Spring AI 利用 MCP 让AI实现联网搜索(webflux方式实现)_spring-ai-starter-mcp-server-webflux
前言
MCP 是一个开放协议,它为应用程序向 LLM 提供上下文的方式进行了标准化。你可以将 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 为设备连接各种外设和配件提供了标准化的方式一样,MCP 为 AI 模型连接各种数据源和工具提供了标准化的接口。
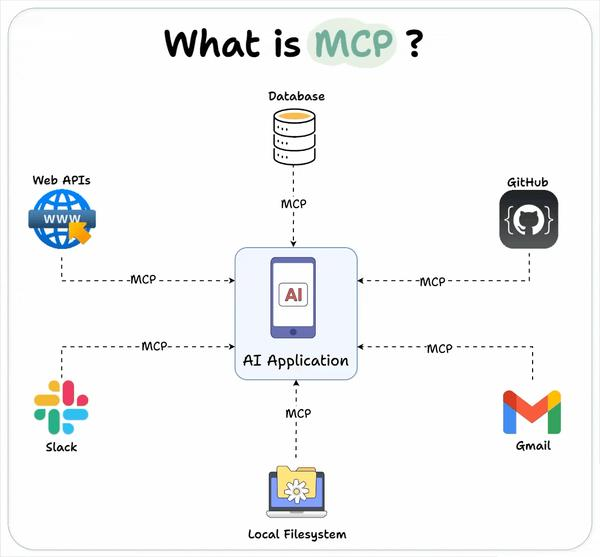
Spring AI 不断的与时俱进,也支持了MCP协议,这使得我们这些普通程序员也能够快速搭建和引入MCP服务。
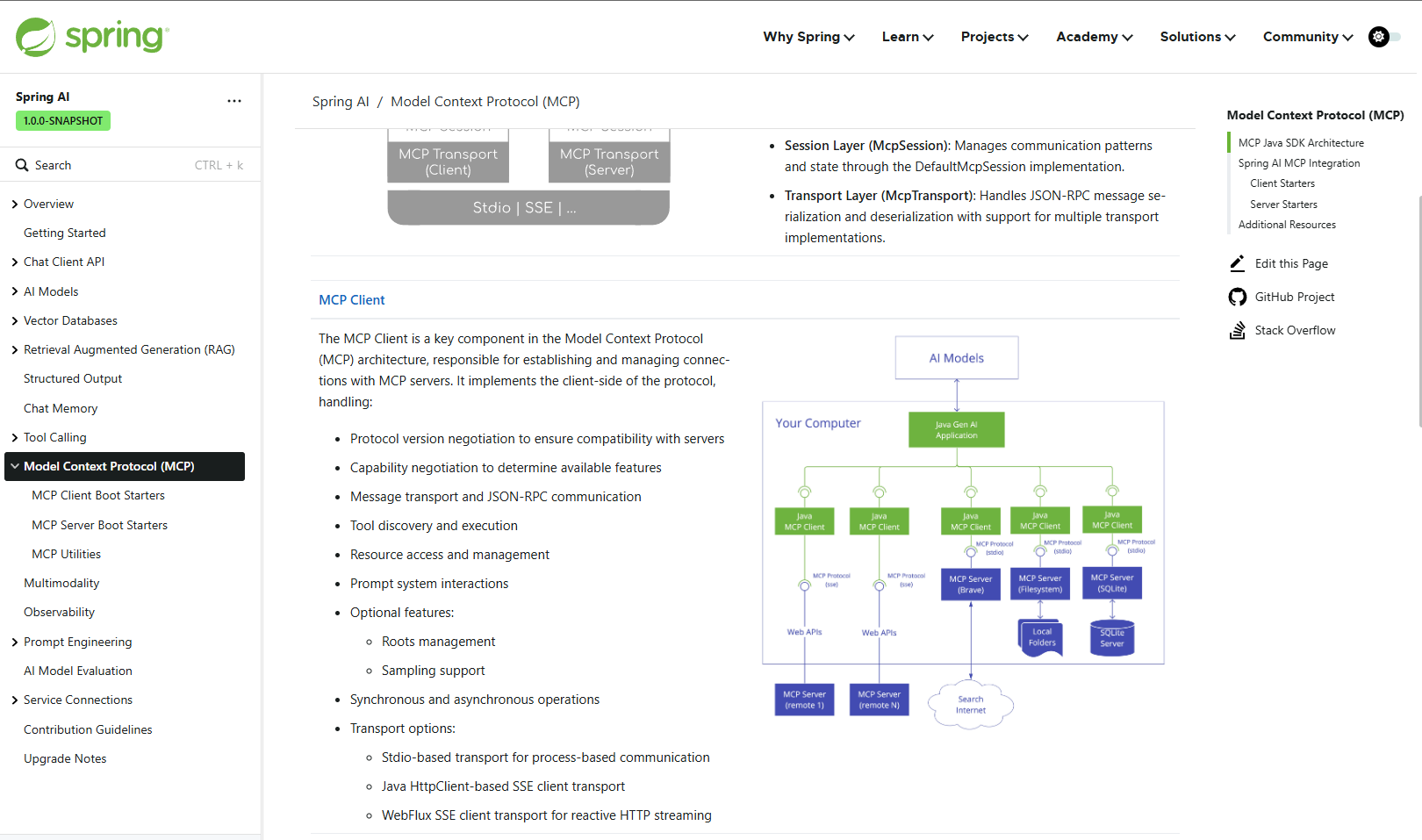
Spring AI 集成 MCP的几种方式
可以通过引入一些依赖,直接让 Spring AI 和 MCP 进行集成,在 Spring Boot 项目中轻松使用。下面是实现的几种方式:
(1)客户端启动器
-
spring-ai-starter-mcp-client:核心启动器,提供 STDIO 和基于 HTTP 的 SSE 支持
-
spring-ai-starter-mcp-client-webflux:基于 WebFlux 的 SSE 流式传输实现
(2)服务器启动器
-
spring-ai-starter-mcp-server:核心服务器,具有 STDIO 传输支持
-
spring-ai-starter-mcp-server-webmvc:基于 Spring MVC 的 SSE 流式传输实现
-
spring-ai-starter-mcp-server-webflux:基于 WebFlux 的 SSE 流式传输实现
本文所采用的是webflux,因为这种方式后续部署和维护最方便。
服务端
1. 引入依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-mcp-server-webflux-spring-boot-starter</artifactId> <version>1.0.0-M6</version> </dependency><dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.12.0</version> </dependency> 2. 配置文件
server: port: 8090 spring: application: name: mcp-server ai: mcp: server: name: mcp-server # MCP服务器名称 version: 0.0.1 # 服务器版本号3. 代码
McpServerApplication.java
@SpringBootApplication public class McpServerApplication { public static void main(String[] args) { SpringApplication.run(McpServerApplication.class, args); } @Bean public ToolCallbackProvider serverTools(MCPService MCPService) { return MethodToolCallbackProvider.builder().toolObjects(MCPService).build(); } }MCPService.java
/** * 使用Tavily进行AI搜索 * @param query 搜索关键词 * @param maxResults 最大返回结果数 * @return JSON格式的搜索结果(失败时返回错误信息) */ @Tool(name = \"tavilySearch\", description = \"执行AI驱动的互联网搜索\") public String tavilySearch( @ToolParam(description = \"搜索关键词\", required = true) String query, @ToolParam(description = \"最大返回结果数\") int maxResults ) { try { TavilySearch tavilySearch = new TavilySearch(); List<Map<String, String>> results = tavilySearch.tavilySearch(query, maxResults); log.debug(\"Tavily search completed for query: {}, results: {}\", query, results.size()); return new ObjectMapper().writeValueAsString(results); } catch (Exception e) { log.error(\"Tavily search failed for query: {}\", query, e); return \"{\\\"error\\\":\\\"Search failed: \" + e.getMessage() + \"\\\"}\"; } }TavilySearch.java
// 搜索引擎 private String baseUrl = \"https://api.tavily.com/search\"; // apikey private String apiKey = \"tvly-XXX\"; //Tavily的apikey需要替换为自己的 private final OkHttpClient client; private final ObjectMapper objectMapper; public TavilySearch() { this.client = new OkHttpClient.Builder() .connectTimeout(30, TimeUnit.SECONDS) .readTimeout(30, TimeUnit.SECONDS) .build(); this.objectMapper = new ObjectMapper(); } public List<Map<String, String>> tavilySearch(String query, int maxResults) { List<Map<String, String>> results = new ArrayList<>(); try { Map<String,Object> requestBody = new HashMap<>(); requestBody.put(\"query\", query); // requestBody.put(\"search_depth\", searchDepth); requestBody.put(\"max_results\", maxResults); // requestBody.put(\"time_range\", timeRange); Request request = new Request.Builder().url(baseUrl).post(RequestBody.create(MediaType.parse(\"application/json\"), objectMapper.writeValueAsString(requestBody))).header(\"Content-Type\", \"application/json\").header(\"Authorization\", \"Bearer\" + apiKey).build(); try (Response response = client.newCall(request).execute()) { if (!response.isSuccessful()) throw new IOException(\"请求失败: \" + response); JsonNode jsonNode = objectMapper.readTree(response.body().string()).get(\"results\"); if (!jsonNode.isEmpty()) {jsonNode.forEach(data -> { Map<String, String> processedResult = new HashMap<>(); processedResult.put(\"title\", data.get(\"title\").toString()); processedResult.put(\"url\", data.get(\"url\").toString()); processedResult.put(\"content\", data.get(\"content\").toString()); results.add(processedResult);}); } } } catch (Exception e) { System.err.println(\"搜索时发生错误: \" + e.getMessage()); } return results; }这里Tavily的apikey需要替换为自己的,申请地址:
https://tavily.com/
客户端
1. 引入依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-mcp-client-webflux-spring-boot-starter</artifactId> <version>1.0.0-M6</version> </dependency>2. 配置文件
spring:ai: mcp: client: enabled: true name: mcp-client version: 1.0.0 request-timeout: 120s type: ASYNC # 类型同步或者异步 sse: connections: server1: url: http://localhost:80903. 代码
@RestController @RequestMapping(\"/mcp\") @Tag(name = \"MCP\") @Slf4j public class MCPController { @Autowired private ChatClient chatClient; @PostMapping(value = \"/client\", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux<String> client(String message) { log.info(\"正在连接MCP服务器: {}\", mcpServerUrl); var transport = new WebFluxSseClientTransport(WebClient.builder().baseUrl(mcpServerUrl)); return Flux.using( () -> McpClient.sync(transport).build(), client -> {client.initialize();try { List<McpSchema.Tool> tools = client.listTools().tools(); String name = \"tavilySearch\"; log.info(\"Available Tools = {}\", tools); McpSchema.CallToolResult mcpResult = null; //无参数调用mcp // mcpResult = client.callTool(new McpSchema.CallToolRequest(name, Map.of())); //有参数调用mcp mcpResult = client.callTool(new McpSchema.CallToolRequest(name, Map.of(\"query\", message, \"maxResults\", 5))); String content = mcpResult.content().toString(); String mcpResultString = \"{\" + name + \" : \" + content + \"}, \"; log.info(\"最终请求信息{}\", mcpResultString + message); // 先返回MCP的结果,然后再返回chatClient的流式响应 return Flux.concat( Flux.just(mcpResultString), chatClient.prompt() .user(mcpResultString + message) .stream() .content() );} catch (Exception e) { log.error(\"MCP调用出错: \", e); return Flux.error(new RuntimeException(\"MCP调用出错: \" + e.getMessage()));} } ); } }测试
由结果图可以看到大模型回答前都会先调用mcp的联网搜索然后再回答,这样就解决大模型语料库落后的问题了。
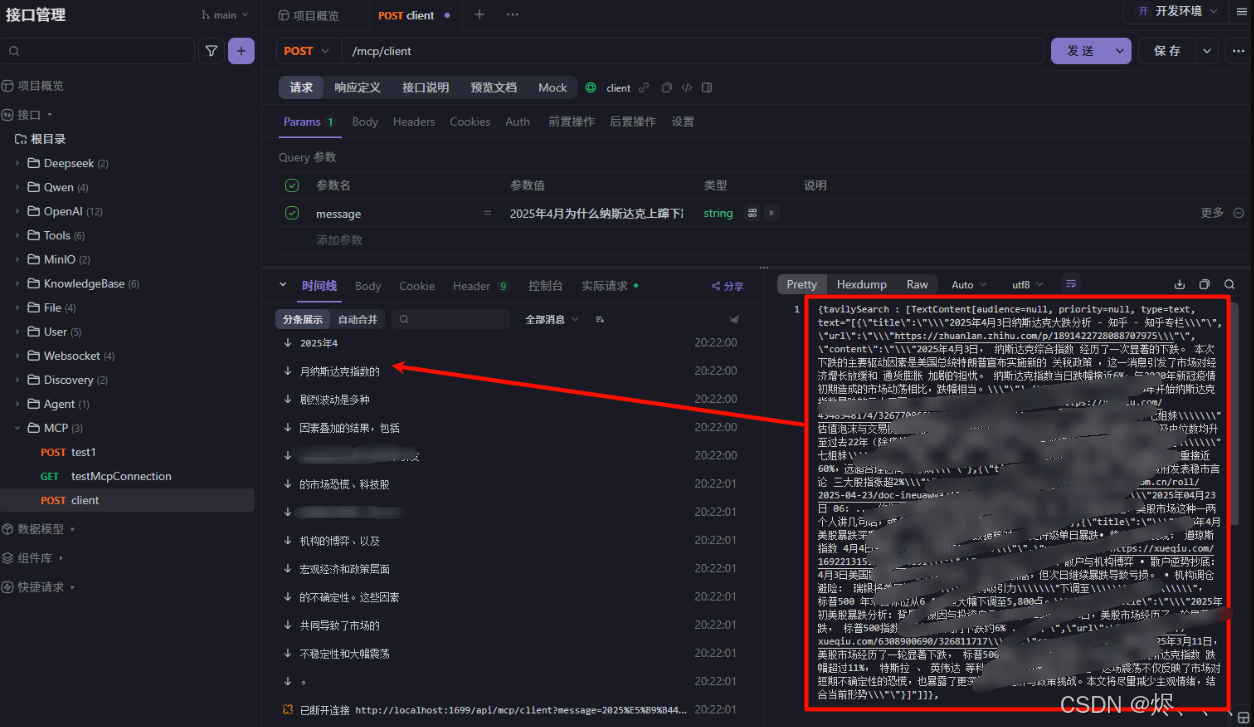
下面是实际应用的项目:
https://yiyongai.cn/

