大数据(一)MaxCompute
一、引言
作者后面会使用MaxCompute,所以在进行学习研究,总会有一些疑问产生,这里讲讲作者的疑问和思路
二、介绍
MaxCompute(原名 ODPS - Open Data Processing Service)是阿里云提供的大数据处理平台,专门用于批量数据存储和大规模并行计算。它广泛应用于数据分析和处理任务,为企业级数据处理提供高效的解决方案。
下面是 MaxCompute 的一些主要功能和应用场景:
-
大规模数据存储:MaxCompute 提供高效的数据存储解决方案,可以存储 PB 级别的数据,支持结构化和半结构化数据。它的存储系统具有高可用性和高可靠性。
-
大数据计算引擎:MaxCompute 提供了强大的计算能力,能够处理大规模数据集。它支持 SQL 、MapReduce 、Graph 和 UDF(用户自定义函数)等多种计算模型,为复杂数据分析提供支持。
-
高效的资源管理:MaxCompute 通过资源组、任务队列等资源管理机制,能够实现资源的高效调度和利用,确保计算任务的高效进行。
-
安全和权限管理:MaxCompute 提供了完善的安全机制,包括数据访问权限控制、数据加密等,确保数据的安全性。
-
数据处理和分析:适用于多种数据处理和分析任务,包括数据清洗、预处理、数据挖掘、统计分析等。它可以与阿里云其他大数据产品(如 DataWorks 、AnalyticDB)集成,形成完整的大数据解决方案。
-
扩展性和高可用性:MaxCompute 具有很强的扩展性,可以根据需要动态扩展计算资源。此外,它具有高可用性设计,确保服务的稳定运行。
-
多语言支持:MaxCompute 支持多种编程语言,如 SQL 、Python 、Java 等,方便用户编写数据处理和分析任务
三、问答
看了一段时间官方文档之后,常见的SQL问题以及优化示例_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心作者有很多疑问
1、长尾问题是什么?
一般来说数据分布中存在少量出现频率非常高的“热点”数据,而同时也有大量出现频率低但多样性高的“长尾”数据
但是MaxCompute将Fuxi Instance 耗费时长高于平均值 2倍的实例判定为长尾
也就是将任务分配和执行的引擎实例时间执行过长的认为长尾
比如这个sql他就举例说会引起长尾问题
SELECT shop_id,sum(is_open) AS 营业天数 FROM table_xxx_diWHERE dt BETWEEN \'bizdate365′AND′bizdate365′AND′{bizdate}\'GROUP BY shop_id;按照社区请教了一些朋友,这种可能是数据倾斜造成,比如一些 shop_id 的数据量远大于其他 shop_id,GROUP BY shop_id的处理时间会明显超过平均值,从而导致长尾现象
解决方案一般是
-
数据预处理和分区调整:
尝试在数据写入阶段使用均匀分布的分区键,如果可能,重新设计数据模型以减轻倾斜。
-
计算逻辑优化:
- 将复杂计算在 ETL 阶段提前处理或者分解为多个合理的小任务。
- 使用窗口函数或其他优化 SQL 技术来减少不必要的数据重计算。
这些说起来都比较笼统,作者对于这个长尾还是有一些模糊
比如数据是
sql查询是
SELECT user_id, COUNT(*) AS transaction_countFROM transactionsGROUP BY user_idORDER BY transaction_count DESC;这样会因为user_id 1001 存在大量记录(数据倾斜),导致数据在计算节点上分布不均。部分计算节点会因为数据量过大而成为瓶颈,其他节点却几乎无事可做。这会拖慢整个查询的执行时间,造成长尾问题
对应的解决方案是
1. 盐值处理(作者觉得类似hash进行key的分散)
将热点用户的记录通过添加附加前缀或后缀进行分散,来分配给不同的计算节点。
修改 SQL
首先在数据预处理时对user_id进行变换:
INSERT INTO transactions_with_saltSELECT CONCAT(user_id, \'_\', CAST(RAND() * 10 AS INT)) AS user_salt, amountFROM transactions;然后在查询时进行逆变换处理:
SELECT SUBSTR(user_salt, 0, LENGTH(user_salt) - 2) AS user_id, SUM(transaction_count) AS total_transactionsFROM ( SELECT user_salt, COUNT(*) AS transaction_count FROM transactions_with_salt GROUP BY user_salt) AS salted_dataGROUP BY SUBSTR(user_salt, 0, LENGTH(user_salt) - 2)ORDER BY total_transactions DESC;这样相当于是多遍计算,因为要进行随机化再分组,然后把结果给去除之前处理进行重新分组,但是把计算压力给到了多个节点
2. 分区与并行化
对user_id分区或者引入合适的分区键,比如category_id,以在存储阶段给予更好的数据分配
2、为什么MapReduce需要本地Combiner?
看到示例的MapReduce,作息的理解是进行分布式的数据录入处理,然后进行集中处理,感觉很像是java的Fork/Join 框架进行分治
作者理解是吧线程映射成了机器,进行分布式处理然后合并
但是他为什么有个本地Combiner呢?
作者一开始是不理解的,后面再思考发现最明显的是作用范围不一样,
Combiner作用于单个 Mapper 节点的本地数据,仅对本节点的数据进行局部汇总,他主要是减少数据传输,本地先算一下会快很多
Reducer对所有 Mapper 节点输出的数据进行处理
package com.aliyun.odps.mapred.open.example;import java.io.IOException;import java.util.Iterator;import com.aliyun.odps.data.Record;import com.aliyun.odps.data.TableInfo;import com.aliyun.odps.mapred.JobClient;import com.aliyun.odps.mapred.MapperBase;import com.aliyun.odps.mapred.ReducerBase;import com.aliyun.odps.mapred.conf.JobConf;import com.aliyun.odps.mapred.utils.InputUtils;import com.aliyun.odps.mapred.utils.OutputUtils;import com.aliyun.odps.mapred.utils.SchemaUtils;public class WordCount { public static class TokenizerMapper extends MapperBase { private Record word; private Record one; @Override public void setup(TaskContext context) throws IOException { word = context.createMapOutputKeyRecord(); one = context.createMapOutputValueRecord(); one.set(new Object[] { 1L }); System.out.println(\"TaskID:\" + context.getTaskID().toString()); } @Override public void map(long recordNum, Record record, TaskContext context) throws IOException { for (int i = 0; i < record.getColumnCount(); i++) { word.set(new Object[] { record.get(i).toString() }); context.write(word, one); } } } /** * A combiner class that combines map output by sum them. **/ public static class SumCombiner extends ReducerBase { private Record count; @Override public void setup(TaskContext context) throws IOException { count = context.createMapOutputValueRecord(); } /**Combiner实现的接口和Reducer一样,是可以立即在Mapper本地执行的一个Reduce,作用是减少Mapper的输出量。*/ @Override public void reduce(Record key, Iterator values, TaskContext context) throws IOException { long c = 0; while (values.hasNext()) { Record val = values.next(); c += (Long) val.get(0); } count.set(0, c); context.write(key, count); } } /** * A reducer class that just emits the sum of the input values. **/ public static class SumReducer extends ReducerBase { private Record result = null; @Override public void setup(TaskContext context) throws IOException { result = context.createOutputRecord(); } @Override public void reduce(Record key, Iterator values, TaskContext context) throws IOException { long count = 0; while (values.hasNext()) { Record val = values.next(); count += (Long) val.get(0); } result.set(0, key.get(0)); result.set(1, count); context.write(result); } } public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println(\"Usage: WordCount \"); System.exit(2); } JobConf job = new JobConf(); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(SumCombiner.class); job.setReducerClass(SumReducer.class); /**设置Mapper中间结果的key和value的Schema, Mapper的中间结果输出也是Record的形式。*/ job.setMapOutputKeySchema(SchemaUtils.fromString(\"word:string\")); job.setMapOutputValueSchema(SchemaUtils.fromString(\"count:bigint\")); /**设置输入和输出的表信息。*/ InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(), job); OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(), job); JobClient.runJob(job); }}3、Graph图识别使用场景?
看到他有个图识别的功能,作者挺感兴趣的,主要是想看看他在什么场景下可以使用
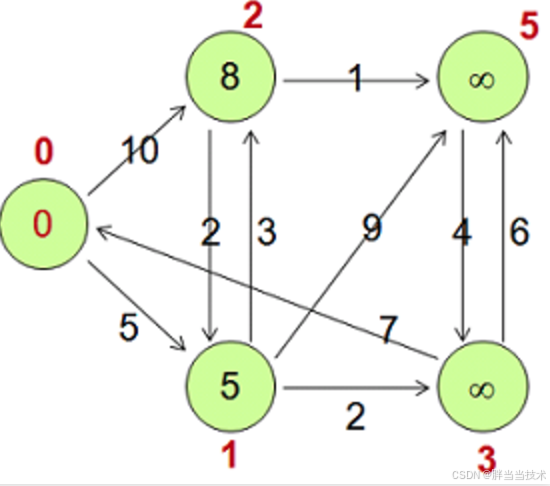
不过看起来也不多,程序示例只有三个,比较经典的是PageRank识别
看着里面的代码还有点疑惑,比如hasEdges这个没有具体的实现,想了一下应该是Vertex这个父类里面应该做了一些通用的实现
PageRank(i)为什么等于 0.15/TotalNumVertices+0.85*sum?
这也是一个不容易理解的点,他会考虑其连接的其他页面对其排名的“投票”权重,同时也引入了一个“随机跳转”的概率
作者想的是为什么会有自由跳转,每个页面被多少页面引用不是应该是确定的嘛?
作者理解他主要是防呆的
-
防止死循环和陷阱页面:
在某些情况下,一个算法可能会遇到“死循环”或者陷入一个“陷阱”。例如,一个圈子内的页面互相链接,但与外界没有链接。在没有自由跳转的情况下,PageRank 值可能会无限在这个局部循环中传播,而无法扩展到其他页面。
-
处理无出链接页面(dead-ends):
-
对于那些没有出链接的节点(也被称为“死角”或“孤立页面”),它们可能导致算法难以进行,因为 PageRank 值会留在这里,而无法流动到其他节点。
-
带有自由跳转机制,任何页面,包括孤立节点,始终有机会把 PageRank 值扩散到网络中的其他页面。
-
-
算法的数学稳定性:
-
自由跳转确保 PageRank 表示为马尔可夫链中的一次遍历,确保整个网络是强连通的。
-
这种做法保证算法能够收敛到一个唯一的解决方案(稳定的 PageRank 值),因为加了一种“外力”平衡系统,确保无论什么初值和结构,计算都可以在有限步内收敛。
-
-
现实浏览行为的模拟:
-
自由跳转还可以模拟真实用户在互联网浏览过程中的不确定行为。人们很可能会在阅读一段时间后通过打字地址栏或者点击收藏夹而不是继续点击当前链接进行跳转。
-
这种不确定性通过自由跳转体现出用户在网络上的随机行为。
-
sendMessageToNeighbors会将节点的 PageRank 值发送到所有直接连接的邻居节点,作者又有问题了:如果相邻节点已经计算过,发送过去有什么用呢?
-
每个节点在超级步骤开始时接收来自邻居的消息,根据这些消息更新自己的状态
-
计算完成后,将新的或调整过的信息发送给所有出链的邻居
-
这个过程在多个超级步骤中重复,直至达到一定的收敛条件
作者理解这就是区分了三个if的迭代过程,算好的值还会接受相邻节点再进行结合计算
import java.io.IOException;import org.apache.log4j.Logger;import com.aliyun.odps.io.WritableRecord;import com.aliyun.odps.graph.ComputeContext;import com.aliyun.odps.graph.GraphJob;import com.aliyun.odps.graph.GraphLoader;import com.aliyun.odps.graph.MutationContext;import com.aliyun.odps.graph.Vertex;import com.aliyun.odps.graph.WorkerContext;import com.aliyun.odps.io.DoubleWritable;import com.aliyun.odps.io.LongWritable;import com.aliyun.odps.io.NullWritable;import com.aliyun.odps.data.TableInfo;import com.aliyun.odps.io.Text;import com.aliyun.odps.io.Writable;public class PageRank { private final static Logger LOG = Logger.getLogger(PageRank.class); public static class PageRankVertex extends Vertex { @Override public void compute( ComputeContext context, Iterable messages) throws IOException { if (context.getSuperstep() == 0) { setValue(new DoubleWritable(1.0 / context.getTotalNumVertices())); } else if (context.getSuperstep() >= 1) { double sum = 0; for (DoubleWritable msg : messages) { sum += msg.get(); } DoubleWritable vertexValue = new DoubleWritable( (0.15f / context.getTotalNumVertices()) + 0.85f * sum); setValue(vertexValue); } if (hasEdges()) { context.sendMessageToNeighbors(this, new DoubleWritable(getValue() .get() / getEdges().size())); } } @Override public void cleanup( WorkerContext context) throws IOException { context.write(getId(), getValue()); } } public static class PageRankVertexReader extends GraphLoader { @Override public void load( LongWritable recordNum, WritableRecord record, MutationContext context) throws IOException { PageRankVertex vertex = new PageRankVertex(); vertex.setValue(new DoubleWritable(0)); vertex.setId((Text) record.get(0)); System.out.println(record.get(0)); for (int i = 1; i < record.size(); i++) { Writable edge = record.get(i); System.out.println(edge.toString()); if (!(edge.equals(NullWritable.get()))) { vertex.addEdge(new Text(edge.toString()), NullWritable.get()); } } LOG.info(\"vertex edgs size: \" + (vertex.hasEdges() ? vertex.getEdges().size() : 0)); context.addVertexRequest(vertex); } } private static void printUsage() { System.out.println(\"Usage: [Max iterations (default 30)]\"); System.exit(-1); } public static void main(String[] args) throws IOException { if (args.length = 3) job.setMaxIteration(Integer.parseInt(args[2])); long startTime = System.currentTimeMillis(); job.run(); System.out.println(\"Job Finished in \" + (System.currentTimeMillis() - startTime) / 1000.0 + \" seconds\"); }}4、他的存储是什么结构?
根据资料,他使用的分布式文件系统专为大规模数据存储和处理设计,具备高可用性、高可靠性和高性能的特点。
在存储模型上,类似于对象存储,数据以对象的形式存储,便于快速访问和处理
为优化查询性能和存储效率,MaxCompute 在存储层面支持列式存储格式
看起来很类似 Hadoop 的 HDFS
-
NameNode:
负责管理元数据和文件系统的命名空间。 NameNode 知道每个文件和目录中每个数据块的位置。它是系统的中心,并不存储实际数据或文件
-
DataNode:
负责存储实际数据以及数据块。每个 DataNode 定期向 NameNode 报告其存储的块信息。在集群规模扩大时,可以通过增加 DataNode 来增加存储能力
-
Secondary NameNode:
协助 NameNode 的检查点和元数据快照工作,减少 NameNode 的启动时间
当然具体是不是,还需要看源代码才知道,他没有开源,作者后续再进行源码研究
5、他的索引结构是什么样子?
他是列式存储(列存)来提高查询性能,对数据进行分区(例如按日期、地理位置等字段),减小查询范围,加快查询速度。这种机制在做范围查询或按条件过滤时比较高效。
存储文件可能会被分成多个区块,每个区块内的数据在物理存储上是连续的,通常会根据统计信息(如最小值和最大值)对这些区块建立索引,从而快速跳过不相关的数据块。
对于一些离散型类别数据,常使用数据字典技术来进行压缩并加速查询。
6、histogram有什么用?
他介绍过一个sql优化,意思是拿直方图来作为分析
ANALYZE TABLE compute statistics FOR columns WITH histogram 256 buckets;256 BUCKETS 表示直方图中将数据分为 256 个桶,这个就是横坐标
比如数据值的范围是 0到 100,我们用 256 个桶来描述这列数据的直方图。那么可能的分布形式会类似于:
- Bucket 1: [0-0.39], Frequency: 5
- Bucket 2: [0.4-0.79], Frequency: 15
- ...
- Bucket 128: [50-50.39], Frequency: 25
- ...
- Bucket 256: [99.6-100], Frequency: 30
类似于
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ └───┴──┴───┴───┴── 0 20 40 60 80 100但是作者觉得还是不太理解这在什么时候要用到,等后面进项目看看
四、总结
他的内容很多,作者暂时看了四五分之一吧,作者会持续研究分享
目前没有进项目,也没有看到实际源码,很多问题和分析都是作者YY的,过几天进项目了再看看源码,很多疑问就会有确定的答案
作者认为带着问题去学习研究才是最快的,大胆假设疑问,小心分析求证,原理都是相通的,区别不会很大


