scrapy爬虫实战(二): 结合Selenium实现动态加载网页数据采集(详细解说爬取过程以及完整代码)_scrapy selenium
目录
一、环境准备
二、实战
1、项目介绍
2、创建项目
新建项目
定义Item(items)
mysql建表
3、selenium模拟用户点击网页并加载更多(middlewares)
4、管道文件(Pipelines)
mysql存储
CSV存储
5、配置文件(settings)
6、爬虫文件(cls_finance)
7、运行测试
一、环境准备
1、python
python3以上,你可以直接下个anaconda,参考之前我写的博客
Anaconda安装+scrapy部署及初步认识-CSDN博客
2、mysql
3、scrapy
参考:Anaconda安装+scrapy部署及初步认识-CSDN博客
4、selenium+chromdriver
因为我的浏览器是chrom,所以用的chromdiver
参考:scrapy爬虫实战:爬取财经网站新闻数据(动态渲染页面)---详细图文解说-CSDN博客
二、实战
1、项目介绍
本项目要爬取的数据是财联社的头条新闻数据,模拟用户点击加载更多按钮,获取完整的网页源码,并把数据存储在mysql数据库。

财联社是主流的财经新闻媒体,专注于中国证券市场动态的分析、报道。
财联社深度:重大政策事件及时分析解读_供给侧改革
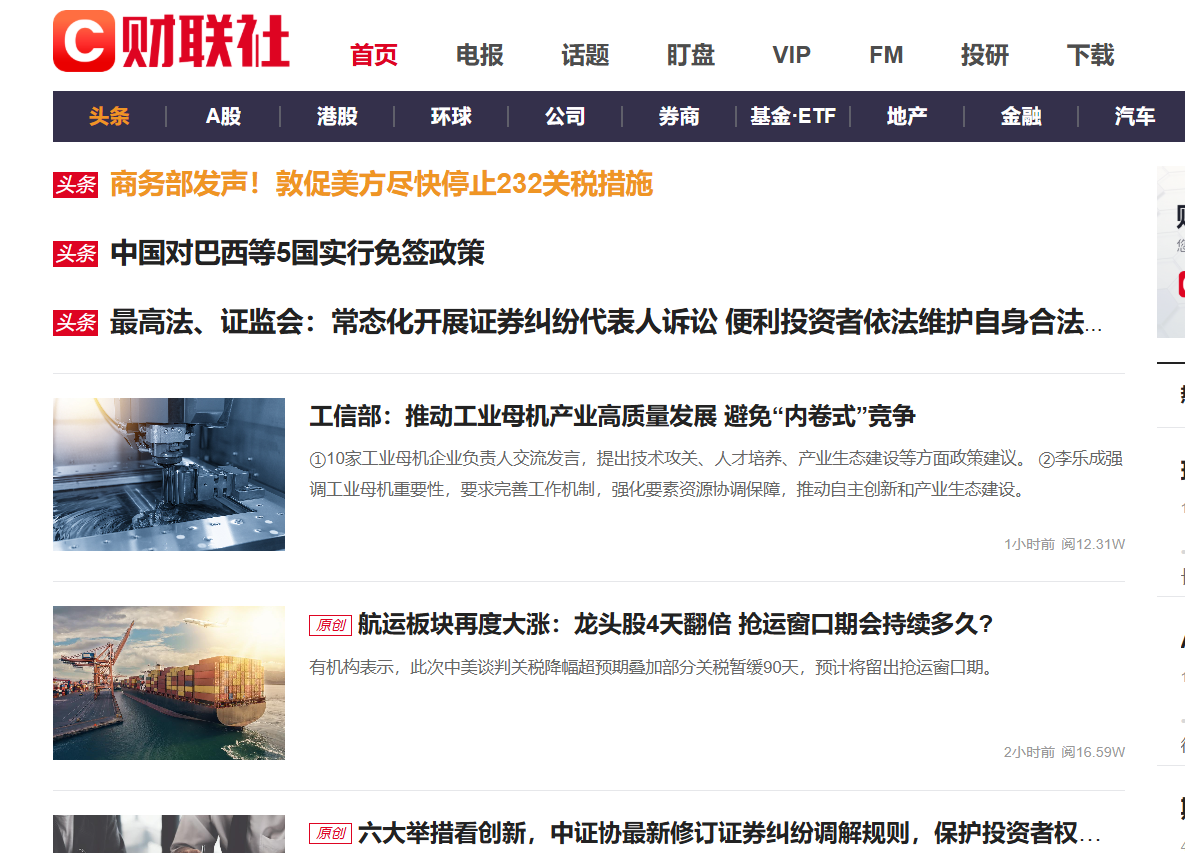
然后按F12分析发现本网页呈现的逻辑:列表数据是通过Ajax加载的。
数据通过 AJAX 加载 是指网页的内容(如列表、表格、动态更新的信息)不是直接写在初始 HTML 代码中,而是通过 JavaScript 异步请求(AJAX) 从服务器获取数据,再动态插入到页面中的技术。
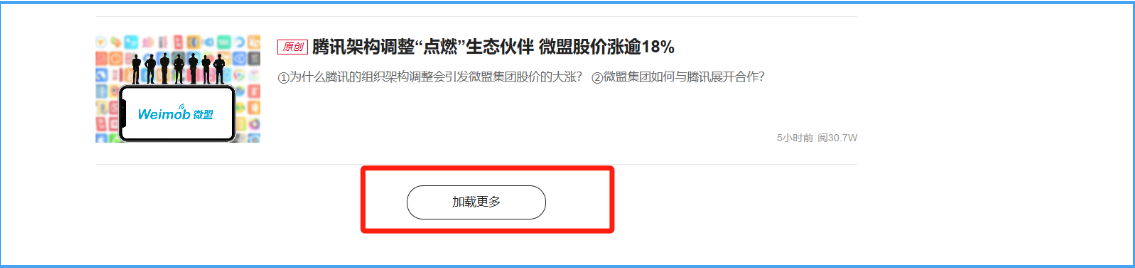
要想爬取全部头条数据得使用selenium模拟人工点击到加载完成才能获取。
2、创建项目
新建项目
首先新建一个Scrapy项目,名字叫做financeSpider,创建命令如下(在base环境中执行):
(看过上个博客已经创建过项目的不需要再创建)
scrapy startproject financeSpider接下来进入项目,然后新建一个Spider,名称cls_finance,命令如下:
cd ./financeSpiderscrapy genspider cls_finance https://www.cls.cn/定义Item(items)
定义需要爬取的字段,在items.py里面定义一个FinancespiderItem,代码如下(比上个博客的数据结构多了个news_source字段,记录文章来源的)
class FinancespiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() source=scrapy.Field() source_url= scrapy.Field() title = scrapy.Field() link = scrapy.Field() content = scrapy.Field() news_source = scrapy.Field() update_time = scrapy.Field()mysql建表
建表并给url列设为唯一,ddl命令如下
CREATE TABLE if not exists finance_news ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, -- ✅ 自增ID(无符号整数) url VARCHAR(255) NOT NULL UNIQUE COMMENT \'新闻url\', -- ✅ 唯一URL( title VARCHAR(255) COMMENT \'新闻标题\', source VARCHAR(255) COMMENT \'新闻来源网站\', source_url VARCHAR(255) COMMENT \'来源url\', content TEXT COMMENT \'新闻内容\', news_source VARCHAR(255) COMMENT \'新闻来源\', update_time VARCHAR(255) COMMENT \'新闻更新时间\', dt DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'数据写入时间\', -- ✅ 时间戳(自动记录时间) -- 可选:添加普通索引(根据查询需求) INDEX idx_dt (dt) -- 如果经常按时间查询可加索引) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;# 加唯一索引ALTER TABLE finance_newsADD UNIQUE INDEX idx_unique_url (url);3、selenium模拟用户点击网页并加载更多(middlewares)
在middlewares文件中,新建selenium下载中间件(middlewares),完整代码如下
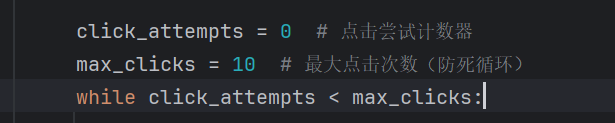
class SeleniumMiddleware: def process_request(self, request, spider): # 检查是否需要使用Selenium,默认关闭 if not request.meta.get(\'use_selenium\', False): return None # 继续正常处理 # 配置浏览器参数 chrome_options = Options() # chrome_options.add_argument(\"--ignore-certificate-errors\") # 忽略 SSL 证书错误 # chrome_options.add_argument(\'--ignore-ssl-errors\') chrome_options.add_argument(\'--headless\') # 无头模式 driver = webdriver.Chrome(options=chrome_options) try: driver.get(request.url) click_attempts = 0 # 点击尝试计数器 max_clicks = 10 # 最大点击次数(防死循环) while click_attempts < max_clicks: try: # 等待“加载更多”按钮出现 wait = WebDriverWait(driver, 10) load_more_button = wait.until(EC.presence_of_element_located( (By.XPATH, \"//div[contains(@class, \'list-more-button\') andcontains(text(), \'加载更多\')]\"))) # 点击“加载更多”按钮 # 做个有点击按钮的判断,没有就退出循环 if load_more_button: load_more_button.click() else: print (\"没有找到加载更多按钮\") break # 强制等待动态内容加载(根据网络情况调整) time.sleep(3) click_attempts += 1 except (NoSuchElementException, TimeoutException): print(\"已经加载到最后\") break # 获取完整渲染后的页面源码 body = driver.page_source return HtmlResponse(url=driver.current_url, body=body, encoding=\'utf-8\') finally: driver.quit()代码重点解析:
- 模拟点击加载更多按钮,因为要点击多次设置了while循环,以防发生死循环所以做了个最大值限制
- selenium耗内存,下载效率慢,所以在request设置了开启和关闭标签,

- 一定要记得及时关闭浏览器,释放内存
4、管道文件(Pipelines)
mysql存储
把数据写入mysql数据库(同上一篇博客)
import pymysqlfrom itemadapter import ItemAdapterfrom scrapy.exceptions import DropItemclass MySQLPipeline: def __init__(self, host, port, user, password, db, charset): self.host = host self.port = port self.user = user self.password = password self.db = db self.charset = charset self.connection = None self.cursor = None @classmethod def from_crawler(cls, crawler): return cls( host=crawler.settings.get(\'MYSQL_HOST\'), port=crawler.settings.get(\'MYSQL_PORT\'), user=crawler.settings.get(\'MYSQL_USER\'), password=crawler.settings.get(\'MYSQL_PASSWORD\'), db=crawler.settings.get(\'MYSQL_DATABASE\'), charset=crawler.settings.get(\'MYSQL_CHARSET\') ) def open_spider(self, spider): \"\"\"连接数据库\"\"\" self.connection = pymysql.connect( host=self.host, port=self.port, user=self.user, password=self.password, db=self.db, charset=self.charset, cursorclass=pymysql.cursors.DictCursor ) self.cursor = self.connection.cursor() def close_spider(self, spider): \"\"\"关闭连接\"\"\" self.connection.close() def process_item(self, item, spider): \"\"\"处理Item\"\"\" try: # 构建SQL语句(根据你的表结构修改) sql = \"\"\" INSERT INTO finance_news( url, title, source, source_url, content, news_source, update_time ) VALUES ( %s, %s, %s, %s, %s , %s, %s ) ON DUPLICATE KEY UPDATE title = VALUES(title), source = VALUES(source), source_url = VALUES(source_url), content = VALUES(content), news_source = VALUES(news_source), update_time = VALUES(update_time);\"\"\" params = (item[\"link\"],item[\"title\"],item[\"source\"],item[\"source_url\"],item[\"content\"],item[\"news_source\"],item[\"update_time\"]) # 从item提取数据(字段名需要对应) self.cursor.execute(sql,params) self.connection.commit() except Exception as e: self.connection.rollback() raise DropItem(f\"Error saving item to MySQL: {str(e)}\") return itemCSV存储
没有mysql的可以用本地文件存储数据
import csvfrom itemadapter import ItemAdapterimport datetime# 获取当前日期today = datetime.date.today()class FinanceCsvPipeline(object): def process_item(self, item, spider): with open(f\"finance_news_{today}.csv\", \"a+\", encoding=\"utf-8\") as f: w = csv.writer(f) row=item[\"link\"],item[\"title\"],item[\"source\"],item[\"source_url\"],item[\"content\"],item[\"news_source\"],item[\"update_time\"] w.writerow(row) return item做完pipelines文件修改后,一定要记得修改配置文件(settings)的ITEM_PIPELINES
5、配置文件(settings)
*重点修改
释放DOWNLOADER_MIDDLEWARES
DOWNLOADER_MIDDLEWARES = {
\"financeSpider.middlewares.FinancespiderSpiderMiddleware\": 543,#原来的
\"financeSpider.middlewares.SeleniumMiddleware\": 600 #新建的selenium中间件
}
#根据自己存储的具体情况修改
ITEM_PIPELINES = {
# \"financeSpider.pipelines.FinanceSpiderPipeline\": 300,
#存储在本地文件csv
#\"financeSpider.pipelines.FinanceCsvPipeline\": 300,
#存储在mysql数据库
\"financeSpider.pipelines.MySQLPipeline\": 300,
}
数字代码级别,级别越低优先级越高
完整代码如下(其他配置同上一篇博客):
BOT_NAME = \"financeSpider\"SPIDER_MODULES = [\"financeSpider.spiders\"]NEWSPIDER_MODULE = \"financeSpider.spiders\"#修改请求头,可以弄得完整点,这个是全局配置,spider请求的时候不需要加# Override the default request headers:DEFAULT_REQUEST_HEADERS = { \'Accept\': \'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8\', \'accept-encoding\': \'gzip, deflate, br, zstd\', \'Accept-Language\': \'zh-CN,zh;q=0.9\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\'}#下载中间件DOWNLOADER_MIDDLEWARES = { \"financeSpider.middlewares.FinancespiderSpiderMiddleware\": 543, \"financeSpider.middlewares.SeleniumMiddleware\": 600 }#mysql的配置参数根据自己的mysql地址修改# mysql SETTING========MYSQL_HOST=\'192.168.X.XX\'MYSQL_PORT=3306MYSQL_USER=\'root\'MYSQL_PASSWORD=\'123456\'MYSQL_DATABASE = \'finance\'MYSQL_CHARSET=\'utf8mb4\'# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { # \"financeSpider.pipelines.FinanceSpiderPipeline\": 300, #存储在csv文件 #\"financeSpider.pipelines.FinanceCsvPipeline\": 300, #存储在mysql数据库 \"financeSpider.pipelines.MySQLPipeline\": 300,}#推荐加上的配置参数ROBOTSTXT_OBEY = FalseRETRY_HTTP_CODES = [401, 403, 500, 502, 503, 504]CONCURRENT_REQUESTS = 106、爬虫文件(cls_finance)
import scrapyimport timefrom bs4 import BeautifulSoupfrom financeSpider.items import FinancespiderItem# 爬取财联社的头条新闻,模拟人类点击加载更多 https://www.cls.cn/depth?id=1000 使用selenium + Beautifulsoup技术 scrapy crawl cls_financeclass ClsFinanceSpider(scrapy.Spider): name = \"cls_finance\" allowed_domains = [\"cls.cn\"] start_urls = [\"https://www.cls.cn/\"] #因为要使用selenium重写请求首页 def start_requests(self): url=\"https://www.cls.cn/depth?id=1000\" yield scrapy.Request(url=url,meta={\"use_selenium\":True},callback=self.parse) # 标记需要处理 只有需要selenium的时候标记,默认不用 def parse(self, response): soup = BeautifulSoup(response.text, \'lxml\') # print (soup) # 用css模糊匹配 items = soup.select(\'div[class*=\"subject-interest-list\"]\') # print (items) for t in items: item = FinancespiderItem() item[\'source\'] = \'财联社\' item[\'source_url\'] = response.url item[\'title\'] = t.select_one(\'div[class*=\"subject-interest-title\"]\').text.replace(\'原创\', \'\').strip() item[\'link\'] = \"https://www.cls.cn\" + t.a[\'href\'] # print(item[\'link\'] ) # print (item[\'title\']) time.sleep(1) yield scrapy.Request(url=item[\'link\'], meta={\"item\": item}, callback=self.parse1) def parse1(self, response): item = response.meta[\'item\'] soup = BeautifulSoup(response.text, \'lxml\') print(\"正在抓取内容\") # 声明变量并赋值,这样能在解析异常的时候还能正常入表,以防数据丢失 content = \"none\" dt = \"none\" source = \"none\" # 文本解析异常处理 try: content = soup.select_one(\'div[class*=\"detail-content\"]\').text.strip() dt = soup.select_one(\'div[class=\"f-l m-r-10\"]\').text.strip()[0:16] source = soup.select_one(\'div[class=\"f-l\"]\').text.strip() except AttributeError as e: print (f\"{e}:文本解析报错\") item[\"content\"] = content item[\'update_time\']=dt item[\'news_source\'] =source # # print (item[\"content\"] +\"\\t\"+item[\'update_time\']) yield item7、运行测试
在base环境,写入命令
scrapy crawl cls_finance运行结果如下:
最后运行完的结果 :
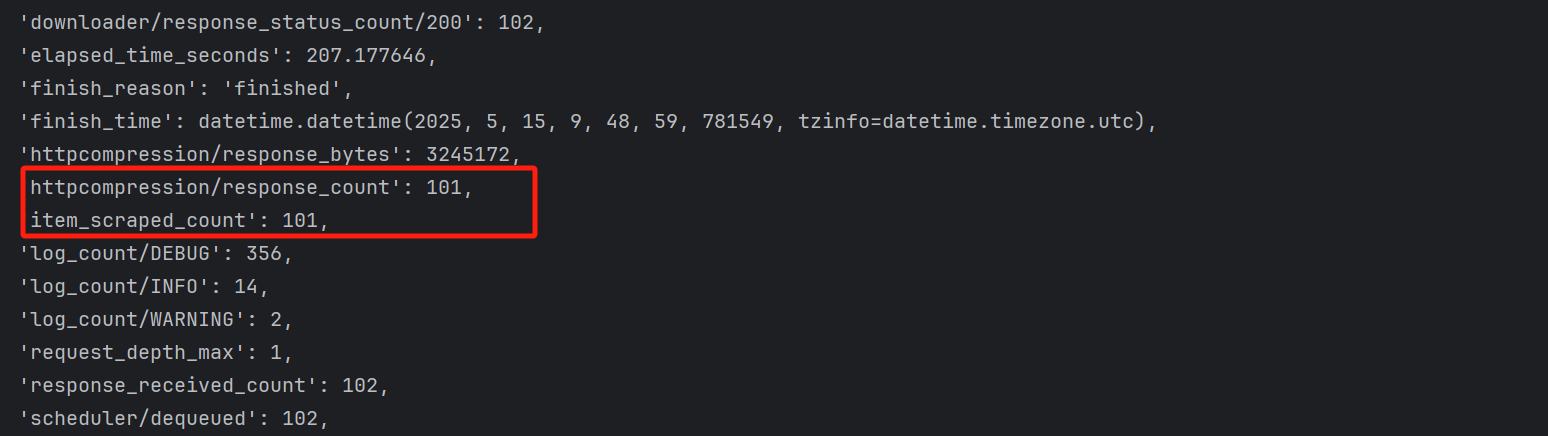
101条新闻全部爬取成功。
数据结果如下:

我们已经可以用scrapy+selenium成功爬取数据啦!
………………………………………………………………………………………………………………
大家有什么优化或者建议欢迎评论区告诉我,我们一起共同进步,谢谢!

