HashMap:Java开发者必备的哈希表生存手册_keymap hashmap
一、HashMap核心概念
-
键值对存储:每个元素是
Map.Entry对象 -
无序性:不保证插入顺序(LinkedHashMap 可保序)
-
允许键值:
null键(唯一) +null值(多个) -
非线程安全:多线程操作需同步处理
二、核心参数详解
三、哈希机制底层原理
1. 哈希函数
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
-
扰动函数设计:高位参与运算,减少哈希碰撞
-
null键处理:固定存储在索引0位置
2. 桶定位算法
index = (table.length - 1) & hash(key)
-
位运算替代取模:要求容量必须是2的幂
-
高效性:位运算比取模快10倍以上(基准测试数据)
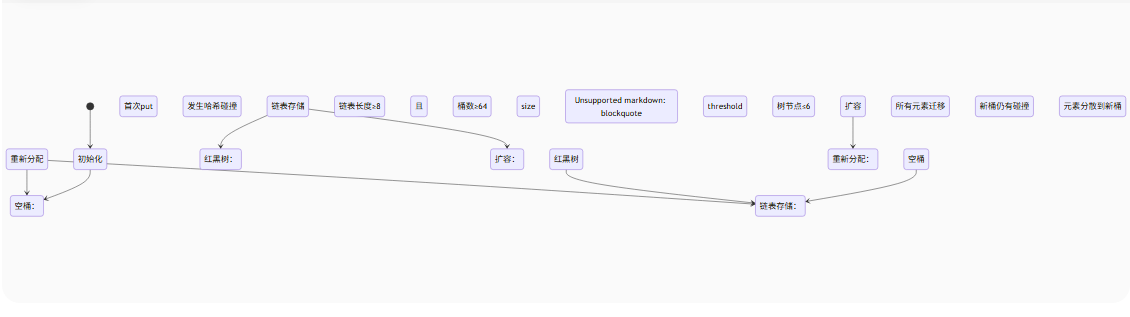
四、碰撞冲突解决全流程
五、扩容机制深度解析
1. 扩容触发条件
if (size > threshold) resize(); // threshold = capacity * loadFactor
2. 扩容优化(JDK8)
// 元素新位置 = 原位置 或 原位置 + 旧容量if ((e.hash & oldCap) == 0) { // 保持原索引} else { // 新索引 = 原索引 + oldCap}
位运算原理:
当容量为16时,哈希值后4位决定位置(二进制 1111)
扩容到32后,哈希值后5位决定位置(二进制 11111)
通过判断第5位是0/1即可确定新位置
六、关键方法源码解析
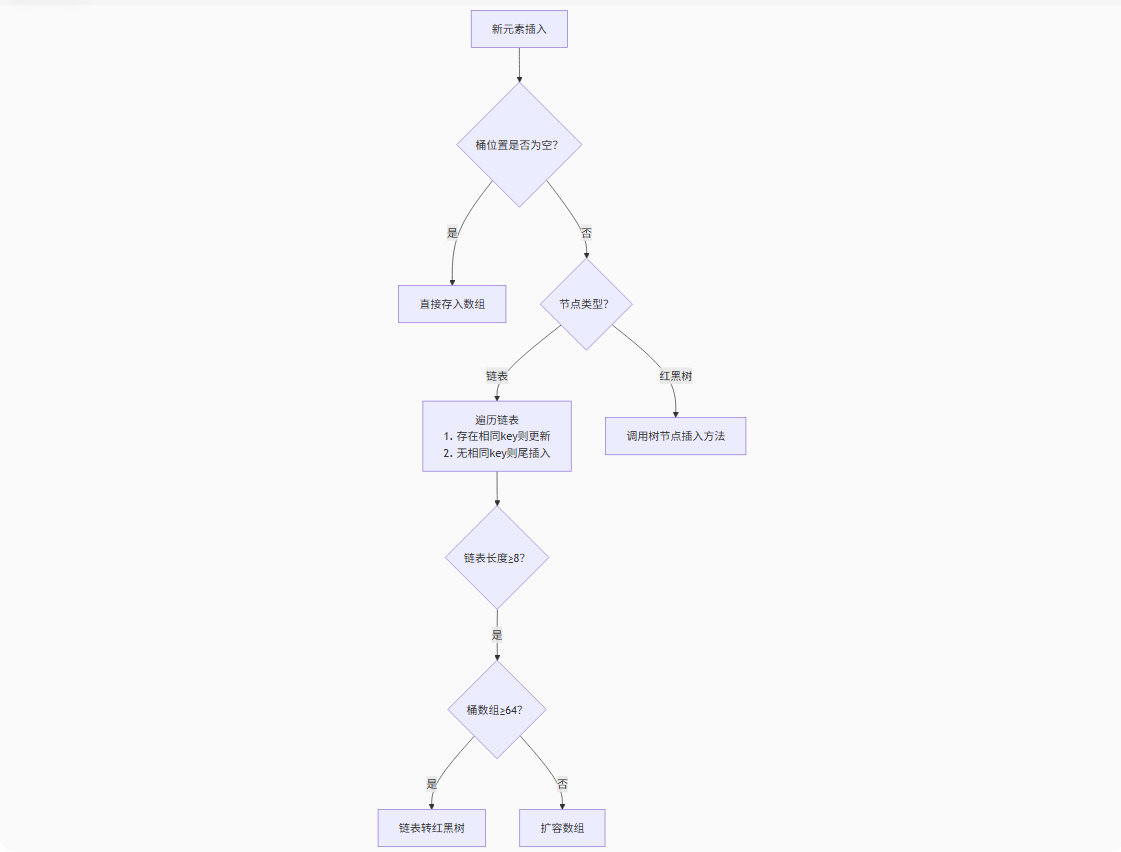
1. put() 方法流程
public V put(K key, V value) { return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 步骤分解: // 1. 表为空则初始化 // 2. 计算桶索引 // 3. 桶为空直接插入 // 4. 桶不为空:遍历链表/树 // 5. 遇到相同key则更新 // 6. 新增节点后检查扩容}
2. get() 方法优化
Node getNode(int hash, Object key) { // 优先检查头节点 // 链表:遍历直到匹配 // 树:调用树查找方法(时间复杂度O(log n))}
七、使用规范与陷阱规避
-
键对象要求:
-
重写
hashCode()和equals() -
推荐使用不可变对象(如String、Integer)
// 错误示范:可变对象作KeyMap<List, String> map = new HashMap();List key = new ArrayList();map.put(key, \"value\");key.add(\"change\"); // hashCode改变导致无法检索
-
-
初始化优化:
// 已知元素数量N时new HashMap((int)(N / 0.75f) + 1)
-
遍历性能对比:
遍历方式 时间复杂度 推荐指数 entrySet() O(n) ★★★★★ keySet() + get() O(n) ★★☆☆☆ forEach() O(n) ★★★★☆ -
并发安全方案:
// 方案1:锁全表(低效)Map syncMap = Collections.synchronizedMap(new HashMap());// 方案2:分段锁(高效)Map concurrentMap = new ConcurrentHashMap();
八、调试技巧与工具
-
查看桶分布:
java
复制
下载
// 反射获取内部表Field tableField = HashMap.class.getDeclaredField(\"table\");tableField.setAccessible(true);Object[] table = (Object[]) tableField.get(map);System.out.println(\"桶数量:\" + table.length);
-
JOL分析内存布局:
xml文件
org.openjdk.jol jol-core 0.16
System.out.println(ClassLayout.parseInstance(map).toPrintable());
九、与其他Map实现对比
十、高频面试题精解
-
为什么链表长度超过8才转树?
基于泊松分布:哈希冲突达到8的概率仅0.00000006%,树化会消耗额外内存,权衡时间和空间成本
-
为什么用红黑树不用AVL树?
红黑树牺牲部分平衡性(最大高度2log(n)),换取更快的插入/删除速度,更适合频繁修改的场景
-
重写equals()时为什么要重写hashCode()?
违反规则:若两个对象equals相等但hashCode不同,会导致HashMap中重复存储逻辑相等的键
-
为什么容量总是2的幂?
① 位运算高效替代取模
② 扩容时元素迁移更优(只需判断高位bit)
③ 哈希分布更均匀
HashMap生命周期全景图