python中pandas之dataframe知识_python dataframe
目录
(1)dataframe介绍
(2)dataframe生成
(3)数据访问
1.索引访问
2.视图与副本
3.获取列名序列、index序列和值二维序列
4.获取和修改index名字和列名字
5.查看头尾数据
6.遍历访问
7.数据筛选
1.bool筛选
①bool简单条件筛选
②布尔型Series的并集与交集
③pdobj.any()与all()
④一些实际应用
2.df.query
(4)数据修改
1.创建新列和删除列
2.修改某一列的值
3.布尔替换
4.删除数据
5.去重
6.转置
(5)值的字符串操作
(6)排序
1.对行或者列名指定顺序
①pdobj.reindex() 对行名和列名重新指定顺序和筛选
用reindex筛选列
②pdobj.sort_index() 根据行索引和列名值大小指定顺序
③df.set_index()和 df.reset_index()
2.按值进行排序:pdobj.sort_values()
(7)数学运算
1.数学运算以及fill_value参数
2.Series 和 DataFrame 广播运算
(8)常用统计方法
(9)函数映射
1.np 的函数可以用于 pd 对象:操作元素
2.dataframe.apply(func):操作df每一行或者列
3.dataframe.applymap(func):操作df每个元素
4.Series.map(func):操作series每个元素
(10)pandas数据规整
(1)dataframe介绍
DataFrame是二维表格型数据结构,有行列索引,可高效存储、操作与分析结构化数据。
import pandas as pdif __name__ == \"__main__\": x = [[91, 90, 85, 80, 77], [100, 100, 100, 100, 100]] df = pd.DataFrame(x,index=[\'ZhangSan\', \'LiSi\'],columns=[\'Math\', \'English\', \'Chinese\', \'History\', \'Physics\']) print(df) 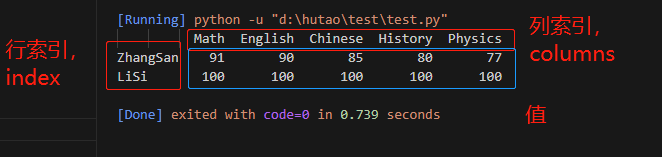
(2)dataframe生成
函数:pd.DataFrame(可迭代对象, columns = 列名的列表, index = 行名的列表)
例子1:传递一维列表创建
import pandas as pdimport numpy as npfrom random import randint# ①传递一维列表x = [1,2,3,4,5]df = pd.DataFrame(x)print(df) # 不指定index和columns时,采用默认索引0,1,...N-1例子2:传递嵌套列表创建
matrix = [[randint(1, 10)]*5 for x in range(3)]print(matrix)df = pd.DataFrame(matrix)print(df)例子3:传递字典创建
data = {\'state\': [\'Ohio\', \'Ohio\', \'Ohio\', \'Nevada\', \'Nevada\', \'Nevada\'], \'year\': [2000, 2001, 2002, 2001, 2002, 2003], \'population\': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}df = pd.DataFrame(data)print(df) # columns为键名,index采用默认索引例子4:传递字典时,同时自定义index
df = pd.DataFrame(data, index = [\"A\", \"B\",\"C\", \"D\",\"E\", \"F\",])print(df)例子5:传递嵌套字典
data2 = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} df2 = pd.DataFrame(data2)print(df2) # columns为外键,index为内键例子6:传递嵌套字典时,指定列名的顺序
df = pd.DataFrame(data2, columns = [\'pop\', \'state\', \'year\', \'newcolumn\'])print(df) # 若字典中不存在该列名,则 dataframe 会以这个新列名新建一个全为 NaN 的列例子7:传递嵌套字典时,指定行名和列名的顺序
df = pd.DataFrame(data2, columns = [\'pop\', \'state\', \'year\', \'newcolumn\'], index=[\'a\',\'c\',\'b\',\'d\',\'e\',\'f\',\'newrow\'])print(df) 例子8:传递值为Series的字典时
pop = {\'Nevada\': {2001: 2.4, 2002: 2.9}, \'Ohio\': {2000: 1.5, 2001: 1.7, 2002: 3.6}}df = pd.DataFrame(pop)newdict = {\'Ohio\': df[\'Ohio\'][:-1], \'Nevada\': df[\'Nevada\'][1:]}newdf = pd.DataFrame(newdict)print(newdf) # columns为外键,index为 Series 的索引的并集# Ohio Nevada# 2000 1.5 NaN# 2001 1.7 2.4# 2002 NaN 2.9(3)数据访问
1.索引访问
示例数据
import pandas as pdimport numpy as npdata = {\'state\': {\"a\": \'Ohio\', \"b\": \'Ohio\', \"c\": \'Ohio\', \'d\': \'Nevada\', \"e\": \'Nevada\', \"f\": \'Nevada\'}, \'year\': {\"a\": 2000, \"b\": 2001, \"c\": 2002, \'d\': 2001, \"e\": 2002, \"f\": 2003}, \'pop\': {\"a\": 1.5, \"b\": 1.7, \"c\": 3.6, \'d\': 2.4, \"f\": 2.9, \"e\": 3.2}}df = pd.DataFrame(data)print(df)例子①:访问单列
result = df.stateresult = df[\'state\']result = df.loc[:, \'state\']print(result)例子②:访问多列
result = df[[\'state\', \'year\']]result = df.loc[:,[\'state\', \'year\']]print(result)# 如果访问的索引不存在,则KeyErrorresult = df[[\'state\', \'year\', \'xxx\']]print(result) # KeyError: \"[\'xxx\'] not in index\"例子③:访问单行
result = df.loc[\'a\']result = df.loc[\'a\',:]print(result) # Series# state Ohio# year 2000# pop 1.5# Name: a, dtype: objectresult = df.loc[[\'a\']]print(result) # dataframe# state year pop# a Ohio 2000 1.5例子④:访问多行
result = df[\'a\': \'b\'] # 切片,两端都能取到result = df[:2] # 切片,右端取不到print(result)result = df.loc[[\'d\', \'a\', \'c\']] # 访问指定行result = df.loc[[\'d\', \'a\', \'c\'],:]result = df.loc[\'a\': \'b\', :] print(result)result = df[0:1] print(result) # 这个只能取到一行,但返回的是dataframe# state year pop# a Ohio 2000 1.5例子⑤:单行多列
result = df.loc[\"a\",[\'year\',\'pop\']] # Seriesresult = df.loc[[\"a\"],[\'year\',\'pop\']] # DataFrame例子⑥:按指定名访问多行多列(注意不要忘了嵌套中括号)(常用)
result = df.loc[[\'d\', \'a\', \'c\'], [\'year\', \'pop\']]result = df.loc[:, [\'year\', \'pop\']]result = df.loc[[\'d\', \'a\', \'c\'], :]result = df.loc[\"a\":\"c\", [\'year\', \'pop\']]print(result)例子⑦:先索引多列再按切片索引多行(常用)
result = df[[\'state\', \'pop\']][:2]print(result)例子⑧:按默认索引访问。通常访问第一个或者最后一个,用iloc。(常用)
data = pd.DataFrame(np.arange(16).reshape((4, 4)), index=[\'Ohio\', \'Colorado\', \'Utah\', \'New York\'], columns=[\'one\', \'two\', \'three\', \'four\'])print(data.iloc[2, [3, 0, 1]])print(data.iloc[[1, 2], [3, 0, 1]])print(data.iloc[:2, :2])print(data.iloc[:2, [3, 0, 1]])注意事项:
1.索引的返回结果类型
- 多行或多列是 dataframe
- 单行或单列是 Series
- 特殊情况:
- df[0:1]这种切片的单行是 dataframe
- df.loc[[\'a\']]这种嵌套中括号的单行是dataframe
- 特殊情况:
2.切片右端能否取到
- 按名字切片时可以取到
- 按默认索引时取不到
2.视图与副本
索引访问是视图,副本需用 copy 方法
import pandas as pdpop = {\'Nevada\': {2001: 2.4, 2002: 2.9}, \'Ohio\': {2000: 1.5, 2001: 1.7, 2002: 3.6}}frame = pd.DataFrame(pop)print(frame)# Nevada Ohio# 2000 NaN 1.5# 2001 2.4 1.7# 2002 2.9 3.6subframe1 = frame[\'Nevada\']subframe1[2001] = 99print(frame)# Nevada Ohio# 2000 NaN 1.5# 2001 99.0 1.7# 2002 2.9 3.6subframe2 = frame[\'Nevada\'].copy()subframe2[2002] = 99print(frame)# Nevada Ohio# 2000 NaN 1.5# 2001 99.0 1.7# 2002 2.9 3.63.获取列名序列、index序列和值二维序列
df.columns:列名序列
df.index:行索引序列
df.values:值序列(二维)
import pandas as pdimport numpy as npdata = pd.DataFrame(np.arange(16).reshape((4, 4)), index=[\'Ohio\', \'Colorado\', \'Utah\', \'New York\'], columns=[\'one\', \'two\', \'three\', \'four\'])x = data.columnsy = data.indexz = data.valuesprint(type(x))print(type(y))print(type(z))print(list(x)) # [\'one\', \'two\', \'three\', \'four\']print(list(y)) # [\'Ohio\', \'Colorado\', \'Utah\', \'New York\']print(list(z)) # [array([0, 1, 2, 3]), array([4, 5, 6, 7]), array([ 8, 9, 10, 11]), array([12, 13, 14, 15])]print(list( list(z)[0] )) # [0, 1, 2, 3]# dataframe如何转化为二维列表df.values.tolist()# 类型查看data = pd.read_csv(path)close = data[\'close\'].valuesprint(type(data)) # print(type(data[\'close\'])) # print(type(close)) # 4.获取和修改index名字和列名字
df.index.name:index名字
df.columns.name:列名名字
①创建时设置名字
data = pd.DataFrame(np.arange(6).reshape((2, 3)), index = pd.Index([\'Ohio\',\'Colorado\'], name = \'state\'), columns = pd.Index([\'one\', \'two\', \'three\'],name = \'number\'))print(data) ②默认名字为空,创建后更改名字
import pandas as pdimport numpy as npdata2 = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} frame2 = pd.DataFrame(data2)print(frame2)print(frame2.index.name) # Noneprint(frame2.columns.name) # Noneframe2.index.name = \"xxx\"frame2.columns.name = \"yyy\"print(frame2.index.name) # xxxprint(frame2.columns.name) # yyyprint(frame2)③用rename方法按字典修改列名(推荐)
df = df.rename(columns = {\"Ticker\":\"code\",\"Direction\":\"direction\"})
5.查看头尾数据
df.head()和df.tail():默认值是5行
# 使用 head()方法查看前几行,使用 tail()方法查看后几行 data = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} frame = pd.DataFrame(data)print(frame.head()) # 默认是前 5 行print(frame.tail()) # 默认是后 5 行print(frame.head(2)) # 查看前两行6.遍历访问
通常按行遍历,需要用到df.iterrows(),常用for index, row in holding_data.iterrows():,示例如下:
import numpy as npimport pandas as pdframe = pd.DataFrame({\'a\': range(7),\'b\': range(7, 0, -1),\'c\': [\'one\', \'one\', \'one\', \'two\', \'two\', \'two\', \'two\'],\'d\': [0, 1, 2, 0, 1, 2, 3]})print(frame)for index, row in frame.iterrows(): # print(index) # print(type(row)) # Series # print(row) print(f\"第{index}行a列的值为\", row[\'a\'])7.数据筛选
1.bool筛选
①bool简单条件筛选
import pandas as pdimport numpy as npdata2 = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}, \'xxx\': {\"a\":2., \"b\":1., \"c\":3.6, \'d\':9.9, \"f\":1.5, \"e\":3}} frame2 = pd.DataFrame(data2)print(frame2)# 例子1mybool1 = frame2.state == \'Ohio\' # 创建布尔型Seriesprint(mybool1)newdf = frame2[mybool1].copy() # 布尔筛选print(newdf)# 例子2mybool2 = frame2[\"pop\"] < frame2[\"xxx\"]mybool2 = frame2[\"pop\"].astype(float) < frame2[\"xxx\"].astype(float)print(mybool2)newdf = frame2[mybool2].copy()print(newdf)
②布尔型Series的并集与交集
import pandas as pddata1 = [True, True, False]s1 = pd.Series(data1)print(s1)data2 = [False, False, True]s2 = pd.Series(data2)print(s2)print(s1 | s2) # 并集,只要有一个为真则为真print(s1 & s2) # 交集,只要有一个为假则为假trade_file_path = r\"D:\\data\\trade.csv\"df_trade = pd.read_csv(trade_file_path, encoding=\"gbk\")bool1 = df_trade[\"成交时间\"] == \"09:25:00\"bool2 = df_trade[\"成交时间\"] == \"9:25:00\"condition = bool1 | bool2print(condition)df_trade_joint = df_trade[condition]print(df_trade_joint)布尔取反用 ~bool_var
# 注意这里一定要有小括号bool_zero = (df_diff[\"实际市值\"] == 0) & (df_diff[\"目标市值\"] == 0)df_diff = df_diff[~bool_zero]例子:或(注意每个条件要用小括号)
df_temp = df_fund_yestrade[(df_fund_yestrade.证券代码 == 204001) | (df_fund_yestrade.证券代码 == 131810)]例子:查询a列大于3且b列小于5的数据
df[(df[“a”] > 3) & (df[“b”]<5)]例子:只保留日期列中为 2021-01,2021-02 的行数据
mybool = data[\'日期\'].apply(lambda x:True if x in [\'2021-01\',\'2021-02\'] else False )data = data[mybool]③pdobj.any()与all()
any() 函数将一个可迭代对象作为参数,只要该可迭代对象中至少有一项为 True,就返回 True
all 是全部为为 True,才返回 True
- 如果是Series调用该方法,返回True或者False
- 如果dataframe调用该方法,返回Series,Series的值由多个True或者False组成,每一个值表明某行或者某列的那个Series调用该方法返回的True或者False
DataFrame.any(self, axis=0, bool_only=None, skipna=True, level=None, **kwargs) axis:轴方向,默认为0bool_only:用于是否只利用序列中的Boolean值进行判断skipna,是否跳过NA/null值 return 一个series或DataFrameDataFrame.all(self, axis=0, bool_only=None, skipna=True, level=None, **kwargs) 参数与any()一致
④一些实际应用
应用①:pandas中 isnull() 和 any() 的联合使用,来判断是否存在空值
- dataframe调用isnull()函数会得到一个值类型为bool的dataframe,df2
- 再对df2调用any()方法会得到一个series,索引为列名,值为False或者True,如果为False,表明该列一个True都没有,即对应原dataframe该列一个空值都没有,如果为True,表明至少有一个True,即原dataframe该列存在空值
应用②:找到某一列为指定值的index
# 找到某一列为指定值的indextest = frame2[\"xxx\"] == 1.5print(test)if result.any(): index = list(frame2[\"xxx\"][frame2[\"xxx\"] == 1.5].index) print(index) print(index[0])应用③:df中等于某个值的索引
print(\"全局最小值的索引\")print(df[df == value]) boolmin = df[df == value]result = []for index in boolmin.index: for col in boolmin.columns: if boolmin.loc[index,col] == value: result.append([index,col])print(result)2.df.query
查询数据可以用前面提到的布尔型筛选,但有时筛选条件比较复杂时,可以用Pandas自带的df.query方法。当然两种也都可以用。
df.query形式:DataFrame.query(expr, inplace=False, **kwargs)
其中expr为要返回boolean结果的字符串表达式
例子①:查询a列大于3且b列小于5的数据
bool筛选:df[(df[“a”] > 3) & (df[“b”]<5)]
query函数筛选:df.query(“a>3 & b<5”)
例子②:查询最低温度低于-10度的前3行数据
bool查询:df[df[\"yWendu\"] < -10].head(3)
query查询:df.query(\"yWendu < 3\").head(3)
例子③:复杂条件查询:查询最高温度小于30度,并且最低温度大于15度,并且是晴天,并且天气为优的数据
用bool方式查询是这样的(注意组合条件用&符号合并,每个条件判断都得带括号)
df[ (df[\"bWendu\"]=15) & (df[\"tianqi\"]==\'晴\') & (df[\"aqiLevel\"]==1)]但如果使用df.query可以简化代码
df.query(\"bWendu=15 & tianqi==\'晴\' & aqiLevel==1\")例子④:df.query更多高级用法
df.query可支持的表达式语法:
- 逻辑操作符: &, |, ~
- 比较操作符: <, =, >
- 单变量操作符: -
- 多变量操作符: +, -, *, /, %
查询温差大于15度的日子,前5行数据
df.query(\"bWendu-yWendu >= 15\").head()还可以可以使用外部的变量(用@符号)
# 查询温度在这两个温度之间的数据high_temperature = 15low_temperature = 13df.query(\"yWendu=@low_temperature\").head()(4)数据修改
1.创建新列和删除列
import pandas as pdimport numpy as npdata2 = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} frame2 = pd.DataFrame(data2)# 如果newcolumn已存在,则修改值# 如果newcolumn不存在,则创建新列frame2[\'newcolumn\'] = 10print(frame2)# 删除列del frame2[\'newcolumn\']print(frame2)2.修改某一列的值
import pandas as pdimport numpy as npdata2 = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} frame2 = pd.DataFrame(data2)# 1.使用标量frame2[\'pop\'] = 1000 print(frame2)# 2.使用相同长度的列表frame2[\'pop\'] = [10, 20, 30, 40, 50, 60] print(frame2)# 3.使用相同长度的 np 数组frame2[\'pop\'] = np.arange(6.) print(frame2)# 4.使用相同 index 的 Seriesmyseries = pd.Series(np.arange(6), index = [\'a\', \'b\', \'c\', \'d\', \'e\', \'f\'])frame2[\'pop\'] = myseriesprint(frame2)# 5.将index为\'a\',\'d\',\'f\'的值变为这些值,其他index对应的值将会变为 NaNval = pd.Series([99, 88, 77], index=[\'a\', \'d\', \'f\']) frame2[\'pop\'] = val print(frame2)# state year pop# a Ohio 2000 99.0# b Ohio 2001 NaN# c Ohio 2002 NaN# d Nevada 2001 88.0# e Nevada 2002 NaN# f Nevada 2003 77.0# 6.Series多出来的 index 和值将会被忽略val = pd.Series([99, 88, 77, 6666], index=[\'a\', \'d\', \'f\', \'newindex\']) frame2[\'pop\'] = val print(frame2)# state year pop# a Ohio 2000 99.0# b Ohio 2001 NaN# c Ohio 2002 NaN# d Nevada 2001 88.0# e Nevada 2002 NaN# f Nevada 2003 77.03.布尔替换
import pandas as pdimport numpy as npdata2 = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}, \'xxx\': {\"a\":2., \"b\":1., \"c\":3.6, \'d\':9.9, \"f\":1.5, \"e\":3}} frame2 = pd.DataFrame(data2)print(frame2)# 创建布尔型Seriesmybool1 = frame2.state == \'Ohio\'print(mybool1)mybool2 = frame2[\"pop\"] < frame2[\"xxx\"]mybool2 = frame2[\"pop\"].astype(float) < frame2[\"xxx\"].astype(float)print(mybool2)# 创建布尔型的新列frame2[\'eastern\'] = frame2.state == \'Ohio\'print(frame2)# 布尔型过滤newdf = frame2[mybool2].copy()print(newdf)# 布尔型替换frame2[mybool2] = 2 # 将为True的行的每一列都变为了2print(frame2)frame2[\"xxx\"][mybool2] = 999print(frame2) # 将为True的行的指定列变为9994.删除数据
DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
参数含义:
- labels:要删除的行或列,用列表给出
- axis:默认为0,指要删除的是行,删除列时需指定axis为1
- index :直接指定要删除的行,删除多行可以使用列表作为参数
- columns:直接指定要删除的列,删除多列可以使用列表作为参数
- inplace: 默认为False,该删除操作不改变原数据;inplace = True时,改变原数据
删除行或列有两种方式:
1. 通过参数labels和axis 来指定
2. 通过参数index或者columns来指定
如果要删除的索引不存在,则KeyError。因此在删除前可以用in来判断是否存在。
import pandas as pdimport numpy as npdata = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} frame = pd.DataFrame(data)# 1.通过labels和axis参数来删除行if \"a\" in frame.index: frame.drop(labels = \"a\", axis = 0, inplace = True) # 默认axis = 0 print(frame)if \"a\" in frame.index: frame.drop(labels=[\"a\"], axis=0, inplace=True) print(frame)# 如果要删除的索引不存在,则KeyError frame.drop(labels=[\"b\",\"c\"], axis=0, inplace=True) print(frame)# 2.将要删除的index放入列表来删除delkey = [\"b\", \"c\", \"e\"]for key in delkey: if key in frame.index: frame.drop(labels=key, axis=0, inplace=True) print(frame)# 3.通过labels和axis参数来删除列frame.drop(labels=[\"year\",\"pop\"], axis=1, inplace=True) print(frame)# 4.通过index参数来删除行# 使用index参数后,axis参数失效data = {\'state\': {\"a\":\'Ohio\', \"b\":\'Ohio\', \"c\":\'Ohio\', \'d\':\'Nevada\', \"e\":\'Nevada\', \"f\":\'Nevada\'}, \'year\': {\"a\":2000, \"b\":2001, \"c\":2002, \'d\':2001, \"e\":2002, \"f\": 2003}, \'pop\': {\"a\":1.5, \"b\":1.7, \"c\":3.6, \'d\':2.4, \"f\":2.9, \"e\":3.2}} frame = pd.DataFrame(data)frame.drop(index=[\"a\",\"b\"], axis=1, inplace=True) print(frame)# 5.如何删除后3行数据df_holdXZ = df_holdXZ.drop(df_holdXZ.tail(3).index)# 6.通过columns参数来删除列# 使用columns参数后,axis参数失效frame.drop(columns=[\"year\"], axis=1, inplace=True) print(frame)5.去重
DataFrame.drop_duplicates(subset=None, keep=\'first\', inplace=False)
参数:
- subset是用来指定特定的列,默认为所有列。参数传入column label or sequence of labels,比如subset=\'列1\',subset=[\'列1\', \'列2\']。
- keep
- 当keep=\'first\'时,就是保留第一次出现的重复行,其余删除
- 当keep=\'last\'时,就是保留最后一次出现的重复行,其余删除
- 当keep=False时,就是删除所有重复行
- inplace是指是否直接在原数据上进行修改,默认为否
6.转置
pop = {\'Nevada\': {2001: 2.4, 2002: 2.9}, \'Ohio\': {2000: 1.5, 2001: 1.7, 2002: 3.6}}frame = pd.DataFrame(pop)print(frame)print(frame.T) # 转置(5)值的字符串操作
在使用pandas的时候,经常要对DataFrame的某一列的值进行操作,如果是数值类型,一般还比较好处理,但很多时候是字符串类型,一般都会使用df[\"xx\"].str下的方法。
当然在pandas里面如果是object,不能是整形、时间类型等等,如果想对这些类型使用的话,必须先df[\"xx\"].astype(str)转化一下。
这里举一个例子说明,比如有以下数据
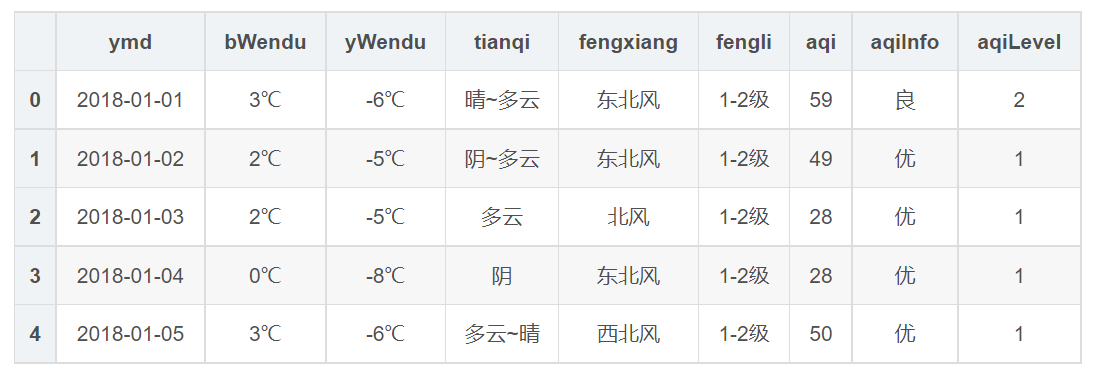
现在我们想把温度列的值里面的℃给删除,然后将数值类型转化为整型,如何操作呢,示例代码如下
# 替换掉温度的后缀℃df.loc[:, \"bWendu\"] = df[\"bWendu\"].str.replace(\"℃\", \"\").astype(\'int32\')df.loc[:, \"yWendu\"] = df[\"yWendu\"].str.replace(\"℃\", \"\").astype(\'int32\')当然还有更多关于字符串的操作,参考:pandas中Series对象下的str所拥有的方法(df[\"xx\"].str) - ministep88 - 博客园
(6)排序
1.对行或者列名指定顺序
pdobj.reindex():对Series或者dataframe按指定的index排序
pdobj.sort_index():对Series或者dataframe根据索引自身大小进行升序或者降序排序
①pdobj.reindex() 对行名和列名重新指定顺序和筛选
# ①pdobj.reindex()# 用 index 对 Series 重新排序obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=[\'d\', \'b\', \'a\', \'c\'])obj2 = obj.reindex([\'a\', \'b\', \'c\', \'d\', \'e\'])print(obj2) # 如果某个索引值不存在(这里是\'e\'),则引入空值 NaN# 用参数fill_value将NaN变为特定值obj3 = obj.reindex([\'a\', \'b\', \'c\', \'d\', \'e\'], fill_value = 999)print(obj3)# 用 index 和 columns 对 dataframe 重新排序frame = pd.DataFrame(np.arange(9).reshape((3,3)),index=[\'a\', \'c\', \'d\'],columns=[\'Ohio\', \'Texas\', \'California\'])print(frame)# 默认是按照行索引进行重新排序frame2 = frame.reindex([\'a\', \'b\', \'c\', \'d\']) print(frame2)frame3 = frame.reindex(index = [\'a\', \'b\', \'c\', \'d\'])print(frame3)frame4 = frame.reindex(columns = [\'Ohio\', \'California\', \'Texas\', \'xxx\'])print(frame4)frame5 = frame.reindex(index = [\'a\', \'b\', \'c\', \'d\'], columns = [\'Ohio\', \'California\', \'Texas\', \'xxx\'])print(frame5)# 用参数fill_value将NaN变为特定值frame6 = frame.reindex(index = [\'a\', \'b\', \'c\', \'d\'], columns = [\'Ohio\', \'California\', \'Texas\', \'xxx\'], fill_value = 9999)print(frame6)# 用参数method和limit进行插值处理obj = pd.Series([\'blue\', \'purple\', \'yellow\'], index=[0, 2, 4])obj2 = obj.reindex(np.arange(6), method = \'ffill\')print(obj2) # 前向填充,往前面方向填充 # 越下面的数据越前obj3 = obj.reindex(np.arange(6), method = \'bfill\')print(obj3) # 后向填充obj = pd.Series([\'blue\', \'purple\', \'yellow\'], index=[0, 3, 6])obj4 = obj.reindex(np.arange(10), method = \'ffill\', limit = 1)print(obj4) # 用limit设置单次填充的数量# 用匿名函数对行索引排序empindex = list(empInfoDF.index) # 获取编号(行索引)empindex.sort(key = lambda x:int(x), reverse = True) # 编号倒序empInfoDF.reindex(empindex) # 重新索引用reindex筛选列
import pandas as pddata = [[1, 2, 3], [4, 5, 6]]df = pd.DataFrame(data, columns=[\"A\", \"B\", \"C\"])print(df)\"\"\" A B C0 1 2 31 4 5 6\"\"\"df = df.reindex(columns=[\"A\", \"B\"])print(df)\"\"\" A B0 1 21 4 5\"\"\"②pdobj.sort_index() 根据行索引和列名值大小指定顺序
# pdobj.sort_index()# 按行索引自身的大小进行排序obj = pd.Series(range(4), index=[\'d\', \'a\', \'b\',\'c\'])obj2 = obj.sort_index()print(obj2) # 默认按 axis = 0 行排序 # 默认升序print(obj) # 说明 pandas 对象排序没有对原对象进行修改 obj.sort_index(inplace = True) # 对原对象进行修改print(obj)# 按列索引自身的大小进行排序frame = pd.DataFrame(np.arange(8).reshape((2, 4)), index=[\'three\', \'one\'], columns=[\'d\', \'a\', \'b\', \'c\'])print(frame)frame.sort_index(axis = 1, inplace = True)print(frame)# 按降序进行排列frame.sort_index(axis=1, ascending=False, inplace = True)print(frame)③df.set_index()和 df.reset_index()
前者是把某一列变为行索引,后者是把行索引变为列,然后行索引采用默认索引
frame = pd.DataFrame({\'a\': range(7),\'b\': range(7, 0, -1),\'c\': [\'one\', \'one\', \'one\', \'two\', \'two\', \'two\', \'two\'],\'d\': [0, 1, 2, 0, 1, 2, 3]})print(frame)frame2 = frame.set_index([\'c\', \'d\'])print(frame2)frame3 = frame2.reset_index()print(frame3)# 用drop参数删除原有的行索引,使得行索引变为默认索引frame4 = frame2.reset_index(drop = True) print(frame4)2.按值进行排序:pdobj.sort_values()
# ①对Series值的的大小进行排序obj = pd.Series([4, 7, -3, 2])print(obj)obj.sort_values(inplace = True) # 默认按行索引 # 默认升序print(obj) # 缺失值 NaN 排序在末尾obj = pd.Series([4, np.nan, 7, np.nan, -3, 2])print(obj) obj.sort_values(inplace = True) print(obj)# ②用by参数对dataframe的列进行排序matrix = [[1, 2, 3, 4], [2, 3, 4, 5], [1, 0, 0, 0], [2, 5, 7, 9]]frame = pd.DataFrame(matrix, index = [\'one\', \'two\', \'three\', \'four\'], columns = [\'a\', \'b\', \'c\', \'d\'])print(frame)# 按照‘a’列的降序排列frame.sort_values(by = \'a\', ascending = False,inplace = True) print(frame)# 主列‘a’用降序,次列‘b’用升序frame.sort_values(by = [\'a\', \'b\'], ascending = [False, True],inplace = True)print(frame)(7)数学运算
1.数学运算以及fill_value参数
①运算后索引会合并,只要有一方没有,就为 NaN
import pandas as pdimport numpy as np# 加法s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=[\'a\', \'c\', \'d\', \'e\'])s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1], index=[\'a\', \'c\', \'e\', \'f\', \'g\'])print(s1 + s2)print(s1.add(s2))df1 = pd.DataFrame(np.arange(9.0).reshape((3,3)), columns=list(\'bcd\'), index = [\'Ohio\', \'Texas\', \'Colorado\'])df2 = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list(\'bde\'), index=[\'Utah\', \'Ohio\', \'Texas\', \'Oregon\'])print(df1 + df2)# 减法print(s1 - s2)print(s1.sub(s2))print(df1 - df2)# 乘法print(s1 * s2)print(s1.mul(s2))print(df1 * df2)# 除法print(s1 / s2)print(s1.div(s2))print(df1 / df2)# 整除print(s1 // s2)print(s1.floordiv(s2))print(df1 // df2)# 幂print(s1 ** s2)print(s1.pow(s2))print(df1 ** df2)②用参数fill_value将只有一方的存在缺失值的位置填充为特定值,注意空值加空值仍为空值
print(s1.add(s2,fill_value = 0))2.Series 和 DataFrame 广播运算
frame = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list(\'bde\'), index=[\'Utah\', \'Ohio\', \'Texas\', \'Oregon\'])print(frame)series = frame.iloc[0]print(series)# ①默认按行广播(将 series“变为行”,然后向下广播)result = frame - seriesprint(result) # 如果将Series变为行以后,索引不一致,则合并,只要一方没有值的索引结果都是空值series2 = pd.Series(range(3), index=[\'b\',\'e\',\'f\'])print(series2)print(frame + series2)# ②按列进行广播frame = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns = list(\'bde\'), index = [\'Utah\', \'Ohio\', \'Texas\', \'Oregon\'])print(frame)series3 = frame[\'d\']print(series3)# 默认是 axis = \'columns\'或者 axis = 1result = frame.sub(series3, axis = \'index\') print(result)(8)常用统计方法
axis = 0就是行与行之间运算,axis = 1是列与列
数据
import numpy as npimport pandas as pddata = [[1.4, np.nan], [7.1, -4.5], [np.nan, np.nan], [0.75, -1.3]]df = pd.DataFrame(data, index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'one\',\'two\'])print(df)求和
print(\"求和\")print(df.sum()) # 对每一列求和print(df.sum(axis = 0))print(df.sum(axis = 1)) # 对每一行求和# 注意空值不进行运算,也就是【非空数求和/非空数个数】skipna参数
print(\"用skipna参数将空值运算均为空值\")# 默认的是空值不进行运算,也就是【非空数求和/非空数个数】# 现在将空值参与运算,结果也为空值print(df.sum(axis = 0, skipna = False))求平均
print(\"求平均\")print(df.mean()) # 对每一列求平均print(df.mean(axis = \'columns\', skipna = False)) # 对每一行求平均累计求和
print(\"累计求和\")print(df.cumsum()) # NaN 处仍为 NaN, NaN 不参与运算print(df.cumsum(axis = 0)) print(df.cumsum(axis = 1)) 累计求和与原值相比的最小值/最大值
print(\"累计求和与原值相比的最小值\")print(df.cummin()) print(df.cummin(axis = 0)) print(df.cummin(axis = 1)) print(\"累计求和与原值相比的最大值\")print(df.cummax()) print(df.cummax(axis = 0)) print(df.cummax(axis = 1)) 样本值的累计积
print(\"样本值的累计积\") # NaN 处仍为 NaN, NaN 不参与运算print(df.cumprod()) print(df.cumprod(axis = 1)) 样本值的一阶差分
print(\"样本值的一阶差分\") # NaN与任何运算都是NaNprint(df.diff()) print(df.diff(axis = 1)) 统计非空值个数
print(\"统计非空值个数\")print(df.count()) print(df.count(axis = 0)) print(df.count(axis = 1)) 最小值/最大值
print(\"最小值\")# 空值不参与比较,全为空值时返回空值print(df.min()) print(df.min(axis = 0)) print(df.min(axis = 1)) print(\"全局最小值\")print(df.min().min()) print(\"最大值\")print(df.max()) print(df.max(axis = 0)) print(df.max(axis = 1)) print(\"全局最大值\")print(df.max().max()) 最小值/最大值的索引
print(\"最小值的索引\")print(df.idxmin()) print(df.idxmin(axis = 1)) print(\"最大值的索引\")print(df.idxmax()) print(df.idxmax(axis = 1)) df中等于某个值的索引
print(\"全局最小值的索引\")print(df[df == df.min().min()]) boolmin = df[df == df.min().min()]result = []for index in boolmin.index: for col in boolmin.columns: if boolmin.loc[index,col] == df.min().min(): result.append([index,col])print(result)样本的分位数
print(\"样本的分位数\")print(df.quantile()) # 默认50%分位数,就是中位数print(df.quantile(0.7)) # 70%分位数print(df.quantile(0.7,axis = 0)) # 70%分位数print(df.quantile(0.7,axis = 1)) # 70%分位数平均均对离差
print(\"根据平均值计算平均均对离差\")print(df.mad()) print(df.mad(axis = 1)) 方差和标准差
print(\"计算样本的方差\")print(df.var()) print(df.var(axis = 1)) print(\"计算样本的标准差\")print(df.std()) print(df.std(axis = 1)) 样本的偏度和峰度
print(\"计算样本的偏度(三阶矩)\")print(df.skew()) print(df.skew(axis = 1)) print(\"计算样本的峰度(四阶矩)\")print(df.kurt()) print(df.kurt(axis = 1)) 描述性统计
print(\"数的描述统计\")# 总个数、平均值、标准差、最小值最大值、分位数print(df.describe()) # dataframe# 默认分位数是25%,50%,75%# one two# count 3.000000 2.000000# mean 3.083333 -2.900000# std 3.493685 2.262742# min 0.750000 -4.500000# 25% 1.075000 -3.700000# 50% 1.400000 -2.900000# 75% 4.250000 -2.100000# max 7.100000 -1.300000# 自定义分位数print(df.describe(percentiles=[.01,.05,.95,.99]))# one two# count 3.000000 2.000000# mean 3.083333 -2.900000# std 3.493685 2.262742# min 0.750000 -4.500000# 1% 0.763000 -4.468000# 5% 0.815000 -4.340000# 50% 1.400000 -2.900000# 95% 6.530000 -1.460000# 99% 6.986000 -1.332000# max 7.100000 -1.300000print(\"非数的描述统计\")# 总个数、不重复值个数、出现最多的值、出现最多的值的出现次数obj = pd.Series([\'a\', \'a\', \'b\', \'c\'] * 4)print(obj.describe()) # Series# count 16# unique 3# top a# freq 8# dtype: object百分比变化
print(\"百分比变化\")df = pd.DataFrame([[1.40, 1], [7.10, 2], [3.12, 4.25], [0.75, -1.3]], index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'one\',\'two\'])print(df)print(df.pct_change())print(df.pct_change(axis = 0))print(df.pct_change(axis = 1))样本的相关系数
print(\"样本的相关系数\")df = pd.DataFrame([[1.40, 1], [7.10, 2], [3.12, 4.25], [0.75, -1.3]], index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'one\',\'two\'])print(\"计算两个 Series 之间的相关系数\")print(df[\'one\'].corr(df[\'two\']))print(\"获取完整的相关系数矩阵\")print(df.corr())print(\"获取整个 dataframe 与某一列的相关相关系数\")print(df.corrwith(df[\'two\']))print(\"获取两个 dataframe 之间的相关系数\")df1 = pd.DataFrame([[1.40, 1], [7.10, 2], [3.12, 4.25], [0.75, -1.3]], index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'one\',\'two\'])df2 = pd.DataFrame([[1.40, 1], [7.10, 2], [3.12, 4.25], [0.75, -1.3]], index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'three\',\'two\'])print(df1.corrwith(df2)) # 相同列名之间计算相关系数,只有一方存在的列返回空# 传入参数 axis = \'columns\'即可按行进行计算 # 注意计算行与行的相关系数时,列名必须全部相同df1 = pd.DataFrame([[1.40, 1], [7.10, 2], [3.12, 4.25], [0.75, -1.3]], index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'one\',\'two\'])df2 = pd.DataFrame([[1.40, 1], [7.10, 2], [3.12, 4.25], [0.75, -1.3]], index = [\'a\', \'b\', \'c\', \'d\'], columns=[\'one\',\'two\'])print(df1.corrwith(df2, axis = \'columns\')) pdobj.rank()排名
pdobj.rank(method = \"average\")
pdobj.rank(method = \"min\")
pdobj.rank(method = \"average\")
pdobj.rank(method = \"first\")
pdobj.rank(method = \"dense\")
排名解释
默认情况下,按升序排名,也就是值越小排名越低。
A 是第 4 名,B,C,D 同为第 5 名,E 为第 8 名
average:BCD 三人的平均排名都是(5+6+7)/2 = 6
min:BCD的最小排名取5
max:BCD的最大排名取7
first:值相同时,按出现顺序排名
dense:相同值的类型为同一个整数排名,不同值之间的排名步长为 1
obj = pd.Series([7, -5, 7, 4, 2, 0, 4], index = list(\'ABCDEFG\'))print(obj.rank()) # 默认按升序 and 平均排名排序print(obj.rank(ascending = True, method = \'average\'))print(obj.rank(method = \'first\'))print(obj.rank(ascending = False)) # 按降序 and 默认的平均排名排序# dataframe 的排名frame = pd.DataFrame({\'b\': [4.3, 7, -3, 2], \'a\': [0, 1, 0, 1], \'c\': [-2, 5, 8, -2.5]})print(frame)print(frame.rank()) # 默认行与行之间进行排名print(frame.rank(axis = \'columns\')) # 按列之间进行排名pdobj.isin(vip)
# 判断值是否具有成员资格obj = pd.Series([\'c\', \'a\', \'d\', \'a\', \'a\', \'b\', \'b\', \'c\', \'c\'])vip = [\'b\', \'c\', \'e\']result = obj.isin(vip)print(result)pdobj.unique()
# 获取唯一值obj = pd.Series([\'c\', \'a\', \'d\', \'a\', \'a\', \'b\', \'b\', \'c\', \'c\'])newUnique = obj.unique()print(newUnique)pd.value_counts()
# 统计频率obj = pd.Series([\'c\', \'a\', \'d\', \'a\', \'a\', \'b\', \'b\', \'c\', \'c\'])print( pd.value_counts(obj.values, sort=False) ) # 默认是要排降序的pdIndex.get_indexer()
# 判断一个 Series 中的 index 在另一个 Series 的 index 中的默认索引位置y = pd.Series([\'c\', \'a\', \'b\', \'b\', \'c\', \'a\',\'xxxx\'])x = pd.Series([\'c\', \'b\' ,\'a\'])print(pd.Index(x).get_indexer(y)) # 不存在的返回-1 # [ 0 2 1 1 0 2 -1](9)函数映射
1.np 的函数可以用于 pd 对象:操作元素
frame = pd.DataFrame(np.random.randn(4, 3),columns=list(\'bde\'),index=[\'Utah\', \'Ohio\', \'Texas\', \'Oregon\'])print(frame)print(np.abs(frame)) 2.dataframe.apply(func):操作df每一行或者列
对每一行或者每一列进行操作
import numpy as npimport pandas as pdframe = pd.DataFrame(np.random.randn(4, 3),columns=list(\'bde\'),index=[\'Utah\', \'Ohio\', \'Texas\', \'Oregon\'])print(frame)# b d e# Utah -0.625087 -0.836672 0.489147# Ohio 1.630943 0.759868 1.790182# Texas 0.039539 -0.231303 0.114784# Oregon 0.777801 0.408354 1.031780f = lambda x: x.max() - x.min()print(frame.apply(f))print(frame.apply(func = f))print(frame.apply(func = lambda x : x.max() - x.min())) # 默认是 axis = 0,axis = index# b 2.256031# d 1.596540# e 1.675399# dtype: float64print(frame.apply(func = f, axis = 1)) print(frame.apply(func = f, axis = \'columns\'))# Utah 1.325820# Ohio 1.030315# Texas 0.346086# Oregon 0.623426# dtype: float64def g(x): return pd.Series([x.max(), x.min(), x.max() - x.min()], index = [\'max\', \'min\', \'max - min\']) print(frame.apply(g))# b d e# max 1.630943 0.759868 1.790182# min -0.625087 -0.836672 0.114784# max - min 2.256031 1.596540 1.675399df.apply与统计函数的结合
import pandas as pddata = pd.DataFrame({\'Qu1\': [1, 3, 4, 3, 4], \'Qu2\': [2, 3, 1, 2, 3], \'Qu3\': [1, 5, 2, 4, 4]}, index = list(\'abcde\'))print(data)print(data.apply(pd.value_counts))print(data.apply(pd.value_counts, axis = 1))3.dataframe.applymap(func):操作df每个元素
frame = pd.DataFrame(np.random.randn(4, 3),columns=list(\'bde\'),index=[\'Utah\', \'Ohio\', \'Texas\', \'Oregon\'])print(frame)# b d e# Utah 0.204463 0.823870 -1.583584# Ohio -1.433623 -0.688780 -0.987990# Texas -0.445880 0.862802 1.108125# Oregon -0.632052 0.227178 -2.174199g = lambda x: format(x, \".2f\")print(frame.applymap(g))# b d e# Utah 0.20 0.82 -1.58# Ohio -1.43 -0.69 -0.99# Texas -0.45 0.86 1.11# Oregon -0.63 0.23 -2.174.Series.map(func):操作series每个元素
import maths = pd.Series(np.arange(5), index = list(\'abcde\'))print(s)# a 0# b 1# c 2# d 3# e 4# dtype: int32g = lambda x: format(math.sin(x) + math.cos(x), \'.2f\')print(s.map(g))# a 1.00# b 1.38# c 0.49# d -0.85# e -1.41# dtype: object(10)pandas数据规整
见:Pandas数据规整-CSDN博客
end

