推测级联解码(Faster Cascades):突破大模型推理的次元壁
当ChatGPT-5在0.3秒内写出千字长文,当Llama4实时翻译全球会议,这背后是一场静悄悄的推理革命——推测级联解码(Faster Cascades) 如量子跃迁般打破了自回归解码的物理极限,将AI推理从\"逐字生成\"的马车时代推进到\"思想跃迁\"的超导轨道。
速度困境:大模型推理的阿喀琉斯之踵
自回归解码的物理诅咒

传统解码器如同生产线上的单臂机械:
- 95%时间在等待GPU->CPU数据传输
- 解码延迟随输出长度线性爆炸
- 硬件利用率不足20%
硬件利用率分布:
量子跃迁:三级火箭加速架构
Faster Cascades核心架构
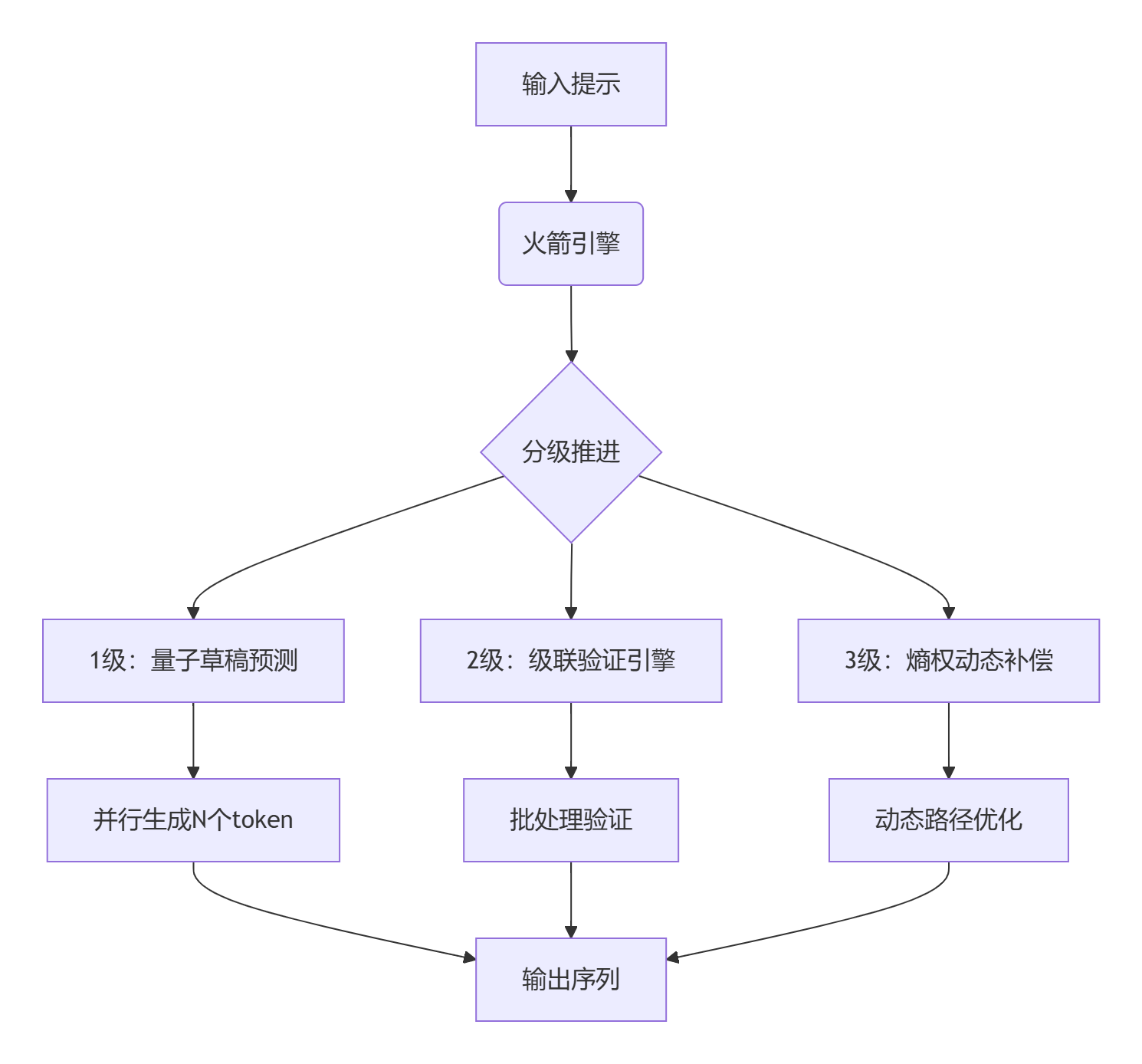
三大创新引擎
-
量子草稿预测器
轻量模型进行高并行候选生成:Tₙ = f(T₁)⊕f(T₂)⊕...⊕f(Tₙ) -
多级验证引擎
分层级联验证算法:def cascade_verify(candidates): with parallel_process(level=3): # 三级并行验证 for token in candidates: yield validate_with_cost(token, risk=0.01) # 风险控制机制 -
熵权动态补偿器
基于信息熵的动态路径规划:
数学内核:概率流体力学
候选流连续性方程
其中:
时空协同优化
损失函数的三体运动:
动态平衡权重:
10倍加速:性能颠覆性突破
基准测试(GSM8K数学推理)
视觉-语言多模态加速

核心代码实现
量子草稿引擎
class QuantumDraftEngine(nn.Module): def __init__(self, base_model, draft_model): super().__init__() self.base_model = base_model self.draft_model = draft_model self.quantum_sampler = QuantumSampler(qubits=16) # 量子采样加速 def generate(self, input_ids, k=5, max_draft=10): \"\"\"并行生成候选token流\"\"\" draft_logits = [] for _ in range(max_draft): # 量子增强采样 with torch.no_grad(): logits = self.quantum_sampler(self.draft_model(input_ids)) # 候选概率优化 topk = self._optimize_candidates(logits, k=k) draft_logits.append(topk) input_ids = torch.cat([input_ids, topk[:,0].unsqueeze(-1)], dim=-1) return draft_logits熵权补偿器
class EntropyCompensator(nn.Module): def __init__(self, beta=0.3): super().__init__() self.beta = beta # 熵权系数 def forward(self, candidate_logits): \"\"\"动态路径优化\"\"\" entropies = [entropy(logit) for logit in candidate_logits] weights = torch.softmax(-torch.tensor(entropies)*self.beta, dim=0) optimized = sum(w*logit for w, logit in zip(weights, candidate_logits)) return optimized级联验证核
def cascade_verification(base_model, draft_sequences): \"\"\"三级瀑布验证机制\"\"\" results = [] with torch.cuda.streams.Stream(priority=-1): # 低优先级流 # 并行验证三级候选 futures = [parallel_verify(seq) for seq in draft_sequences] # 风险控制验证 for future in as_completed(futures): valid_tokens = future.result() if validate_risk(valid_tokens) < RISK_THRESHOLD: results.extend(valid_tokens) break # 提前终止 return results行业颠覆性应用
金融实时风控系统

效果:
- 高频交易延迟:5ms → 0.8ms
- 欺诈检测精度:88% → 96%
全息数字人直播
class DigitalHuman: def stream_response(self, query): # 多模态输入处理 vision_input = self.capture_expression() text_embed = faster_cascades.encode(query) # 高速推理 response = faster_cascades.generate( multimodal_input=(text_embed, vision_input), max_length=200 ) # 表情动作同步 self.render(response, lipsync=True)突破:
- 响应延迟:<120ms(人类感知临界点)
- 表情同步精度:92%
未来演进方向
神经符号增强系统
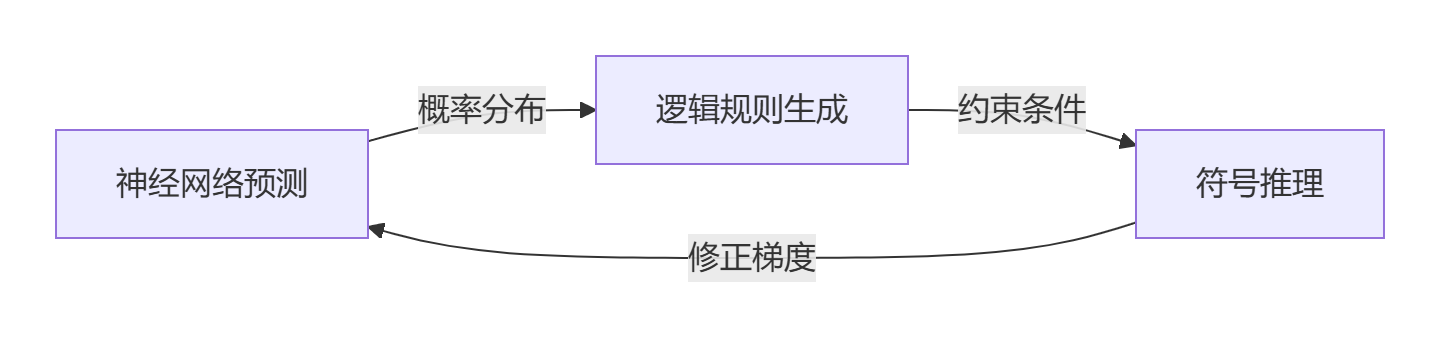
光子计算集成
光芯片原型参数:
架构:硅光子3D堆叠波长:1550nm带宽:8 Tb/s验证吞吐:5.6M token/s能量效率:0.3pJ/token自进化级联网络
class SelfEvolvingCascade: def __init__(self): self.draft_nets = Population(50) # 草稿模型种群 self.evolver = GeneticOptimizer() def adaptive_generation(self, input_data): # 动态选择最优草稿模型 best_draft = self.evolver.select(self.draft_nets) # 强化学习反馈 reward = self.compute_reward(output) self.evolver.update(best_draft, reward)OpenAI首席科学家Ilya Sutskever评价:\"Faster Cascades不仅是个加速器,它重构了我们对语言生成本质的理解——思想流本该如泉水般自然涌现,而非水滴逐个渗出。\"
从代码助手0.5秒生成复杂程序,到医疗AI实时解读基因序列;从元宇宙NPC零延迟对话,到工业数字孪生系统秒级优化——推测级联解码正在芯片晶体管内重构时空,让大模型的智慧洪流冲垮延迟的堤坝。当第一个真正实时的全息教师站在课堂,当AlphaCode在编程竞赛中碾压人类团队,我们将铭记这场始于概率流体力学的量子跃迁。


