基于 BiLSTM+自注意力机制(改进双塔神经网络) 的短文本语义匹配
基于 BiLSTM+自注意力机制(改进双塔神经网络) 的短文本语义匹配
代码详见:https://github.com/xiaozhou-alt/Semantic_Matching
文章目录
- 基于 BiLSTM+自注意力机制(改进双塔神经网络) 的短文本语义匹配
- 一、项目介绍
- 二、文件夹结构
- 三、数据集介绍
- 四、BiLSTM模型和自注意力机制介绍
- 五、项目实现
-
- 1. 参数配置
- 2. 数据加载与预处理
- 3. 双塔模型架构
- 4. 模型训练配置
- 5. 开始训练!
- 6. 验证集评估
- 六、结果展示
一、项目介绍
这是一个基于改进双塔神经网络的 语义匹配 模型实现,主要用于判断两个句子在语义上的相似程度。项目采用了先进的深度学习技术,结合了 BiLSTM、自注意力机制 和卷积神经网络等多种架构,实现了高效的语义匹配功能。
功能简要说明:
- 语义相似度计算 :判断两个句子在语义上的相似程度
- 改进双塔模型 :结合BiLSTM、自注意力和CNN的混合架构
- 多特征融合 :绝对差、点积相似度和原始编码拼接
- 自动化训练 :包含学习率调度、早停和模型检查点
- 性能评估 :以AUC为主要评估指标
本次项目源于:天池大赛 > 日常学习赛 >【NLP系列学习赛】语音助手:对话短文本语义匹配 (aliyun.com)
二、文件夹结构
Semantic_Matching\\├── data.ipynb # 数据预处理和分析文件├── data\\ # 原始数据文件夹 ├── README-data.md # 数据说明文档 ├── gaiic_track3_round1_testA_20210228.tsv # 测试集A ├── gaiic_track3_round1_testB_20210317.tsv # 测试集B ├── gaiic_track3_round2_train_20210407.tsv # 初赛训练集 ├── gaiic_track3_round1_train_20210228.tsv # 复赛训练集 └── train.tsv # 融合后的总体训练集├── output\\ # 输出文件夹 ├── log\\ # 日志文件夹 └── Semantic_Matching.log # 训练日志 ├── model\\ # 模型文件夹 ├── semantic_matching_model_best.h5 # 最佳模型文件 ├── pic\\ # 图片文件夹 ├── train(kaggle).ipynb # Kaggle训练的原始 Notebook └── validation_predictions.csv # 验证集预测结果├── predict.py # 预测脚本├── train.py # 训练脚本├── README.md└── requirements.txt三、数据集介绍
训练数据包含输入query- pair,以及对应的真值。初赛训练样本 10 10 10 万,复赛训练样本 30 30 30 万(已使用 data.ipynb 进行融合,共计 40 40 40 万条数据)。为确保数量,每一个样本的真值都有进行人工标注校验。每行为一个训练样本,由 query- pair 和 真值 组成,每行格式如下:
· query- pair格式:query以中文为主,中间可能带有少量英文单词(如英文缩写、品牌词、设备型号等),采用UTF- 8编码,未分词,之间使用ts分割。# ps:数据集经过脱敏处理,文本query中字或词会转成唯一整数ID,ID与ID之间使用空格分割· 真值:真值可为0或1,其中1代表query- pair含义相匹配,0则代表不匹配,真值与query- pair之间也用\\t分割。ps:数据集经过 脱敏处理,文本query中字或词会转成唯一整数ID,ID与ID之间使用空格分割
数据集样例展示:
12 13 14 15(此处为制表符\\t)12 15 11 16(此处为制表符\\t)0
17 18 12 19 20 21 22 23 24(此处为制表符\\t)12 23 25 6 26 27 19(此处为制表符\\t)1
…
数据集下载地址:Semantic_Matching (kaggle.com)
四、BiLSTM模型和自注意力机制介绍
BiLSTM (双向长短期记忆网络):
-
背景
- RNN 的局限性: 循环神经网络( R N N ) 循环神经网络(RNN) 循环神经网络(RNN)是处理序列数据(文本、语音、时间序列)的经典模型。然而,标准 RNN 存在严重的 梯度消失/爆炸 问题,难以学习长距离依赖关系
- LSTM 的提出: L S T M (长短期记忆网络) LSTM(长短期记忆网络) LSTM(长短期记忆网络)作为一种特殊的RNN,通过引入精心设计的 门控机制(输入门、遗忘门、输出门)和 细胞状态,有效地解决了梯度消失问题,显著提升了捕捉长距离依赖的能力
- 单向的局限性: 标准的 LSTM(或 RNN)在处理序列时是单向的(通常是从前往后 t=1 -> t=T)。这意味着在时刻 t t t,模型只能利用 t t t 时刻及之前的信息(历史信息),无法利用 t t t 时刻之后的信息(未来信息)
- BiLSTM 的诞生: 为了克服单向模型的局限,BiLSTM 应运而生。它的核心思想很简单:同时训练两个独立的LSTM网络,一个处理 正向 序列,另一个处理 反向 序列,然后将两个方向的信息在每个时间步进行组合(通常是拼接),从而让模型能够同时捕获 过去 和 未来 的上下文信息
-
架构:
- 核心组件: 两个独立的 LSTM 层。
- 前向 LSTM (LSTM_f): 按时间顺序处理输入序列 ( x 1 , x 2 , . . . , x T ) (x_1, x_2, ..., x_T) (x1,x2,...,xT),生成隐藏状态序列 ( h f 1 , h f 2 , . . . , h f T ) (h_{f1}, h_{f2}, ..., h_{fT}) (hf1,hf2,...,hfT)。
- 后向 LSTM (LSTM_b): 按时间逆序处理输入序列 ( x T , x T − 1 , . . . , x 1 ) (x_T, x_{T-1}, ..., x_1) (xT,xT−1,...,x1),生成隐藏状态序列 ( h b T , h b T − 1 , . . . , h b 1 ) (h_{bT}, h_{bT-1}, ..., h_{b1}) (hbT,hbT−1,...,hb1)。
- 信息融合: 对于序列中的每个时间步 t t t:
- 获取前向 LSTM 在该时刻的隐藏状态 h f t h_{ft} hft。
- 获取后向 LSTM 在该时刻的隐藏状态 h b t h_{bt} hbt(注意:对于正向序列的 t t t 时刻,后向 LSTM 处理的是 T − t + 1 T-t+1 T−t+1 时刻对应的输入)。
- 将两个隐藏状态 拼接(Concatenate)起来: h t = [ h f t ; h b t ] h_t = [h_{ft}; h_{bt}] ht=[hft;hbt]。这个拼接后的向量 h t h_t ht 就代表了 t t t 时刻融合了 整个序列上下文(从开始到结束)的信息。
- 输出: BiLSTM的输出就是每个时间步 t t t 对应的融合隐藏状态序列 ( h 1 , h 2 , . . . , h T ) (h_1, h_2, ..., h_T) (h1,h2,...,hT)。这些输出可以直接用于序列标注任务(如命名实体识别),或者被送入后续的网络层(如全连接层、CRF层)进行分类或预测。也可以取最后一个时间步的 h T h_T hT 作为整个序列的表示用于分类。
- 核心组件: 两个独立的 LSTM 层。
BiLSTM模型:
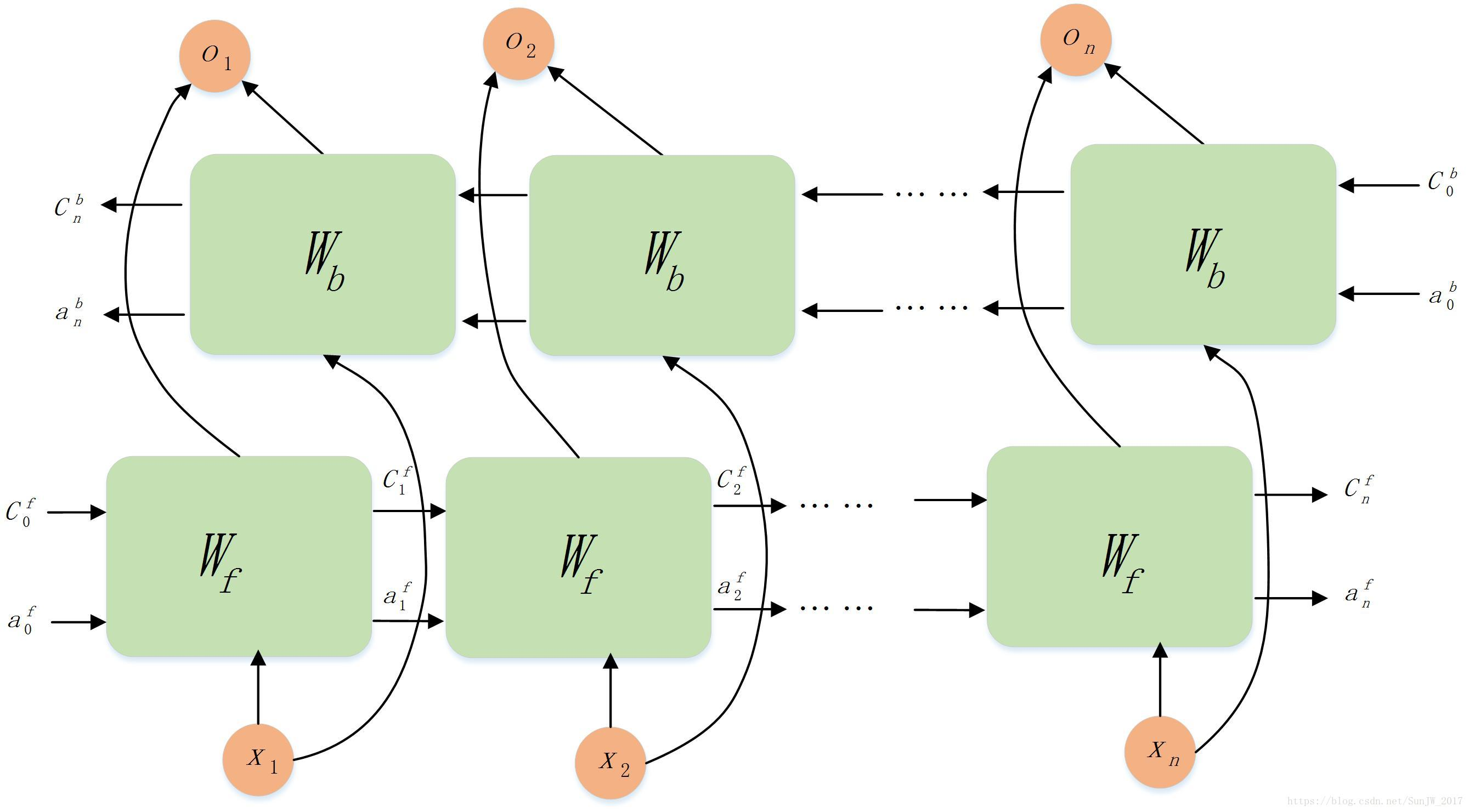
更多关于 BiLSTM 的信息详见:BiLSTM之一:模型理解
自注意力机制 (Self-Attention Mechanism):
- 背景:
- RNN/LSTM的瓶颈: 尽管 BiLSTM 解决了单向信息的问题,但其固有的 顺序计算特性(即使是双向,每个方向内部仍需顺序计算)严重限制了模型的 并行计算能力,导致训练速度慢。同时,捕捉 极长距离依赖 和 元素间直接关系 的效率仍有提升空间。
- 注意力机制的启发: 注意力机制最初在机器翻译中被提出(Bahdanau Attention, Luong Attention),用于解决 Seq2Seq 模型中编码器-解码器信息传递的瓶颈问题。它允许解码器在生成每个词时,“ 有选择地聚焦 ” 于编码器输出的不同部分。
- Self-Attention 的突破: Self-Attention(或称 Intra-Attention)是注意力机制的一种特殊形式,由 Transformer 模型的核心论文《Attention is All You Need》引入。其关键创新在于:序列中的每个元素不再依赖RNN的逐步传递,而是直接计算该序列中所有其他元素与自身的关联性(权重)。这彻底摆脱了顺序计算的束缚。
自注意力机制原理图:

2. 架构:
给定一个输入序列表示 X = [ x 1 , x 2 , . . . , x T ] X = [x_1, x_2, ..., x_T] X=[x1,x2,...,xT](其中 x i x_i xi 是第 i i i 个元素的向量表示,如词嵌入):
- 线性变换 (生成Q, K, V): 对输入序列 X X X 进行三次不同的线性变换(乘以可学习的权重矩阵 W Q W^Q WQ, W K W^K WK, W V W^V WV),得到:
- 查询向量 (Query) Q = X W Q Q = XW^Q Q=XWQ
- 键向量 (Key) K = X W K K = XW^K K=XWK
- 值向量 (Value) V = X W V V = XW^V V=XWV
- (通常 Q Q Q, K K K, V V V 的维度小于或等于输入嵌入维度,以实现降维和模型容量控制)。
- 计算注意力分数 (Attention Scores): 计算 Q u e r y Query Query 向量与所有 K e y Key Key 向量的点积(Dot-Product),衡量每个元素 i i i 的查询 q i q_i qi 与所有元素 j j j 的键 k j k_j kj 的相关性。得到一个 T T T x T T T 的分数矩阵: S c o r e s = Q K T Scores = QK^T Scores=QKT。
- 缩放 (Scale): 为了防止点积结果过大导致 softmax 梯度消失,将分数除以 K e y Key Key 向量维度的平方根: S c a l e d S c o r e s = S c o r e s / s q r t ( d k ) ScaledScores = Scores / sqrt(d_k) ScaledScores=Scores/sqrt(dk) (其中 d k d_k dk 是 K K K 向量的维度)。
- 应用Softmax: 对 S c a l e d S c o r e s ScaledScores ScaledScores 矩阵的每一行(对应一个 Q u e r y Query Query)应用 softmax 函数,将其归一化为概率分布(和为 1 1 1),得到 注意力权重矩阵 A t t e n t i o n W e i g h t s = s o f t m a x ( S c a l e d S c o r e s ) AttentionWeights = softmax(ScaledScores) AttentionWeights=softmax(ScaledScores)。权重 a i j a_{ij} aij 表示元素 i i i 对元素 j j j 的 “关注程度”。
- 加权求和 (计算输出): 将 A t t e n t i o n W e i g h t s AttentionWeights AttentionWeights 矩阵与 V a l u e Value Value 矩阵 V V V 相乘,得到最终的输出序列 Z = A t t e n t i o n W e i g h t s ∗ V Z = AttentionWeights * V Z=AttentionWeights∗V。输出向量 z i z_i zi 是所有值向量 v j v_j vj 的加权和,权重就是 a i j a_{ij} aij,即 z i = s u m j = 1 T a i j v jz_i = sum_{j=1}^T a_{ij} v_j zi=sumj=1Taijvj。 Z Z Z 中的每个向量 z i z_i zi 都融合了整个输入序列的信息,且聚焦在与 i i i 最相关的部分。
项目中使用的总体模型架构示意图:
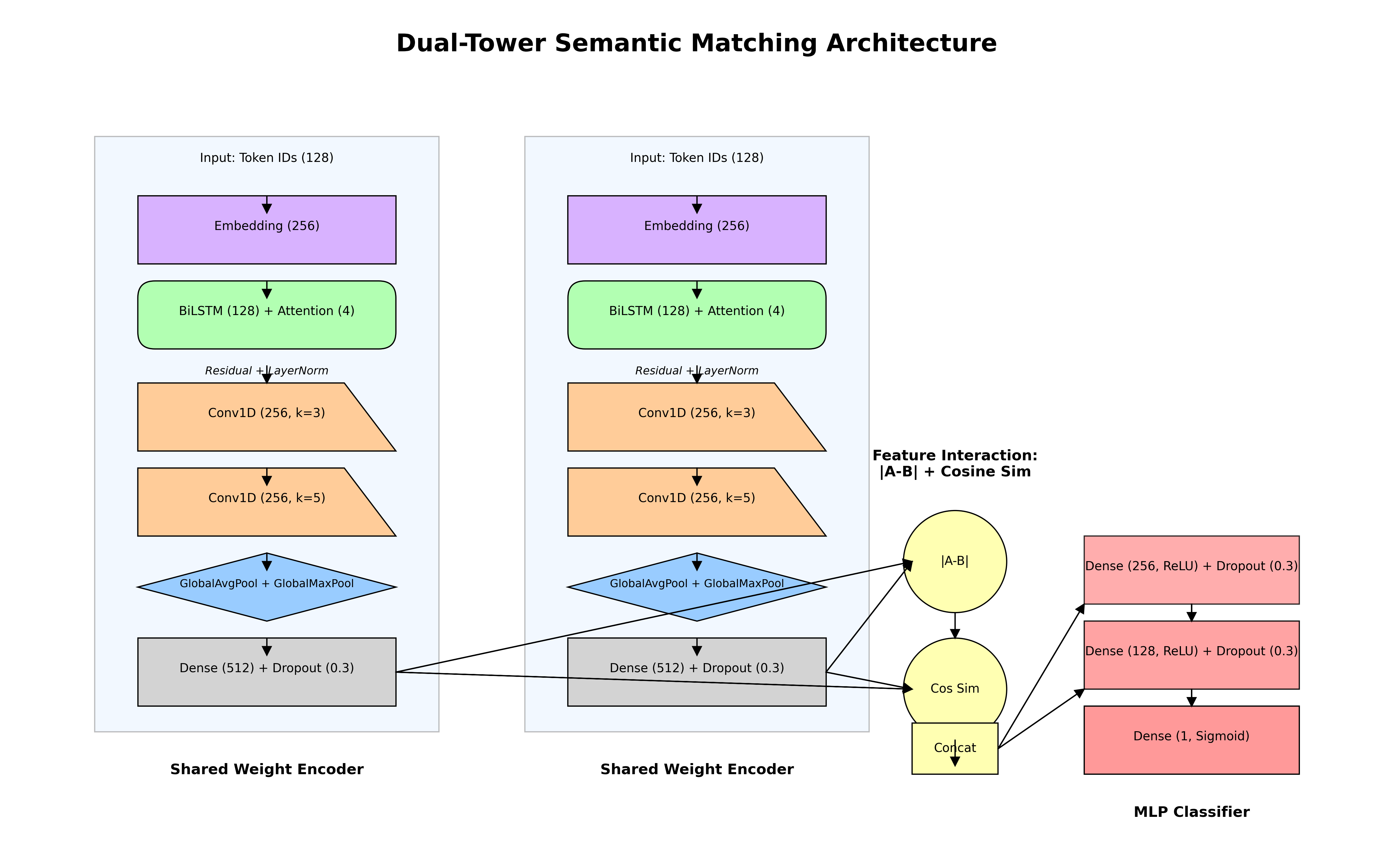
五、项目实现
1. 参数配置
- M A X _ L E N = 128 MAX\\_LEN=128 MAX_LEN=128:统一序列长度
- E M B E D _ D I M = 256 EMBED\\_DIM=256 EMBED_DIM=256:词向量维度
- P R O J E C T I O N _ D I M = 512 PROJECTION\\_DIM=512 PROJECTION_DIM=512:投影层维度(双塔输出维度)
# 配置参数MAX_LEN = 128 # 最大序列长度EMBED_DIM = 256 # 词嵌入维度PROJECTION_DIM = 512 # 投影层维度BATCH_SIZE = 512 # 批量大小EPOCHS = 50 # 训练轮数VOCAB_SIZE = 33958 # 词汇表大小2. 数据加载与预处理
从 TSV 文件读取句子对和标签,解析句子 ID 序列(已预处理的整数序列),构建 DataFrame 存储 结构化 数据;动态计算实际词汇量(基于数据中最大 ID),避免使用预定义但未使用的词汇;序列填充:截断长序列,填充短序列(用 0 0 0 填充),转换为 NumPy 数组便于模型输入,输出三个数组:query-1
、query-2
、label
分层抽样(stratify=y)确保正负样本比例一致,固定随机种子(random_state=42)保证可复现性,输出六个数组:两个句子的训练/验证集和对应标签
def load_data(file_path): data = [] with open(file_path, \'r\') as f: for line in f: ... return pd.DataFrame(data)# 构建词汇表vocab_size = max( max(df[\'sent1_ids\'].max()), max(df[\'sent2_ids\'].max())) + 1print(f\"实际词汇表大小: {vocab_size}\")def preprocess_data(df): # 填充序列 df[\'sent1_padded\'] = df[\'sent1_ids\'].apply( lambda x: x[:MAX_LEN] + [0] * (MAX_LEN - len(x))) # ...同样处理sent2... ...X1, X2, y = preprocess_data(df)# 划分训练集和验证集 (80%训练, 20%验证)X1_train, X1_val, X2_train, X2_val, y_train, y_val = train_test_split( X1, X2, y, test_size=0.2, random_state=42, stratify=y)3. 双塔模型架构
-
共享编码器:
- 两个句子使用相同的编码器结构(参数共享)
- 包含嵌入层、位置编码、双向 LSTM、自注意力机制
-
特征增强:
- 残差连接:LSTM 输出 + 自注意力
- 层归一化:稳定训练过程
- 多尺度卷积:3×3和5×5卷积核捕获不同粒度特征
- 双池化策略:全局平均池化+全局最大池化
-
特征融合创新:
- 绝对差值|vec1 - vec2|捕获差异特征
- 余弦相似度 直接计算向量相似度
- 联合特征:原始向量 + 绝对差值
-
分类器设计:
- 两层全连接网络(256 → 128单元)
- D r o p o u t = 0.3 Dropout=0.3 Dropout=0.3 防止过拟合
- S i g m o i d Sigmoid Sigmoid 输出二分类概率
#mermaid-svg-A2Z4BVvenpoBbZ45 {font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .error-icon{fill:#552222;}#mermaid-svg-A2Z4BVvenpoBbZ45 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-A2Z4BVvenpoBbZ45 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .marker.cross{stroke:#333333;}#mermaid-svg-A2Z4BVvenpoBbZ45 svg{font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-A2Z4BVvenpoBbZ45 .label{font-family:\"trebuchet ms\",verdana,arial,sans-serif;color:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .cluster-label text{fill:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .cluster-label span{color:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .label text,#mermaid-svg-A2Z4BVvenpoBbZ45 span{fill:#333;color:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .node rect,#mermaid-svg-A2Z4BVvenpoBbZ45 .node circle,#mermaid-svg-A2Z4BVvenpoBbZ45 .node ellipse,#mermaid-svg-A2Z4BVvenpoBbZ45 .node polygon,#mermaid-svg-A2Z4BVvenpoBbZ45 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-A2Z4BVvenpoBbZ45 .node .label{text-align:center;}#mermaid-svg-A2Z4BVvenpoBbZ45 .node.clickable{cursor:pointer;}#mermaid-svg-A2Z4BVvenpoBbZ45 .arrowheadPath{fill:#333333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-A2Z4BVvenpoBbZ45 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-A2Z4BVvenpoBbZ45 .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-A2Z4BVvenpoBbZ45 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-A2Z4BVvenpoBbZ45 .cluster text{fill:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 .cluster span{color:#333;}#mermaid-svg-A2Z4BVvenpoBbZ45 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-A2Z4BVvenpoBbZ45 :root{--mermaid-font-family:\"trebuchet ms\",verdana,arial,sans-serif;}#mermaid-svg-A2Z4BVvenpoBbZ45 .input>*{fill:#BBDEFB!important;stroke:#1E88E5!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .input span{fill:#BBDEFB!important;stroke:#1E88E5!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .encoder>*{fill:#C8E6C9!important;stroke:#388E3C!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .encoder span{fill:#C8E6C9!important;stroke:#388E3C!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .fusion>*{fill:#FFF9C4!important;stroke:#F57F17!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .fusion span{fill:#FFF9C4!important;stroke:#F57F17!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .feature>*{fill:#FFE0B2!important;stroke:#EF6C00!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .feature span{fill:#FFE0B2!important;stroke:#EF6C00!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .concat>*{fill:#F8BBD0!important;stroke:#D81B60!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .concat span{fill:#F8BBD0!important;stroke:#D81B60!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .mlp>*{fill:#D1C4E9!important;stroke:#7B1FA2!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .mlp span{fill:#D1C4E9!important;stroke:#7B1FA2!important;stroke-width:2px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .output>*{fill:#FFCDD2!important;stroke:#E53935!important;stroke-width:3px!important;color:#000000!important;}#mermaid-svg-A2Z4BVvenpoBbZ45 .output span{fill:#FFCDD2!important;stroke:#E53935!important;stroke-width:3px!important;color:#000000!important;} 序列数据 序列数据 512维向量 1536维 query-1 输入 编码器 query-2 输入 特征融合 绝对差值 原始向量 余弦相似度 特征拼接 MLP 256 MLP 128 输出
def create_encoder(): input_layer = layers.Input(shape=(MAX_LEN,)) # 词嵌入层 + 位置编码 embedding = layers.Embedding(vocab_size, EMBED_DIM, mask_zero=True)(input_layer) position_embedding = layers.Embedding(MAX_LEN, EMBED_DIM)(tf.range(MAX_LEN)) embedding += position_embedding # 双向LSTM + 自注意力 lstm = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(embedding) attention = layers.MultiHeadAttention(num_heads=4, key_dim=64)(lstm, lstm) # 残差连接 + 层归一化 lstm = layers.Add()([lstm, attention]) lstm = layers.LayerNormalization()(lstm) # 卷积层 conv1 = layers.Conv1D(256, 3, activation=\'relu\', padding=\'same\')(lstm) conv2 = layers.Conv1D(256, 5, activation=\'relu\', padding=\'same\')(conv1) # 双池化层 avg_pool = layers.GlobalAveragePooling1D()(conv2) max_pool = layers.GlobalMaxPooling1D()(conv2) pooled = layers.Concatenate()([avg_pool, max_pool]) # 投影层 projection = layers.Dense(PROJECTION_DIM, activation=\'relu\')(pooled) projection = layers.Dropout(0.3)(projection) return models.Model(inputs=input_layer, outputs=projection)# 创建双塔模型sent1_input = layers.Input(shape=(MAX_LEN,))sent2_input = layers.Input(shape=(MAX_LEN,))encoder = create_encoder()sent1_encoded = encoder(sent1_input)sent2_encoded = encoder(sent2_input)# 特征融合diff = layers.Subtract()([sent1_encoded, sent2_encoded])abs_diff = layers.Lambda(tf.abs)(diff)cosine_sim = layers.Dot(axes=1, normalize=True)([sent1_encoded, sent2_encoded])# 多层感知机分类器merged = layers.Concatenate()([sent1_encoded, sent2_encoded, abs_diff])dense1 = layers.Dense(256, activation=\'relu\')(merged)dense1 = layers.Dropout(0.3)(dense1)dense2 = layers.Dense(128, activation=\'relu\')(dense1)output = layers.Dense(1, activation=\'sigmoid\')(dense2)model = models.Model(inputs=[sent1_input, sent2_input], outputs=output)4. 模型训练配置
优化器: Adam Adam Adam(学习率 0.001 0.001 0.001)
损失函数:二元交叉熵(binary_crossentropy)
评估指标: AUC AUC AUC(更适合类别不平衡场景)
回调函数:模型检查点:保存最佳 AUC 模型;早停机制: 10 10 10 轮无提升则停止;学习率调度:第 5 5 5 轮后每轮衰减 10% 10\\% 10%
# 编译模型optimizer = Adam(learning_rate=1e-3)model.compile( optimizer=optimizer, loss=\'binary_crossentropy\', metrics=[tf.keras.metrics.AUC(name=\'auc\')])# 回调函数model_checkpoint = callbacks.ModelCheckpoint( filepath=\'best_model.h5\', monitor=\'val_auc\', mode=\'max\', save_best_only=True)early_stopping = callbacks.EarlyStopping( monitor=\'val_auc\', patience=10, mode=\'max\', restore_best_weights=True)lr_scheduler = callbacks.LearningRateScheduler( lambda epoch, lr: lr * 0.9 if epoch > 5 else lr)5. 开始训练!
批量大小 512 512 512,最大 50 50 50 轮次,使用验证集监控模型性能,回调函数协同工作优化训练,保存最佳模型和最终模型,记录训练过程中的 AUC 和损失变化
# 训练模型history = model.fit( [X1_train, X2_train], y_train, validation_data=([X1_val, X2_val], y_val), epochs=EPOCHS, batch_size=BATCH_SIZE, callbacks=[early_stopping, model_checkpoint, lr_scheduler])# 保存最终模型model.save(\'final_model.h5\')# 可视化训练历史def plot_training_history(history): # 绘制AUC和损失曲线 # 保存最佳AUC点 return best_aucbest_auc = plot_training_history(history)6. 验证集评估
计算验证集 AUC(ROC 曲线下面积),保存预测概率用于后续分析,可视化训练历史辅助模型诊断
# 验证集评估val_preds = model.predict([X1_val, X2_val]).flatten()val_auc = roc_auc_score(y_val, val_preds)# 保存预测结果val_results = pd.DataFrame({\'真实标签\': y_val, \'预测概率\': val_preds})val_results.to_csv(\'validation_predictions.csv\', index=False)六、结果展示
训练过程中训练集和验证集上的 损失 和 AUC指标 记录如下:

验证集上的 AUC指数 变化:

如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!

