数据库设计双刃剑:范式规范与反范式性能的终极权衡
一、 范式化设计原则
核心范式解析
name-age → name + age设计误区示例:
错误设计:订单表(order_id, 商品_id, 商品_name)(商品_name仅依赖商品_id)
修正方案:拆分为订单明细表(order_id, 商品_id)+商品表(商品_id, 商品_name)
二、反范式化设计策略
适用场景与实现方式
UPDATE counter SET cnt=cnt+1 WHERE slot=RAND()*100范式化 vs 反范式化对比
设计建议:读多写少场景(如电商首页)采用反范式化;写密集场景(如交易系统)优先范式化 。
三、 字段数据类型
选型核心原则
- 更小更好:
TINYINT(1字节)存状态值优于INT(4字节) - 简单优先:整型比字符串操作快10倍以上(无需字符集处理)
- 避免NULL:可为NULL的列增加索引存储开销(额外1字节/记录)
各类型优化策略
TINYINT UNSIGNED;用户ID→BIGINT UNSIGNEDINT(11)与INT(3)存储相同,仅影响显示宽度DECIMAL(20,2);科学计算→DOUBLEDECIMAL计算比DOUBLE慢3-5倍CHAR(2);变长内容(地址)→VARCHAR(100)VARCHAR(255)比VARCHAR(10)多占内存DATETIME;自动更新→TIMESTAMPTIMESTAMP范围仅1970-2038年ENUM(\'active\',\'inactive\')ENUM(\'1\',\'2\')易混乱BLOB/TEXT分离存储示例:
CREATE TABLE articles (id INT, title VARCHAR(200));-- 主表CREATE TABLE article_content (article_id INT, content LONGTEXT);-- 分离大文本
四、命名规范
强制性规则
- 格式统一:全小写+下划线,禁用保留字(如
desc,range) - 布尔字段:
is_前缀(is_deleted TINYINT(1)) - 索引命名:
- 主键 →
pk_user_id - 唯一索引 →
uk_user_email - 普通索引 →
idx_create_time
典型错误:
CREATE TABLE OrderData (-- 大写+复数ID INT,-- 无意义字段名desc VARCHAR(100)-- 使用保留字);五、 B+树索引
为什么选择B+树而非其他结构?
B+树在MySQL中的实现特性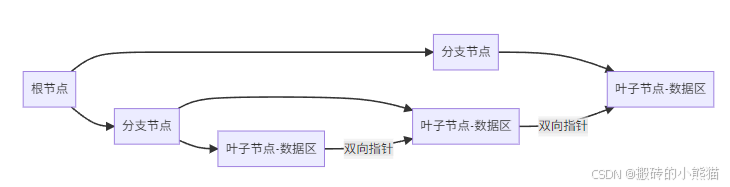
磁盘优化原理:
- 节点大小16KB(4K页整数倍)→ 充分利用磁盘顺序IO
- 相邻节点物理存储相邻 → 减少寻道时间(顺序读比随机读快40倍)
总结:设计决策矩阵
终极原则:
- 在线事务系统优先范式化(3NF/BCNF)保障一致性
- 分析型系统倾向反范式化(冗余+汇总)提升查询性能
- 混合场景采用分层设计:底层范式化 + 上层物化视图


