【云计算】多云统一管理平台_基于云计算的多云管理平台技术要求
一、云计算多云统一管理平台
1.1 多云统一管理平台选型
在多云统一管理平台选型时,评估工具对异构资源的兼容性和扩展性是确保平台长期可用性和效能的核心。以下是基于行业标准和实践的系统化评估框架:
1.1.1、异构资源兼容性评估
1. 资源纳管覆盖度
- 关键指标:
- 云平台支持:是否覆盖主流公有云(AWS/Azure/阿里云/腾讯云)及私有云(OpenStack/VMware)。
- 基础设施类型:是否支持虚拟机、裸金属服务器、容器(Kubernetes/Docker)及存储/网络设备。
- 数据来源:可信云评估显示,首批参评厂商中仅20%支持容器纳管,裸金属服务器支持率达100%。
- 验证方法:
- 要求厂商提供兼容性矩阵表,并实地测试跨平台资源接入(如同时纳管AWS EC2和本地VMware集群)。
- 通过POC验证边缘设备(如IoT网关)的纳管能力。
2. 接口与协议兼容性
- 关键能力:
- API标准化:是否提供RESTful API,并支持Terraform/Ansible等IaC工具集成。
- 协议适配:是否兼容SNMP、IPMI等硬件管理协议,以及Kubernetes CRD等容器接口。
- 风险点:非标准接口可能导致定制化成本增加(如需单独开发适配器)。
3. 数据与格式兼容性
- 要求:
- 统一数据模型:能否将不同云平台的监控数据(如Prometheus/CloudWatch)转换为统一指标。
- 存储格式转换:支持跨云数据迁移(如AWS S3到Azure Blob),并确保元数据一致性。
4. 运维生态兼容性
- 集成能力:
- 是否支持与现有ITSM(如ServiceNow)、监控(如Zabbix)及安全工具(如Hashicorp Vault)对接。
- 日志分析兼容性:能否聚合AWS CloudTrail、Azure Monitor等日志到统一平台。
1.1.2、扩展性评估
1. 架构设计扩展性
- 核心要求:
- 微服务架构:模块化设计(如分离编排引擎与监控模块),支持独立扩容。
- 无状态服务:通过Kubernetes部署管理组件,实现自动扩缩容。
- 案例:某政务云平台通过微服务架构,支撑了10万+节点管理,QPS峰值达5万+。
2. 负载调度与弹性扩展
- 能力验证:
- 动态资源调度:是否支持基于策略的跨云负载迁移(如检测到阿里云CPU过载时自动切换至腾讯云)。
- 弹性策略:能否配置阈值触发扩容(如CPU>80%时自动增加VM实例)。
- 局限:部分平台受网络限制,跨云调度延迟超100ms。
3. 性能与容量扩展
- 压测指标:
- 节点规模:单集群能否管理≥5000节点(如某民航平台需支持3000+虚拟机实时监控)。
- 并发处理:API请求响应延迟<500ms(万级并发下)。
1.1.3、兼容性与扩展性量化对比表
1.1.4、选型决策流程建议
-
需求分级:
- 必选项:覆盖现有资源(如VMware+阿里云)+ 支持Kubernetes。
- 加分项:边缘设备纳管、AI调度策略。
-
概念验证(PoC):
- 场景设计:模拟跨云灾备(AWS RDS同步至本地MySQL)并测量RTO/RPO。
- 极限测试:注入节点故障,验证自愈流程是否触发多云切换。
-
厂商能力评估:
- 技术生态:检查开源贡献(如Kubernetes Operator开发)及API文档完整性。
- 升级承诺:确认版本迭代计划(如季度支持新云服务API)。
总结
选型需平衡“广度兼容”与“深度扩展”:
- 兼容性优先解决资源接入问题,避免“管理孤岛”(如缺失容器支持导致运维割裂);
- 扩展性聚焦架构抗压能力,确保业务增长时平台性能线性提升(如万级节点调度不降速)。
最终建议:通过可信云认证的平台(如FIT2CLOUD、博云)通常已通过26项基础测试,可作为初筛基准,再结合PoC验证定制化需求。
1.2 混合云环境的多云管理平台设计方案
针对混合云环境的多云管理平台设计方案、安全策略及协同机制的综合架构,结合行业实践与技术规范,分为核心模块进行说明:
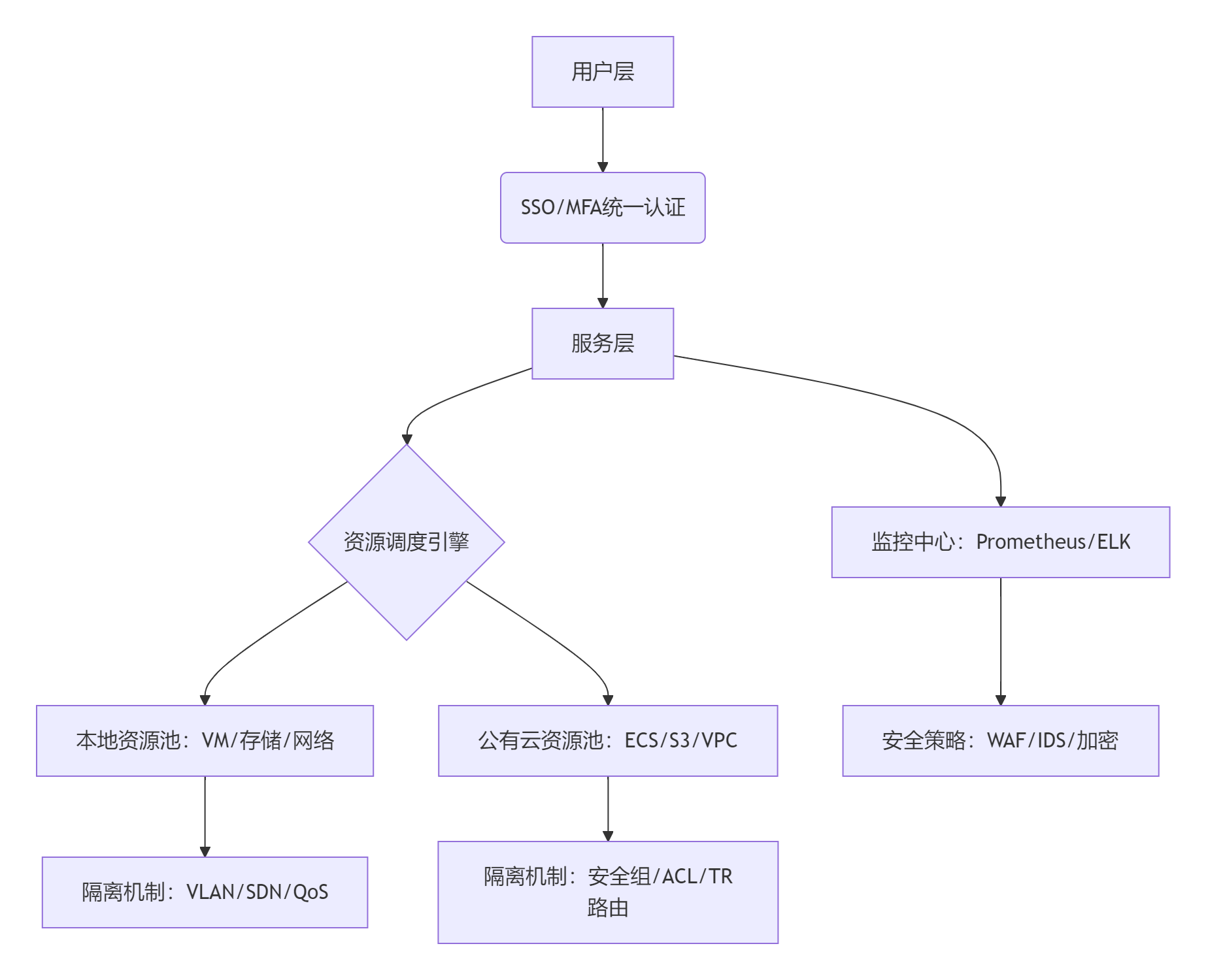
1.2.1、多云管理平台架构设计
1. 分层架构模型
- 资源接入层
- 统一适配器:通过插件化设计(如云聚平台的50+标准云插件)纳管AWS/Azure/私有云/信创云等异构资源,屏蔽底层API差异。
- 资源抽象:将虚拟机、容器、裸金属统一抽象为计算单元,存储与网络资源标准化建模。
- 服务层
- 服务目录:提供跨云IaaS/PaaS产品自助申请,支持资源拓扑设计(如VPC+安全组联动)。
- 编排引擎:通过Terraform或自研引擎实现跨云资源自动化部署(如VM+数据库+负载均衡联动创建)。
- 运营监控层
- 全局仪表盘:集成Prometheus+云原生监控,实时展示多云资源利用率、成本分摊及SLA合规性。
2. 关键能力设计
- 算力融合调度
- 支持GPU/NPU池化,动态分配AI训练任务至性价比最优的云(如本地鲲鹏芯片+公有云NVIDIA集群)。
- 成本优化引擎
- 基于历史数据预测资源需求,自动清理闲置资源,优化付费模式(预留实例+按量混用)。
1.2.2、安全策略设计
1. 统一身份与访问控制
- SSO与MFA机制
- SSO集成:通过SAML/OIDC协议打通企业AD与云平台IAM,单点登录所有云服务。
- MFA强化:登录敏感操作需叠加生物识别/硬件令牌验证,降低账号泄露风险。
- 精细化权限模型
- RBAC+ABAC组合:按角色分配基础权限(如开发人员仅可启停VM),基于属性动态授权(如财务系统仅允许内网IP访问)。
2. 数据与网络安全
- 数据生命周期加密
- 传输层:IPSec/VPN加密跨云流量;存储层:敏感数据强制AES-256加密,密钥由Hashicorp Vault托管。
- 网络隔离与防护
- 分段策略:
- 本地数据中心:通过VLAN+防火墙划分生产/测试网段,关键业务DMZ区隔离。
- 公有云:安全组+网络ACL实现应用分层防护(Web层仅开放80/443端口)。
- 统一威胁检测:部署云防火墙联动本地IDS,识别跨云攻击链(如从公有云渗透私有云的横向移动)。
- 分段策略:
1.2.3、协同机制设计
1. 租户与资源隔离机制
- 多级租户模型
- 组织架构映射:集团-分公司-部门三级租户,资源配额按需分配(如分公司A独占50核CPU+10TB存储)。
- 分权分域控制:租户管理员仅管理所属资源,平台运营方全局监控。
- 资源隔离实现
- 计算隔离:Kubernetes Namespace限制容器资源抢占,VMware资源池保障核心业务CPU预留。
- 存储隔离:
- 本地:Ceph存储池按SSD/HDD分级,QoS限制IOPS峰值。
- 云端:对象存储桶策略禁止跨账号访问,敏感数据启用WORM(一次写入多次读取)。
- 网络隔离:
- 本地:SDN控制器动态分配VxLAN,避免广播风暴。
- 云端:TR多路由表实现业务引流,可信流量与外部流量物理隔离。
2. 资源分配与弹性机制
- 智能调度策略
- 本地资源:OpenStack调度器按反亲和性规则分布VM(如主备节点跨机架部署)。
- 跨云弹性:基于阈值(CPU>80%)自动扩容至公有云,流量回落时释放资源。
- 混合存储管理
- 冷热数据分层:本地全闪存存储热数据,云端S3 IA存储备份数据,生命周期策略自动迁移。
1.2.4、运维与治理协同
- 统一监控闭环
- 日志集中采集:ELK聚合云平台与本地Syslog,AI聚类分析异常模式(如磁盘IO异常突增)。
- 自动化修复:检测到漏洞时,Ansible批量推送补丁至受影响资源。
- 合规联动
- 内置GDPR/HIPAA合规模板,扫描多云配置并生成审计报告。
架构图示例
总结与建议
- 设计要点:
- 兼容性优先:插件化架构快速纳管异构云(如云聚平台兼容40+云厂商)。
- 安全零信任:从身份验证到数据流动全程加密,策略跨云同步。
- 资源效能:通过分级存储+弹性调度,资源利用率提升30%+,成本降低25%。
- 典型场景:
- AI训练任务:本地GPU资源不足时,自动调度至公有云竞价实例,训练完成回传结果。
- 灾备切换:公有云数据库故障时,流量切至本地从库,RTO<5分钟。
实际部署参考:某金融机构采用上述架构后,管理10万+节点,API延迟<100ms,合规审计效率提升60%。进一步优化可结合边缘节点处理低延迟业务(如IoT实时分析)。
1.3 混合云场景下各类数据库的数据读写方案设计
混合云场景下各类数据库的数据读写方案设计,涵盖索引设计、IO优化、配置参数及场景适配,结合行业实践与技术规范进行系统化阐述:
1.13.1、全局设计原则
-
混合云架构核心挑战
- 网络延迟:跨云数据传输需控制延迟(建议<10ms),采用专线+本地缓存降低影响。
- 数据一致性:强一致性场景用同步复制(如PolarDB三副本),弱一致性用异步+冲突解决机制。
- 存储分层:热数据存本地SSD,冷数据存云端对象存储(如阿里云OSS),成本降40%以上。
-
通用读写优化方案
graph LRA[写入场景] --> B[批量写入:合并写入+异步提交]A --> C[高频写:LSM-Tree+WAL日志]D[读取场景] --> E[顺序读:预取机制+大块IO]D --> F[随机读:缓存+布隆过滤器]
1.13.2、时序数据库方案(如InfluxDB/TDengine)
-
核心架构
- 索引方案:时间范围索引(TSI)+ 倒排索引(按tag过滤),查询速度提升10倍。
- IO优化:
- 批量写入:每批次10万数据点,启用压缩(Snappy)
- 顺序读:使用列式存储(Parquet),预取窗口1MB。
- 异步提交:WAL日志分段提交,写入吞吐提升至50万点/秒。
-
关键参数配置
参数 写入密集型 查询密集型 调优依据 wal_flush_interval100ms 1s 磁盘IOPS能力 cache-snapshot-write-size64MB 256MB 内存容量 compaction_level4 2 数据精度要求
1.13.3、分布式MPP数据库方案(如ClickHouse/Greenplum)
-
核心架构
- 索引方案:Skip索引(minmax)+ 布隆过滤器,减少90%无效扫描。
- IO优化:
- 批量读写:列块大小128MB,启用ZSTD压缩
- 随机写:禁用(改用LSM替代Update)。
- 异步提交:后台MergeTree合并,写入延迟<500ms。
-
分场景参数
# 高并发查询场景max_threads = 32max_block_size = 65536# 大数据分析场景background_pool_size = 16max_memory_usage = 128GB
1.13.4、文档数据库方案(如MongoDB)
-
核心架构
- 索引方案:组合索引(时间戳+设备ID),TTL索引自动清理。
- IO优化:
- 批量写入:
ordered=false+ 1000文档/批次 - 随机读:覆盖索引+Redis缓存热点。
- 批量写入:
- 异步提交:WriteConcern=0(不等待确认)。
-
故障恢复机制
graph TBG[主节点宕机] --> H[从节点选举新主]H --> I[异步线程重放Oplog]I --> J[数据一致性校验]
1.13.5、列式数据库方案(如HBase)
-
核心架构
- 索引方案:RowKey设计(哈希前缀防热点)+ 协处理器二级索引。
- IO优化:
- 顺序写:MemStore 4GB阈值刷盘
- 批量读:Scan缓存设置10万行。
- 异步提交:WAL分组提交(GroupCommit)。
-
混合云同步
- 通过HBase Replication同步跨云数据,带宽占用比1:1.2(压缩后)。
1.13.6、关系数据库方案(PolarDB/MySQL/PostgreSQL)
-
OLTP场景(如PolarDB)
- 索引方案:B+树主键 + 覆盖索引,避免回表。
- IO优化:
- 高频写:Redo Log双写 + 16KB页大小
- 随机读:Buffer Pool大小设为内存80%。
- 异步提交:
innodb_flush_log_at_trx_commit=2(每秒刷盘)。
-
OLAP场景(如OceanBase)
- 分布式架构:Paxos协议保证跨云数据一致性,RPO=0。
- 批量加载:使用OSS外部表 + 并行导入(
parallel_workers=32)。
1.13.7、国产数据库方案(人大金仓/达梦)
-
人大金仓(KES)
- 混合云适配:通过Roach工具实现本地到云端的增量同步。
- 参数调优:
ALTER SYSTEM SET wal_level = \'logical\';ALTER SYSTEM SET max_wal_senders = 8; -- 跨云同步通道数
-
达梦(DM)
- 存储优化:HUGE表空间存时序数据,压缩率>70%。
- 灾备设计:主备库延迟<1秒(10G专线)。
1.13.8、量化指标与参数决策矩阵
1.13.9、场景化配置策略
-
物联网高频写入
- 数据库选型:时序库(InfluxDB)
- 关键参数:
batch_size=10000,wal_compaction=zstd- 索引:TSI + 倒排索引(device_id)
-
金融交易系统
- 数据库选型:关系库(OceanBase)
- 关键参数:
sync_log=true,memory_limit=90%- 索引:B+树联合索引(account_id+timestamp)
-
电商大促
- 数据库选型:文档库(MongoDB)+ Redis缓存
- 关键参数:
writeConcern=0,readPreference=nearest
1.13.10、总结与建议
- 核心公式:性能 = 索引设计 × IO优化 × 资源配比
- 混合云黄金法则:
- 数据本地性:高频访问数据靠近计算节点;
- 异步流水线:批量操作异步化+压缩传输;
- 动态治理:基于监控(如Prometheus)自动扩缩容。
- 国产化替代:达梦兼容Oracle语法,人大金仓适配PostgreSQL生态,迁移时需验证存储引擎兼容性。
实际案例:某车联网平台通过上述方案,在AWS+本地IDC混合架构中支撑日均10亿数据点写入,查询P99延迟稳定在80ms内,存储成本降低60%。最终建议:混合云数据库选型需匹配业务SLA,OLTP用关系库,时序场景用时序库,分析型MPP库用于BI,通过统一管控平台(如KubeSphere)降低运维复杂度。

