开源深度学习优化框架DeepSpeed使用指南
DeepSpeed 是由微软开发的开源深度学习优化框架,专为超大规模模型训练与推理设计,通过显存优化、并行策略和通信加速等核心技术,显著提升训练效率并降低资源消耗。以下从核心架构、实践指南到最佳实践进行全面解析:

⚙️ 一、核心架构与技术亮点
-
ZeRO 显存优化
- 分阶段策略:
- ZeRO-1:优化器状态分片(显存降为 1/4)
- ZeRO-2:梯度+优化器分片(显存降为 1/8)
- ZeRO-3:参数+梯度+优化器全分片(支持万亿参数训练)
- 扩展技术:
- ZeRO-Offload:将优化器状态卸载至 CPU/NVMe,单卡 V100 可训练 130 亿参数模型
- ZeRO-Infinity:支持 NVMe 硬盘扩展,突破 GPU 显存墙

- 分阶段策略:
-
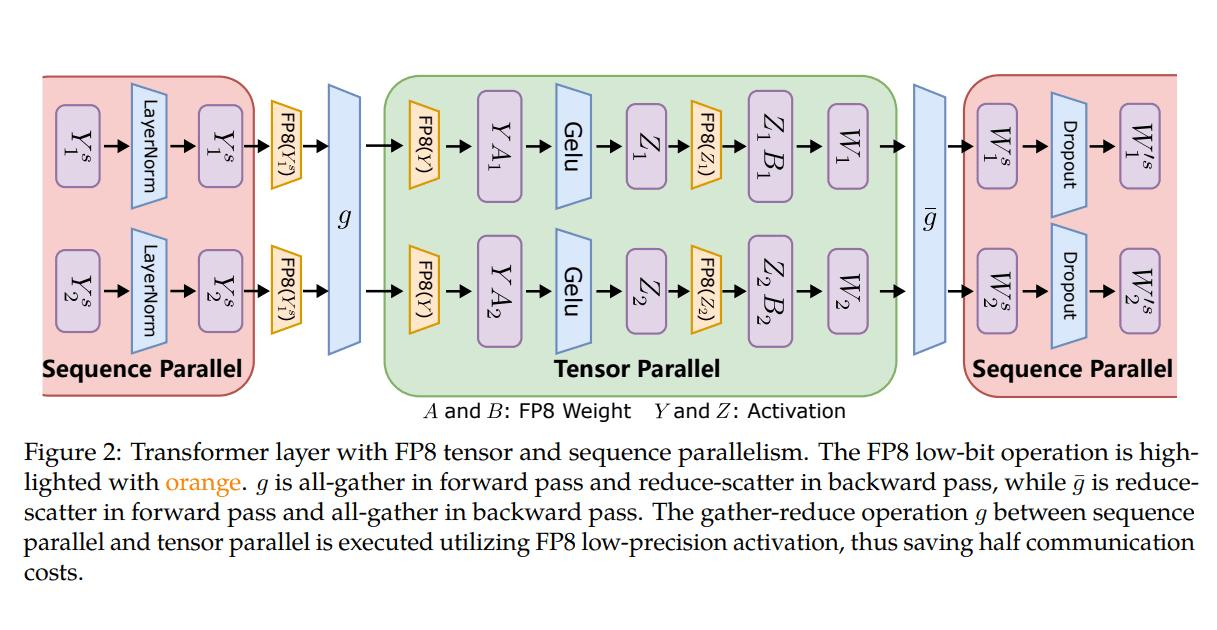
3D 并行策略
并行类型 作用 适用场景 数据并行(DP) 拆分数据至多 GPU 常规分布式训练 流水线并行(PP) 模型按层切分到不同设备 超长模型(如 Transformer) 张量并行(TP) 单层参数切片至多 GPU 大矩阵运算优化 💡 三者叠加可实现 万亿级模型训练(如 GPT-3),通信效率提升 2-7 倍
-
计算与通信优化
- 混合精度训练:FP16/BF16 自动切换,显存减半,速度提升 30%
- 1-bit Adam:梯度压缩至 1 比特,通信量减少 5 倍,训练提速 3.5 倍
- 稀疏注意力:长序列处理速度提升 6 倍(如文本/图像任务)
🛠️ 二、安装与基础使用
1. 环境部署
# 创建虚拟环境conda create -n ds_env python=3.10conda activate ds_env# 安装 DeepSpeed 及依赖pip install deepspeed[all] # 包含 MPI、NCCL 等扩展2. 训练脚本改造(以 Hugging Face 为例)
import deepspeed# 初始化 DeepSpeed 引擎model_engine, optimizer, _, _ = deepspeed.initialize( model=model, # PyTorch 模型 optimizer=optimizer, # 优化器(如 Adam) config=\"ds_config.json\", # 配置文件 model_parameters=model.parameters())# 训练循环改造for batch in dataloader: loss = model_engine(batch) model_engine.backward(loss) # DeepSpeed 托管反向传播 model_engine.step() # 梯度更新3. 配置文件详解(ds_config.json)
{ \"train_batch_size\": 32, // 全局 batch size \"train_micro_batch_size_per_gpu\": 4, // 单 GPU batch size \"gradient_accumulation_steps\": 8, // 梯度累积步数 \"zero_optimization\": { // ZeRO 配置 \"stage\": 3, // ZeRO-3 全分片 \"offload_optimizer\": {\"device\": \"cpu\"} // 卸载至 CPU }, \"fp16\": {\"enabled\": true}, // 混合精度训练 \"activation_checkpointing\": { // 激活值重计算 \"partition_activations\": true, \"contiguous_memory_optimization\": true }}✅ 关键参数:
stage:ZeRO 阶段(1/2/3 按需选择)offload_optimizer:CPU 卸载省显存,但增加延迟activation_checkpointing:牺牲 20% 速度换 50% 显存节省
🚀 三、高级功能与配置
1. 多机多卡训练
- 步骤:
- 配置 SSH 免密登录节点间通信
- 编写
hostfile定义节点与 GPU 数量:host1 slots=4 # 节点1 使用4张 GPUhost2 slots=4 - 启动命令:
deepspeed --hostfile hostfile train.py --deepspeed ds_config.json💡 DeepSpeed 自动通过 SSH 启动其他节点任务,无需手动操作
2. Hugging Face 集成
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments( output_dir=\"./results\", per_device_train_batch_size=4, deepspeed=\"ds_config.json\", # 直接集成 DeepSpeed fp16=True,)trainer = Trainer( model=model, args=training_args, train_dataset=dataset,)trainer.train()3. 推理优化
- DeepSpeed Inference:支持 Tensor 切片 + KV 缓存量化
- MoE 模型加速:结合专家并行(Expert Parallel)和动态路由,70B 模型推理延迟低至 25ms
🎯 四、最佳实践场景指南
activation_checkpointing💡 避坑提示:
- 日志问题:多 GPU 训练默认仅输出 rank 0 日志,需添加
--enable_each_rank_log独立保存- NCCL 兼容性:RTX 40 系列需设置
export NCCL_P2P_DISABLE=1避免通信失败
⚠️ 五、常见问题与解决方案
-
OOM(显存不足)
- 对策:
- 降低
train_micro_batch_size_per_gpu - 启用 ZeRO-3 +
offload_optimizer - 增加
gradient_accumulation_steps
- 降低
- 对策:
-
多节点训练启动失败
- 检查点:
- 确认 SSH 免密登录有效
- 确保所有节点 Docker/Python 环境一致
- 使用
--include指定 GPU(如localhost:0,1)
- 检查点:
-
推理吞吐量低
- 优化方案:
- 切换至 vLLM 框架(专精高并发推理)
- 启用 FP8 量化(需 H100/A100 支持)
- 优化方案:
💎 总结
- 中小规模场景:优先 Hugging Face + DeepSpeed 集成,快速实现微调
- 超大规模训练:DeepSpeed-Megatron 组合 + 3D 并行,千卡集群线性加速比 >0.9
- 国产硬件适配:昇腾 910B 已支持 ZeRO 优化,实测性能达 A100 的 85%
学习资源:
- DeepSpeed 官方 GitHub
- Hugging Face 集成文档
- 实战示例:DeepSpeed-Chat 项目(含 SFT 全流程)

