使用LLaMA Factory进行模型微调全流程_llama-factory 本地微调 mac
使用 LLaMA Factory 进行模型微调全流程
前面提到了整个 LLaMA Factory 模型微调环境的搭建以及 Ollama + MaxKB 实现模型本地部署与可视化交互界面部署的过程。这篇博客主要针对模型微调的过程进行讲解。以下是跳转链接:
Ollama+MaxKB实现模型本地部署
LLaMA Factory 模型微调环境搭建
模型微调需要了解的参数
如果只是自己做一些简单的微调,可以跳过此部分。
原始模型文件下载
国内建议使用 魔搭社区 下载模型文件,有特殊网络环境也可以选择 HuggingFace 网站下载模型文件。
https://www.modelscope.cn/homehttps://huggingface.co/这里我以魔搭社区演示如何寻找合适的模型文件。使用HuggingFace可以参考我的另一篇博客:https://blog.csdn.net/weixin_46241866/article/details/144700025?
以通义千问模型为例,首先在搜索框内输入Qwen2.5-7B可以看到推荐了一堆的模型文件,我们找到后缀为 Instruct 的,这是已经经过微调的模型文件,我们可以进行小规模的微调,足以达到使用的条件。
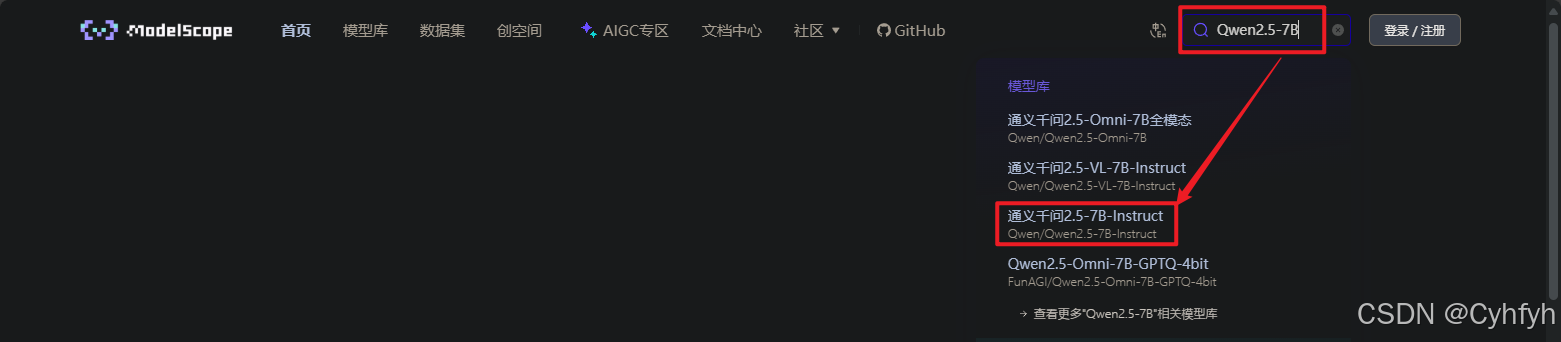
在页面中找到Git下载链接。
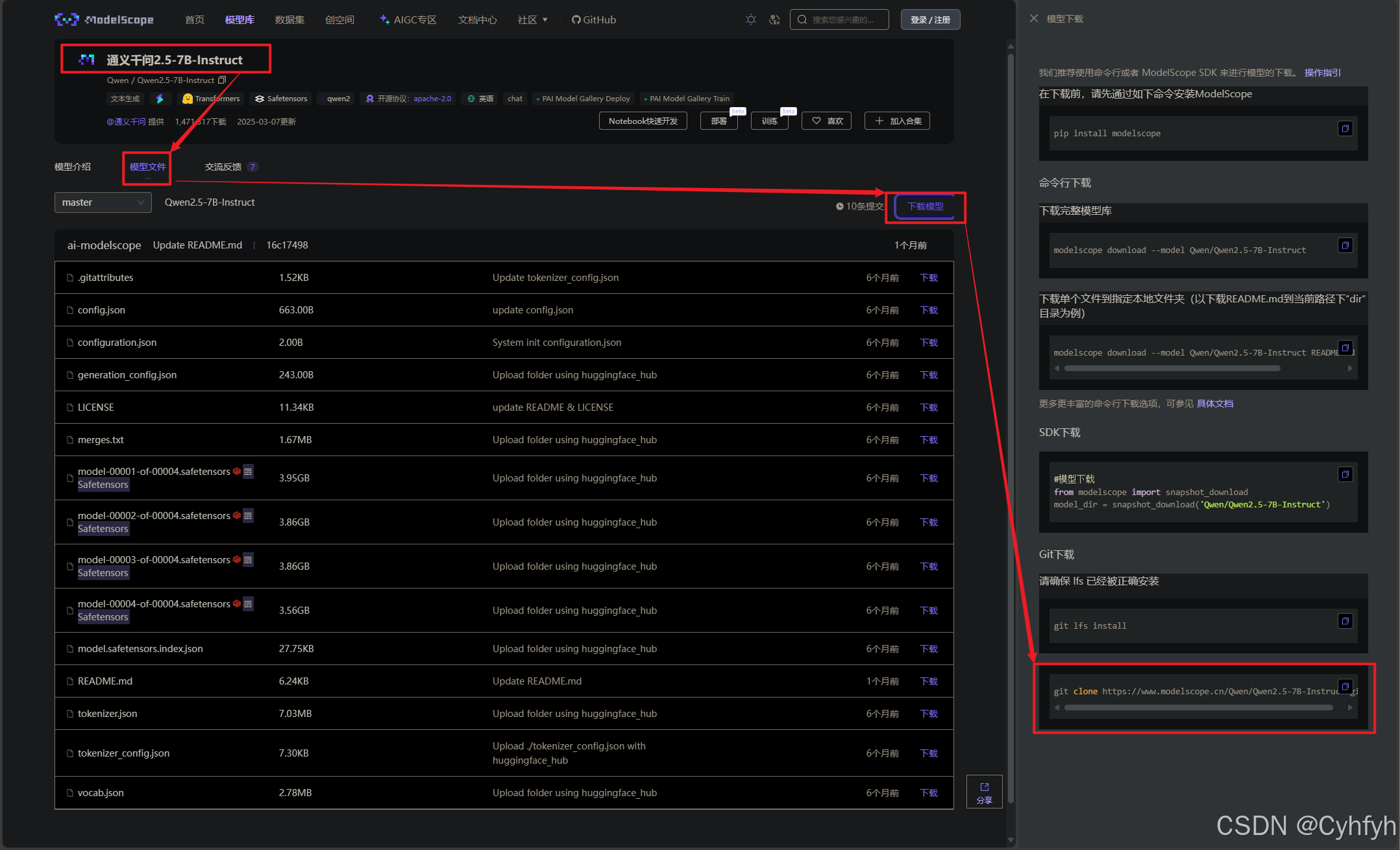
随后在电脑手动创建一个用于存储我们下载的模型文件的文件夹,随后使用Git工具拉取模型文件。模型文件较大,拉取过程也没有进度条,可以耐心等待。
模型微调
首先需要准备数据集,也就是用来微调模型的数据,主要包含输入跟输出的部分。在LLaMA-Factory/data目录下其实有提供了一些模板数据集。我们将自己的数据集放到data目录下。
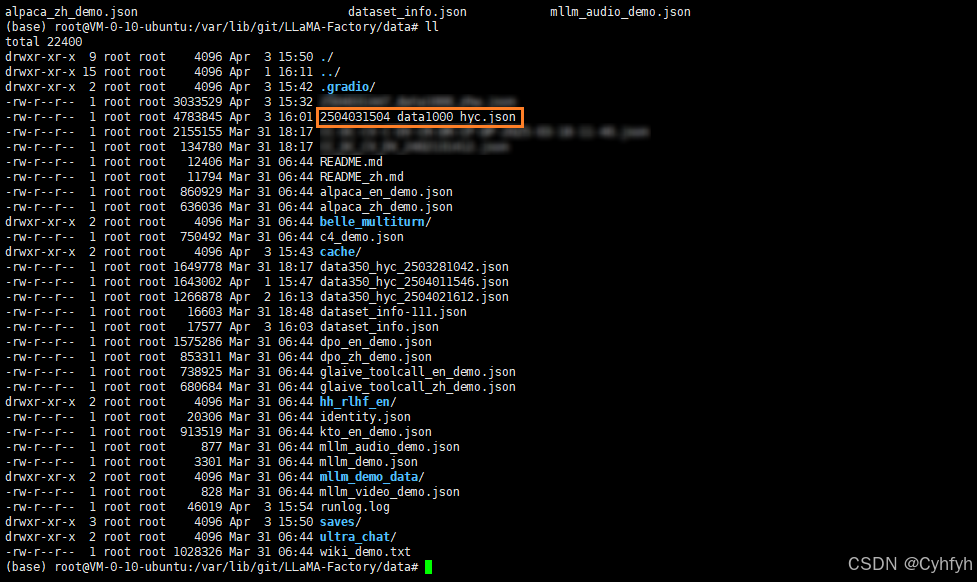
打开该目录下的dataset.json文件,将我们的数据文件配置进来,包含数据集命名以及文件路径。

配置完成即可直接在LlamaBoard页面中看到数据集。
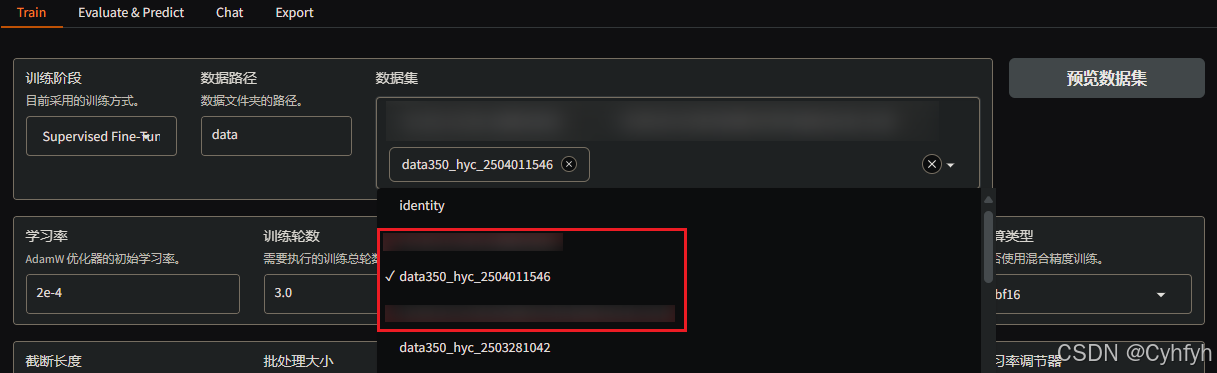
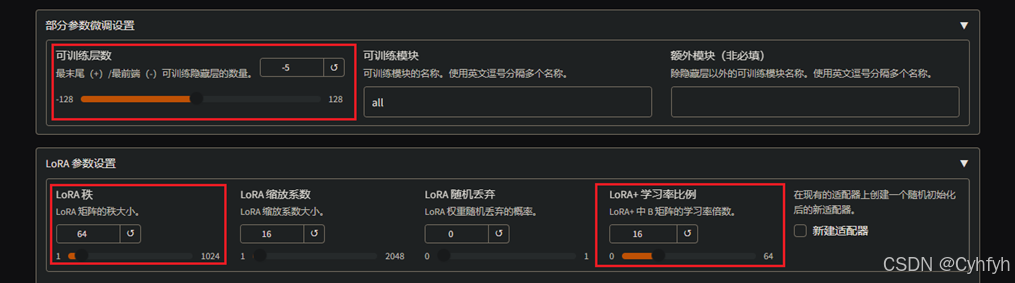
进行微调需要如下配置(具体配置据需求而定)




点击开始,直接执行微调,此时可以看到日志打印了进度信息,等待微调完毕即可。

至此模型微调结束
但模型微调完成后我们需要对模型进行导出以及转换与量化。将在这篇博客中介绍:


