Kotlin中Flow
Kotlin Flow 深度解析:从原理到实战
一、Flow 核心概念体系
1. Flow 的本质与架构
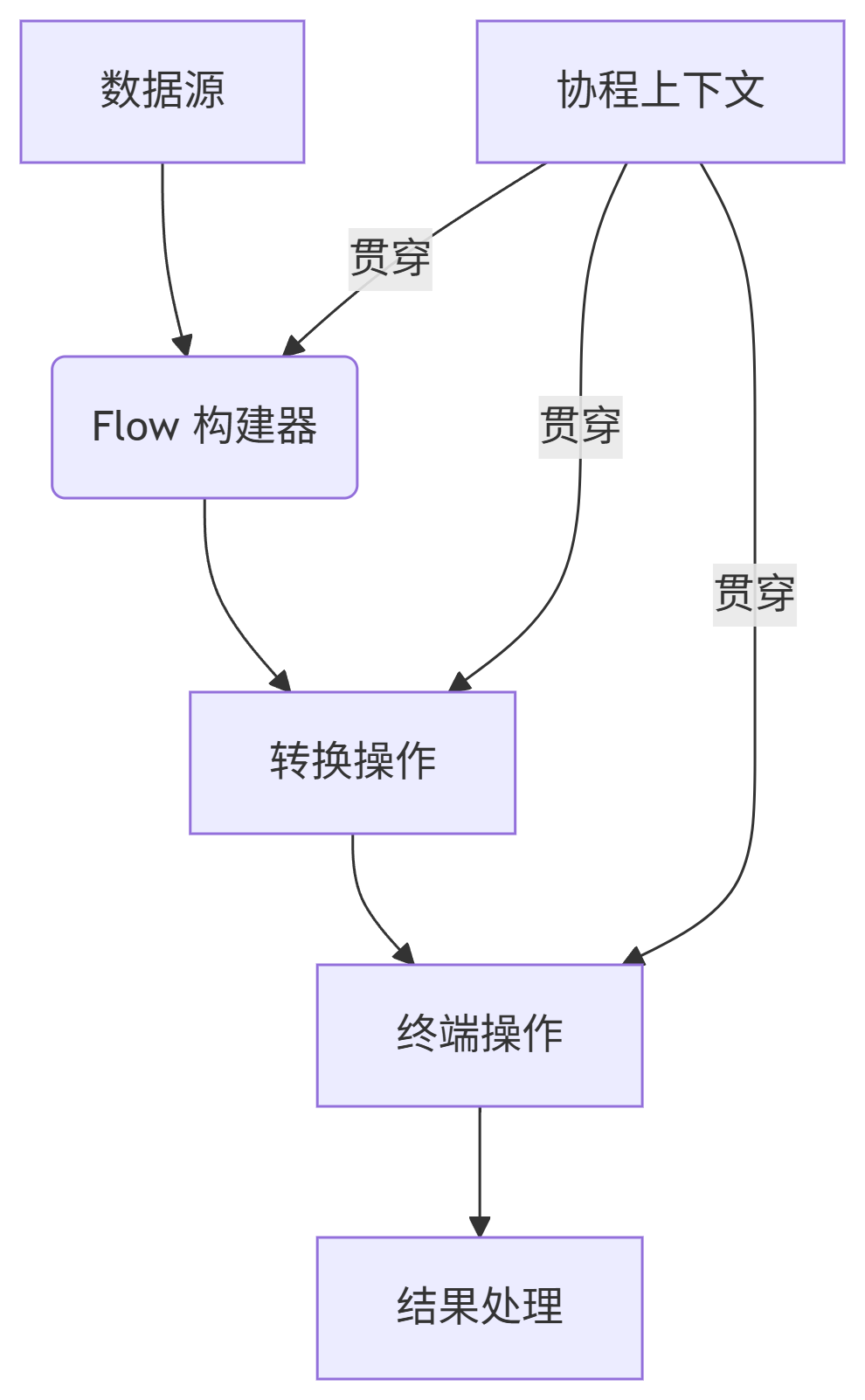
Flow 是 Kotlin 协程库中的异步数据流处理框架,核心特点:
-
响应式编程:基于观察者模式的数据处理
-
协程集成:无缝融入 Kotlin 协程生态
-
背压支持:内置生产者-消费者平衡机制
-
声明式API:链式调用实现复杂数据处理
2. 冷流 vs 热流深度解析
(1) 冷流(Cold Stream)
val coldFlow = flow { println(\"生产开始\") for (i in 1..3) { delay(100) emit(i) // 发射数据 }}// 第一次收集coldFlow.collect { println(\"收集1: $it\") }// 输出: // 生产开始// 收集1: 1// 收集1: 2// 收集1: 3// 第二次收集coldFlow.collect { println(\"收集2: $it\") }// 输出:// 生产开始// 收集2: 1// 收集2: 2// 收集2: 3核心特征:
-
按需启动:每次
collect()触发独立的数据生产 -
私有数据流:每个收集器获得完整独立的数据序列
-
零共享状态:无跨收集器的状态共享
-
资源友好:无收集器时无资源消耗
适用场景:
-
数据库查询结果流
-
网络API分页请求
-
文件读取操作
-
一次性计算任务
(2) 热流(Hot Stream)
// 创建热流val hotFlow = MutableSharedFlow()// 生产端CoroutineScope(Dispatchers.IO).launch { for (i in 1..5) { delay(200) hotFlow.emit(i) // 主动发射数据 println(\"发射: $i\") }}// 收集器1 (延迟启动)CoroutineScope(Dispatchers.Default).launch { delay(500) hotFlow.collect { println(\"收集器1: $it\") }}// 收集器2CoroutineScope(Dispatchers.Default).launch { hotFlow.collect { println(\"收集器2: $it\") }}/* 输出:发射: 1收集器2: 1发射: 2收集器2: 2发射: 3收集器2: 3收集器1: 3 // 收集器1只收到后续数据收集器2: 3发射: 4收集器1: 4收集器2: 4发射: 5收集器1: 5收集器2: 5*/核心特征:
-
主动生产:创建后立即开始数据发射
-
数据共享:多个收集器共享同一数据源
-
状态保持:独立于收集器生命周期
-
实时订阅:新收集器只能获取订阅后的数据
热流类型对比:
SharedFlowStateFlow3. 冷热流转换机制
// 冷流转热流val coldFlow = flow { for (i in 1..100) { delay(10) emit(i) }}val hotSharedFlow = coldFlow.shareIn( scope = viewModelScope, started = SharingStarted.WhileSubscribed(5000), replay = 3)val hotStateFlow = coldFlow.stateIn( scope = viewModelScope, started = SharingStarted.Lazily, initialValue = 0)启动策略:
-
WhileSubscribed(stopTimeout):无订阅者时自动停止,有订阅者时启动 -
Eagerly:立即启动,无视订阅状态 -
Lazily:首个订阅者出现后启动,永不停止
二、背压处理与高级操作
1. 背压问题本质
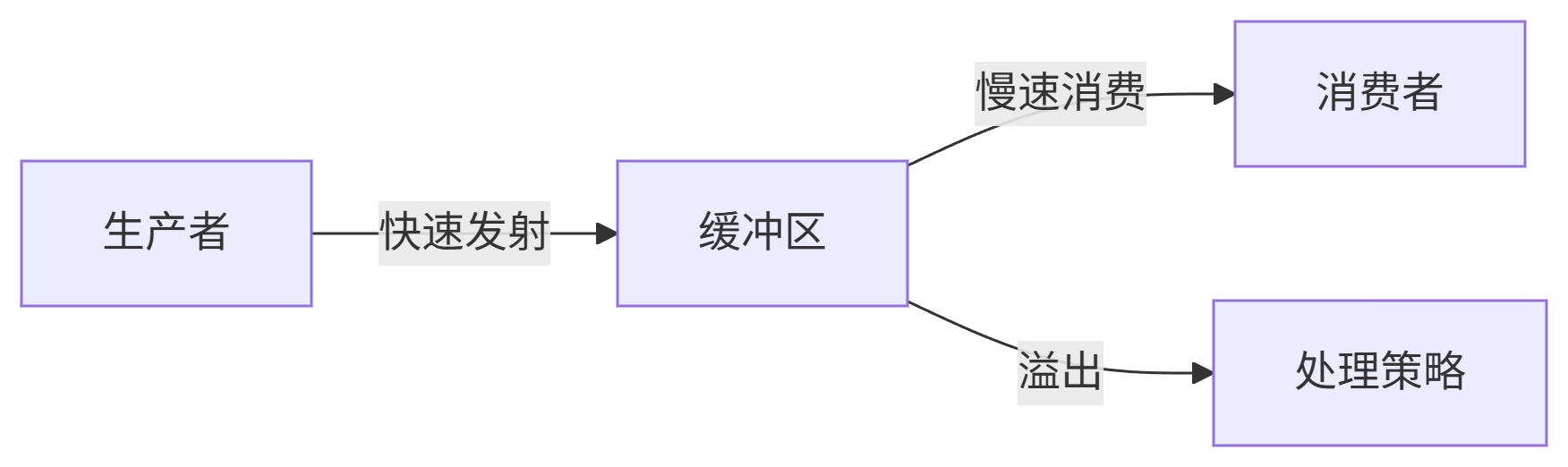
当 生产速率 > 消费速率 时:
-
内存积压导致 OOM
-
数据延迟影响实时性
-
资源浪费降低性能
2. 背压处理策略矩阵
buffer().buffer(32)conflate().conflate()collectLatest.collectLatest { }throttleLatest.throttleLatest(300ms)onBackpressureDroponBackpressureDrop()3. 背压处理流程图
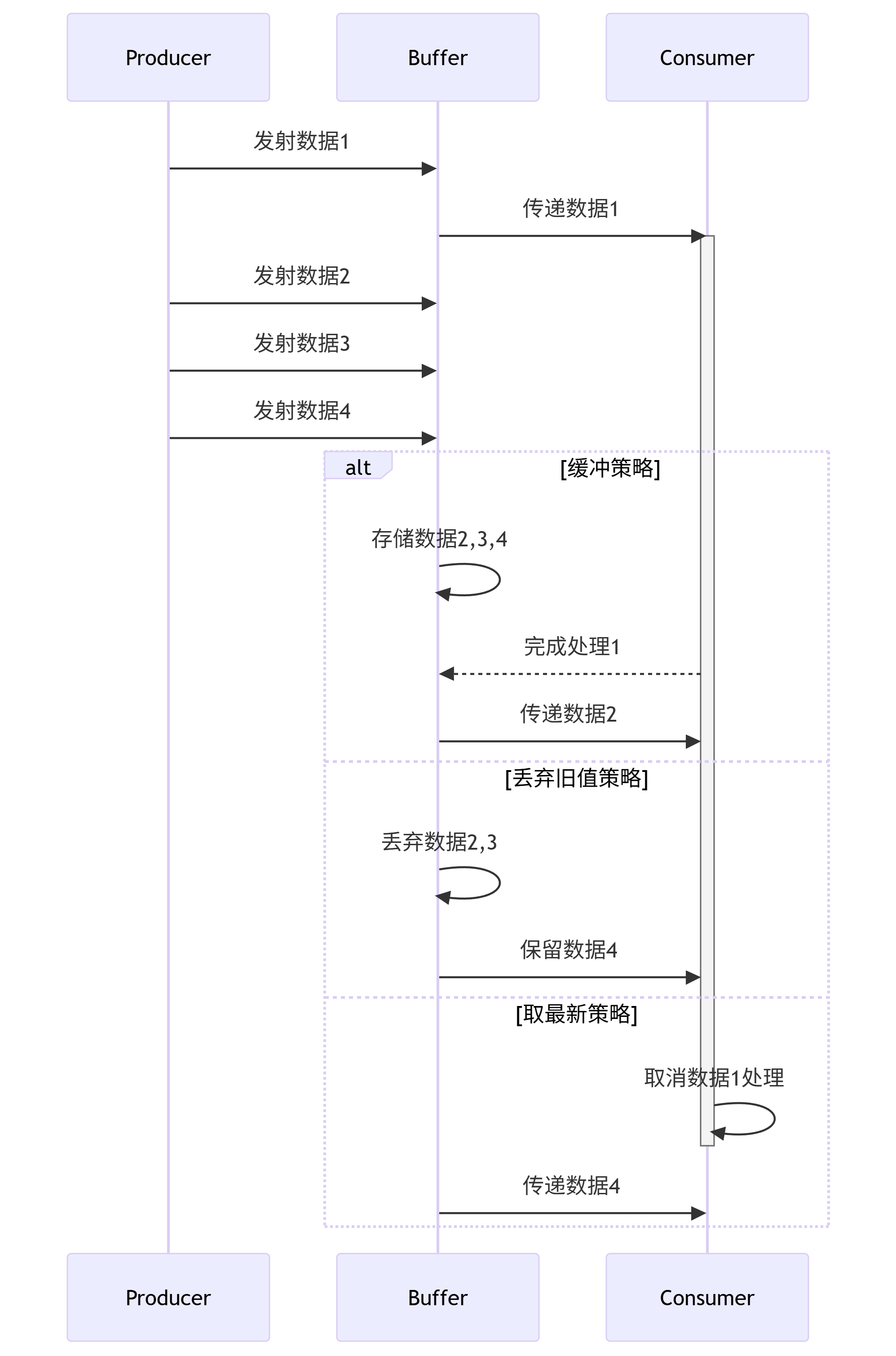
4. 高级操作技巧
(1) 复杂流合并
val flow1 = flowOf(\"A\", \"B\", \"C\")val flow2 = flowOf(1, 2, 3)// 组合操作flow1.zip(flow2) { letter, number -> \"$letter$number\" }.collect { println(it) } // A1, B2, C3flow1.combine(flow2) { letter, number -> \"$letter$number\" }.collect { println(it) } // A1, B1, B2, C2, C3(2) 异常处理链
flow { emit(1) throw RuntimeException(\"出错\")}.catch { e -> println(\"捕获异常: $e\") emit(-1) // 恢复发射}.onCompletion { cause -> cause?.let { println(\"流完成异常\") } ?: println(\"流正常完成\")}.collect { println(it) }(3) 上下文控制
flow { // 默认在收集器上下文 emit(computeValue()) }.flowOn(Dispatchers.Default) // 上游在IO线程.buffer() // 缓冲在通道.map { // 在下游上下文执行 it.toString() }.collect { // 在收集器上下文 showOnUI(it) }三、Flow 性能优化实战
1. 流执行模型优化
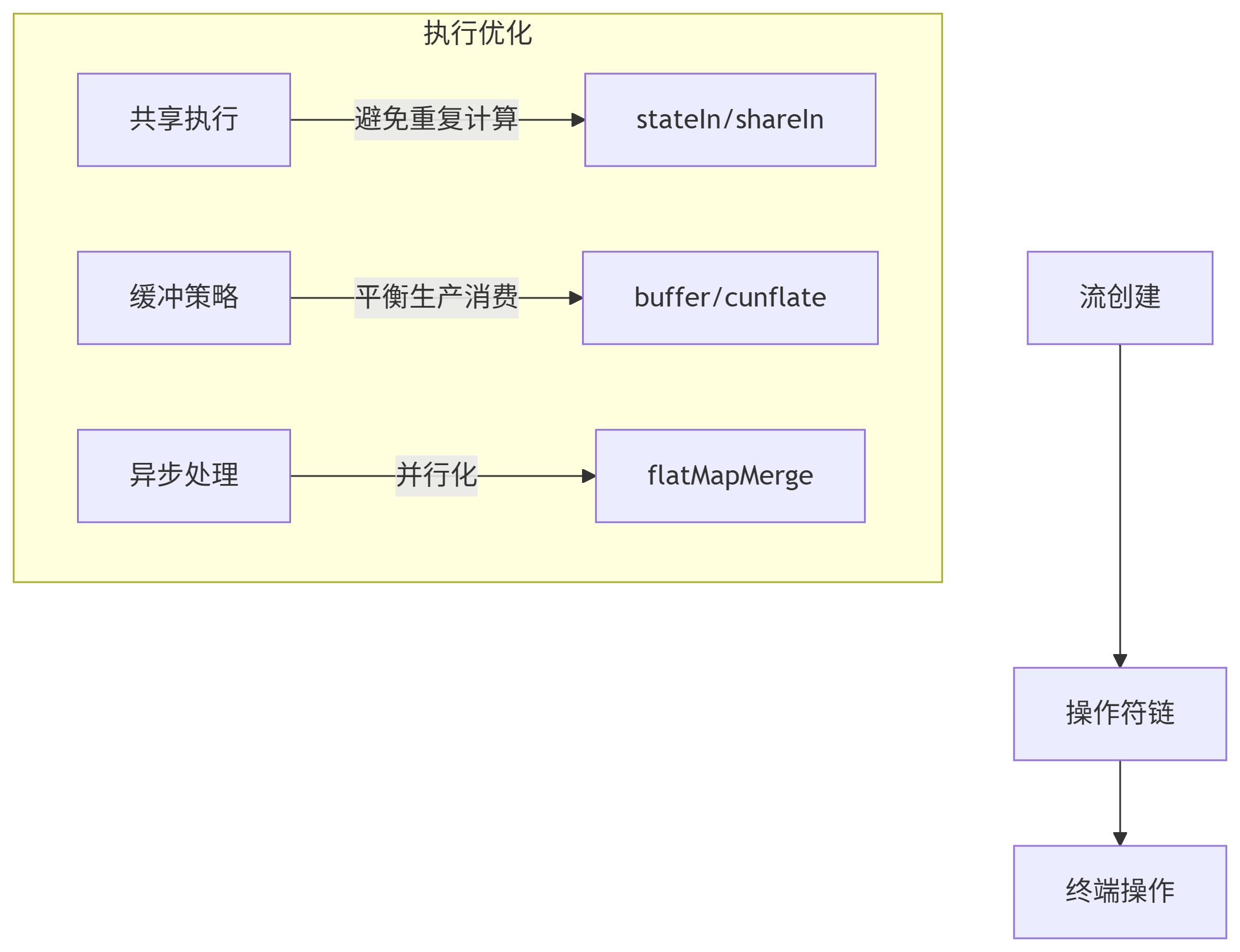
2. 性能优化技巧
shareIn/stateInbuffer + DROP_OLDESTconflate() + distinctUntilChangedcombine 替代 zipchunked + flatMapMerge3. Flow 与协程结构化并发
class MyViewModel : ViewModel() { private val _uiState = MutableStateFlow(Loading) val uiState: StateFlow = _uiState.asStateFlow() init { viewModelScope.launch { dataRepository.fetchData() .map { data -> processData(data) } .catch { e -> _uiState.value = Error(e) } .collect { result -> _uiState.value = Success(result) } } } // 取消时自动取消流收集}四、Flow 在 Android 的典型应用
1. 架构模式集成

2. 实战代码模板
// 数据层class UserRepository { fun getUsers(): Flow<List> = flow { // 先加载缓存 emit(localDataSource.getCachedUsers()) // 获取网络数据 val remoteUsers = remoteDataSource.fetchUsers() // 更新缓存 localDataSource.saveUsers(remoteUsers) // 发射最终数据 emit(remoteUsers) }.catch { e -> // 错误处理 if (e is IOException) { emit(localDataSource.getCachedUsers()) } else { throw e } }}// ViewModel 层class UserViewModel : ViewModel() { private val _users = MutableStateFlow<List>(emptyList()) val users: StateFlow<List> = _users.asStateFlow() init { viewModelScope.launch { userRepository.getUsers() .flowOn(Dispatchers.IO) .distinctUntilChanged() .collect { _users.value = it } } }}// UI 层class UserFragment : Fragment() { override fun onViewCreated(view: View, savedInstanceState: Bundle?) { viewLifecycleOwner.lifecycleScope.launch { repeatOnLifecycle(Lifecycle.State.STARTED) { viewModel.users.collect { users -> adapter.submitList(users) } } } }}五、常见问题总结
Q:Flow 与 LiveData/RxJava 有何本质区别?
A:
-
协程集成深度:
-
Flow 是 Kotlin 协程原生组件,支持结构化并发
-
LiveData 是 Android 生命周期感知组件
-
RxJava 是独立响应式扩展库
-
-
背压处理能力:
-
Flow 内置多种背压策略(
buffer,conflate,collectLatest) -
LiveData 无背压概念(仅最新值)
-
RxJava 需手动配置背压策略
-
-
流控制能力:
-
LiveData 仅支持简单值观察
-
RxJava 操作符更丰富但学习曲线陡峭
-
-
Android 集成:
-
Flow 需要
lifecycleScope实现生命周期感知 -
LiveData 自动处理生命周期
-
RxJava 需额外绑定生命周期
-
Q:StateFlow 和 SharedFlow 如何选择?
A:
StateFlowSharedFlow使用公式:
-
状态管理 =
StateFlow -
事件通知 =
SharedFlow(replay=0) -
带历史事件 =
SharedFlow(replay=N)
Q:如何处理 Flow 的背压问题?
A:
-
缓冲策略(生产消费速度差稳定):
.buffer(capacity = 64, onBufferOverflow = BufferOverflow.SUSPEND) -
节流策略(UI 更新场景):
.conflate() // 或 .throttleLatest(300ms) -
优先最新(实时数据处理):
.collectLatest { /* 取消前次处理 */ } -
动态控制(复杂场景):
.onBackpressureDrop { /* 自定义丢弃逻辑 */ }.onBackpressureBuffer( /* 自定义缓冲 */ )
性能考量:
-
缓冲区大小需平衡内存与吞吐
-
conflate可能导致数据丢失 -
collectLatest可能增加 CPU 负载
Q:Flow 如何保证线程安全?
A:
-
明确上下文:
.flowOn(Dispatchers.IO) // 指定上游上下文 -
状态流封装:
private val _state = MutableStateFlow(0)val state: StateFlow = _state.asStateFlow() // 对外暴露不可变 -
安全更新:
// 原子更新_state.update { current -> current + 1 } -
并发控制:
mutex.withLock { _state.value = computeNewState()}
总结
Q:请全面解释 Kotlin Flow 的核心机制和使用实践
A:
-
Flow 本质
Kotlin 协程的异步数据流组件,提供声明式 API 处理序列化异步数据,基于生产-消费模型构建。 -
冷热流区别
-
冷流:按需启动(collect 触发),数据独立(如 flow{}),适合一次性操作
-
热流:主动发射(创建即启动),数据共享(StateFlow/SharedFlow),适合状态管理
-
-
背压处理
当生产 > 消费时:-
缓冲:
.buffer()临时存储 -
取新:
.conflate()或.collectLatest -
节流:
.throttleLatest()控制频率 -
策略选择需平衡实时性/完整性
-
-
Android 集成
-
分层架构:Repository 返回 Flow,ViewModel 转 StateFlow,UI 层收集
-
生命周期:
repeatOnLifecycle(STARTED)避免泄露 -
性能优化:
shareIn复用冷流,distinctUntilChanged减少无效更新
-
-
线程安全
-
用
flowOn控制上下文 -
MutableStateFlow 更新用原子操作
-
复杂操作加 Mutex 锁
-
-
对比 RxJava
-
优势:协程原生支持、结构化并发、更简洁 API
-
劣势:缺少部分高级操作符(需配合协程实现)
-
使用准则:
-
UI 状态管理用
StateFlow -
单次事件用
SharedFlow(replay=0) -
数据层返回冷流
-
关注背压策略和线程控制


