字节开源地表最强GUI Agent:UI-TARS
0. 引言
闲云潭影日悠悠,物换星移几度秋。

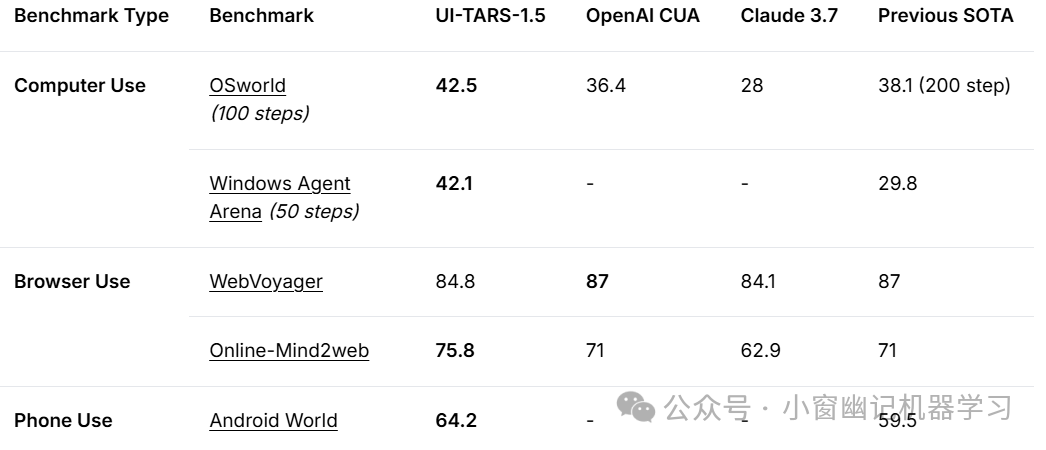
小伙伴们好,我是微信公众号\"小窗幽记机器学习\"的小编卖猪脚饭的小男孩。近日,字节开源了基于视觉-语言模型的GUI Agent:UI-TARS-1.5。该模型具备高级推理能力,能够在采取行动之前进行思考推理,显著提高了其性能和适应性。最新版本UI-TARS-1.5在各种标准基准测试中取得了最先进的结果,展示了强大的推理能力,并且相比之前的模型有了显著的改进。
真十项全能!十边形战士!
论文地址:
https://arxiv.org/abs/2501.12326
GitHub地址:
https://github.com/bytedance/UI-TARS
模型下载:
https://huggingface.co/ByteDance-Seed/UI-TARS-72B-DPO
https://huggingface.co/ByteDance-Seed/UI-TARS-7B-DPO
https://huggingface.co/ByteDance-Seed/UI-TARS-2B-SFT
1. 简介
UI-TARS是一个原生的 GUI Agent模型, 该模型仅以屏幕截图作为输入,并执行类似人类的交互操作(例如,键盘和鼠标操作)。 与依赖于经过大量封装的商业模型(例如 GPT-4o)以及专家精心设计的提示和工作流程的现有Agent框架不同,UI-TARS 是一个端到端的模型,其性能超越了这些复杂的框架。
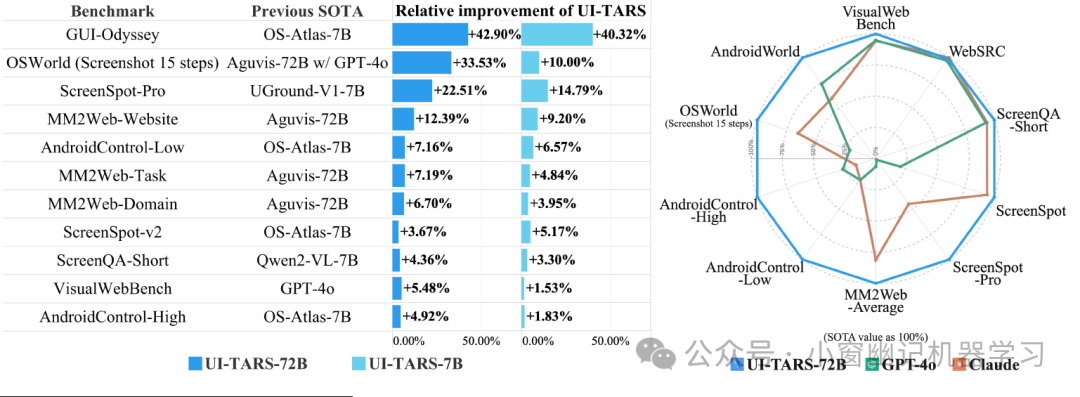
实验表明,UI-TARS 在 10 多个 GUI Agent 基准测试中取得了 SOTA(State-of-the-art,最先进)的性能,这些基准测试评估了感知、 grounding 和 GUI 任务执行能力。值得注意的是,在 OSWorld 基准测试中,UI-TARS 在 50 步和 15 步的情况下分别取得了 24.6 和 22.7 的分数,优于 Claude 的 22.0 和 14.9. 在 AndroidWorld 中,UI-TARS 的得分为 46.6,超过了 GPT-4o 的 34.5。
UI-TARS 包含以下几个关键创新:
-
(1) 增强的感知能力:利用大规模的 GUI 屏幕截图数据集进行上下文感知的 UI 元素理解和精确的标注。
-
(2) 统一的动作建模:将跨平台的动作标准化到一个统一的空间,并通过大规模的动作轨迹实现精确的 grounding 和交互。
-
(3) 慢思考(System-2)推理:将深思熟虑的推理融入到多步骤决策过程中,涉及任务分解、反思思考、里程碑识别等多种推理模式
-
(4) 通过反思性在线轨迹进行迭代训练:通过在数百个虚拟机上自动收集、过滤和反思性地优化新的交互轨迹来解决数据瓶颈问题。通过迭代训练和反思性调优,UI-TARS 可以在最少的人工干预下不断地从错误中学习并适应不可预测的情况。
此外,论文还分析了 GUI Agent的演进路径,以指导该领域的进一步发展。这里略,感兴趣的小伙伴可以阅读原文。
以下是以问答方式概述论文核心内容:
Q1: 这篇文章想要解决什么问题?
A1: 这篇文章旨在解决现有 GUI Agent框架依赖于大量封装的商业模型、专家设计的提示和工作流程,以及文本依赖所带来的平台限制、冗余和可扩展性不足等问题。研究目标是构建一个端到端的原生 GUI Agent模型 UI-TARS,该模型仅通过屏幕截图进行感知,能够执行类似人类的 GUI 交互,并在各种 GUI 任务中实现卓越的性能.
Q2: 这篇文章如何解决这些问题?
A2: UI-TARS 通过以下关键创新来解决这些问题:
-
增强的 GUI 感知:通过构建大规模的 GUI 屏幕截图数据集,并设计了元素描述、密集标注、状态转换标注、问题回答和 Set-of-Mark 提示等多种任务,提升模型对 UI 元素的上下文理解和精确标注能力。
-
统一的动作建模和 Grounding:设计了一个跨平台的统一动作空间,并通过结合人工标注和开源数据构建了大规模的动作轨迹数据集,提升了模型在不同平台上的动作执行和精确 grounding 能力.
-
注入慢思考推理:通过抓取和过滤 600 万个 GUI 教程,并结合任务分解、长期一致性、里程碑识别、试错和反思等多种推理模式增强动作轨迹数据,使模型在采取每个动作之前生成显式的“想法”,从而实现深思熟虑的决策。
-
通过反思性在线轨迹进行迭代训练:通过在数百个虚拟机上自动生成、过滤和反思性地优化新的交互轨迹,解决了数据瓶颈问题。引入了错误纠正和后反思标注数据,并使用直接偏好优化(DPO)进行训练,使模型能够从错误中学习并动态适应。
Q3: 文章所提出方法的效果如何?
A3: 实验结果表明,UI-TARS 在多个 GUI 代理基准测试中取得了最先进的性能.
-
在 OSWorld 基准测试中,UI-TARS 显著优于 Claude。
-
在 AndroidWorld 中,UI-TARS 的性能超过了 GPT-4o。
-
在评估感知能力的基准测试(如 Visual-WebBench、WebSRC 和 ScreenQA-short)中,UI-TARS 也展现出卓越的性能,超越了包括 GPT-4o 在内的现有模型。例如,UI-TARS-72B 在 Visual-WebBench 上取得了 82.8 的高分,高于 GPT-4o 的 78.5。UI-TARS-7B 在 WebSRC 上达到了 93.6 的领先分数。
-
在评估 grounding 能力的 ScreenSpot Pro 基准测试中,UI-TARS 取得了 38.1 的 SOTA 分数。
-
在离线代理能力评估基准测试(如 Multimodal Mind2Web、Android Control 和 GUI Odyssey)和在线代理能力评估基准测试(如 OSWorld 和 AndroidWorld)中,UI-TARS 的性能均表现出色,超越了许多现有的 Agent Framework 和 Agent Model。
Q4: 文章所提方法还有哪些不足?
A4: 尽管 UI-TARS 取得了显著的进展,但文章也展望了未来 GUI Agent的发展方向,暗示了当前方法的潜在不足。例如,文章提到,尽管原生Agent的适应性有所提高,但仍然在很大程度上依赖人类专家进行数据标注和训练指导,这限制了其能力,使其依赖于人类提供的数据和知识的质量和广度。 因此,如何进一步减少对人工标注的依赖,实现更强的自主学习和泛化能力,可能是未来需要改进的方向。此外,模型在面对完全未知或极其复杂的 GUI 环境时,其鲁棒性和泛化能力可能仍有提升空间。
更多大模型相关,欢迎关注微信公众号:小窗幽记机器学习
2. 方法
UI-TARS 的架构概述如图 4 所示。
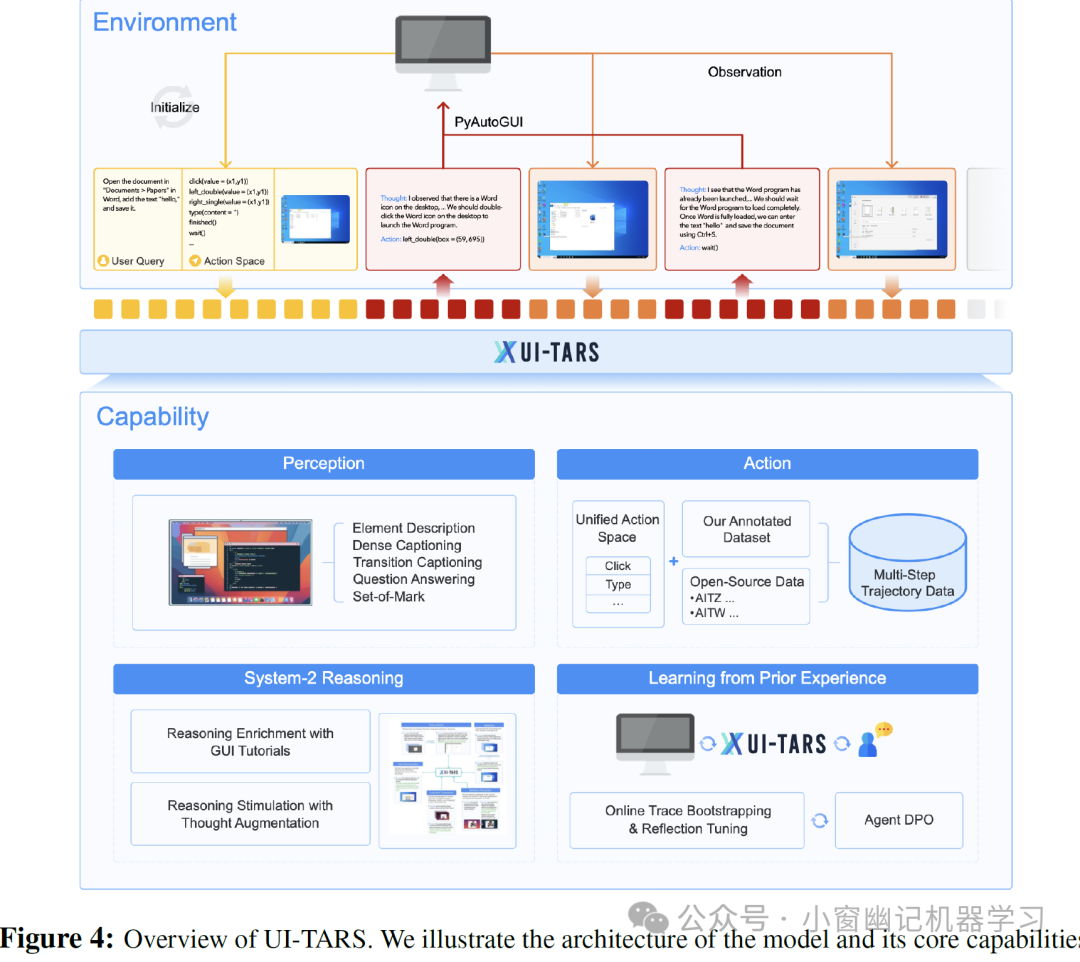
给定一个初始任务指令,UI-TARS 迭代地接收来自设备的观察(屏幕截图),并执行相应的动作以完成任务。这一过程可以形式化地表示为公式 (3):
UI-TARS 会持续地从设备接收观察(observations)并执行相应的动作(actions),以此来完成任务。这个顺序过程可以形式化地表示为:
-
首先,模型接收一个初始指令。
-
然后,在每个步骤中,模型会获取当前环境的观察(例如,GUI 的截图)。
-
基于指令和历史的交互(包括之前的观察和动作),UI-TARS 会进行推理(Reasoning)并生成一个动作。
-
这个动作会被发送到环境中执行。
-
环境会根据执行的动作更新其状态,并向 UI-TARS 返回新的观察。
-
这个过程会迭代地重复,直到任务完成或者达到预设的步骤限制。
UI-TARS 的核心能力包括增强的 GUI 感知、统一的动作建模与 Grounding、注入慢思考推理以及通过经验学习进行迭代改进.
2.1 增强 GUI 感知
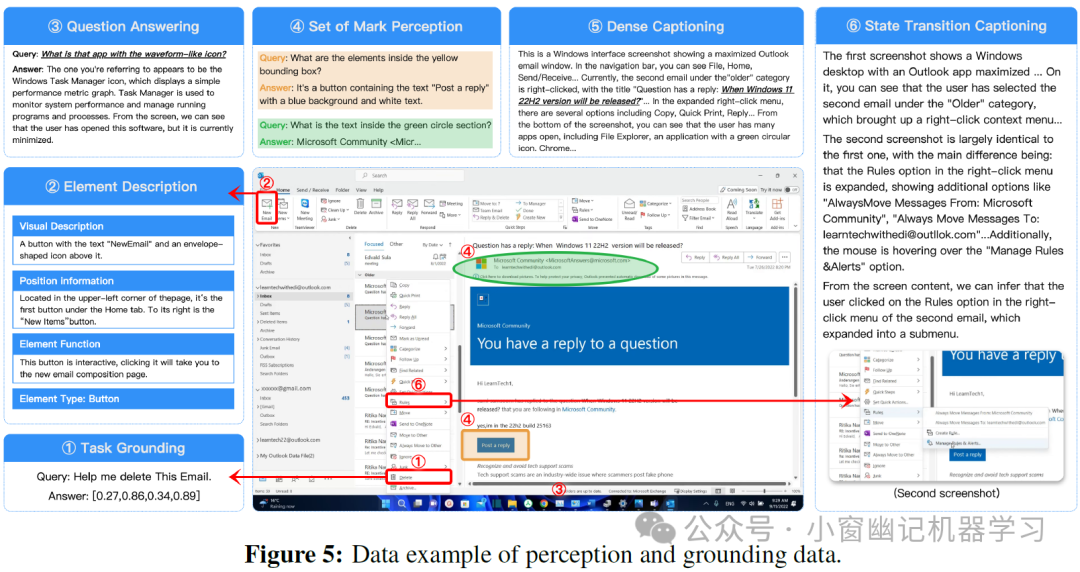
为了应对 GUI 屏幕截图的稀疏性、高信息密度和小元素识别的挑战,UI-TARS 采用了自下而上的数据构建方法。作者构建了一个大规模的 GUI 屏幕截图数据集,并针对以下五个核心任务进行了标注 (Figure 5):
-
元素描述:为每个可见的 UI 元素生成详细和结构化的描述,包括元素类型、视觉描述、位置信息和功能。
-
密集标注:生成对整个 GUI 屏幕截图的全面、详细描述,捕捉元素本身及其空间关系和界面整体布局。
-
状态转换标注:捕捉屏幕的细微视觉变化,识别并描述两个连续屏幕截图之间的差异,判断是否发生了用户交互(如点击或键盘输入)或非交互式的 UI 变化。
-
问题回答 (QA) :合成涵盖界面理解、图像解释、元素识别和关系推理等多种任务的 QA 数据, 增强模型的视觉推理能力。
-
Set-of-Mark (SoM) :通过在 GUI 屏幕截图中为解析出的元素绘制视觉上独特的标记,使模型更好地将视觉标记与其对应的元素相关联,并将其与密集标注和 QA 等任务相结合。
2.2 统一的动作建模和 Grounding
为了标准化跨平台的语义等效动作,UI-TARS 设计了一个统一的动作空间 (Table 1), 包括通用动作(如点击、拖动、滚动、输入、等待、完成、请求用户干预)以及特定于桌面和移动平台的动作。

为了改进多步骤执行能力,作者创建了一个大规模的动作轨迹数据集,结合了人工标注的轨迹和标准化的开源数据 (Table 2)。
通过将元素描述与其空间坐标配对,并结合开源 grounding 数据集,提升了模型精确识别和交互特定 GUI 元素的能力。
2.3 注入慢思考推理
为了增强模型的推理能力,作者爬取了约 600 万个高质量的 GUI 教程(平均每个教程有3.3张图和510个文本token),用于提供 GUI 知识以支持逻辑决策。在此基础上,通过 ActRe 注释方法 (Yang et al., 2024b),将任务分解、长期一致性、里程碑识别、试错和反思等多种推理模式注入到收集到的动作轨迹数据中,生成“想法” (Figure 6)。

Figure 6: Various reasoning patterns in our augmented thought.
训练过程中既包含带有“想法”的增强数据,也包含原始的无“想法”的动作轨迹数据。
2.4 通过经验学习进行迭代改进
为了克服大规模高质量动作轨迹数据稀缺的挑战,UI-TARS 采用了一个迭代改进框架,该框架动态地收集和优化新的交互轨迹 (Figure 7)。
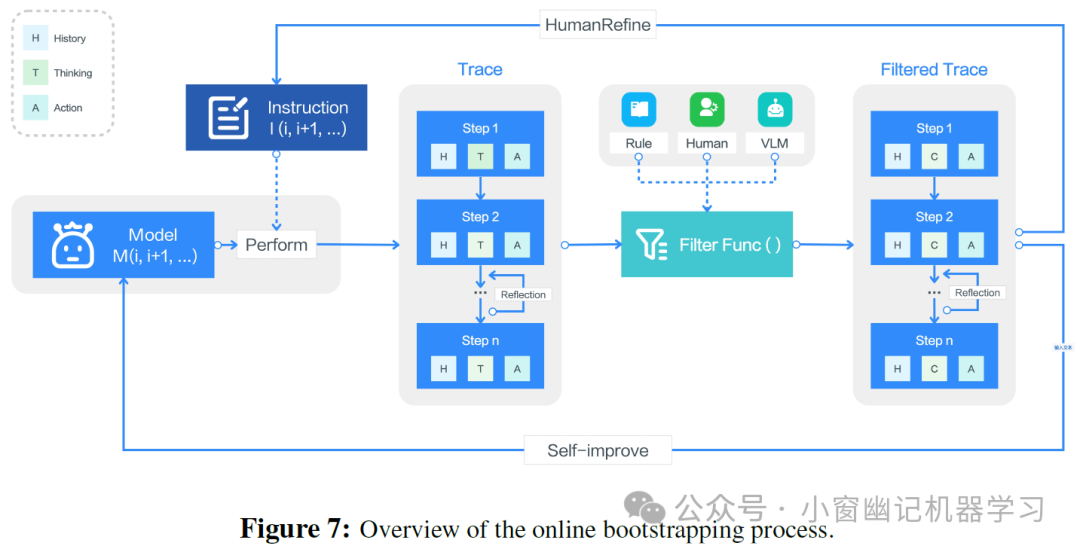
通过在数百个虚拟机上基于构建的指令探索各种真实世界的任务并生成大量轨迹,然后经过规则、VLM 评分和人工审核等多阶段过滤,确保轨迹质量。 这些优化的轨迹被反馈回模型进行持续的迭代增强。这个在线引导过程的另一个核心组成部分是反思调整。UI-TARS 采用了反思性调优,通过让模型分析自身次优的动作并学习如何纠正错误来提高其鲁棒性。研究人员标注了两种数据用于此过程: (1)错误纠正,标注人员指出智能体生成的轨迹中的错误并标注纠正性动作; (2)后反思,标注人员模拟恢复步骤,演示智能体在发生错误后应如何重新调整任务进度
这两种类型的数据创建了配对样本,用于使用直接偏好优化(DPO)训练模型,确保智能体不仅学会避免错误,还能在错误发生时动态调整策略。
2.5 训练
为了与现有工作进行公平比较,UI-TARS 使用了相同的 VLM 主干 Qwen-2-VL,并采用了三阶段的训练过程,总数据量约为 500 亿 tokens。这三个阶段包括:持续预训练阶段(使用所有感知、grounding 和动作轨迹数据)、退火阶段(选择高质量子集进行更 focused 的学习)和 DPO 阶段(使用反思性标注数据进行偏好优化)。训练了 UI-TARS-2B、UI-TARS-7B 和 UI-TARS-72B 三种模型变体。
3. 实验结果
论文通过全面的实验评估了 UI-TARS 在感知、grounding 和代理能力三个关键维度上的性能.
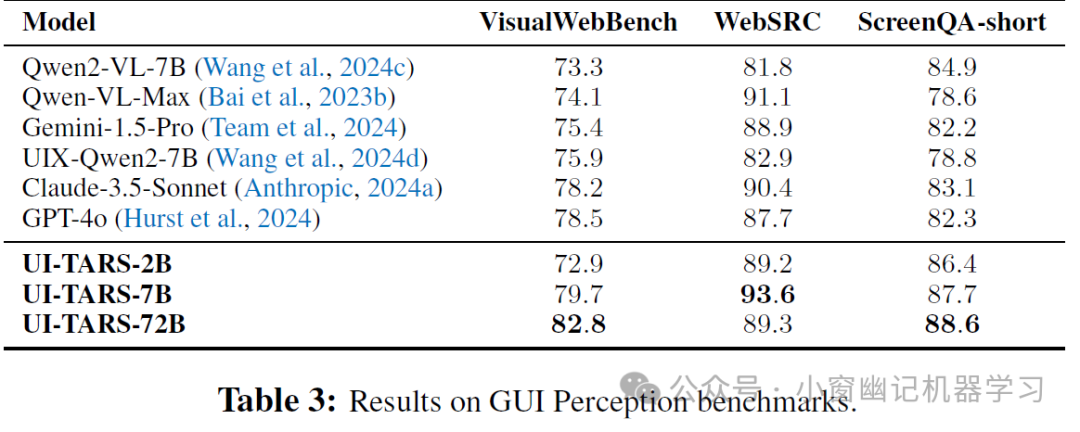
1、感知能力评估: 在 VisualWebBench、WebSRC 和 ScreenQA-short 等 GUI 感知基准测试中,UI-TARS 的不同模型变体均取得了优异的成绩,超越了包括 Qwen2-VL、GPT-4o 和 Claude-3.5-Sonnet 在内的先进模型 (Table 3)。这些结果验证了 UI-TARS 在理解网页结构、移动屏幕内容以及执行视觉问答任务方面的卓越能力。
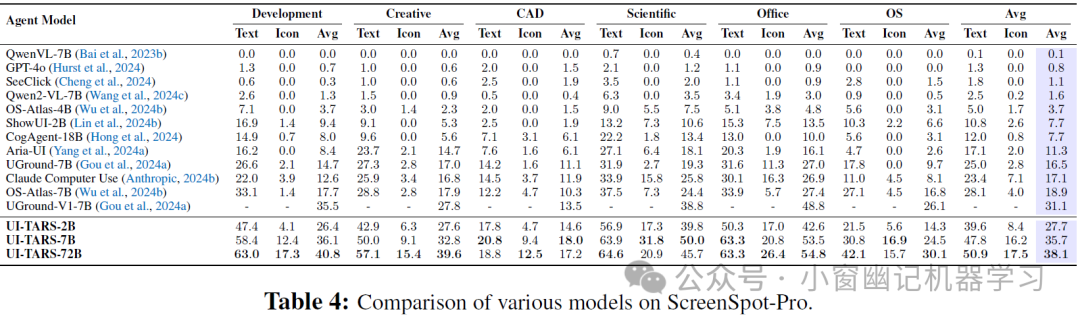
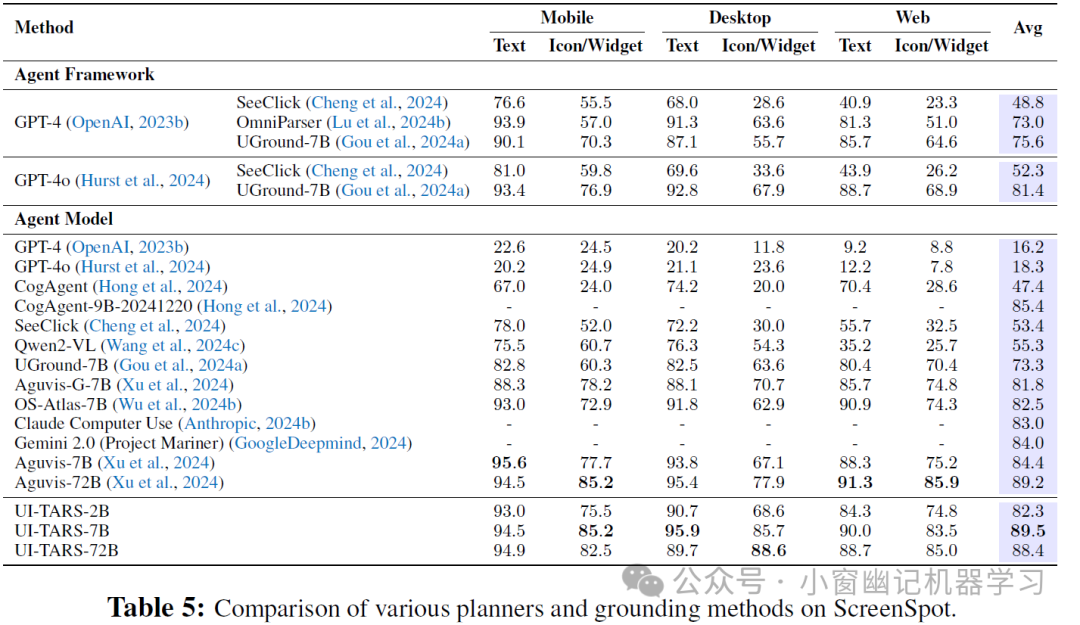
2、Grounding 能力评估: 在具有挑战性的 ScreenSpot Pro 基准测试中,UI-TARS 的所有模型都取得了显著的领先优势 (Table 4). UI-TARS-72B 取得了 38.1 的 SOTA 分数,证明了其在移动、桌面和 Web 环境中精确关联 GUI 元素与其空间坐标方面的强大能力. 此外,在 ScreenSpot 和 ScreenSpot-V2 基准测试中,UI-TARS 也展现了强大的 grounding 性能 (Table 5, Table 6)。
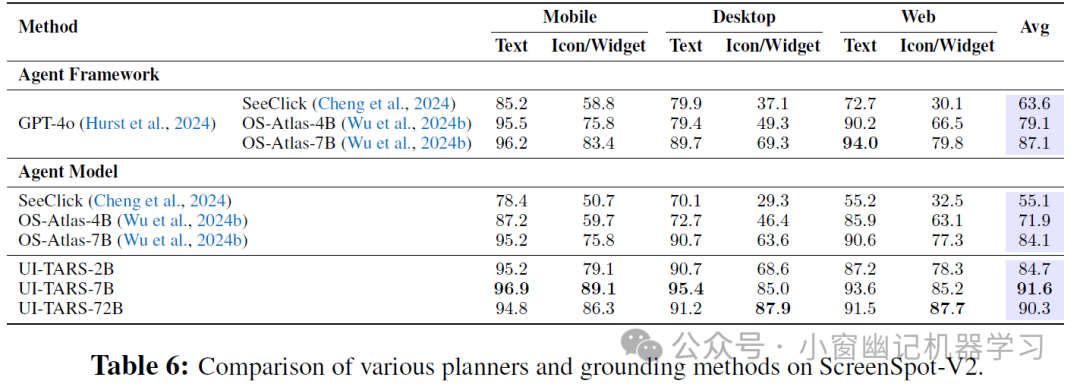
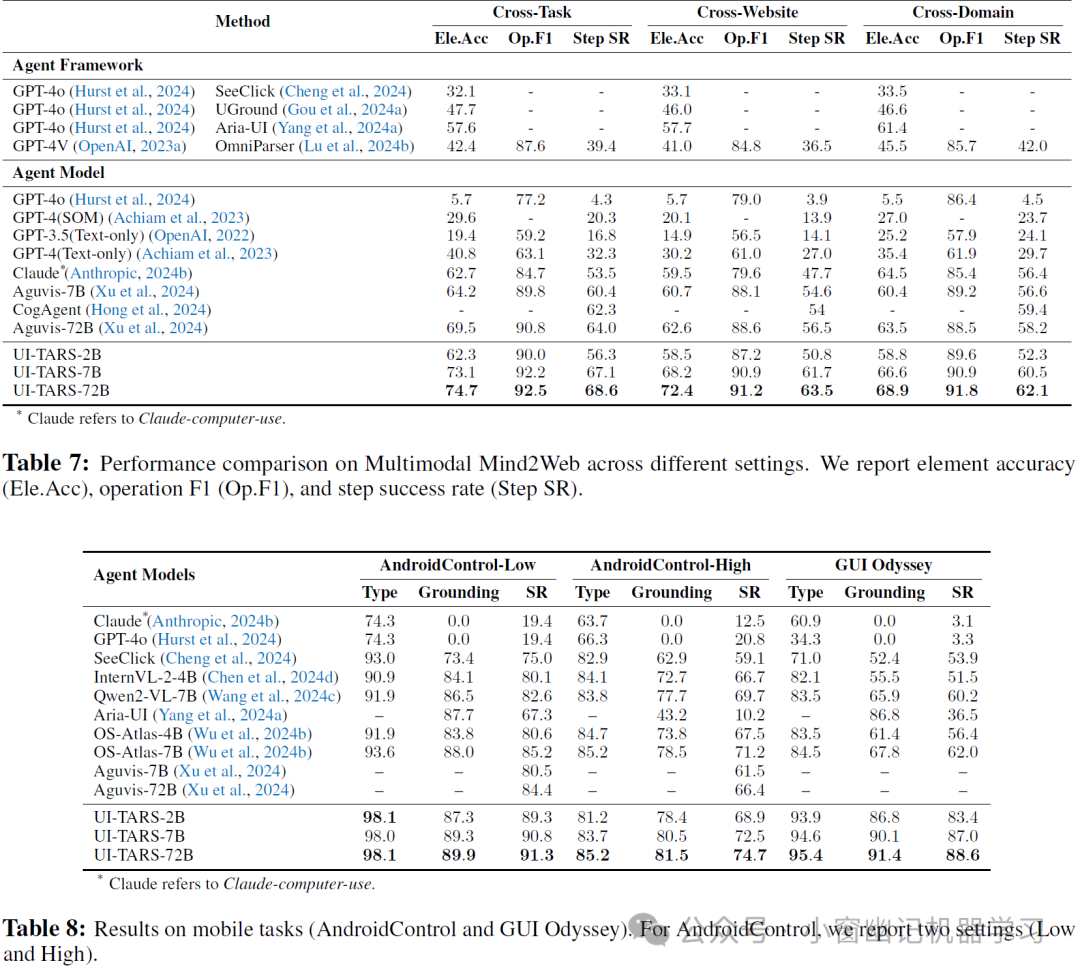
3、离线代理能力评估: 在 Multimodal Mind2Web、Android Control 和 GUI Odyssey 三个离线基准测试中,UI-TARS 在跨任务、跨网站和跨领域等不同设置下均表现出色 (Table 7, Table 8)。 例如,在 Multimodal Mind2Web 中,UI-TARS-7B 和 UI-TARS-72B 在元素准确率、操作 F1 值和步骤成功率等指标上均取得了领先或具有竞争力的结果. 在 Android Control 和 GUI Odyssey 中,UI-TARS 也展现了在移动环境中进行规划和执行多步骤任务的强大能力。
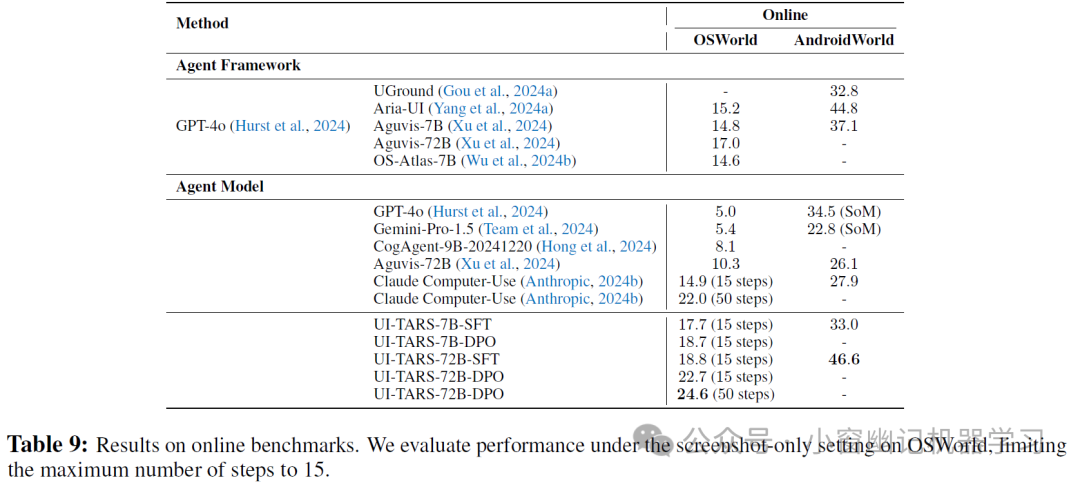
4、在线代理能力评估: 在模拟真实世界交互的动态环境 OSWorld 和 AndroidWorld 中,UI-TARS 取得了 SOTA 的性能 (Table 9)。值得注意的是,UI-TARS 在 OSWorld 基准测试中显著超越了 Claude 和 GPT-4o。在 AndroidWorld 中,UI-TARS 的表现也优于 GPT-4o。这些结果强调了 UI-TARS 在复杂、动态 GUI 环境中完成任务的有效性。
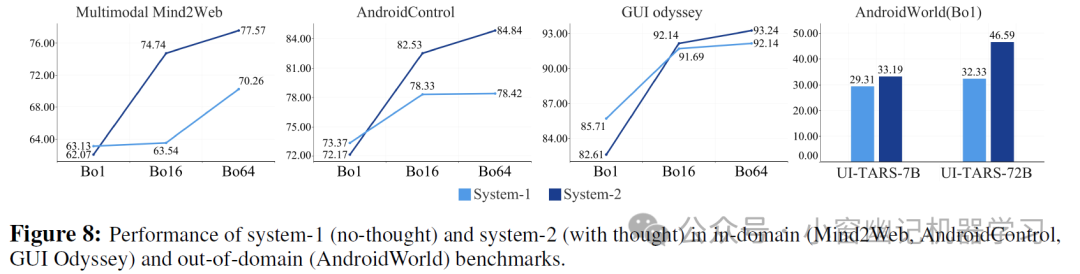
5、快思考(系统 1)和慢思考(系统 2)推理的比较: 通过在推理阶段修改提示,研究了系统 1(直接生成动作)和慢思考(先生成推理步骤再选择动作)推理对模型性能的影响Figure 8。实验结果表明,在具有相应训练数据的领域内基准测试(Multimodal Mind2Web、Android Control 和 GUI Odyssey)中,使用 Best-of-N 采样方法时,慢思考推理通常可以带来性能的提升。
4. 总结
UI-TARS是一个端到端的原生 GUI Agent模型,它仅依赖屏幕截图作为输入,并通过增强的感知、统一的动作建模、注入的慢思考 推理以及基于在线轨迹反思的迭代训练,在多个具有挑战性的 GUI Agent基准测试中取得了最先进的性能,显著超越了现有的 Agent Framework 和 Agent Model,例如 Claude 和 GPT-4o。UI-TARS 的创新性方法有效地解决了传统 GUI Agent框架的局限性,为构建更通用、更强大、更自主的 GUI Agent奠定了坚实的基础。
未来可改进的方向或要点包括:
-
进一步探索减少对人工标注数据的依赖,研究更有效的自监督或半监督学习方法,以提高模型的可扩展性和泛化能力。
-
提升模型在完全未知或高度复杂的 GUI 环境中的鲁棒性和适应性,例如通过更有效的探索策略和知识迁移方法。
-
更深入地研究和优化慢思考 推理能力,使其在更广泛的任务和更长的交互序列中发挥更大的作用。
-
探索将 UI-TARS 扩展到更多平台和应用场景的可能性,例如更复杂的桌面应用程序或特定领域的专业软件。
-
研究如何使 UI-TARS 具备更强的长期记忆和持续学习能力,使其能够随着时间的推移不断积累经验和知识,并适应用户不断变化的需求。
-
进一步分析和理解 UI-TARS 的决策过程和推理机制,提高模型的可解释性和可信度。
更新AI算法相关欢迎关注微信公众号\"小窗幽记机器学习\":



