带你对比三大主流消息队列RabbitMQ、RocketMQ以及Kafka_mq各个区别
目录
一、三大MQ该如何进行技术选型?
二、三大MQ的吞吐量对比?
三、三大MQ的低延迟对比?
四、三大MQ的消息可靠性对比?
五、三大MQ都是如何保障消息有序性的?
六、三大MQ都是如何保障事务一致性的?
七、三大MQ都是如何保障消费幂等性的?
八、三大MQ都是如何处理消息积压问题的?
九、三大MQ都是如何保障高可用的?
十、为什么RabbitMQ不适合分布式架构?
十一、三大MQ都是如何操作死信的?
十二、三大MQ的消息存储机制与效率对比?
十三、三大MQ的的延迟消息的实现方式对比?
十四、三大MQ的消息过滤机制对比?
十五、三大MQ的资源消耗模型对比?
十六、三大MQ的消息优先级支持对比?
三大队列的详细讲解:
带你轻松学习RabbitMQ-CSDN博客
https://blog.csdn.net/2401_88959292/article/details/149294023?spm=1001.2014.3001.5502带你轻松学习RocketMQ-CSDN博客
带你轻松学习Kafka-CSDN博客
一、三大MQ该如何进行技术选型?
在详细讲述每个MQ的博客里我都有总结其适用场景与不适用场景,故在此处我只提供选型树,若想更加详细地了解请翻阅上面三篇博客。
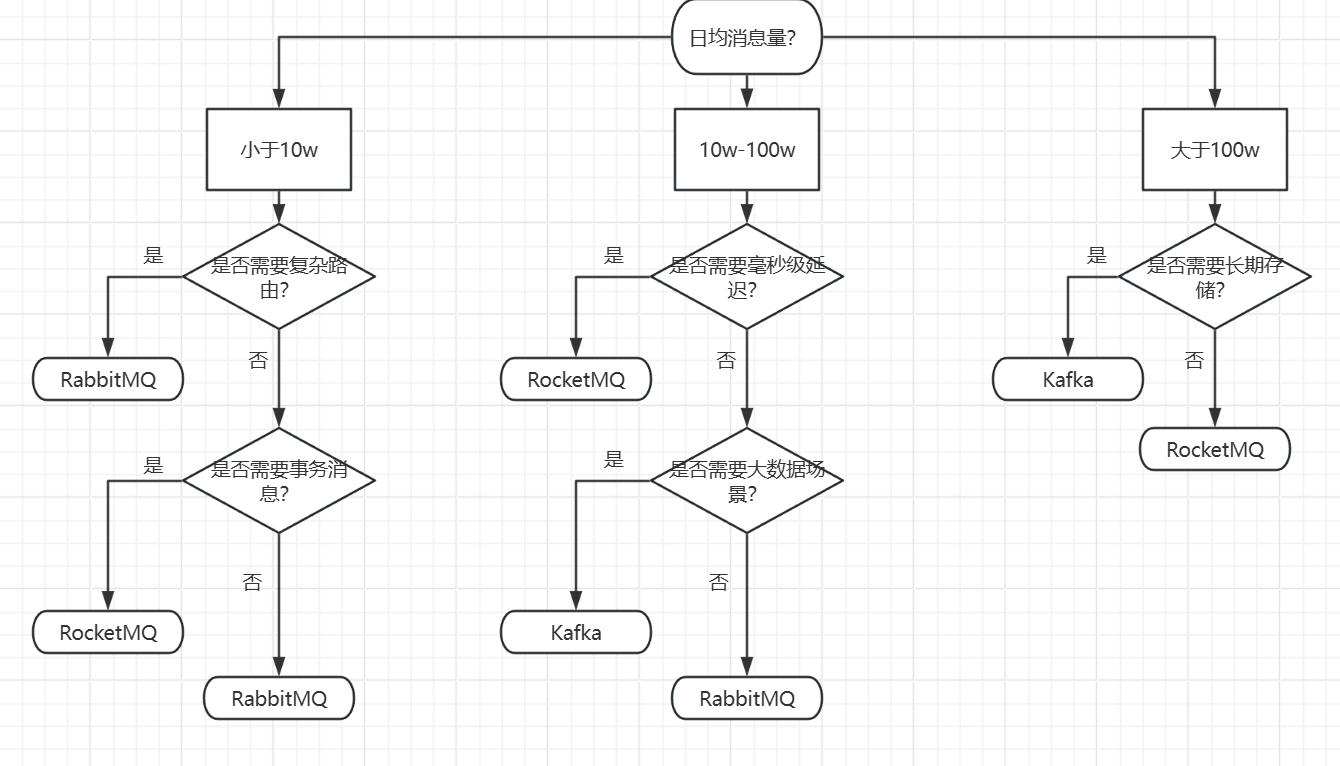
-
RabbitMQ的特性决定了其适合中小规模、实时性要求高、需要灵活路由、消息丢失零容忍的场景,不适合大规模高吞吐量、流处理场景。
-
RocketMQ的特性决定了其适合大规模高并发、强可靠、需要复杂业务处理的场景,不适合小规模低延迟、简单通信或资源受限的场景。
-
Kafka作为分布式流处理平台,其核心特性决定了其适合大规模数据流式传输、实时分析、日志收集等场景,同时在低延迟、强事务、小规模应用等场景下存在局限性。
这么来看,RocketMQ其实使用场景更加广泛一些,这也是为什么我在RocketMQ篇的博客里只能提取出其一个缺点。
二、三大MQ的吞吐量对比?
- 顺序写:每个分区的日志文件采用Append-Only(追加)模式,磁盘IO为顺序写。
- sendfile零拷贝技术
- 批量压缩:减少网络I/O
- 分区并行:一个Topic拥有多个分区
- 顺序写:所有逻辑队列共享一份CommitLog文件,因此磁盘IO就是顺序读写的形式,大大加快了磁盘IO效率
- mmap零拷贝技术
- PageCache内存映射:CommitLog和ConsumeQueue均映射到操作系统PageCache,读取消息时直接从内存获取,避免磁盘IO
- 存储机制限制:RabbitMQ的队列采用每个队列单独存储的模式,高吞吐量下,多个队列的磁盘IO会相互竞争,导致IO瓶颈(随机写)。
- Erlang虚拟机:RabbitMQ基于Erlang开发,Erlang的BEAM虚拟机虽然适合高并发小任务,但对于大流量数据传输),其性能不如JVM高效。
- 镜像队列同步开销:镜像队列需要将消息异步同步到多个从节点,高吞吐量下会占用大量网络带宽和磁盘IO。
- 灵活性换取高吞吐:消息会在发送到队列之前由交换机进行路由,可能会造成消息堆积。
三、三大MQ的低延迟对比?
1. RabbitMQ:微秒级低延迟
-
延迟表现:
-
低负载下可达微秒级,高吞吐量时升至毫秒级。
-
-
核心优势:
-
轻量级Erlang进程模型,内存操作优先。
-
支持实时消息确认。
-
2. Kafka:高吞吐下的毫秒级延迟
-
延迟表现:
-
平均2–5毫秒,百万级TPS下保持稳定。
-
-
核心优势:
-
批量压缩 + 顺序磁盘I/O。
-
零拷贝技术减少数据复制。
-
-
局限: 小消息批次累积可能增加延迟。
3. RocketMQ:均衡型毫秒级延迟
-
延迟表现:
-
平均3–10毫秒,十万级TPS稳定。
-
-
核心优势:
-
顺序写入 + 内存映射优化。
-
原生支持延时消息。
-
因此如果要最求延迟低的话,低并发优先RabbitMQ;高并发且消息大优先Kafka;高并发且消息小优先RocketMQ。
四、三大MQ的消息可靠性对比?
RabbitMQ:
-
持久化:交换机和队列、以及被标记为持久化的消息数据会存储到磁盘。
-
生产者确认:开启confirm模式后,当消息到达交换机后Broker会发送ack消息给生产者,生产者可根据确认结果重发消息。
-
消费者确认:消费者可选择自动和手动向Broker发送ack消息的方式,从而确保消息是否被消费掉。
-
高可用集群:通过多个Broker节点以及镜像队列、Quorum Queue来实现任意节点宕机的情况下也不会影响消息的正常传递。
RockeMQ:
-
持久化:
-
CommitLog:所有消息都写入磁盘(顺序写),确保Broker宕机后消息不丢失;
-
ConsumeQueue:Topic-Queue的索引文件,存储在磁盘,确保索引不丢失;
-
offset:写入磁盘,确保消费者宕机或重启可以正常拉取后续消息;
-
-
生产者确认: 生产者支持同步发送、异步发送,确保消息到达Broker。
-
消费者确认: 消费者采用Offset确认机制,处理完消息后发送ACK,Broker更新Offset;若消费者宕机,下次从上次的Offset继续消费,确保至少一次交付;
-
高可用集群: 采用Master-Slave主从副本机制,Master处理读写请求,Slave异步同步Master的数据;Master宕机后,Slave自动晋升为新Master。
Kafka:
-
副本同步:每个分区有多个副本(默认1个Leader+2个Follower),Leader处理读写请求,Follower同步Leader的日志数据。ISR动态维护,确保副本的一致性。
-
Leader选举:若Leader节点宕机,Kafka会从ISR中选举新的Leader,整个过程秒级完成,不影响服务。
-
数据可靠性:生产者可配置acks=all(或-1),要求Leader确认消息写入本地日志且多数Follower同步完成后返回成功,保证数据不丢失(适合金融等核心业务)。
可靠性排序(集群模式且默认配置下):RocketMQ > RabbitMQ > Kafka
五、三大MQ都是如何保障消息有序性的?
-
全局有序(牺牲并发)
-
三个MQ一致:单队列+单消费者(吞吐骤降)。
-
-
分区有序(高并发方案)
-
RabbitMQ:无原生分区,需业务层路由相同ID到同一队列。
-
RocketMQ:逻辑队列分区,相同订单ID哈希到同一Queue,消费时锁定该Queue。
-
Kafka:Topic切片分区,相同Key的消息写入同一Partition,单线程消费该分区。
-
六、三大MQ都是如何保障事务一致性的?
-
RabbitMQ原生是没有事务支持的,只能通过业务进行事务一致性的绑定,但无法保证本地事务与消息发送的原子性。
-
RocketMQ支持半事务消息:
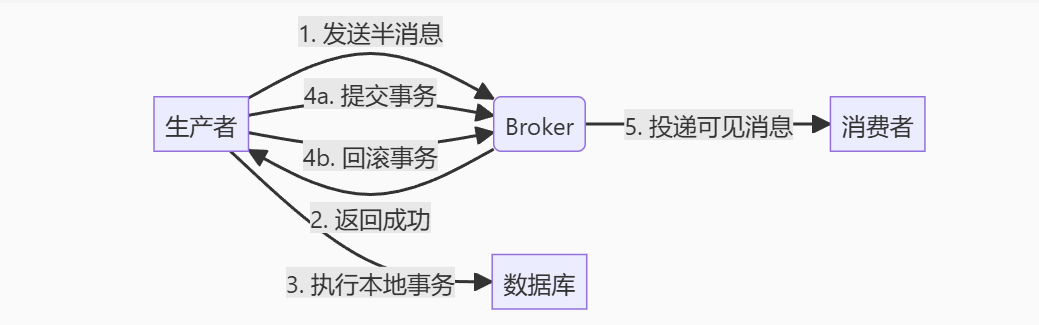
-
Kafka支持生产者端的事务,支持原子性发送多个消息到多个Topic/分区,但无法处理事务失败的场景。
所以三大MQ中就只有RocketMQ对事务一致性是有强保障的。
七、三大MQ都是如何保障消费幂等性的?
Message ID + Message Key + 消费位点持久化(避免重复投递)commit_sync手动提交位点八、三大MQ都是如何处理消息积压问题的?
其实消息积压问题要不就是生产者发送太快,要不就是消费者消费太慢,所以可以拓宽消息传递容器或者增加消费者的方式来处理。
-
RabbitMQ
-
使用镜像队列增加消费者节点
-
将大队列拆为多个小队列
-
-
RockeMQ
-
增加Broker节点,拓宽Topic逻辑队列数
-
增加消费者组中的消费者数量
-
-
Kafka
-
增加Topic分区数量
-
增加消费者组中的消费者数量
-
九、三大MQ都是如何保障高可用的?
-
RabbitMQ:
-
镜像队列:将Queue复制到主节点+从节点(如1主2从),主节点处理读写请求,从节点同步消息;主节点宕机后,从节点自动接管(最终一致)。
-
Quorum Queue:基于Raft协议的强一致队列,每个Queue有多个副本,消息需被多数节点确认后才会被消费者接收;主节点宕机后,从节点自动选举为新主节点(强一致)。
-
-
RocketMQ:
-
NameServer、Broker均采用无状态设计,使得一台宕机也不会给其他节点造成任何影响。
-
NameServer定期检查Broker心跳,及时剔除宕机Broker路由,避免消息的无效传递。
-
Broker分为主从模式,可自由搭建多主多从的同步或异步模式,且主从都拥有读写权,使得即使主节点宕机了从节点也可以立即接替其职责。
-
定期刷盘使消息数据持久化。
-
-
Kafka:
-
副本同步:每个分区有多个副本(默认1个Leader+2个Follower),Leader处理读写请求,Follower同步Leader的日志数据。ISR动态维护,确保副本的一致性。
-
Leader选举:若Leader节点宕机,Kafka会从ISR中选举新的Leader,整个过程秒级完成,不影响服务。
-
数据可靠性:生产者可配置acks=all(或-1),要求Leader确认消息写入本地日志且多数Follower同步完成后返回成功,保证数据不丢失(适合金融等核心业务)。
-
十、为什么RabbitMQ不适合分布式架构?
-
队列与节点强耦合
- 队列创建后绑定在特定节点,跨节点访问需代理转发(性能瓶颈)
- 扩容需手动迁移队列(第三方插件支持有限)
-
扩展性缺陷
- 镜像队列扩容后:
- 写入性能不提升(所有节点同步写)
- 网络开销随节点数指数增长
- 对比Kafka/RocketMQ:
维度 RabbitMQ Kafka/RocketMQ 水平扩展 ❌ 队列绑定节点 ✅ 分区自动负载均衡 吞吐提升 ❌ 单队列受限 ✅ 分区并行读写
- 镜像队列扩容后:
总结一下就是RabbitMQ水平扩展性很差,模型是按垂直扩展来设计的。
十一、三大MQ都是如何操作死信的?
-
RabbitMQ
-
触发条件:
-
消息被拒绝且配置requeue=false
-
消息TTL过期
-
队列达到最大长度
-
-
处理流程:
-
通过
x-dead-letter-exchange声明死信交换机 -
通过
x-dead-letter-routing-key指定路由键 -
死信消息自动路由到指定的DLX(死信交换机)
-
最终进入绑定的死信队列等待处理
-
-
-
RocketMQ
-
触发条件:消息重试消费超过最大次数(默认16次)
-
处理流程:
-
自动转移到死信队列
-
死信队列独立存储,需人工干预处理
-
支持通过控制台重新投递死信消息
-
-
-
Kafka
-
无原生死信机制:
-
消费失败时需手动提交offset跳过消息
-
常见方案:
-
将异常消息写入专用\"死信Topic\"
-
使用拦截器捕获异常消息存入数据库
-
配合外部系统(如es)存储死信
-
-
-
十二、三大MQ的消息存储机制与效率对比?
十三、三大MQ的的延迟消息的实现方式对比?
-
RabbitMQ
-
实现方案:
-
TTL+死信队列:设置消息TTL放入无消费者订阅的队列,过期后成为死信来间接达成延迟消息
-
使用插件:
rabbitmq-delayed-message-exchange
-
-
缺陷:
-
固定TTL需预设多队列
-
高精度延迟支持差
-
-
-
RocketMQ
-
原生方案:
-
内置18个延迟级别
-
消息存入SCHEDULE_TOPIC_XXXX定时队列
-
TimerService线程扫描到期消息
-
-
优势:毫秒级精度,亿级延迟消息支持
-
-
Kafka(不支持)
十四、三大MQ的消息过滤机制对比?
-
RabbitMQ
-
路由过滤:
-
Direct Exchange:精确匹配Routing Key
-
Topic Exchange:通配符匹配(*/#)
-
-
-
RocketMQ
-
Tag过滤:
-
消费时指定Tag表达式(如\"TAG_A || TAG_B\")
-
Broker端过滤,减少网络传输
-
-
SQL过滤:
-
基于消息属性过滤(
a>5 AND b=\'test\')
-
-
-
Kafka
-
分区级过滤:Key哈希到特定分区
-
客户端过滤:消费者拉取后本地过滤
-
流处理过滤:Kafka Streams实时过滤
-
十五、三大MQ的资源消耗模型对比?
什么是GC?
GC(Garbage Collection) 是自动回收无用内存的机制。代替程序员手动管理内存,防止内存泄漏和野指针错误。
但其运行过程会对系统性能产生多维度影响,称为 “GC影响”。
GC 在回收内存时,会争夺系统资源并干扰程序运行,导致三大问题:
服务卡顿(STW)
现象:垃圾回收时所有业务线程暂停
后果:消息处理延迟飙升,实时系统违反 SLA
资源争抢
CPU 占用:GC 线程扫描对象消耗计算资源,挤占业务线程
内存碎片:频繁回收后内存零散,可用连续空间减少
系统崩溃风险
Full GC 卡顿过长会导致服务无响应
堆外内存泄漏会导致物理内存耗尽触发OOM
十六、三大MQ的消息优先级支持对比?
-
RabbitMQ
-
原生支持:
-
队列声明时设置
x-max-priority(0-255) -
高优先级消息优先出队
-
-
限制:仅对未消费的堆积消息有效
-
-
RocketMQ
-
间接实现:
-
创建多级优先级队列(如P0/P1/P2)
-
消费者优先消费高优先级队列
-
-
缺陷:无法实现动态优先级调整
-
-
Kafka(不支持)
~码文不易,留个赞再走吧~

