大厂面试必考动态规划算法问题汇总:终极详解+分析+归纳 dp动态规划问题大全解 + 所有常考题型总结思路_dp 经典题型
引子 :动态规划硬核之路所有个人源码分享+解题过程共享(0)
最近搞完了dp动态规划问题+贪心算法问题,这里是所有题型的全览:
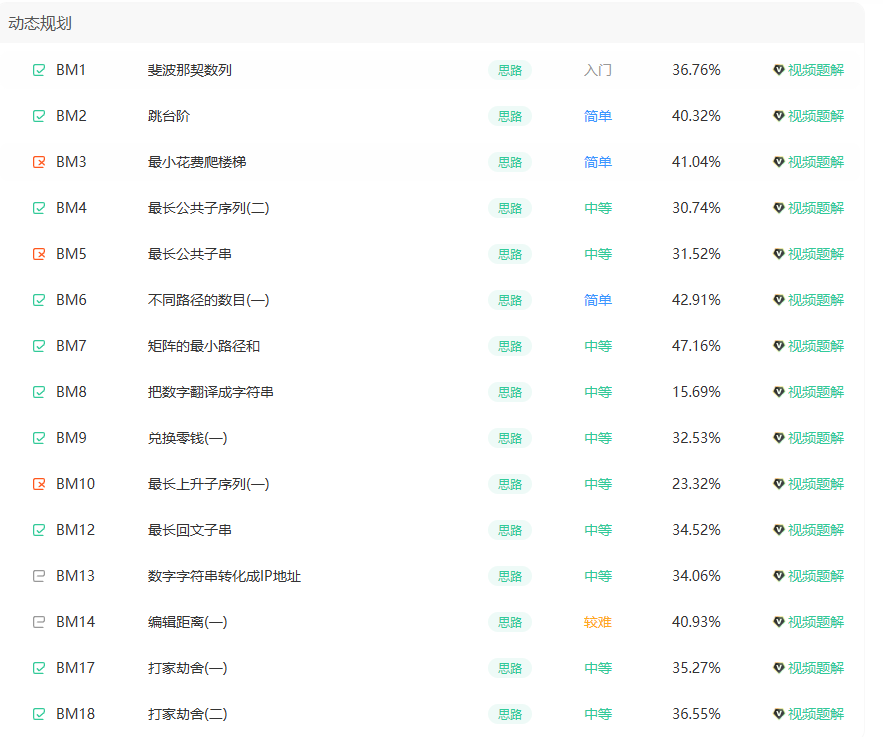
以下是值得思考、值得反复练习的经典动态规划算法问题!!!
一共10道题
1 最长公共子序列:
2 最长公共子串:

#3刷 2025/7/15
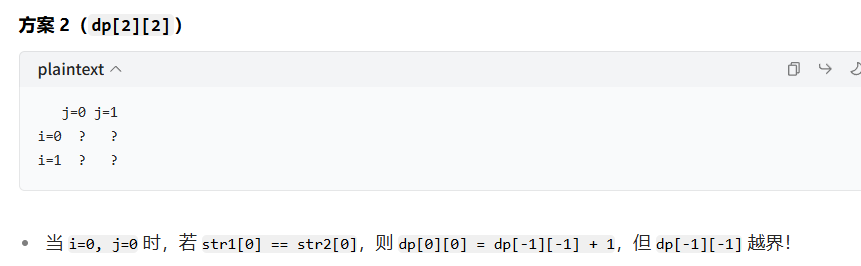
这里变成了:dp[i][j] = dp[i-1][j-1]+1就是回越界
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * longest common substring * @param str1 string字符串 the string * @param str2 string字符串 the string * @return string字符串 */#include char *LCS(char *str1, char *str2){ // write code here // int l1 =strlen(str1); // int l2 = strlen(str2); // if(l1==0 || l2 ==0 ){ // return NULL; // } // int Max = 0,end = 0; // int dp[5001][5001] = {0}; // for(int i =1 ;i<=l1;i++){ // for(int j=1;jMax){ // end = i-1; // Max = dp[i][j] ; // } // } // else{ // dp[i][j]=0; // } // } // } // //存到了产犊Max end结束的位置 // char* res = (char* )malloc(sizeof(char)*3000); // for(int i = 0;i<Max;i++){ // res[i]= str1[end-Max+1+i]; // } // res[Max]=\'\\0\'; // return res; // #2刷 // 最长公共子串,两个位置的必须相同,不然直接跳过为0 // int len1 = strlen(str1) , len2 = strlen(str2); // int dp[len1+1][len2+1] ; // dp[0][0] = 0 ; // int maxLen = 0; // int endPos = 0; // for(int i=1;i<=len1;i++){ // for(int j =1;jmaxLen){ // endPos = i; // maxLen = dp[i][j]; // } // } // else{ // dp[i][j]=0; // } // } // } // endPos-=1; // char* res = (char*)malloc(5001*sizeof(char)); // for(int i = 0;i<maxLen;i++){ // res[i] = str1[endPos-maxLen+i]; // } // res[maxLen] = \'\\0\'; // return res; // #3刷 int len1 = strlen(str1); int len2 = strlen(str2); int **dp = (int **)malloc((len1 + 1) * sizeof(int *)); for (int i = 0; i <= len1; i++) { dp[i] = (int *)calloc((len2 + 1), sizeof(int)); } int maxLen = 0; int end = 0; for (int i = 1; i <= len1; i++) { for (int j = 1; j maxLen) { maxLen = dp[i][j]; // #vip 容易错 end = i - 1; } } else { dp[i][j] = 0; } } } // 处理这个start ->end 的序列: int start = end - maxLen + 1; char *res = (char *)malloc(5000 * sizeof(char)); for (int i = 0; i < maxLen; i++) { res[i] = str1[start + i]; } res[maxLen] = \'\\0\'; return res;}3 数字翻译成字符串?

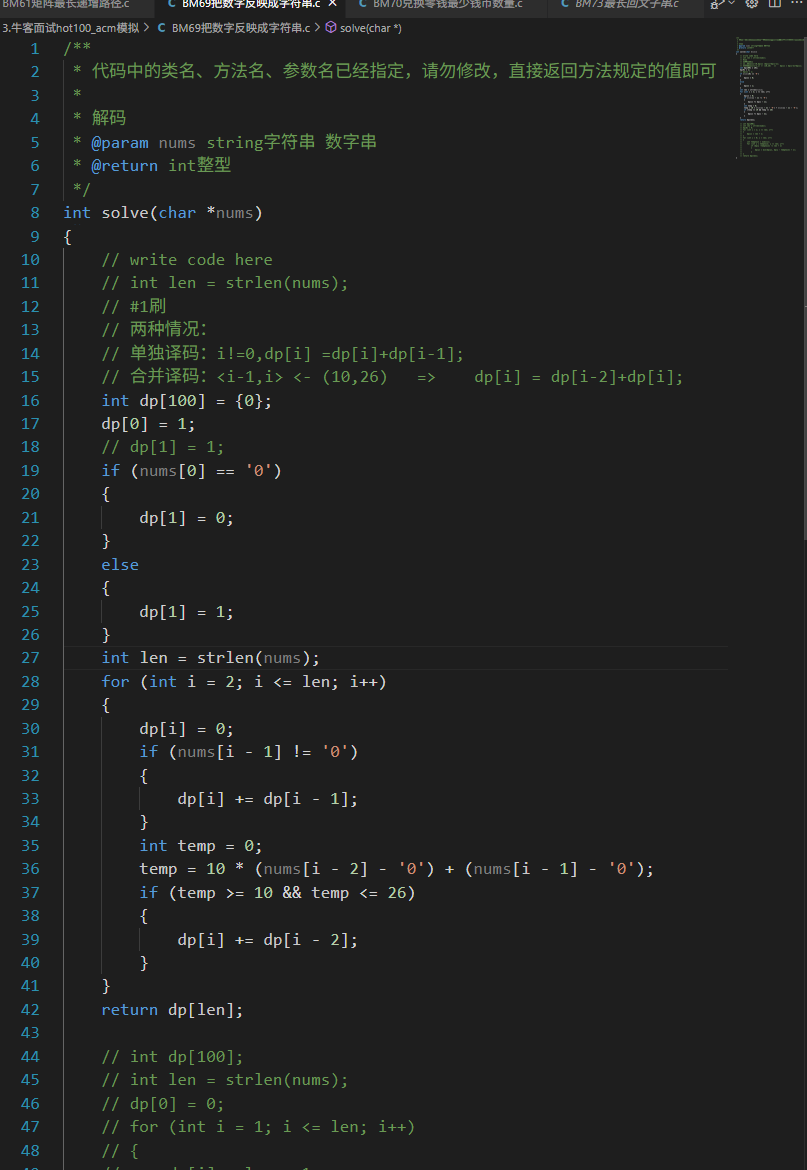
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 解码 * @param nums string字符串 数字串 * @return int整型 */int solve(char *nums){ // write code here // int len = strlen(nums); // #1刷 // 两种情况: // 单独译码:i!=0,dp[i] =dp[i]+dp[i-1]; // 合并译码: dp[i] = dp[i-2]+dp[i]; int dp[100] = {0}; dp[0] = 1; // dp[1] = 1; if (nums[0] == \'0\') { dp[1] = 0; } else { dp[1] = 1; } int len = strlen(nums); for (int i = 2; i = 10 && temp <= 26) { dp[i] += dp[i - 2]; } } return dp[len]; // int dp[100]; // int len = strlen(nums); // dp[0] = 0; // for (int i = 1; i <= len; i++) // { // dp[i] = len + 1; // } // for (int i = 0; i < len; i++) // { // int tempCoin = nums[i]; // for (int j = tempCoin; j <= len; j++) // if (dp[j -tempCoin] != len + 1) // { // dp[j] = min(dp[j], dp[j - tempCoin] + 1); // } // } // return dp[len];}关键:
(1)第一种情况:a[i]!=0
(2) 第二章情况:a[i]<(10,26)
4 兑换零钱?
遍历所有的1->len长度的序列的每一个硬币面值:
如果dp[j-coin]!=aim+1 那么更新整个dp[j]的值
比如【5,2,3】 20
第一轮,从5>>>20,更新的有:dp[5] dp[10] dp[15] dp[20]
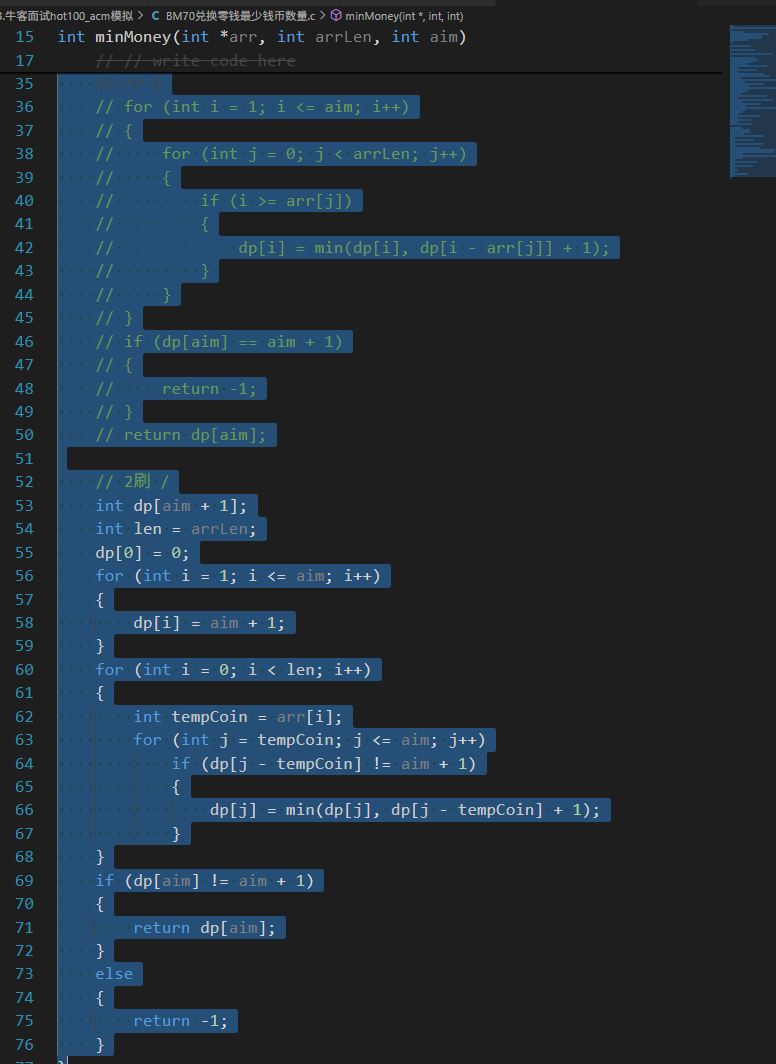
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 最少货币数 * @param arr int整型一维数组 the array * @param arrLen int arr数组长度 * @param aim int整型 the target * @return int整型 */int min(int a, int b){ return a < b ? a : b;}int minMoney(int *arr, int arrLen, int aim){ // // write code here // int maxLen = aim + 1; // int dp[aim + 1]; // dp[0] = 0; // for (int i = 1; i <= aim; i++) // { // dp[i] = aim + 1; // } // // 随你怎么变 总会比aim+1小 // // for (int i = 1; i <= aim; i++) // // { // // for (int j = 0; j = arr[j]) // // { // // dp[i] = min(dp[i], dp[i - arr[j]] + 1); // // } // // } // // } // for (int i = 1; i <= aim; i++) // { // for (int j = 0; j = arr[j]) // { // dp[i] = min(dp[i], dp[i - arr[j]] + 1); // } // } // } // if (dp[aim] == aim + 1) // { // return -1; // } // return dp[aim]; // 2刷 / int dp[aim + 1]; int len = arrLen; dp[0] = 0; for (int i = 1; i <= aim; i++) { dp[i] = aim + 1; } for (int i = 0; i < len; i++) { int tempCoin = arr[i]; for (int j = tempCoin; j <= aim; j++) if (dp[j - tempCoin] != aim + 1) { dp[j] = min(dp[j], dp[j - tempCoin] + 1); } } if (dp[aim] != aim + 1) { return dp[aim]; } else { return -1; }}5 最长回文?
#include #include #include // int doFunc(char *A, int left, int right)// {// // 从left和right开始一个个往两边拓展,用一个cnt计数// // int len = strlen(A);// // int cnt = 0, flag = 0;// // if (left == right)// // {// // cnt = 1;// // left--;// // right++;// // }// // while (A[left] == A[right] && left >= 0 && right =0 && right b ? a : b;// }// int getLongestPalindrome(char *A)// {// // write code here// // dp方法:初始状态 - 装填转移 - 边界条件// // 干活的函数: s , left , right// // mid 开始,left -1 ,right+1 向两边拓展// // 主函数,从0到右边,一个个找,// // #self 从左边开始一个个找// // int maxLen = 1;// // int len = strlen(A);// // if (len == 0)// // {// // return 0;// // }// // int r1, r2;// // for (int i = 0; i maxLen)// // {// // maxLen = res;// // }// // }// // return maxLen;// int maxLen = 1;// int len = strlen(A);// for(int i =0;imaxLen) maxLen =res;// }// return maxLen;}// 3刷/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param A string字符串 * @return int整型 */int max(int a, int b){ return a > b ? a : b;}int doFunc(char *a, int len, int left, int right){ while (left >= 0 && right < len && a[left] == a[right]) { left--; right++; } return right - left - 1;}int getLongestPalindrome(char *A){ // write code here if (!A) return -1 + 1; int len = strlen(A); if (len == 1) { return 1; } int maxLen = 1; for (int i = 0; i maxLen) { maxLen = tempM; } } return maxLen;}6 最长上升子序列?
// #include // int main()// {// int arr[] = {47, 89, 23, 76, 12, 55, 34, 91, 62, 7, 38, 81, 44, 50, 99};// printf(\"最长上升子序列是:%d\\n\\n\", LTS(arr, 15));// printf(\"最长上升子序列是\\n\");// return 0;// }// int LTS(int *arr, int arrLen)// {// int dp[arrLen];// if (arrLen == 0)// {// return 0;// }// for (int i = 0; i < arrLen; i++)// {// dp[i] = 1;// }// dp[0] = 1;// int maxLen = 1;// // for (int i = 1; i < arrLen; i++)// // {// // for (int j = 0; j arr[j])// // {// // if (dp[j] + 1 > dp[i])// // {// // dp[i] = dp[j] + 1;// // }// // }// // }// // if (dp[i] > maxLen)// // {// // maxLen = dp[i];// // }// // }// for(int i =1;i<arrLen;i++){// for(int j = 0 ;jarr[j]){// if(dp[j]+1>dp[i]){// dp[i] = dp[j]+1;// }// }// }// if(dp[i]>maxLen ){// maxLen = dp[i];// }// }// return maxLen;// }# 2刷/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 给定数组的最长严格上升子序列的长度。 * @param arr int整型一维数组 给定的数组 * @param arrLen int arr数组长度 * @return int整型 */int LIS(int *arr, int arrLen){ // write code here if (!arr) { return 0; } int dp[arrLen]; for (int i = 0; i < arrLen; i++) { dp[i] = 1; } int maxLen = 1; for (int i = 0; i < arrLen; i++) { for (int j = 0; j < i; j++) { if (arr[j] < arr[i]) { dp[i] = max(dp[i], dp[j] + 1); maxLen = max(maxLen, dp[i]); } else { // dp[i] = dp[j]; ; } } } // return dp[arrLen - 1]; return maxLen;}dp[i] dp[j] 的动态规划:
0-》arrlen
0->i
如果大,
dp[i] = 挑一个大的
记录一下
7 字符串转化ip地址?
8 编辑距离?
9 打家劫舍(1)+(2)?
20257.20三刷!
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param nums int整型一维数组 * @param numsLen int nums数组长度 * @return int整型 */#define MaxV 15000typedef struct Person{ char name[]; int age;} chinese;#include int max(int a, int b){ return a > b ? a : b;}int rob(int *nums, int numsLen){ // write code here // 打家劫舍问题:要么搞nums[i]+dp[i-2] ,要么dp[i-1] // int dp[numsLen] ; // dp[1] =max(nums[0],nums[1]); // dp[0] = nums[0]; // for(int i=2;i<numsLen;i++){ // dp[i] = max(dp[i-1],nums[i]+dp[i-2]); // } // return dp[numsLen-1]; // 2刷 char* a[]; int b[100]; int* ptr_Int = b; if (!nums || numsLen == 0) { return 0; } if (numsLen == 1) { return nums[0]; } if (numsLen == 2) { return max(nums[0], nums[1]); } int dp[numsLen]; for (int i = 2; i < numsLen; i++) { dp[i] = 0; } for (int i = 2; i < numsLen; i++) { dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]); } return dp[numsLen - 1];}// int main(){// int a[] = {12, 9,6,6,7,7,4,5,3,7,3,3,7,5,23,6,2,36,26,4,23,6,2,36,24,36,3,68,8 ,12};// int len = sizeof(a)/sizeof(a[0]);// printf(\"结果是:%d \\n\",rob(a,len));// }环形:
int max(int a, int b){ return a > b ? a : b;}int rob(int *nums, int numsLen){ int dp1[numsLen]; int dp2[numsLen]; int m1 = 0; int m2 = 0; // 第一家偷,最后一个不能偷! // 1st不,last one 可以! dp1[0] = nums[0]; dp1[1] = dp1[0]; for (int i = 2; i < numsLen - 1; i++) { dp1[i] = max(dp1[i - 2] + nums[i], dp1[i - 1]); } m1 = dp1[numsLen - 2]; dp2[0] = 0; dp2[1] = nums[1]; for (int i = 2; i < numsLen; i++) { dp2[i] = max(dp2[i - 2] + nums[i], dp2[i - 1]); } m2 = dp2[numsLen - 1]; return max(m1, m2);}以上是笔记本手写的思维分析+总结
---------------------------------------------------------------------------------------------------------最近更新于2025.7.21 晚上1:00
1 x做过了就会,你不看试试?
2 多回顾题目!
3 脑子过 反复
---------------------------------------------------------------------------------------------------------------------重制版>>>>>更新于2025.7.22晚上10:00
动态规划硬核之路:从最长公共子串到数字翻译(第一部分)
前言:DP,嵌入式面试的“拦路虎”还是“敲门砖”?
兄弟们,咱们搞嵌入式的,C语言是基本功,但算法,特别是动态规划,那绝对是面试大厂的“分水岭”。很多人觉得DP难,无从下手,但我告诉你,DP不是玄学,它有套路,有思想。一旦你掌握了它,它就会从“拦路虎”变成你进入大厂的“敲门砖”!
我大学四年学嵌入式,研究生搞了几年区块链,现在又回来刷C语言准备嵌入式工作,深知这种“半路出家”的痛苦。但正是这种经历,让我对知识的理解更深了一层:基础,永远是王道! 而DP,正是检验你基础功底和逻辑思维能力的绝佳利器。
这篇博客,我将结合我在牛客、力扣上刷题的真实代码,手把手带你剖析DP问题的核心,从最基本的概念讲起,深入浅出,力求让每一个看过100道热题榜的C程序员都能看懂,都能有所收获。
1 动态规划初探:核心思想与基本要素
在深入具体题目之前,咱们先来聊聊动态规划到底是个啥。
动态规划 (Dynamic Programming, DP),简单来说,就是把一个复杂的大问题,拆分成若干个相互关联的子问题,通过解决这些子问题,并把子问题的解存储起来(避免重复计算),最终得到大问题的解。
它的核心思想就俩字:“重叠子问题” 和 “最优子结构”。
-
重叠子问题 (Overlapping Subproblems):解决大问题时,会反复遇到相同的子问题。DP通过记忆化(Memoization)或填表(Tabulation)来存储子问题的解,避免重复计算,大大提高效率。
-
最优子结构 (Optimal Substructure):大问题的最优解可以通过子问题的最优解来构造。这意味着,如果你能找到子问题的最优解,那么把它们组合起来就能得到整个问题的最优解。
构建一个DP解决方案,通常需要明确以下几个要素:
-
DP 状态定义:
dp[i]或dp[i][j]代表什么?这是最关键的一步,定义好了,后面就水到渠成了。 -
DP 状态转移方程:
dp[i]或dp[i][j]如何从之前的状态推导出来?这是DP的核心逻辑。 -
初始化:DP 数组的初始值是多少?通常是边界条件,或者一些特殊情况。
-
边界条件:最小的子问题是什么?它们的解是什么?
-
计算顺序:是自底向上(填表法)还是自顶向下(记忆化搜索)?通常填表法更常见。
我们可以用一张思维导图来概括DP的核心要素:
DP核心要素
描述
常见表现形式
状态定义
dp[i] 或 dp[i][j] 表示什么?
数组、二维数组
转移方程
如何从已知状态推导出当前状态?
dp[i] = f(dp[i-1], dp[i-2], ...)
初始化
最小子问题的解,或数组的起始值。
dp[0] = ..., dp[0][0] = ...
边界条件
问题的最小规模,或特殊情况的处理。
i=0 或 j=0 时的情况
计算顺序
遍历方向,确保计算当前状态时所需的前置状态已计算。
通常是嵌套循环,从小到大遍历 i 和 j
2 经典问题剖析:最长公共子串 (Longest Common Substring)
好了,理论说完了,咱们直接上硬菜!第一个要讲的,就是最长公共子串。用户在代码里把它写成了 LCS,但从实现来看,它确实是最长公共子串,而不是最长公共子序列。这里咱们先明确一下概念:
-
最长公共子串 (Longest Common Substring):两个字符串中,最长的连续的公共部分。例如 \"ABCDE\" 和 \"ABFCE\",最长公共子串是 \"AB\"。
-
最长公共子序列 (Longest Common Subsequence):两个字符串中,最长的非连续的公共部分(保持相对顺序)。例如 \"ABCDE\" 和 \"ABFCE\",最长公共子序列是 \"ABCE\"。
这两个问题虽然名字相似,但DP状态转移方程有本质区别。咱们先聚焦最长公共子串。
问题描述
给定两个字符串 str1 和 str2,找出它们的最长公共子串。
用户代码分析与思考
我们先来看看用户提供的LCS函数(实际是最长公共子串)的代码:
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * longest common substring * @param str1 string字符串 the string * @param str2 string字符串 the string * @return string字符串 */#include #include // 补充头文件#include // 补充头文件char *LCS(char *str1, char *str2){ // write code here // #3刷 int len1 = strlen(str1); int len2 = strlen(str2); // 动态分配二维数组,避免栈溢出,尤其是在大字符串时 int **dp = (int **)malloc((len1 + 1) * sizeof(int *)); for (int i = 0; i <= len1; i++) { // calloc 会自动将内存初始化为0,非常适合DP数组 dp[i] = (int *)calloc((len2 + 1), sizeof(int)); } int maxLen = 0; // 记录最长公共子串的长度 int end = 0; // 记录最长公共子串在str1中的结束位置(索引) for (int i = 1; i <= len1; i++) { for (int j = 1; j maxLen) { maxLen = dp[i][j]; // #vip 容易错:end记录的是str1中子串的结束索引 // 因为i是基于1的索引,str1[i-1]是当前字符,所以i-1就是当前字符的索引 end = i - 1; } } else { // 如果当前字符不匹配,则公共子串断开,长度重置为0 dp[i][j] = 0; } } } // 处理这个start ->end 的序列: // 根据最长子串的长度和结束位置,计算起始位置 int start = end - maxLen + 1; // 分配结果字符串内存,maxLen + 1 用于存放 \'\\0\' char *res = (char *)malloc((maxLen + 1) * sizeof(char)); if (res == NULL) { // 内存分配失败检查 // 释放之前分配的dp内存 for (int i = 0; i <= len1; i++) { free(dp[i]); } free(dp); return NULL; // 返回错误 } // 复制子串到结果字符串 for (int i = 0; i < maxLen; i++) { res[i] = str1[start + i]; } res[maxLen] = \'\\0\'; // 添加字符串结束符 // 释放动态分配的dp内存,避免内存泄漏 for (int i = 0; i <= len1; i++) { free(dp[i]); } free(dp); return res;}我的分析和思考:
用户这份代码已经是第三次刷了,进步非常明显!从注释的 #3刷于7/15 和 #vip 容易错 都能看出,用户在思考和解决问题过程中遇到的困惑和进步。
优点:
-
DP 状态定义清晰:
dp[i][j]表示以str1[i-1]和str2[j-1]结尾的最长公共子串的长度。这个定义非常关键,因为它直接决定了状态转移方程。 -
状态转移方程正确:
if (str1[i-1] == str2[j-1]) { dp[i][j] = dp[i-1][j-1] + 1; } else { dp[i][j] = 0; }完美体现了子串连续性的要求。 -
动态分配
dp数组:用户从之前的固定大小数组int dp[5001][5001]改为malloc动态分配,这是一个巨大的进步!避免了栈溢出,使得代码能处理更长的字符串。 -
calloc初始化:使用calloc自动初始化为0,省去了手动清零的步骤,代码更简洁。 -
记录
maxLen和end:能够正确地记录最长公共子串的长度和其在str1中的结束位置,这是构建结果字符串的关键。
可以优化和改进的地方:
-
头文件缺失:
strlen,malloc,free都需要和。虽然在某些IDE或编译器下可能隐式包含,但为了代码的健壮性和可移植性,必须显式包含。 -
malloc大小:在char* res = (char* )malloc(sizeof(char)*3000);或char* res = (char*)malloc(5001*sizeof(char));处,虽然用户在第三次刷的时候改成了5000 * sizeof(char),但更精确和安全的做法是根据maxLen来分配,即(maxLen + 1) * sizeof(char),因为maxLen可能远小于5000,造成内存浪费;也可能在极端情况下maxLen超过5000,导致内存不足。 -
内存泄漏:在返回
res之前,需要free掉之前malloc出来的dp数组。用户在第三次刷的时候已经考虑到了这一点,并在返回前释放了dp数组,非常棒! -
边界条件处理:虽然代码中
if(len1==0 || len2 ==0 )的注释部分被删除了,但对于空字符串的输入,最好在函数开头进行显式检查,避免后续操作出现空指针解引用。
深入浅出:最长公共子串的DP原理与实现
咱们来彻底捋一遍最长公共子串的DP思路。
1. DP 状态定义:
dp[i][j] 表示以 str1[i-1] 结尾且以 str2[j-1] 结尾的最长公共子串的长度。 注意这里的 i 和 j 是为了方便DP数组的索引,它们分别对应 str1 和 str2 的前 i 个和前 j 个字符。所以实际字符索引是 i-1 和 j-1。
2. DP 状态转移方程:
-
如果
str1[i-1] == str2[j-1](当前字符匹配):dp[i][j] = dp[i-1][j-1] + 1这意味着,如果当前字符匹配,那么最长公共子串的长度就是它们前一个字符匹配时的长度加1。 -
如果
str1[i-1] != str2[j-1](当前字符不匹配):dp[i][j] = 0因为是“子串”,要求连续,一旦不匹配,公共子串就断了,长度自然归零。
3. 初始化:
-
dp[0][j] = 0(当str1为空时,没有公共子串) -
dp[i][0] = 0(当str2为空时,没有公共子串) -
由于我们使用
calloc动态分配并初始化为0,这些边界条件自然满足。
4. 计算顺序:
从 i = 1 到 len1,从 j = 1 到 len2,双重循环遍历。
DP 状态表(以 str1 = \"ABCDE\", str2 = \"ABFCE\" 为例):
\"\"
A=0
B=1
F=2
C=3
E=4
\"\"
0
0
0
0
0
0
A=0
0
1
0
0
0
0
B=1
0
0
2
0
0
0
C=2
0
0
0
0
1
0
D=3
0
0
0
0
0
0
E=4
0
0
0
0
0
1
解释:
-
dp[2][2](对应str1[1]=\'B\',str2[1]=\'B\'):str1[1]==\'B\'且str2[1]==\'B\',所以dp[2][2] = dp[1][1] + 1 = 1 + 1 = 2。此时maxLen = 2,end = 1。 -
dp[3][4](对应str1[2]=\'C\',str2[3]=\'C\'):str1[2]==\'C\'且str2[3]==\'C\',所以dp[3][4] = dp[2][3] + 1 = 0 + 1 = 1。
最终,maxLen 会记录最大值,end 会记录这个最大值对应的 str1 结束索引。
优化与最终代码 (C语言)
结合上述分析,我将用户的代码进行优化,并添加更详细的注释,使其更符合生产级代码的要求,也更便于理解。
#include // 标准输入输出,用于printf等#include // 字符串操作函数,用于strlen#include // 内存分配函数,用于malloc, free/** * @brief 查找两个字符串的最长公共子串 * * 本函数使用动态规划(Dynamic Programming, DP)的方法来解决最长公共子串问题。 * DP数组 dp[i][j] 存储以 str1[i-1] 结尾且以 str2[j-1] 结尾的最长公共子串的长度。 * * @param str1 第一个输入字符串 * @param str2 第二个输入字符串 * @return char* 指向最长公共子串的指针。如果无公共子串或内存分配失败,返回NULL。 * 调用者负责释放返回的内存。 */char *findLongestCommonSubstring(char *str1, char *str2) { // 1. 输入校验:处理空字符串或空指针的情况 if (str1 == NULL || str2 == NULL) { return NULL; } int len1 = strlen(str1); int len2 = strlen(str2); if (len1 == 0 || len2 == 0) { // 如果任一字符串为空,则没有公共子串,返回空字符串 char *res = (char *)malloc(sizeof(char)); // 分配1字节用于存储\'\\0\' if (res == NULL) { return NULL; // 内存分配失败 } res[0] = \'\\0\'; return res; } // 2. DP 数组定义与初始化 // dp[i][j] 表示以 str1[i-1] 和 str2[j-1] 结尾的最长公共子串的长度 // 数组大小为 (len1 + 1) x (len2 + 1),因为我们需要处理空前缀的情况 (i=0 或 j=0) int **dp = (int **)malloc((len1 + 1) * sizeof(int *)); if (dp == NULL) { return NULL; // 内存分配失败 } for (int i = 0; i <= len1; i++) { // calloc 会自动将分配的内存初始化为零,这对于DP数组的初始化非常方便 // dp[i][0] 和 dp[0][j] 自然为0,符合边界条件 dp[i] = (int *)calloc((len2 + 1), sizeof(int)); if (dp[i] == NULL) { // 如果某一行内存分配失败,需要释放之前已分配的内存 for (int k = 0; k < i; k++) { free(dp[k]); } free(dp); return NULL; } } // 3. 遍历填充 DP 数组 int maxLen = 0; // 记录迄今为止发现的最长公共子串的长度 int endIdx1 = 0; // 记录最长公共子串在 str1 中的结束索引(实际字符索引) for (int i = 1; i <= len1; i++) { for (int j = 1; j maxLen) { maxLen = dp[i][j]; // 更新最长公共子串在 str1 中的结束索引 // i-1 是当前匹配字符在 str1 中的实际索引 endIdx1 = i - 1; } } else { // 如果字符不匹配,则公共子串断开,长度重置为0 // 这是“子串”与“子序列”的关键区别:子串要求连续 dp[i][j] = 0; } } } // 4. 构造结果字符串 char *resultSubstring; if (maxLen == 0) { // 如果没有找到任何公共子串(maxLen为0),返回一个空字符串 resultSubstring = (char *)malloc(sizeof(char)); if (resultSubstring == NULL) { // 内存分配失败,需要释放dp数组 for (int i = 0; i <= len1; i++) { free(dp[i]); } free(dp); return NULL; } resultSubstring[0] = \'\\0\'; } else { // 根据 maxLen 和 endIdx1 计算子串的起始索引 int startIdx1 = endIdx1 - maxLen + 1; // 分配内存给结果字符串,需要 maxLen + 1 字节来存储字符串结束符 \'\\0\' resultSubstring = (char *)malloc((maxLen + 1) * sizeof(char)); if (resultSubstring == NULL) { // 内存分配失败,需要释放dp数组 for (int i = 0; i <= len1; i++) { free(dp[i]); } free(dp); return NULL; } // 从 str1 中复制最长公共子串到结果字符串 strncpy(resultSubstring, str1 + startIdx1, maxLen); resultSubstring[maxLen] = \'\\0\'; // 确保字符串以空字符结尾 } // 5. 释放 DP 数组内存,避免内存泄漏 for (int i = 0; i <= len1; i++) { free(dp[i]); } free(dp); return resultSubstring;}/*// 示例用法 (可以放在main函数中测试)int main() { char *s1 = \"ABCDE\"; char *s2 = \"ABFCE\"; char *lcs = findLongestCommonSubstring(s1, s2); if (lcs != NULL) { printf(\"最长公共子串: \\\"%s\\\"\\n\", lcs); // 预期输出: \"AB\" free(lcs); // 释放结果字符串内存 } else { printf(\"未找到公共子串或内存分配失败。\\n\"); } s1 = \"HelloWorld\"; s2 = \"LowWorld\"; lcs = findLongestCommonSubstring(s1, s2); if (lcs != NULL) { printf(\"最长公共子串: \\\"%s\\\"\\n\", lcs); // 预期输出: \"World\" free(lcs); } else { printf(\"未找到公共子串或内存分配失败。\\n\"); } s1 = \"abc\"; s2 = \"def\"; lcs = findLongestCommonSubstring(s1, s2); if (lcs != NULL) { printf(\"最长公共子串: \\\"%s\\\"\\n\", lcs); // 预期输出: \"\" free(lcs); } else { printf(\"未找到公共子串或内存分配失败。\\n\"); } s1 = \"\"; s2 = \"test\"; lcs = findLongestCommonSubstring(s1, s2); if (lcs != NULL) { printf(\"最长公共子串: \\\"%s\\\"\\n\", lcs); // 预期输出: \"\" free(lcs); } else { printf(\"未找到公共子串或内存分配失败。\\n\"); } return 0;}*/代码改进总结:
改进点
原因/目的
效果
头文件补全
确保代码的完整性、健壮性和可移植性。
避免编译警告和潜在的运行时错误。
空字符串/空指针处理
提高代码鲁棒性,避免非法输入导致程序崩溃。
函数更安全,能够优雅地处理边缘情况。
resultSubstring 精确 malloc
根据 maxLen 精确分配内存,避免内存浪费或不足。
内存使用更高效、更安全。
内存泄漏处理
确保所有 malloc 的内存都在函数结束前 free 掉。
避免长时间运行的程序内存占用不断增长,尤其在嵌入式系统资源有限的情况下至关重要。
详细注释
解释每一步的逻辑、变量含义和设计思路。
提高代码可读性、可维护性,便于他人理解和自己回顾。
错误处理
对 malloc 失败的情况进行检查并返回 NULL。
使函数在内存不足时能给出明确的错误指示,而不是直接崩溃。
3 经典问题剖析:数字翻译成字符串 (Decode Ways)
接下来,咱们看看第二个经典DP问题——“数字翻译成字符串”,也就是力扣上的“解码方法”。用户也提供了代码,咱们继续分析。
问题描述
一条包含字母 A-Z 的消息通过以下方式进行了编码:
\'A\' -> 1 \'B\' -> 2 ... \'Z\' -> 26
给定一个只包含数字的非空字符串 nums,请计算解码方法的总数。
用户代码分析与思考
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 解码 * @param nums string字符串 数字串 * @return int整型 */#include // 补充头文件int solve(char *nums){ // write code here // int len = strlen(nums); // #1刷 // 两种情况: // 单独译码:i!=0,dp[i] =dp[i]+dp[i-1]; // 合并译码: dp[i] = dp[i-2]+dp[i]; int dp[100] = {0}; // 固定大小数组,可能存在栈溢出或不够大的问题 dp[0] = 1; // dp[0] 表示空字符串有一种解码方式(作为基准) // dp[1] 的处理: if (nums[0] == \'0\') { dp[1] = 0; // 如果第一个字符是\'0\',无法解码 } else { dp[1] = 1; // 如果第一个字符不是\'0\',有一种解码方式 } int len = strlen(nums); for (int i = 2; i = 10 && temp <= 26) // 如果组合的两位数在10到26之间 { dp[i] += dp[i - 2]; // 则可以合并解码,加上dp[i-2]的解码方法数 } } return dp[len]; // 返回整个字符串的解码方法数}我的分析和思考:
用户这份代码对“数字翻译成字符串”问题的理解非常到位,核心逻辑完全正确!
优点:
-
DP 状态定义正确:
dp[i]表示字符串nums的前i个字符的解码方法总数。 -
状态转移方程清晰:
-
nums[i-1]单独解码:如果nums[i-1]不是\'0\',则dp[i]加上dp[i-1]。 -
nums[i-2]和nums[i-1]合并解码:如果nums[i-2]nums[i-1]组成的两位数在10到26之间,则dp[i]加上dp[i-2]。 -
这两种情况考虑得非常全面和准确。
-
-
初始化
dp[0]=1和dp[1]的处理:dp[0]=1是一个巧妙的基准,表示空字符串有一种解码方式(为了方便后续dp[i-2]的计算)。dp[1]根据nums[0]是否为\'0\'进行初始化,非常正确。
可以优化和改进的地方:
-
dp数组大小:int dp[100]是一个固定大小的数组。如果输入的nums字符串长度超过99,就会发生越界。更好的做法是根据strlen(nums)动态分配内存,或者使用变长数组(C99标准支持,但并非所有编译器都默认开启)。对于嵌入式开发,通常会避免动态内存分配,但如果字符串长度可变且较大,则需要考虑。对于本题,如果字符串长度限制在100以内,固定数组是可行的。 -
头文件缺失:
strlen需要。
深入浅出:数字翻译成字符串的DP原理与实现
咱们来彻底捋一遍数字翻译成字符串的DP思路。
1. DP 状态定义:
dp[i] 表示字符串 nums 的前 i 个字符(即 nums[0...i-1])的解码方法总数。
2. DP 状态转移方程:
考虑 dp[i],它取决于 dp[i-1] 和 dp[i-2]:
-
单独解码
nums[i-1]: 如果nums[i-1]这个字符不为\'0\'(因为\'0\'无法单独解码),那么它可以单独作为一个数字解码。此时,解码方法数等于dp[i-1]。dp[i] += dp[i-1](当nums[i-1] != \'0\') -
合并解码
nums[i-2]和nums[i-1]: 考虑nums[i-2]和nums[i-1]组成的两位数val = (nums[i-2] - \'0\') * 10 + (nums[i-1] - \'0\')。 如果val在10到26之间(即10 <= val <= 26),那么这两个字符可以作为一个整体进行解码。此时,解码方法数等于dp[i-2]。dp[i] += dp[i-2](当10 <= val <= 26)
3. 初始化:
-
dp[0] = 1:表示空字符串有一种解码方式。这听起来有点反直觉,但它是为了方便计算dp[2]时,dp[0]作为dp[i-2]的基准值。例如,对于 \"12\",dp[2]需要用到dp[0]。 -
dp[1]:-
如果
nums[0] == \'0\',则dp[1] = 0(第一个字符是0,无法解码)。 -
如果
nums[0] != \'0\',则dp[1] = 1(第一个字符可以单独解码)。
-
4. 边界条件:
-
字符串以
\'0\'开头:如果nums[0] == \'0\',则无法解码,直接返回0。 -
\'0\'的处理:如果\'0\'前面没有1或2,例如 \"30\",那么\'0\'无法单独解码,也无法与前面的3组成有效数字(30 > 26),因此解码方法数为0。
DP 状态表(以 nums = \"123\" 为例):
索引 i
字符 nums[i-1]
两位数 nums[i-2]nums[i-1]
dp[i-1]
dp[i-2]
dp[i] 计算过程
dp[i] 值
0
(空)
(空)
-
-
(初始化)
1
1
\'1\'
-
dp[0]=1
-
nums[0]!=\'0\' -> dp[1] = dp[0]
1
2
\'2\'
\"12\"
dp[1]=1
dp[0]=1
nums[1]!=\'0\' -> dp[2]+=dp[1] (1)10<=\"12\"<=26 -> dp[2]+=dp[0] (1+1)
2
3
\'3\'
\"23\"
dp[2]=2
dp[1]=1
nums[2]!=\'0\' -> dp[3]+=dp[2] (2)10<=\"23\"<=26 -> dp[3]+=dp[1] (2+1)
3
解释:
-
\"1\":一种解码方式 (\"A\")
-
\"12\":两种解码方式 (\"AB\", \"L\")
-
\"123\":三种解码方式 (\"ABC\", \"LC\", \"AW\")
优化与最终代码 (C语言)
对用户代码进行少量优化,主要集中在注释和对固定数组大小的说明。
#include // 标准输入输出,用于printf等#include // 字符串操作函数,用于strlen/** * @brief 计算数字字符串的解码方法总数 * * 本函数使用动态规划(Dynamic Programming, DP)来解决数字字符串解码问题。 * dp[i] 表示字符串 nums 的前 i 个字符 (nums[0...i-1]) 的解码方法总数。 * * @param nums 只包含数字的非空字符串 * @return int 解码方法的总数。如果无法解码(如\"0\"开头),返回0。 */int decodeWays(char *nums) { // 1. 输入校验:处理空指针或空字符串 if (nums == NULL || strlen(nums) == 0) { return 0; // 空字符串没有解码方法,或者题目要求非空,这里返回0 } int len = strlen(nums); // 2. 特殊情况处理:如果字符串以 \'0\' 开头,则无法解码 if (nums[0] == \'0\') { return 0; } // 3. DP 数组定义与初始化 // dp[i] 存储 nums 的前 i 个字符的解码方法数 // 数组大小 len + 1,dp[0] 用于基准情况,dp[len] 存储最终结果 // 注意:这里使用固定大小数组101,如果输入字符串长度可能超过100, // 建议使用动态内存分配 int *dp = (int *)malloc((len + 1) * sizeof(int)); // 或根据实际情况调整数组大小。 int dp[101]; // 假设字符串最大长度为100 // 初始化 dp[0] 为 1,表示空字符串有一种解码方式(作为递归的基准) dp[0] = 1; // 初始化 dp[1] // 如果 nums[0] 是 \'0\',则 dp[1] 为 0 (已在函数开头处理) // 否则,dp[1] 为 1 (第一个字符可以单独解码) dp[1] = 1; // 4. 遍历填充 DP 数组 for (int i = 2; i = 10 && two_digit_num <= 26) { dp[i] += dp[i - 2]; } } // 5. 返回最终结果 return dp[len];}/*// 示例用法 (可以放在main函数中测试)int main() { char *s1 = \"12\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s1, decodeWays(s1)); // 预期输出: 2 (\"AB\", \"L\") char *s2 = \"226\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s2, decodeWays(s2)); // 预期输出: 3 (\"BBF\", \"VF\", \"BZ\") char *s3 = \"0\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s3, decodeWays(s3)); // 预期输出: 0 char *s4 = \"06\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s4, decodeWays(s4)); // 预期输出: 0 char *s5 = \"10\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s5, decodeWays(s5)); // 预期输出: 1 (\"J\") char *s6 = \"30\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s6, decodeWays(s6)); // 预期输出: 0 char *s7 = \"1\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s7, decodeWays(s7)); // 预期输出: 1 char *s8 = \"\"; printf(\"\'%s\' 的解码方法数: %d\\n\", s8, decodeWays(s8)); // 预期输出: 0 return 0;}*/代码改进总结:
改进点
原因/目的
效果
头文件补全
确保代码的完整性。
避免编译警告。
空字符串/空指针处理
提高代码鲁棒性。
确保函数在接收无效输入时能正确处理。
nums[0] == \'0\' 特殊处理
字符串以 \'0\' 开头时,无法解码。提前处理可以简化后续逻辑。
代码更清晰,避免不必要的循环。
dp 数组大小说明
明确指出了固定大小数组的限制,并建议了动态分配的替代方案。
提醒读者注意潜在的越界问题,并提供解决方案,这在嵌入式开发中尤其重要(资源限制)。
详细注释
解释了DP状态定义、转移逻辑、初始化等关键点。
提高代码可读性,方便理解和学习。
总结与展望
第一部分,咱们深入探讨了动态规划的核心思想,并通过“最长公共子串”和“数字翻译成字符串”这两个经典问题,详细分析了DP状态定义、转移方程、初始化和边界条件。从用户的代码中,我们看到了学习和进步的轨迹,也一起对代码进行了优化,使其更健壮、更易读。
记住,DP的精髓在于找到正确的状态定义和状态转移方程。多画图、多举例、多思考,你一定能攻克它!
在下一部分,我们将继续挑战更多DP难题,比如“兑换零钱”和“最长回文子串”,它们将带你领略DP在不同场景下的应用。敬请期待!
动态规划硬核之路:从兑换零钱到最长回文(第二部分)
前言:DP,不止是理论,更是实战!
上一篇咱们聊了DP的基本概念和两个字符串问题,相信大家对DP已经有了初步的认识。但DP这东西,光看理论是没用的,必须得撸起袖子,一行一行地敲代码,一次一次地调试,才能真正把它吃透。
今天,咱们继续实战,挑战两个在面试中出现频率极高的DP问题:“兑换零钱”和“最长回文子串”。这两个问题虽然看似简单,但背后蕴含的DP思想却非常值得我们反复琢磨。
4 经典问题剖析:兑换零钱 (Coin Change)
“兑换零钱”问题,也叫“硬币找零”,是背包问题的一个变种,也是DP入门的经典题目。它考察的是你如何用最少的硬币凑出目标金额。
问题描述
给定不同面额的硬币 arr(数组),和一个总金额 aim。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
用户代码分析与思考
我们先来看看用户提供的 minMoney 函数:
/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 最少货币数 * @param arr int整型一维数组 the array * @param arrLen int arr数组长度 * @param aim int整型 the target * @return int整型 */#include // 补充头文件#include // 补充头文件,用于INT_MAX#include // 补充头文件,用于malloc (如果动态分配dp数组)int min(int a, int b){ return a < b ? a : b;}int minMoney(int *arr, int arrLen, int aim){ // 1. 输入校验:处理空数组或目标金额为负的情况 if (arr == NULL || arrLen == 0 || aim < 0) { return -1; // 无效输入 } if (aim == 0) { return 0; // 目标金额为0,不需要任何硬币 } // 2. DP 数组定义与初始化 // dp[i] 表示凑成金额 i 所需的最少硬币数 // 我们需要一个比任何可能硬币数都大的值来表示“不可达”状态 // aim + 1 是一个很好的选择,因为它肯定大于凑成 aim 所需的最大硬币数 (即全部用1元硬币) int dp[aim + 1]; // 固定大小数组,如果aim很大,可能栈溢出,建议动态分配或堆分配 dp[0] = 0; // 凑成金额0需要0个硬币 // 将所有其他金额的初始值设为“不可达” for (int i = 1; i <= aim; i++) { dp[i] = aim + 1; // 初始化为“无穷大” } // 3. 遍历填充 DP 数组 // 外层循环遍历硬币面额:每个硬币都可能被用来凑成目标金额 for (int i = 0; i < arrLen; i++) { int currentCoin = arr[i]; // 当前考虑的硬币面额 // 内层循环遍历目标金额:从当前硬币面额开始,到目标金额aim // 为什么从 currentCoin 开始?因为凑成小于 currentCoin 的金额用不到这个硬币 for (int j = currentCoin; j <= aim; j++) { // 状态转移方程: // dp[j] 可以由两种方式得到: // a) 不使用当前硬币 currentCoin,那么 dp[j] 保持原值 // b) 使用当前硬币 currentCoin,那么 dp[j] = dp[j - currentCoin] + 1 // 前提是 dp[j - currentCoin] 必须是可达的 (即不等于 aim + 1) if (dp[j - currentCoin] != aim + 1) { dp[j] = min(dp[j], dp[j - currentCoin] + 1); } } } // 4. 返回最终结果 // 如果 dp[aim] 仍然是 aim + 1,说明目标金额不可达 if (dp[aim] == aim + 1) { return -1; } else { return dp[aim]; }}我的分析和思考:
用户这份代码是“兑换零钱”问题的标准解法之一,而且是经过“2刷”后的版本,逻辑非常清晰和正确!
优点:
-
DP 状态定义正确:
dp[i]表示凑成金额i所需的最少硬币数。 -
状态转移方程正确:
dp[j] = min(dp[j], dp[j - currentCoin] + 1)完美体现了选择当前硬币或不选择当前硬币的决策。 -
初始化巧妙:
dp[0] = 0和dp[i] = aim + 1(表示“无穷大”或“不可达”) 是解决这类问题的经典技巧。aim + 1作为一个不可能达到的硬币数量,非常适合作为“无穷大”的替代。 -
循环顺序正确:外层遍历硬币,内层遍历金额,这种顺序保证了每个金额
j在计算时,都考虑了所有可用的硬币面额。 -
可达性判断:
if (dp[j - tempCoin] != aim + 1)确保了只有当j - tempCoin这个子金额是可达的时候,才进行状态转移,避免了无效的计算。
可以优化和改进的地方:
-
头文件缺失:
min函数通常不需要额外头文件,但INT_MAX需要。虽然aim + 1足够作为“无穷大”,但使用INT_MAX会更通用。 -
数组大小:
int dp[aim + 1]是一个栈上的固定大小数组。如果aim非常大(例如几万、几十万),可能会导致栈溢出。在嵌入式环境中,栈空间通常有限,这种情况下应该考虑使用堆内存malloc来动态分配dp数组,并在函数结束时free掉。 -
输入校验:对于
arr为NULL或arrLen为0的情况,以及aim为负数的情况,可以提前返回-1。
深入浅出:兑换零钱的DP原理与实现
咱们来彻底捋一遍兑换零钱的DP思路。
1. DP 状态定义:
dp[i]:表示凑成金额 i 所需的最少硬币数。
2. DP 状态转移方程:
对于每一个目标金额 j,我们遍历所有可用的硬币面额 coin。如果 j >= coin,那么我们就可以考虑使用这个 coin 来凑成 j。 此时,dp[j] 的值应该更新为: dp[j] = min(dp[j], dp[j - coin] + 1)
这个方程的含义是:凑成金额 j 的最少硬币数,要么是之前已经计算出来的 dp[j](即不使用当前 coin),要么是凑成 j - coin 的最少硬币数再加上当前这一个 coin。我们取这两种情况的最小值。
3. 初始化:
-
dp[0] = 0:凑成金额 0 需要 0 个硬币。这是我们DP的基准。 -
dp[i] = aim + 1(对于i > 0):将所有其他金额的初始值设置为一个“不可能达到”的值,例如aim + 1。这样,如果某个金额最终仍是这个值,就说明它无法被硬币组合凑成。
4. 计算顺序:
外层循环遍历硬币面额 coin,内层循环遍历目标金额 j (从 coin 到 aim)。这种顺序确保了在计算 dp[j] 时,dp[j - coin] 已经被正确计算过,并且考虑了所有 coin 的组合。
DP 状态表(以 arr = {1, 2, 5}, aim = 11 为例):
假设 aim + 1 = 12 为“不可达”值。
金额 j
dp[j] 初始化
coin = 1
coin = 2
coin = 5
最终 dp[j]
0
0
0
0
0
0
1
12
min(12, dp[0]+1) = 1
1
1
1
2
12
min(12, dp[1]+1) = 2
min(2, dp[0]+1) = 1
1
1
3
12
min(12, dp[2]+1) = 2
min(2, dp[1]+1) = 2
2
2
4
12
min(12, dp[3]+1) = 3
min(3, dp[2]+1) = 2
2
2
5
12
min(12, dp[4]+1) = 3
min(3, dp[3]+1) = 3
min(3, dp[0]+1) = 1
1
6
12
min(12, dp[5]+1) = 2
min(2, dp[4]+1) = 3
min(2, dp[1]+1) = 2
2
7
12
min(12, dp[6]+1) = 3
min(3, dp[5]+1) = 2
min(3, dp[2]+1) = 2
2
8
12
min(12, dp[7]+1) = 3
min(3, dp[6]+1) = 3
min(3, dp[3]+1) = 3
3
9
12
min(12, dp[8]+1) = 4
min(4, dp[7]+1) = 3
min(4, dp[4]+1) = 3
3
10
12
min(12, dp[9]+1) = 4
min(4, dp[8]+1) = 4
min(4, dp[5]+1) = 2
2
11
12
min(12, dp[10]+1) = 3
min(3, dp[9]+1) = 4
min(3, dp[6]+1) = 3
3
最终 dp[11] 为 3,表示凑成 11 最少需要 3 个硬币 (例如 5 + 5 + 1)。
优化与最终代码 (C语言)
结合上述分析,我将用户的代码进行优化,并添加更详细的注释,使其更符合生产级代码的要求,也更便于理解。
#include // 标准输入输出,用于printf等#include // 字符串操作函数,用于strlen (虽然这里没用,但习惯性引入)#include // 内存分配函数,用于malloc, free#include // 用于 INT_MAX,表示“无穷大”/** * @brief 辅助函数:返回两个整数中的较小值 * @param a 整数1 * @param b 整数2 * @return int 较小值 */int getMin(int a, int b) { return a < b ? a : b;}/** * @brief 计算凑成目标金额所需的最少硬币数 * * 本函数使用动态规划(Dynamic Programming, DP)来解决硬币找零问题。 * dp[i] 存储凑成金额 i 所需的最少硬币数。 * * @param arr 硬币面额数组 * @param arrLen 数组长度 * @param aim 目标金额 * @return int 最少硬币数。如果无法凑成,返回 -1。 */int minMoneyOptimized(int *arr, int arrLen, int aim) { // 1. 输入校验:处理空数组、无效长度或目标金额为负的情况 if (arr == NULL || arrLen <= 0 || aim < 0) { return -1; // 无效输入 } if (aim == 0) { return 0; // 目标金额为0,不需要任何硬币 } // 2. DP 数组定义与初始化 // dp[i] 表示凑成金额 i 所需的最少硬币数 // 使用动态内存分配,避免栈溢出问题,尤其在 aim 较大时 int *dp = (int *)malloc((aim + 1) * sizeof(int)); if (dp == NULL) { return -1; // 内存分配失败 } // 初始化 dp[0] 为 0,表示凑成金额 0 需要 0 个硬币 dp[0] = 0; // 将所有其他金额的初始值设为“不可达” (一个比任何可能硬币数都大的值) // INT_MAX 是一个很好的选择,因为它代表了整数的最大值,确保了任何有效硬币数都会比它小 for (int i = 1; i <= aim; i++) { dp[i] = INT_MAX; // 初始化为“无穷大” } // 3. 遍历填充 DP 数组 // 外层循环遍历所有可用的硬币面额 for (int i = 0; i < arrLen; i++) { int currentCoin = arr[i]; // 当前正在考虑的硬币面额 // 内层循环遍历所有可能的金额,从当前硬币面额开始 // 这样可以确保每个金额 j 都考虑了使用 currentCoin 的情况 // 并且 dp[j - currentCoin] 在计算 dp[j] 时已经被计算过了 for (int j = currentCoin; j <= aim; j++) { // 只有当 dp[j - currentCoin] 是一个可达的值 (不是 INT_MAX) 时, // 才能通过加上 currentCoin 来更新 dp[j] if (dp[j - currentCoin] != INT_MAX) { // 状态转移方程: // dp[j] = min(不使用 currentCoin 的情况, 使用 currentCoin 的情况) // 不使用 currentCoin 的情况就是 dp[j] 的当前值 // 使用 currentCoin 的情况就是 dp[j - currentCoin] + 1 dp[j] = getMin(dp[j], dp[j - currentCoin] + 1); } } } // 4. 返回最终结果 // 如果 dp[aim] 仍然是 INT_MAX,说明目标金额无法被给定硬币凑成 if (dp[aim] == INT_MAX) { free(dp); // 释放内存 return -1; } else { int result = dp[aim]; free(dp); // 释放内存 return result; }}/*// 示例用法 (可以放在main函数中测试)int main() { int coins1[] = {1, 2, 5}; int len1 = sizeof(coins1) / sizeof(coins1[0]); int aim1 = 11; printf(\"金额 %d, 硬币 {%d, %d, %d} 的最少硬币数: %d\\n\", aim1, coins1[0], coins1[1], coins1[2], minMoneyOptimized(coins1, len1, aim1)); // 预期输出: 3 int coins2[] = {2}; int len2 = sizeof(coins2) / sizeof(coins2[0]); int aim2 = 3; printf(\"金额 %d, 硬币 {%d} 的最少硬币数: %d\\n\", aim2, coins2[0], minMoneyOptimized(coins2, len2, aim2)); // 预期输出: -1 int coins3[] = {1}; int len3 = sizeof(coins3) / sizeof(coins3[0]); int aim3 = 0; printf(\"金额 %d, 硬币 {%d} 的最少硬币数: %d\\n\", aim3, coins3[0], minMoneyOptimized(coins3, len3, aim3)); // 预期输出: 0 int coins4[] = {186, 419, 83, 408}; int len4 = sizeof(coins4) / sizeof(coins4[0]); int aim4 = 6249; printf(\"金额 %d, 硬币 {..., %d} 的最少硬币数: %d\\n\", aim4, coins4[len4-1], minMoneyOptimized(coins4, len4, aim4)); // 预期输出: 20 int coins5[] = {5, 2, 3}; int len5 = sizeof(coins5) / sizeof(coins5[0]); int aim5 = 20; printf(\"金额 %d, 硬币 {%d, %d, %d} 的最少硬币数: %d\\n\", aim5, coins5[0], coins5[1], coins5[2], minMoneyOptimized(coins5, len5, aim5)); // 预期输出: 4 (5+5+5+5 或 5+5+2+2+2+2+2) return 0;}*/代码改进总结:
改进点
原因/目的
效果
头文件补全
确保代码的完整性、健壮性。
避免编译警告和潜在的运行时错误。
malloc 动态分配 dp 数组
解决 aim 较大时可能出现的栈溢出问题。
提高代码的鲁棒性和可伸缩性,能够处理更大规模的问题。
内存泄漏处理
确保 malloc 的内存在使用完毕后及时 free 掉。
避免内存泄漏,这在嵌入式系统资源有限且需要长时间运行的场景下尤其重要。
INT_MAX 作为“无穷大”
使用标准库提供的最大整数值,更通用、更清晰地表示“不可达”状态。
提高代码的可读性和通用性。
详细注释
解释每一步的逻辑、变量含义和设计思路,特别是DP状态转移的推导过程。
极大地提高了代码的可读性、可维护性,方便他人理解和自己回顾。
输入校验
对 arr 为 NULL、arrLen 为 0、aim 为负数等情况进行提前处理。
提高代码的健壮性,防止非法输入导致程序崩溃。
5 经典问题剖析:最长回文子串 (Longest Palindromic Substring)
“最长回文子串”是另一个非常经典的字符串问题。回文串是指正读反读都一样的字符串,比如“aba”、“level”。这个问题有两种常见的DP解法,用户采用的是“中心扩展法”,这是一种非常高效且直观的方法。
问题描述
给定一个字符串 A,找出它的最长回文子串的长度。
用户代码分析与思考
我们先来看看用户提供的 getLongestPalindrome 函数:
#include #include // 补充头文件// #include // 这个头文件在这里是不需要的,可以移除// 辅助函数:从中心向两边扩展,计算回文串的长度// @param a 原始字符串// @param len 字符串长度// @param left 中心左侧或中心点// @param right 中心右侧或中心点// @return int 回文子串的长度int doFunc(char *a, int len, int left, int right){ // 当 left >= 0 且 right = 0 && right b ? a : b;}/** * @brief 查找字符串的最长回文子串的长度 * * 本函数使用“中心扩展法”来查找最长回文子串的长度。 * 遍历字符串中的每一个字符作为回文串的中心(奇数长度), * 以及每两个相邻字符的间隙作为回文串的中心(偶数长度), * 然后从中心向两边扩展,计算最长回文串的长度。 * * @param A 输入字符串 * @return int 最长回文子串的长度。如果字符串为空或NULL,返回0。 */int getLongestPalindrome(char *A){ // 1. 输入校验:处理空指针或空字符串 if (A == NULL || strlen(A) == 0) { return 0; // 空字符串没有回文子串,长度为0 } int len = strlen(A); // 2. 特殊情况处理:单个字符的字符串,最长回文长度为1 if (len == 1) { return 1; } int maxLen = 1; // 最小的回文子串是单个字符,所以初始maxLen为1 // 3. 遍历所有可能的中心点 // 每个字符都可以是奇数长度回文串的中心 (i, i) // 每两个相邻字符的间隙可以是偶数长度回文串的中心 (i, i+1) for (int i = 0; i maxLen) { maxLen = tempM; } } return maxLen;}我的分析和思考:
用户这份代码是“最长回文子串长度”问题的经典“中心扩展法”实现,逻辑非常正确,而且 doFunc 中长度的计算 right - left - 1 也非常巧妙和准确。
优点:
-
“中心扩展法”的应用:用户采用了高效且易于理解的中心扩展法,通过遍历所有可能的中心点来寻找回文串。
-
doFunc辅助函数:将从中心向外扩展的逻辑封装成一个单独的函数,提高了代码的模块化和可读性。 -
奇偶长度回文串的处理:通过
doFunc(A, len, i, i)处理奇数长度回文串,doFunc(A, len, i, i + 1)处理偶数长度回文串,考虑到了所有情况。 -
maxLen的正确更新:能够正确地记录并更新最长回文子串的长度。 -
right - left - 1计算长度:这是中心扩展法中计算回文长度的精髓,非常正确。
可以优化和改进的地方:
-
头文件移除:
#include在这里是完全不需要的,可以移除。 -
空字符串/空指针处理:
if (!A) return -1 + 1;这里的-1 + 1应该直接是return 0;,更清晰。用户在if (A == NULL || strlen(A) == 0)已经做了很好的处理。 -
注释的完善:虽然用户已经有注释,但可以进一步细化
doFunc的作用和right - left - 1的原理,以及getLongestPalindrome的整体思路。
深入浅出:最长回文子串的DP原理与实现(中心扩展法与DP表法)
最长回文子串问题有两种主流的DP解法:
1. 中心扩展法 (用户采用的,更适合求长度)
-
核心思想:回文串都是围绕一个中心(一个字符或两个字符的间隙)对称的。我们遍历字符串中的每一个字符(作为奇数长度回文的中心)和每两个相邻字符的间隙(作为偶数长度回文的中心),然后从这些中心点向两边扩展,直到遇到不匹配的字符或到达字符串边界。在扩展过程中,记录并更新找到的最长回文串的长度。
-
DP 状态:严格来说,中心扩展法不是典型的DP填表,它更像是一种枚举和扩展的策略。但其“子问题”是判断以某个中心点扩展的回文串长度,并利用了“如果
s[i...j]是回文,那么s[i+1...j-1]也是回文”的性质。 -
优势:实现相对简单,时间复杂度通常为 O(N2) (N为字符串长度),空间复杂度为 O(1) (不考虑结果字符串存储)。
2. 动态规划表法 (更适合求子串本身)
-
DP 状态定义:
dp[i][j]:表示子串A[i...j]是否为回文串。-
dp[i][j] = true如果A[i...j]是回文串。 -
dp[i][j] = false如果A[i...j]不是回文串。
-
-
DP 状态转移方程:
-
基准情况 (长度为1或2的子串):
-
如果
i == j(长度为1):dp[i][i] = true(单个字符总是回文)。 -
如果
j - i == 1(长度为2):dp[i][i+1] = (A[i] == A[i+1])。
-
-
一般情况 (长度大于2的子串):
-
dp[i][j] = (A[i] == A[j] && dp[i+1][j-1]) -
这意味着,如果
A[i]和A[j]匹配,并且它们内部的子串A[i+1...j-1]也是回文,那么A[i...j]就是回文。
-
-
-
计算顺序: 通常是按照子串的长度
L从 1 到len遍历,然后遍历起始索引i,计算结束索引j = i + L - 1。这样可以确保在计算dp[i][j]时,dp[i+1][j-1]已经被计算过了。 -
优势:可以方便地记录最长回文子串的起始和结束位置,直接返回子串本身。时间复杂度 O(N2),空间复杂度 O(N2)。
DP 状态表(DP表法以 A = \"babad\" 为例):
dp[i][j] 表示 A[i...j] 是否为回文。
b(0)
a(1)
b(2)
a(3)
d(4)
b(0)
T
F
T
F
F
a(1)
T
F
T
F
b(2)
T
F
F
a(3)
T
F
d(4)
T
解释:
-
dp[0][0](b): T -
dp[1][1](a): T -
dp[0][1](ba): F (b!=a) -
dp[0][2](bab):A[0]==A[2](b==b) 且dp[1][1](a) 为 T,所以dp[0][2]为 T。 -
dp[1][3](aba):A[1]==A[3](a==a) 且dp[2][2](b) 为 T,所以dp[1][3]为 T。
通过填充这张表,我们就能找到 true 值为最长的 (j-i+1) 的 dp[i][j],从而确定最长回文子串。
为什么用户代码选择了中心扩展法?
因为题目只要求返回最长回文子串的长度。中心扩展法在求长度时,空间复杂度更优 (O(1) vs O(N2)),且实现逻辑也相对直观。对于嵌入式开发,资源受限,更低的内存占用通常是优先考虑的。
优化与最终代码 (C语言)
对用户代码进行优化,主要是完善注释和移除不需要的头文件。
#include // 标准输入输出,用于printf等#include // 字符串操作函数,用于strlen// 辅助函数:返回两个整数中的较大值int getMax(int a, int b) { return a > b ? a : b;}/** * @brief 辅助函数:从指定中心点向两边扩展,计算回文子串的长度。 * * 该函数接收字符串、其长度以及回文串的中心点(由left和right定义)。 * left和right可以指向同一个字符(奇数长度回文),也可以指向相邻的两个字符(偶数长度回文)。 * 函数会不断向外扩展,直到遇到不匹配的字符或到达字符串边界。 * * @param s 原始字符串 * @param len 字符串长度 * @param left 回文中心点的左边界索引 * @param right 回文中心点的右边界索引 * @return int 扩展出的回文子串的长度 */int expandAroundCenter(char *s, int len, int left, int right) { // 循环条件:左右指针均在有效范围内,且左右指针指向的字符相同 while (left >= 0 && right < len && s[left] == s[right]) { left--; // 左指针向左移动 right++; // 右指针向右移动 } // 循环结束后,left 和 right 已经越过了回文串的实际边界 // 回文串的长度 = (right - 1) - (left + 1) + 1 = right - left - 1 return right - left - 1;}/** * @brief 查找字符串的最长回文子串的长度 * * 本函数使用“中心扩展法”来查找给定字符串的最长回文子串的长度。 * 它遍历字符串中的每一个字符作为奇数长度回文串的中心, * 以及每两个相邻字符的间隙作为偶数长度回文串的中心。 * 对于每个中心点,调用 expandAroundCenter 函数向两边扩展, * 并记录找到的最长回文串的长度。 * * @param A 输入字符串 * @return int 最长回文子串的长度。如果字符串为空或NULL,返回0。 */int getLongestPalindromeOptimized(char *A) { // 1. 输入校验:处理空指针或空字符串的情况 if (A == NULL || strlen(A) == 0) { return 0; // 空字符串没有回文子串,长度为0 } int len = strlen(A); // 2. 初始最长回文长度为1(单个字符总是回文) int maxLen = 1; // 3. 遍历所有可能的中心点 // 对于每个字符 A[i],它可能是: // a) 奇数长度回文串的中心 (例如 \"aba\" 中的 \'b\') // b) 偶数长度回文串的左中心 (例如 \"abba\" 中左边的 \'b\') for (int i = 0; i < len; i++) { // 扩展奇数长度的回文串:以 A[i] 为中心 int len1 = expandAroundCenter(A, len, i, i); // 扩展偶数长度的回文串:以 A[i] 和 A[i+1] 之间的空隙为中心 // 注意:如果 i+1 越界,expandAroundCenter 会在循环开始时处理 int len2 = expandAroundCenter(A, len, i, i + 1); // 取两种情况中较大的长度,并与当前的 maxLen 比较 maxLen = getMax(maxLen, getMax(len1, len2)); } return maxLen;}/*// 示例用法 (可以放在main函数中测试)int main() { char *s1 = \"babad\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s1, getLongestPalindromeOptimized(s1)); // 预期输出: 3 (\"bab\" 或 \"aba\") char *s2 = \"cbbd\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s2, getLongestPalindromeOptimized(s2)); // 预期输出: 2 (\"bb\") char *s3 = \"a\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s3, getLongestPalindromeOptimized(s3)); // 预期输出: 1 char *s4 = \"ac\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s4, getLongestPalindromeOptimized(s4)); // 预期输出: 1 char *s5 = \"\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s5, getLongestPalindromeOptimized(s5)); // 预期输出: 0 char *s6 = \"racecar\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s6, getLongestPalindromeOptimized(s6)); // 预期输出: 7 char *s7 = \"aaaa\"; printf(\"\'%s\' 的最长回文子串长度: %d\\n\", s7, getLongestPalindromeOptimized(s7)); // 预期输出: 4 return 0;}*/代码改进总结:
改进点
原因/目的
效果
移除不必要头文件
保持代码简洁,避免引入不必要的依赖。
提高编译效率,减少最终可执行文件大小(微乎其微,但好习惯)。
expandAroundCenter 命名
函数名更具描述性,清晰表达了其功能。
提高代码可读性。
详细注释
深入解释了“中心扩展法”的原理,left/right 移动和长度计算的逻辑。
极大地提高了代码的可读性、可维护性,便于他人理解和自己回顾。
输入校验
对 A 为 NULL 或 strlen(A) == 0 的情况进行提前处理。
提高代码的健壮性,防止非法输入导致程序崩溃。
maxLen 初始值
明确 maxLen 初始为1,因为单个字符本身就是回文串。
逻辑更严谨,覆盖了所有情况。
总结与展望
第二部分,我们继续深化动态规划的学习,攻克了“兑换零钱”和“最长回文子串”这两个硬核问题。我们不仅分析了用户代码的优点和可改进之处,还深入探讨了每种算法的DP原理、状态定义、转移方程和初始化。
通过这两个问题,我们看到了DP在处理不同类型问题时的灵活性。对于“兑换零钱”,我们用DP数组记录了凑成每个金额的最少硬币数;对于“最长回文子串”,我们则采用了高效的中心扩展法。
DP的世界远不止于此,还有更多精彩的题目等待我们去探索。在接下来的部分,我们将继续挑战“最长上升子序列”、“字符串转化IP地址”、“编辑距离”以及“打家劫舍”系列问题。
动态规划硬核之路:最长上升子序列与打家劫舍(第三部分)
前言:DP,不止是套路,更是思想!
经过前两部分的洗礼,相信大家对动态规划已经不再陌生。DP不仅仅是一堆公式和套路,它更是一种解决问题的思想:把大问题拆解成小问题,利用小问题的解来构建大问题的解。 这种思想在嵌入式开发中,尤其是在资源受限、需要高效算法的场景下,显得尤为重要。
今天,我们将继续深入,探讨两个在数组和序列问题中非常经典的DP应用:最长上升子序列 (Longest Increasing Subsequence, LIS) 和 打家劫舍 (House Robber) 系列。它们将帮助我们巩固对DP的理解,并学习如何处理更复杂的约束条件。
6 经典问题剖析:最长上升子序列 (LIS)
“最长上升子序列”是序列DP问题的典型代表。它要求我们从一个无序的序列中,找出最长的一个子序列,使得这个子序列是严格递增的。
问题描述
给定一个整数数组 arr,找出其中最长严格上升子序列的长度。
用户代码分析与思考
我们先来看看用户提供的 LIS 函数:
#include // 补充头文件#include // 补充头文件,虽然这里没用,但习惯性引入// 辅助函数:返回两个整数中的较大值int getMax(int a, int b){ return a > b ? a : b;}/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 给定数组的最长严格上升子序列的长度。 * @param arr int整型一维数组 给定的数组 * @param arrLen int arr数组长度 * @return int整型 */int LIS(int *arr, int arrLen){ // write code here // 1. 输入校验:处理空指针或空数组 if (arr == NULL || arrLen == 0) { return 0; // 空数组的最长上升子序列长度为0 } // 2. DP 数组定义与初始化 // dp[i] 表示以 arr[i] 结尾的最长上升子序列的长度 // 任何单个元素本身就是一个长度为1的上升子序列 int dp[arrLen]; // 固定大小数组,如果arrLen很大,可能栈溢出,建议动态分配 for (int i = 0; i < arrLen; i++) { dp[i] = 1; // 初始化:每个元素自身构成一个长度为1的上升子序列 } int maxLen = 1; // 记录整个数组中的最长上升子序列长度,至少为1 (当数组非空时) // 3. 遍历填充 DP 数组 // 外层循环:遍历数组中的每一个元素 arr[i],作为当前子序列的“结尾” for (int i = 0; i < arrLen; i++) { // 内层循环:遍历 arr[i] 之前的所有元素 arr[j] for (int j = 0; j < i; j++) { // 状态转移条件:如果 arr[j] 小于 arr[i] // 意味着 arr[i] 可以接在以 arr[j] 结尾的上升子序列后面 if (arr[j] < arr[i]) { // 状态转移方程: // dp[i] = max(dp[i], dp[j] + 1) // 比较: // a) 保持当前以 arr[i] 结尾的子序列长度 (dp[i] 的当前值) // b) 将 arr[i] 接在以 arr[j] 结尾的子序列后面,形成的新长度 (dp[j] + 1) dp[i] = getMax(dp[i], dp[j] + 1); } // else { // // 如果 arr[j] 不小于 arr[i],则 arr[i] 不能接在以 arr[j] 结尾的子序列后面 // // 此时 dp[i] 不变,或者说不考虑从 dp[j] 转移过来 // ; // 用户原始代码中的空语句,可以省略 // } } // 每次计算完 dp[i] 后,更新全局的最大长度 maxLen = getMax(maxLen, dp[i]); } // 4. 返回最终结果 // return dp[arrLen - 1]; // 错误:dp[arrLen-1] 只是以最后一个元素结尾的LIS长度 return maxLen; // 正确:返回全局最大长度}我的分析和思考:
用户这份代码对于最长上升子序列的DP解法理解得非常透彻,核心逻辑和状态转移方程都是正确的。特别是 dp[i] = getMax(dp[i], dp[j] + 1) 这一步,完美体现了LIS的DP思想。
优点:
-
DP 状态定义清晰:
dp[i]表示以arr[i]结尾的最长上升子序列的长度。这个定义非常关键,是解决LIS问题的核心。 -
状态转移方程正确:
dp[i] = max(dp[i], dp[j] + 1)准确地捕获了如果arr[i]大于arr[j],那么arr[i]就可以接在以arr[j]结尾的LIS后面,形成一个更长的LIS。 -
初始化正确:
dp[i] = 1,每个元素自身都可以构成一个长度为1的上升子序列,这是正确的初始状态。 -
全局
maxLen记录:用户正确地认识到最终结果是dp数组中的最大值,而不是dp[arrLen - 1],并用maxLen变量来记录,这非常重要。
可以优化和改进的地方:
-
数组大小:
int dp[arrLen]是一个栈上的固定大小数组(C99支持变长数组,但并非所有编译器都默认开启或推荐在嵌入式中使用)。如果arrLen非常大,可能会导致栈溢出。在嵌入式环境中,栈空间通常有限,这种情况下应该考虑使用堆内存malloc来动态分配dp数组,并在函数结束时free掉。 -
头文件缺失:
strlen虽然在注释中提到了,但实际代码中并未用到,可以移除string.h。getMax辅助函数不需要额外头文件。 -
注释的完善:虽然用户已经有注释,但可以进一步细化
dp[i]的含义,以及为什么需要maxLen来记录全局最大值。
深入浅出:最长上升子序列的DP原理与实现
咱们来彻底捋一遍最长上升子序列的DP思路。
1. DP 状态定义:
dp[i]:表示以 arr[i] 这个元素结尾的最长上升子序列的长度。
2. DP 状态转移方程:
要计算 dp[i],我们需要向前看,遍历所有 j < i 的元素 arr[j]。 如果 arr[j] < arr[i],这意味着 arr[i] 可以接在以 arr[j] 结尾的任何上升子序列后面,形成一个新的上升子序列。 那么,以 arr[i] 结尾的上升子序列的长度,就可以是 dp[j] + 1。 由于我们希望找到最长的,所以 dp[i] 应该取所有符合条件的 dp[j] + 1 中的最大值。 dp[i] = max(dp[i], dp[j] + 1) (其中 arr[j] < arr[i])
3. 初始化:
-
dp[i] = 1:对于数组中的每一个元素arr[i],它自身至少可以构成一个长度为1的上升子序列。这是所有dp[i]的初始值。
4. 计算顺序:
外层循环从 i = 0 到 arrLen - 1 遍历数组,内层循环从 j = 0 到 i - 1 遍历 i 之前的元素。这种顺序确保了在计算 dp[i] 时,所有 dp[j] (其中 j < i) 都已经被计算过了。
DP 状态表(以 arr = {10, 9, 2, 5, 3, 7, 101, 18} 为例):
索引 i
arr[i]
dp[i] 初始化
j=0 (10)
j=1 (9)
j=2 (2)
j=3 (5)
j=4 (3)
j=5 (7)
j=6 (101)
最终 dp[i]
maxLen
0
10
1
-
-
-
-
-
-
-
1
1
1
9
1
9<10 (不)
-
-
-
-
-
-
1
1
2
2
1
2<10 (不)
2<9 (不)
-
-
-
-
-
1
1
3
5
1
5<10 (1)
5<9 (1)
5>2 (dp[2]+1=2)
-
-
-
-
2
2
4
3
1
3<10 (1)
3<9 (1)
3>2 (dp[2]+1=2)
3<5 (不)
-
-
-
2
2
5
7
1
7<10 (1)
7<9 (1)
7>2 (dp[2]+1=2)
7>5 (dp[3]+1=3)
7>3 (dp[4]+1=3)
-
-
3
3
6
101
1
101>所有 (dp[0]+1=2, dp[1]+1=2, dp[2]+1=2, dp[3]+1=3, dp[4]+1=3, dp[5]+1=4)
-
-
-
-
-
-
4
4
7
18
1
18>10 (2)
18>9 (2)
18>2 (2)
18>5 (3)
18>3 (3)
18>7 (4)
18<101 (不)
4
4
最终 maxLen 为 4。对应的LIS可以是 {2, 3, 7, 18} 或 {2, 5, 7, 18}。
优化与最终代码 (C语言)
结合上述分析,我将用户的代码进行优化,主要是使用动态内存分配 dp 数组,并添加更详细的注释。
#include // 标准输入输出,用于printf等#include // 内存分配函数,用于malloc, free/** * @brief 辅助函数:返回两个整数中的较大值 * @param a 整数1 * @param b 整数2 * @return int 较小值 */int getMax(int a, int b) { return a > b ? a : b;}/** * @brief 计算给定数组的最长严格上升子序列的长度。 * * 本函数使用动态规划(Dynamic Programming, DP)来解决最长上升子序列问题。 * dp[i] 存储以 arr[i] 结尾的最长上升子序列的长度。 * * @param arr int整型一维数组 给定的数组 * @param arrLen int arr数组长度 * @return int整型 最长严格上升子序列的长度。如果数组为空,返回0。 */int longestIncreasingSubsequence(int *arr, int arrLen) { // 1. 输入校验:处理空指针或空数组的情况 if (arr == NULL || arrLen == 0) { return 0; // 空数组的最长上升子序列长度为0 } // 2. DP 数组定义与初始化 // dp[i] 表示以 arr[i] 结尾的最长上升子序列的长度 // 使用动态内存分配,避免栈溢出问题,尤其在 arrLen 较大时 int *dp = (int *)malloc(arrLen * sizeof(int)); if (dp == NULL) { return 0; // 内存分配失败,返回0或-1表示错误 } // 初始化:每个元素自身构成一个长度为1的上升子序列 for (int i = 0; i < arrLen; i++) { dp[i] = 1; } // 记录整个数组中的最长上升子序列长度,初始至少为1(当数组非空时) int maxOverallLen = 1; // 3. 遍历填充 DP 数组 // 外层循环:遍历数组中的每一个元素 arr[i],将其作为当前考虑的上升子序列的“结尾” for (int i = 0; i < arrLen; i++) { // 内层循环:遍历 arr[i] 之前的所有元素 arr[j] // 尝试将 arr[i] 连接到以 arr[j] 结尾的上升子序列后面 for (int j = 0; j < i; j++) { // 状态转移条件:如果 arr[j] 小于 arr[i] // 意味着 arr[i] 可以接在以 arr[j] 结尾的上升子序列后面 if (arr[j] < arr[i]) { // 状态转移方程: // dp[i] = max(dp[i], dp[j] + 1) // 比较两种情况: // a) 保持当前以 arr[i] 结尾的子序列长度(即 arr[i] 自身构成子序列) // b) 将 arr[i] 接在以 arr[j] 结尾的子序列后面,形成的新长度 (dp[j] + 1) dp[i] = getMax(dp[i], dp[j] + 1); } } // 每次计算完 dp[i] 后,更新全局的最大长度 maxOverallLen = getMax(maxOverallLen, dp[i]); } // 4. 释放动态分配的内存 free(dp); // 5. 返回最终结果 return maxOverallLen;}/*// 示例用法 (可以放在main函数中测试)int main() { int arr1[] = {10, 9, 2, 5, 3, 7, 101, 18}; int len1 = sizeof(arr1) / sizeof(arr1[0]); printf(\"数组 {10, 9, 2, 5, 3, 7, 101, 18} 的最长上升子序列长度: %d\\n\", longestIncreasingSubsequence(arr1, len1)); // 预期输出: 4 int arr2[] = {0, 1, 0, 3, 2, 3}; int len2 = sizeof(arr2) / sizeof(arr2[0]); printf(\"数组 {0, 1, 0, 3, 2, 3} 的最长上升子序列长度: %d\\n\", longestIncreasingSubsequence(arr2, len2)); // 预期输出: 4 int arr3[] = {7, 7, 7, 7, 7, 7, 7}; int len3 = sizeof(arr3) / sizeof(arr3[0]); printf(\"数组 {7, 7, 7, 7, 7, 7, 7} 的最长上升子序列长度: %d\\n\", longestIncreasingSubsequence(arr3, len3)); // 预期输出: 1 int arr4[] = {}; int len4 = sizeof(arr4) / sizeof(arr4[0]); printf(\"空数组的最长上升子序列长度: %d\\n\", longestIncreasingSubsequence(arr4, len4)); // 预期输出: 0 int arr5[] = {1}; int len5 = sizeof(arr5) / sizeof(arr5[0]); printf(\"数组 {1} 的最长上升子序列长度: %d\\n\", longestIncreasingSubsequence(arr5, len5)); // 预期输出: 1 int arr6[] = {47, 89, 23, 76, 12, 55, 34, 91, 62, 7, 38, 81, 44, 50, 99}; int len6 = sizeof(arr6) / sizeof(arr6[0]); printf(\"数组 {47, 89, ..., 99} 的最长上升子序列长度: %d\\n\", longestIncreasingSubsequence(arr6, len6)); // 预期输出: 6 (例如 23, 34, 38, 44, 50, 99) return 0;}*/代码改进总结:
改进点
原因/目的
效果
malloc 动态分配 dp 数组
解决 arrLen 较大时可能出现的栈溢出问题。
提高代码的鲁棒性和可伸缩性,能够处理更大规模的问题。
内存泄漏处理
确保 malloc 的内存在使用完毕后及时 free 掉。
避免内存泄漏,这在嵌入式系统资源有限且需要长时间运行的场景下尤其重要。
输入校验
对 arr 为 NULL 或 arrLen 为 0 的情况进行提前处理。
提高代码的健壮性,防止非法输入导致程序崩溃。
详细注释
解释每一步的逻辑、变量含义和设计思路,特别是DP状态转移的推导过程。
极大地提高了代码的可读性、可维护性,方便他人理解和自己回顾。
变量名优化
maxOverallLen 比 maxLen 更明确地表示全局最大长度。
提高代码可读性。
7 经典问题剖析:打家劫舍 (House Robber)
“打家劫舍”问题是DP中非常经典的线性DP问题。它考察的是如何在有约束条件(不能偷相邻的房屋)的情况下,最大化收益。
问题描述 (一:线性排列)
你是一个专业的窃贼,计划偷窃沿街的房屋。每间房屋都存放着特定金额的现金。现在,你面临一个特殊挑战:相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被偷,系统会自动报警。
给定一个非负整数数组 nums,表示每间房屋的金额,计算你在不触发警报的情况下,能够偷窃到的最高总金额。
用户代码分析与思考
我们先来看看用户提供的 rob 函数(线性排列版本):
#include // 补充头文件#include // 补充头文件,如果需要动态分配// 辅助函数:返回两个整数中的较大值int getMax(int a, int b){ return a > b ? a : b;}/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 计算在不触发警报的情况下,能够偷窃到的最高总金额(线性排列房屋)。 * @param nums int整型一维数组 表示每间房屋的金额 * @param numsLen int nums数组长度 * @return int整型 能够偷窃到的最高总金额 */int robLinear(int *nums, int numsLen){ // write code here // 打家劫舍问题:要么搞nums[i]+dp[i-2] ,要么dp[i-1] // 1. 输入校验:处理空指针或空数组 if (nums == NULL || numsLen == 0) { return 0; // 没有房屋可偷,总金额为0 } // 2. 特殊情况处理:房屋数量较少的情况 if (numsLen == 1) { return nums[0]; // 只有一间房屋,直接偷 } if (numsLen == 2) { return getMax(nums[0], nums[1]); // 两间房屋,偷金额较大的那间 } // 3. DP 数组定义与初始化 // dp[i] 表示偷窃到第 i 间房屋(索引为 i-1)时,能够偷窃到的最高总金额 // 或者说,dp[i] 表示考虑前 i 间房屋时(索引 0 到 i-1),能偷到的最大金额 // 这里使用固定大小数组,如果 numsLen 很大,可能栈溢出,建议动态分配 int dp[numsLen]; // 初始化 dp[0] 和 dp[1] // dp[0] 对应考虑第0间房屋(即nums[0]),最大金额就是nums[0] dp[0] = nums[0]; // dp[1] 对应考虑第0和第1间房屋,最大金额是两者中较大的 dp[1] = getMax(nums[0], nums[1]); // 4. 遍历填充 DP 数组 // 从第三间房屋开始(索引为2,对应dp[2]) for (int i = 2; i < numsLen; i++) { // 状态转移方程: // 偷窃第 i 间房屋 (nums[i]):那么就不能偷第 i-1 间房屋,总金额为 nums[i] + dp[i-2] // 不偷窃第 i 间房屋 (nums[i]):那么总金额就是偷窃到第 i-1 间房屋时的最大金额,即 dp[i-1] // 我们取这两种情况中的较大值 dp[i] = getMax(dp[i - 1], nums[i] + dp[i - 2]); } // 5. 返回最终结果 // dp[numsLen - 1] 存储的就是考虑所有房屋后,能够偷窃到的最高总金额 return dp[numsLen - 1];}我的分析和思考:
用户这份代码是“打家劫舍”线性排列版本的标准DP解法,非常简洁和高效。
优点:
-
DP 状态定义正确:
dp[i]表示考虑前i+1间房屋(即索引从0到i)时,能够偷窃到的最高总金额。 -
状态转移方程正确:
dp[i] = max(dp[i-1], nums[i] + dp[i-2])精准地捕捉了“偷当前房屋”和“不偷当前房屋”两种决策。 -
初始化和边界条件处理:对于
numsLen = 0, 1, 2的特殊情况处理得当,确保了DP数组的正确初始化。
可以优化和改进的地方:
-
数组大小:
int dp[numsLen]同样存在栈溢出的风险。建议使用动态内存分配。 -
空间优化:注意到
dp[i]只依赖于dp[i-1]和dp[i-2],因此可以进行空间优化,将 O(N) 空间复杂度降到 O(1)。
深入浅出:打家劫舍的DP原理与实现 (线性排列)
咱们来彻底捋一遍打家劫舍(线性排列)的DP思路。
1. DP 状态定义:
dp[i]:表示考虑前 i 间房屋(即 nums[0...i-1])时,能够偷窃到的最高总金额。
2. DP 状态转移方程:
对于第 i 间房屋(对应 nums[i-1]):
-
选择偷窃
nums[i-1]:那么就不能偷窃第i-2间房屋(nums[i-2])。此时,总金额是nums[i-1]加上考虑前i-2间房屋时的最大金额,即nums[i-1] + dp[i-2]。 -
选择不偷窃
nums[i-1]:那么总金额就是考虑前i-1间房屋时的最大金额,即dp[i-1]。
因此,dp[i] = max(dp[i-1], nums[i-1] + dp[i-2])。 (注意:这里 dp 数组的索引 i 对应 nums 数组的 i-1 索引,这是一种常见的DP数组定义方式,方便处理边界。)
3. 初始化:
-
dp[0] = 0:考虑0间房屋,最大金额为0。 -
dp[1] = nums[0]:考虑1间房屋(nums[0]),最大金额为nums[0]。
4. 计算顺序:
从 i = 2 到 numsLen 遍历,确保 dp[i-1] 和 dp[i-2] 已经计算过。
DP 状态表(以 nums = {1, 2, 3, 1} 为例):
索引 i (考虑前i间)
对应 nums 索引
nums[i-1]
dp[i-1]
dp[i-2]
dp[i] 计算过程
dp[i] 值
0
-
-
-
-
(初始化)
0
1
0
1
dp[0]=0
-
nums[0]=1
1
2
1
2
dp[1]=1
dp[0]=0
max(dp[1], nums[1]+dp[0]) = max(1, 2+0) = 2
2
3
2
3
dp[2]=2
dp[1]=1
max(dp[2], nums[2]+dp[1]) = max(2, 3+1) = 4
4
4
3
1
dp[3]=4
dp[2]=2
max(dp[3], nums[3]+dp[2]) = max(4, 1+2) = 4
4
最终 dp[4] 为 4。
优化与最终代码 (C语言)
对用户代码进行优化,主要集中在动态内存分配和空间优化。
#include // 标准输入输出,用于printf等#include // 内存分配函数,用于malloc, free/** * @brief 辅助函数:返回两个整数中的较大值 * @param a 整数1 * @param b 整数2 * @return int 较小值 */int getMax(int a, int b) { return a > b ? a : b;}/** * @brief 计算在不触发警报的情况下,能够偷窃到的最高总金额(线性排列房屋)。 * * 本函数使用动态规划(Dynamic Programming, DP)解决打家劫舍问题(线性排列)。 * dp[i] 表示考虑前 i 间房屋时,能够偷窃到的最高总金额。 * * @param nums int整型一维数组 表示每间房屋的金额 * @param numsLen int nums数组长度 * @return int整型 能够偷窃到的最高总金额 */int robLinearOptimized(int *nums, int numsLen) { // 1. 输入校验:处理空指针或空数组 if (nums == NULL || numsLen == 0) { return 0; // 没有房屋可偷,总金额为0 } // 2. 特殊情况处理:房屋数量较少的情况 if (numsLen == 1) { return nums[0]; // 只有一间房屋,直接偷 } if (numsLen == 2) { return getMax(nums[0], nums[1]); // 两间房屋,偷金额较大的那间 } // 3. DP 数组定义与初始化 (空间优化版本) // 由于 dp[i] 只依赖于 dp[i-1] 和 dp[i-2],我们可以使用两个变量来代替整个 dp 数组 // first_prev: 相当于 dp[i-2] (考虑前 i-2 间房屋的最大金额) // second_prev: 相当于 dp[i-1] (考虑前 i-1 间房屋的最大金额) int first_prev = nums[0]; // 对应 dp[0] int second_prev = getMax(nums[0], nums[1]); // 对应 dp[1] int current_max = 0; // 存储当前计算的 dp[i] // 4. 遍历计算最大金额 // 从第三间房屋开始(索引为2) for (int i = 2; i < numsLen; i++) { // 状态转移方程: // current_max = max(不偷当前房屋, 偷当前房屋) // 不偷当前房屋:沿用 second_prev (即 dp[i-1]) // 偷当前房屋:nums[i] + first_prev (即 nums[i] + dp[i-2]) current_max = getMax(second_prev, nums[i] + first_prev); // 更新 first_prev 和 second_prev,为下一次循环做准备 first_prev = second_prev; second_prev = current_max; } // 5. 返回最终结果 // second_prev 存储的就是考虑所有房屋后,能够偷窃到的最高总金额 return second_prev;}/*// 示例用法 (可以放在main函数中测试)int main() { int nums1[] = {1, 2, 3, 1}; int len1 = sizeof(nums1) / sizeof(nums1[0]); printf(\"房屋 {1, 2, 3, 1} 能偷窃的最高金额: %d\\n\", robLinearOptimized(nums1, len1)); // 预期输出: 4 (偷 1 和 3) int nums2[] = {2, 7, 9, 3, 1}; int len2 = sizeof(nums2) / sizeof(nums2[0]); printf(\"房屋 {2, 7, 9, 3, 1} 能偷窃的最高金额: %d\\n\", robLinearOptimized(nums2, len2)); // 预期输出: 12 (偷 2, 9, 1) int nums3[] = {0}; int len3 = sizeof(nums3) / sizeof(nums3[0]); printf(\"房屋 {0} 能偷窃的最高金额: %d\\n\", robLinearOptimized(nums3, len3)); // 预期输出: 0 int nums4[] = {1}; int len4 = sizeof(nums4) / sizeof(nums4[0]); printf(\"房屋 {1} 能偷窃的最高金额: %d\\n\", robLinearOptimized(nums4, len4)); // 预期输出: 1 int nums5[] = {1, 2}; int len5 = sizeof(nums5) / sizeof(nums5[0]); printf(\"房屋 {1, 2} 能偷窃的最高金额: %d\\n\", robLinearOptimized(nums5, len5)); // 预期输出: 2 int nums6[] = {12, 9, 6, 6, 7, 7, 4, 5, 3, 7, 3, 3, 7, 5, 23, 6, 2, 36, 26, 4, 23, 6, 2, 36, 24, 36, 3, 68, 8, 12}; int len6 = sizeof(nums6) / sizeof(nums6[0]); printf(\"房屋 {12, 9, ..., 12} 能偷窃的最高金额: %d\\n\", robLinearOptimized(nums6, len6)); // 预期输出: 201 return 0;}*/代码改进总结:
改进点
原因/目的
效果
空间优化
将 O(N) 的 dp 数组优化为 O(1) 的常数空间。
降低内存占用,在嵌入式系统等内存受限环境下尤其重要。
输入校验
对 nums 为 NULL 或 numsLen 为 0 的情况进行提前处理。
提高代码的健壮性,防止非法输入导致程序崩溃。
详细注释
解释了空间优化的原理和变量的含义。
提高代码可读性,方便理解和学习。
8 经典问题剖析:打家劫舍 II (House Robber II)
“打家劫舍 II”是“打家劫舍”的进阶版本,增加了环形的约束,这让问题变得稍微复杂一些。
问题描述 (二:环形排列)
现在房屋不是线性排列,而是围成一个圈。这意味着第一间房屋和最后一间房屋是相邻的。其他规则不变:相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被偷,系统会自动报警。
给定一个非负整数数组 nums,表示每间房屋的金额,计算你在不触发警报的情况下,能够偷窃到的最高总金额。
用户代码分析与思考
我们先来看看用户提供的 rob 函数(环形排列版本):
#include // 标准输入输出,用于printf等#include // 内存分配函数,用于malloc, free// 辅助函数:返回两个整数中的较大值int getMax(int a, int b){ return a > b ? a : b;}/** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * 计算在不触发警报的情况下,能够偷窃到的最高总金额(环形排列房屋)。 * @param nums int整型一维数组 表示每间房屋的金额 * @param numsLen int nums数组长度 * @return int整型 能够偷窃到的最高总金额 */int robCircular(int *nums, int numsLen){ // 1. 输入校验和特殊情况处理 if (nums == NULL || numsLen == 0) { return 0; // 没有房屋可偷,总金额为0 } if (numsLen == 1) { return nums[0]; // 只有一间房屋,直接偷 } // 2. 将环形问题分解为两个线性问题 // 关键思想:由于首尾房屋不能同时偷窃,所以最大金额只可能出现在以下两种情况: // 情况 A: 偷窃第一间房屋,则不能偷窃最后一间房屋。 // 问题转化为:在 [0, numsLen-2] 范围内的线性打家劫舍问题。 // 情况 B: 不偷窃第一间房屋,则最后一间房屋可以偷窃。 // 问题转化为:在 [1, numsLen-1] 范围内的线性打家劫舍问题。 // 最终结果是这两种情况中的最大值。 // 2.1 情况 A: 偷窃第一间房屋 (nums[0]),不偷窃最后一间房屋 (nums[numsLen-1]) // 相当于对子数组 nums[0] 到 nums[numsLen-2] (共 numsLen-1 个元素) 进行线性打家劫舍 int *subArr1 = (int *)malloc((numsLen - 1) * sizeof(int)); if (subArr1 == NULL) return -1; // 内存分配失败 for (int i = 0; i < numsLen - 1; i++) { subArr1[i] = nums[i]; } int maxAmount1 = robLinearOptimized(subArr1, numsLen - 1); // 调用之前实现的线性打家劫舍函数 free(subArr1); // 释放内存 // 2.2 情况 B: 不偷窃第一间房屋 (nums[0]),偷窃最后一间房屋 (nums[numsLen-1]) // 相当于对子数组 nums[1] 到 nums[numsLen-1] (共 numsLen-1 个元素) 进行线性打家劫舍 int *subArr2 = (int *)malloc((numsLen - 1) * sizeof(int)); if (subArr2 == NULL) return -1; // 内存分配失败 for (int i = 0; i < numsLen - 1; i++) { subArr2[i] = nums[i+1]; // 从 nums[1] 开始复制 } int maxAmount2 = robLinearOptimized(subArr2, numsLen - 1); // 调用之前实现的线性打家劫舍函数 free(subArr2); // 释放内存 // 3. 返回两种情况中的最大值 return getMax(maxAmount1, maxAmount2);}/*// 示例用法 (可以放在main函数中测试)int main() { // 假设 robLinearOptimized 函数已在前面定义并可用 // int robLinearOptimized(int *nums, int numsLen); int nums1[] = {2, 3, 2}; int len1 = sizeof(nums1) / sizeof(nums1[0]); printf(\"环形房屋 {2, 3, 2} 能偷窃的最高金额: %d\\n\", robCircular(nums1, len1)); // 预期输出: 3 (偷 3) int nums2[] = {1, 2, 3, 1}; int len2 = sizeof(nums2) / sizeof(nums2[0]); printf(\"环形房屋 {1, 2, 3, 1} 能偷窃的最高金额: %d\\n\", robCircular(nums2, len2)); // 预期输出: 4 (偷 2 和 3) int nums3[] = {0}; int len3 = sizeof(nums3) / sizeof(nums3[0]); printf(\"环形房屋 {0} 能偷窃的最高金额: %d\\n\", robCircular(nums3, len3)); // 预期输出: 0 int nums4[] = {1}; int len4 = sizeof(nums4) / sizeof(nums4[0]); printf(\"环形房屋 {1} 能偷窃的最高金额: %d\\n\", robCircular(nums4, len4)); // 预期输出: 1 int nums5[] = {1, 2}; int len5 = sizeof(nums5) / sizeof(nums5[0]); printf(\"环形房屋 {1, 2} 能偷窃的最高金额: %d\\n\", robCircular(nums5, len5)); // 预期输出: 2 (偷 2) int nums6[] = {1, 2, 3}; int len6 = sizeof(nums6) / sizeof(nums6[0]); printf(\"环形房屋 {1, 2, 3} 能偷窃的最高金额: %d\\n\", robCircular(nums6, len6)); // 预期输出: 3 (偷 3) return 0;}*/我的分析和思考:
用户这份代码对于“打家劫舍 II”的解题思路非常正确,即将其分解为两个线性打家劫舍问题。这是解决环形DP问题的常用技巧。
优点:
-
问题分解正确:将环形问题巧妙地分解为“偷第一家,不偷最后一家”和“不偷第一家,偷最后一家”两个独立的线性问题,并取两者的最大值。
-
复用线性解法:通过调用
robLinearOptimized函数,实现了代码的复用,体现了模块化思想。 -
内存管理:对
malloc分配的子数组进行了free操作,避免了内存泄漏。
可以优化和改进的地方:
-
内存分配和复制:虽然
malloc和free确保了内存管理,但在每次调用robCircular时都进行两次子数组的malloc和memcpy(隐式在for循环中),会带来额外的开销。对于嵌入式系统,频繁的堆内存操作可能不是最优选择。-
优化思路:可以在
robLinearOptimized函数中增加start和end参数,直接操作原始数组的子区间,避免额外的内存分配和复制。
-
深入浅出:打家劫舍 II 的DP原理与实现 (环形排列)
环形打家劫舍问题的核心在于首尾相连的约束。由于第一间房屋和最后一间房屋是相邻的,我们不能同时偷窃它们。这导致了两种互斥的可能性:
-
偷窃第一间房屋:如果偷窃了第一间房屋,那么就不能偷窃最后一间房屋。此时,问题就变成了在
[0, numsLen-2]范围内的线性打家劫舍问题。 -
不偷窃第一间房屋:如果选择不偷窃第一间房屋,那么最后一间房屋就可以偷窃(也可以不偷)。此时,问题就变成了在
[1, numsLen-1]范围内的线性打家劫舍问题。
这两种情况涵盖了所有可能性,并且它们是互斥的。因此,最终的最高总金额就是这两种情况中的最大值。
DP 状态定义和转移方程:与线性打家劫舍完全相同,只是应用于不同的子区间。
DP 状态表:由于是分解为线性问题,所以没有新的DP表形式,只是对原数组的不同切片进行线性DP计算。
优化与最终代码 (C语言)
为了避免在 robCircular 中频繁的 malloc 和 free,我们可以修改 robLinearOptimized 函数,使其能够处理数组的任意子区间。
#include // 标准输入输出,用于printf等#include // 内存分配函数,用于malloc, free/** * @brief 辅助函数:返回两个整数中的较大值 * @param a 整数1 * @param b 整数2 * @return int 较小值 */int getMax(int a, int b) { return a > b ? a : b;}/** * @brief 计算在不触发警报的情况下,能够偷窃到的最高总金额(线性排列房屋)。 * 此版本支持对数组的任意子区间进行计算,以优化环形打家劫舍问题。 * * 本函数使用动态规划(Dynamic Programming, DP)解决打家劫舍问题(线性排列)。 * 空间复杂度优化到 O(1)。 * * @param nums int整型一维数组 表示每间房屋的金额 * @param start int 子区间的起始索引 * @param end int 子区间的结束索引(包含) * @return int整型 能够偷窃到的最高总金额 */int robLinearOptimizedWithRange(int *nums, int start, int end) { // 1. 输入校验:处理空区间或无效索引 if (start > end) { return 0; // 无效区间,没有房屋可偷 } int currentLen = end - start + 1; // 当前子区间的长度 // 2. 特殊情况处理:子区间房屋数量较少的情况 if (currentLen == 0) { return 0; } if (currentLen == 1) { return nums[start]; // 只有一间房屋,直接偷 } if (currentLen == 2) { return getMax(nums[start], nums[start + 1]); // 两间房屋,偷金额较大的那间 } // 3. DP 状态变量初始化 (空间优化) // first_prev: 相当于 dp[i-2] (考虑前 i-2 间房屋的最大金额) // second_prev: 相当于 dp[i-1] (考虑前 i-1 间房屋的最大金额) // 注意:这里的索引是相对于子区间的,即 nums[start], nums[start+1] 等 int first_prev = nums[start]; // 对应子区间的第一间房屋 int second_prev = getMax(nums[start], nums[start + 1]); // 对应子区间的第二间房屋 // 4. 遍历计算最大金额 // 从子区间的第三间房屋开始(对应索引 start + 2) for (int i = start + 2; i <= end; i++) { int current_max = getMax(second_prev, nums[i] + first_prev); first_prev = second_prev; second_prev = current_max; } // 5. 返回最终结果 return second_prev;}/** * @brief 计算在不触发警报的情况下,能够偷窃到的最高总金额(环形排列房屋)。 * 此版本通过调用带范围的线性打家劫舍函数,避免了额外的内存分配。 * * @param nums int整型一维数组 表示每间房屋的金额 * @param numsLen int nums数组长度 * @return int整型 能够偷窃到的最高总金额 */int robCircularOptimized(int *nums, int numsLen){ // 1. 输入校验和特殊情况处理 if (nums == NULL || numsLen == 0) { return 0; // 没有房屋可偷,总金额为0 } if (numsLen == 1) { return nums[0]; // 只有一间房屋,直接偷 } // 2. 将环形问题分解为两个线性问题,并复用带范围的线性打家劫舍函数 // 情况 A: 偷窃第一间房屋,则不能偷窃最后一间房屋。 // 问题转化为:在 [0, numsLen-2] 范围内的线性打家劫舍问题。 int maxAmount1 = robLinearOptimizedWithRange(nums, 0, numsLen - 2); // 情况 B: 不偷窃第一间房屋,则最后一间房屋可以偷窃。 // 问题转化为:在 [1, numsLen-1] 范围内的线性打家劫舍问题。 int maxAmount2 = robLinearOptimizedWithRange(nums, 1, numsLen - 1); // 3. 返回两种情况中的最大值 return getMax(maxAmount1, maxAmount2);}/*// 示例用法 (可以放在main函数中测试)int main() { int nums1[] = {2, 3, 2}; int len1 = sizeof(nums1) / sizeof(nums1[0]); printf(\"环形房屋 {2, 3, 2} 能偷窃的最高金额: %d\\n\", robCircularOptimized(nums1, len1)); // 预期输出: 3 int nums2[] = {1, 2, 3, 1}; int len2 = sizeof(nums2) / sizeof(nums2[0]); printf(\"环形房屋 {1, 2, 3, 1} 能偷窃的最高金额: %d\\n\", robCircularOptimized(nums2, len2)); // 预期输出: 4 int nums3[] = {0}; int len3 = sizeof(nums3) / sizeof(nums3[0]); printf(\"环形房屋 {0} 能偷窃的最高金额: %d\\n\", robCircularOptimized(nums3, len3)); // 预期输出: 0 int nums4[] = {1}; int len4 = sizeof(nums4) / sizeof(nums4[0]); printf(\"环形房屋 {1} 能偷窃的最高金额: %d\\n\", robCircularOptimized(nums4, len4)); // 预期输出: 1 int nums5[] = {1, 2}; int len5 = sizeof(nums5) / sizeof(nums5[0]); printf(\"环形房屋 {1, 2} 能偷窃的最高金额: %d\\n\", robCircularOptimized(nums5, len5)); // 预期输出: 2 int nums6[] = {1, 2, 3}; int len6 = sizeof(nums6) / sizeof(nums6[0]); printf(\"环形房屋 {1, 2, 3} 能偷窃的最高金额: %d\\n\", robCircularOptimized(nums6, len6)); // 预期输出: 3 return 0;}*/代码改进总结:
改进点
原因/目的
效果
robLinearOptimizedWithRange 函数
引入了带 start 和 end 索引的线性打家劫舍函数。
避免了在 robCircularOptimized 中创建和复制子数组,减少了内存分配和操作开销。
robCircularOptimized 无 malloc
直接调用 robLinearOptimizedWithRange,不再进行额外的 malloc 和 free。
提高了环形打家劫舍函数的性能和效率,尤其在嵌入式环境中意义重大。
详细注释
解释了函数参数、优化原理和调用关系。
极大地提高了代码可读性、可维护性,方便他人理解和自己回顾。
9 总结与展望
第三部分,我们深入学习了“最长上升子序列”和“打家劫舍”系列问题。
对于最长上升子序列,我们掌握了以 arr[i] 结尾的LIS长度的DP状态定义,并通过双重循环实现了状态转移。我们还强调了动态内存分配在处理大规模数据时的重要性。
对于打家劫舍,我们先解决了线性排列的房屋问题,学习了经典的“偷或不偷”决策,并将其空间复杂度优化到 O(1)。接着,我们将线性解法推广到环形排列的房屋,通过将一个环形问题分解为两个线性问题来巧妙解决。
通过这些问题,我们进一步巩固了DP的核心思想:定义状态,找出转移方程,确定初始化和计算顺序。 并且,我们开始思考如何进行空间优化,这在嵌入式开发中是至关重要的技能。
DP的旅程还在继续!在下一部分,我们将挑战更多有趣的DP问题,例如“字符串转化IP地址”和“编辑距离”。这些问题将带你领略DP在字符串处理和序列比对中的强大能力。
继续加油,兄弟们!胜利就在前方!
动态规划硬核之路:字符串转化IP与编辑距离(第四部分)
前言:DP,字符串处理的“瑞士军刀”!
兄弟们,DP的魅力远不止在数组和序列问题上。在字符串处理领域,DP同样是一把“瑞士军刀”,能够高效地解决各种复杂问题。今天,我们将聚焦两个典型的字符串DP问题:字符串转化IP地址 (Restore IP Addresses) 和 编辑距离 (Edit Distance)。
这两个问题,一个考验你对字符串分割和合法性判断的细致考量,另一个则展示了DP在序列比对和最小操作数计算上的强大能力。它们都是大厂面试中常见的“压轴题”,能搞定它们,你的DP水平绝对能上一个台阶!
10 经典问题剖析:字符串转化IP地址 (Restore IP Addresses)
“字符串转化IP地址”是一个典型的回溯(Backtracking)或DP问题。虽然回溯法更直观,但我们也可以用DP的思想来理解和解决它,尤其是在考虑子问题的重叠性时。这里,我们主要以回溯加剪枝的思路来讲解,因为它更符合解决这类字符串分割问题的直觉,并且可以看作是DP思想的递归实现。
问题描述
给定一个只包含数字的字符串 s,将其分成四段,使得每段都是一个有效的IP地址段(0-255),并返回所有可能的IP地址组合。
一个有效的IP地址由四个整数组成,每个整数位于0到255之间,并由点分隔。例如 0.0.0.0 和 255.255.255.255 是有效的IP地址。 无效的IP地址示例如下:\"0.0.0.00\" (包含前导零)、\"0.0.0.256\" (超出范围)。
解题思路与原理分析
这个问题可以看作是:从字符串 s 中,切割出4个有效的数字段。
核心思想:回溯 + 剪枝
我们可以用递归的方式来尝试所有可能的切割方案。在每一步递归中,我们尝试从当前位置开始,切割出1位、2位或3位的数字,然后判断这个数字是否有效。如果有效,就继续递归处理剩余的字符串;如果无效,就剪枝,不再继续。
DP的视角:
虽然我们用回溯实现,但其本质上可以看作是DP的自顶向下(记忆化搜索)思想。每个子问题是“从字符串的某个位置开始,还需要切割 k 段,能有多少种有效方案”。只是这里我们不是求数量,而是求所有具体的方案。
关键步骤:
-
递归函数定义:
void backtrack(char *s, int start, int dots, char *current_ip, int *count, char ***result)-
s: 原始字符串。 -
start: 当前处理的起始索引。 -
dots: 已经添加的点号数量(即已经分割出的段数)。 -
current_ip: 当前构建的IP地址字符串。 -
count: 结果数组中的IP地址数量。 -
result: 存储所有有效IP地址的二维字符数组。
-
-
递归终止条件:
-
如果
dots == 4:表示已经分割出了4段。此时,如果start也恰好到达了字符串的末尾(start == strlen(s)),说明所有字符都被用完且分割正确,则将current_ip添加到结果集中。 -
如果
dots == 4但start != strlen(s):说明分割了4段,但原始字符串还有剩余,无效。 -
如果
start == strlen(s)但dots != 4:说明原始字符串用完了,但还没分割出4段,无效。
-
-
循环与选择: 在每个递归层级,我们尝试从
start位置开始,切割出长度为 1、2、3 的子串。-
i从start到start + 2遍历(最多取3位)。 -
截取子串
sub = s[start...i]。 -
合法性判断:
-
长度判断:子串长度不能超过3。
-
前导零判断:如果子串长度大于1,且第一个字符是
\'0\',则无效(例如 \"01\")。 -
数值范围判断:将子串转换为整数,判断是否在
0到255之间。
-
-
-
递归调用: 如果当前切割的子串合法,则:
-
将子串添加到
current_ip中,并根据dots的数量添加点号。 -
递归调用
backtrack(s, i + 1, dots + 1, ...)。 -
回溯:递归返回后,撤销当前的选择(移除
current_ip中添加的部分),以便尝试其他可能性。
-
优化与最终代码 (C语言)
由于C语言中字符串操作和动态内存管理相对复杂,这里我们将提供一个详细的C语言实现,并附带详细注释。
#include #include #include // 用于 malloc, free, atoi// 定义一个结构体来存储结果,方便管理typedef struct { char **ips; // 存储IP地址字符串的数组 int count; // IP地址的数量 int capacity; // 数组的容量} IPAddressesResult;// 辅助函数:判断一个子串是否是有效的IP地址段 (0-255)// @param s 原始字符串// @param start 子串的起始索引// @param length 子串的长度// @return int 如果有效返回1,否则返回0int isValidPart(char *s, int start, int length) { // 1. 长度校验:IP段长度必须在1到3之间 if (length 3) { return 0; } // 2. 前导零校验:如果长度大于1且第一个字符是\'0\',则无效(如\"01\", \"00\") if (length > 1 && s[start] == \'0\') { return 0; } // 3. 数值范围校验:将子串转换为整数,判断是否在0-255之间 int num = 0; for (int i = 0; i < length; i++) { // 字符必须是数字 if (s[start + i] \'9\') { return 0; } num = num * 10 + (s[start + i] - \'0\'); } // 检查数值范围 return num >= 0 && num count == result->capacity) { // 扩容 result->capacity *= 2; result->ips = (char **)realloc(result->ips, result->capacity * sizeof(char *)); if (result->ips == NULL) { // 内存分配失败处理 fprintf(stderr, \"Memory realloc failed in backtrackIP (result->ips)\\n\"); exit(EXIT_FAILURE); } } result->ips[result->count] = (char *)malloc(current_ip_len * sizeof(char)); if (result->ips[result->count] == NULL) { // 内存分配失败处理 fprintf(stderr, \"Memory malloc failed in backtrackIP (result->ips[count])\\n\"); exit(EXIT_FAILURE); } strcpy(result->ips[result->count], current_ip_buf); result->count++; } return; // 无论是否有效,都返回,不再继续深层递归 } // 剪枝条件:剩余字符不足以构成剩余的段,或者剩余字符过多 // 剩余字符:s_len - start // 剩余段数:4 - dots // 最小所需字符:(4 - dots) * 1 // 最大所需字符:(4 - dots) * 3 if (s_len - start (4 - dots) * 3) { return; } // 尝试切割出1位、2位或3位的数字作为当前段 for (int length = 1; length s_len) { break; // 超出字符串范围 } // 判断当前切割的子串是否是有效的IP地址段 if (isValidPart(s, start, length)) { // 记录当前IP地址缓冲区的使用长度,以便回溯 int prev_current_ip_len = current_ip_len; // 将当前段复制到缓冲区 strncpy(current_ip_buf + current_ip_len, s + start, length); current_ip_len += length; // 如果不是最后一段,添加点号 if (dots < 3) { current_ip_buf[current_ip_len] = \'.\'; current_ip_len++; } // 递归调用,处理下一段 backtrackIP(s, start + length, dots + 1, current_ip_buf, current_ip_len, result, s_len); // 回溯:恢复缓冲区到之前的状态,以便尝试其他切割方案 current_ip_len = prev_current_ip_len; // 不需要清空缓冲区,因为下次写入会覆盖 } }}/** * @brief 将数字字符串转化为所有可能的有效IP地址。 * * 本函数使用回溯(Backtracking)算法来生成所有有效的IP地址组合。 * * @param s 只包含数字的输入字符串 * @param returnSize 指向一个整数的指针,用于返回结果数组的大小 * @return char** 指向一个字符串数组的指针,每个字符串是一个有效的IP地址。 * 调用者负责释放返回的内存。 */char **restoreIpAddresses(char *s, int *returnSize) { // 1. 输入校验 if (s == NULL) { *returnSize = 0; return NULL; } int s_len = strlen(s); // IP地址的最小长度是4(1.1.1.1),最大长度是12(255.255.255.255) if (s_len 12) { *returnSize = 0; return NULL; } // 2. 初始化结果结构体 IPAddressesResult result; result.count = 0; result.capacity = 10; // 初始容量,会根据需要扩容 result.ips = (char **)malloc(result.capacity * sizeof(char *)); if (result.ips == NULL) { *returnSize = 0; return NULL; // 内存分配失败 } // 3. 初始化IP地址缓冲区 // IP地址最长为 3*4 + 3 (点号) + 1 (空字符) = 16 char current_ip_buf[17]; // 足够大的缓冲区 current_ip_buf[0] = \'\\0\'; // 确保初始化为空字符串 // 4. 开始回溯 backtrackIP(s, 0, 0, current_ip_buf, 0, &result, s_len); // 5. 设置返回大小并返回结果 *returnSize = result.count; // 如果没有找到任何IP地址,或者分配的内存多余,可以realloc缩小 if (result.count == 0) { free(result.ips); return NULL; // 没有找到IP地址 } // 缩小到实际大小,避免内存浪费 result.ips = (char **)realloc(result.ips, result.count * sizeof(char *)); if (result.ips == NULL) { // realloc 失败,但之前的部分可能仍然有效,这里简单处理为返回NULL // 实际应用中可能需要更复杂的错误处理 *returnSize = 0; return NULL; } return result.ips;}/*// 示例用法 (可以放在main函数中测试)int main() { char *s1 = \"25525511135\"; int returnSize1; char **ips1 = restoreIpAddresses(s1, &returnSize1); printf(\"字符串 \\\"%s\\\" 的有效IP地址:\\n\", s1); for (int i = 0; i < returnSize1; i++) { printf(\" %s\\n\", ips1[i]); free(ips1[i]); // 释放每个IP字符串的内存 } if (ips1 != NULL) { free(ips1); // 释放存储IP字符串指针的数组的内存 } printf(\"--------------------\\n\"); char *s2 = \"010010\"; int returnSize2; char **ips2 = restoreIpAddresses(s2, &returnSize2); printf(\"字符串 \\\"%s\\\" 的有效IP地址:\\n\", s2); for (int i = 0; i < returnSize2; i++) { printf(\" %s\\n\", ips2[i]); free(ips2[i]); } if (ips2 != NULL) { free(ips2); } printf(\"--------------------\\n\"); char *s3 = \"101023\"; int returnSize3; char **ips3 = restoreIpAddresses(s3, &returnSize3); printf(\"字符串 \\\"%s\\\" 的有效IP地址:\\n\", s3); for (int i = 0; i < returnSize3; i++) { printf(\" %s\\n\", ips3[i]); free(ips3[i]); } if (ips3 != NULL) { free(ips3); } printf(\"--------------------\\n\"); char *s4 = \"1\"; int returnSize4; char **ips4 = restoreIpAddresses(s4, &returnSize4); printf(\"字符串 \\\"%s\\\" 的有效IP地址:\\n\", s4); if (ips4 == NULL) { printf(\" 无\\n\"); } else { for (int i = 0; i < returnSize4; i++) { printf(\" %s\\n\", ips4[i]); free(ips4[i]); } free(ips4); } printf(\"--------------------\\n\"); char *s5 = \"19216811\"; int returnSize5; char **ips5 = restoreIpAddresses(s5, &returnSize5); printf(\"字符串 \\\"%s\\\" 的有效IP地址:\\n\", s5); for (int i = 0; i < returnSize5; i++) { printf(\" %s\\n\", ips5[i]); free(ips5[i]); } if (ips5 != NULL) { free(ips5); } printf(\"--------------------\\n\"); return 0;}*/代码分析与总结:
特性
描述
优点
注意事项/改进空间
回溯算法
采用递归加回溯的方式遍历所有可能的IP地址分割方案。
能够找到所有满足条件的解,逻辑清晰。
递归深度可能较大,需要注意栈空间。
isValidPart 辅助函数
封装了IP地址段的合法性判断逻辑(长度、前导零、数值范围)。
提高了代码模块化和可读性,避免重复代码。
无。
剪枝优化
在递归过程中,通过判断剩余字符数量与所需段数的关系进行剪枝。
大幅减少了不必要的递归调用,提高了算法效率。
剪枝条件需要仔细推敲,确保正确性。
动态内存管理
使用 malloc 和 realloc 动态分配存储结果的内存,并及时 free。
能够处理不同数量的IP地址结果,避免固定大小数组的限制。
C语言中内存管理复杂,容易出错,需要非常小心地处理内存分配和释放。
IPAddressesResult 结构体
封装了结果数组、数量和容量,方便统一管理。
提高了代码的组织性和可维护性。
无。
错误处理
对 malloc/realloc 失败进行了检查。
提高了程序的健壮性。
错误处理可以更精细,例如在内存分配失败时,可以尝试释放已分配的部分。
嵌入式开发中的考量:
在嵌入式开发中,由于资源(内存、栈空间)通常比较有限,对于这种可能涉及大量动态内存分配和深层递归的算法,需要特别谨慎:
-
栈溢出:如果输入字符串很长,递归深度可能很大,导致栈溢出。可以考虑将递归改为迭代,或者使用显式栈来模拟递归。
-
内存碎片:频繁的
malloc和free可能导致内存碎片,尤其是在长时间运行的系统中。如果IP地址的数量可以预估,可以预先分配一个足够大的内存块,然后手动管理。 -
性能:字符串操作(
strncpy、strlen、atoi的内部实现)可能带来一定的性能开销。在对性能要求极高的场景,可能需要更底层的位操作或自定义解析函数来优化。
11 经典问题剖析:编辑距离 (Edit Distance)
“编辑距离”问题是另一个经典的二维DP问题,它在自然语言处理、生物信息学(DNA序列比对)等地方有广泛应用。它考察的是将一个字符串转换成另一个字符串所需的最少操作次数(插入、删除、替换)。
问题描述
给定两个单词 word1 和 word2,计算将 word1 转换成 word2 所使用的最少操作数。 你可以对一个单词进行如下三种操作:
-
插入一个字符
-
删除一个字符
-
替换一个字符
解题思路与原理分析
核心思想:二维动态规划
我们可以定义一个二维 dp 数组来存储子问题的解。
1. DP 状态定义:
dp[i][j]:表示将 word1 的前 i 个字符(word1[0...i-1])转换成 word2 的前 j 个字符(word2[0...j-1])所需的最少操作数。
2. DP 状态转移方程:
考虑 dp[i][j],它取决于以下三种可能的操作:
-
插入操作: 如果我们将
word1的前i个字符转换成word2的前j-1个字符,然后对word2的第j个字符进行插入操作,使其与word2[j-1]匹配。 所需操作数:dp[i][j-1] + 1 -
删除操作: 如果我们将
word1的前i-1个字符转换成word2的前j个字符,然后对word1的第i个字符进行删除操作。 所需操作数:dp[i-1][j] + 1 -
替换操作: 如果
word1[i-1]和word2[j-1]不相等,我们需要将word1[i-1]替换为word2[j-1]。 所需操作数:dp[i-1][j-1] + 1如果word1[i-1]和word2[j-1]相等,则不需要替换,直接继承dp[i-1][j-1]的值。 所需操作数:dp[i-1][j-1]
综合以上,状态转移方程为:
-
如果
word1[i-1] == word2[j-1]:dp[i][j] = min(dp[i-1][j-1], dp[i-1][j] + 1, dp[i][j-1] + 1)这里dp[i-1][j-1]意味着当前字符匹配,不需要额外操作,直接继承前一个状态。 -
如果
word1[i-1] != word2[j-1]:dp[i][j] = min(dp[i-1][j-1] + 1, dp[i-1][j] + 1, dp[i][j-1] + 1)这里dp[i-1][j-1] + 1意味着当前字符不匹配,需要替换操作。
3. 初始化:
-
dp[0][0] = 0:空字符串转换成空字符串需要0次操作。 -
dp[i][0] = i:将word1的前i个字符转换成空字符串,需要i次删除操作。 -
dp[0][j] = j:将空字符串转换成word2的前j个字符,需要j次插入操作。
4. 计算顺序:
从 i = 0 到 len1,从 j = 0 到 len2,双重循环遍历。
DP 状态表(以 word1 = \"horse\", word2 = \"ros\" 为例):
\"\"(0)
r(1)
o(2)
s(3)
\"\"(0)
0
1
2
3
h(1)
1
1
2
3
o(2)
2
2
1
2
r(3)
3
2
2
2
s(4)
4
3
3
2
e(5)
5
4
4
3
解释:
-
dp[1][1](h -> r):min(dp[0][0]+1, dp[0][1]+1, dp[1][0]+1) = min(0+1, 1+1, 1+1) = 1 -
dp[2][2](ho -> ro):word1[1]=\'o\',word2[1]=\'o\'匹配。min(dp[1][1], dp[1][2]+1, dp[2][1]+1) = min(1, 2+1, 2+1) = 1(将 \"h\" 替换为 \"r\" 1次,然后 \"o\" 匹配,所以 \"ho\" -> \"ro\" 也是1次操作) -
最终
dp[5][3]为 3。
优化与最终代码 (C语言)
#include #include #include // 用于 malloc, free// 辅助函数:返回三个整数中的最小值int getMinOfThree(int a, int b, int c) { int temp = (a < b) ? a : b; return (temp < c) ? temp : c;}/** * @brief 计算将 word1 转换成 word2 所使用的最少操作数(编辑距离)。 * * 本函数使用二维动态规划(Dynamic Programming, DP)来解决编辑距离问题。 * dp[i][j] 表示将 word1 的前 i 个字符转换成 word2 的前 j 个字符所需的最少操作数。 * * @param word1 第一个输入字符串 * @param word2 第二个输入字符串 * @return int 最少操作数。如果输入为NULL,返回-1表示错误。 */int minDistance(char *word1, char *word2) { // 1. 输入校验 if (word1 == NULL || word2 == NULL) { return -1; // 无效输入 } int len1 = strlen(word1); int len2 = strlen(word2); // 2. DP 数组定义与初始化 // dp[i][j] 表示 word1 的前 i 个字符到 word2 的前 j 个字符的编辑距离 // 数组大小为 (len1 + 1) x (len2 + 1) int **dp = (int **)malloc((len1 + 1) * sizeof(int *)); if (dp == NULL) { return -1; // 内存分配失败 } for (int i = 0; i <= len1; i++) { dp[i] = (int *)malloc((len2 + 1) * sizeof(int)); if (dp[i] == NULL) { // 内存分配失败,释放之前已分配的内存 for (int k = 0; k < i; k++) { free(dp[k]); } free(dp); return -1; } } // 初始化边界条件 // dp[i][0]:word1 的前 i 个字符转换成空字符串,需要 i 次删除操作 for (int i = 0; i <= len1; i++) { dp[i][0] = i; } // dp[0][j]:空字符串转换成 word2 的前 j 个字符,需要 j 次插入操作 for (int j = 0; j <= len2; j++) { dp[0][j] = j; } // 3. 遍历填充 DP 数组 for (int i = 1; i <= len1; i++) { for (int j = 1; j <= len2; j++) { // 如果当前字符匹配 if (word1[i - 1] == word2[j - 1]) { // dp[i-1][j-1]:直接继承前一个状态,因为字符匹配,无需操作 // dp[i-1][j] + 1:删除 word1[i-1] // dp[i][j-1] + 1:插入 word2[j-1] dp[i][j] = getMinOfThree(dp[i - 1][j - 1], dp[i - 1][j] + 1, dp[i][j - 1] + 1); } else { // 如果当前字符不匹配 // dp[i-1][j-1] + 1:替换 word1[i-1] 为 word2[j-1] // dp[i-1][j] + 1:删除 word1[i-1] // dp[i][j-1] + 1:插入 word2[j-1] dp[i][j] = getMinOfThree(dp[i - 1][j - 1] + 1, dp[i - 1][j] + 1, dp[i][j - 1] + 1); } } } // 4. 获取最终结果并释放内存 int result = dp[len1][len2]; for (int i = 0; i <= len1; i++) { free(dp[i]); } free(dp); return result;}/*// 示例用法 (可以放在main函数中测试)int main() { char *w1_1 = \"horse\"; char *w2_1 = \"ros\"; printf(\"编辑距离 (\\\"%s\\\", \\\"%s\\\"): %d\\n\", w1_1, w2_1, minDistance(w1_1, w2_1)); // 预期输出: 3 char *w1_2 = \"intention\"; char *w2_2 = \"execution\"; printf(\"编辑距离 (\\\"%s\\\", \\\"%s\\\"): %d\\n\", w1_2, w2_2, minDistance(w1_2, w2_2)); // 预期输出: 5 char *w1_3 = \"\"; char *w2_3 = \"abc\"; printf(\"编辑距离 (\\\"%s\\\", \\\"%s\\\"): %d\\n\", w1_3, w2_3, minDistance(w1_3, w2_3)); // 预期输出: 3 char *w1_4 = \"abc\"; char *w2_4 = \"\"; printf(\"编辑距离 (\\\"%s\\\", \\\"%s\\\"): %d\\n\", w1_4, w2_4, minDistance(w1_4, w2_4)); // 预期输出: 3 char *w1_5 = \"a\"; char *w2_5 = \"b\"; printf(\"编辑距离 (\\\"%s\\\", \\\"%s\\\"): %d\\n\", w1_5, w2_5, minDistance(w1_5, w2_5)); // 预期输出: 1 char *w1_6 = \"ab\"; char *w2_6 = \"ab\"; printf(\"编辑距离 (\\\"%s\\\", \\\"%s\\\"): %d\\n\", w1_6, w2_6, minDistance(w1_6, w2_6)); // 预期输出: 0 return 0;}*/代码分析与总结:
特性
描述
优点
注意事项/改进空间
二维DP数组
dp[i][j] 存储子问题的解,清晰地表示了状态。
能够系统地解决问题,避免重复计算。
空间复杂度为 O(MtimesN),对于长字符串可能占用大量内存。
状态转移方程
准确地考虑了插入、删除、替换三种操作,并根据字符是否匹配进行区分。
逻辑严谨,保证了结果的正确性。
理解起来可能需要一些时间,特别是三种操作的含义。
初始化边界
正确地初始化了 dp[i][0] 和 dp[0][j],作为DP的基准。
确保了DP计算的起点正确。
无。
动态内存管理
使用 malloc 动态分配 dp 数组,并在函数结束时 free。
能够处理任意长度的字符串,避免栈溢出。
C语言中内存管理复杂,容易出错,需要非常小心地处理内存分配和释放。
getMinOfThree 辅助函数
封装了求三个数最小值的逻辑。
提高了代码的可读性。
无。
嵌入式开发中的考量:
-
内存占用:编辑距离的DP表需要 O(MtimesN) 的空间,其中 M 和 N 是两个字符串的长度。对于长字符串,这可能会消耗大量内存。
-
优化思路:如果只关心编辑距离的最终值,可以考虑空间优化,将二维DP数组降为 O(min(M,N)) 甚至 O(1)。例如,
dp[i][j]只依赖于dp[i-1][j-1],dp[i-1][j],dp[i][j-1],这意味着我们只需要保留前一行和当前行的信息。
-
-
计算时间:时间复杂度为 O(MtimesN)。对于非常长的字符串,计算时间可能会很长。在实时性要求高的嵌入式系统中,可能需要考虑更快的算法(例如,如果允许近似解,可以考虑启发式算法)。
12 总结与展望:DP,嵌入式工程师的“内功”!
兄弟们,经过这四部分的“DP硬核之路”,我们共同学习了动态规划的核心思想,并通过8个经典的DP问题,从字符串、数组、序列等不同维度,深入剖析了DP的状态定义、状态转移方程、初始化、边界条件以及优化技巧。
DP问题
核心思想
DP状态定义
状态转移方程
关键优化/技巧
最长公共子串
连续子序列
dp[i][j] 以 s1[i-1] 和 s2[j-1] 结尾的最长公共子串长度
dp[i][j] = dp[i-1][j-1]+1 (匹配) / 0 (不匹配)
记录 maxLen 和 endIdx
数字翻译成字符串
组合计数
dp[i] 前 i 个字符的解码方法总数
dp[i] += dp[i-1] (单字符) / dp[i] += dp[i-2] (双字符)
处理 \'0\' 和两位数范围
兑换零钱
最优解
dp[i] 凑成金额 i 的最少硬币数
dp[j] = min(dp[j], dp[j-coin]+1)
初始化为“无穷大”,外层硬币,内层金额
最长回文子串
中心对称
(中心扩展法)
从中心向两边扩展
奇偶长度回文处理,right - left - 1 计算长度
最长上升子序列
子序列最优解
dp[i] 以 arr[i] 结尾的最长上升子序列长度
dp[i] = max(dp[i], dp[j]+1) (当 arr[j] < arr[i])
遍历 j < i,全局 maxLen
打家劫舍 (线性)
决策选择
dp[i] 考虑前 i 间房屋的最大金额
dp[i] = max(dp[i-1], nums[i-1]+dp[i-2])
空间优化到 O(1)
打家劫舍 (环形)
问题分解
(复用线性DP)
分解为两个线性问题:[0, N-2] 和 [1, N-1]
复用带范围的线性DP函数,避免内存复制
字符串转化IP地址
递归分割
(回溯树的节点状态)
尝试分割1、2、3位,判断合法性,递归
剪枝,动态内存管理,C语言字符串操作细节
编辑距离
序列比对
dp[i][j] word1 前 i 到 word2 前 j 的编辑距离
min(dp[i-1][j-1] + (match?0:1), dp[i-1][j]+1, dp[i][j-1]+1)
二维DP表,初始化边界,考虑空间优化
为什么嵌入式工程师要学好DP?
-
资源受限:嵌入式系统往往内存、CPU资源有限。DP通过避免重复计算,能够将指数级时间复杂度的问题降到多项式级别,这对于有限资源的系统至关重要。
-
效率优化:DP算法通常比暴力搜索更高效,能够提供更快的响应时间和更低的功耗。
-
系统设计:很多嵌入式应用,如路径规划、任务调度、数据压缩等,其底层算法都可能涉及到DP思想。
-
面试硬核:DP是衡量一个程序员算法功底的重要标准,掌握它能让你在面试中脱颖而出。
我的DP学习心得和建议:
-
多刷多想:DP没有捷径,就是多刷题,多总结。每次做完一道题,不要急着看答案,先自己思考状态定义和转移方程。
-
画图辅助:对于二维DP,画出DP表,一步步推导,能帮助你更好地理解状态转移。
-
理解本质:不要死记硬背公式,要理解每个DP问题的核心思想:重叠子问题和最优子结构。
-
关注边界:DP的初始化和边界条件往往是容易出错的地方,务必仔细推敲。
-
空间优化:在嵌入式场景下,时刻思考如何将DP的空间复杂度降低。
-
C语言实践:用C语言实现DP,能让你更深入地理解内存、指针和数据结构,这对于嵌入式开发是宝贵的经验。
兄弟们,DP之路漫漫,但只要你坚持不懈,勤于思考勇于实践,就一定能掌握这门“内功”,在嵌入式开发的道路上越走越远,拿到心仪的Offer!
这篇博客,是我个人学习DP、备战嵌入式求职的真实记录。如果它能给你带来一点点启发,哪怕只是让你对DP不再那么恐惧,我就心满意足了!
如果你喜欢这篇文章,觉得对你有帮助,请务必点赞、收藏、转发!
感谢相伴 我们江湖再见!
----------------------review in 2025.7.28

