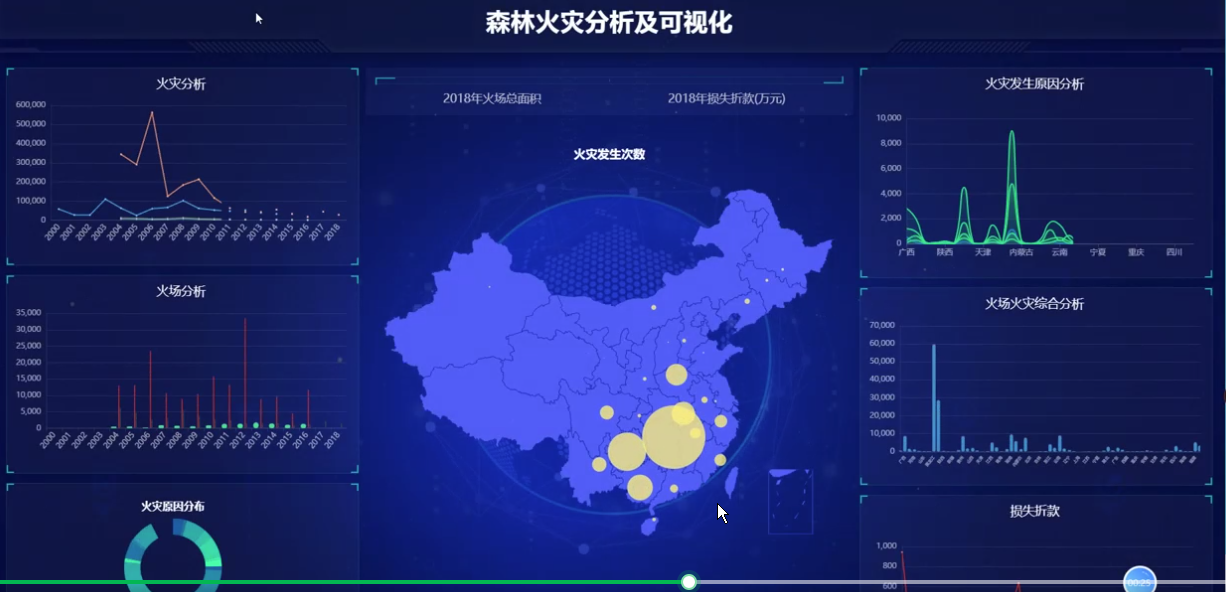
基于大数据的森林火灾分析及可视化
以下是关于大数据驱动的森林火灾分析及可视化系统的技术栈、功能设计、数据库及测试设计的详细方案:
技术栈设计
数据处理层
- 数据采集:Apache Kafka/Flume 实时采集卫星遥感数据(如MODIS、VIIRS)、气象数据(温度、湿度)及IoT传感器数据。
- 数据存储:HDFS分布式存储原始数据,HBase管理非结构化数据(如遥感图像),PostgreSQL存储结构化数据(气象、历史火灾记录)。
- 数据处理:Spark进行分布式计算(火险预测模型训练),Flink处理实时数据流(火点监测)。
分析层
- 机器学习:使用PySpark MLlib或TensorFlow构建火灾预测模型(如随机森林、LSTM),结合历史数据与气象因子训练。
- 空间分析:GeoSpark处理地理空间数据,GDAL库解析遥感影像,生成火点热力图。
可视化层
- 前端框架:React.js + D3.js/ECharts构建动态可视化面板,Mapbox GL JS集成地理空间渲染。
- 后端服务:Spring Boot提供REST API,PyTorch Serving部署预测模型。
部署运维
- 容器化:Docker + Kubernetes集群管理,Prometheus + Grafana监控系统性能。
功能模块设计
核心功能源码示例
- 火点检测算法(Python)
# 基于NDVI与温度阈值的火点检测def fire_detection(ndvi, temp): if ndvi 40: # 植被稀疏且高温区域 return \"High Risk\" elif temp > 45: # 极端高温区域 return \"Critical Risk\" else: return \"Normal\"- 实时数据分析(Spark Streaming)
val fireStream = KafkaUtils.createStream(...) .map(json => parseFireData(json)) // 解析传感器数据 .filter(_.temp > 40) // 过滤高温事件 .window(Minutes(30)) // 滑动窗口统计- 可视化交互(React + Mapbox)
updateFireMarker(e.lngLat)}> // 热力图渲染数据库设计
表结构示例
-
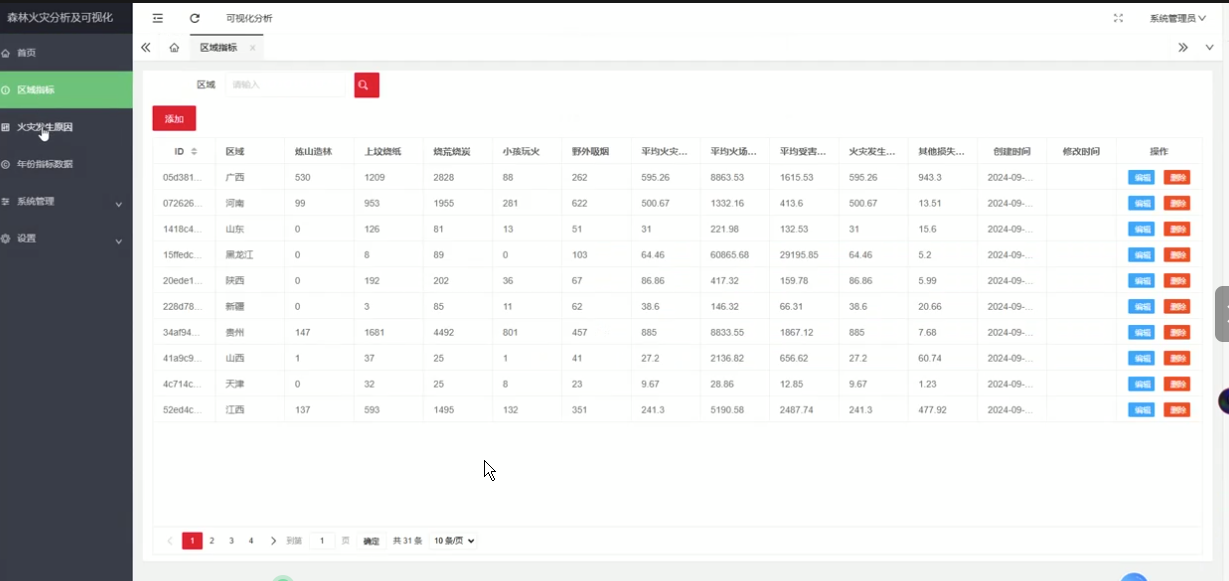
fire_incidents表
| 字段名 | 类型 | 描述 | |--------------|-------------|--------------------| | incident_id | UUID | 火灾事件唯一标识 | | latitude | FLOAT | 火点纬度 | | longitude | FLOAT | 火点经度 | | detected_at | TIMESTAMP | 检测时间 | -
weather_data表
| 字段名 | 类型 | 描述 | |--------------|-------------|--------------------| | station_id | VARCHAR | 气象站ID | | temperature | FLOAT | 实时温度(℃) |
系统测试设计
测试类型
- 单元测试:使用JUnit/Pytest验证火点检测算法逻辑(如高温阈值判定)。
- 集成测试:TestContainers模拟Kafka+Spark数据流水线,验证端到端处理延迟。
- 性能测试:JMeter压力测试API并发响应,确保支持1000+ QPS。
测试用例示例
@Testpublic void testFireDetection() { String result = FireDetection.fire_detection(0.1, 42); assertEquals(\"High Risk\", result); // 验证高风险判定}该方案整合了大数据处理、AI建模及可视化技术,可扩展至无人机数据接入或多源数据融合场景。