基于 Amazon Nova Sonic 和 MCP 构建语音交互 Agent_音频对话交互 组件板

文章目录
- 1、引言
- 2、关键技术概念介绍
- 3、方案介绍
-
- 3.1 技术架构:
- 3.2 方案架构实现
- 3.3 Amazon Nova Sonic 与 MCP 交互
- 3.4 核心组件和调用流程
- 4、方案部署和使用指南
-
- 4.1 方案关键技术和依赖项
- 4.2 安装步骤
- 4.3 使用指南
- 5、结论
1、引言
新福利:新用户可获得高达 200 美元的服务抵扣金。
AWS 新用户可以免费使用 AWS 免费套餐(AWS Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键 AWS 服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用 AWS 服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项 AWS 服务的访问权限。

随着人工智能技术的飞速发展,自然语言处理和语音交互技术正在深刻改变人机交互的方式。语音交互正从简单的“机械应答”向更自然的“类人对话”演进 。
传统的语音系统通常采用模块化架构,将语音处理流程割裂为 ASR(自动语音识别)、NLP(自然语言处理)和 TTS(文本转语音)等独立模块,这种管道式处理方法存在信息衰减、响应延迟和情感缺失等核心痛点 。
因此,如何实现自然的语音交互与多工具协同成为技术突破的关键。Amazon Nova Sonic 通过将语音理解和生成统一到单一模型中,提供了一种简化的解决方案,用于创建自然、类人的语音交互,与需要编排多个模型的传统方法不同 。
本文将深入探讨 Amazon Nova Sonic 基础模型与 MCP(Model Context Protocol,模型上下文协议)的结合,介绍基于 Amazon Nova Sonic 和 MCP 构建实时语音交互应用的技术实践,涵盖技术原理、实际开发部署等,为开发者提供全面的技术指南。
应用场景与行业价值:
Amazon Nova Sonic 模型凭借其低延迟、自然对话流和工具调用能力,适用于广泛的应用场景:
1. 车载智能座舱
Amazon Nova Sonic 模型凭借其在自然度、实时性、上下文感知和工具调用等方面的优势,为构建新一代智能座舱提供了强大的技术支撑,使得车载语音助手不再是简单的指令执行工具,而是能够与用户进行自然、高效、个性化交互的智能伙伴,极大地提升了驾驶的安全性和乐趣。
2. 企业客服与电销自动化
在客户服务领域,Amazon Nova Sonic 可自动处理咨询、退货、订单查询等高频需求,支持与 CRM 系统集成实时调取用户数据。
3. 教育与语言学习
作为智能语言教练,Amazon Nova Sonic 模型可以提供实时发音纠正与场景化对话练习。
4. 医疗与健康管理
支持医生通过语音快速录入病历,或为患者提供症状自检指导。在远程问诊中,模型可识别患者咳嗽声等生理信号,结合电子健康档案生成初步诊断建议。
2、关键技术概念介绍
2.1 Amazon Nova Sonic:语音交互的颠覆性模型
Amazon Nova Sonic 通过单一模型架构实现语音理解与生成的端到端处理,解决了传统多模型拼接的延迟与信息丢失问题。其核心优势包括:
1. 端到端一体化模型
Amazon Nova Sonic 摒弃传统级联式语音系统的模块化设计,将语音输入到输出的全流程统一在单一神经网络中完成。这种设计消除了不同模块间的信息割裂,保留对话中的声学语境(如语气、节奏、停顿),显著提升交互连贯性。
2. 实时双向流式交互
通过 Amazon Bedrock 提供的双向流式 API(InvokeModelWithBidirectionalStream),模型支持用户与 AI 同时进行语音输入输出,平均响应时间仅 1.09秒(优于 GPT-4o 的 1.18 秒),且支持用户中途打断对话而不丢失上下文。技术实现上,采用 5:15 的文本-语音标记混合生成比例,确保语义连贯性与实时性平衡。
3. 多语言与噪声鲁棒性
支持英语(美式/英式)多语言交互,在多语言 LibriSpeech 基准测试中平均词错误率(WER)低至 4.2%,在嘈杂环境(如多人对话)下错误率比 GPT-4o Transcribe 低 46.7%。模型能识别主说话人并过滤背景噪声,适用于工厂、户外等复杂场景。
4. 情感感知与动态调节
模型可解析用户语音中的情绪(如兴奋、愤怒、担忧),并动态调整回应风格。例如,当客服对话中用户语气转为焦虑时,Nova Sonic 会降低语速、增加安抚性词汇,同时触发企业数据库查询相关解决方案。
2.2 MCP:实时语音交互中的大模型&智能体工具标准化连接
MCP 作为开放协议,为端到端语音模型或者相关智能体提供了工具发现、安全调用与数据融合的标准化框架。在实时语音对话场景下,其价值更为突出:
虚拟化工具网关:通过 MCP Gateway 统一管理分散的 API 服务,解决工具碎片化问题。
动态上下文注入:在语音交互中自动关联企业数据,通过 RAG 增强生成结果的事实准确性。这对 speech-to-speech 模型尤为重要,因为用户在实时对话中需要准确、及时的信息响应,而不是模型生成的模糊答复。
实时性能优化:MCP 的标准化调用机制能够显著降低工具调用延迟,这在实时语音对话中至关重要,可以保持对话的自然流畅性,避免因等待外部数据而产生的停顿。
3、方案介绍
接下来我们将详细介绍基于 Nova Sonic 和 MCP 的语音交互方案实现,方案实现了双向音频流、通过 MCP 的工具集成以及响应式 Web 界面。方案实时音频对话系统的总体架构分为前端和后端两大部分,采用 WebSocket 实现实时通信。该方案基于以下主要技术构建:
- 运行环境 :Node.js (v18.0.0+) with TypeScript
- Web 框架 :Node.js 用于 HTTP/WebSocket 服务器
- 实时通信 :IO 用于双向 WebSocket 连接
- 音频处理 :用于基于浏览器的音频捕获/播放的 WebAudio API
- AI 集成 :适用于 Amazon Bedrock Runtime 客户端的 AWS 开发工具包
- 工具集成 :模型上下文协议 SDK (@modelcontextprotocol/sdk)
具有以下关键组件:
- 处理 WebSocket 连接并与 Amazon Bedrock 集成的 Node.js/Express 服务器
- 用于实时音频可视化和交互的现代 Web 界面
- 用于自然对话流程的双向音频流
- 支持中断检测和即时处理
- 通过模型 MCP 与外部工具集成
- 支持多种语音角色和多语言界面
3.1 技术架构:
本方案实现了一个基于 WebSocket 的双向音频流应用,与 Amazon Nova Sonic 模型集成,用于实时语音转语音对话。
系统采用现代 Web 技术栈构建,支持双向实时音频流、多语言界面以及动态工具调用。以下是基于您提供的内容生成的架构图,展示了一个使用 Amazon Nova Sonic 模型的语音交互系统:
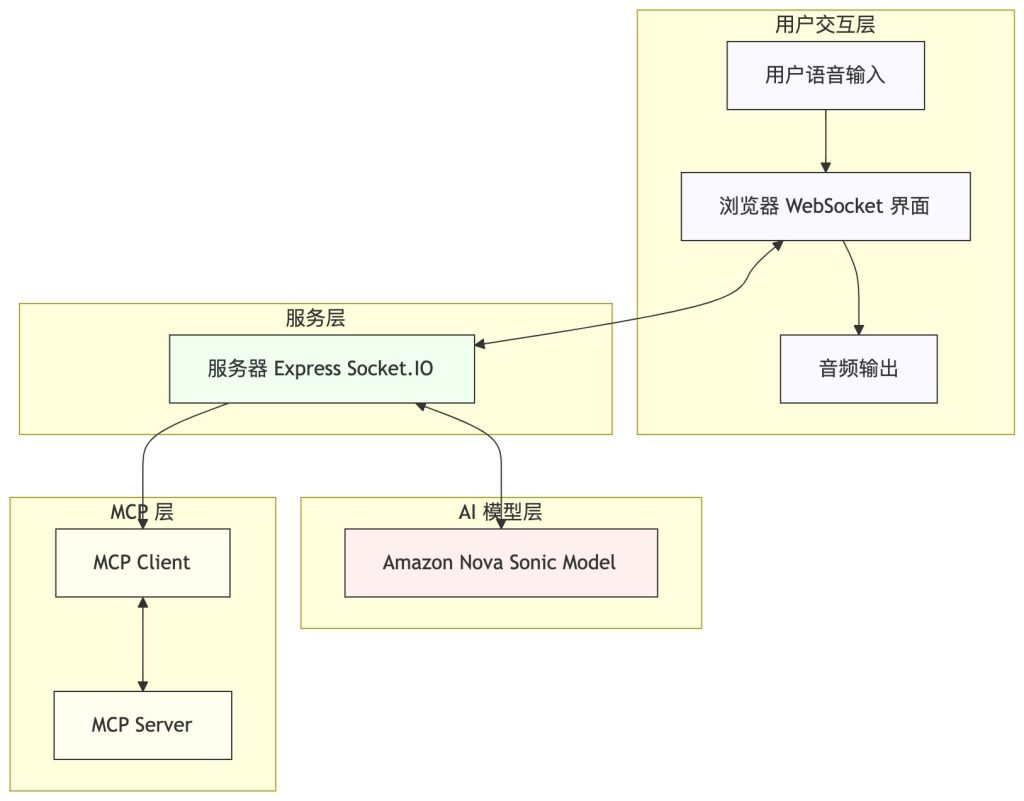
上图系统架构展示了一个完整的语音交互流程
客户端:
- 用户通过麦克风提供语音输入
- 浏览器使用 WebSocket 技术处理实时通信
- 系统将响应转换为音频并通过扬声器输出
服务器:
- 使用 Express 框架构建的后端服务
- 集成 Socket.IO 实现双向实时通信
大模型服务:
- 利用 Amazon Nova Sonic 模型进行语音处理
- 负责语音识别、理解和生成响应
- 负责处理用户中断及响应
- 负责对接 MCP tools 进行工具调用
3.2 方案架构实现
音频处理
音频处理管道通过基于 WebSocket 的流式处理架构实现与 AI 的双向实时语音转语音对话,主要由四个主要阶段组成:
- Audio Capture – 客户端麦克风输入和预处理
- 实时流式处理 – 基于 WebSocket 的双向音频传输
- 服务器处理 – Amazon Nova Sonic 语音转语音模型处理
- Audio Playback – 具有可视化功能的客户端缓冲音频输出
用户的语音输入经由浏览器 WebSocket 发送到服务器,服务器与 Amazon Nova Sonic 模型交互后,将结果返回给浏览器,最终转换为音频输出给用户。
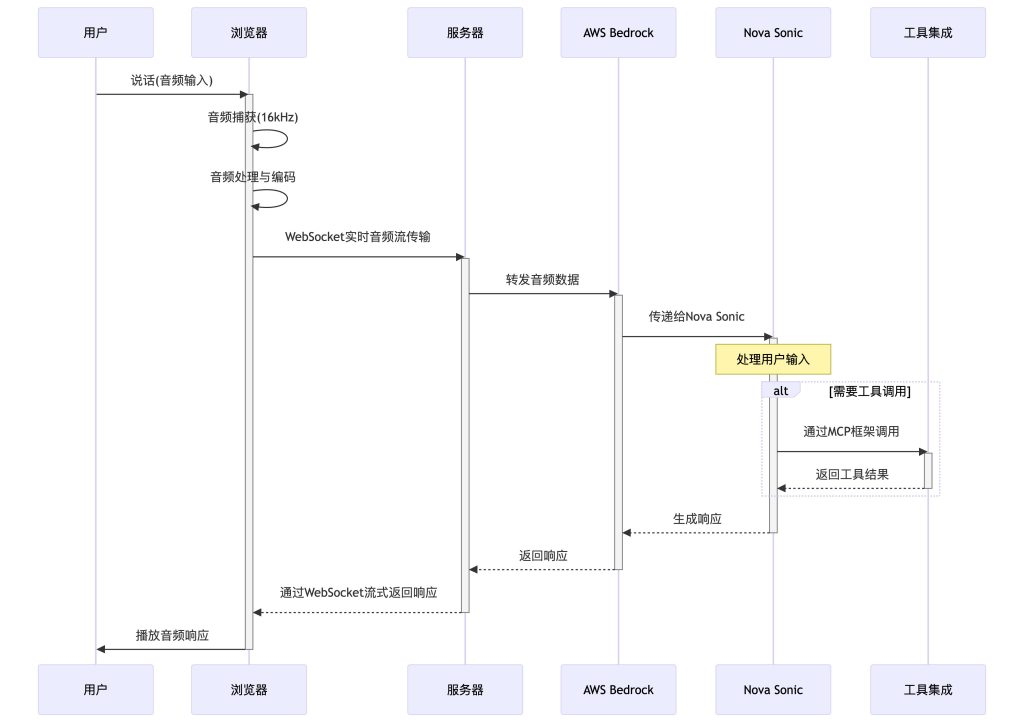
- 音频捕获:浏览器以 16kHz 采样率从用户麦克风捕获音频
- 音频处理:对音频进行处理、分析和编码以便传输
- WebSocket 传输:音频数据实时流式传输到服务器
- Amazon Nova Sonic 处理:服务器通过 - Amazon Bedrock 将音频转发到 Amazon Nova Sonic
- 响应生成:Amazon Nova Sonic 处理输入并生成响应
- 工具集成:如果需要,通过 MCP 框架调用工具
- 音频播放:响应流回客户端并播放给用户
接收和处理 Tool 事件
Nova Sonic 可以支持 Function Call 具备调用外部工具的能力,首先定义函数描述 Schema,将用户输入和函数描述一起输入调用 LLM,解析 LLM 的输出,如果有输出函数名和参数则执行该函数,再将函数结果反馈给 LLM,实现下一轮调用,直至输出最终结果。
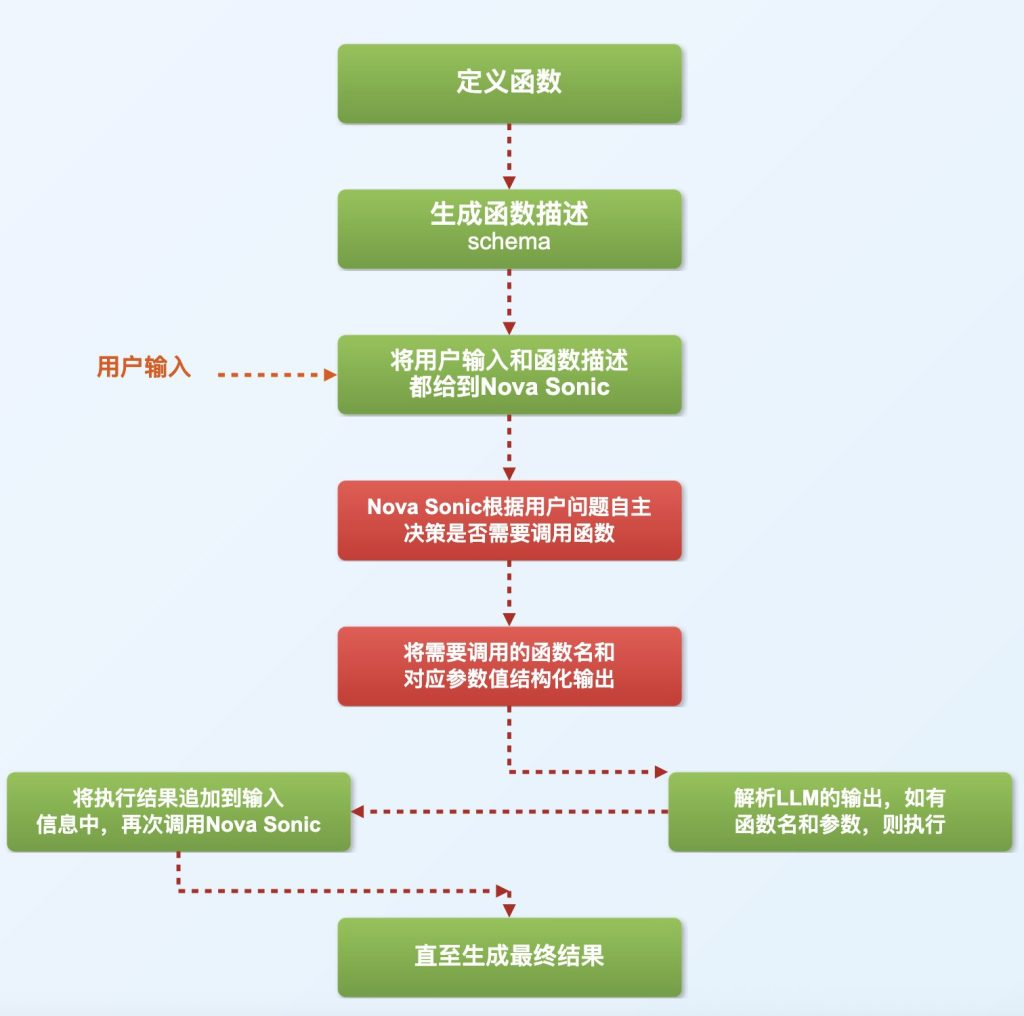
在整个对话过程中,如果用户输入与 ToolConfiguration 中的工具规格之一匹配,Nova Sonic 将触发 ToolUse 事件。例如,如果用户问“今天天气怎么样?”,如下图所示,在收到用户 ASR(脚本)事件后,Sonic 将发送一个 ToolUse 事件,其中包含配置中指定的 toolName getWeatherTool。
3.3 Amazon Nova Sonic 与 MCP 交互
Amazon Nova Sonic 要实现 MCP 这种方式的工具调用,首先需要将函数/工具的描述信息 schema 输入给 LLM,只不过 Function Call 是在本地生成函数描述的,而 MCP 则是远程从 MCP Server 中自动拉取的工具描述。
远程 MCP Server 端有哪些工具的描述,是基于 Server 端工具在开发时用注解的方式描述函数名、用途和参数信息来自动生成的。
和 Function Call 机制一样,Sonic 识别需要调用哪个 MCP 工具,并将要调用的工具名、参数以 json 格式结构化文本输出,然后是由 LLM 所在的 Host 去调用。
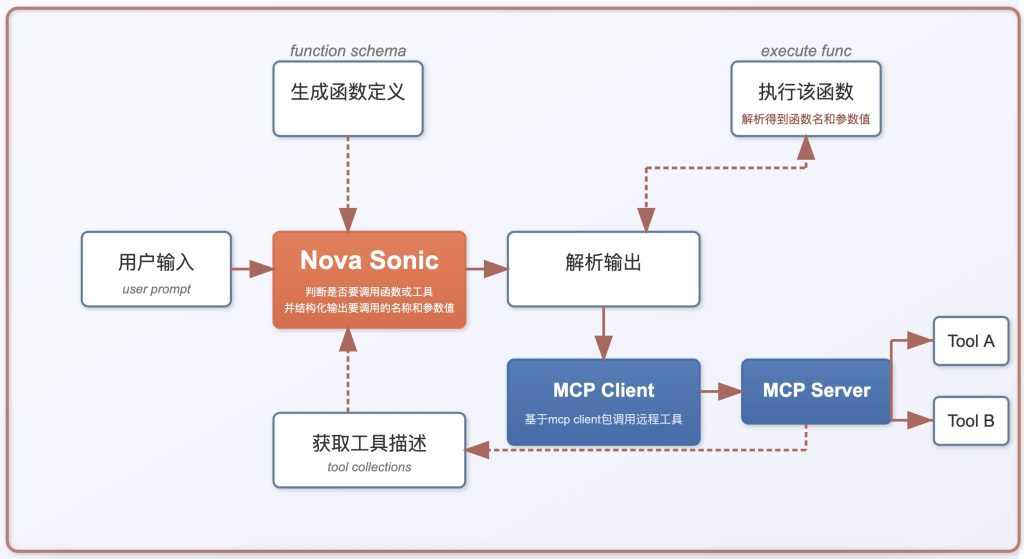
与 Amazon Bedrock 上其他 Nova/Claude 模型类似,我们可以在调用模型推理时,传递 tools configure 配置信息,从而触发模型 function Calling,与第三方系统或者工具集成。
在与 Amazon Nova Sonic 启动新会话时,您可以在发送到 Sonic PromptStart 的第二个事件中提供 Tool 配置,该 Tool 配置是通过 MCP Client 的 list Tools 等 SDK,从 MCP Server 端获取的 tools 工具 schema,包含调用 stdio endpoint command path/arguments,或者 Streamable Http endpoint 的 base_url、headers 等 schema 信息。
Sonic 模型 tools 参数获取该信息后,即可像 Amazon Bedrock 上其他 LLM 一样进行 function calling。
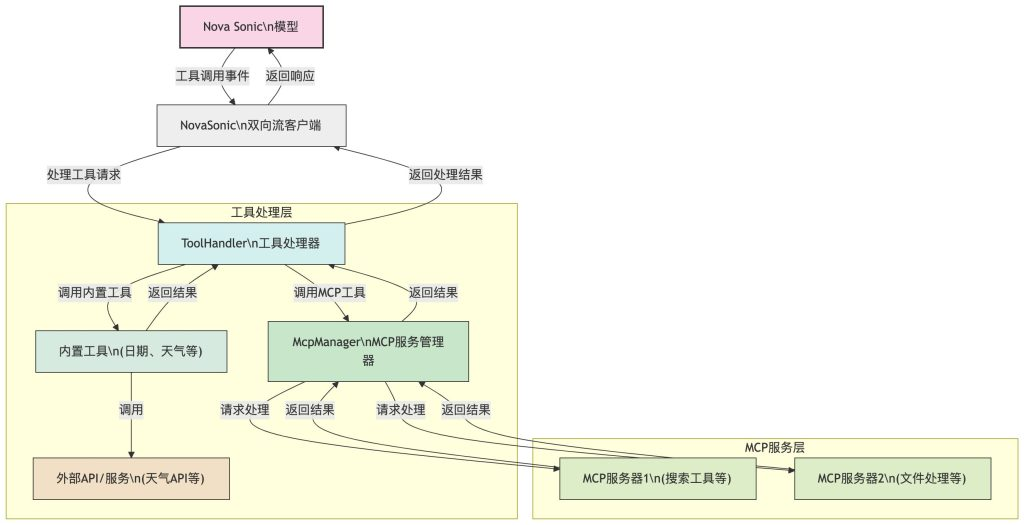
- Amazon Nova Sonic 模型:模型能够识别并发起工具调用事件。
- 双向流客户端:接收模型的工具调用事件,并负责与工具处理器进行通信。
- 工具处理器(ToolHandler):负责分发和处理。
- 工具请求,是系统的中央协调器。它可以:调用内置工具;将请求转发给 MCP 服务管理器。
- 内置工具:系统自带的基础工具,如日期查询、天气查询等,可能需要调用外部 API 获取数据。
- MCP 服务管理器:管理和协调多个 MCP 服务器,负责将请求路由到适当的服务器并收集结果。
- MCP 服务器:提供专门的功能服务,如搜索工具(服务器 1)和文件处理(服务器 2)等。
3.4 核心组件和调用流程
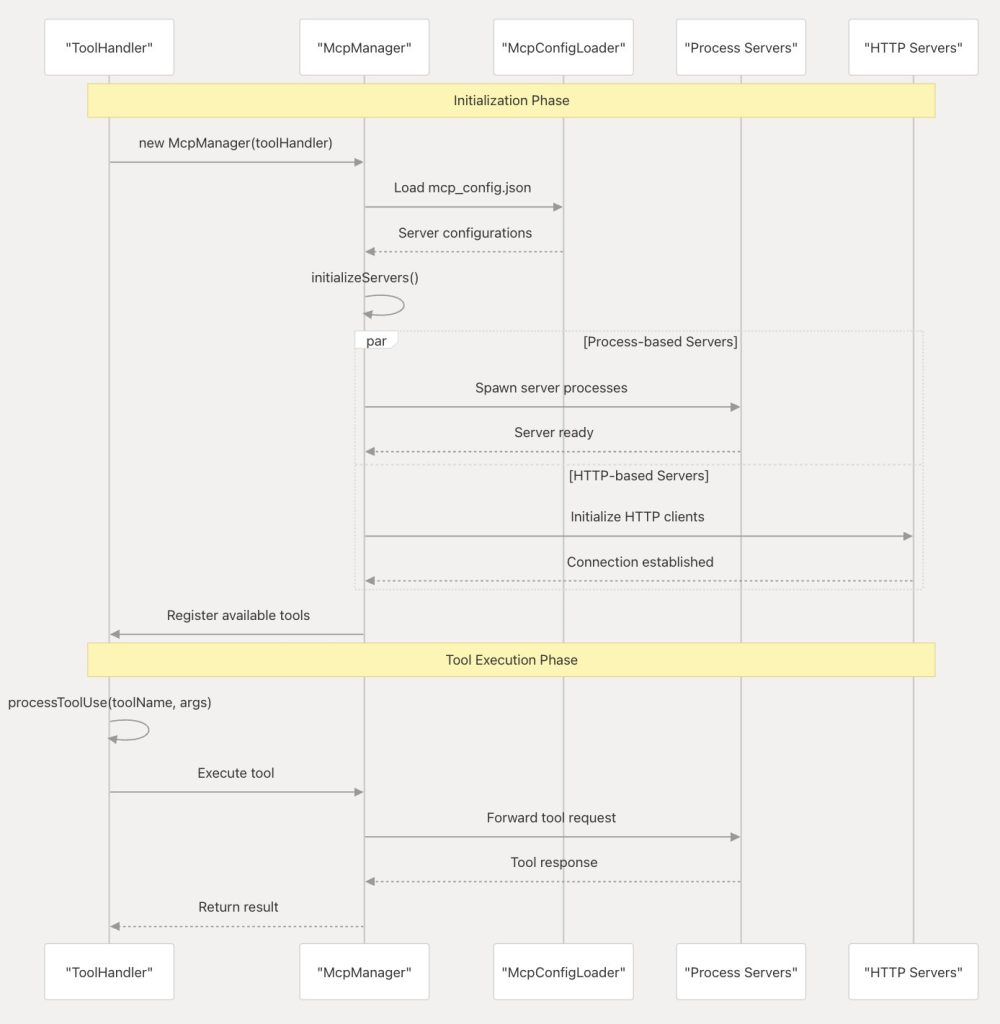
MCP 集成由三个主要组件组成,它们协同工作,为 AI 提供工具功能:
- McpManager:管理 MCP 服务器进程的生命周期
- ToolHandler:编排工具执行并管理已注册的工具
- McpConfigLoader:加载和验证服务器配置
工具处理器 (ToolHandler)
ToolHandler 充当工具注册和执行的中央业务流程协调程序。它维护来自所有连接的 MCP 服务器的可用工具的注册表负责:
- 注册 MCP 工具
- 处理工具调用请求
- 执行工具逻辑
- 返回结果
// 工具处理流程public async processToolUse(toolName: string, toolUseContent: object): Promise { // 1. 检查是否是MCP工具 if (this.mcpTools.has(toolName)) { const toolInfo = this.mcpTools.get(toolName); // 2. 调用对应工具的处理函数 return await toolInfo.handler(toolUseContent); } // 3. 处理内置工具 switch (tool) { case \"getdateandtimetool\": return this.getDateAndTime(); case \"getweathertool\": // 解析参数并调用天气API return this.fetchWeatherData(parsedContent.latitude, parsedContent.longitude); default: throw new Error(`不支持的工具 ${tool}`); }}MCP 管理器 (McpManager)
McpManager 处理 MCP 服务器从初始化到清理的整个生命周期负责:
- 加载 MCP 配置
- 连接 MCP 服务器
- 注册服务器提供的工具
- 调度工具调用
- 调度工具调用
// 连接MCP服务器并注册工具async connectToServer(serverName: string, config: McpServerConfig): Promise<McpTool[]> { // 1. 创建客户端 const client = new Client({...}); // 2. 创建传输层 const transport = new StdioClientTransport({...}); // 3. 连接服务器 await client.connect(transport); // 4. 获取工具列表 const toolsResult = await client.listTools(); // 5. 注册工具到ToolHandler this.registerServerTools(serverName, serverTools, config.autoApprove || []);}MCP Tool 调用流程
工具调用的完整流程如下:
- 配置加载
- 服务器连接
- 工具注册
- 会话初始化
- 工具调用
- 工具执行
- 结果返回
获取工具执行结果
通过 createToolResultEvents 创建结果事件,将结果发送回流。
以下是本方案获取 MCP Server 信息及加载 tools 的代码示例:
/** * 初始化所有启用的 MCP 服务器 */ async initializeServers(): Promise { const servers = Object.entries(this.config.mcpServers); console.log(`发现 ${servers.length} 个 MCP 服务器配置`); await Promise.all( servers.map(async ([serverName, serverConfig]) => { if (serverConfig.disabled !== true) { try { await this.connectToServer(serverName, serverConfig); } catch (error) { console.error(`连接到 MCP 服务器 ${serverName} 失败:`, error); } } else { console.log(`MCP 服务器 ${serverName} 已禁用,跳过连接`); } }) ); } /** * 连接到指定的 MCP 服务器 */ async connectToServer( serverName: string, config: McpServerConfig ): Promise<McpTool[]> { console.log(`正在连接 MCP 服务器: ${serverName}`); try { // 创建客户端 const client = new Client({ name: `nova-sonic-mcp-client-${serverName}`, version: \"1.0.0\", capabilities: { prompts: {}, resources: {}, tools: {}, }, }); let transport; // 根据 command 类型选择不同的 transport if (config.command === \"restful\") { // 使用 StreamableHTTPClientTransport if (!config.baseUrl) { throw new Error(\"使用 restful 模式时必须提供 baseUrl\"); } transport = new StreamableHTTPClientTransport({ baseUrl: config.baseUrl, headers: config.headers || {}, // 可选的 HTTP 头 fetch: globalThis.fetch, // 使用全局 fetch }); } else { // 使用原有的 StdioClientTransport let command = config.command; let args = [...config.args]; if (config.command === \"node\") { command = process.execPath; } transport = new StdioClientTransport({ command: command, args: args, env: { ...getDefaultEnvironment(), ...config.env, }, stderr: \"pipe\", }); transport.stderr?.on(\"data\", (data) => console.info(`[MCP] Stdio stderr for server: `, data.toString()) ); } // 连接到服务器 await client.connect(transport); // 保存客户端和传输 this.clients.set(serverName, client); this.transports.set(serverName, transport); // 获取工具列表 const toolsResult = await client.listTools(); const serverTools = toolsResult.tools.map((tool) => ({ name: tool.name, description: tool.description, inputSchema: tool.inputSchema, serverName: serverName, })); // 保存工具列表 this.tools.set(serverName, serverTools); // 注册工具到 ToolHandler this.registerServerTools( serverName, serverTools, config.autoApprove || [] ); console.log( `已连接到 MCP 服务器 ${serverName},可用工具:`, serverTools.map(({ name }) => name).join(\", \") ); return serverTools; } catch (error) { console.error(`连接到 MCP 服务器 ${serverName} 失败:`, error); throw error; } } /** * 注册服务器工具到 ToolHandler */ private registerServerTools( serverName: string, tools: McpTool[], autoApproveList: string[] ): void { tools.forEach((tool) => { // 修改: 默认所有工具都是自动批准的,不再根据 autoApproveList 判断 const isAutoApproved = true; this.toolHandler.registerMcpTool( tool.name, this.callMcpTool.bind(this, serverName, tool.name), serverName, tool.description, isAutoApproved ); }); }以下是 toolConfiguration 部分的示例 JSON,其中包括 3 个 MCP Server 的示例配置,其中 mcp-playwright 和 server-filesystem 是 stdio 的 MCP Server, searchWebsit_McpHttpServer 是 Streamable Http 的 MCP Server:
{ \"mcpServers\": { \"github.com/executeautomation/mcp-playwright\": { \"disabled\": false, \"command\": \"npx\", \"args\": [\"-y\", \"@executeautomation/playwright-mcp-server\"] }, \"github.com/modelcontextprotocol/servers/tree/main/src/filesystem\": { \"command\": \"npx\", \"args\": [ \"-y\", \"@modelcontextprotocol/server-filesystem\", \"/Users/tangqy/Documents/MCP/filesystem-server\" ], \"disabled\": false, \"autoApprove\": [] } }, \"searchWebsit_McpHttpServer\":{ \"transportType\":\"streamable_http\", \"command\":\"restful\", \"base_url\":\"http://ec2-35-93-77-218.us-west-2.compute.amazonaws.com:8080/message\", \"headers\": { } }}中断处理
Nova Sonic 模型可以有效的处理用户中断,在全双工模式下,用户语音输入是单独的流 channel,在该 channel 的 audio chunk 处理过程中,通过回调机制/输出检测(模型还在 speaking 输出)/间隔阀值…etc 等机制,确认是否用户中断请求,从而在处理 response 的另一条流 channel 中,输出中断标识,从而方便指示客户端处理并响应中断。
其代码示例如下:
socket.on(\"contentEnd\", (data) => { console.log(\"Content end received:\", data); if (data.type === \"TEXT\") { if (role === \"USER\") { // When user\'s text content ends, make sure assistant thinking is shown hideUserThinkingIndicator(); showAssistantThinkingIndicator(); } else if (role === \"ASSISTANT\") { // When assistant\'s text content ends, prepare for user input in next turn hideAssistantThinkingIndicator(); } // Handle stop reasons if (data.stopReason && data.stopReason.toUpperCase() === \"END_TURN\") { chatHistoryManager.endTurn(); } else if ( data.stopReason && data.stopReason.toUpperCase() === \"INTERRUPTED\" ) { console.log(\"Interrupted by user\"); audioPlayer.bargeIn(); } } else if (data.type === \"AUDIO\") { // When audio content ends, we may need to show user thinking indicator if (isStreaming) { showUserThinkingIndicator(); } }});4、方案部署和使用指南
4.1 方案关键技术和依赖项
方案基于以下主要技术构建:
- 运行时间 :Node.js (v18.0.0+) with TypeScript
- Web 框架 :Express.js 用于 HTTP/WebSocket 服务器
- 实时通信 :Socket.IO 用于双向 WebSocket 连接
- 音频处理 :用于基于浏览器的音频捕获/播放的 WebAudio API
- AI 集成 :适用于 Bedrock Runtime 客户端的 亚马逊云科技 开发工具包
- 工具集成 :模型上下文协议 SDK (
@modelcontextprotocol/sdk)
4.2 安装步骤
安装指南
部署 Amazon Nova Sonic 实时语音应用需要以下步骤:
先决条件
– Node.js(v18.0.0 或更高版本)
– 亚马逊云科技 账户,并启用 Amazon Bedrock 访问权限
– 已配置 Amazon CLI 和适当凭证
– 麦克风和扬声器设备
- 克隆仓库
git clone https://github.com/aws-samples/sample-nova-sonic-mcpcd sample-nova-sonic-mcp- 安装依赖
npm install - 配置 Amazon 凭证
aws configure --profile default确保配置正确的区域(如 us-east-1)和有效的访问密钥。
- 构建 TypeScript 代码
npm run build- 配置 MCP 服务器(可选)
编辑 mcp_config.json 文件,配置需要的 MCP 服务器:
{ \"mcpServers\": { \"github.com/tavily-ai/tavily-mcp\": { \"command\": \"npx\", \"args\": [\"-y\", \"tavily-mcp@0.1.4\"], \"env\": { \"TAVILY_API_KEY\": \"your-api-key\" }, \"disabled\": false, \"autoApprove\": [] } }}- 启动应用
npm start- 访问界面
在浏览器中打开 http://localhost:3000
4.3 使用指南
主界面概览
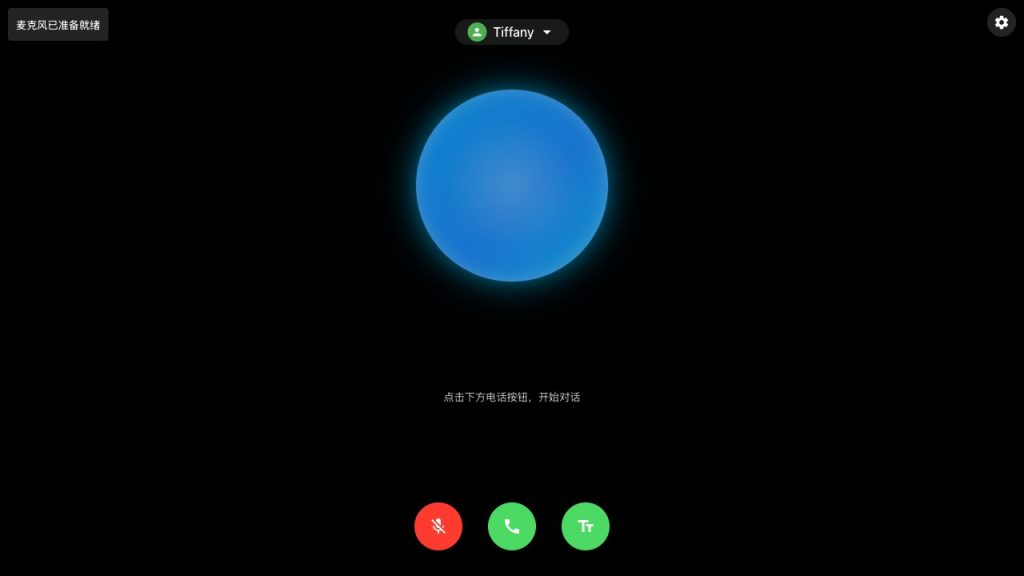
主界面包含以下主要元素:
- 连接状态指示器:左上角显示当前连接状态,如”已连接服务器”或错误信息
- 语音角色选择:顶部中央的下拉菜单,可选择不同 AI 语音角色
- 设置按钮:右上角的齿轮图标,用于打开配置面板
- 音频可视化:中央的蓝色圆形区域,显示实时音频波形和语音活动
- 控制按钮:左下角麦克风按钮:控制麦克风开启/关闭;中央通话按钮:开始/结束对话(红色表示正在对话中);右下角文本按钮:切换显示/隐藏文本对话内容
基本操作
- 开启对话:
- 语音交互:
- 结束对话:
高级功能
语音角色选择:
- 点击顶部的用户头像打开语音选择菜单
- 选择不同的语音角色(如 tiffany、matthew、amy)
- 新的语音设置将应用于下一次对话
配置系统
提示词配置:

点击右上角的设置图标打开配置面板
– 提示词:选择预设提示词或自定义提示词
– 语言:切换界面语言(中英文)
Language configuration (语言配置) 选项卡允许用户在支持的 UI 语言之间切换。
– MCP 服务器:查看已配置的 MCP 服务器和工具
MCP settings 选项卡显示已配置的 MCP 服务器和可用工具的状态。
服务器状态显示:
- 每个 MCP 服务器的连接状态指示器
- 每个服务器的可用工具列表
- 服务器运行状况监控
- 配置验证结果
查看文本对话:
– 点击底部的文本按钮显示/隐藏对话内容
– 对话历史会实时更新,包括用户输入和 AI 响应
– 文本为红色表示聊天记录隐藏,绿色表示显示
使用 MCP 工具
模型自动调用工具:
– 在对话中提出需要工具帮助的问题(如”今天天气如何?”)
– 模型会调用相应工具并在响应中融合调用 MCP Tool 的结果
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~
5、结论
本方案实现展示了如何使用 Amazon Nova Sonic 和 WebSockets 构建完整的语音对话系统。通过遵循本文概述的架构和最佳实践,开发人员可以创建利用 Amazon Bedrock 高级语音模型功能的自然、响应式语音界面。Amazon Nova Sonic 的统一方法简化了开发过程,而双向流 API 实现了真正的交互式对话。
通过 MCP 添加工具集成,这些语音应用程序可以执行复杂任务并访问外部信息,使它们成为各种用例的强大助手。随着语音界面的不断发展,像这样的解决方案将在创建更自然、更直观的用户与技术交互方式方面发挥越来越重要的作用。

