ARM体系架构学习之指令集_arm架构指令集
第5章:指令集
5.1 指令集的背景介绍
早期的ARM处理器支持名为ARM的32位指令集,该指令集功能强大,支持多数指令的条件执行,并提供良好的性能。随着移动市场的火爆,移动端的32位处理器对于功耗和成本等要求变高,所以1995年ARM公司在ARM7TDMI处理器上支持了一种新的16位指令集。该16位指令集被称为thumb,使用这种指令集,代码量减少了30%。Thumb指令集提供了ARM指令集的一个子集,在ARM7TDMI处理器上设计了一个指令译码器,将thumb指令转换为arm32指令,通过双状态模式,使得兼容性更好。在2003年,ARM公司提出了thumb-2技术,thumb-2指令集扩展了thumb指令集,并加入了许多32位指令,该技术使得处理器可以同时使用16位和32位指令集。注意,thumb-2里的32位指令与arm32里的32位指令不同。
5.2 理解汇编语言语法
汇编指令格式如下
label:mnemonic operand1,operand1,... ;注释 /*label:表示地址位置,可选,通过这个label可以得到指令的地址。mnemonic:为助记符,即汇编指令名称operand1:操作数,通常第一个操作数为操作的目的,操作数包含不同的操作类型,具体可查询汇编指令使用方法operand2:操作数,通常为操作的源。;表示为注释符号,和C语言编程中的//*/举例:MOVS R0,#0x123 /*设置R0为0x123*/MOVS R1, #\'A\' /*设置R1为字符A*/汇编代码的一个常见特性为定义常量,通过定义常量,代码的可读性得到提升。下面给出一个常量定义的例子:
NVIC_IRQ_SETEN EQU 0xE000E100 /*宏定义*/NVIC_IRQ0_ENABLE EQU 0x1 /*宏定义*/...LDR R0, =NVIC_IRQ_SETEN /*使用LDR伪指令,将地址信息写入到R0*/MOVS R1,#NVIC_IRQ0_ENABLE /*将0x1立即数写入到R1*/STR R1, [R0] /*store register,作用是将寄存器中的数据写入内存;将R1中的数写入地址0xE000E100中*/5.3 指令后缀的使用
对于ARM处理器的汇编器,有些指令跟着后缀,后缀描述如下
ARM 指令后缀全称速查表
ADDEQ R0, R1, R2MOVNE R0, #1ADDCS R0, R0, R1SUBCC R0, R0, #1RSBMI R0, R0, #0MOVPL R0, #0ADDVS R0, R0, #1SUBVC R0, R0, R1BHI targetMOVGE R1, #1ADDLT R0, R0, #100CMPGT R0, R1LDRB R0, [R1]STRH R0, [R2]LDRD R0, R1, [R2]ADDS R0, R1, R2LDR R0, [R1, #4]!BX R0 (R0 LSB=1)LDMIA R0!, {R1-R3}STMDB SP!, {R4-R6}所有带条件后缀的 ARM 指令,在执行前都会检查执行前的 CPSR 状态,并根据该状态决定是否执行本条指令的操作。指令执行后才会更新 CPSR(如果指令包含 S 后缀)。
5.4 指令集
Cortex-M3和Cortex-M4处理器的指令可以按照功能分为如下几类:
1.处理器内传送数据
在处理器之间执行数据传送是微处理器中最基本的操作。可能会出现如下操作场景
- 将数据从一个寄存器送到另一个寄存器
MOV R4, R0 /*将R0的数据写入到R4*/MOVS R4, R0 /*将R0的数据写入到R4,同时更新APSR寄存器*/MVN R3, R7 /*将R7的数据取反后更新至R3,MVN:move not*/- 在寄存器和特殊寄存器(CONTROL,PRIMASK,FAULTMASK,BASEPRI)之间进行数据传送
MRS R7, PRIMASK /*将PRIMASK(特殊寄存器)的数据写入到R7,MRS全称:move to register from Special register*/MSR CONTROL, R0 /*将R0的数据写入到CONTORL特殊寄存器中*/- 将立即数写入到寄存器中
MOV R4, #0x12 /*将0x12的数据写入到R4*/MOVS R4, #0x12 /*将0x12的数据写入到R4,同时更新APSR寄存器*/MOVW R0, #0x1234 /*将16位立即数加载到寄存器R0的低16位,高16位清零*/MOVT R0, #0x1234 /*将16位立即数加载到寄存器R0的高16位,低16位不变*/- 针对带浮点单元的CORTEX-M4处理器,还支持内核寄存器和浮点单元寄存组,浮点寄存器组之间,以及浮点系统寄存器与内核寄存器,立即数与浮点寄存器之间的数据交换。
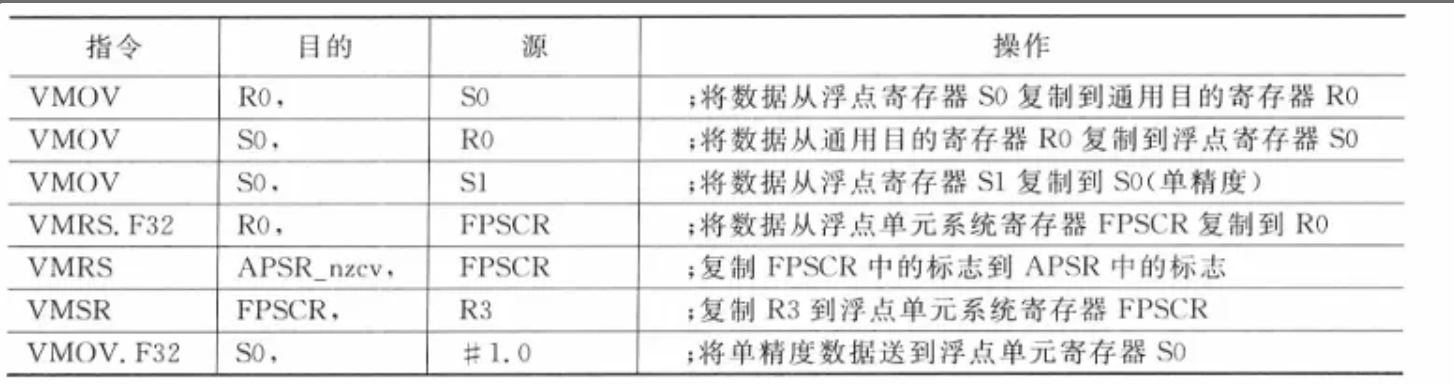
2.存储器访问指令
Cortex-M3/M4支持很多存储器访问指令,寻址模式及数据大小和数据传输方向具有很多组合方式。
- 立即数偏移
数据传输的存储器地址为寄存器中的数值加上偏移值。指令分为load指令和store指令,load指令是将存储器的信息写入到寄存器中,store指令是将寄存器的数据写入到存储器中。
//Load instructionLDRB Rd, [Rn,#offset] /*将地址为Rn加上#offset里面的字节信息读入到Rd中,LDRB:load rgister byte*/LDRSB Rd, [Rn,#offset] /*将地址为Rn加上#offset里面的字节信息进行有符号扩展后读入到Rd中,LDRH Rd, [Rn,#offset] /*将地址为Rn加上#offset里面的半字节信息读入到Rd中,LDRSH Rd, [Rn,#offset] /*将地址为Rn加上#offset里面的半字节信息进行有符号扩展后读入到Rd中,LDR Rd, [Rn,#offset] /*将地址为Rn加上#offset里面的字信息读入到Rd中LDRD Rd1,Rd2, [Rn,#offset] /*将地址为Rn加上#offset里面的双字信息读入到Rd1和Rd2中,//Store instructionSTRB Rd, [Rn,#offset] /*向地址为Rn加上#offset里面写入Rd寄存器中的字节信息STRB:store rgister byte*/STRH Rd, [Rn,#offset] /*向地址为Rn加上#offset里面写入Rd寄存器中的半字节信息STRH:store rgister halfbyte*/STR Rd, [Rn,#offset] /*向地址为Rn加上#offset里面写入Rd寄存器中的字信息STR:store rgister word*/STRD Rd1,Rd2, [Rn,#offset] /*向地址为Rn加上#offset里面写入Rd1,Rd2寄存器中的两字信息STRD:store rgister double word*//*注意:offset参数可以为正数,也可以为负数*/注意,可以在上述指令后加一个 !,如LDR R0, [R1, #offset]!,这就可以实现地址寄存器R1的更新,即在成功完成内存加载后,将计算出的新地址(R1 + offset)写回基址寄存器 R1。这个操作为原子操作,不可被打断
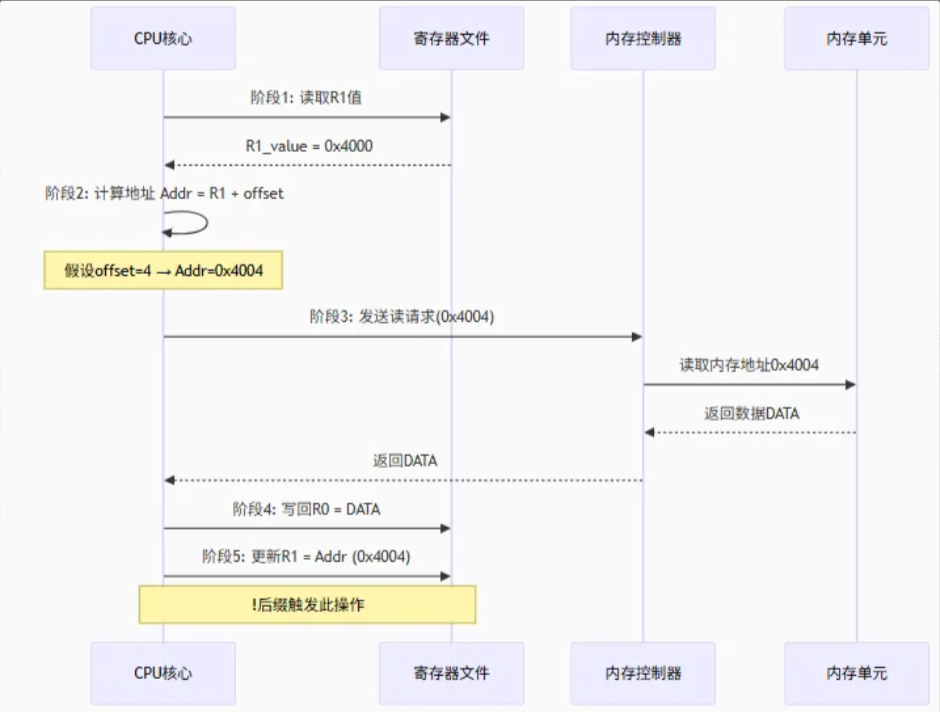
- PC相关寻址
存储器访问可以产生相对于当前PC的地址的偏移值。将立即数加载到寄存器中。也被称为文本池访问。
LDRB R1,[PC,#offset] /*将PC地址+offset(可选)地址里的数据字节信息加载到R1中*/LDRSB R1,[PC,#offset] /*将PC地址+offset(可选)地址里的数据字节信息进行有符号扩展后加载到R1中*/LDRH R1,[PC,#offset] /*将PC地址+offset(可选)地址里的数据半字信息加载到R1中*/LDRSH R1,[PC,#offset] /*将PC地址+offset(可选)地址里的数据半字信息进行有符号扩展后加载到R1中LDR R1,[PC,#offset] /*将PC地址+offset(可选)地址里的数据字信息加载到R1中*/LDRD R1,R2,[PC,#offset] /*将PC地址+offset(可选)地址里的数据字节信息加载到R1,R2中*/*/- 寄存器偏移
寄存器偏移用于所处理的数据数组地址为基地址和从索引值计算出来的偏移得到的情况。
LDRB R0, [R1, R2, LSL #n] /*将地址R1(基地址)+变址寄存器R2<<n之后的地址内容字节数据加载到R0n的取值范围在0-3之间*/LDRSB R0, [R1, R2, LSL #n] /*将地址R1(基地址)+变址寄存器R2<<n之后的地址内容字节数据进行符号扩展加载到R0n的取值范围在0-3之间*/LDRH R0, [R1, R2, LSL #n] /*将地址R1(基地址)+变址寄存器R2<<n之后的地址内容半字节数据加载到R0n的取值范围在0-3之间*/LDRSH R0, [R1, R2, LSL #n] /*将地址R1(基地址)+变址寄存器R2<<n之后的地址内容半字节数据进行符号扩展后加载到R0n的取值范围在0-3之间*/LDR R0, [R1, R2, LSL #n] /*将地址R1(基地址)+变址寄存器R2<<n之后的地址内容字数据加载到R0n的取值范围在0-3之间*/STRB R0, [R1, R2, LSL #n] /*将R0寄存器中的字节内容加载到地址R1(基地址)+变址寄存器R2<<n之后的地址中去n的取值范围在0-3之间*/STRH R0, [R1, R2, LSL #n] /*将R0寄存器中的半字节内容加载到地址R1(基地址)+变址寄存器R2<<n之后的地址中去n的取值范围在0-3之间*/STR R0, [R1, R2, LSL #n] /*将R0寄存器中的字内容加载到地址R1(基地址)+变址寄存器R2<<n之后的地址中去n的取值范围在0-3之间*/- 后序
具有立即数寻址模式的存储器访问指令也有一个立即数偏移数值,不过在访问期间是用不到这个偏移值的,在访问之后才将地址+偏移值的地址更新到地址寄存器中。注意:后序指令中不能使用PC和SP这两个寄存器,偏移数可以为正数,也可以为负数。
LDRB Rd, [R0], #offset /*将R0地址中的字节数据加载到Rd中,在加载结束后,将R0=R0+offset*/LDRSB Rd, [R0], #offset /*将R0地址中的字节数据进行符号位扩展后加载到Rd中,在加载结束后,将R0=R0+offset*/LDRH Rd, [R0], #offset /*将R0地址中的半字节数据加载到Rd中,在加载结束后,将R0=R0+offset*/LDRSH Rd, [R0], #offset /*将R0地址中的半字节数据进行符号位扩展后加载到Rd中,在加载结束后,将R0=R0+offset*/LDR Rd, [R0], #offset /*将R0地址中的字数据加载到Rd中,在加载结束后,将R0=R0+offset*/LDRD Rd1, Rd1, [R0], #offset /*将R0地址中的双字数据加载到Rd1,Rd2中,在加载结束后,将R0=R0+offset*/STRB Rd, [R0], #offset /*将Rd中所存储的字节信息写入到R0地址所在的内存区域,操作结束后更新R0中的地址信息*/STRH Rd, [R0], #offset /*将Rd中所存储的半字节信息写入到R0地址所在的内存区域,操作结束后更新R0中的地址信息*/STR Rd, [R0], #offset /*将Rd中所存储的字信息写入到R0地址所在的内存区域,操作结束后更新R0中的地址信息*/STRD Rd1,Rd2, [R0], #offset /*将Rd中所存储的双字信息写入到R0地址所在的内存区域,操作结束后更新R0中的地址信息*/- 多加载和多存储
ARM架构中有一个重要的优势,就是可以读或者写存储器中多个连续数据,LDM和STM指令只支持32位数据,它们支持两种前序,一种每次读写后增加地址,一种是每次读写后减少地址。如果该类指令后面跟!,则意味着数据加载结束之后会将基址寄存器的信息进行更新。
//LDMIA Rn, /*LDMIA: load data memory increment after*/LDMIA Rn, /*从Rn指定的存储器位置读取多个字,依次将数据存储R1,R2,R3,R4,R5中,每次读写后地址增加*/LDMIA Rn, /*从Rn指定的存储器位置读取多个字,依次将数据存储在R0,R2,R3,R4,R5,R7中,注意,寄存器加载时与顺序无关,加载寄存器按照升序排列进行加载*///LDMDB Rn, /*LDMIA: load data memory decrement befor,先执行地址减操作,然后在加载数据*/LDMDB Rn, /*从Rn指定的存储器位置-4读取多个字,依次将数据存储R5,R4,R3,R2,R1中,每次读写后地址减少*/LDMDB Rn, /*从Rn指定的存储器位置-4读取多个字,依次将数据存储在R7,R5,R4,R3,R2,R1中*///STMIA Rn, /*STMIA: store data memory increment after*/STMIA Rn, /*往Rn指定的存储器位置写入多个字,写入将数据为R1,R2,R3,R4,R5中的数据,每次读写后地址增加*/STMIA Rn, /*从Rn指定的存储器位置读取多个字,依次将数据存储在R0,R2,R3,R4,R5,R7中*///STMDB Rn, /*STMDB : store data memory decrement befor*/STMDB Rn, /*往Rn指定的存储器位置-4写入多个字,依次将数据存储R5,R4,R3,R2,R1中,每次读写后地址增加*/STMDB Rn, /*往Rn指定的存储器位置-4写入多个字,依次将数据存储在R7,R5,R4,R3,R2,R1中*/- 压栈和出栈
栈的PUSH和POP是另外一种形式的多存储和多加载,利用当前选定的栈指针来生成地址,当前指针可以是主栈指针(msp),也可以是进程栈指针(psp)。实际选择是通过处理器的当前模式和CONTROL寄存器的数值决定。
PUSH {R0,R4-R7,R9} ;PUSH指令将R0,R4,R5,R6,R7,R9压入栈中POP {R0,R2} ;POP指令将栈中的内容存入R0,R2寄存器中- SP相关寻址
栈空间除了用于函数或者子例程的寄存器临时存储,同时还常用于存储局部变量。访问这些临时变量需要前面提到过的LDR和STR指令。在函数开始处为局部变量分配栈空间,同时调整SP指针,当调用函数结束后,SP指针释放这部分空间。
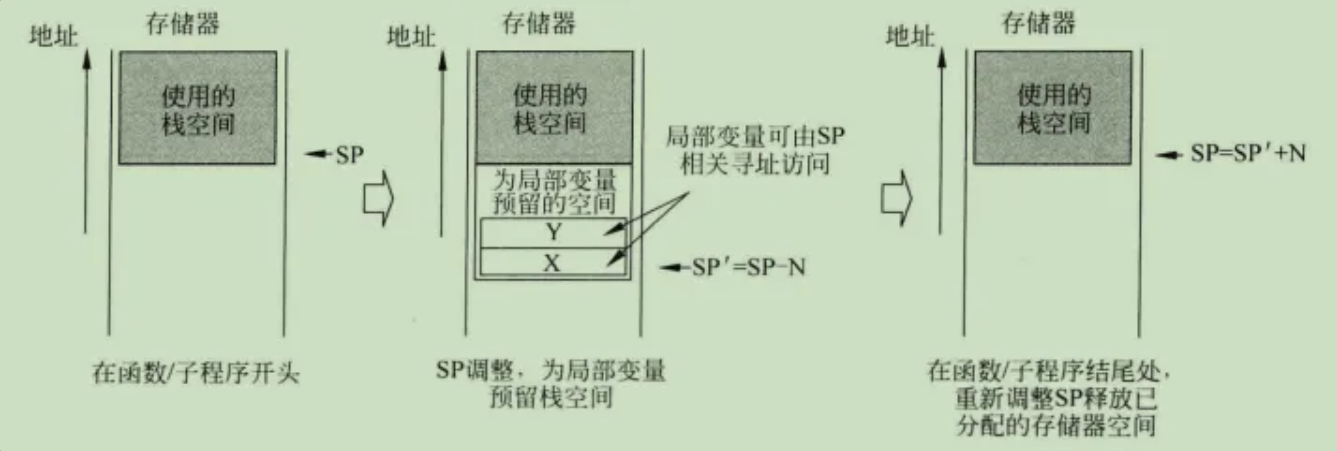
3.算术运算
Cortex-M3/M4处理器提供了多个用于算术运算的指令,具体如下:
ADD Rd, Rn, Rm ; Rd=Rn+Rm ADD Rd, Rn, #immed ; Rd=Rn+immedADC Rd, Rn, Rm ; Rd=Rn+Rm+进位ADC Rd, #immed ; Rd=Rd+immed+进位ADDW Rd, Rn, #immed ; Rd=Rn+immed,注意:这条指令是thumb-2指令,支持完成的12位无符号立即数SUB Rd, Rn, Rm ; Rd=Rn-Rm SUB Rd, #immed ; Rd=Rd-immedSUB Rd, Rn, #immed ; Rd=Rn-immedSBC Rd, Rn, Rm ; Rd=Rn-Rm-借位SBC Rd, #immed ; Rd=Rd-immed-借位SUBW Rd, Rn, #immed ;Rd=Rn-immed 注意:这条指令是thumb-2指令,支持完成的12位无符号立即数RSB Rd, Rn, #immed ; Rd=immed-RnRSB Rd, Rn, Rm ; Rd=Rm-RnMUL Rd, Rn, Rm ;Rd= Rn*RmUDIV Rd, Rn, Rm ;Rd= Rn/Rm ;无符号运算SDIV Rd, Rn, Rm ;Rd= Rn/Rm ;有符号运算 4.逻辑运算
Cortex-M3/M4处理器提供了多个用于逻辑运算的指令,具体如下:
AND Rd,Rn ;Rd=Rd & RnAND Rd,Rn,#immed ;Rd=Rn & immedAND Rd,Rn,Rm ;Rd=Rn & RmORR Rd,Rn ;Rd=Rd | RnORR Rd,Rn,#immed ;Rd=Rn | immedORR Rd,Rn,Rm ;Rd=Rn | RmBIC Rd,Rn ; Rd=Rd &(~Rn) BIC:bit clearBIC Rd,Rn,#immed ;Rd=Rn&(~immed)BIC Rd,Rn,Rm ;Rd=Rn &(~Rm)ORN Rd,Rn,#immed ;Rd=Rn|(~immed) ORN:logic or not或非操作ORN Rd,Rn,Rm ;Rd=Rn |(~Rm)EOR Rd,Rn ; Rd=Rd ^ Rn EOR:Exclusive OREOR Rd,Rn,#immed ;Rd=Rn ^ immedEOR Rd,Rn,Rm ;Rd=Rn ^ Rm5.移位和循环移位
Cortex-M3/M4处理器提供了多个用于移位操作的指令,具体如下:
//算术右移 Arithmetic Shift RightASR Rd, Rn, #immed ;Rd=Rn>>immedASR Rd, Rn ;Rd=Rd>>RnASR Rd, Rn, Rm ;Rd=Rn>>Rm//逻辑右移 Logic Shift RightLSR Rd, Rn, #immed ;Rd=Rn>>immedLSR Rd, Rn ;Rd=Rd>>RnLSR Rd, Rn, Rm ;Rd=Rn>>Rm//逻辑左移 Logic Shift LeftLSL Rd, Rn, #immed ;Rd=Rn<<immedLSL Rd, Rn ;Rd=Rd<<RnLSL Rd, Rn, Rm ;Rd=Rn<<Rm//循环右移 ROtate RightROR Rd, Rn ;Rd右移RnROR Rd, Rn, Rm ; Rd等于Rn右移Rm//循环右移并展开 Rotate Right with ExtendRRX Rd, Rn ;{C,Rd}={Rn,C}给一个例子说明循环右移并展开RRX指令:
初始状态:
R1 = 0x00000003(二进制:0000 0000 0000 0000 0000 0000 0000 0011)C = 1(CPSR 进位标志)- 指令:
RRX R0, R1
执行步骤:
-
构建 33 位数:复制下载
text
C标志位(1) + R1(32位):1_00000000000000000000000000000011 -
循环右移 1 位:复制下载
text
原始33位:1_00000000000000000000000000000011右移1位:1_10000000000000000000000000000001 → **最低位1移出** -
分离结果:
- 低 32 位:
10000000000000000000000000000001→ 0x80000001(存入 R0) - 移出位:
1(存入新 C 标志位)
- 低 32 位:
移位操作总结:
LSL数据 × 2ⁿLSR数据 ÷ 2ⁿ (无符号)ASR数据 ÷ 2ⁿ (有符号)RORRRX6.比较指令
比较指令仅用于更新APSR中的标志,不会保存运算结果。APSR更新的标志将用于后续的条件判断或条件执行。
CMP R0,R1 ;计算R0-R1,根据计算结果更新APSR寄存器CMP R0,#immed ;计算R0-immed,根据计算结果更新APSR寄存器CMN R0,R1 ;计算R0+R1,根据计算结果更新APSR寄存器CMN R0,#immed ;计算R0+immed,根据计算结果更新APSR寄存器7.程序流控制指令
- 跳转
B lable ;跳转到lable,如果条状范围超扩正负2KB,则使用下面的跳转指令。B.W lable BX R0 ;实现间接跳转,并且基于Rm第0位设置处理器的执行状态T位。最低位为0为ram状态,最低位为1为thumb状态- 函数调用
BL lable ;跳转到lable地址出并返回地址保存到LR中BLX Rn ;跳转到Rn指定的地址,并将返回地址保存到LR中,同时更新EPSR中的T位。- 条件条状
//APSR寄存器中的状态位:; N:负标志; Z:0; C:进位标志; V:溢出标志B lable ;cond见下图,lable为函数标签B.W lable ;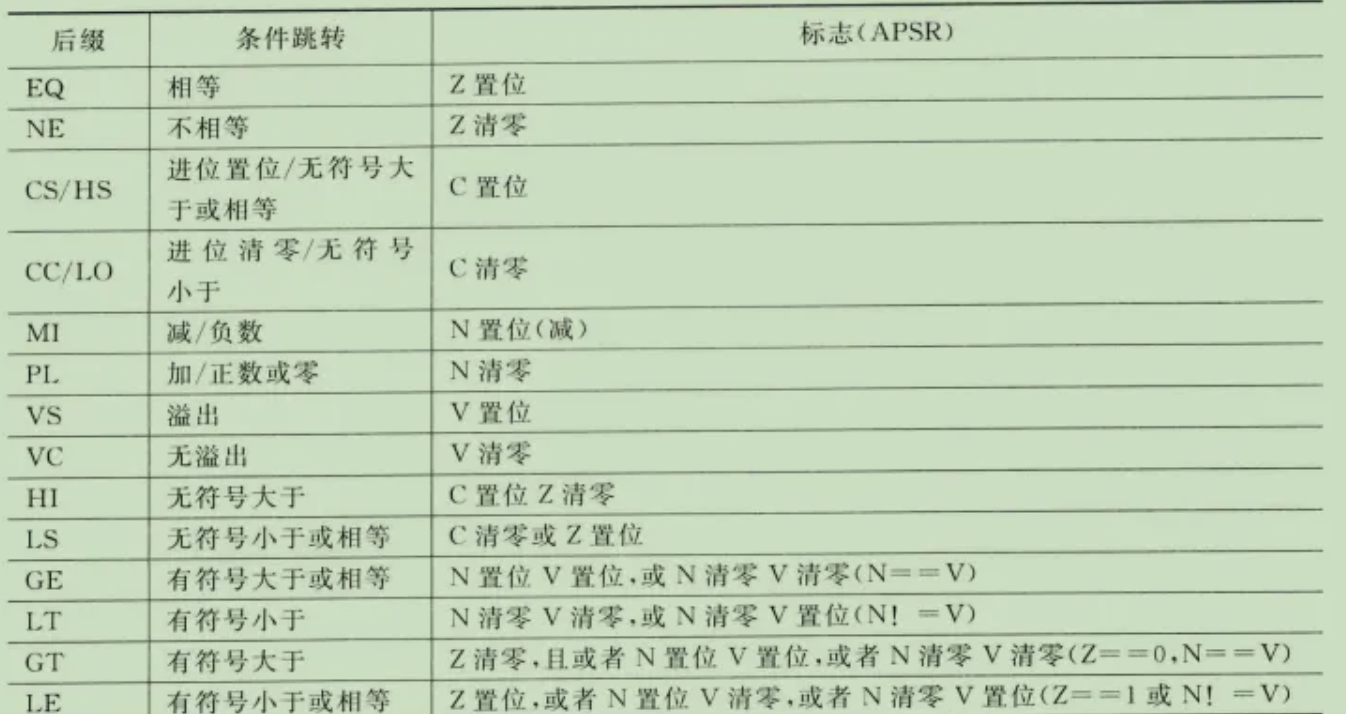
8.休眠模式
进入休眠模式有两条指令
WFI ;wait for interruptWFE ;wait for event9.存储器屏障指令
DMB ;数据存储器屏障,确保在执行新的存储器访问之间所有的存储器访问都已经完成DSB ;数据同步屏障,确保在执行下一条指令前所有的存储器访问都已经完成ISB ;指令同步屏障,清空流水线,确保在执行新的指令之间,前面的指令都已经完成10.其他指令
NOP ;空指令知识点扩展:
1、伪指令EQU
EQU:在 ARM 汇编中,EQU 是最重要的伪指令之一,全称为 Equate(等价)。它的核心作用是为常量、地址或表达式赋予一个符号化的名称,本质上是一种编译时的文本替换机制。是汇编世界的 #define。
- 本质:在编译预处理阶段,将程序中的所有
符号名替换为右侧的表达式 - 不生成机器码:与真实指令不同,
EQU不占用内存空间 - 作用域:通常全局有效(从定义处到文件结束)
EQU 与普通赋值的本质区别
EQUMOV / LDREQU 与其他伪指令对比
EQUBAUD EQU 115200SETLCOUNT SETL 10=size = 0x100DCBstr: DCB \"Hello\",02、伪指令LDR
ARM汇编中的伪指令 LDR(Load Register)是一个强大的工具,它不是真实的机器指令,而是由汇编器(如GNU AS或ARM Compiler)在编译阶段转换为一条或多条等效的真实机器指令。
主要功能:加载常量或地址到寄存器
加载任意32位立即数
当需要将超出 MOV/MVN 指令范围的立即数(如 0x12345678)加载到寄存器时,伪指令 LDR 会自动拆解为合适的机器指令序列。
LDR R0, =0x12345678; 伪指令 → 汇编器自动处理编译后可能转换为:
LDR R0, [PC, #offset]; 从\"文字池\"加载(PC相对寻址)....ltorg; 文字池中存储0x12345678-
加载标号(函数或变量)地址
在获取全局变量、函数的地址时,避免手动计算偏移量。
LDR R0, =main; 将main函数的地址加载到R0LDR R1, =global_var; 将全局变量global_var的地址加载到R1
重要说明:真实指令 LDR 用于从内存加载数据(如 LDR R0, [R1]),而伪指令 LDR 用于加载常量或地址(带等号 =)。
伪指令 LDR 的底层实现原理
汇编器处理伪指令 LDR 的两种方式:
-
优化为
MOV/MVN(若立即数可用单指令表示)LDR R0, =0xFF → MOV R0, #0xFF; Thumb-2下可能用 MOVW -
存入\"文字池\" (Literal Pool) + PC相对加载
-
汇编器在代码段末尾或
LTORG声明处创建数据区存储常量。 -
生成真实指令从文字池加载:
LDR R0, [PC, #offset]; offset为到文字池的偏移量
-
3.文字池的本质:隐藏在代码段中的“数据仓库”
文字池是汇编器自动创建的数据存储区,专门用于存放:
- 伪指令
LDR Rd, =value中的大立即数 - 函数/变量的绝对地址
- 编译时确定的复杂表达式结果
文字池的三大核心特性
1. 位置依赖性
- 汇编器默认在代码段末尾放置文字池
- 若伪指令距离文字池太远 → 超出PC偏移范围导致错误
2. 对齐要求
- ARM模式:文字池需 4字节对齐
- Thumb模式:强烈建议4字节对齐(某些Cortex-M核要求严格对齐)
3. 作用域隔离
每个汇编文件有独立文字池,链接器最终合并所有文字池到代码段。
4、逻辑PC和物理PC
核心原理:流水线中的PC永远指向未来
在任何流水线设计中:
PC始终指向当前正在“取指”(Fetch)阶段的指令地址
这意味着:
-
执行(Execute)单元处理的指令
-
译码(Decode)单元处理的指令
-
取指(Fetch)单元处理的指令
三者是同时存在的不同指令!
假设当前CPU状态:
时钟周期 | 取指(F) | 译码(D) | 执行(E) | PC值----------------------------------------周期1 | 指令A | - | - | 0x8000 (A地址)周期2 | 指令B | 指令A | - | 0x8004 (B地址)周期3 | 指令C | 指令B | 指令A | 0x8008 (C地址) ← 关键点!-
当指令A在周期3执行时:
- PC已指向指令C(0x8008)
- 超前A的地址:
0x8008 - 0x8000 = 8字节
-
公式:
执行阶段PC = 当前指令地址 + 2×指令长度(ARM每条指令4字节 → 2×4=8字节)
关键结论:PC偏移量的通用公式
黄金规律:
执行阶段的PC = 当前指令地址 + (流水线深度 - 1) × 指令长度
对程序员/调试者的重大影响
-
调试器显示的是“取指PC”
当您看到调试器显示
PC=0x8010时:- 真正执行的指令在
0x8010 - 16 = 0x8000(五级流水线)
- 真正执行的指令在
-
PC相对寻址计算需注意
在汇编中写:
LDR R0, [PC, #0]; 你以为加载当前PC?实际加载的是 PC + 流水线偏移量 处的数据!
-
断点行为的深层原因
设置断点于0x8000时,CPU其实在:
- 五级流水线:断在0x8000指令的执行阶段
- 此时PC已指向0x8010
流水线时代的现实冲突
现代CPU采用流水线后:
+-----+-----+-----+周期n | F取 | D译 | E执 | ← 指令A在E阶段执行时 +-----+-----+-----+ | | F取 | D译 | ← 指令B在D阶段 +-----+-----+-----+ | | | F取 | ← 指令C在F阶段 (PC指向这里!) +-----+-----+-----+- 关键矛盾点:
- 物理事实:硬件PC寄存器永远指向正在取指的指令
- 逻辑需求:程序员需要知道当前执行指令的下一条地址
不同场景下的“PC所指”对比表
两种“PC”的辩证关系
- 物理PC (硬件层面)
- 永远指向正在取指的指令
- 值 = 当前执行指令地址 + (流水线深度-1)×指令长度
- 程序员不可见,但影响PC相对寻址计算
- 逻辑PC (软件层面)
- 调试器和文档显示的“当前指令地址+4”
- 是架构设计的抽象层(ARM称为\"Programmer\'s Model\")
- 用于保证:
- 分支目标计算符合直觉
- 调试器单步执行语义正确
- 反汇编列表可读性
注:推荐一个网站Compiler Explorer,实时查看ram汇编输出。

