LLaMA-Factory微调大模型_llama factory训练数据集怎么加上下文
LLaMA-Factory安装
github 下载 LLaMA-Factory项目



创建虚拟环境
conda create -n llama_factory python==3.10 激活
activate llama_factorytorch 安装
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia依赖安装
pip install requirements.txt
解决方案:
pip install -r F:\\conda_work\\LLaMA-Factory-main\\requirements.txt

pip install -e .[metrics]
检测 llamafactory 命令有哪些
llamafactory-cli train -h 
启动
llamafactory-cli webui如果要开启 gradio的share功能,或者修改端口号
// 改端口 改IP 端口默认是7860 GRADIO_SHARE是允许远程访问 USE_MODELSCOPE_HUB设为1,表示模型来源是ModelScopeUSE_MODELSCOPE_HUB=1 CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 GRADIO_SERVER_PORT=7860 

设置中文语言

下载模型
下载开源模型


微调数据集
偏好数据
sft微调一般用alpaca格式,dpo优化的偏好数据一般用sharegpt 格式
DPO优化偏好数据集
下面是DPO优化偏好数据集示例:
https://huggingface.co/datasets/hiyouga/DPO-En-Zh-20k/viewer/zh?row=5
HelpSteer2
英伟达开源的HelpSteer2
https://huggingface.co/datasets/nvidia/HelpSteer2
论文:https://arxiv.org/pdf/2406.08673
数据集注册
数据集格式






自定义数据集
创建 dataset_info.json 文件,这个文件需要放到 LLaMA-Factory-main\\data 目录下

我们用longgeai的甄嬛数据集进行测试
我们先下载alpaca格式的 huanhuan.json数据集
可以在这儿下载数据集进行测试:https://www.modelscope.cn/datasets/longgeai3x3/huanhuan-chat/files

将下载的 huanhuan.json文件放到data目录

然后打开 dataset_info.json 文件,将 huanhuan.json 注册进去
\"huanhuan_chat\": { \"file_name\": \"huanhuan.json\" },
保存之后在界面上就可以找到

点击预览数据集可以查看数据集的格式

微调
对话模版 选择 qwen 是因为我这里的底座模型选择的是qwen系列的
微调方法:一般选择lora ,显卡的要求较低
量化等级:如果 Qlora 这里就要选择量化等级
训练阶段:做私有知识库就选sft
数据集:可以选择自定义的,后文会介绍如何自定义
批处理大小:是根据显卡发小以及数据集的大小进行调整的
计算类型:老显卡不支持bf16


微调中断续调
命令
llamafactory-cli eval 是评估模型命令
llamafactory-cli train 是训练模型命令
llamafactory-cli api 是api服务命令
需要调整对应参数即可
llamafactory-cli train ` --stage sft ` --do_train True ` --model_name_or_path Qwen/Qwen2.5-Coder-0.5B ` --preprocessing_num_workers 16 ` --finetuning_type lora ` --template default ` --flash_attn auto ` --dataset_dir data ` --dataset huanhuan_chat ` --cutoff_len 2048 ` --learning_rate 5e-05 ` --num_train_epochs 3.0 ` --max_samples 100000 ` --per_device_train_batch_size 2 ` --gradient_accumulation_steps 8 ` --lr_scheduler_type cosine ` --max_grad_norm 1.0 ` --logging_steps 5 ` --save_steps 100 ` --warmup_steps 0 ` --packing False ` --report_to none ` --output_dir saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-04-09-15-04-44 ` --bf16 True ` --plot_loss True ` --trust_remote_code True ` --ddp_timeout 180000000 ` --include_num_input_tokens_seen True ` --optim adamw_torch ` --lora_rank 8 ` --lora_alpha 16 ` --lora_dropout 0 ` --lora_target all也可以将命令放到yaml文件中 llamafactory-cli train 执行yaml
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml如果是windows下,在cmd窗口中,把命令中\\和换行删掉,当成一行命名即可
如果你要使用的话 需要改三处地方,
第一处是模型Qwen/Qwen/Qwen2.5-Coder-0.5B ,
第二处是训练路径 F:\\conda_work\\LLaMA-Factory-main\\saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-03-17-15-51-59\\checkpoint-200,
第三处是输出 saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-03-17-15-51-59
llamafactory-cli train --stage sft --do_train True --model_name_or_path Qwen/Qwen/Qwen2.5-Coder-0.5B --preprocessing_num_workers 16--finetuning_type lora --template qwen --flash_attn auto --dataset_dir data --dataset huanhuan_chat --cutoff_len 1024 --learning_rate 5e-05 --num_train_epochs 3.0 --max_samples 100000 --per_device_train_batch_size 2 --gradient_accumulation_steps 8 --lr_scheduler_type cosine --max_grad_norm 1.0 --logging_steps 5 --save_steps 100 --warmup_steps 0 --optim adamw_torch --packing False--report_to none --resume_from_checkpoint F:\\conda_work\\LLaMA-Factory-main\\saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-03-17-15-51-59\\checkpoint-200--output_dir saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-03-17-15-51-59 --fp16True --plot_loss True --ddp_timeout 180000000 --include_num_input_tokens_seen True --quantization_bit 4 --quantization_method bitsandbytes --lora_rank 8 --lora_alpha 16 --lora_dropout 0 --lora_target all也可以 这个不指定checkpoint ,选择的是 --output_dir saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-04-09-15-04-44 程序会自动找到这个文件夹下的checkpoint开始继续训练
这个命令就是在界面上中断之后点击的命令预览处复制出来的
llamafactory-cli train --stage sft --do_train True --model_name_or_path Qwen/Qwen2.5-Coder-0.5B --preprocessing_num_workers 16 --finetuning_type lora --template default --flash_attn auto --dataset_dir data --dataset huanhuan_chat --cutoff_len 2048 --learning_rate 5e-05 --num_train_epochs 3.0 --max_samples 100000 --per_device_train_batch_size 2 --gradient_accumulation_steps 8 --lr_scheduler_type cosine --max_grad_norm 1.0 --logging_steps 5 --save_steps 100 --warmup_steps 0 --packing False --report_to none --output_dir saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-04-09-15-04-44 --bf16 True --plot_loss True --trust_remote_code True --ddp_timeout 180000000 --include_num_input_tokens_seen True --optim adamw_torch --lora_rank 8 --lora_alpha 16 --lora_dropout 0 --lora_target all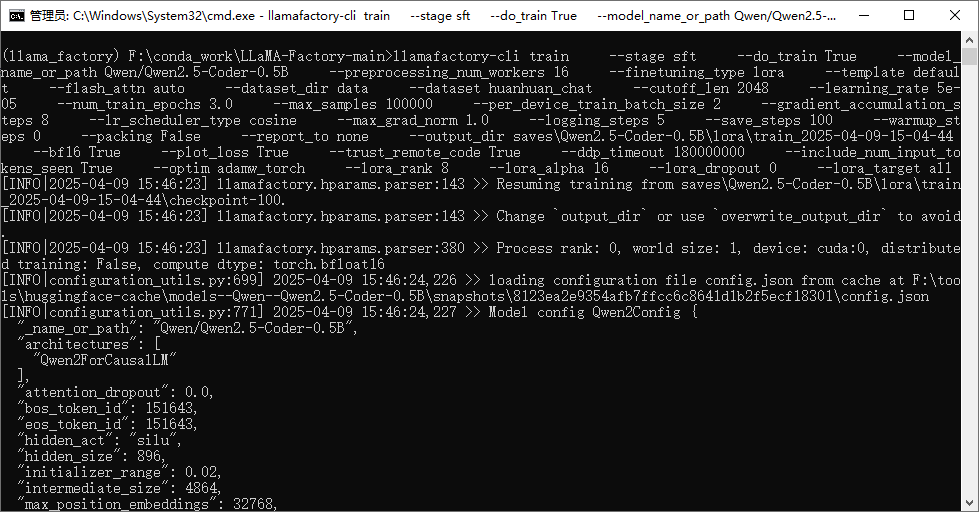
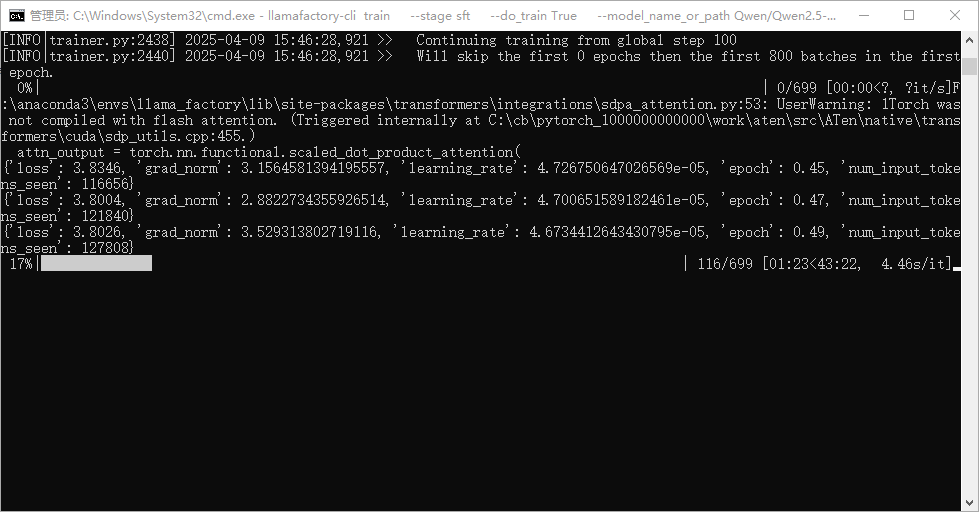
中断继续训练的参数解释
存点是100步,但是在150步中断,会从100步开始继续
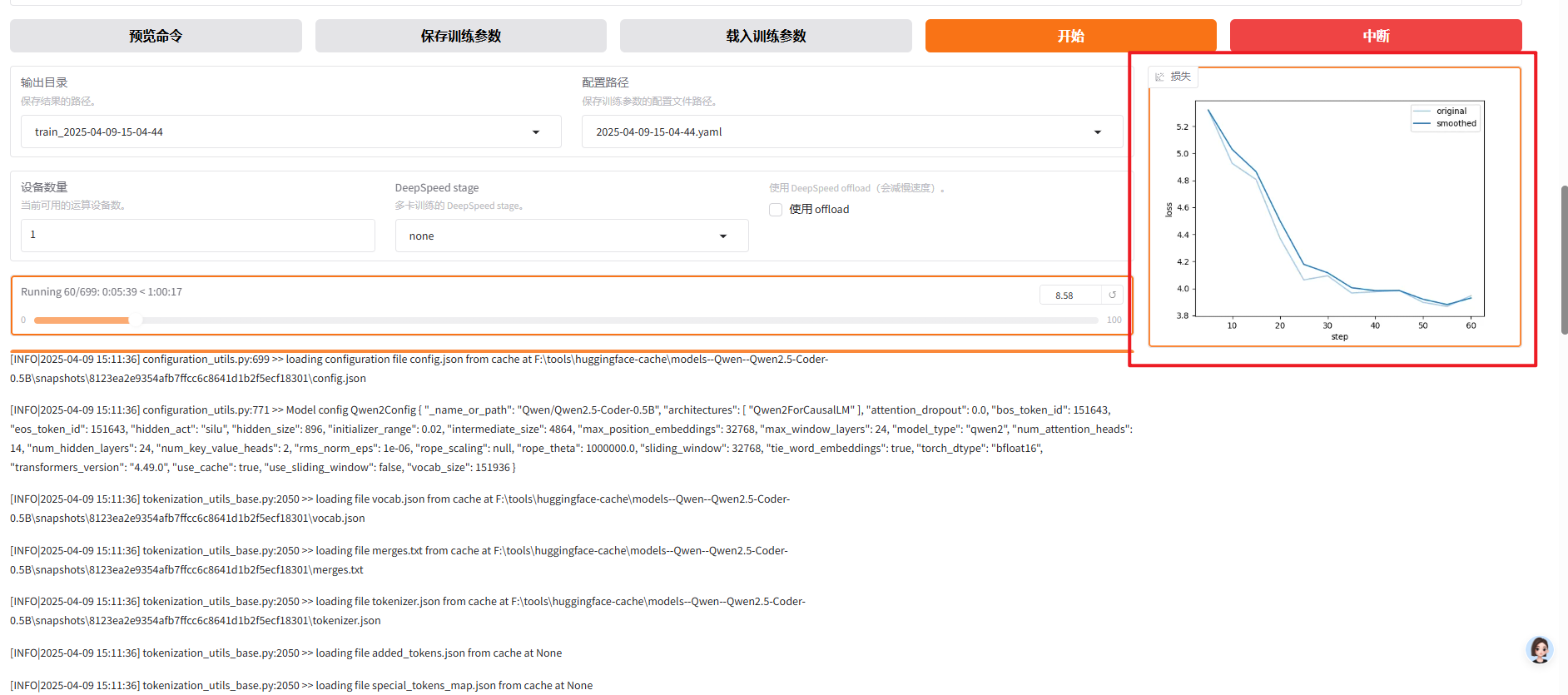
saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-04-09-15-04-44/checkpoint-100--output_dir new_dir#--resume_lora_training #这个可以不设置#如果不需要换output_dir,另外两条命令都不加,脚本会自动寻找最新的 checkpoint--output_dir saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-04-09-15-04-44当然使用命令训练,没有用webui看loss那么直观,需要加一个命令
--plot_loss # 添加此参数以生成loss图可以通过添加命令让训练集从头开始训练,适合用新数据集继续训练
#lora的保存路径在llama-factory根目录下,如saves\\Qwen2.5-Coder-0.5B\\lora\\train_2025-03-17-15-51-59\\checkpoint-100--adapter_name_or_path lora_save_patch模型评估
如果使用原默认配置文件也可以,但是需要科学上网以及配置Hugging Face账号,让其自动下载评估模型,太繁琐了,我这里在modelscope 下载的评估模型
下载开源模型教程
https://modelscope.cn/models/LLM-Research/Meta-Llama-3.1-8B-Instruct
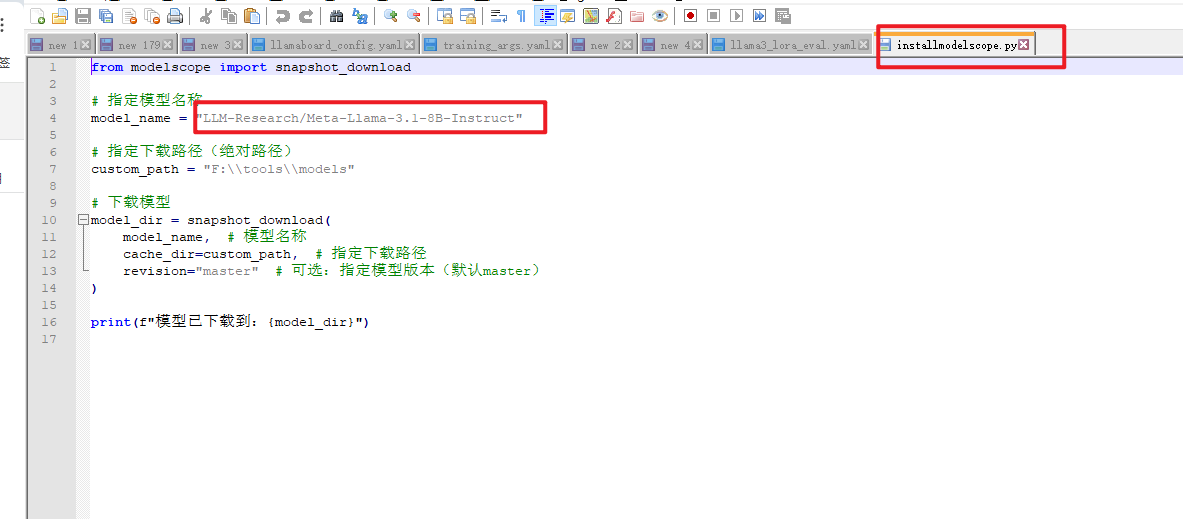
使用模型下载脚本
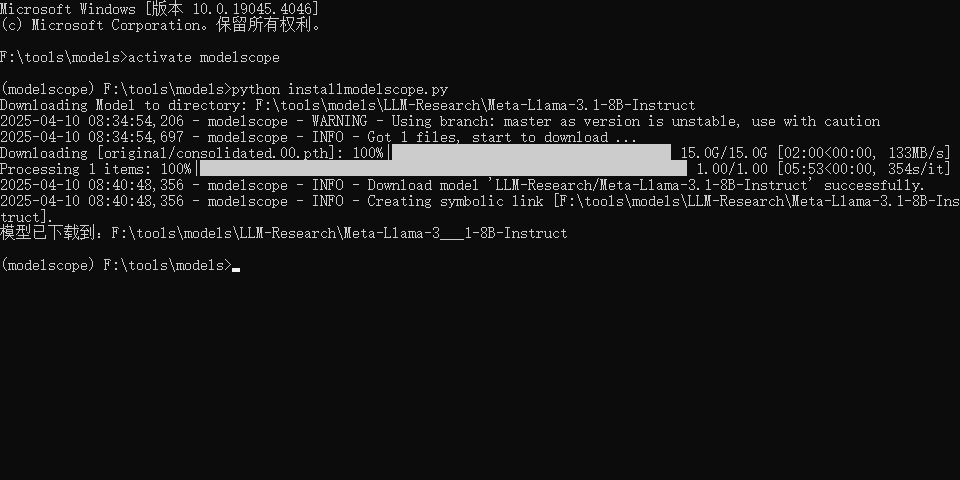
下载完成
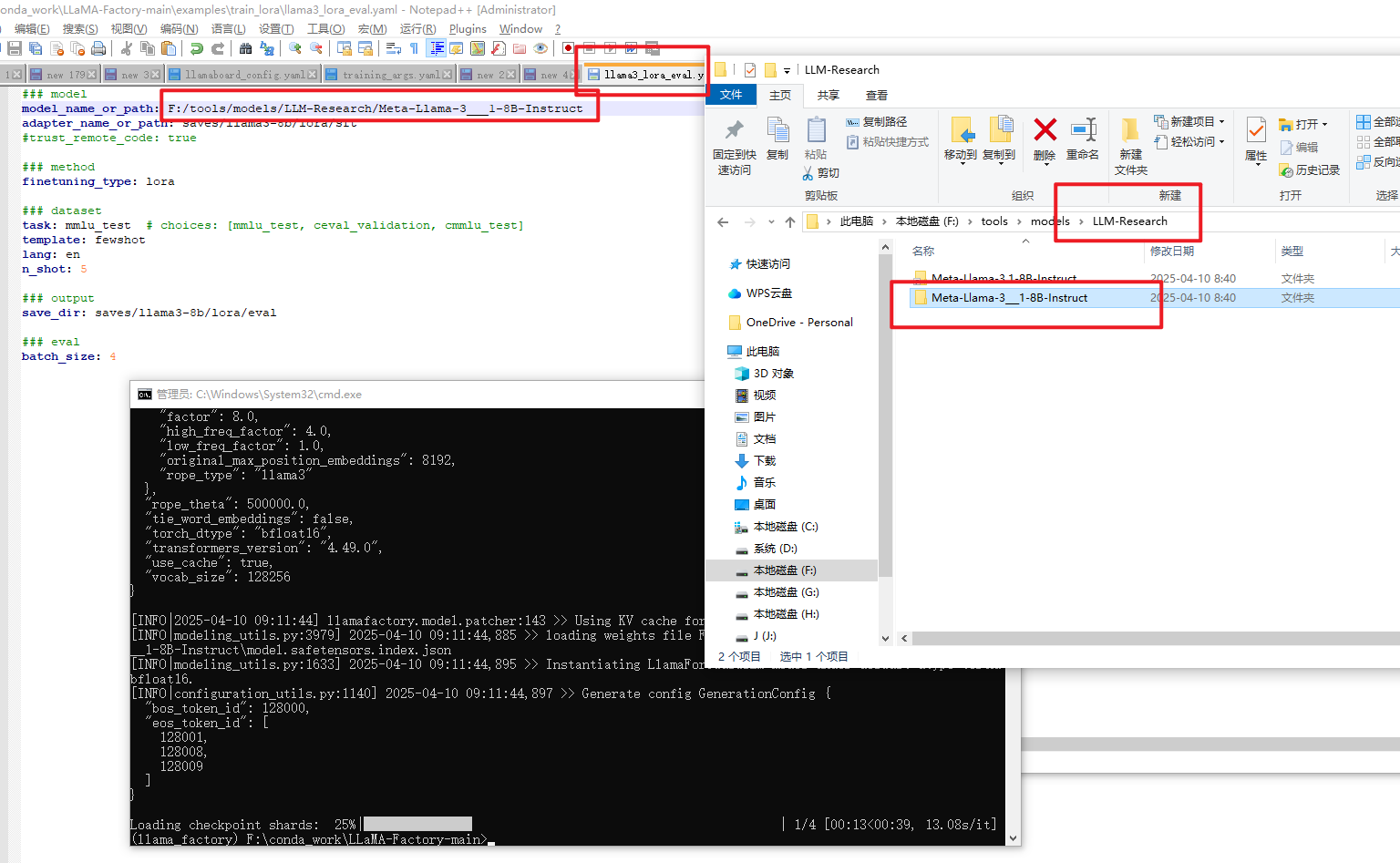
修改llama3_lora_eval.yaml配置文件
修改内容如下:将模型地址改为你本地的路径
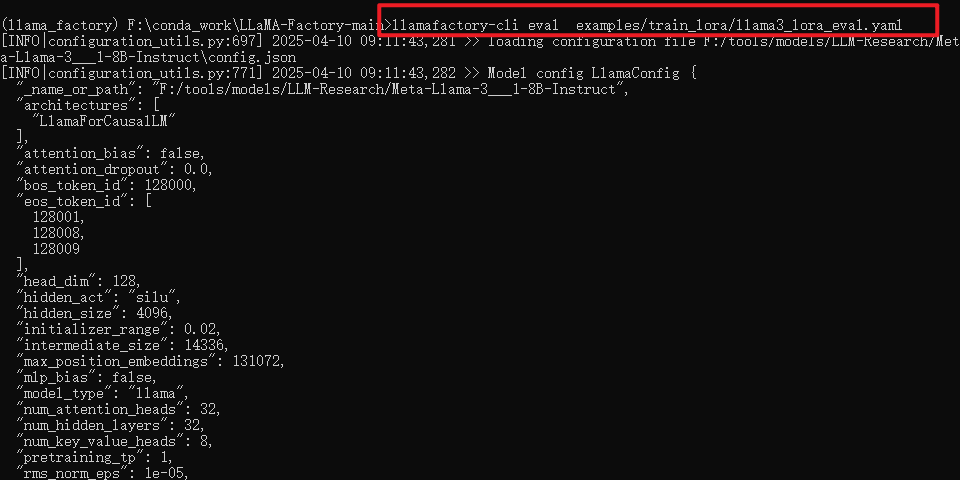
开始评估
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yamlllamafactory-cli eval 是评估模型命令
开源自动化评测项目:
https://github.com/open-compass/opencompass
https://github.com/EleutherAI/lm-evaluation-harness/tree/main
批量推理
先安装相关环境
pip install jieba #中文文本分词库pip install rouge-chinese # 衡量文本摘要质量的标准pip install nltk #自然语言处理工具包(Natural Language Toolkit)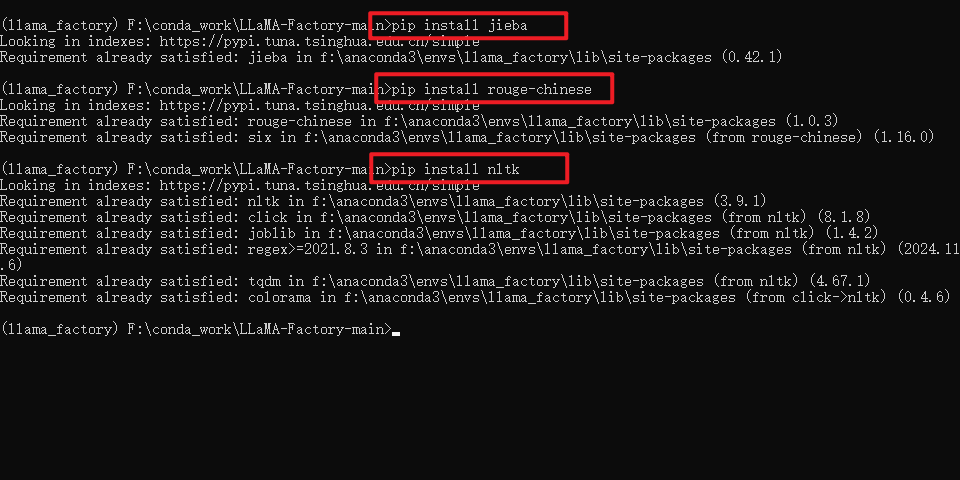
可以命令操作也可以页面操作
命令解释
llamafactory-cli train \\--stage sft \\ #监督微调--do_predict \\ #现在是预测模式--model_name_or_path F:/tools/models/LLM-Research/Meta-Llama-3___1-8B-Instruct \\ #底模路径--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \\ #lora路径--eval_dataset alpaca_gpt4_zh,identity,adgen_local \\ #评测数据集--dataset_dir ./data \\ #数据集路径推理示例命令预览windows下的测试命令:--template qwen \\ #提示词模版,比如llama3 ,qwen 和训练微调一样--finetuning_type lora \\ #微调方式 lora--output_dir ./saves/LLaMA3-8B/lora/predict \\ #评估预测输出文件夹--overwrite_cache \\--overwrite_output_dir \\--cutoff_len 1024 \\ #提示词截断长度--preprocessing_num_workers 16 \\ #预处理数据的线程数量--per_device_eval_batch_size 1 \\ #每个设备评估时的batch size--max_samples 20 \\ #每个数据集采样多少用于预测对比--predict_with_generate #现在用于生成文本页面操作
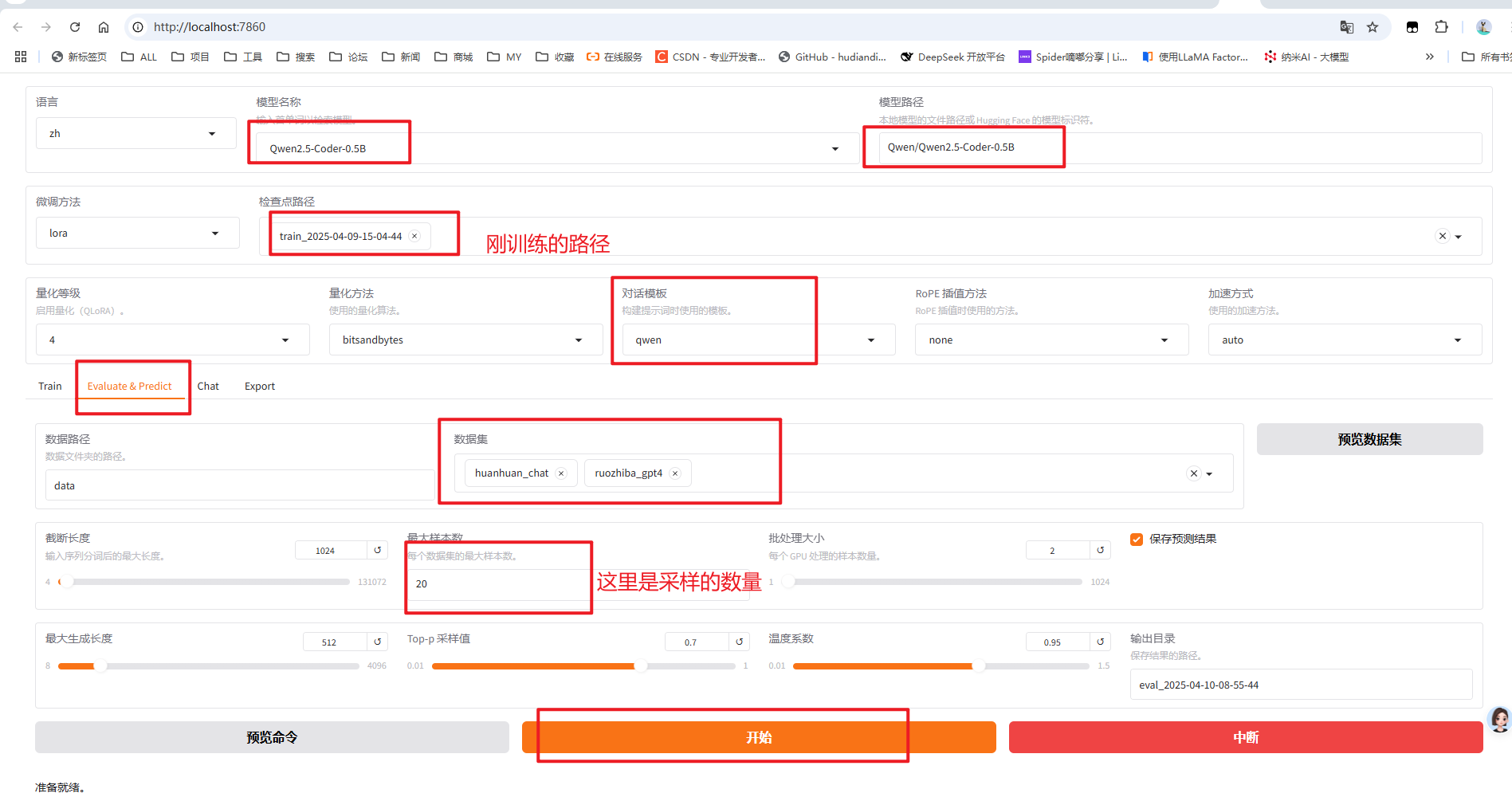
数据集:这里最好是根据行业知识和企业私有知识,构建一个测试数据集
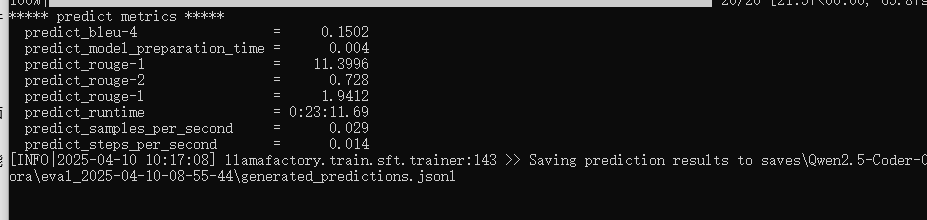
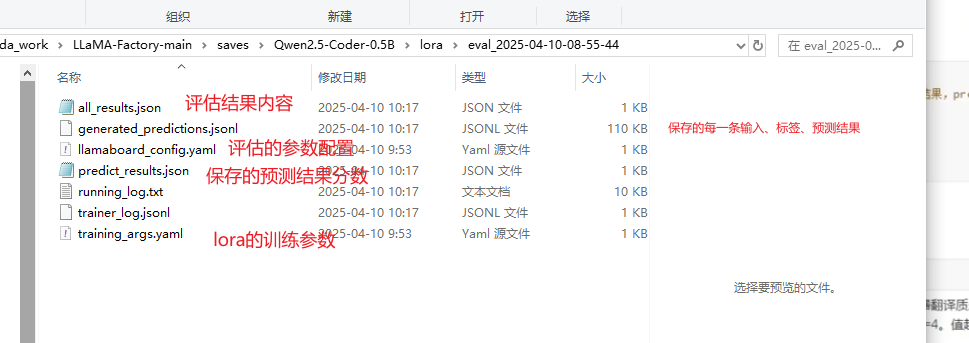
批量推理结果
llamafactory的api服务
训练好后,也可以将模型的能力形成一个可访问的服务,通过API 来调用,接入到langchian
或者其他下游业务中,项目也自带了这部分能力。
API 实现的标准是参考了OpenAI的相关接口协议,基于uvicorn服务框架进行开发, 使用如下的方式启动
llamafactory-cli api 是api服务命令
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \\--model_name_or_path /llama3/Meta-Llama-3-8B-Instruct \\--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \\--template llama3 \\--finetuning_type lora模型合并导出
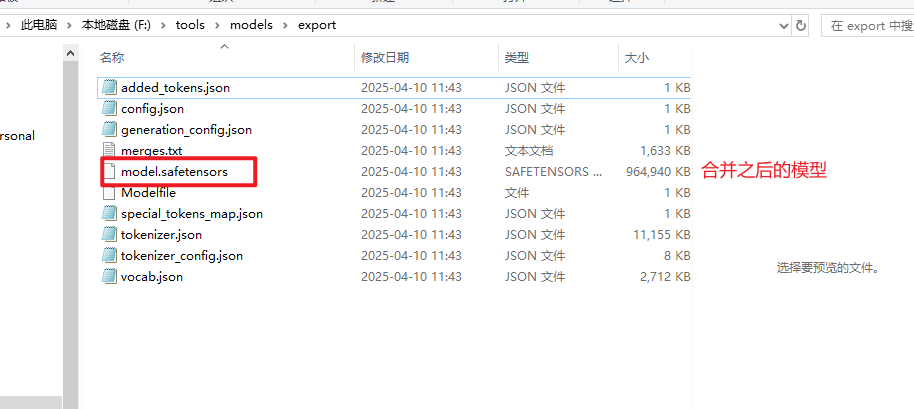
合并导出全精度模型
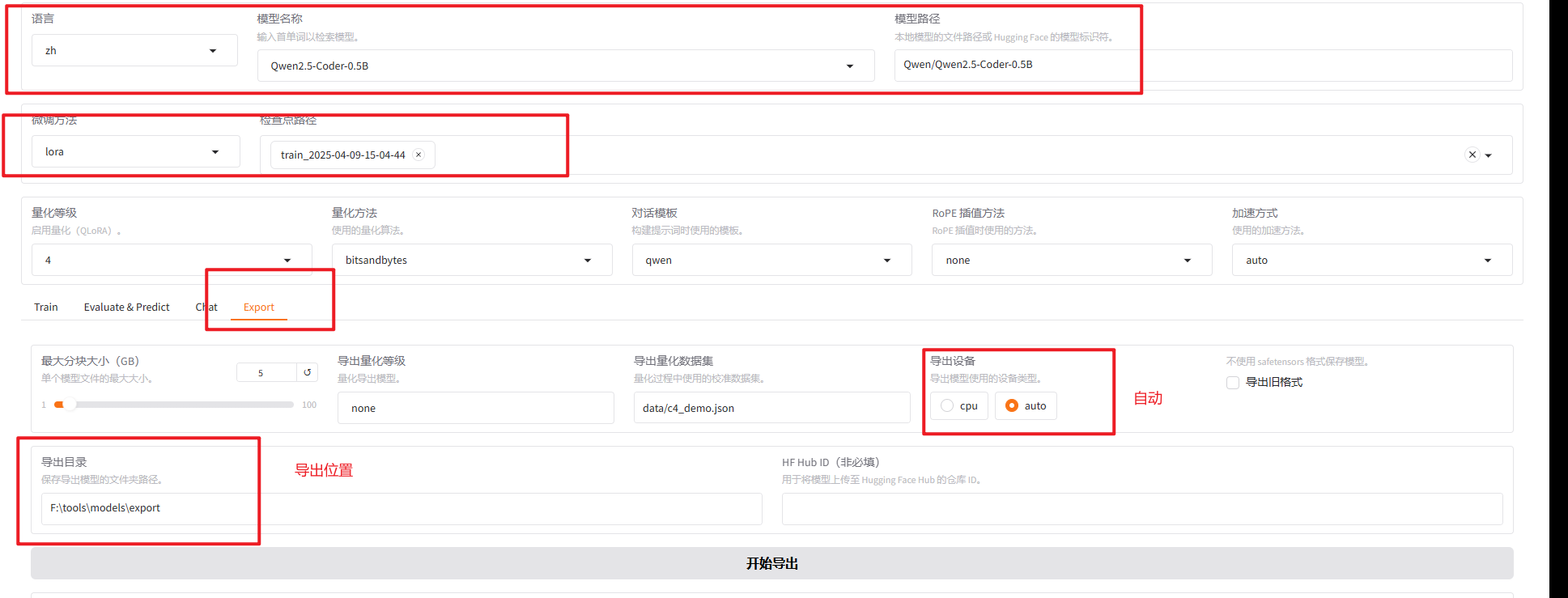

如果需要量化的模型
这里量化4bit (图上少标注了一点就是导出路径更改为新的路径)
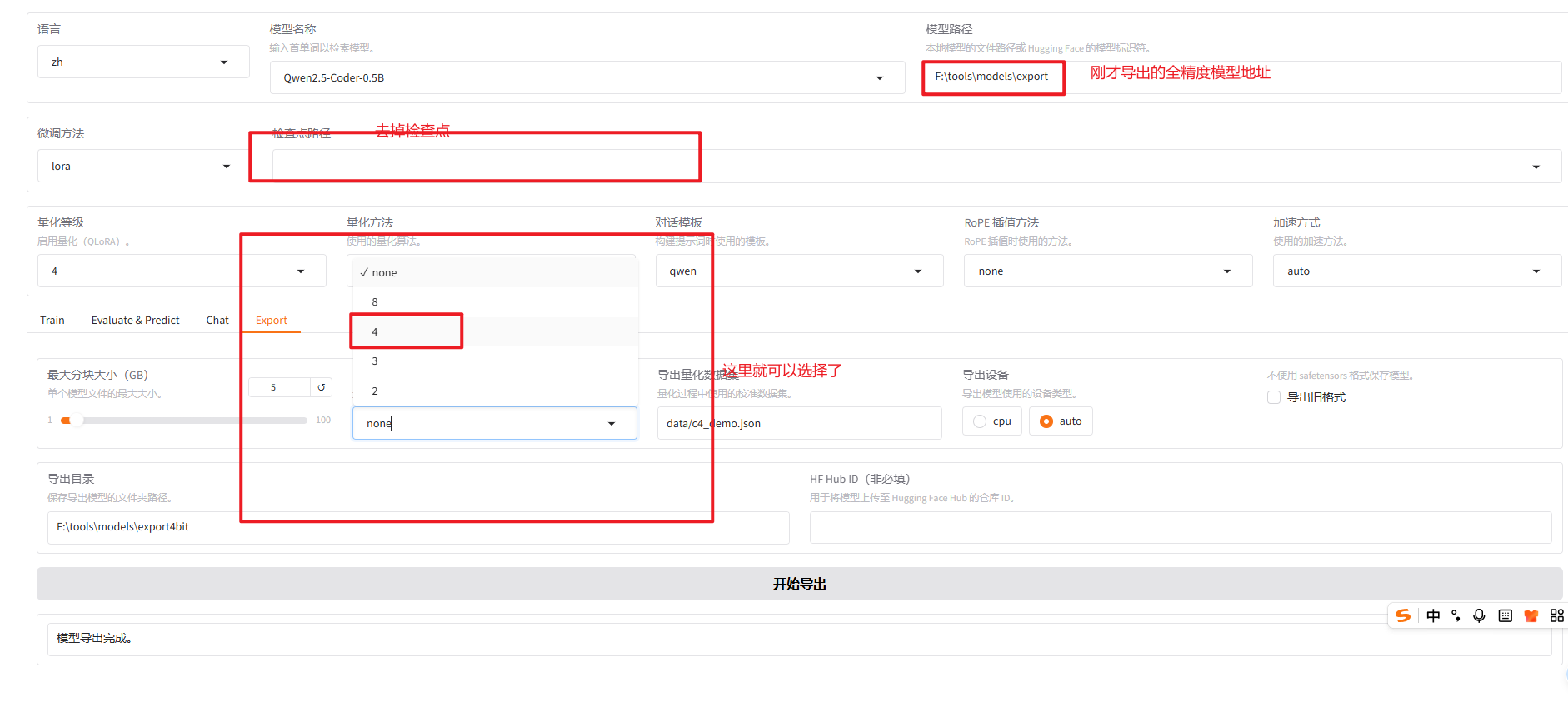
导出成功
踩坑记录
- 点击开始训练报错
页面文件太小,无法完成操作。是因为虚拟内存不够,分配虚拟内存即可
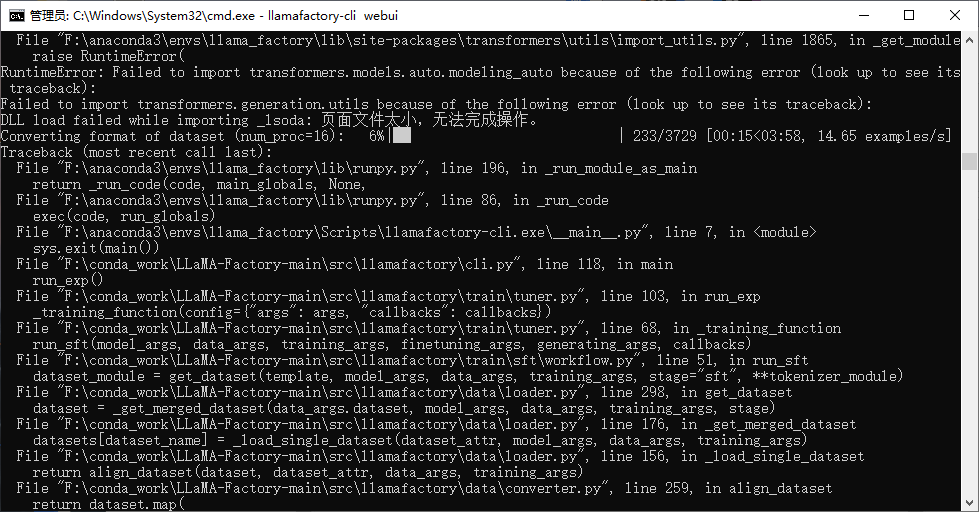

更改为以下
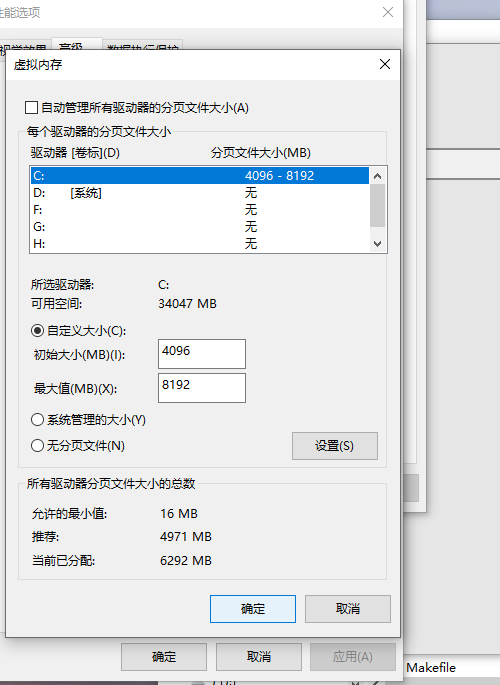
重新开始训练
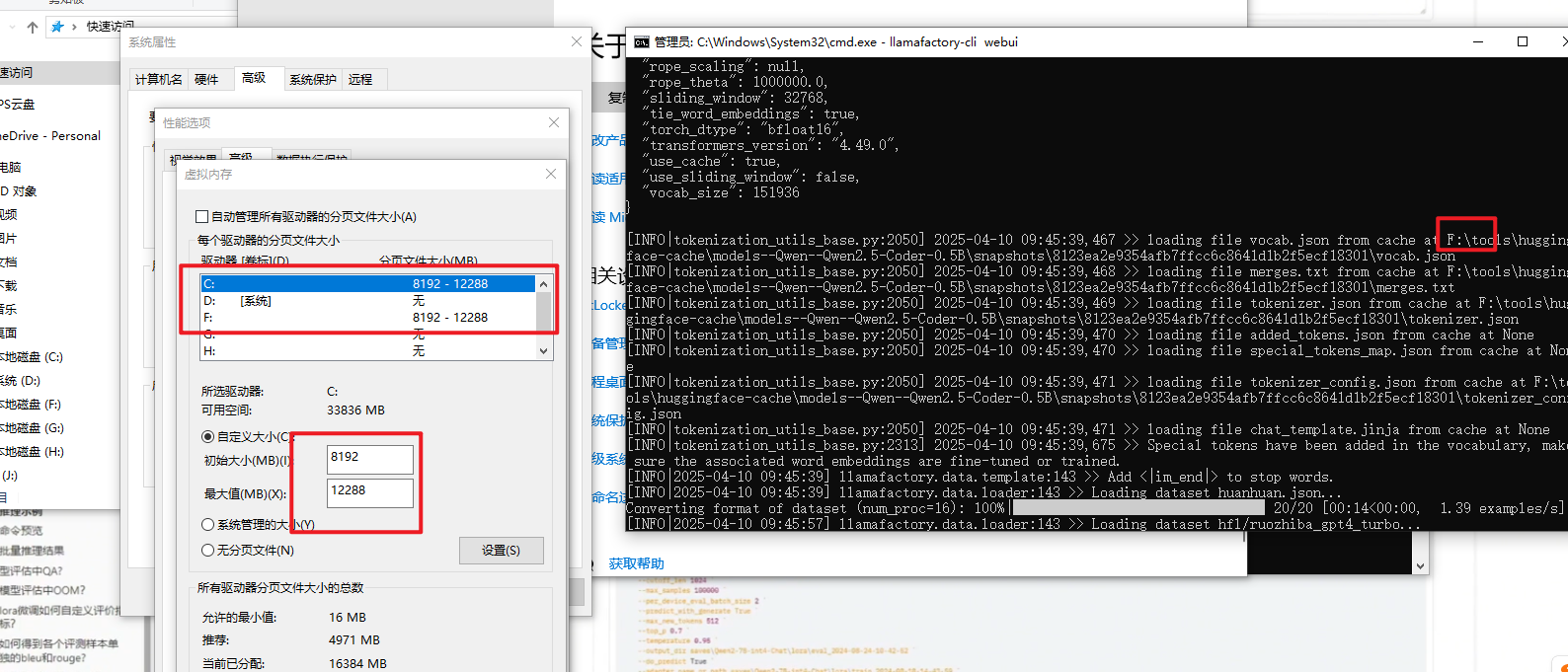
如果训练模型按此虚拟内存解决后,推理模型时有报此问题,将虚拟内存继续调大就可以了
2.导出模型报错
During handling of the above exception, another exception occurred:Traceback (most recent call last): File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\queueing.py\", line 715, in process_events response = await route_utils.call_process_api( File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\route_utils.py\", line 322, in call_process_api output = await app.get_blocks().process_api( File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\blocks.py\", line 2103, in process_api result = await self.call_function( File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\blocks.py\", line 1662, in call_function prediction = await utils.async_iteration(iterator) File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\utils.py\", line 735, in async_iteration return await anext(iterator) File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\utils.py\", line 729, in __anext__ return await anyio.to_thread.run_sync( File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\anyio\\to_thread.py\", line 56, in run_sync return await get_async_backend().run_sync_in_worker_thread( File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\anyio\\_backends\\_asyncio.py\", line 2461, in run_sync_in_worker_thread return await future File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\anyio\\_backends\\_asyncio.py\", line 962, in run result = context.run(func, *args) File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\utils.py\", line 712, in run_sync_iterator_async return next(iterator) File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\gradio\\utils.py\", line 873, in gen_wrapper response = next(iterator) File \"F:\\conda_work\\LLaMA-Factory-main\\src\\llamafactory\\webui\\components\\export.py\", line 105, in save_model export_model(args) File \"F:\\conda_work\\LLaMA-Factory-main\\src\\llamafactory\\train\\tuner.py\", line 119, in export_model model = load_model(tokenizer, model_args, finetuning_args) # must after fixing tokenizer to resize vocab File \"F:\\conda_work\\LLaMA-Factory-main\\src\\llamafactory\\model\\loader.py\", line 126, in load_model patch_config(config, tokenizer, model_args, init_kwargs, is_trainable) File \"F:\\conda_work\\LLaMA-Factory-main\\src\\llamafactory\\model\\patcher.py\", line 111, in patch_config configure_quantization(config, tokenizer, model_args, init_kwargs) File \"F:\\conda_work\\LLaMA-Factory-main\\src\\llamafactory\\model\\model_utils\\quantization.py\", line 132, in configure_quantization check_version(\"optimum>=1.17.0\", mandatory=True) File \"F:\\conda_work\\LLaMA-Factory-main\\src\\llamafactory\\extras\\misc.py\", line 87, in check_version require_version(requirement, hint) File \"F:\\anaconda3\\envs\\llama_factory\\lib\\site-packages\\transformers\\utils\\versions.py\", line 104, in require_version raise importlib.metadata.PackageNotFoundError(importlib.metadata.PackageNotFoundError: No package metadata was found for The \'optimum>=1.17.0\' distribution was not found and is required by this application.To fix: run `pip install optimum>=1.17.0`.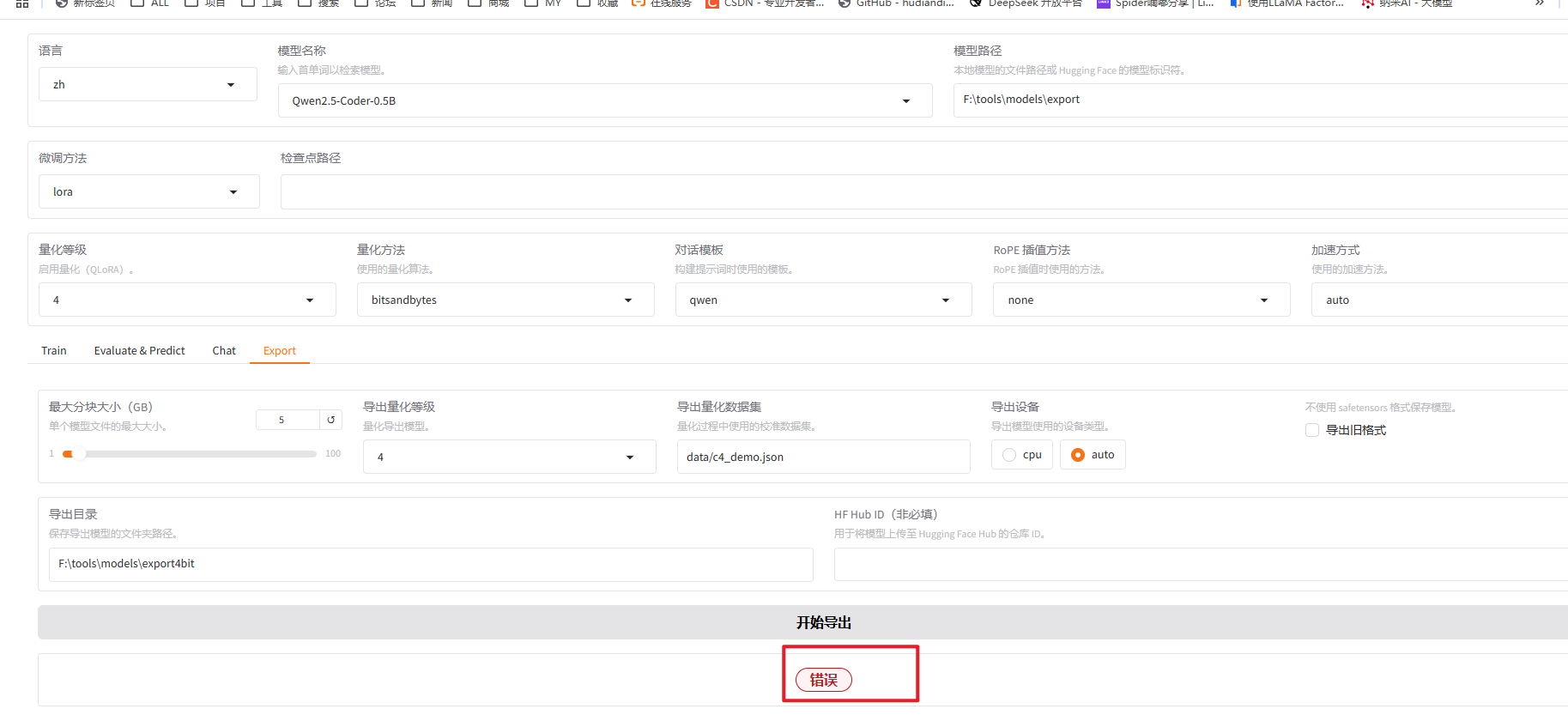

安装完成后重启llamafactory
然后再点击导出