Spring AI实战15分钟上手:从零对接大模型API/流式响应/企业知识库增强(文末附源码)_springai 实战
原文链接 发布于2025年05月12日 19:06 北京
知识回顾与项目亮点
大家好,我是BiggerBoy,在《Spring AI:Java开发者的智能应用神器,快速上手攻略!》技术解析基础上,北哥爆肝两天,基于Spring AI手搓了一个AI项目。本次实战项目将实现三大突破:
1. 全栈架构实现
2. 企业级知识增强
通过RAG**(检索增强生成)技术实现:
- 本地知识库向量化存储
- 基于语义的精准知识检索
- 上下文感知的智能回复生成
3. 生产级特性
- 流式响应处理(SSE)
- 对话历史管理
- 多文档格式解析支持
效果抢先看
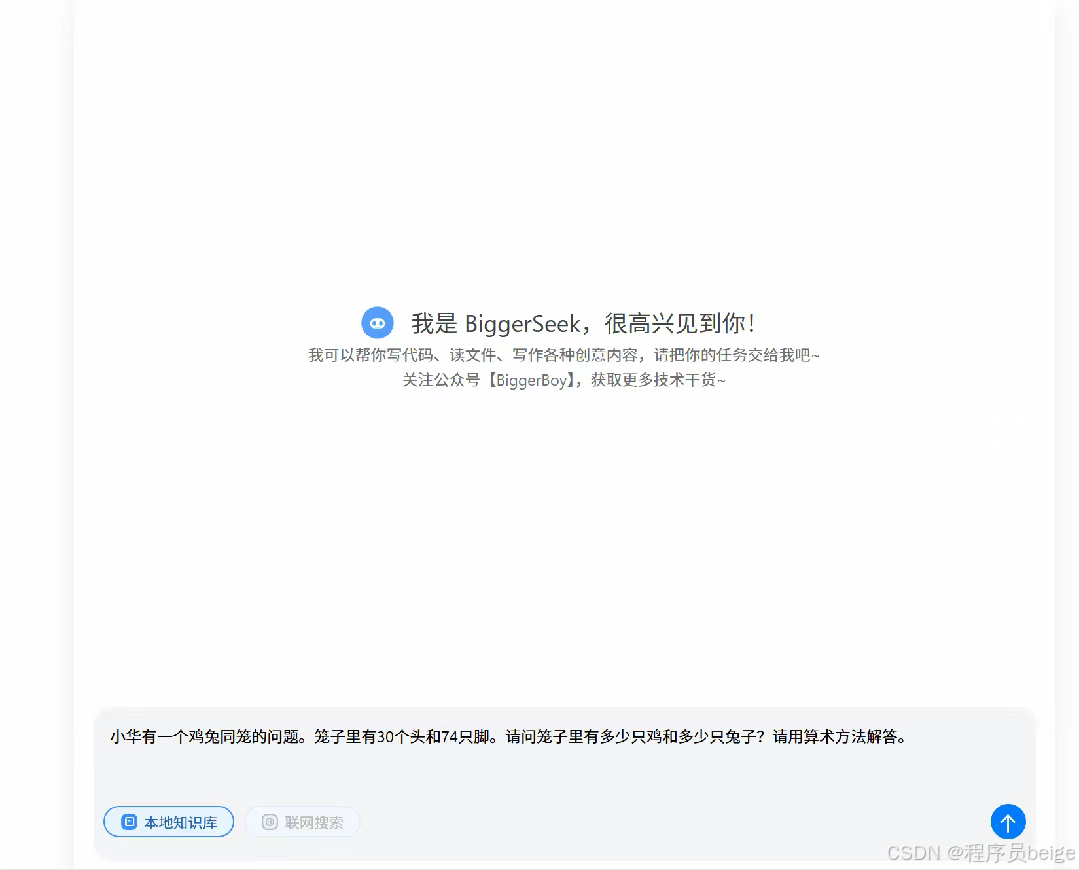
开发手记
一、环境准备
-
- 配置JDK17+环境
-
- 申请智谱API_KEY
-
- 初始化SpringAI项目
二、核心功能实现
// 智普大模型接入示例@Beanpublic ChatClient chatClient(AiClient aiClient) { return new ZhiPuChatClient(aiClient) .withTemperature(0.7) .enableStreaming();}三、企业级扩展
-
- 文档解析器配置
-
- 向量索引构建
-
- 检索增强管道实现
配套源码
文末附完整工程代码(无套路),包含:
- • 后端SpringBoot工程
- • 前端Vue3工程
(注:本教程已通过SpringAI 1.0.0-M8 + SpringBoot4.0.0验证)
导入依赖
在pom.xml文件添加依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-zhipuai</artifactId> </dependency></dependencies><dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>${spring-ai.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies></dependencyManagement>基本配置
- • 秘钥配置
从智普AI控制台(https://open.bigmodel.cn/login)获取秘钥,点击右上角【添加新的API Key】
复制API Key到配置文件,当然你可以把它导入到环境变量,那样更安全。
spring: application: name: SpringAI-demo ai: zhipuai: api-key: 你的秘钥- • 跨域配置
后端暴露给前端的API和前端不同域,需要支持跨域请求。
@ConfigurationpublicclassWebConfigimplementsWebMvcConfigurer { @Override publicvoidaddCorsMappings(CorsRegistry registry) { registry.addMapping(\"/ai/**\") .allowedOrigins(\"http://localhost:5173\") // 你的前端地址 .allowedMethods(\"GET\", \"POST\") .allowedHeaders(\"*\"); }}暴露API给前端
下面的代码有两个API,第一个是生成全部回复后,一次性把回复内容返回给前端,第二个是流式生成,采用SSE技术,可以实现回复的就像打字一样展示,这也是大多数生成式AI采用的方式。
对SSE不了解的参考前几天的文章:WebSocket之外,SSE协议为何被大厂悄悄采用?
/** * 生成回复 * @Author 公众号:BiggerBoy * @date 2025/5/8 11:05 * @param message * @return */ @GetMapping(\"/ai/generate\") public Map generate(@RequestParam(value = \"message\", defaultValue = \"Tell me a joke\") String message) { // 如果没有匹配的答案,调用AI模型生成回复 return Map.of(\"generation\", this.chatModel.call(message)); }流式生成回复的具体代码,Controller调用Service层的generateStream方法:
/** * 流式生成回复 * * @param message * @param local * @return */@GetMapping(\"/ai/generateStream\")public SseEmitter generateStream(@RequestParam String message) { return vStoreService.generateStreamWithLocal(message);}generateStream具体代码:
/** * 异步处理用户输入并通过服务器发送事件(SSE)返回聊天模型的流式响应。 * * @param userText 用户输入的文本 * @return 用于发送 SSE 事件的 {@link SseEmitter} 对象 */public SseEmitter generateStream(String userText) { SseEmitter emitter = new SseEmitter(); CompletableFuture.runAsync(() -> { try { // 创建消息 var prompt = new Prompt(new UserMessage(userText)); // 使用 stream 方法获取流式响应 chatModel.stream(prompt) .subscribe( chunk -> { try { String content= chunk.getResult().getOutput().getText(); if (StringUtils.hasText(content)) { // 发送消息到客户端 // 注意这里,我们直接发送 JSON 字符串,让 SseEmitter 自动添加 data: 前缀 emitter.send(Map.of(\"content\", content)); } } catch (IOException e) { emitter.completeWithError(e); } }, error -> { try { emitter.send(Map.of(\"content\", \"发生错误: \" + error.getMessage())); } catch (IOException e) { emitter.completeWithError(e); } finally { emitter.complete(); } }, emitter::complete); } catch (Exception e) { emitter.completeWithError(e); } }); return emitter;}进阶:基于本地知识库生成准确回复
如果想让AI结合你们公司的特有业务知识进行回复,就需要把数据喂给大模型,回复的时候大模型会参考你给的数据进行筛选。
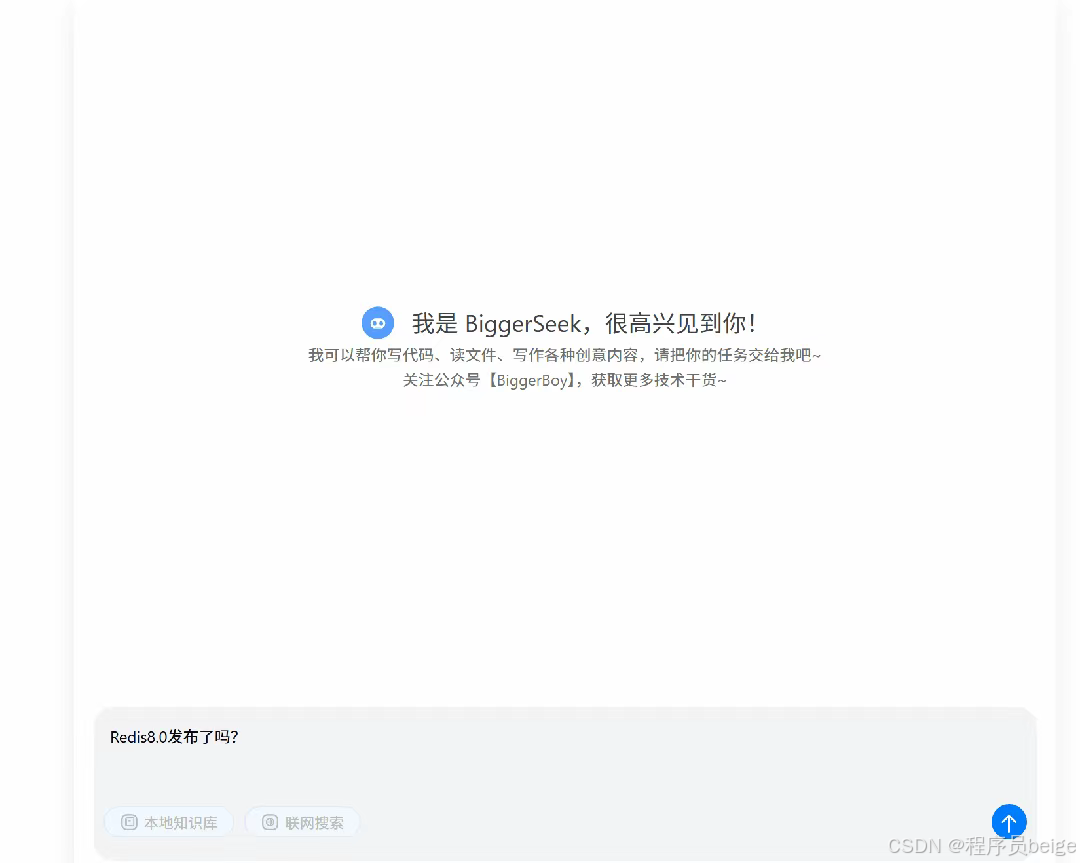
咱们看一下,当没有喂给大模型数据时,我问Redis 8.0发布了吗?它回答不了,因为它的训练数据截止到2023年。
Spring AI的向量数据库完美地解决了这个问题。
向量数据库
向量数据库是一种特殊类型的数据库,在 AI 应用程序中起着至关重要的作用。
在向量数据库中,查询不同于传统的关系数据库。 它们执行相似性搜索,而不是完全匹配。 当给定一个向量作为查询时,向量数据库会返回与查询向量“相似”的向量。 有关如何在高级别计算此相似性的更多详细信息,请参阅 向量相似性.
矢量数据库用于将数据与 AI 模型集成。 使用它们的第一步是将您的数据加载到矢量数据库中。 然后,当要将用户查询发送到 AI 模型时,首先检索一组类似的文档。 然后,这些文档用作用户问题的上下文,并与用户的查询一起发送到 AI 模型。 这种技术被称为检索增强生成 (RAG)。
Spring AI支持的向量数据库有19个之多,以后还会支持更多。

下面咱们就用Redis 8.0版本作为向量数据库来实现这个功能。推荐阅读:Redis 8.0 震撼发布:AI 时代的数据引擎,性能狂飙 112%!
1、添加依赖:
首先在pom.xml文件添加相关依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-advisors-vector-store</artifactId></dependency>2、添加配置:
spring: application: name:SpringAI-demo ai: zhipuai: api-key:你的秘钥 vectorstore: redis: initialize-schema:true index-name:custom-index prefix:custom-prefix data: redis: host:127.0.0.1#修改为你得Redis地址 port:6379 #修改为你得Redis端口然后咱们把本地知识加载到向量数据库,为了方便演示,我这里在Bean加载时读取文件并存储到Redis。
如下代码加载resources/redis8.txt,这个txt文档介绍 Redis 在2025年5月份发布了8.0版本,一般大模型的训练数据在2023年或2024年,所以不会有Redis 8.0的信息,这样我们就能看出效果。

3、加载本地知识到向量数据库:
@Autowiredprivate VectorStore vectorStore;@Autowiredprivate ZhiPuAiChatModel chatModel;private static final String MARK_FILE_PATH=\"knowledge_base_added.mark\";private static final String DOCUMENT_FILE_PATH=\"src/main/resources/redis8.txt\";/** * 在 Bean 初始化完成后执行,检查知识库文件是否更新,若更新则重新添加到向量存储中,并进行相似度搜索测试。 */@PostConstructpublic void addDocument() { File markFile = new File(MARK_FILE_PATH); File documentFile = new File(DOCUMENT_FILE_PATH); // 检查文档文件是否存在 if (!documentFile.exists()) { System.out.println(\"知识库文件不存在: \" + DOCUMENT_FILE_PATH); return; } // 检查标记文件是否存在,或者文档文件是否已更新 if (!markFile.exists() || documentFile.lastModified() > markFile.lastModified()) { if (markFile.exists()) { // 删除旧的标记文件 markFile.delete(); } try { Resource documentResource = new ClassPathResource(\"redis8.txt\"); DocumentReader documentReader = new TextReader(documentResource); List<Document> documents2 = documentReader.get(); TextSplitter textSplitter = new TokenTextSplitter(); // 按 Token 数分块 List<Document> chunks = textSplitter.split(documents2); vectorStore.add(chunks); // Retrieve documents similar to a query List<Document> results = this.vectorStore .similaritySearch(SearchRequest.builder().query(\"Spring\").topK(5).build()); System.out.println(\"Similarity Search Results:\" + results); // 创建新的标记文件 markFile.createNewFile(); } catch (IOException e) { e.printStackTrace(); } }}客户端工具连接Redis查看:
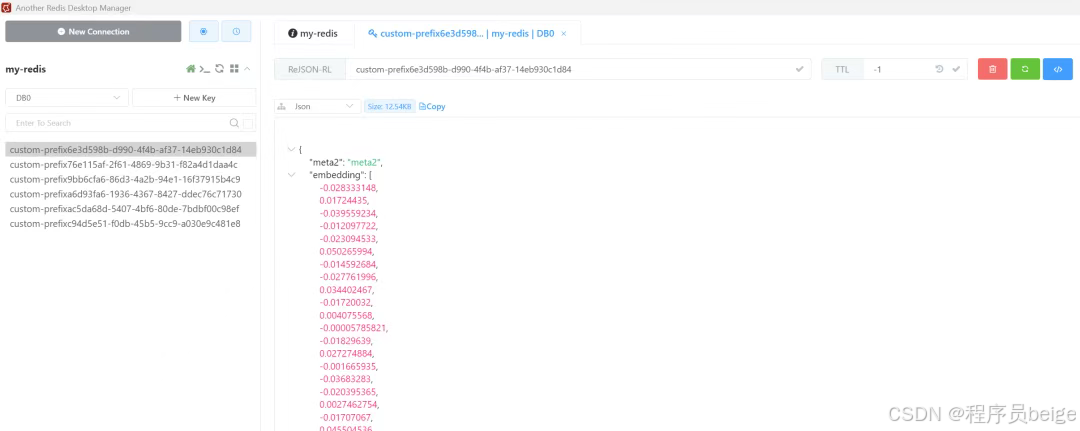
4、结合本地知识库进行回复:
建立了本地知识库后,下一步就是在AI回复时要把本地知识库的内容利用起来。我们重新这个方法generateStreamWithLocal,具体代码如下:
/** * 处理用户输入并通过服务器发送事件(SSE)返回聊天模型的流式响应。 * 使用 {@link QuestionAnswerAdvisor} 结合向量存储来提供更准确的回答。 * * @param userText 用户输入的文本 * @return 用于发送 SSE 事件的 {@link SseEmitter} 对象 */public SseEmitter generateStreamWithLocal(String userText) { SseEmitter emitter = new SseEmitter(); ChatClient.builder(chatModel) .build().prompt() .advisors(new QuestionAnswerAdvisor(vectorStore)) .user(userText) .stream() .chatResponse() .subscribe( chunk -> { try { String content= chunk.getResult().getOutput().getText(); if (StringUtils.hasText(content)) { // 发送消息到客户端 // 注意这里,我们直接发送 JSON 字符串,让 SseEmitter 自动添加 data: 前缀 emitter.send(Map.of(\"content\", content)); } } catch (IOException e) { emitter.completeWithError(e); } }, error -> { try { emitter.send(Map.of(\"content\", \"发生错误: \" + error.getMessage())); } catch (IOException e) { emitter.completeWithError(e); } finally { emitter.complete(); } }, emitter::complete); return emitter;}修改Controller,当页面未勾选“本地知识库”时仍然调用Service层的generateStream方法,当勾选后调用generateStreamWithLocal:
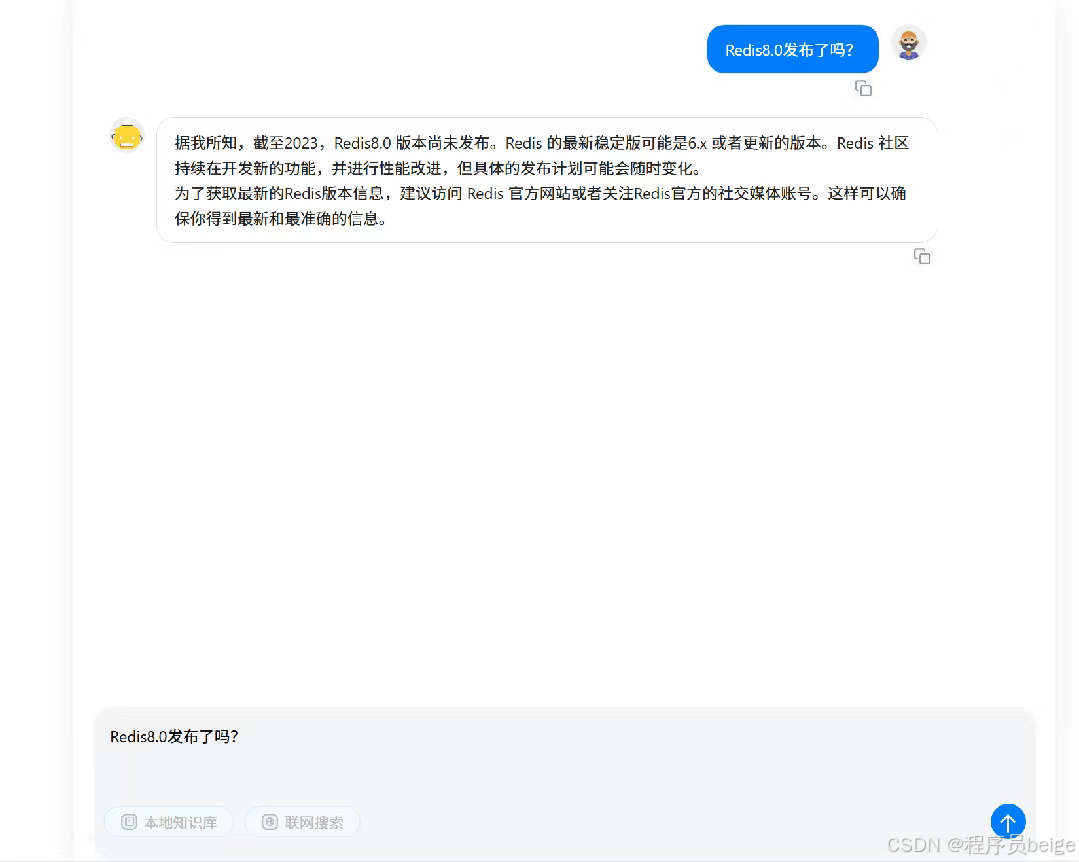
/** * 流式生成回复 * * @param message * @param local * @return */@GetMapping(\"/ai/generateStream\")public SseEmitter generateStream(@RequestParam String message, @RequestParam Boolean local) { if (Boolean.FALSE.equals(local)) { return vStoreService.generateStream(message); } return vStoreService.generateStreamWithLocal(message);}启动项目,咱们试验一下。效果如下,选中输入框下的本地知识库,然后发给AI同样的消息,它的回复就会结合咱们喂给它的数据。
结语
接下来我会继续完善这个项目,实现【上下文感知的智能回复生成】、【对话历史管理】敬请关注!
通过本次实战,我们不仅完成了从大模型对接到知识增强的完整技术闭环,更验证了Spring AI在企业级AI应用中的独特价值——5行代码对接主流大模型,20分钟构建知识增强管道,这正是Java开发者拥抱AI时代的利器。
技术永不眠,当你在实际部署中遇到embedding优化、RAG精度提升等深度问题时,欢迎在评论区留下你的实践思考。
关注【BiggerBoy】公众号,回复「AI全栈」获取本次工程源码!另外没关注的朋友,麻烦给北哥点个关注、转发,感谢支持😁!



