ICCV 2025 SEGS-SLAM:一种结构启发的3DGS+SLAM算法,TUM RGB-D、Replica、EuRoC、Scannet均超过SOTA!_基于3dgs的slam
【SEGS-SLAM: Structure-enhanced 3D Gaussian Splatting SLAM with Appearance Embedding】
文章链接:[2501.05242] SEGS-SLAM: Structure-enhanced 3D Gaussian Splatting SLAM with Appearance Embedding
项目主页:SEGS-SLAM https://segs-slam.github.io/
代码:segs-slam/SEGS-SLAM(官方实现,只提供编译完的代码。非官方实现请参考leaner-forever/SEGS-SLAM,这个repo复现的指标与我们论文相当接近,请放心使用)
作者单位:南开大学
发表会议:ICCV 2025

3D高斯溅射(3D-GS)最近在同步定位与地图构建(SLAM)问题中的新视图合成领域引发了革命性变革。然而,大多数现有算法无法充分捕捉潜藏结构,导致结构不一致性。此外,它们难以处理突变的外观变化,进而造成视觉质量的不连贯。为解决这些问题,我们提出了SEGS-SLAM,一种结构增强的3D高斯溅射SLAM系统,实现了高质量的照片级真实感建图。我们的主要贡献体现在两个方面: 1. 首次提出结构增强照片级真实感建图(SEPM)框架:该框架利用高度结构化的点云初始化结构化3D高斯,显著提升了渲染质量。 2. 提出运动外观嵌入(AfME):使3D高斯能够更好地建模不同相机位姿下的图像外观变化。 在单目、双目和RGB-D数据集上的大量实验表明,SEGS-SLAM在照片级真实感建图质量上显著优于现有最优(SOTA)方法。例如,在单目相机的TUM RGB-D数据集上,其PSNR相比MonoGS提升了19.86%。项目主页可访问:https://segs-slam.github.io/。
所解决的问题:
大部分的基于3DGS的SLAM算法没能考虑环境的潜藏结构,限制他们的渲染质量。一些算法探索了采用3D高斯进行定位与建图的精度、效率性以及传感器不确定性。仅有Photo-SLAM利用了环境的结构。它采用了一种解耦的架构,采用间接法视觉SLAM得到的点云初始化3D高斯,并进一步引入基于几何的稠密化模块来稠密化高斯。3DGS原文中采用SfM,由于间接法SLAM与SfM具有高度相似的pipline,包括特征匹配与跟踪、bundle adjustmen等等,使得他们生成的点云具有高度相似的内在特性。Photo-SLAM 实现了不错质量的实时真实感建图。但其对于环境结构的利用仍然不充分。
另一个这些方法没有处理的问题是环境中较大的外观变化(例如曝光、光照)。这个问题较早的时候被NeRF-W初步解决,他们引入外观嵌入来解决这个问题,这个嵌入的输入为图像索引。但是他们要求在采用测试集中每张图片的一半进行训练。
核心insight:
如果能生成高质量的环境点云来初始化3DGS,并且在整个训练过程中保证结构的稳定性,最终会获得很好的结果。
创新点
1.这是第一篇将scaffold-gs的anchor化3DGS的结构与ORB-SLAM3结合的方法,实现了对场景结构很好地利用,精度远超当前的所有的SOTA方法。
2.我们提出从运动嵌入外观,将每张图像的外观变化建模到相机位姿编码后的潜藏空间。
3.我们的方法在TUM RGB-D、Replica、EuRoC、Scannet四个数据集中均实现了最高的渲染质量,并具备ORB-SLAM3的高精确位姿估计能力。同时我们的方法支持单目、双目以及RGB-D三种相机类型。据我们所知这是已知目前唯一同时能实现大量相机类型和数据集均超过SOTA的3DGS-based SLAM方法。
架构:
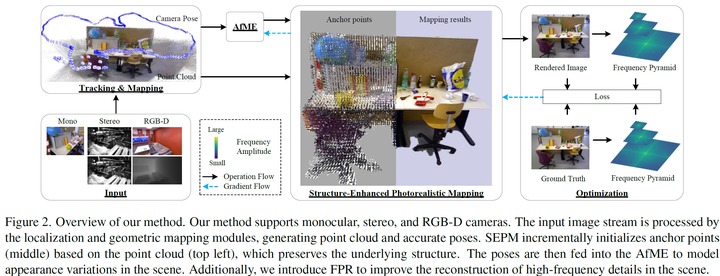
数据流:
我们的方法支持单目、双目和RGB-D相机。输入的图像流由定位和几何建图模块处理,生成点云与精确位姿。结构增强照片级真实感建图(SEPM)基于点云(左上角)渐进式初始化锚点(中间),以此保留底层结构。随后将位姿输入运动外观嵌入(AfME),用于建模场景中的外观变化。此外,我们引入了频率金字塔正则化(FPR)以提升场景高频细节的重建效果。
结构增强照片级真实感建图(SEPM):

我们的方法将ORB-SLAM3与Scaffol-GS结合,在训练完成后获得了很好地结构性,因此对于细小的结构能有更好地还原,见上图。下图的消融实验也很好地说明了这点:

运动外观嵌入(AfME):
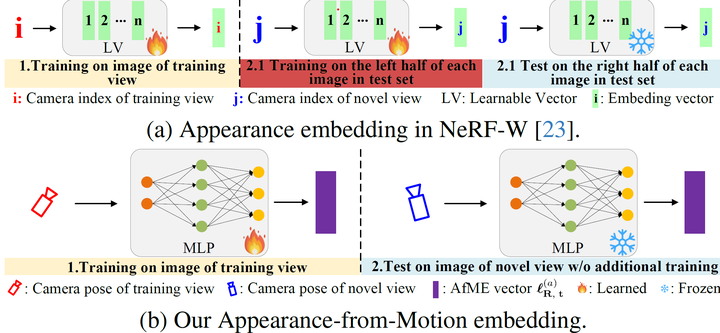
NeRF-W的外观嵌入的输入为图像索引。他们要求在采用测试集中每张图片的一半进行训练,不具备泛化性。我们的insight是:外观变化是由于观测位姿与光源的位置变化导致的,因此将外观变化编码到位姿空间,就能很好地预测新视角的外观变化了。下图的消融实验能说明这点,可以看到我么的方法能更好地还原新视角的亮度:

不加AfME图像亮度偏暗
频率金字塔正则化(FPR)
我们将真值图像降采样至多个尺度,并采用快速傅里叶变换提取高频频谱,用来监督。这样能引导高斯往高频区域稠密化,从而更好地还原场景细节。

实验结果
实现:参考Photo-SLAM,C++和LibTorch实现。GPU:4090
对比方法:RTG-SLAM (SIGGRAPH 2024), GS-SLAM (CVPR 2024), SplaTAM (CVPR 2024), MonoGS (CVPR 2024), Photo-SLAM(CVPR 2024), SGS-SLAM (ECCV 2024), and GS-ICP SLAM (ECCV 2024)
数据集:TUM RGB-D、Replica、EuRoC、Scannet
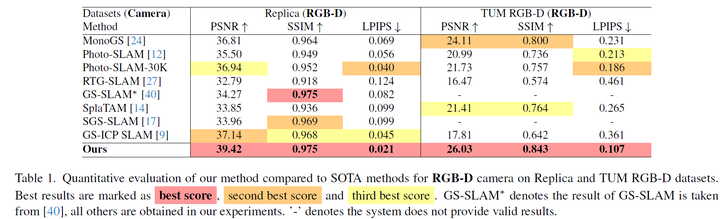
RGB-D:
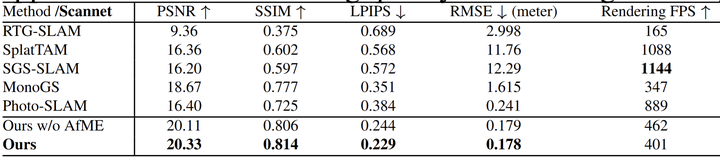
Scannet
Mono(单目)和 双目:

定位:
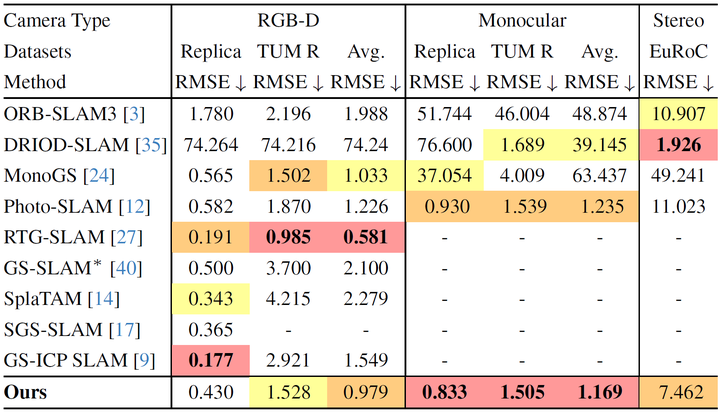
因为使用的ORB-SLAM3,没有什么很大的改进,就正常精度。
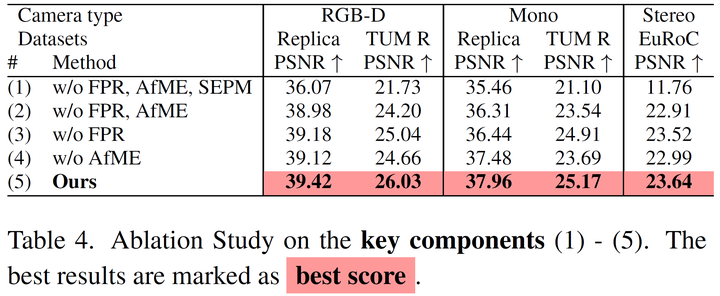
消融实验
后续研究方向:
我给出几个我没来的及做的点,希望能给大家一些启发:
1.过分依赖局限性,如和在点云质量较差的场景work,是一个问题。
2.扩展至动态场景、室外场景。可以参考FreetimeGS。
3.提升实时性。参考Taming-GS
最后
最后感谢大家能读到这里,如果能帮助到大家就太好了。也非常感谢复现我们算法并且开源的朋友。由于最近在找工作,回复可能不太及时,见谅。


