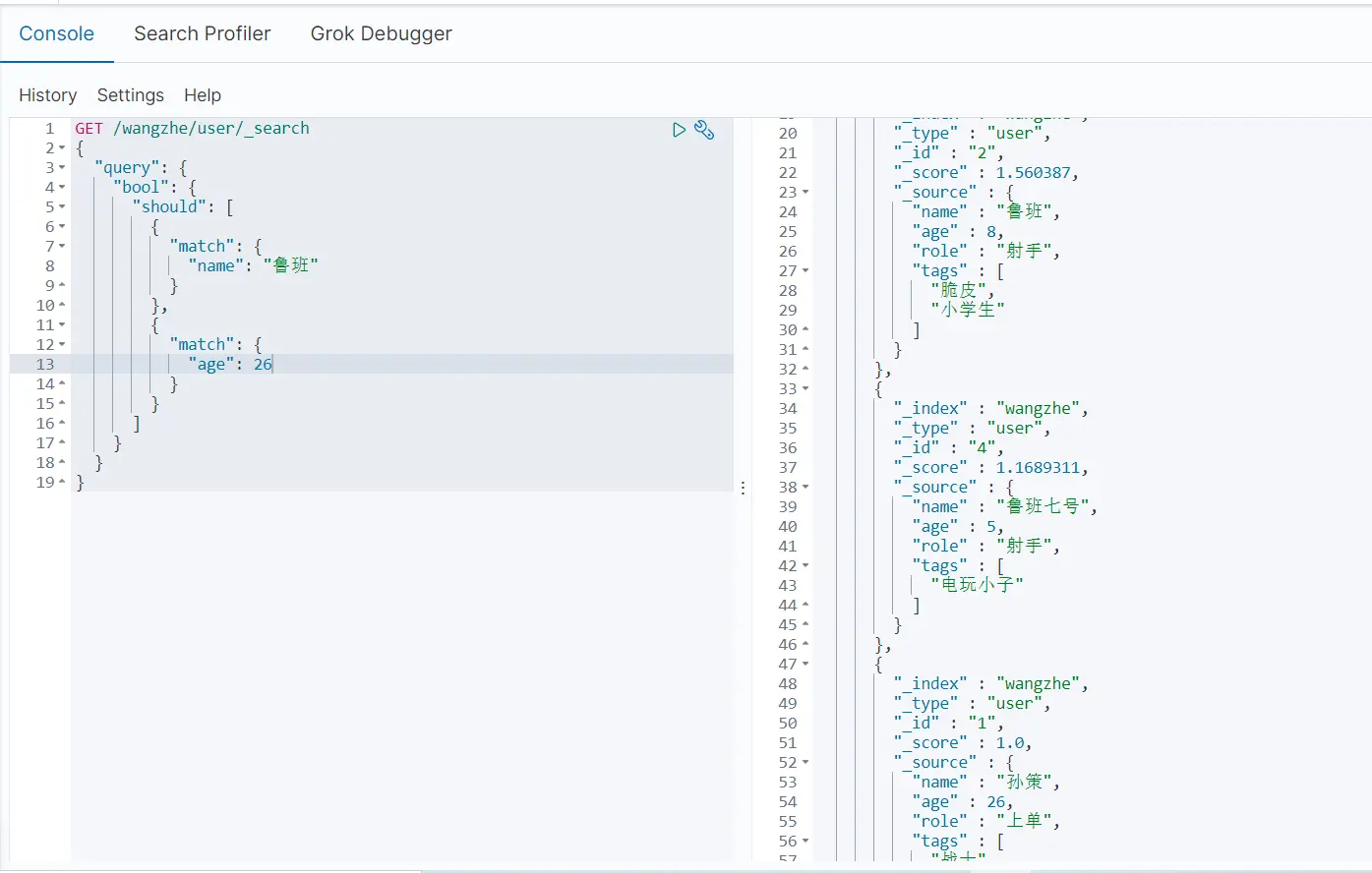
- 通过filter进行过滤查询
GET /wangzhe/_search{ \"query\": { \"bool\": { \"should\": [ { \"match\": { \"name\": \"鲁班\" } } ], \"filter\": { \"range\": { \"age\": { \"lte\": 8 } } } } }}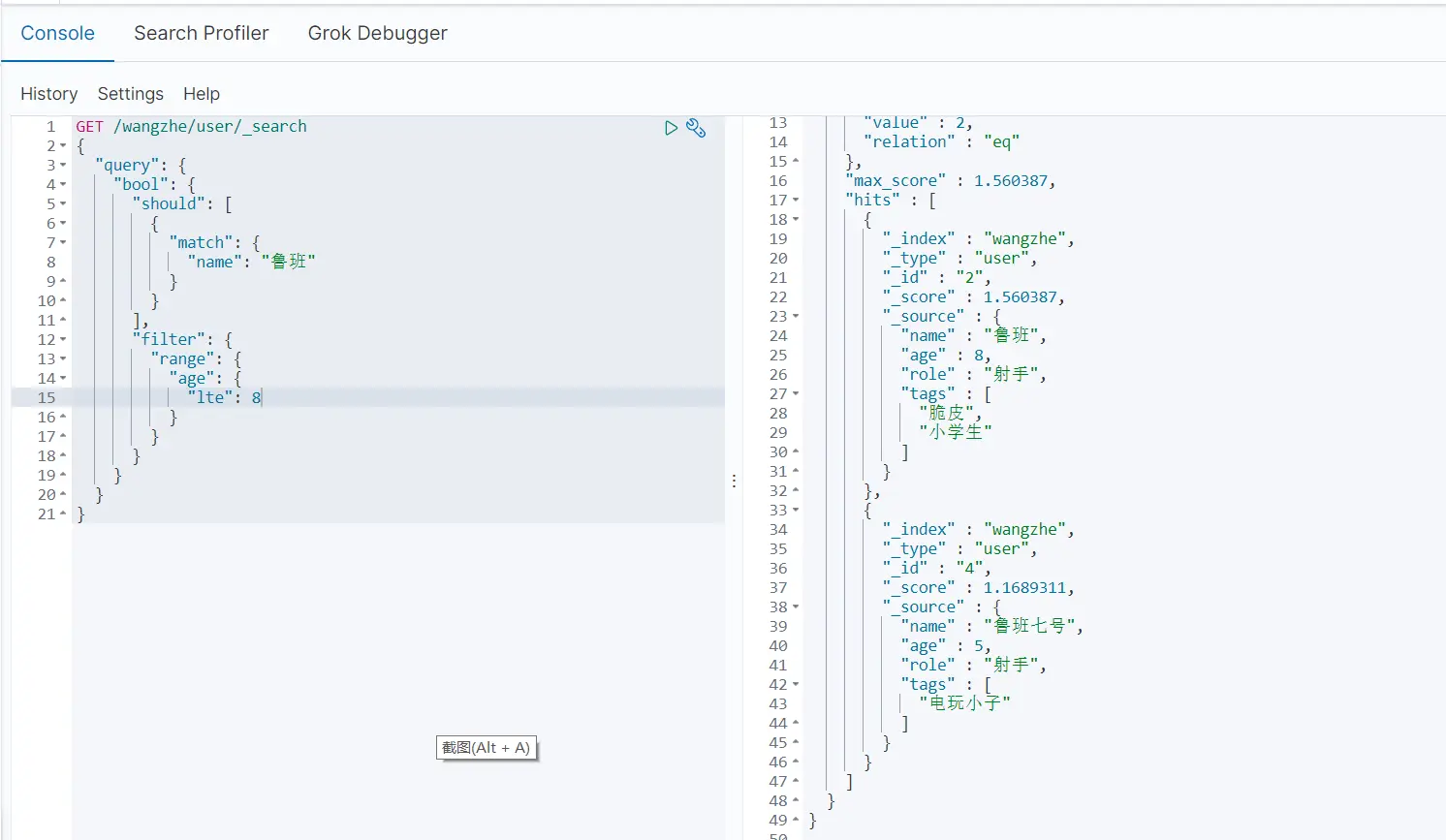
- 数组匹配查询
数组里的多个匹配条件通过空格隔开即可,只要满足其中一个条件即可被查出
GET /wangzhe/_search{ \"query\": { \"match\": { \"tags\": \"学生 肉\" } }}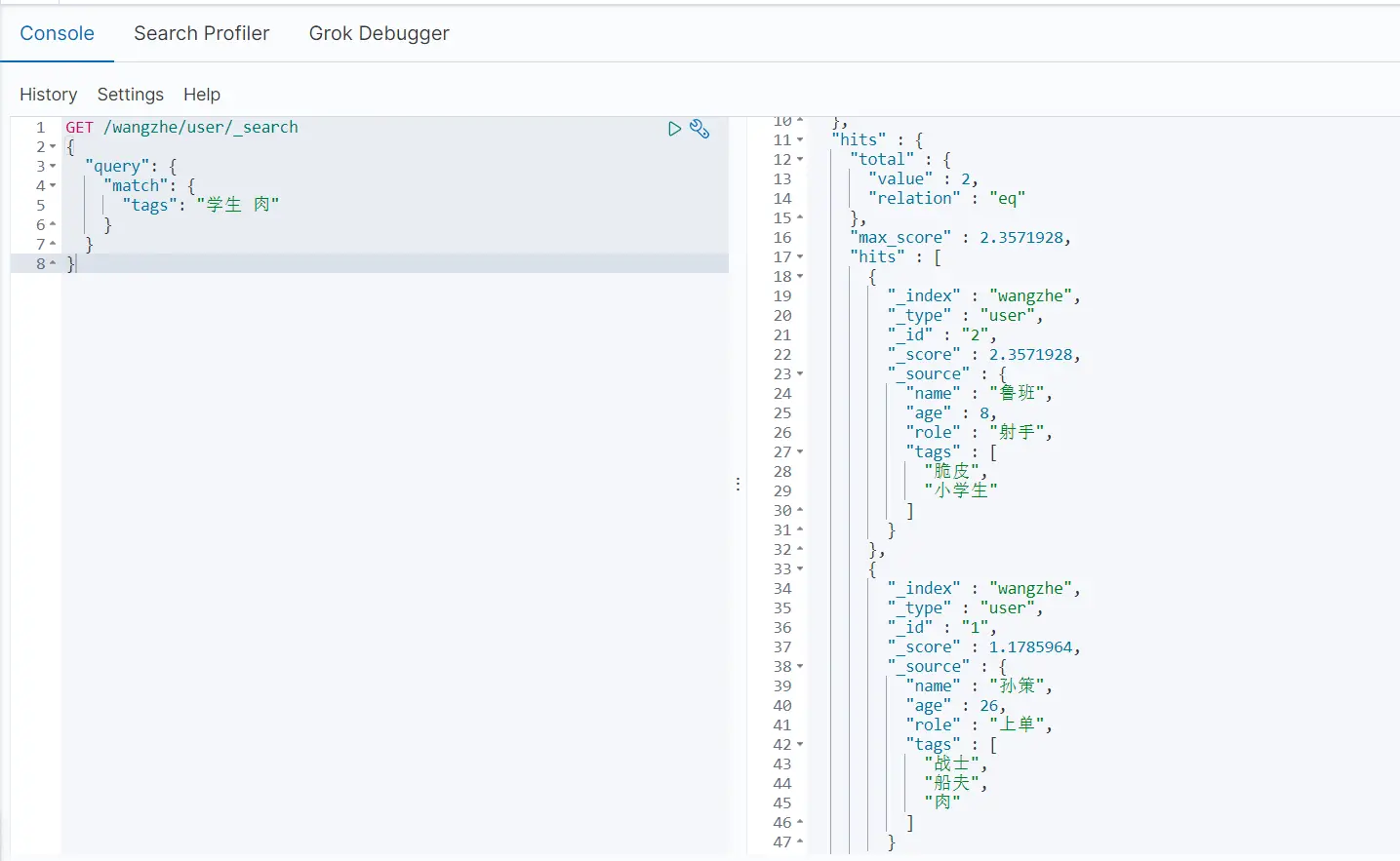
- 精确查询
term查询是直接通过倒排索引指定的词条进程精确的查找!
关于分词
a. term:查询精确的
b. match:会使用分词器解析(先分析文档,再通过分析的文档进行查询)
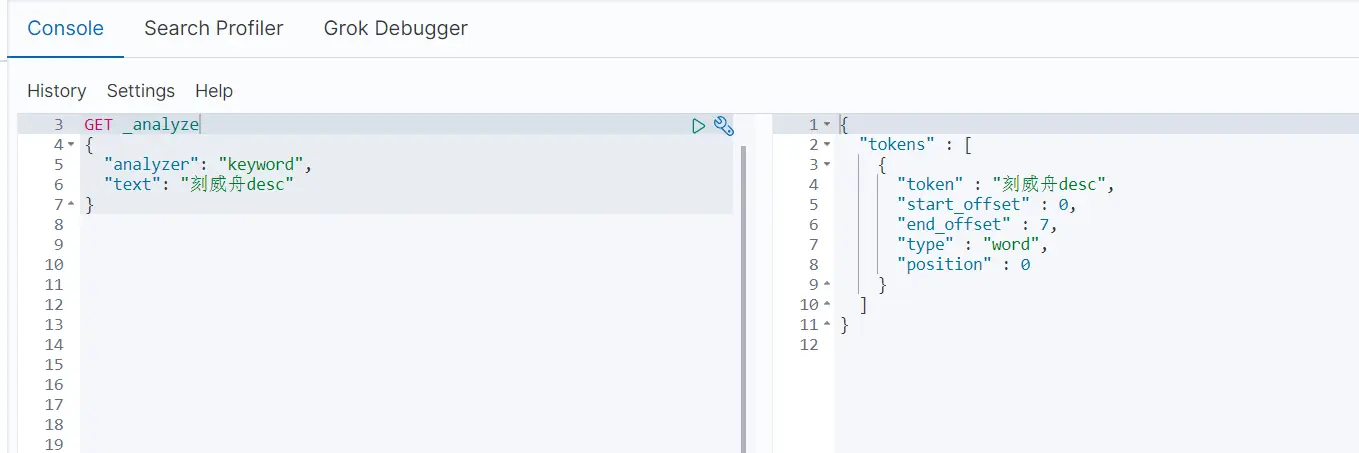
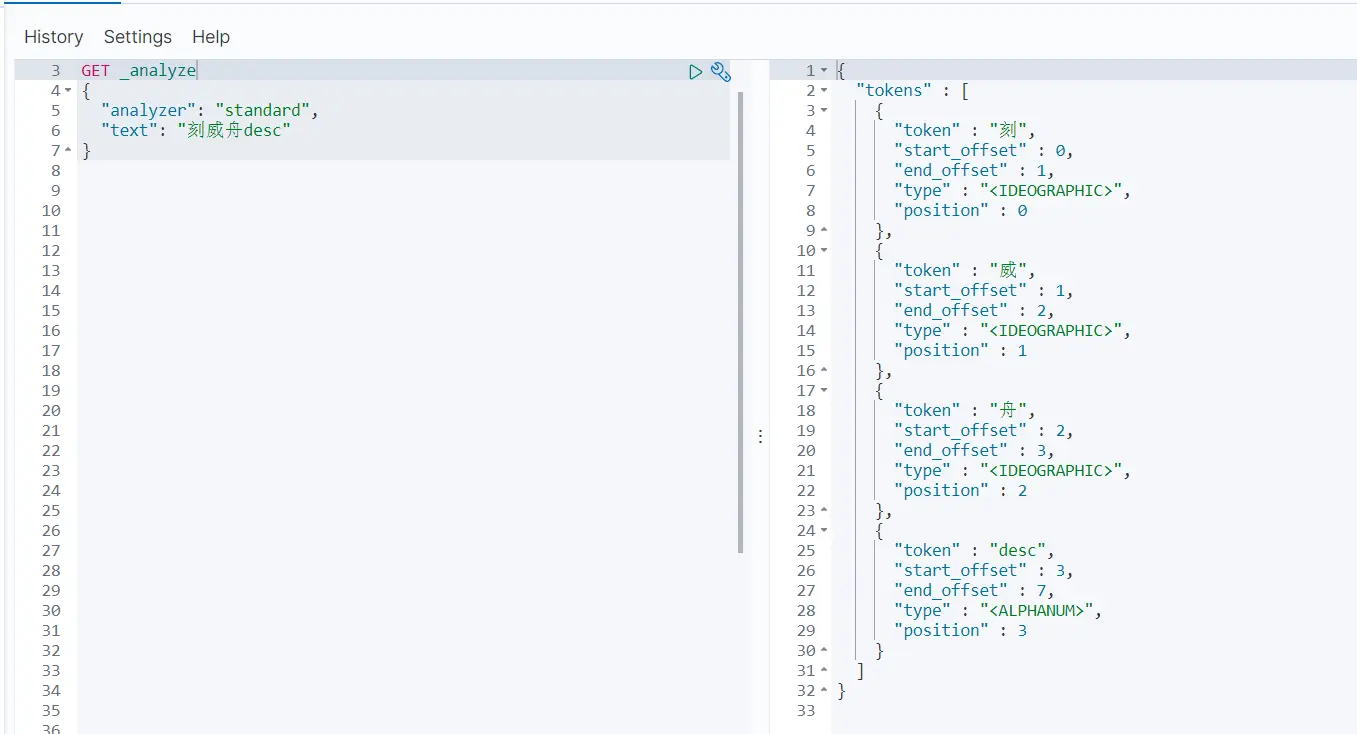
两个类型 text keyword
创建testdb索引并插入两条数据,name为text类型,desc为keyword类型。text类型会被当成分词器普通解析,如果是keyword类型则不会解析。
PUT testdb{ \"mappings\": { \"properties\": { \"name\":{ \"type\": \"text\" }, \"desc\":{ \"type\": \"keyword\" } } }}PUT testdb/_doc/1{ \"name\":\"刻威舟\", \"desc\":\"刻威舟desc1\"}PUT testdb/_doc/2{ \"name\":\"刻威舟\", \"desc\":\"刻威舟desc2\"}通过head插件查看索引的映射规则:
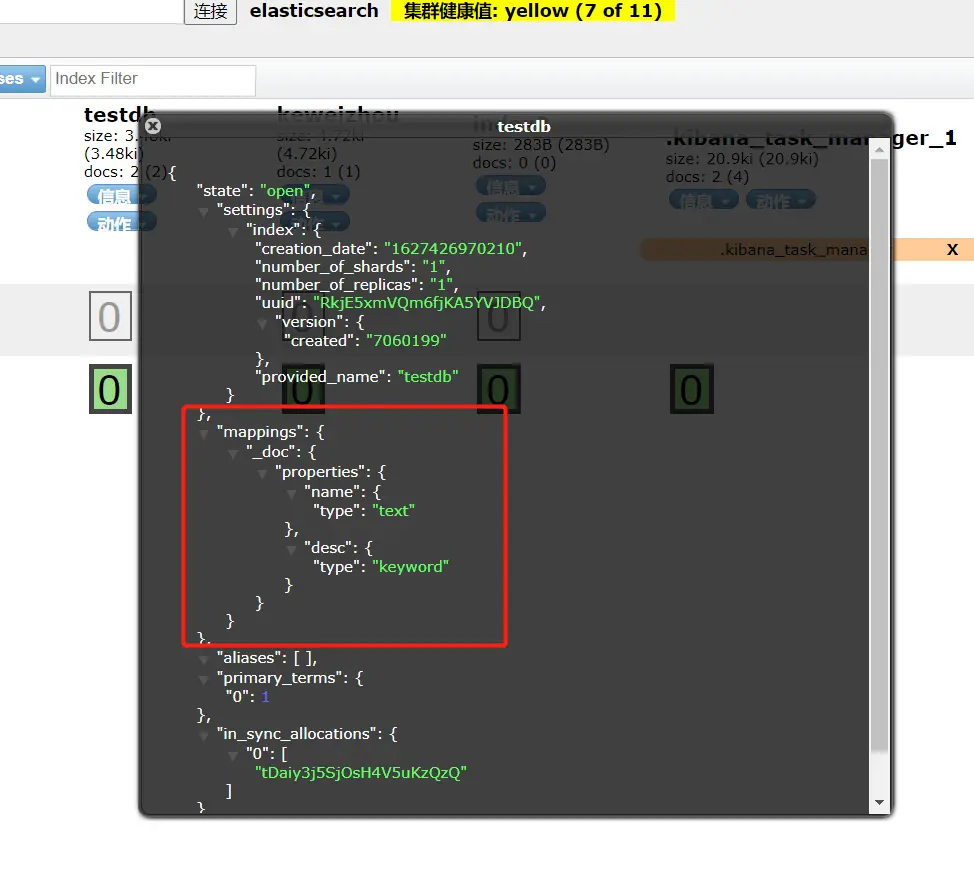
测试text、keyword两种类型
利用keyword会把它当做一个整体,而利用普通的默认分词器,会把它拆分成一个个字,如下图:
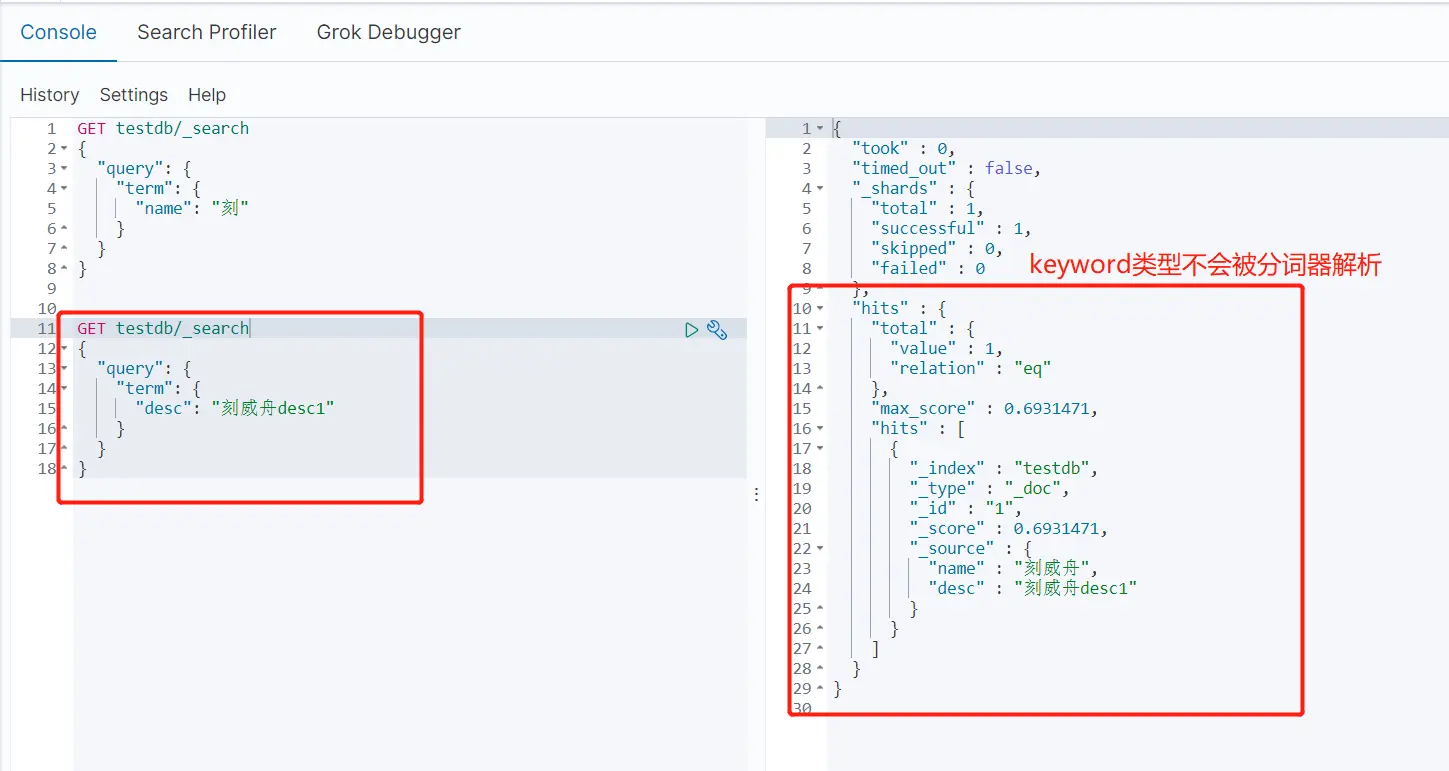
- 多个值匹配精确查询
- 高亮查询
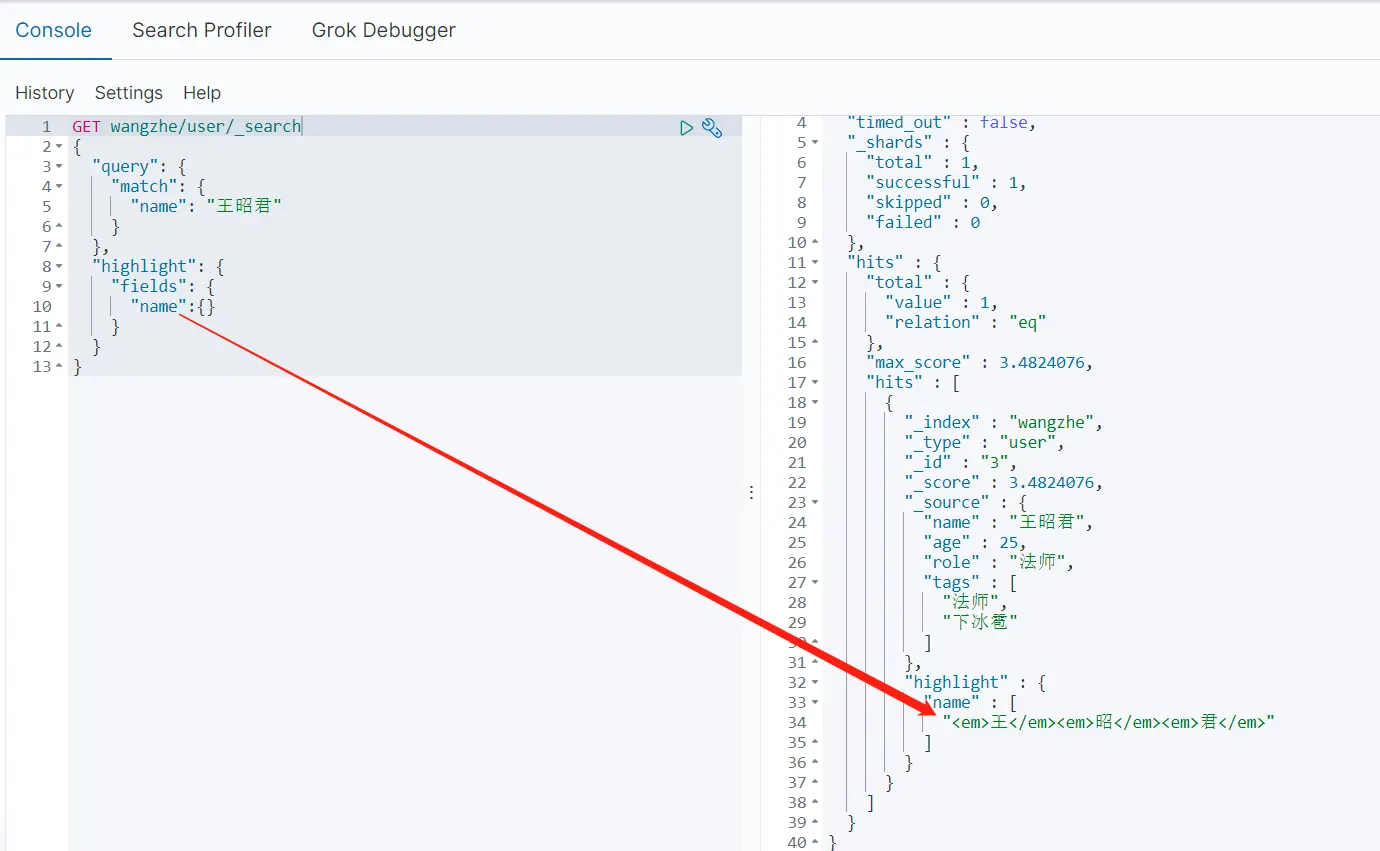
1.默认高亮查询
GET wangzhe/_search{ \"query\": { \"match\": { \"name\": \"王昭君\" } }, \"highlight\": { \"fields\": { \"name\":{} } }}搜索相关的结果会被高亮显示,通过highlight里面的fields进行字段设置
2.自定义高亮查询
GET wangzhe/_search{ \"query\": { \"match\": { \"name\": \"王昭君\" } }, \"highlight\": { \"pre_tags\": \"<p class=\'key\' style=\'color:red\'\", \"post_tags\": \"\", \"fields\": { \"name\":{} } }}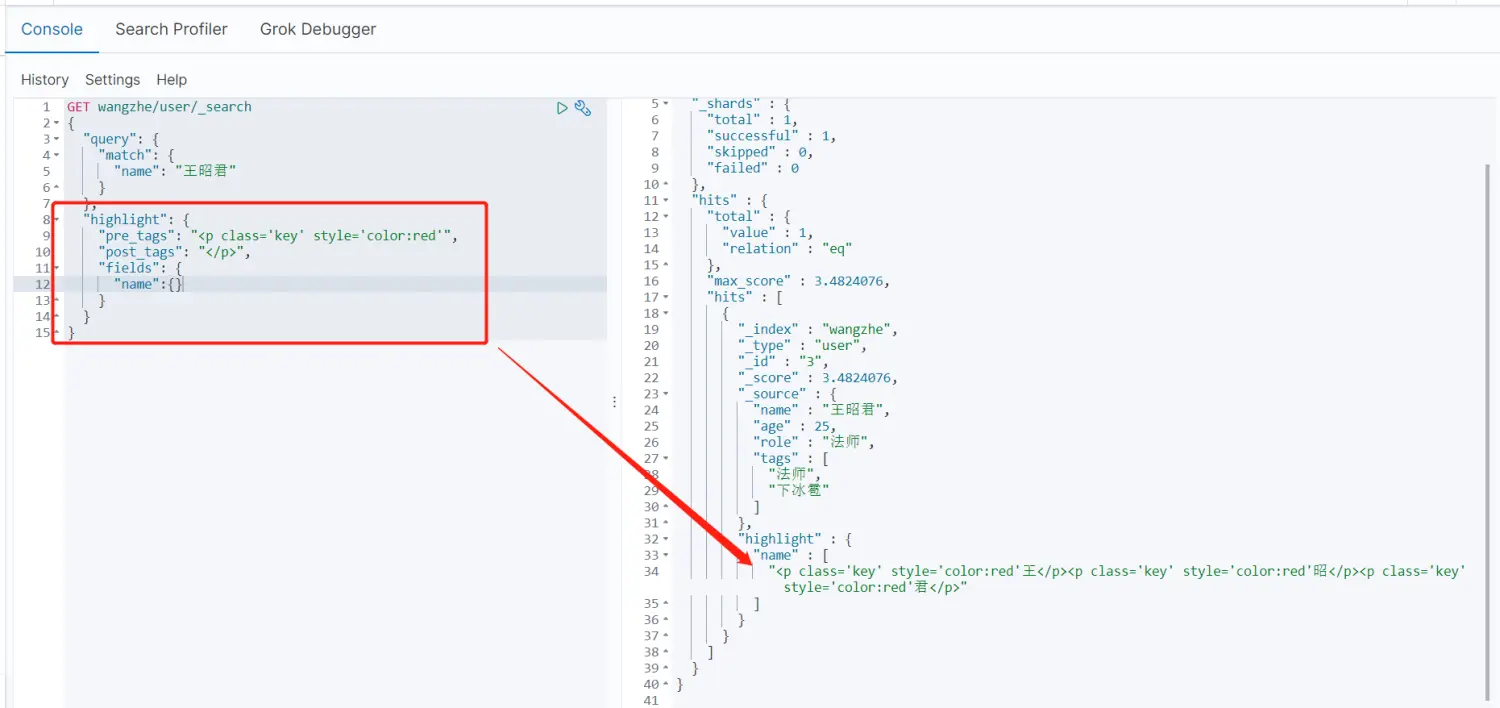
五、处理冲突
关系型数据库使用悲观并发控制,假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。而es使用乐观并发控制,不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
更多技术干货欢迎关注微信公众号“风雨同舟的AI笔记”~
【转载须知】:转载请注明原文出处及作者信息


