Whisper(Openai)部署方案测试_whisper部署
1.Whisper介绍
Whisper 是由 OpenAI 开发的开源语音识别模型,于 2020 年发布。它以 强大的多语言处理能力、高精度转录效果 和 灵活的应用场景 成为当前最受欢迎的语音识别工具之一。其核心目标是实现 “通用语音识别”,即通过单一模型处理多种语言、口音和音频类型(如演讲、播客、视频旁白等)。
2.部署测试
下面我以一个简单的方式教大家如何在虚拟环境中部署一下whisper,感受一下音频转文字的效果。
一:conda生成虚拟环境
conda create -n whisper python=3.9创建虚拟环境可以与本地环境保持隔离,比如后面安装其他库要安装其他版本的numpy,但本地有些历程可能与模型需要的numpy版本不匹配。通过虚拟环境就可以很好的规避这个问题,在虚拟环境中安装的numpy既满足的模型需求也不影响本地numpy的版本。还要注意python版本的问题,可能装根据文档安装3.9.9可能安装不了虚拟环境,因为有些虚拟环境部署无法实现版本精度很高的python安装,用3.9基本上问题也不大。
二: Pytorch安装
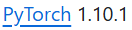
注意安装这个版本的Pytorch,与上面python同理,建议安装cuda版本的CPU版本可能效果不太好。
cuda版:
pip install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.htmlCPU版:
pip install torch==1.10.1+cpu torchvision==0.11.2+cpu torchaudio==0.10.1+cpu -f https://download.pytorch.org/whl/torch_stable.html三:其他工具安装
安装相关使用工具
pip install -U openai-whisperpip install git+https://github.com/openai/whisper.git 如果想更新的话可以执行这条命令
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git由于我服务器是Ubuntu系统,ffmpeg用这条指令就好了
# on Ubuntu or Debiansudo apt update && sudo apt install ffmpeg最后安装rust工具集就OK了
pip install setuptools-rust3.测试与验证
官方给了我们一下版本的模型进行测试:

由图可知:tiny是最小的,large是最大的。我在4090上部署测试tiny版本不会出现显存问题,而large几乎运行两次显存必满(可能是显卡上还跑了其他模型的缘故)。其中turbo版本效果较好,而且对显存影响不大。下面就是模型测试代码:
import whispermodel = whisper.load_model(\"turbo\")result = model.transcribe(\"audio.mp3\")print(result[\"text\"])\"turbo\"是模型的名称,如果想换其他版本只需改这里即可。如要部署large版本就改为:model = whisper.load_model(\"large\");“audio.mp3”改成需要测试的音频文件就好了,注意要和创建的py文件在同一个目录;最后print打印出测试结果。

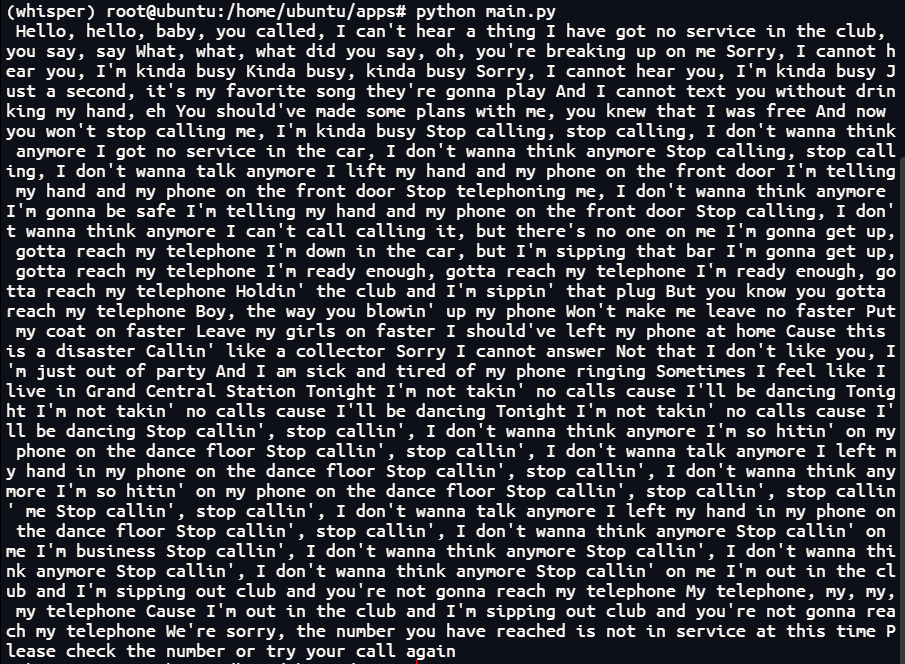
最后附上GitHub链接 ,希望大家早日部署自己的whisper,有疑惑欢迎在评论区讨论。

