【C++】B2113 输出亲朋字符串

博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C++
文章目录
- 💯前言
- 💯题目描述
-
- 示例输入输出
- 💯思路分析
- 💯我的做法及分析
-
- 代码实现
- 运行分析
- 优点与不足
- 💯老师的第一种做法及分析
-
- 代码实现
- 优点与不足
- 💯老师的第二种做法及分析
-
- 代码实现
- 优点与不足
- 示例分析
- 💯方法对比总结
- 💯拓展与优化
- 💯小结

💯前言
C++ 参考手册

💯题目描述
如下图所示,题目要求生成一个“亲朋字符串”,具体规则如下:
B2113 输出亲朋字符串
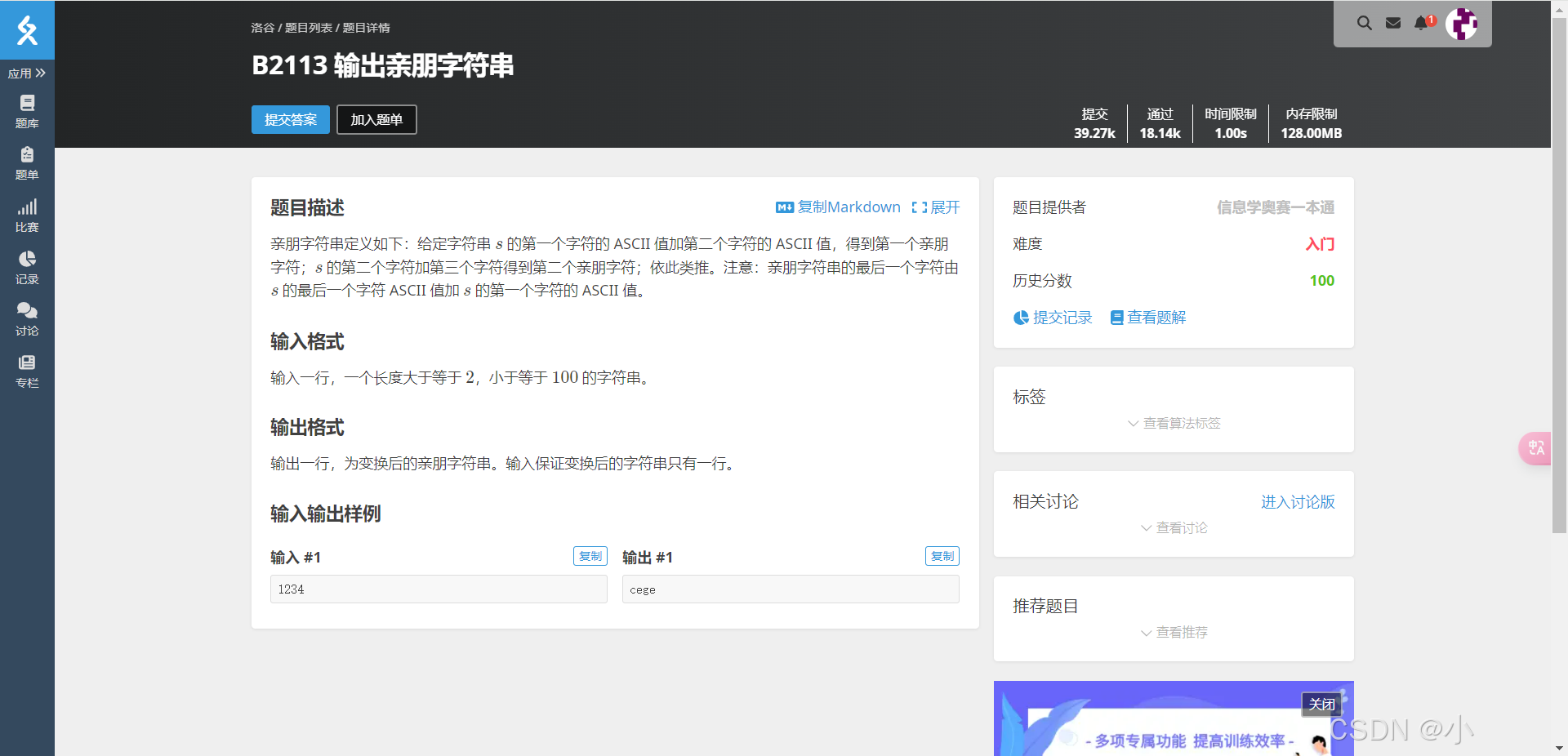
亲朋字符串定义如下:
给定字符串s,它的“亲朋字符串”按以下规则生成:
- 第1个字符等于
s中第1个字符的ASCII值加第2个字符的ASCII值;- 第2个字符等于
s中第2个字符的ASCII值加第3个字符的ASCII值;- …以此类推;
- 如果是字符串的最后一个字符,则与字符串第1个字符相加。
输入格式:
- 一行字符串,长度大于2且小于等于100。
输出格式:
- 一行“亲朋字符串”。
示例输入输出
输入:
1234输出:
cege💯思路分析
在本题中,字符串的核心操作包括以下几点:
- 逐字符遍历: 我们需要逐一处理字符串的每个字符,将其与下一个字符相加。
- 循环处理边界: 特别是字符串的最后一个字符,需要将其与第一个字符相加。
- ASCII计算: 两个字符相加的结果实际上是ASCII值的和,需要将结果重新转换为字符。
- 内存安全: 避免字符串越界的问题是代码实现中需要注意的核心。
接下来,我们将通过三种代码实现来逐步解析。
💯我的做法及分析
代码实现
#include #include #include using namespace std;const int N = 105; // 定义最大长度char s1[N]; // 输入字符串char s2[N]; // 输出字符串int main() { scanf(\"%s\", s1); // 读取输入 int len = strlen(s1); // 获取字符串长度 for (int i = 0; i < len; i++) { if (i == len - 1) s2[i] = s1[i] + s1[0]; // 最后一个字符和第一个字符相加 else s2[i] = s1[i] + s1[i + 1]; // 当前字符与下一个字符相加 } s2[len] = \'\\0\'; // 补充字符串结束符 cout << s2 << endl; // 输出结果 return 0;}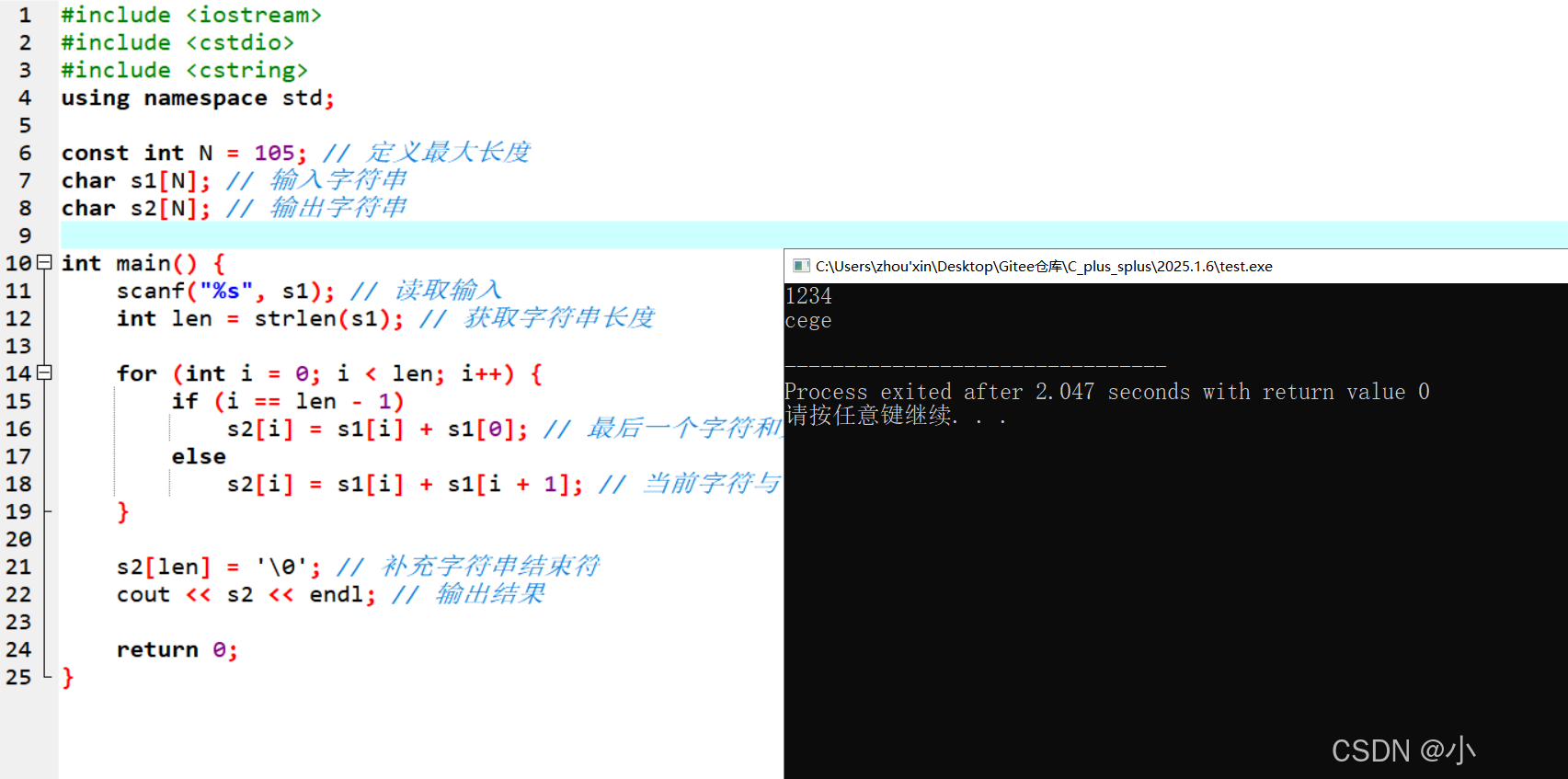
运行分析
- 输入
1234后,程序依次计算:- 第1个字符:
\'1\' + \'2\' = 49 + 50 = 99,ASCII值99对应字符\'c\'; - 第2个字符:
\'2\' + \'3\' = 50 + 51 = 101,ASCII值101对应字符\'e\'; - 第3个字符:
\'3\' + \'4\' = 51 + 52 = 103,ASCII值103对应字符\'g\'; - 第4个字符:
\'4\' + \'1\' = 52 + 49 = 101,ASCII值101对应字符\'e\'。
- 第1个字符:
- 输出结果为
cege。
优点与不足
- 优点:
- 使用数组存储结果,方便调试和后续操作。
- 逻辑清晰,易于理解。
- 不足:
- 对最后一个字符的处理需要特殊判断,显得不够简洁。
- 若忘记手动添加字符串结束符,可能会导致程序输出异常。
💯老师的第一种做法及分析
代码实现
#include using namespace std;const int N = 110;char str[N];int main() { cin >> str; // 输入字符串 int i = 0; while (str[i + 1]) { // 遍历到倒数第二个字符 char tmp = str[i] + str[i + 1]; // 当前字符与下一个字符相加 cout << tmp; // 输出结果 i++; } // 单独处理最后一个字符与第一个字符 cout << (char)(str[i] + str[0]) << endl; return 0;}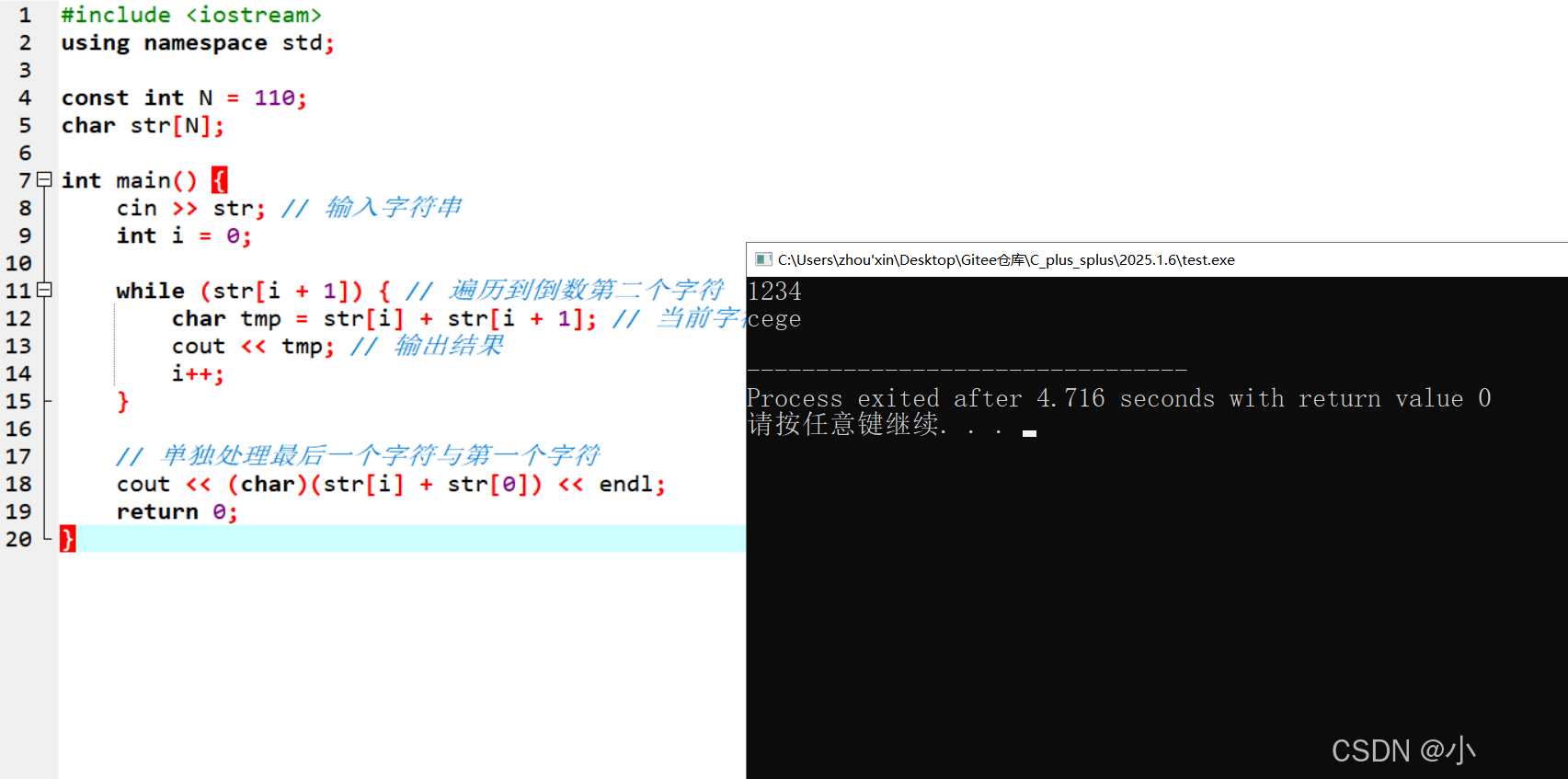
优点与不足
- 优点:
- 直接输出,无需额外数组存储结果。
- 逻辑简单,避免了对字符串结束符的显式处理。
- 不足:
- 需要特判最后一个字符,稍显复杂。
- 输出的结果直接依赖于循环条件
str[i + 1],对于初学者来说可能不够直观。
- 这类题⽬就是精确的控制下标,防⽌越界,算准下标。
- cout 在打印数据的时候是需要明确知道打印数据的类型的,⽅法1中 str[i] + str[0] 算的结果直接打印就被编译器当做整数打印了,所以我们做了 (char) 的强制类型转换。
💯老师的第二种做法及分析
代码实现
#include #include using namespace std;const int N = 110;char str[N];int main() { cin >> str; // 输入字符串 int len = strlen(str); // 获取字符串长度 for (int i = 0; i < len; i++) { char tmp = str[i] + str[(i + 1) % len]; // 当前字符与下一个字符(取模)相加 cout << tmp; // 输出结果 } cout << endl; // 换行 return 0;}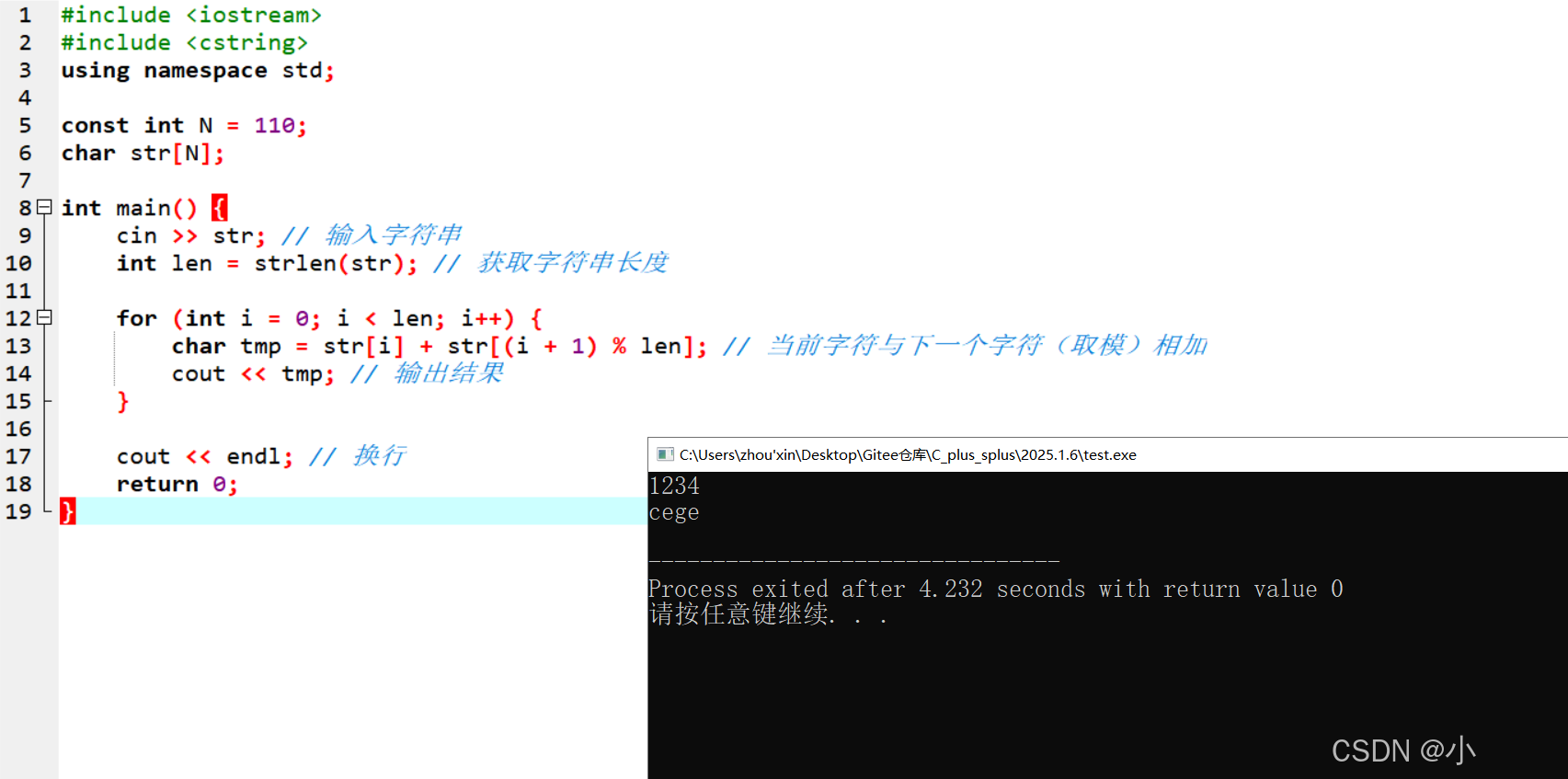
优点与不足
- 优点:
- 使用取模运算
% len统一处理了首尾字符的关系,无需特殊判断。 - 代码结构简洁,逻辑清晰。
- 使用取模运算
- 不足:
- 如果不熟悉取模运算的读者,可能需要额外理解其含义。
示例分析
对于输入1234:
- 第1个字符:
str[0] + str[1] = \'1\' + \'2\' = 99,输出c; - 第2个字符:
str[1] + str[2] = \'2\' + \'3\' = 101,输出e; - 第3个字符:
str[2] + str[3] = \'3\' + \'4\' = 103,输出g; - 第4个字符:
str[3] + str[0] = \'4\' + \'1\' = 101,输出e。
最终输出cege。
💯方法对比总结
💯拓展与优化
-
加强鲁棒性: 在所有实现中,都没有处理字符串为空的情况。如果输入为空,代码可能会出错。可以通过在读取输入后加上检查来解决:
if (strlen(str) == 0) { cout << endl; return 0;} -
支持
std::string: 如果将char数组替换为std::string,代码将更加现代化:#include #include using namespace std;int main() { string str; cin >> str; int len = str.length(); for (int i = 0; i < len; i++) { char tmp = str[i] + str[(i + 1) % len]; cout << tmp; } cout << endl; return 0;} -
适配Unicode字符: 如果需要支持更广泛的字符集,可以使用
wchar_t或UTF-8编码。
💯小结
通过这道亲朋字符串题目,我们不仅复习了C++中的字符串操作,还深入理解了下标控制、ASCII计算、以及边界处理等细节。在学习代码的过程中,不同的实现方式展现了从“解决问题”到“简洁优雅”的进阶过程。希望这篇文章能够帮助读者加深对C++字符串处理的理解,同时激发更多的编程灵感!
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

