深入分布式与云计算课程PPT:构建高效系统的关键技术
本文还有配套的精品资源,点击获取 
简介:分布式与云计算是信息技术领域的重要组成部分,对于构建高效、高可用的系统至关重要。该PPT课程提供深入学习这两个概念的资源,涵盖了分布式系统的设计原则、关键技术和云计算的多种服务模式,以及相关开源框架。学生将通过本课程提升对分布式一致性、负载均衡、容错机制和分布式计算的理解,同时掌握IaaS、PaaS和SaaS等云计算服务。即使内容全英文,但通过学习可增进英语技能及技术理解。
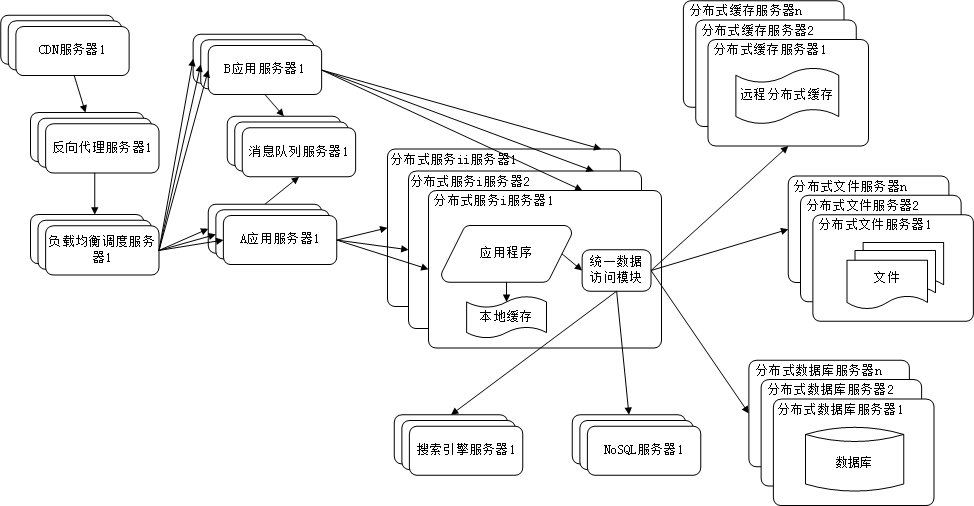
1. 分布式系统概念与关键特性
1.1 分布式系统的定义和目标
分布式系统是由多个独立且自治的计算单元组成的系统,它们之间通过网络进行通信,共同完成某一任务。这些计算单元可以是硬件也可以是软件,它们分布在不同的物理或逻辑位置上。分布式系统的主要目标是提高系统的可用性、可扩展性和可靠性。
1.2 分布式系统的关键特性
分布式系统的关键特性包括:模块化、并发、无共享、故障容错、一致性和开放性。模块化指的是系统可以被拆分成多个模块,每个模块负责一部分任务;并发指的是系统中的多个模块可以同时执行;无共享指的是模块之间不共享内存,所有的数据交换都需要通过网络进行;故障容错指的是系统能够处理单点故障,保证系统的高可用性;一致性指的是系统中的所有模块能够协同工作,保证数据的一致性;开放性指的是系统能够接受新的模块,易于扩展。
1.3 分布式系统的优势
分布式系统的优势在于它的高可用性和可扩展性。由于系统中的模块是独立且自治的,即使某个模块出现故障,也不会影响到整个系统的运行。此外,由于系统是模块化的,可以根据需求增加或减少模块,实现系统的动态扩展。
1.4 分布式系统的挑战
然而,分布式系统也面临一些挑战。首先是网络延迟和不稳定性,这可能导致模块之间的通信出现延迟或中断。其次是数据一致性的维护,由于数据需要在各个模块之间进行同步,如何保证数据的一致性是一个挑战。最后是系统的复杂性,由于系统是由多个模块组成的,如何设计和管理这个系统是一个复杂的问题。
2. 分布式一致性算法
2.1 一致性算法基础
2.1.1 一致性算法的定义和目的
一致性算法是一组协议或者规则的集合,用于确保分布式系统中各个节点的数据保持一致,无论它们之间进行多少次交互或者在面对节点故障时仍然能够达成共识。在分布式系统中,因为节点可能独立地接受更新请求,导致数据副本之间的不一致,因此,保证数据在多个副本之间的一致性是分布式系统设计的核心挑战之一。
一致性算法的目标包括:
- 可靠性 :系统能够在节点故障情况下依然能够提供服务。
- 一致性 :系统的数据副本在任意时刻对于任何数据项的值都是一致的。
- 持久性 :一旦一个数据项被更新成功,那么后续的任何操作都不会影响这一更新。
2.1.2 一致性算法的分类和比较
一致性算法大致可以分为两类:强一致性算法和弱一致性算法。
- 强一致性算法 :保证了系统更新操作后,所有节点的数据副本立刻或者在很短的时间内达到一致状态。比如Paxos和Raft算法就属于强一致性算法。
- 弱一致性算法 :只保证最终一致性,即在一段时间后,数据会逐渐达到一致的状态。例如,Dynamo风格的系统通常采用最终一致性模型。
下面展示一个表格,对几个著名的一致性算法进行了比较:
2.2 典型一致性算法详解
2.2.1 Paxos算法原理与实践
Paxos算法是由莱斯利·兰伯特提出的,它能确保在出现节点故障或者网络分区的情况下,分布式系统依然能正常工作。Paxos算法的精髓在于它能够处理一种称为”拜占庭将军问题”的分布式一致性问题。
Paxos算法主要包含以下几个角色和阶段:
- 提议者(Proposer) :发起提案。
- 接受者(Acceptor) :对提案进行投票。
- 学习者(Learner) :了解提案的结果。
- 准备(Prepare) :提议者询问接受者是否准备好接受某个编号的提案。
- 接受(Accept) :接受者承诺将会接受的提案编号,并可以对提案内容进行投票。
- 告知(Learn) :一旦提案被接受,学习者将了解提案内容。
Paxos算法的执行流程可以简化为以下步骤:
- 阶段一:准备阶段 - 提议者选择一个提案编号N,然后向所有接受者发送准备请求。
- 阶段二:接受阶段 - 如果接受者尚未接受任何编号小于N的提案,则承诺接受编号N的提案,并可以接受提案内容。
- 告知阶段 - 提议者将提案内容告知所有学习者。
2.2.2 Raft算法原理与实践
Raft算法是一种更易理解的分布式一致性算法,它将Paxos算法分解成了几个关键的子问题,并为每个子问题提供了清晰的解决方案。
Raft算法主要包括以下元素:
- 领导者(Leader) :负责处理客户端请求。
- 跟随者(Follower) :不主动发起任何请求。
- 候选者(Candidate) :用于选举领导者。
- 选举(Election) :领导者每隔一段时间进行一次选举。
- 日志复制(Log Replication) :领导者接受客户端请求,并将它们复制到跟随者。
Raft算法的工作流程可以总结为:
- 领导者选举 :当领导者失效时,候选者将发起选举。
- 日志复制 :领导者接收客户端请求,将它们作为新的日志条目添加到自己的日志中,然后并行地向跟随者发出复制请求。
- 安全性 :Raft算法保证了安全性,并通过诸如限制投票和提交索引的方式来避免日志不一致。
2.2.3 一致性算法的优化策略
由于一致性算法在实际应用中可能会遇到性能瓶颈,因此研究人员和工程师通常会采取一些优化策略来提升系统整体的性能和可靠性。
常见的优化策略包括:
- 分片技术(Sharding) :将数据分布存储在多个节点上,以降低单点负载,提高系统吞吐量。
- 读写分离 :对于读多写少的应用场景,可以采用读写分离策略,减少对主节点的请求压力。
- 批处理 :将多个小操作合并为一个大的操作进行,这样可以减少通信次数和提高效率。
- 缓存机制 :在各个节点上使用本地缓存,减少对中心存储的依赖,提升读操作的性能。
以上章节详细介绍了分布式一致性算法的基础知识和两种典型算法Paxos与Raft的原理和实践,以及为了提高性能所采取的优化策略。在实际系统设计时,需要根据具体的应用场景和需求选择合适的算法,并结合优化策略来提高系统的稳定性和响应能力。
3. 负载均衡策略
3.1 负载均衡基础概念
3.1.1 负载均衡的定义及应用场景
负载均衡是分布式系统中常见的技术,它的主要目的是优化资源使用,最大化吞吐量,降低延迟,并确保系统的高可用性。在物理服务器或虚拟服务器上,负载均衡器可以智能地分配请求,使每台服务器都保持均衡的负载,防止任何一台服务器过载而导致服务中断。
负载均衡可以应用在多种场景中,例如:
- Web服务器集群 :当网站访问量大时,单台服务器可能无法处理如此多的并发请求,负载均衡器可以将请求分发给多台服务器处理。
- 数据库服务器 :为了提高数据库查询效率和数据的可靠性,负载均衡可以分配数据请求到多个数据库服务器。
- 缓存服务器 :对于缓存层,负载均衡可以分散缓存服务器上的负载,提升缓存数据的读取速度。
3.1.2 负载均衡的方法分类
负载均衡的实现方法有很多,可以分为如下几类:
- 轮询(Round Robin) :负载均衡器按照顺序将请求依次分发给每台服务器。
- 最少连接(Least Connections) :将新的连接请求分配给当前拥有最少连接数的服务器。
- 响应时间(Response Time) :选择响应时间最短的服务器。
- 基于IP哈希(IP Hash) :根据客户端IP地址计算出一个哈希值,将请求分发到对应服务器。
- 基于地理位置(Location-based) :根据用户的地理位置信息将请求分发到最近的服务器。
3.2 负载均衡技术实现
3.2.1 常见负载均衡技术对比
在众多负载均衡技术中,Nginx、HAProxy和LVS(Linux Virtual Server)是三种较为流行的选择。
- Nginx :适用于HTTP、HTTPS和邮件代理服务器,性能稳定且配置灵活。
- HAProxy :专为高可用性设计,支持HTTP、TCP等多种协议,速度快且易于配置。
- LVS :在Linux环境下运行,它工作在网络层,转发效率高,适合大规模部署。
3.2.2 负载均衡算法的原理与应用
在实际应用中,各种负载均衡算法都有其特点和适用场景。以最少连接算法为例,这种算法在处理大量长连接时尤其有效。它能确保每台服务器上的连接数大致相同,从而避免某台服务器资源耗尽而其它服务器闲置的情况。
下面是一个简单的最少连接负载均衡算法的实现示例代码:
from collections import defaultdict# 服务器列表servers = [\'Server1\', \'Server2\', \'Server3\']# 当前服务器连接数connections = defaultdict(int)def least_connections(): # 查找当前连接数最少的服务器 min_conn = min(connections.values()) # 找出所有连接数最少的服务器列表 min_conn_servers = [server for server in servers if connections[server] == min_conn] # 随机选择一个服务器返回 return random.choice(min_conn_servers)# 模拟请求到来,更新连接数for _ in range(10): selected_server = least_connections() connections[selected_server] += 1 print(f\"Request handled by: {selected_server}\")通过这个简单的Python脚本,我们可以模拟一个基于最少连接数算法的负载均衡器。每次有请求到来时,算法都会从服务器列表中选择一个当前拥有最少活跃连接数的服务器,并将请求发送给它。这种方法在实际环境中可以显著提高系统的处理能力和可用性。
4. 容错机制设计
4.1 容错机制概述
4.1.1 容错机制的重要性
在分布式系统中,由于系统的规模庞大且组成部分众多,任何组件都有可能遭遇故障。容错机制是为了确保系统在组件发生故障时仍能持续运行而设计的一种关键技术。重要性体现在以下几个方面:
- 系统的可靠性 :通过容错机制可以预防和处理故障,确保服务的持续可用性,从而提高整个系统的可靠性。
- 服务质量保障 :容错机制可以确保即便在部分组件失效的情况下,系统对外提供的服务质量不会受到太大影响。
- 服务的连续性 :在某些对数据准确性要求极高的场景中,比如金融交易,容错机制能够保证数据的一致性和事务的完整性。
4.1.2 容错策略的基本类型
容错策略根据其应对故障的类型和方法可以分为以下几种基本类型:
- 故障检测 :包括主动和被动两种方式。主动检测通过不断检查节点的状态来发现故障,而被动检测则依赖于超时机制等手段。
- 错误恢复 :一旦检测到错误,系统需要有能力将自身状态恢复到一个安全的状态。常见的恢复方法有状态回滚、重试和重新配置等。
- 冗余技术 :通过数据冗余、服务冗余和计算资源冗余等手段来提供冗余支持,从而在某个节点或服务出现故障时,有备份可以接替其工作。
- 异常处理 :设计异常处理流程,如异常捕捉、日志记录和报警机制等,以确保在出现异常时,系统能够及时响应和处理。
4.2 容错技术深入分析
4.2.1 状态复制与故障恢复技术
状态复制技术是分布式系统中实现容错的重要手段之一,它确保系统中的关键数据和状态可以在多个节点间共享和同步。
- 数据复制模型 :包括主从复制、对等复制和基于多版本的复制等。每种模型都有其适用的场景和优缺点,需要根据实际需求做出选择。
- 一致性协议 :例如Raft和Paxos协议,这些协议在容错技术中用来保证分布式系统中的数据一致性,即使在节点发生故障的情况下。
- 故障恢复策略 :通常需要结合日志记录来实现。例如,采用WAL(Write-Ahead Logging)日志可以记录所有重要的事务,以便在系统重启后能够根据日志信息恢复到故障发生前的状态。
4.2.2 容错算法的设计与实现
设计容错算法的目的是为了在分布式系统中实现高效且可靠的容错机制。一个容错算法通常需要包括以下几个关键步骤:
- 故障检测算法 :如心跳机制、超时判断等,用来及时发现系统中出现的问题。
- 恢复和修复算法 :在故障检测到之后,系统需要有一个明确的恢复流程。这包括数据同步、节点重启等操作。
- 算法的性能优化 :容错算法的性能直接影响系统的整体性能。算法设计时需要考虑如何减少通信开销、提高检测速度和准确性等问题。
下面是一个简单的容错检测和恢复的伪代码示例:
class FaultTolerantSystem: def __init__(self): self.nodes = {} # Dictionary of nodes and their status def check_faults(self): for node in self.nodes: if not self.detect_fault(node): self.recover(node) # Call specific recovery function def detect_fault(self, node): # Simple heartbeat check for demonstration return node.is_heartbeat_valid() def recover(self, node): # Recovery process could include: rejoining the cluster, state sync, etc. node.rejoin_cluster() node.sync_state() 在这个示例中, FaultTolerantSystem 类负责管理节点的状态, check_faults 方法定期检查所有节点, detect_fault 方法用于检测单个节点是否健康, recover 方法处理节点的恢复过程。
容错机制是分布式系统设计中不可或缺的一部分,直接影响到系统的稳定性和可靠性。通过理解不同容错策略和技术的实现原理,可以更好地设计和优化分布式系统,以满足日益增长的业务需求和技术挑战。
5. 分布式计算模型
5.1 分布式计算模型概述
5.1.1 分布式计算模型的定义与优势
分布式计算模型是计算机科学中的一个重要概念,指的是将计算任务分散到网络中多个独立的计算节点上,以并行或分散的方式执行。这些计算节点可以是物理服务器,也可以是虚拟机,并且它们可能分布在世界的任何地方。通过这种方式,分布式计算能够提供巨大的计算能力和存储资源,同时还能提供良好的容错性和可扩展性。
分布式计算的核心优势在于其能够解决单个计算资源无法处理的大规模问题。它允许系统通过添加更多的计算资源(横向扩展)来增强性能,而不是依赖于单一节点的性能提升(纵向扩展)。这种方法不仅提高了计算效率,还有助于降低系统瓶颈,使得系统能够支持更多的并发用户和更大的数据集。
5.1.2 常见分布式计算模型比较
在众多分布式计算模型中,MapReduce、Dryad、Spark等模型被广泛应用于大数据处理和云计算平台中。它们各自有着不同的设计理念和优化方向。
MapReduce模型最初由Google提出,它将计算分为Map和Reduce两个阶段。Map阶段负责数据的分发和初步处理,而Reduce阶段负责汇总Map阶段的结果。MapReduce模型易于理解和实现,适用于需要大量数据处理和批处理作业的场景。
Dryad模型则允许用户指定数据流图,其中的节点表示计算任务,边表示数据流。Dryad提供了一个通用的执行环境,允许各种程序的并发执行,特别适用于复杂的数据处理流程。
Spark模型则在MapReduce的基础上引入了内存计算的概念,支持高效的迭代算法和交互式数据挖掘。Spark通过其弹性分布式数据集(RDD)和DAG调度器,为处理速度和容错性提供了显著的改进。
5.2 MapReduce实例解析
5.2.1 MapReduce的工作原理
MapReduce模型的工作原理包含两个主要步骤:Map阶段和Reduce阶段。在Map阶段,输入数据被拆分成独立的块,由多个Map任务并行处理。每个Map任务处理一个块,并输出键值对(key-value pairs)。然后,Map输出的键值对经过排序和分组,相同的键会被合并在一起,分配到同一个Reduce任务。在Reduce阶段,每个Reduce任务处理一个或多个分组,并将合并后的结果输出。
MapReduce框架通过这种方式实现并行计算,大大提高了处理大数据集的能力。同时,由于Map和Reduce任务是独立的,框架能够应对节点故障的情况,通过重新调度失败的任务来保证计算的可靠性。
5.2.2 MapReduce编程范式与优化策略
MapReduce编程范式强调“计算向数据移动”的原则,即尽量在存储数据的节点上进行计算,减少数据在网络中的传输。为此,MapReduce框架设计了一系列优化策略,如:
- 数据局部性优化:通过调度策略将计算任务安排在数据所在的节点或附近的节点上执行。
- 数据压缩技术:减少磁盘IO和网络传输的压力。
- 任务合并技术:在可能的情况下合并Map或Reduce任务以减少任务启动的开销。
此外,MapReduce程序员可以通过自定义partitioner来优化数据的分组,以及通过combiner函数在Map端进行部分数据的合并,这样可以减少传输到Reduce端的数据量。最后,对于复杂的数据处理流程,可以通过MapReduce与其他系统(如HBase、Hive等)的集成来实现更高效的数据处理。
代码块示例:
public class WordCount { public static class TokenizerMapper extends Mapper { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split(\"\\\\s+\"); for (String str : words) { word.set(str); context.write(word, one); } } } public static class IntSumReducer extends Reducer { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }}参数说明和逻辑分析:
上述Java代码是MapReduce算法的一个简单实现,用于统计文本文件中每个单词出现的次数。在TokenizerMapper类中,输入的文本被分割成单词,并为每个单词创建一个键值对(word, 1)。之后,这些键值对被传递到Reduce阶段,在IntSumReducer类中,相同单词的计数被累加。
MapReduce程序的编写通常遵循此模式,其中Mapper类处理输入数据并生成键值对,Reducer类接收具有相同键的键值对集合,然后进行合并计算。这种模式适合于许多大规模数据处理任务,因为可以高度并行化,并且可以通过增加更多的节点来扩展计算能力。
6. 云计算服务模式及特性
6.1 云计算服务模式概述
云计算服务模式是指云服务提供商通过互联网提供的服务形式,主要包括基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。这些服务模式定义了用户与云服务提供商之间的责任划分和交付方式。
6.1.1 IaaS、PaaS、SaaS的定义与区别
-
IaaS(Infrastructure as a Service) :基础设施即服务,提供虚拟化的计算资源,如虚拟机、存储、网络等。IaaS 用户可以在这些基础设施上部署和运行任意软件,包括操作系统和应用程序。亚马逊的AWS EC2和谷歌的Compute Engine就是IaaS服务的例子。
-
PaaS(Platform as a Service) :平台即服务,提供开发、测试、部署和运行应用程序的平台。PaaS 解决了软件开发和维护中的诸多问题,用户无需管理底层的基础设施,只需要关注代码的开发。Google App Engine和Heroku是典型的PaaS服务。
-
SaaS(Software as a Service) :软件即服务,这是一种软件分发模式,它提供完整的应用程序作为服务,用户通过网络访问。SaaS 应用通常由服务提供商维护和管理,常见的例子包括Salesforce CRM和Dropbox。
6.1.2 云计算服务模式的选取策略
企业选择云服务模式时,通常需要考虑以下因素:
- 业务需求 :企业当前的业务流程和未来发展方向。
- 成本预算 :不同服务模式的成本差异和预算限制。
- 技术能力 :企业内部的技术团队能力以及对服务的控制需求。
- 扩展性 :业务扩展的速度以及对服务伸缩性的要求。
企业往往从IaaS开始,因为它的灵活性较高,随着业务的不断成熟,可能逐渐迁移到PaaS或SaaS以减少运营负担并专注于核心业务。
6.2 云计算的核心特性
6.2.1 弹性伸缩的实现与价值
弹性伸缩指的是云服务能够根据实际需求自动增加或减少资源。这为用户提供了极大的灵活性,允许企业仅为其使用的计算能力付费,优化资源利用,同时保证在需求高峰期有足够的资源来处理工作负载。
实现弹性伸缩的主要方式有:
- 水平伸缩 :通过增加或减少运行中的实例数量来应对负载。
- 垂直伸缩 :改变单个实例的计算能力,如CPU和内存。
云服务通常提供自动伸缩服务,通过预设的规则和指标来动态调整资源,比如CPU负载、网络流量等。
6.2.2 高可用性的架构设计
高可用性(High Availability, HA)是指系统持续提供服务的能力。在云计算中,实现高可用性要求云服务具有故障检测和自动恢复的能力。
为了保证高可用性,云架构通常需要:
- 冗余设计 :在不同地理位置部署多个数据中心,以确保即使某个区域发生故障,系统也能够继续运行。
- 故障转移机制 :当一个服务实例失败时,能够迅速切换到另一个健康的实例。
- 定期备份和数据复制 :确保数据不会因为单点故障而丢失。
6.2.3 成本效益的分析与管理
云计算的一个关键优势是其成本效益,它将用户的资本支出转换为可变成本。企业不需要购买和维护大量的硬件资源,可以根据实际使用量进行付费。
为了更好地管理成本,企业应:
- 监控和分析使用情况 :使用云监控工具来跟踪资源使用,优化使用和避免浪费。
- 选择合适的计费模式 :如按需计费、预付费或保留实例。
- 定期审计成本 :定期审查云服务使用情况和账单,以发现和修正过度配置或未使用资源的问题。
6.2.4 快速创新在云计算中的应用
云计算提供了快速创新的能力,因为开发和部署新服务的速度比传统硬件环境快得多。云平台提供的工具和服务促进了开发人员的生产力,并使得测试新想法更为简单和成本低廉。
一些使快速创新成为可能的云服务包括:
- 容器化 :Docker容器和Kubernetes等编排工具使得应用程序的打包、分发和运行变得简单。
- 无服务器计算 :如AWS Lambda和Azure Functions,允许开发者编写和部署代码,而无需管理服务器。
- 持续集成/持续部署(CI/CD)管道 :自动化软件开发过程中的构建、测试和部署环节。
通过这些特性和服务,云计算平台使得企业能够更快地响应市场变化,更快地创新和发布新服务。
本文还有配套的精品资源,点击获取
简介:分布式与云计算是信息技术领域的重要组成部分,对于构建高效、高可用的系统至关重要。该PPT课程提供深入学习这两个概念的资源,涵盖了分布式系统的设计原则、关键技术和云计算的多种服务模式,以及相关开源框架。学生将通过本课程提升对分布式一致性、负载均衡、容错机制和分布式计算的理解,同时掌握IaaS、PaaS和SaaS等云计算服务。即使内容全英文,但通过学习可增进英语技能及技术理解。
本文还有配套的精品资源,点击获取

