全实验室最perfect计算机视觉深度学习路线解析୧₍˄·͈༝·͈˄₎୨
目录
第一章:学习规划
第二章:CNN与transformer
2.1 CNN:图像处理的“局部专家”
2.2 Transformer:基于“注意力”的全局建模者
CNN vs Transformer:核心对比总结
2.3 当前趋势与融合
2.4 总结
第三章:openmmlab
3.1 核心架构与模块化设计
3.2 技术优势与创新
3.3 学习与实践路径
3.4 适用场景总结
第四章:模型项目
4.1 OpenPose:人体姿态估计标杆
4.2 SlowFast:视频动作识别双流架构
4.3 YOLOv8:实时目标检测新王者
4.4 DeepSORT:多目标跟踪鲁棒引擎
4.5 U-Net:医学图像分割黄金标准
4.6 待续
4.7 总结
第五章:多模态BEV
5.1 BEV的核心价值:为何需要统一视角?
5.2 关键技术模块解析
5.3 前沿创新:MoE与动态路由
5.4 实战挑战与优化方向
5.5 学习建议
前言:当你看完本up主的深度学习环境搭建超级无敌全面de教程ദ്ദി˶•̀֊<)✧-CSDN博客与智能车视觉训练数据集de制作_智能车竞赛拍摄标注数据集怎么做-CSDN博客文章并点赞+关注后继续看这篇文章,会更有收获~~
第一章:学习规划
本up主也是通过接触实验室de学长与导师(若有若无)的指导下进行学习,当时是学深度学习搞智能车的视觉,最终走上一条“不归路”。现在作为学长,马上要迎接学弟学妹们。接下来是个人对学习历程的归纳整理与总结,希望能让热爱学习,竞赛,科研等盆友们受益:
我个人是从python基础开始学习,然后学习各类调用库eg.opencv,numpy......在视觉方面要针对opencv做一些图像预处理,数据增强等基操。以及一些传统机器学习的处理手法。然后深度学习上学习主流框架pytorch就足矣(整个环境配置和版本适配一定要处理好,否则后期麻烦大,具体见up主其他文章,pytorch就跟着学长推荐的B站up主:小土堆。这里是笔记链接https://zhuanlan.zhihu.com/p/634866046)好!接着你看完本up主的数据集制作,你的学习生涯算是开始啦(嘿嘿)
从第二章:CNN与transformer开始深挖底层原理,从第三章:openmmlab开始系统学习计算机视觉开源工具框架,从第四章模型项目开始编写计算机视觉领域六大核心主流模型,从第五章多模态BEV开始踏入一条计算机视觉de不归旅程......
而我——陌生Boy将带你步入元婴期!!
第二章:CNN与transformer
2.1 CNN:图像处理的“局部专家”
-
核心思想:模仿人眼视觉皮层的工作原理。
-
关键结构与工作原理:
-
卷积层:
-
操作: 小卷积核在输入(图像或上一层的特征图)上滑动,进行点积运算(核的权重乘以对应区域的像素值再求和)。
-
作用: 提取局部特征(如边缘、角点、特定纹理)。不同的核学习提取不同的特征。
-
核心特性:
-
局部连接: 每个神经元只连接输入的一小块区域(感受野),大大减少参数。
-
参数共享: 同一个卷积核在整个输入上滑动使用相同的权重,进一步减少参数,赋予模型平移不变性(物体在图像中平移后,其特征响应也应平移)。
-
空间层次性: 浅层提取简单特征(边缘),深层组合简单特征形成复杂特征(物体部件、整个物体)。
-
-
-
池化层:
-
操作: 对局部区域(如2x2)进行下采样(Downsampling)。常用最大池化(取区域内最大值)或平均池化(取区域内平均值)。
-
作用: 降低特征图的空间尺寸(宽高),减少计算量和参数;增加感受野;提供一定的平移鲁棒性(物体在池化区域内小幅度移动不影响输出)。
-
-
激活函数:
-
通常在每个卷积层后添加(如ReLU)。引入非线性,使网络能学习复杂的模式。
-
-
全连接层:
-
在网络的末端(卷积层之后),将特征图展平成一维向量,进行最终的分类或回归预测。现代CNN架构中,全连接层的作用逐渐减弱或被替代(如全局平均池化)。
-
-
-
优点:
-
强大的局部特征提取能力: 对图像的局部结构(如纹理、边缘)捕捉能力极强。
-
参数效率高: 局部连接和参数共享极大减少了模型参数量。
-
平移不变性: 天然适合图像,物体位置变化不影响识别。
-
计算高效: 卷积操作高度并行化,易于在GPU上加速。
-
经过长期验证: 在CV领域取得巨大成功(AlexNet, VGG, ResNet等),是经典且成熟的技术。
-
-
缺点:
-
难以建模长距离依赖: 卷积核的感受野有限(尤其在浅层),模型需要堆叠很多层才能获取全局信息。对于需要理解图像中相距很远的元素之间关系(如“猫坐在沙发左边,狗在沙发右边”)的任务,效率较低。
-
空间位置信息可能丢失: 池化操作会损失精确的位置信息。虽然卷积有平移不变性,但有时精确位置也很重要(如姿态估计)。
-
归纳偏置强: 其结构设计(局部性、平移不变性)是基于对图像数据的先验知识(归纳偏置)。这既是优势(数据效率高),也可能成为限制(如果任务不符合这些假设)。
-
-
典型应用: 图像分类、目标检测(如Faster R-CNN, YOLO)、图像分割(如U-Net)、人脸识别、图像风格迁移等。
2.2 Transformer:基于“注意力”的全局建模者
-
核心思想:利用“自注意力机制”动态计算序列中所有元素之间的关联度(权重)。
-
起源于自然语言处理(NLP),用于处理单词序列。
-
应用到CV(如Vision Transformer - ViT)时,需要先将图像处理成“序列”。
-
-
关键结构与工作原理(以ViT为例):
-
图像分块:
-
将输入图像分割成固定大小(如16x16)的非重叠小块(Patches)。
-
每个块展平成一个向量。
-
-
线性嵌入:
-
将每个块向量通过一个线性层(全连接层)映射到模型所需的特征维度(
D)。 -
此时,输入图像变成了一个“序列”:
[块1向量, 块2向量, ..., 块N向量]。
-
-
添加位置编码:
-
关键! 因为Transformer本身对输入顺序不敏感(排列不变性),但图像块的空间位置信息至关重要。
-
为每个块向量添加一个位置编码向量(通常是可学习的或使用正弦函数)。这告诉模型每个块在原图中的位置。
-
-
Transformer编码器: (ViT的核心)
-
由多个相同的层堆叠而成,每层包含两个核心模块:
-
多头自注意力:
-
核心思想: 让每个块(查询 - Query)去“关注”序列中所有其他块(键 - Key),根据相关性(Query和Key的点积)计算权重(Value的加权和)。
-
过程:
-
对每个输入向量(包含块信息+位置信息)分别计算其
Query,Key,Value向量(通过三个不同的线性层)。 -
计算
Query和所有Key的点积,缩放(防止梯度爆炸),应用Softmax得到每个Key(即每个其他块)相对于当前Query(当前块)的注意力权重(0-1之间,表示“关注程度”)。 -
用这些权重对对应的
Value向量进行加权求和,得到当前Query块的新表示。这个新表示融合了它认为最相关的其他块的信息。
-
-
“多头”: 并行进行多次上述自注意力操作(从不同子空间学习信息),然后将结果拼接起来再映射回原维度。
-
效果: 一步到位地建立任意两个图像块(无论远近)之间的依赖关系! 全局信息建模能力强。
-
-
前馈神经网络:
-
一个简单的多层感知机(通常包含非线性激活函数)。
-
作用:对自注意力层的输出进行非线性变换,增强模型的表达能力。
-
-
-
每层通常还包含层归一化和残差连接(有助于训练深度网络)。
-
-
分类头:
-
通常在序列开头添加一个特殊的
[CLS]标记(Class Token),其最终输出向量用于图像分类任务(通过一个MLP)。 -
也可以使用其他块的特征做其他任务(如分割、检测)。
-
-
-
优点:
-
强大的全局建模能力: 自注意力机制允许模型直接计算图像中任意两个区域的关系,无论距离多远。非常适合理解图像的整体结构、场景上下文。
-
长距离依赖建模高效: 不需要像CNN那样堆叠很多层来扩大感受野。
-
可并行性高: 自注意力计算本身可以高度并行化(尽管序列长度大时计算量和内存开销大)。
-
通用架构: 在NLP和CV等多个领域都取得了顶尖效果,结构相对统一。
-
更少的空间层次性假设: 对图像数据的先验假设(归纳偏置)比CNN弱,理论上更灵活,可能发现CNN难以捕捉的模式。
-
-
缺点:
-
计算和内存开销大: 自注意力计算复杂度与序列长度的平方(
O(N²))成正比。图像分块数量N很大时(尤其是高分辨率图像),计算和内存需求急剧增加。 -
数据饥渴: 相比CNN,Transformer通常需要大量的训练数据才能充分发挥其潜力,避免过拟合(因为其归纳偏置较弱)。在中小型数据集上,CNN往往表现更好。
-
位置编码的挑战: 如何有效地编码二维空间位置信息是一个持续研究的课题。位置编码的好坏对性能影响很大。
-
解释性相对弱: 注意力权重图虽然能提供一些洞见,但整体模型行为可能比CNN更难直观理解。
-
-
典型应用: 图像分类(ViT, DeiT)、目标检测(DETR, Swin Transformer)、图像分割(SETR, SegFormer)、图像生成(DALL-E 2, Imagen)、视频理解、多模态任务(CLIP)等。在需要强全局理解的任务上表现突出。
CNN vs Transformer:核心对比总结
2.3 当前趋势与融合
-
混合架构: 结合CNN和Transformer的优势是最热门的方向之一。常见模式:
-
CNN主干 + Transformer头: 用CNN提取低级到中级特征(高效),再用Transformer建模高级特征间的长距离依赖(如DetectoRS, BoTNet)。
-
Transformer主干 + CNN技巧: 在Transformer架构中融入卷积的思想(如局部窗口注意力、卷积位置编码、卷积下采样)来提高效率和利用局部性(如Swin Transformer, ConvNeXt)。
-
-
ViT的改进: 持续研究解决ViT的计算效率(如分层的Swin T, PVT)和数据效率(如知识蒸馏DeiT, 数据增强)问题。
-
主导地位: Transformer及其变体在越来越多的CV基准任务(尤其是需要强全局理解的任务)上达到了SOTA(State-of-the-art),并推动了多模态学习的发展。但CNN(尤其是高效轻量级CNN)在资源受限、中小型数据集或实时应用中仍有不可替代的地位。
2.4 总结
-
CNN 是CV的基石,它像一位经验丰富的“局部侦探”,擅长从图像的小区域中高效地提取关键线索(特征),尤其适合处理纹理、边缘等局部模式。它的效率和成熟度使其在众多实际应用中仍是首选。
-
Transformer 是CV的新锐力量,它更像一位“全局战略家”,利用自注意力机制瞬间把握图像中所有元素之间的复杂关系,无论它们相隔多远。它在需要理解整体场景和长距离依赖的任务上展现出强大威力,尤其在数据充足的情况下。
-
未来属于融合: 两者并非替代关系,而是互补。将CNN的局部特征提取效率与Transformer的全局建模能力结合起来的混合模型,是当前最活跃、最有前景的研究方向,推动着计算机视觉不断突破边界。
第三章:openmmlab
OpenMMLab 是由香港中文大学多媒体实验室(MMLab)与商汤科技联合发起的开源计算机视觉算法体系,始于 2018 年。它通过模块化设计和统一框架,覆盖了图像分类、目标检测、分割、姿态估计等 30+ 视觉任务,集成了 300+ 算法和 2400+ 预训练模型,成为学术研究与工业落地的核心工具库。
3.1 核心架构与模块化设计
-
统一底层框架
-
MMCV/MMEngine:提供基础算子、训练流程管理、数据集加载等通用组件,支持所有上层算法库的高效运行。
-
模块化抽象:将算法拆解为数据集、模型、训练策略、推理接口四大组件,用户可通过配置文件自由组合(如更换主干网络为 ResNet 或 Swin Transformer)。
-
-
算法库全景
各子库专注特定任务,接口统一且可协同使用:算法库 核心任务 代表模型 应用场景 MMDetection 目标检测/实例分割 Faster R-CNN, YOLO, Mask R-CNN 工业质检、自动驾驶 MMSegmentation 语义分割 PSPNet, DeepLabV3+ 遥感图像、医疗影像 MMPose 2D/3D 姿态估计 HRNet, ViTPose 运动分析、人机交互 MMOCR 文字检测/识别 DBNet, CRNN 文档数字化、车牌识别 MMRotate 旋转目标检测 RoI Transformer, ReDet 遥感、航拍图像 MMDetection3D 3D 目标检测 PointPillars, MVXNet 机器人导航、AR/VR8 其他重要库如 MMAction2(视频分析)、MMEditing(图像生成/修复)、MMDeploy(模型部署)共同构成完整生态。
3.2 技术优势与创新
-
高性能与可复现性
-
所有算法复现论文指标,提供标准评测脚本(如 COCO mAP、Cityscapes mIoU)。
-
底层 CUDA 算子优化(如
RotatedFeatureAlign支持旋转框检测),训练速度显著提升。
-
-
灵活的任务扩展
-
多模态支持:如 MMPretrain 统一管理图像-文本预训练模型(CLIP、ALIGN),支持跨模态检索。
-
长尾场景适配:MMFewShot 提供小样本学习方案,解决数据稀缺问题。
-
-
工业级部署
MMDeploy 将模型转换为 ONNX/TensorRT 格式,实现端侧低延迟推理。
3.3 学习与实践路径
-
快速入门
-
安装:通过
openmim一键管理依赖pip install openmimmim install mmdet # 安装目标检测库
-
推理示例(5 行代码调用预训练模型):
from mmdet.apis import init_detector, inference_detectormodel = init_detector(\"configs/faster_rcnn.py\", \"checkpoints/faster_rcnn.pth\")results = inference_detector(model, \"image.jpg\")
-
-
定制化开发流程
-
数据集适配:转换标注为 COCO/PASCAL VOC 格式,修改配置文件路径。
-
模型调整:配置文件(如
configs/yolo/yolov3.py)定义网络结构、训练超参,无需修改代码。 -
训练与验证:
mim train mmdet yolov3.py --work-dir logs/mim test mmdet yolov3.py --checkpoint yolov3.pth --metrics
-
-
进阶资源
-
官方文档:OpenMMLab 官网 提供各子库详细教程。
-
实战社区:知乎专栏《OpenMMLab 教程》详解源码结构与调试技巧。
-
3.4 适用场景总结
-
学术研究:快速复现 SOTA 算法(如 ViT 分割),论文代码均开源。
-
工业落地:MMDeploy 支持 NVIDIA Jetson/华为昇腾等硬件部署。
-
竞赛/二次开发:基于预训练模型微调,如 Kaggle 卫星图像检测。
提示:初学者建议从 MMDetection 入手掌握配置范式,再扩展至 3D(MMDetection3D)或生成式任务(MMagic)。遇到问题可提交 GitHub Issue,社区响应迅速。
OpenMMLab 通过开源协作推动视觉技术民主化——无论验证新算法还是构建医疗影像分析系统,它都以模块化设计平衡灵活性与性能,成为 CV 领域的“深度学习工厂”
第四章:模型项目
4.1 OpenPose:人体姿态估计标杆
核心原理
-
多阶段关键点检测
Stage 1:使用VGG主干网络提取特征,预测人体部位置信图(Part Confidence Maps)
Stage 2:通过部分亲和域(Part Affinity Fields, PAFs)建模关节点之间的连接关系
Stage 3:匈牙利算法匹配PAFs生成完整人体骨架
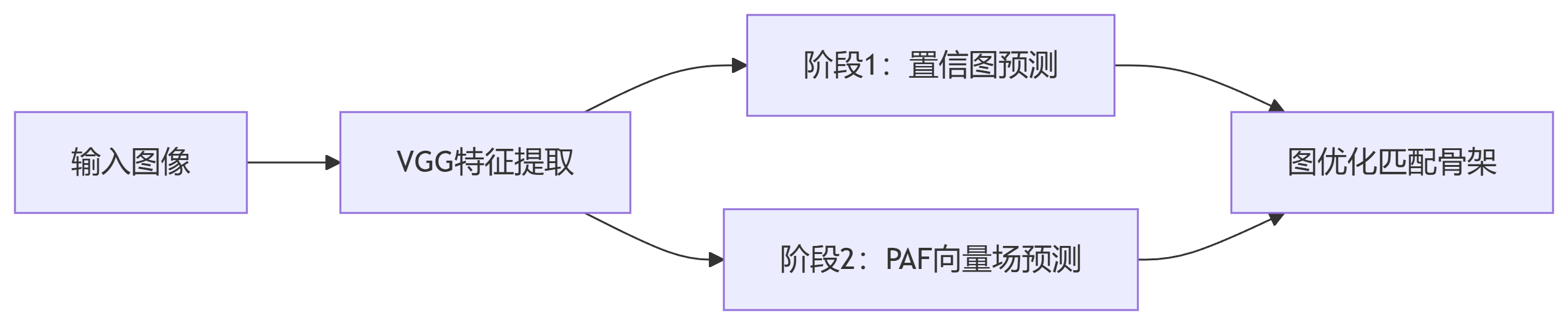
关键特性
-
实时多人姿态估计:最高支持20人同时检测(1080p视频 @ 22 FPS)
-
拓扑结构鲁棒性:PAFs机制有效解决遮挡场景下的关节点错配
-
扩展能力:支持手部(21点)、面部(70点)、足部关键点检测
4.2 SlowFast:视频动作识别双流架构
核心创新:时空分离建模
路径
采样率
通道数
作用
Slow路径
低帧率(1/16)
高(~2048)
捕捉语义信息(场景/物体)
Fast路径
高帧率(1/4)
低(~256)
捕捉运动信息(瞬时变化)
工作流程
-
Slow分支:输入16帧低采样片段(时间维度压缩)
-
Fast分支:输入64帧高采样片段(空间维度压缩)
-
横向连接:通过3D卷积融合双路径特征(e.g. TDN模块)
性能优势
-
Kinetics-400准确率:79.0%(比单流C3D高12%)
-
计算效率:Fast路径通道数仅为Slow的1/8,总FLOPs仅增加20%
4.3 YOLOv8:实时目标检测新王者
架构升级亮点
-
Backbone:CSPDarknet53 → C2f模块(跨阶段部分融合+多分支残差)
-
Neck:PAN-FPN → 改进BiFPN(加权特征融合)
-
Head:解耦头设计(分类/回归分离) + Anchor-Free机制
关键性能指标
模型
mAP@50
速度(FPS)
参数量(M)
YOLOv8n
37.3
435
3.2
YOLOv8x
53.9
102
68.2
对比v5x
*+6.2*
*+28%*
*-15%*
开发者工具革新
-
命令行自动化:
yolo train data=coco.yaml model=yolov8s.pt epochs=100 -
部署优化:支持TensorRT/OpenVINO/CoreML一键导出
-
功能扩展:内置实例分割/姿态估计/目标跟踪任务接口
4.4 DeepSORT:多目标跟踪鲁棒引擎
核心组件
模块
算法
作用
检测器
YOLOv8(默认)
提供目标检测框
外观特征提取
WideResNet-48
生成128维ReID嵌入向量
运动模型
卡尔曼滤波
预测目标位置/速度
数据关联
匈牙利算法 + 级联匹配
解决遮挡导致的ID切换
抗遮挡策略
-
轨迹保留机制:丢失目标在30帧内重新出现仍维持原ID
-
置信度衰减:未匹配检测框需连续3帧确认才生成新轨迹
4.5 U-Net:医学图像分割黄金标准
对称编码器-解码器结构
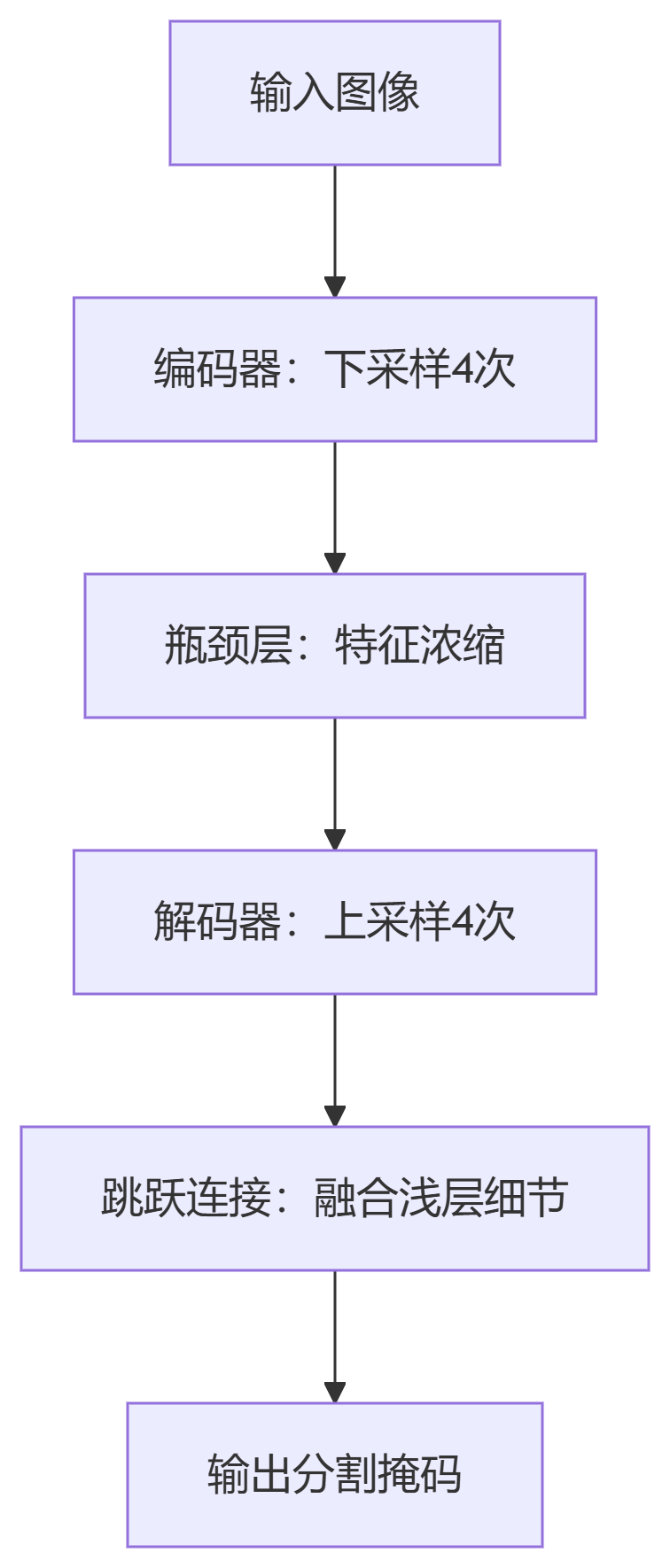
核心创新
-
跳跃连接:融合深层语义信息(编码器)与浅层空间细节(解码器)
-
重叠拼接策略:解决图像边界分割断裂问题
-
数据增强:弹性变形合成训练数据,适应小样本场景
医学领域统治力
-
ISBI细胞追踪挑战赛:IoU 92% (2015年冠军)
-
BraTS脑瘤分割:Dice系数 0.87(2020年SOTA)
变体演进
密集跳跃连接
小目标精细分割
3D卷积+残差块
前列腺MRI分割
门控注意力机制
胰腺CT病灶定位
4.6 待续
4.7 总结
掌握这六大模型,我们已覆盖计算机视觉检测-分割-跟踪-姿态-时序分析核心能力链。接下来则需通过OpenMMLab等开源框架实战训练,快速打通技术落地闭环!
第五章:多模态BEV
多模态BEV(Bird\'s Eye View)感知是自动驾驶与机器人领域的核心技术,它将多传感器(如相机、激光雷达、毫米波雷达)的数据统一到鸟瞰视角空间,实现高效融合与多任务感知。以下从核心概念、关键技术、前沿进展及应用挑战四方面展开详解:
5.1 BEV的核心价值:为何需要统一视角?
-
解决传统融合的缺陷
-
点级融合(Point-level):将激光雷达点投影到图像上采样特征,但仅利用约5%的图像信息,且依赖精确外参(易受颠簸影响)。
-
特征级融合(Feature-level):通过Query机制跨模态关联特征,但仍存在几何失真和遮挡敏感问题。
-
BEV融合优势:在俯视视角下统一多模态特征,保留几何结构(激光雷达)与语义密度(相机),避免投影偏差,支持更灵活的任务扩展。
-
-
任务兼容性强
BEV空间天然适配3D检测、语义分割、轨迹预测等任务,同一特征图可同时输出车道线、障碍物、可行驶区域等信息。
5.2 关键技术模块解析
1. 视角转换:2D/3D数据如何统一到BEV?
-
图像→BEV:
-
深度估计:预测每个像素的离散深度分布(如41个深度区间),沿相机射线生成3D特征点云。
-
高效池化:通过预计算网格索引(减少17ms→4ms)和并行GPU聚合(减少500ms→2ms),解决传统方法计算瓶颈。
-
-
激光雷达→BEV:
点云通过体素化(如VoxelNet)或柱状编码(PointPillars)生成BEV栅格特征,保留几何精度。
2. 时序融合:如何利用历史帧信息?
-
运动补偿:利用轮速计(Odometry)将历史BEV特征对齐当前帧,减少目标抖动。
-
融合策略:
-
等时间间隔(如10帧):部署简单,但对齐精度受帧率波动影响。
-
等空间间隔(如移动1米取帧):更符合运动连续性,但计算复杂。
-
-
Recurrent模式:板端部署采用循环网络缓存特征,仅增加1ms延迟,显著提升小目标检测(如50米处车道线)。
3. 多模态融合:主流方案对比
5.3 前沿创新:MoE与动态路由
混合专家系统(Mixture of Experts, MoE)
-
动机:多任务(检测+分割)易冲突,需动态分配计算资源。
-
实现方式:
-
RM²oE:路由器根据输入数据选择专家(如检测专家、分割专家),加权融合输出。
-
HM²oE:固定专家分工(如Det-FFN处理检测),简化计算但灵活性低。
-
-
效果:在传感器部分故障时,MoE通过跨模态注意力补偿信息缺失,NDS提升4.2%。
通用融合框架FUTR3D
-
模态无关采样器(MAFS):Object Query生成3D参考点,跨模态采集特征(相机投影/激光雷达最近邻/雷达聚合)。
-
低成本方案:4线激光雷达+相机融合效果超越32线激光雷达(56.8 vs 56.6 mAP),推动降本落地。
5.4 实战挑战与优化方向
-
部署效率
-
地平线采用四平面融合替代Transformer方案:BEV分辨率0.4m时,Transformer延迟过高(>30ms),而四平面方案达9.6ms。
-
图像分辨率是关键:2M→8M相机使50米处特征精度从2米提升至0.6米,减少目标分裂。
-
-
真值构建
-
动态障碍物需融合Lidar点云、高精地图、纯视觉建图,标注规则需算法工程师参与制定(如车道线颜色、车位关键点)。
-
-
极端场景应对
-
仙途智能针对环卫场景优化:
-
视觉为主+激光辅助检测低矮障碍(如垃圾袋)。
-
Occupancy预测过滤扬尘/水雾,误检率降低32.6%
-
-
5.5 学习建议
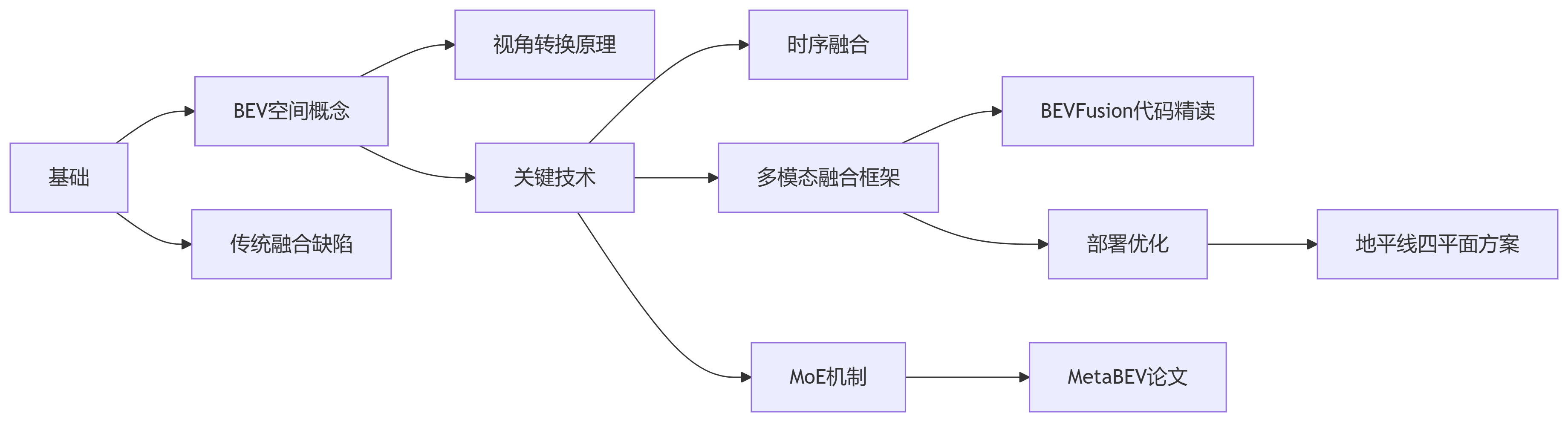
推荐学习路径:
-
入门:从BEVFusion源码入手(GitHub开源),理解相机/LiDAR独立支路设计。
-
进阶:研读MetaBEV的跨模态注意力,掌握传感器故障补偿机制。
-
实战:复现SimpleBEV深度估计模块,体会激光雷达填充稀疏深度的价值。
多模态BEV正推动感知系统从“多传感器依赖”转向“任务为中心”的统一架构,其核心在于平衡几何精度、语义密度与计算效率。随着MoE等动态路由技术的成熟,BEV有望成为自动驾驶的“感知操作系统”,实现真正可扩展的场景泛化。


