从淘宝推荐到微信搜索:查找算法如何支撑亿级用户——动画可视化数据结构之查找算法_数据结构10个 动画 查找
本篇技术博文摘要 🌟
本文通过动画可视化深入解析数据结构中的核心查找算法,从基础概念到高阶应用,全面覆盖顺序查找、折半查找、分块查找、B树/B+树及散列查找的核心原理与实现细节。文章以动态演示为核心工具,直观展现算法执行过程与数据结构演化,帮助读者突破抽象理论难点。
内容核心:
基础算法:
顺序查找:从暴力遍历到哨兵优化,结合判定树分析ASL(平均查找长度),探讨有序表场景下的效率提升策略。
折半查找:通过二分思想与判定树模型,解析有序数据的高效检索逻辑,并给出代码实现与时间复杂度推导。
进阶索引结构:
分块查找:融合顺序与折半查找优势,分析块划分对效率的影响。
B树与B+树:从多叉查找树的平衡规则出发,动态演示插入、删除操作如何维持树结构稳定;对比B+树的特性(如叶子节点链表),阐释其在数据库索引中的核心地位。
散列查找与冲突解决:
详解哈希函数设计原则(如除留余数法),通过动画模拟拉链法、开放定址法、再散列法的冲突处理过程,揭示哈希表动态扩容与数据分布规律。
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员,希望能够与各位在此共同成长。
数据结构之查找算法动画演示:
B树
通过动画可视化算法B+树
二分查找/折半查找
封闭hash查找(封闭散列寻址)
Open哈希表(封闭寻址)算法动态图例结合代码全程展示
动画可视化之顺序查找 ×

上节回顾
目录
本篇技术博文摘要 🌟
引言 📘
数据结构之查找算法动画演示:
上节回顾
1.查找
查找的基本概念
对查找表的常见操作:
查找算法的评价指标:
1.1动画可视化顺序查找
定义:
顺序查找的代码实现:
顺序查找的代码实现(哨兵):
对有序表进行顺序查找的优化:
用查找判定树分析ASL:
顺序查找的优化(被查概率不相等):
1.2动画可视化折半查找
算法思想:
代码实现:
查找效率分析:
折半查找判定树的构造:
1.3动画可视化之分块查找
算法思想:
查找效率分析:
1.4动画可视化之B树
m叉查找树:
那么该如何保证查找效率呢?
B树的定义:
B树的高度:
B树最大高度的另一种推导方法:
动画可视化之B树的插入删除
B树的插入:
B树的删除[结合原理看动画]:
1.5动画可视化之B+树
定义和性质:
一棵m阶的B+树需满足下列条件:
B+树的查找:
B+树和B树区别:
1.6动画可视化之散列(哈希)查找
定义:
处理冲突的方法——拉链法:
常见的散列函数:
动画可视化之处理冲突的方法——开放定址法:
处理冲突的方法——动画可视化之再散列法

1.查找
查找的基本概念
-
查找: 在数据集合中寻找满足某种条件的数据元素的过程称为查找
-
查找表(查找结构):用于查找的数据集合称为查找表,它由同一类型的数据元素(或记录)组成
-
关键字: 数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的。
对查找表的常见操作:
- 查找符合条件的数据元素
-
静态查找表
-
仅关注查找速度即可
-
- 插入、删除某个数据元素
-
动态查找表
-
除了查找速度,也要关注插/删操作是否方便实现
-
查找算法的评价指标:
-
查找长度:在查找运算中,需要对比关键字的次数称为查找长度
-
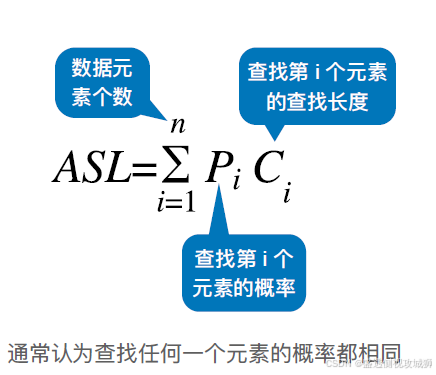
平均查找长度(ASL, Average Search Length ):所有查找过程中进行关键字的比较次数的平均值
-
ASL的数量级反应了查找算法的时间复杂度
-
评价一个查找算法的效率时,通常考虑查找成功、查找失败两种情况的ASL

1.1动画可视化顺序查找
动画可视化之顺序查找 ×
定义:
- 顺序查找,又叫“线性查找”,通常用于线性表。
- 算法思想:从头到尾依次往后找
顺序查找的代码实现:
typedef struct{ //查找表的数据结构(顺序表) ElemType *elem; //动态数组基址 int TableLen; //表的长度 }SSTable; //顺序查找 int Search_Seq(SSTable ST, ElemType key){ int i; for(i=0; i<ST.TableLen && ST.elem[i]!=key; ++i); //查找成功,则返回元素下标;查找失败,则返回-1 return i==ST.TableLen? -1 : i; }
顺序查找的代码实现(哨兵):
typedef struct{ //查找表的数据结构(顺序表) ElemType *elem; //动态数组基址 int TableLen; //表的长度 }SSTable; //顺序查找 int Search_Seq(SSTable ST, ElemType key){ ST.elem[0]=key; //“哨兵” int i; for(i=ST.TableLen; ST.elem[i]!=key; --i); //从后往前找 return i; //查找成功,则返回元素下标;查找失败,则返回0 }
- 优点:无需判断是否越界,效率更高


对有序表进行顺序查找的优化: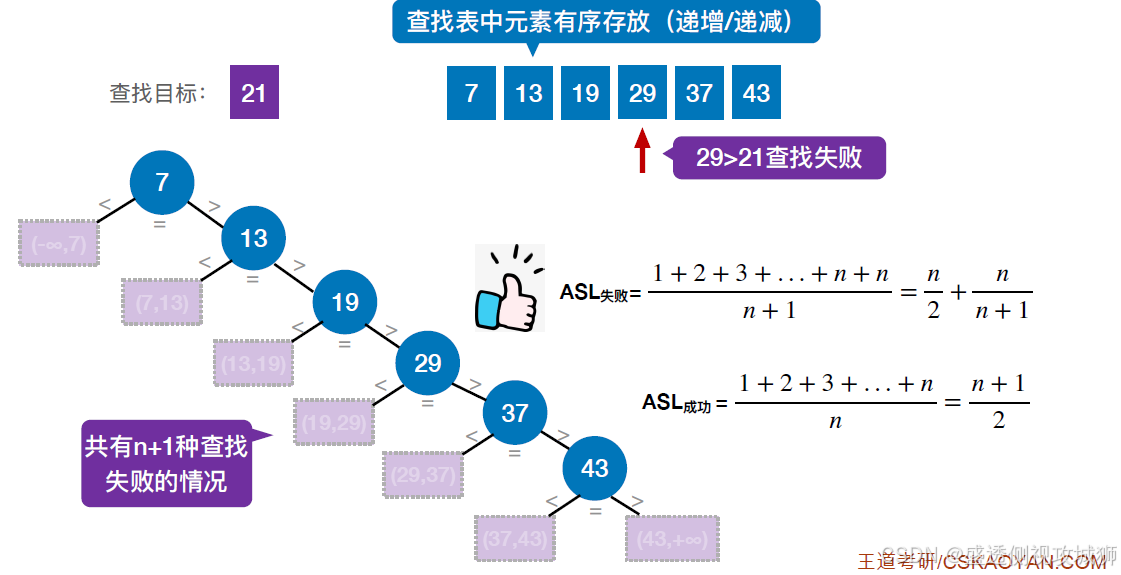
用查找判定树分析ASL:
一个成功结点的查找长度 = 自身所在层数
一个失败结点的查找长度 = 其父结点所在层数
默认情况下,各种失败情况或成功情况都等概率发生
顺序查找的优化(被查概率不相等):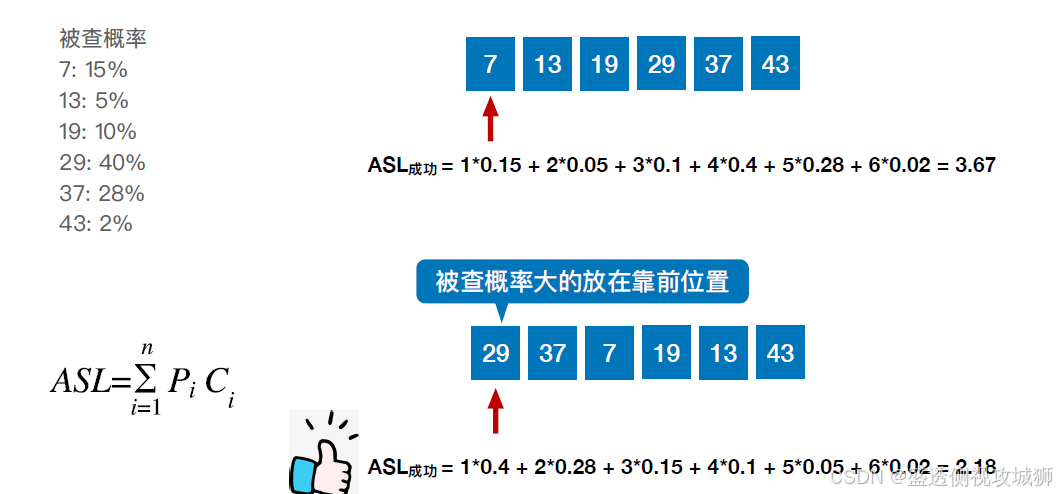

1.2动画可视化折半查找
二分查找/折半查找
算法思想:
- 折半查找,又称“二分查找”,仅适用于有序的顺序表。
- 查找成功:
- 注意:下面的mid向下取整
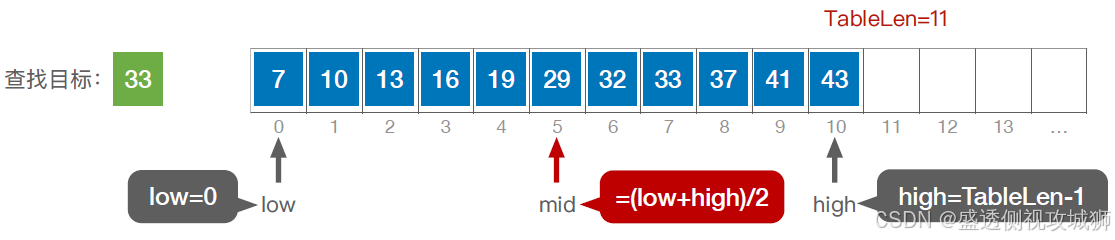
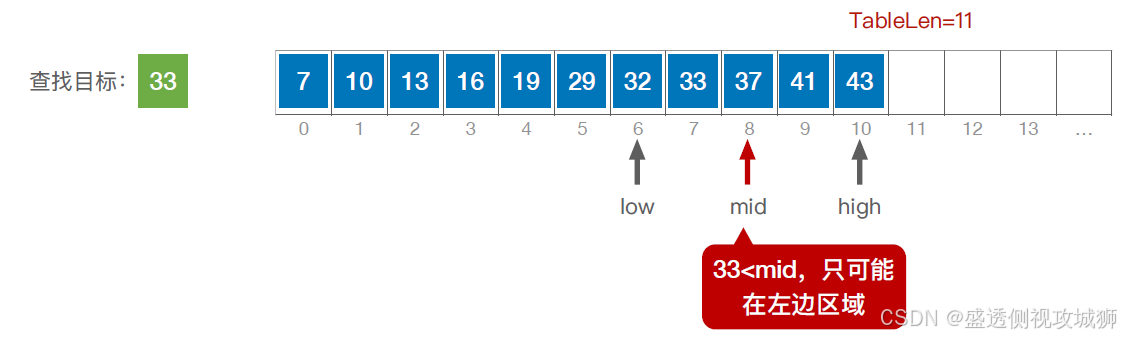
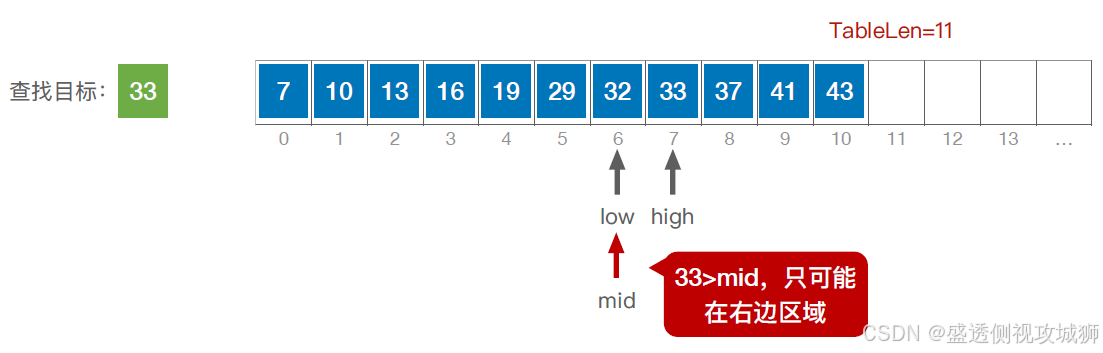
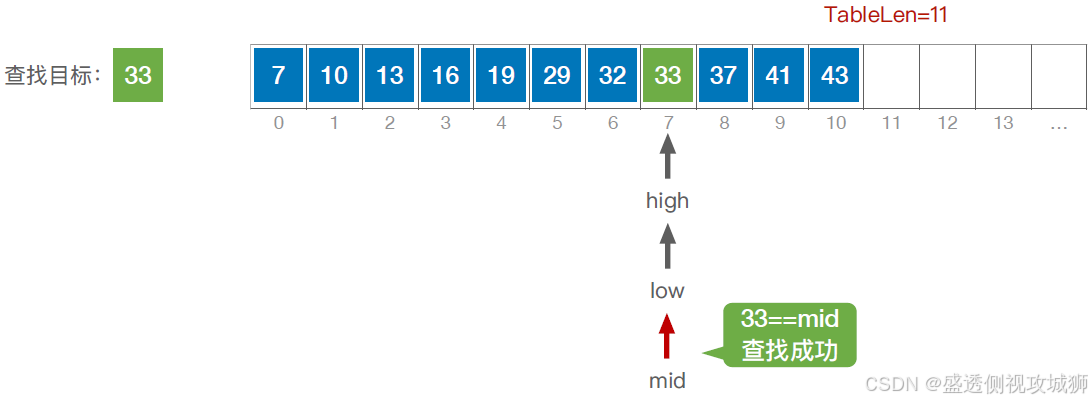
代码实现:
typedef struct{ //查找表的数据结构(顺序表) ElemType *elem; //动态数组基址 int TableLen; //表的长度 }SSTable; //折半查找 int Binary_Search(SSTable L, ElemType key){ int low=0, high=L.TableLen-1, mid; while(lowkey) high=mid-1; //从前半部分继续查找 else low=mid+1; //从后半部分继续查找 } return -1; //查找失败,返回-1 } //折半查找,又称“二分查找”,仅适用于有序的顺序表。 //顺序表拥有随机访问 的特性,链表没有查找效率分析: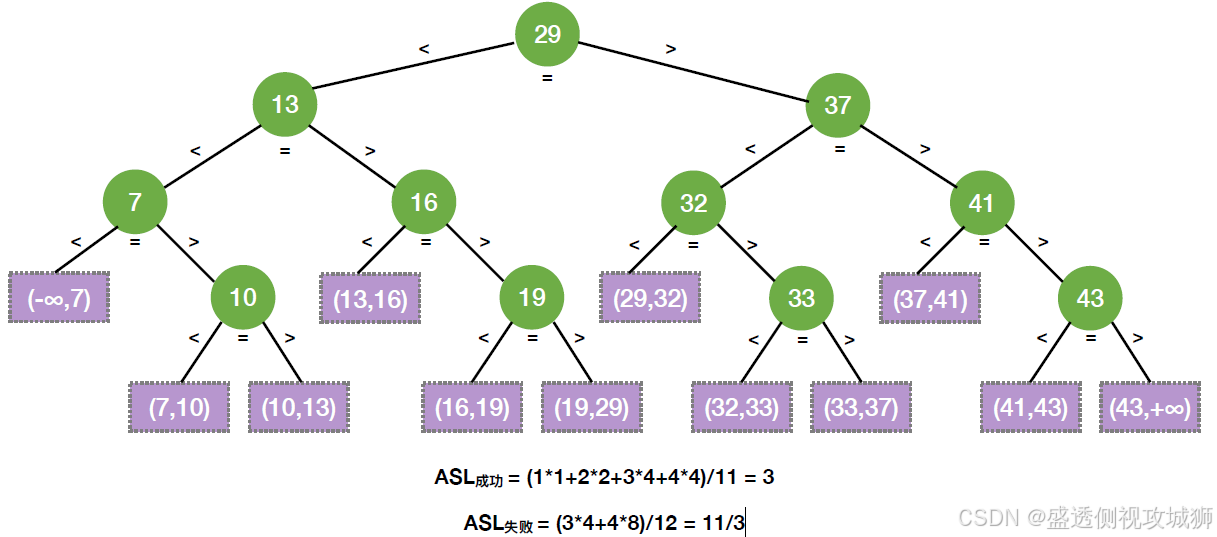
折半查找判定树的构造:
如果当前low和high之间有偶数个元素,则 mid 分隔后,左半部分比右半部分少一个元素
如果当前low和high之间有奇数个元素,则 mid 分隔后,左右两部分元素个数相等
折半查找的判定树中,mid = [(low + high)/2]则对于任何一个结点,必有:右树结点数-左子树结点数=0或1
折半查找的判定树一定是平衡二叉树
折半查找的判定树中,只有最下面一层是不满的因此,元素个数为n时树高h = [log2(n + 1)]
判定树结点关键字:左<中<右,满足二叉排序树的定义
失败结点:n+1个(等于成功结点的空链域数量)
折半查找的时间复杂度 = O(log2n)

1.3动画可视化之分块查找
算法思想: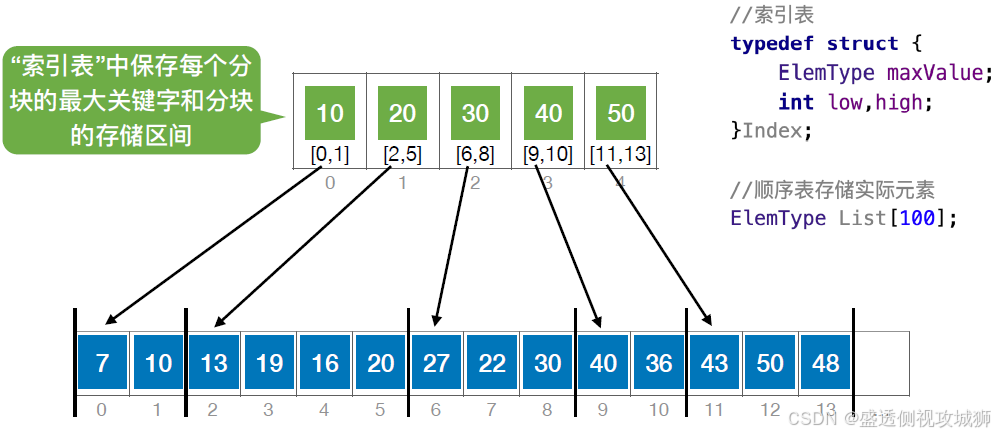
特点:块内无序、块间有序
分块查找,又称索引顺序查找,算法过程如下:
在索引表中确定待查记录所属的分块(可顺序、可折半)
在块内顺序查找
查找效率分析:

1.4动画可视化之B树
B树
m叉查找树:
实际上就是二叉查找树的拓展,结点多少有多少个分叉就是多少叉查找树
每个结点关键字的查找可以用顺序查找也可以用折半查找
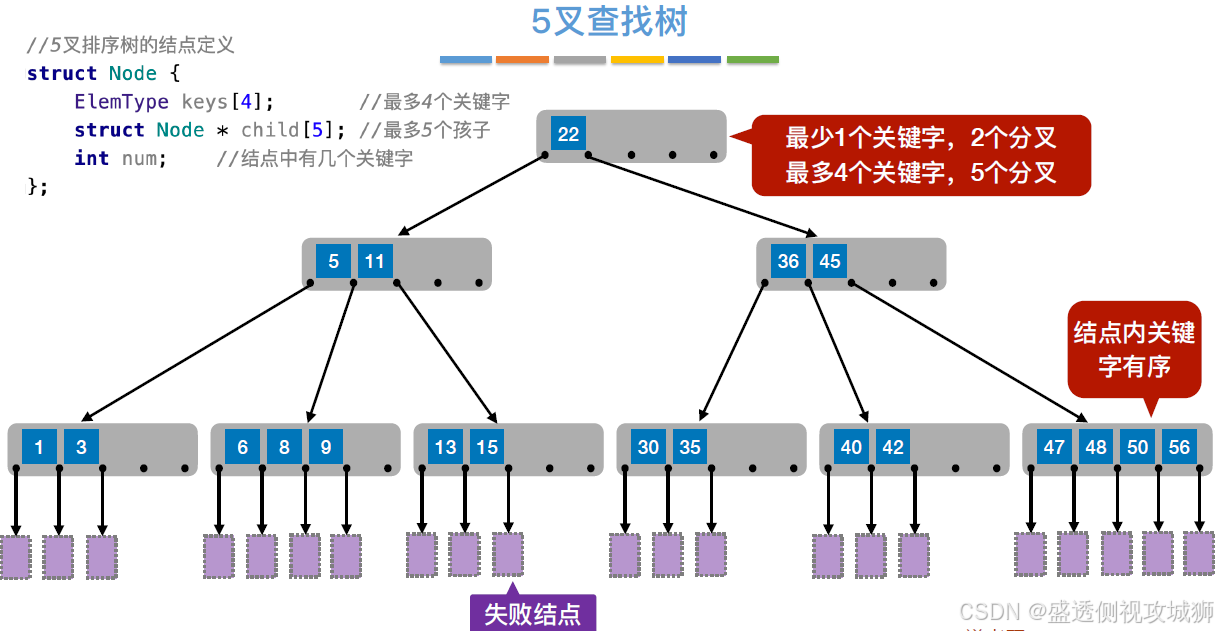
那么该如何保证查找效率呢?
- 若每个结点内关键字太少,导致树变高,要查更多层结点,效率低
策略:m叉查找树中,规定除了根结点外,任何结点至少有⌈m/2⌉个分叉,即至少含有⌈m/2⌉ − 1 个关键字
为什么不能保证根结点至少有⌈m/2⌉个分叉:如果整个树只有1个元素,根结点只能有两个分叉
- 不够“平衡”,树会很高,要查很多层结点
策略:m叉查找树中,规定对于任何一个结点,其所有子树的高度都要相同。
B树的定义:
- B树,又称多路平衡查找树,B树中所有结点的孩子个数的最大值称为B树的阶,通常用m表示。一棵m阶B树或为空树,或为满足如下特性的m叉树:
树中每个结点至多有m棵子树,即至多含有m-1个关键字。
若根结点不是终端结点,则至少有两棵子树。
除根结点外的所有非叶结点至少有⌈m/2⌉棵子树,即至少含有 ⌈m/2⌉-1(向上取整)个关键字。
所有非叶结点的结构如下:
其中,Ki(i = 1, 2,…, n)为结点的关键字,且满足K1 < K2 <…< Kn;Pi(i = 0, 1,…, n)为指向子树根结点的指针,且指针Pi-1所指子树中所有结点的关键字均小于Ki,Pi所指子树中所有结点的关键字均大于Ki,n(⌈m/2⌉- 1≤n≤m - 1)为结点中关键字的个数。
所有的叶结点都出现在同一层次上,并且不带信息(可以视为外部结点或类似于折半查找判定树的查找失败结点,实际上这些结点不存在,指向这些结点的指针为空)。
B树的高度: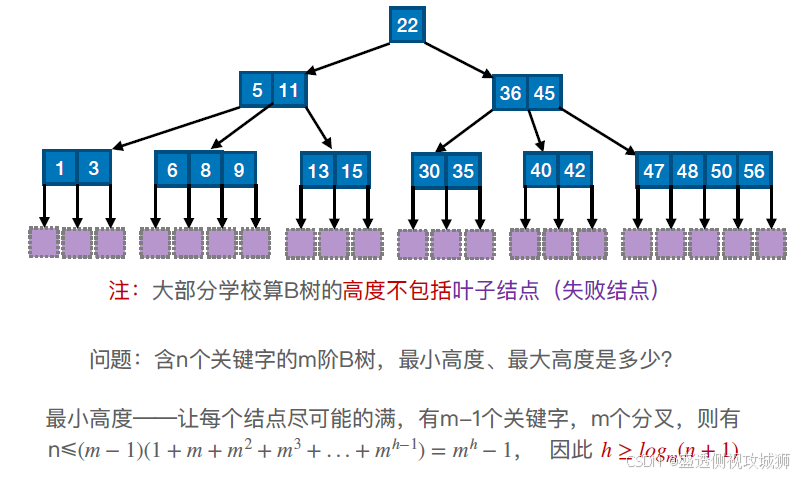
B树最大高度的另一种推导方法: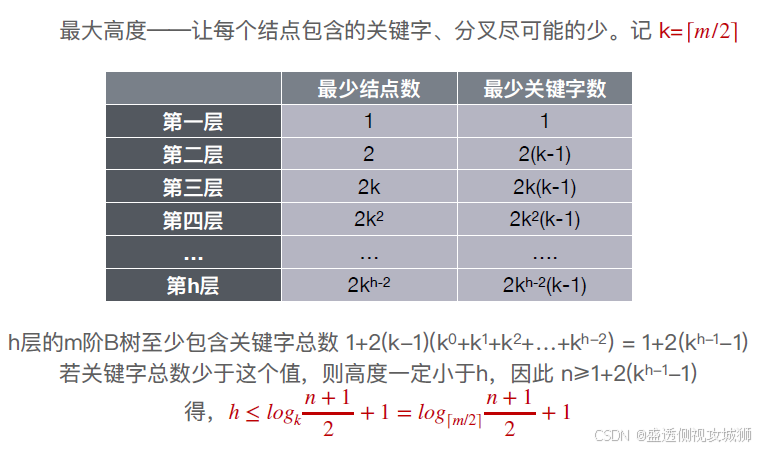
动画可视化之B树的插入删除
B树
B树的插入:
新元素一定是插入到最底层“终端结点”,用“查找”来确定插入位置
在插入key后,若导致原结点关键字数超过上限,则从中间位置(⌈m/2⌉)将其中的关键字分为两部分
左部分包含的关键字放在原结点中,右部分包含的关键字放到新结点中,中间位置(⌈m/2⌉)的结点插入原结点的父结点
若此时导致其父结点的关键字个数也超过了上限,则继续进行这种分裂操作,直至这个过程传到根结点为止,进而导致B树高度增1。
B树的删除[结合原理看动画]:
若被删除关键字在终端结点,则直接删除该关键字(要注意结点关键字个数是否低于下限 ⌈m/2⌉ − 1)
若被删除关键字在非终端结点,则用直接前驱或直接后继来替代被删除的关键字
直接前驱:当前关键字左侧指针所指子树中“最右下”的元素
直接后继:当前关键字右侧指针所指子树中“最左下”的元素
若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点右(或左)兄弟结点的关键字个数还很宽裕,则需要调整该结点、右(或左)兄弟结点及其双亲结点(父子换位法)
当右兄弟很宽裕时,用当前结点的后继(比当前结点大一位)、后继的后继(比当前结点大两位)来填补空缺
当左兄弟很宽裕时,用当前结点的前驱(比当前结点小一位)、前驱的前驱(比当前结点小两位)来填补空缺
若被删除关键字所在结点删除前的关键字个数低于下限,且此时与该结点相邻的左、右兄弟结点的关键字个数均=⌈m/2⌉ − 1,则将关键字删除后与左(或右)兄弟结点及双亲结点中的关键字进行合并

1.5动画可视化之B+树
定义和性质:
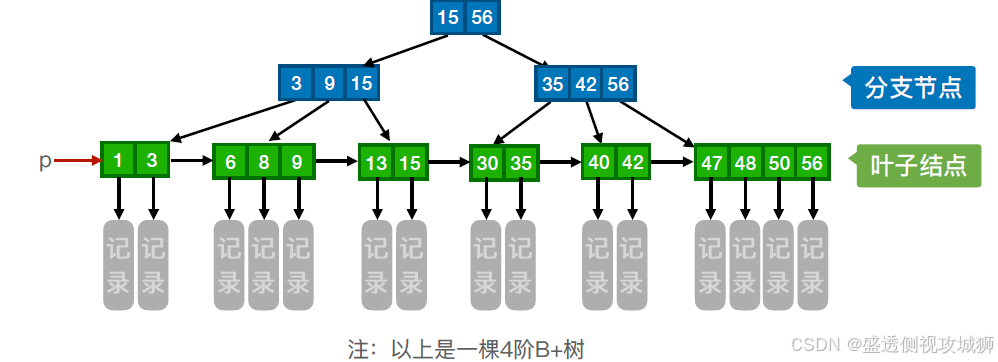
一棵m阶的B+树需满足下列条件:
每个分支结点最多有m棵子树(孩子结点)。
非叶根结点至少有两棵子树,其他每个分支结点至少有⌈m/2⌉棵子树。
可以理解为:要追求“绝对平衡”,即所有子树高度要相同
结点的子树个数与关键字个数相等。
所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序相互链接起来。
所有分支结点中仅包含它的各个子结点中关键字的最大值及指向其子结点的指针。
B+树的查找:
- B+树中,无论查找成功与否,最终一定都要走到最下面一层结点,因为只有叶子结点才有关键字对应的记录
B+树和B树区别:
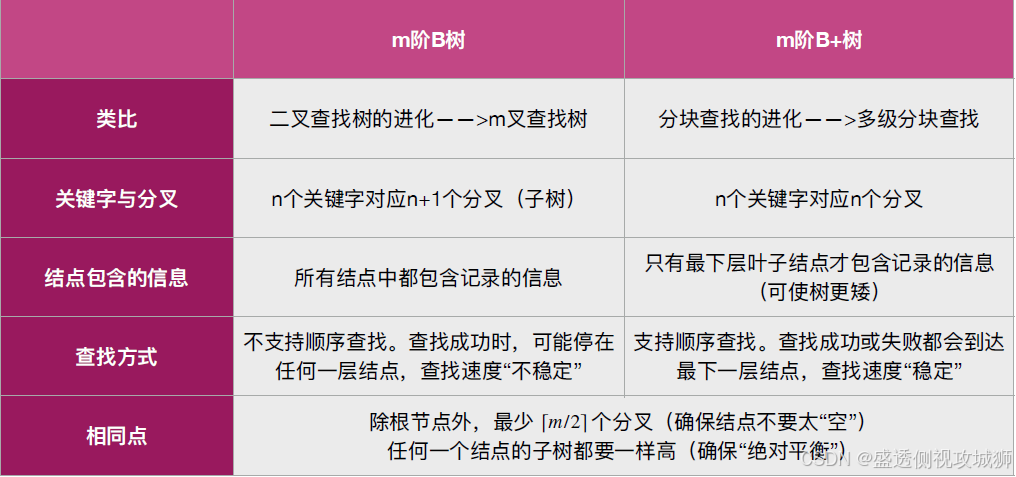
典型应用:关系型数据库的“索引”(如MySQL)
在B+树中,非叶结点不含有该关键字对应记录的存储地址。
可以使一个磁盘块可以包含更多个关键字,使得B+树的阶更大,树高更矮,读磁盘次数更少,查找更快
1.6动画可视化之散列(哈希)查找
封闭hash查找(封闭散列寻址)
定义:
散列表(Hash Table),又称哈希表
是一种数据结构,特点是:数据元素的关键字与其存储地址直接相关
通过哈希函数建立关键字和存储地址的联系
若不同的关键字通过散列函数映射到同一个值,则称它们为“同义词”
通过散列函数确定的位置已经存放了其他元素,则称这种情况为“冲突”
处理冲突的方法——拉链法:
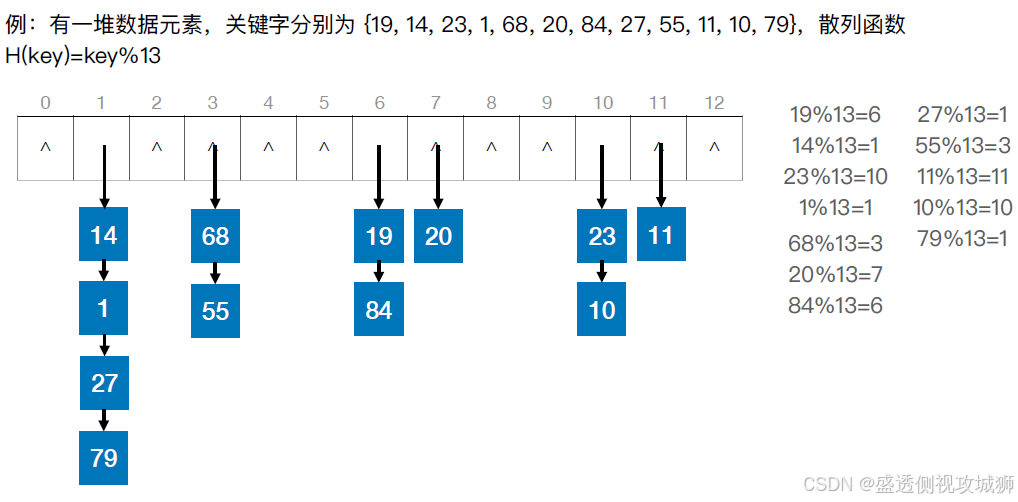
用拉链法(又称链接法、链地址法)处理“冲突”:把所有“同义词”存储在一个链表中
最理想情况:散列查找时间复杂度可到达O(1)
“冲突”越多,查找效率越低
实际上就是顺序表和链表的结合结合两者优点,比如顺序表的随机存取,然后用链表的解决冲突问题,又规避了顺序表的一系列缺点
在插入新元素时,保持关键字有序,可微微提高查找效率
常见的散列函数:
- 散列函数的设计目的:
-
让不同关键字的冲突尽可能的少
-
散列查找是典型的“用空间换时间”的算法,只要散列函数设计的合理,则散列表越长,冲突的概率越低。
-
- 除留余数法:H(key) = key % p
-
散列表表长为m,取一个不大于m但最接近或等于m的质数p
-
质数又称素数。指除了1和此整数自身外,不能被其他自然数整除的数
-
用质数取模,分布更均匀,冲突更少。参见《数无序列表论》
-
注意:散列函数的设计要结合实际的关键字分布特点来考虑,不要教条化
-
- 直接定址法 : H(key) = key 或 H(key) = a*key + b
-
其中,a和b是常数。这种方法计算最简单,且不会产生冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费。
-
例如:存储同一个班级的学生信息
-
- 数字分析法:选取数码分布较为均匀的若干位作为散列地址
-
设关键字是r进制数(如十进制数),而r个数码在各位上出现的频率不一定相同,可能在某些位上分布均匀一些,每种数码出现的机会均等;
-
而在某些位上分布不均匀,只有某几种数码经常出现,此时可选取数码分布较为均匀的若干位作为散列地址。这种方法适合于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数。
-
例如:以“手机号码”作为关键字设计散列函数
-
- 平方取中法:取关键字的平方值的中间几位作为散列地址。
-
具体取多少位要视实际情况而定。
-
这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀,适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数。
-
例如:要存储整个学校的学生信息,以“身份证号”作为关键字设计散列函数
-
动画可视化之处理冲突的方法——开放定址法:
Open哈希表(封闭寻址)算法动态图例结合代码全程展示
- 所谓开放定址法,是指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。其数学递推公式为:
Hi = (H(key) + di) % m
i = 0, 1, 2,…, k(k≤m - 1),m表示散列表表长;di为增量序列;
i 可理解为“第i次发生冲突”
线性探测法
di = 0, 1, 2, 3, …, m-1;即发生冲突时,每次往后探测相邻的下一个单元是否为空,为空则可以插入数值
查找也是类似,先通过公式得到Hi再依次往后查找,若遇到空的位置则说明查找失败,所以越早遇到空位置,就可以越早确定查找失败
删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填入散列表的同义词结点的查找路径,可以做一个“删除标记”,进行逻辑删除
线性探测法由于冲突后再探测一定是放在某个连续的位置,很容易造成同义词、非同义词的“聚集(堆积)”现象,严重影响查找效率
平方探测法
当di = 0^2, 1^2, -1^2, 2^2, -2^2, …, k^2, -k^2时,称为平方探测法,又称二次探测法,其中k≤m/2
比起线性探测法更不易产生“聚集(堆积)”问题
注意:负数的模运算,(-3)%27 = 24,而不是3
模运算的规则:a MOD m == (a+km) MOD m , 其中,k为任意整数
- 散列表长度m必须是一个可以表示成4j + 3的素数,才能探测到所有位置
- 伪随机序列法
di 是一个伪随机序列,如 di= 0, 5, 24, 11, …
处理冲突的方法——动画可视化之再散列法
封闭hash查找(封闭散列寻址)
除了原始的散列函数 H(key) 之外,多准备几个散列函数
当散列函数冲突时,用下一个散列函数计算一个新地址,直到不冲突为止:
Hi = RHi(Key)
i=1,2,3….,k



