Unity-ECS详解_unity ecs
今天我们来了解Unity最先进的技术——ECS架构(EntityComponentSystem)。
Unity官方下有源码,我们下载源码后来学习。
ECS
与OOP(Object-Oriented Programming)对应,ECS是一种完全不同的编程范式与数据架构,ECS(实体-组件-系统)以数据驱动为核心,通过组合与分离逻辑提升性能,适用于高并发场景。
总的来说,如果场景内有大量的对象或者数据需要处理,我们就可以用ECS来完成以大大提高计算效率。
当然,这里还是要提一嘴相关概念,关于DOTS:

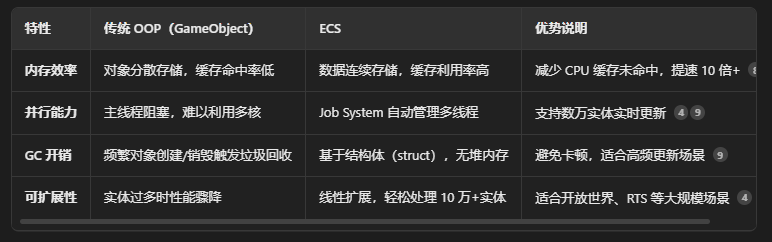
DOTS是以ECS为骨架、Job System为肌肉、Burst为加速引擎的高性能开发生态。它通过数据连续存储(ECS)、多线程调度(Job)和机器码编译(Burst),解决了传统游戏开发中内存碎片化、多核利用率低、GC卡顿三大痛点,尤其适用于开放世界/RTS/大规模模拟场景。
Unity提供的源码下载下来后长这样:
由于内容过多,就不一一展开细说了,我们主要来学习这个Dots101的内容:这是一个帮助我们快速入门的项目示例文件夹。
Dots101
我们先从最基础的Dots101开始吧,这个文件夹的内容就是帮助我们快速理解和上手Dots的。
不过话说回来居然要求Unity6000.0.32,版本要求这么高干嘛?
可以看到Dots101里就包含了Entities,Jobs,Netcode,Physics和一些其他内容的示例,是一个精华版的ECS架构展示。
Entities101
关于Entities:在Unity DOTS中,Entities是实现数据与逻辑分离的核心手段,其核心目标是通过连续内存存储优化CPU缓存命中率和并行效率。

首先ECS的分工是这样的:E就是实体——作为一个标识符,并不存储任何信息,C则是组件,专门负责存储数据,S是系统,用来处理所有的复杂逻辑。在ECS的底层中,会根据实体的组件组成来划分不同的原型分类,每一个内存块,也就是chunk,就只对应一个原型分类。当我们需要访问数据时,我们先根据实体ID找到原型分类后再找到对应的chunk。
这个文件夹里给了四个学习的示例:
分别是消防队员救火,生成方块,踢球小游戏和龙卷风模拟。
消防员救火:
首先这个示例中做了一个对比:主线程 vs 单线程作业 vs 并行作业的对比。
private void HeatSpread_MainThread(ref SystemState state, DynamicBuffer heatBuffer, Config config) { var heatRW = heatBuffer; NativeArray heatRO = heatBuffer.ToNativeArray(Allocator.Temp); var speed = SystemAPI.Time.DeltaTime * config.HeatSpreadSpeed; int numColumns = config.GroundNumColumns; int numRows = config.GroundNumRows; for (int index = 0; index < heatRO.Length; index++) { int row = index / numColumns; int col = index % numRows; var prevCol = col - 1; var nextCol = col + 1; var prevRow = row - 1; var nextRow = row + 1; float increase = 0; increase += Index(row, nextCol, heatRO, numColumns, numRows); increase += Index(row, prevCol, heatRO, numColumns, numRows); increase += Index(prevRow, prevCol, heatRO, numColumns, numRows); increase += Index(prevRow, col, heatRO, numColumns, numRows); increase += Index(prevRow, nextCol, heatRO, numColumns, numRows); increase += Index(nextRow, prevCol, heatRO, numColumns, numRows); increase += Index(nextRow, col, heatRO, numColumns, numRows); increase += Index(nextRow, nextCol, heatRO, numColumns, numRows); increase *= speed; heatRW[index] = new Heat { Value = math.min(1, heatRO[index].Value + increase) }; } }这是主线程的实现。
[BurstCompile] public struct HeatSpreadJob_SingleThreaded : IJob { public NativeArray heatRW; [ReadOnly] public NativeArray heatRO; public float HeatSpreadSpeed; public int NumColumns; public int NumRows; public void Execute() { for (int index = 0; index < heatRO.Length; index++) { int row = index / NumColumns; int col = index % NumColumns; var prevCol = col - 1; var nextCol = col + 1; var prevRow = row - 1; var nextRow = row + 1; float increase = 0; increase += Index(row, nextCol); increase += Index(row, prevCol); increase += Index(prevRow, prevCol); increase += Index(prevRow, col); increase += Index(prevRow, nextCol); increase += Index(nextRow, prevCol); increase += Index(nextRow, col); increase += Index(nextRow, nextCol); increase *= HeatSpreadSpeed; heatRW[index] = new Heat { Value = math.min(1, heatRO[index].Value + increase) }; } } private float Index(int row, int col) { if (col = NumColumns || row = NumRows) { return 0; } return heatRO[row * NumColumns + col].Value; } }这是单线程实现(但是Burst编译器优化)。
[BurstCompile] public struct HeatSpreadJob_Parallel : IJobParallelFor { public NativeArray heatRW; [ReadOnly] public NativeArray heatRO; public float HeatSpreadSpeed; public int NumColumns; public int NumRows; public void Execute(int index) { int row = index / NumColumns; int col = index % NumColumns; var prevCol = col - 1; var nextCol = col + 1; var prevRow = row - 1; var nextRow = row + 1; float increase = 0; increase += Index(row, nextCol); increase += Index(row, prevCol); increase += Index(prevRow, prevCol); increase += Index(prevRow, col); increase += Index(prevRow, nextCol); increase += Index(nextRow, prevCol); increase += Index(nextRow, col); increase += Index(nextRow, nextCol); increase *= HeatSpreadSpeed; heatRW[index] = new Heat { Value = math.min(1, heatRO[index].Value + increase) }; } private float Index(int row, int col) { if (col = NumColumns || row = NumRows) { return 0; } return heatRO[row * NumColumns + col].Value; } }这个就是并行处理的实现,同样是Burst编译器优化。
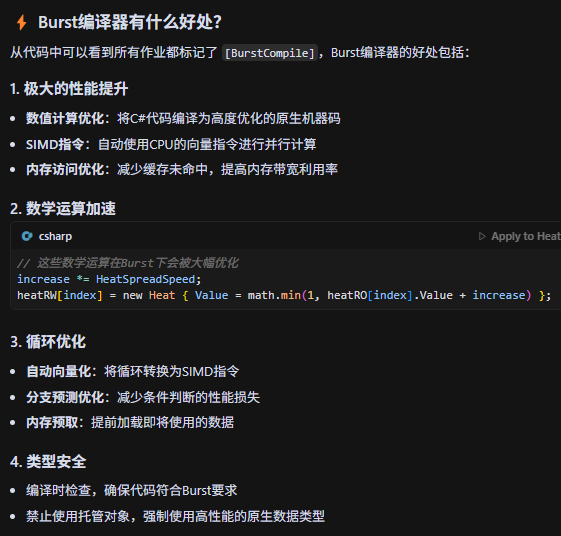
Burst 编译器是 Unity DOTS(数据导向技术栈)中的高性能代码优化引擎,专为大规模数据计算设计,通过将 C# 代码编译为高度优化的机器码,显著提升并行计算效率。
关于这个SIMD指令:SIMD(Single Instruction, Multiple Data,单指令多数据流)是一种并行计算技术,允许CPU用一条指令同时对多个数据元素执行相同的操作,从而大幅提升数据处理效率。
关于Burst编译器,我们至少要了解他是一个在大密度大数量高性能计算场景下非常厉害的编译器即可。

前面提到了三种处理方式:主线程、单线程和并行,如何看出三者的性能差距呢?
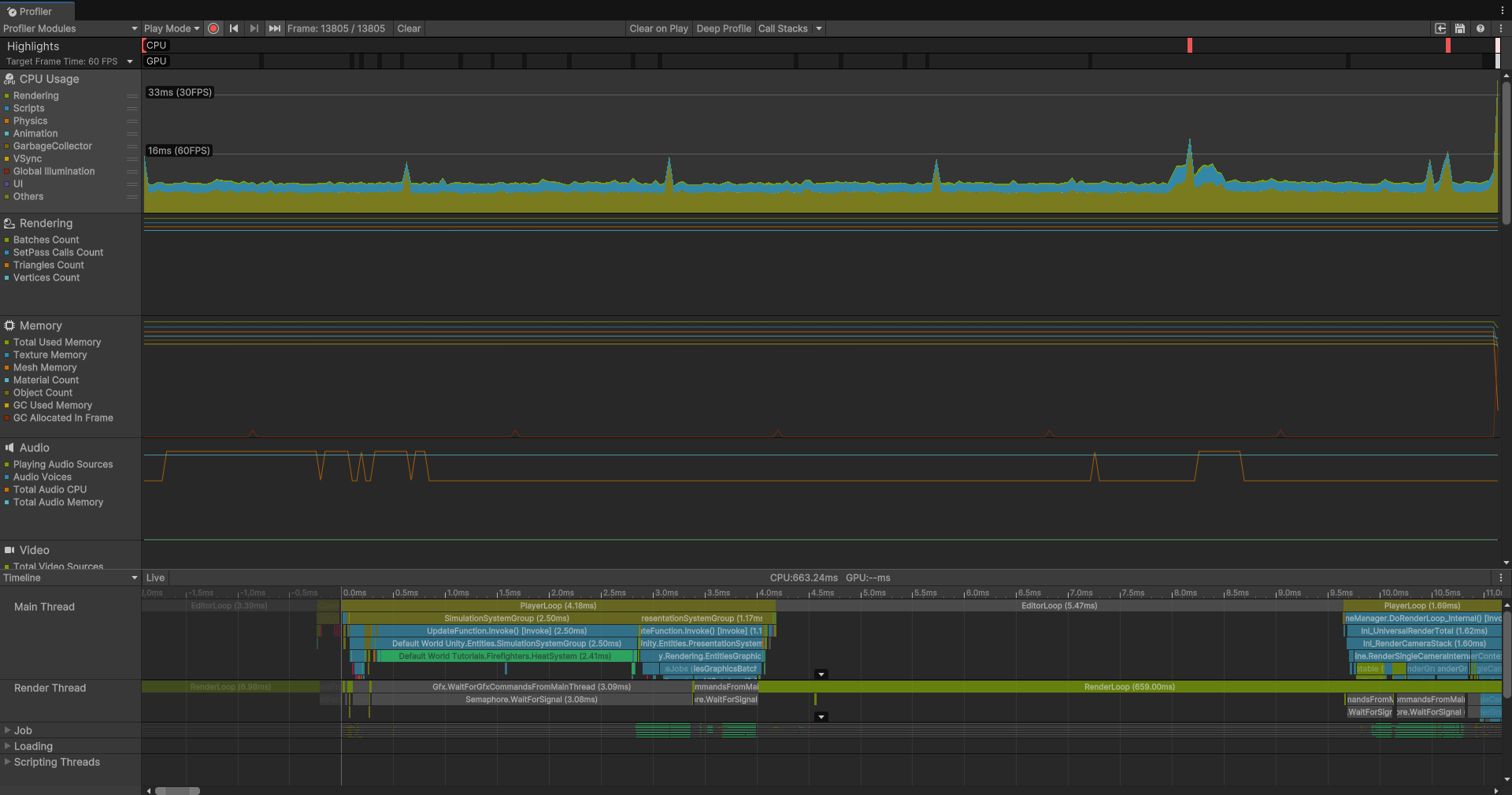
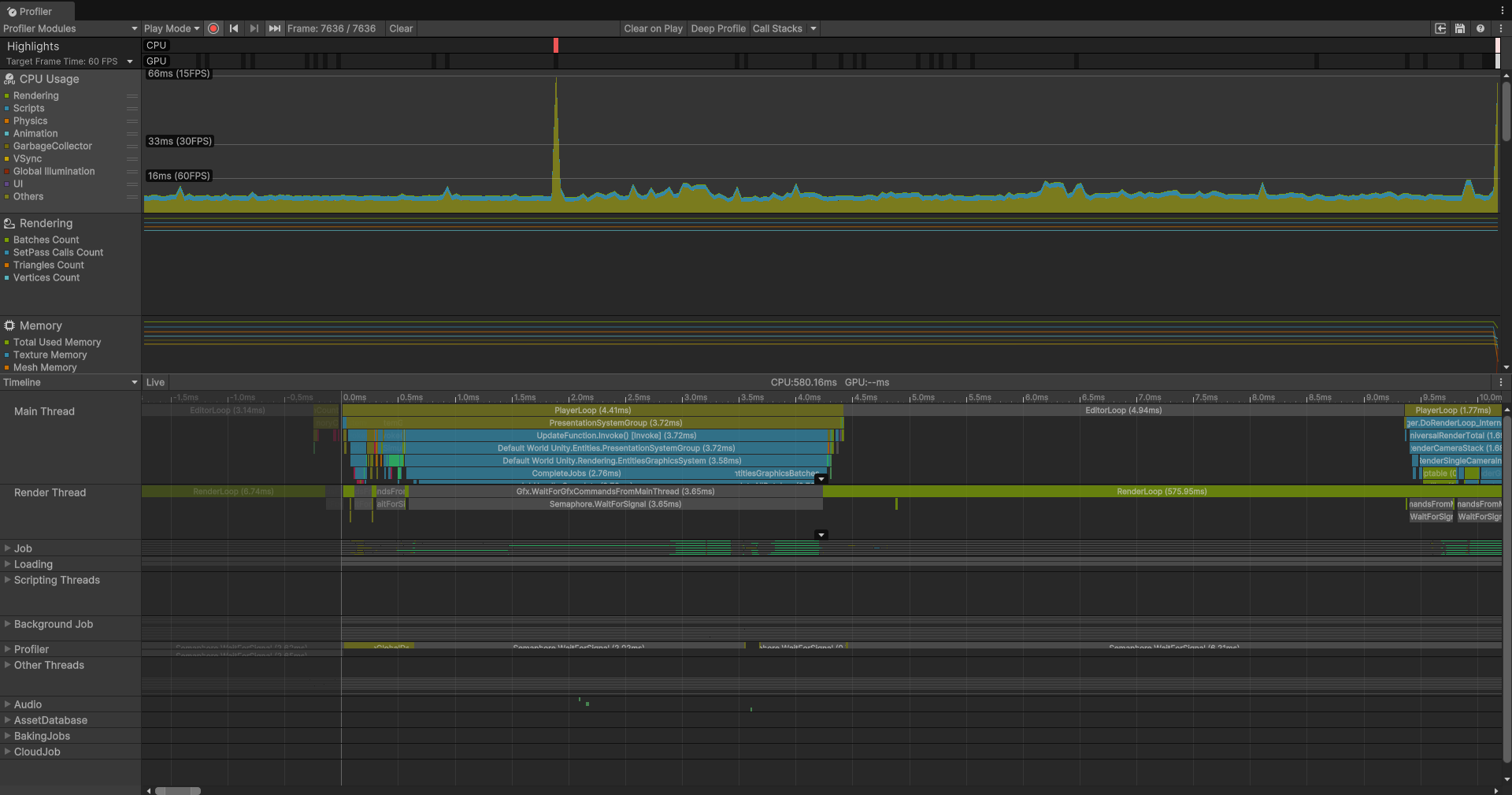
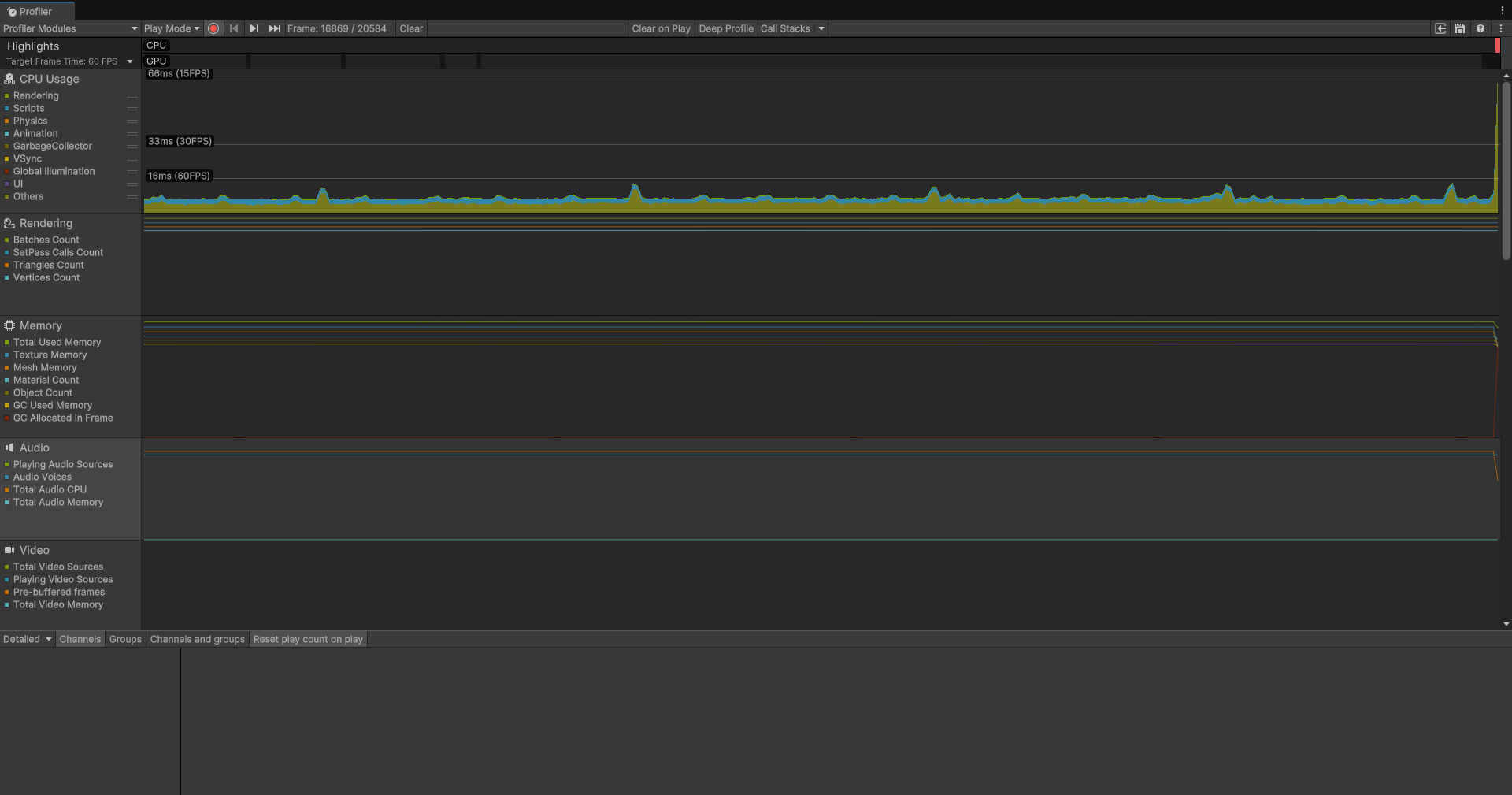
这就是三种处理方式的Profiler的性能表现:

可见当我们需要大规模的计算和生成时,并行处理是最好的选择,在Unity中,有专门这样一个库负责处理大规模并行任务:
还有值得一提的是:Unity 的 Jobs 库(Job System) 是专门针对 CPU 多核并行计算 设计的,而 GPU 无法直接执行 Job System 的任务,这是由两者的硬件架构和执行逻辑的差异决定的。Job System 是 Unity 提供的 多线程任务调度框架,旨在将计算密集型任务(如物理模拟、AI 决策)拆分为子任务,分配到多个 CPU 核心并行执行,其设计目标是最大化 CPU 多核利用率,避免主线程阻塞。
然后是这个HelloCubes示例:
HelloCube通过ECS架构实现高效的大量立方体生成:首先在场景中配置SpawnerAuthoring组件并引用立方体预制体,烘焙时转换为ECS的Spawner组件;然后SpawnSystem检测到场景中没有立方体时,使用EntityManager.Instantiate(prefab, 500, Allocator.Temp)一次性批量生成500个实体;接着通过并行作业为每个立方体设置随机位置,使用独立的随机种子确保线程安全;立方体在FallAndDestroySystem中旋转下落,当Y坐标小于0时通过EntityCommandBuffer延迟销毁;最后当所有立方体被销毁后,SpawnSystem再次检测到场景为空,重新开始生成循环,形成一个持续的\"生成→下落→销毁→重新生成\"的高性能循环系统。
Spawner组件负责存储GameObject由Baker转换而来的Entity引用,Entity物体就可以被EntityManager来实现大批量生成的效果;EntityCommandBuffer则是一个命令缓冲区,在这个区会缓冲一系列我们对于Entity物体的命令。
效果如图:
Jobs101
Unity Job System 是 Unity 引擎提供的一套多线程任务调度框架,旨在通过并行化计算密集型任务,充分利用多核 CPU 性能,提升游戏运行效率并降低主线程压力。
现代 CPU 普遍拥有多核心,但传统 Unity 代码默认运行在主线程,无法充分利用多核资源,而Job System 将任务拆分为小单元(Job),分配到多个 CPU 核心并行执行,显著提升计算效率。
在官方的示例代码中,我们的Jobs101生成了大量的方块,蓝色方块(Seeker)会去寻找最近红色方块(Target)。
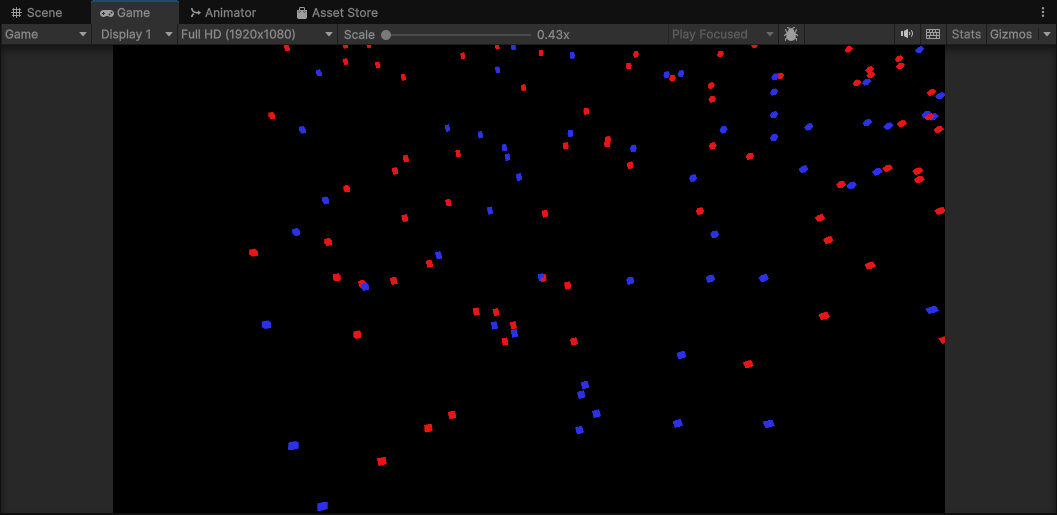
我们用四种方法来实现这个效果并比较性能:
首先是无Job,全部主线程暴力遍历:
// 在MonoBehaviour的Update里foreach (var seeker in seekers){ float minDist = float.MaxValue; Vector3 nearest = Vector3.zero; foreach (var target in targets) { float dist = Vector3.Distance(seeker.position, target.position); if (dist < minDist) { minDist = dist; nearest = target.position; } } // 画线 Debug.DrawLine(seeker.position, nearest, Color.white);}相信不用我多说都知道有多慢,首先只用主线程就很糟糕了,这个暴力的时间复杂度不知道是On多少了都,不卡是不可能的,Profiler效果如下:
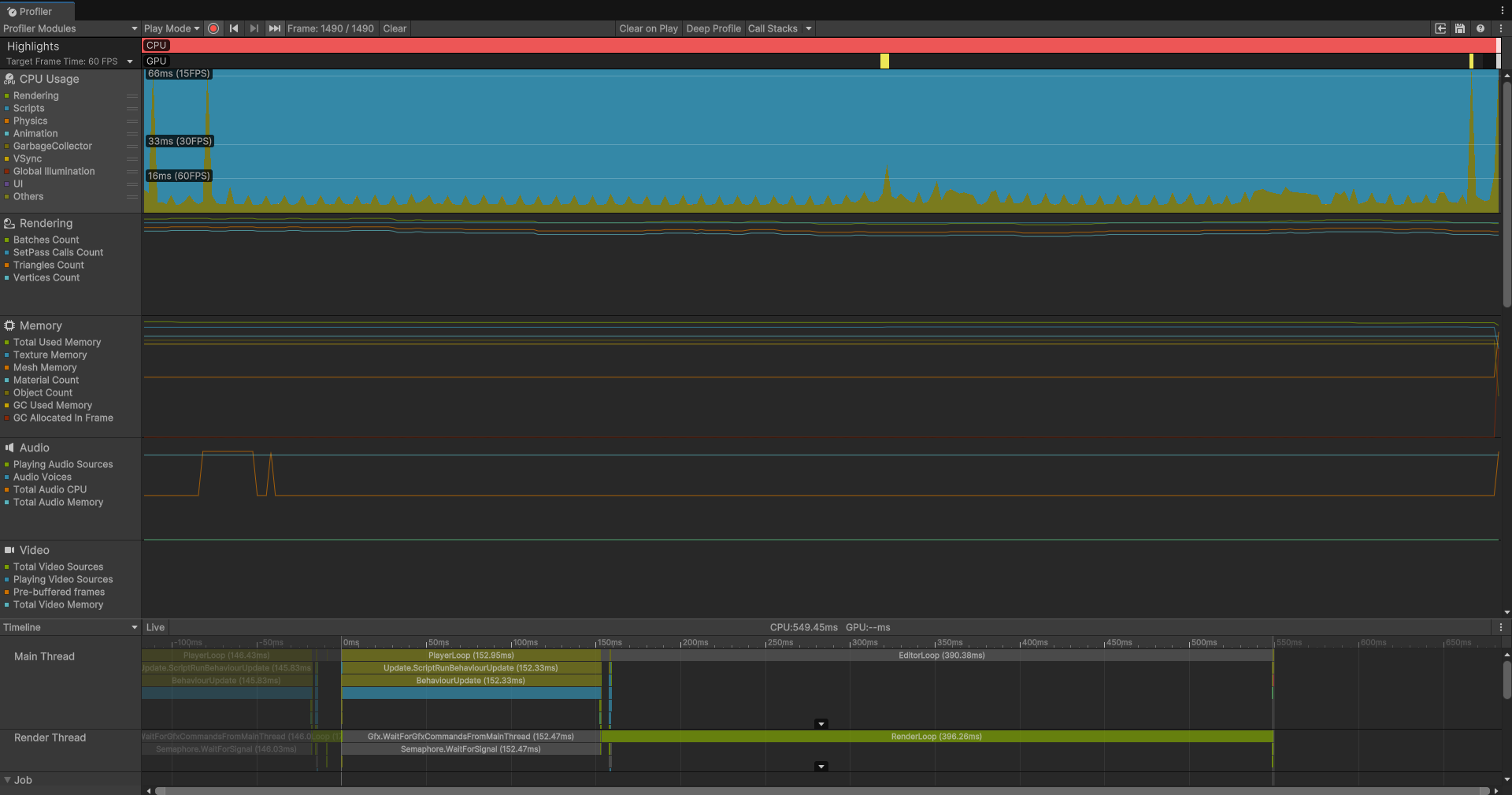
别的不说,就这大片大片的蓝色,这糟糕的帧数,体验有多差可想而知。(蓝色表示CPU的主要开销来源是Scripts,也就是脚本)。
然后是单线程Job:
public struct FindNearestJob : IJob{ [ReadOnly] public NativeArray TargetPositions; [ReadOnly] public NativeArray SeekerPositions; public NativeArray NearestTargetPositions; public void Execute() { for (int i = 0; i < SeekerPositions.Length; i++) { float minDist = float.MaxValue; float3 nearest = float3.zero; for (int j = 0; j < TargetPositions.Length; j++) { float dist = math.distance(SeekerPositions[i], TargetPositions[j]); if (dist < minDist) { minDist = dist; nearest = TargetPositions[j]; } } NearestTargetPositions[i] = nearest; } }}可以看到我们的方法基于IJob的接口实现,实现这个接口的方法会默认将我们的任务放在Job System分配的工作线程上,而Job System是和我们的Burst编译器深度集成的,我们基于Job System分配的任务就可以去使用Burst编译器进行加速了。
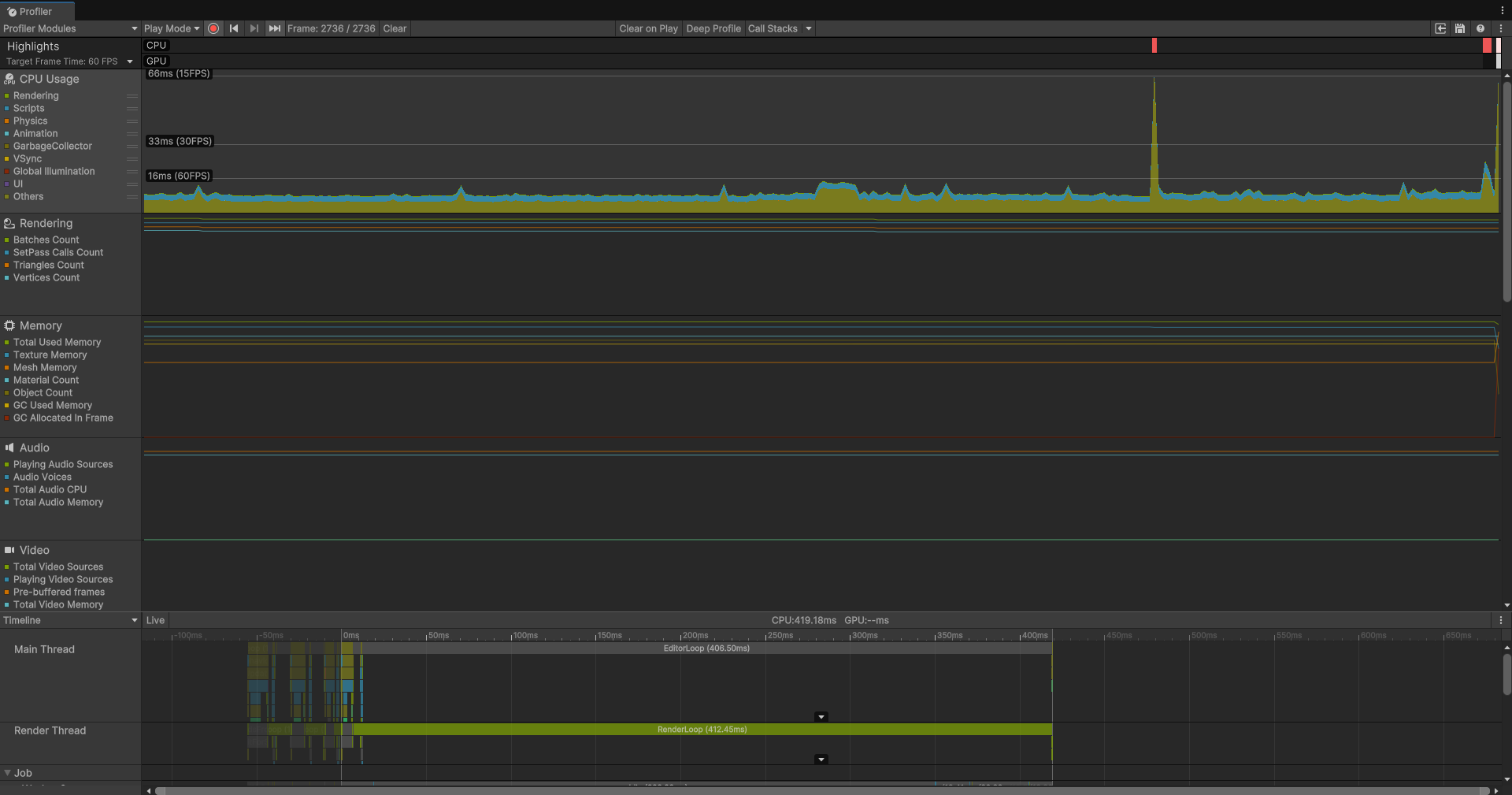
可以看到单线程Job的效果就非常好了,首先帧数大大提高,然后可以看到CPU开销主要的来源都是渲染相关的准备。
我们在这个基础上加入并行:并行Job。
用IJobParallelFor,每个Seeker的查找任务分配到不同线程,充分利用多核CPU,极大提升速度。
public struct FindNearestJob : IJobParallelFor{ [ReadOnly] public NativeArray TargetPositions; [ReadOnly] public NativeArray SeekerPositions; public NativeArray NearestTargetPositions; public void Execute(int i) { float minDist = float.MaxValue; float3 nearest = float3.zero; for (int j = 0; j < TargetPositions.Length; j++) { float dist = math.distance(SeekerPositions[i], TargetPositions[j]); if (dist < minDist) { minDist = dist; nearest = TargetPositions[j]; } } NearestTargetPositions[i] = nearest; }}效果如下: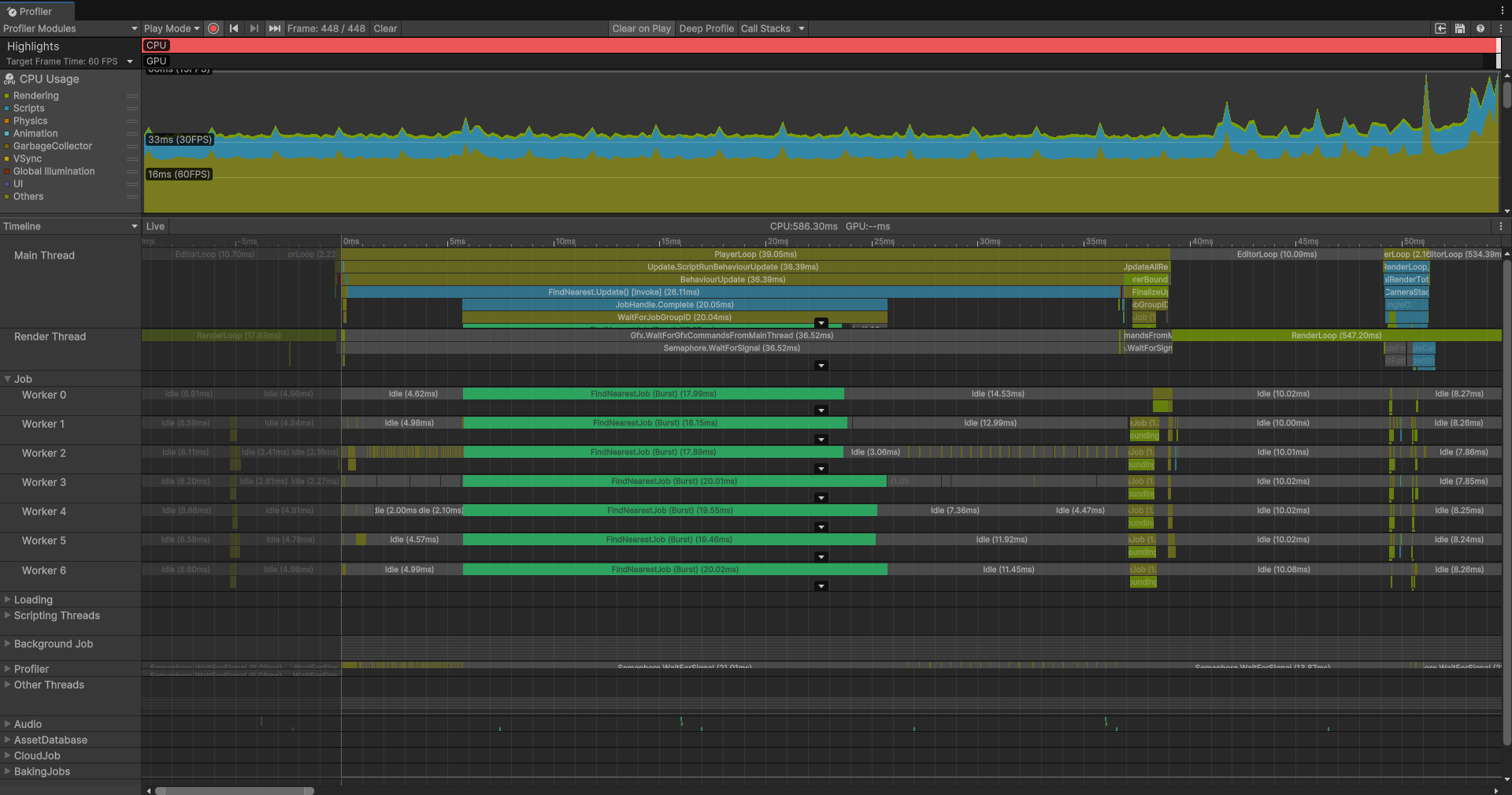
可以看到并行开启后,更多的worker出现了,但是我们会发现总的CPU开销反而还在提高——这显然是反常识的,我也感觉非常奇怪,那么出现这种现象的只有一种说法就是:线程的切换和调度的开销改过了本身利用CPU的多核提高效率的改善,尤其是当单个Job工作量其实不大时。还有一个点就是虽然我们充分利用了CPU,但是我们没有去改善算法,那么时间复杂度依然很爆炸。
所以我们需要最后的做法:并行Job + 优化算法(空间分区/排序)
using System.Collections.Generic;using Unity.Burst;using Unity.Collections;using Unity.Jobs;using Unity.Mathematics;namespace Tutorials.Jobs.Step4{ [BurstCompile] public struct FindNearestJob : IJobParallelFor { [ReadOnly] public NativeArray TargetPositions; // 已按X排序 [ReadOnly] public NativeArray SeekerPositions; public NativeArray NearestTargetPositions; public void Execute(int index) { float3 seekerPos = SeekerPositions[index]; // 1. 二分查找X坐标最近的Target int startIdx = TargetPositions.BinarySearch(seekerPos, new AxisXComparer { }); // 2. 处理未精确命中情况 if (startIdx = TargetPositions.Length) startIdx = TargetPositions.Length - 1; float3 nearestTargetPos = TargetPositions[startIdx]; float nearestDistSq = math.distancesq(seekerPos, nearestTargetPos); // 3. 向右查找 Search(seekerPos, startIdx + 1, TargetPositions.Length, +1, ref nearestTargetPos, ref nearestDistSq); // 4. 向左查找 Search(seekerPos, startIdx - 1, -1, -1, ref nearestTargetPos, ref nearestDistSq); NearestTargetPositions[index] = nearestTargetPos; } // 辅助查找函数 void Search(float3 seekerPos, int startIdx, int endIdx, int step, ref float3 nearestTargetPos, ref float nearestDistSq) { for (int i = startIdx; i != endIdx; i += step) { float3 targetPos = TargetPositions[i]; float xdiff = seekerPos.x - targetPos.x; // X轴距离的平方大于当前最小距离,提前终止 if ((xdiff * xdiff) > nearestDistSq) break; float distSq = math.distancesq(targetPos, seekerPos); if (distSq < nearestDistSq) { nearestDistSq = distSq; nearestTargetPos = targetPos; } } } } // 用于X轴排序的比较器 public struct AxisXComparer : IComparer { public int Compare(float3 a, float3 b) { return a.x.CompareTo(b.x); } }}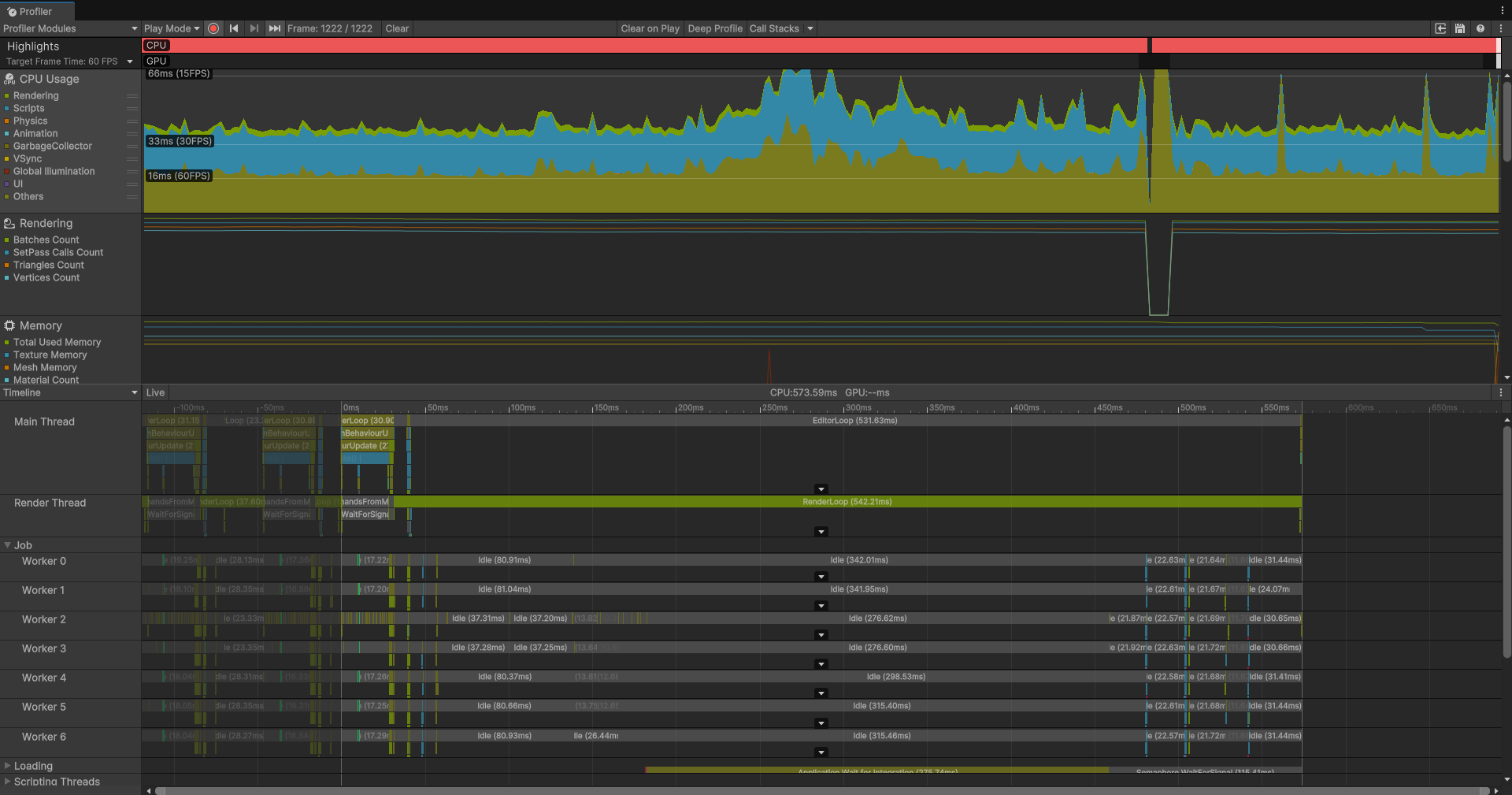
虽然可以看到实际的效果好像不是很好,但至少首先我们的CPU开销渲染的部分降低了而脚本的开销变大了,然后多个线程在同时工作,也算是符合预期吧。
那么从以上的示例可以知道的是:
Job System是一个专门为CPU设计的多线程任务处理器,可以充分利用CPU的多核优势,并且和Burst编译器深度集成,针对大数据计算任务尤其有优势。

首先可以知道的是Job System的底层是一个线程池,但是与传统线程池不同的是,Job System还添加了很多内容:
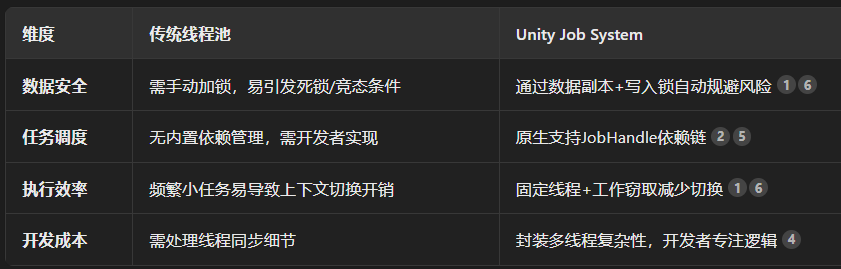
NetCode101
这个示例则是一个具体的ECS架构的使用,一般来说我们来做游戏时:


因为这个示例代码中没有提供基于OOP实现的游戏示例,我们也没法直观地通过Profiler来判断二者的性能差异。
Physics101
终于来到我们真正的目标——物理引擎了。我们之前已经走马观花地看过了PhysX引擎的内容了,现在问题来了:Unity DOTS Physics与PhysX的区别在哪呢?

我们拿两段代码出来比对一下就能看出差别了:
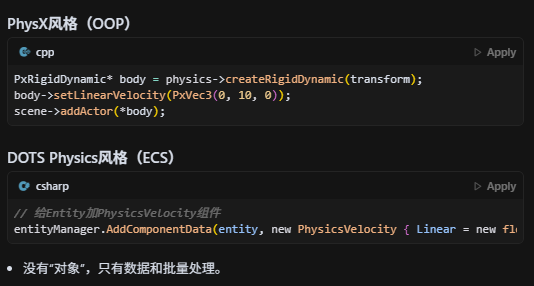
在Dots101中实现了很多物体内容啊,我们来挑几个比较重要的来说说:
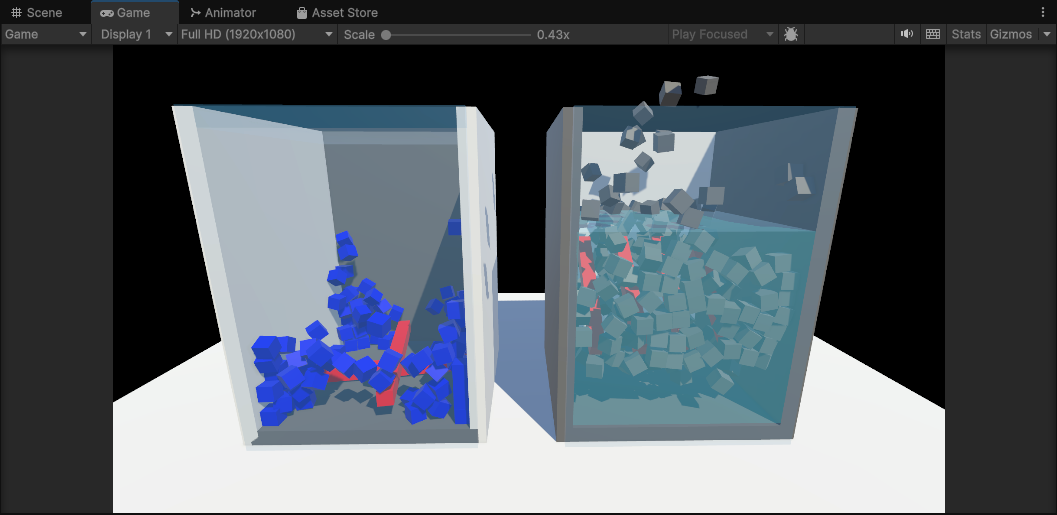
这个示例中模拟了水的浮力以及阻力的效果,以及旋转叶片与旋转叶片的碰撞的效果。
public struct Blade : IComponentData{ public float3 AngularVelocity;}public partial struct RotateBladeSystem : ISystem{ public void OnUpdate(ref SystemState state) { foreach (var (bladeData, velocity) in SystemAPI.Query<RefRO, RefRW>()) { velocity.ValueRW.Angular = bladeData.ValueRO.AngularVelocity; } }}每个叶片是一个Entity,带有Blade组件(包含角速度),系统每帧将Blade.AngularVelocity赋值给PhysicsVelocity.Angular,实现持续旋转。
public struct Buoyancy : IComponentData, IEnableableComponent{ public float WaterLevel; public float BuoyancyForce; public float Drag;}public partial struct BuoyancySystem : ISystem{ public void OnUpdate(ref SystemState state) { foreach (var (buoyant, transform, velocity, mass) in SystemAPI.Query<RefRO, RefRW, RefRW, RefRO>()) { float depth = buoyant.ValueRO.WaterLevel - transform.ValueRW.Position.y; float buoyancyForce = depth * buoyant.ValueRO.BuoyancyForce * deltaTime; velocity.ValueRW.ApplyLinearImpulse(mass.ValueRO, new float3(0, buoyancyForce, 0)); velocity.ValueRW.Linear *= 1.0f - buoyant.ValueRO.Drag * deltaTime; } }}立方体带有Buoyancy组件(包含水面高度、浮力系数、阻力系数),系统每帧计算立方体与水面的相对深度,施加向上的浮力和线性阻力。
public partial struct BuoyancyZoneSystem : ISystem{ public void OnUpdate(ref SystemState state) { // 先禁用所有立方体的浮力 var buoyancyQuery = SystemAPI.QueryBuilder().WithAll().Build(); state.EntityManager.SetComponentEnabled(buoyancyQuery, false); // 监听TriggerEvents,激活进入水区的立方体浮力 var sim = SystemAPI.GetSingleton().AsSimulation(); sim.FinalJobHandle.Complete(); foreach (var triggerEvent in sim.TriggerEvents) { // 判断哪个是立方体,哪个是水区 // ...(省略判断代码) // 复制水区的浮力参数到立方体 cubeBuoyancy.ValueRW = zone.ValueRO.Buoyancy; SystemAPI.SetComponentEnabled(cubeEntity, true); } }}水区是一个带有BuoyancyZone组件的Entity,系统监听物理TriggerEvents(触发事件),当立方体进入水区时,激活其Buoyancy组件并复制水区的浮力参数。
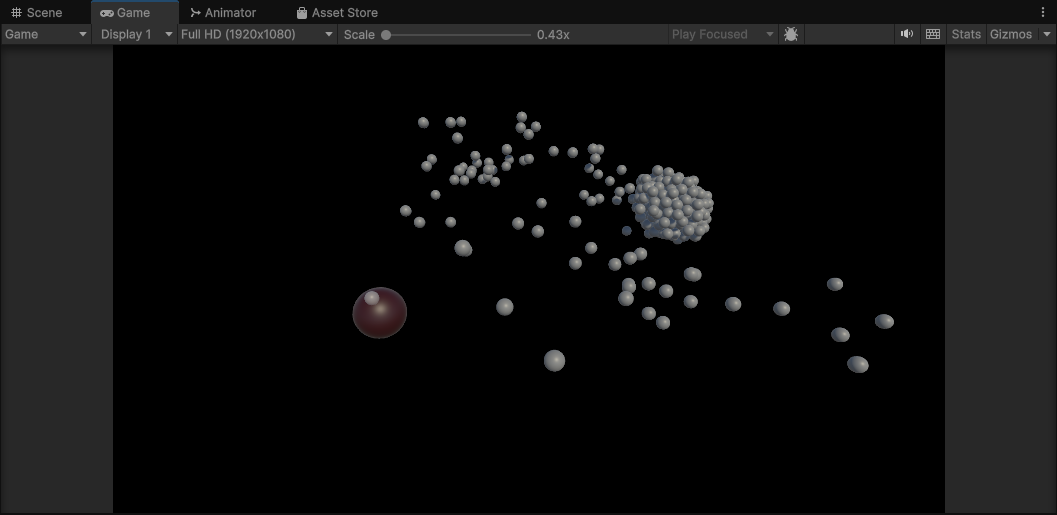
这里是实现了一个重力井的效果,重力井绕着圆心旋转,并不断吸附附近的小球。
// GravityWellSystem.csforeach (var (wellTransform, well) in SystemAPI.Query<RefRW, RefRW>()){ // 让重力井的角度不断增加,实现绕圆心旋转 well.ValueRW.OrbitPos += config.WellOrbitSpeed * dt; math.sincos(well.ValueRW.OrbitPos, out var s, out var c); wellTransform.ValueRW.Position = new float3(c, 0, s) * config.WellOrbitRadius;}这是让重力井实现圆周运动的代码。
// 获取所有重力井的位置var wellQuery = SystemAPI.QueryBuilder().WithAll().Build();var wellTransforms = wellQuery.ToComponentDataArray(Allocator.Temp);// 对每个小球foreach (var (velocity, collider, mass, ballTransform) in SystemAPI.Query<RefRW, RefRO, RefRO, RefRO>()){ // 对每个重力井 for (int i = 0; i < wellTransforms.Length; i++) { var wellTransform = wellTransforms[i]; // 施加“吸引力”,本质是ApplyExplosionForce的负值 velocity.ValueRW.ApplyExplosionForce( mass.ValueRO, collider.ValueRO, ballTransform.ValueRO.Position, ballTransform.ValueRO.Rotation, -config.WellStrength, // 负值=吸引 wellTransform.Position, 0, // 半径为0,表示无限远都有效 dt, math.up()); }}实现吸附。
其他的相关示例还有很多,大家感兴趣的可以自行查阅。
一些问题和补充:
Q:
你为什么选择ECS架构?和传统GameObject方式相比有什么优势?
A:
ECS(Entity Component System)架构是一种相比传统面向对象(OOP)更适合大规模数据处理的编程范式。它将对象拆分为三部分:实体(Entity)、组件(Component)和系统(System)。实体只负责唯一标识,组件用于描述实体的各种功能或属性,而系统则专注于实现具体的业务逻辑和实体间的交互。ECS最大的特点在于,它能够将所有拥有相同组件的实体的数据以连续内存的方式存储,这样不仅显著提升了CPU的缓存命中率和数据访问效率,还能充分利用SIMD(单指令多数据)指令集进行批量处理,因为SIMD要求数据类型一致且内存地址连续。此外,连续内存也极大方便了多线程并行处理(如Unity的Job System),每个线程可以高效地处理一段连续的数据,避免频繁的内存跳转带来的性能损耗。相比之下,传统OOP由于对象结构不统一、内存分散,既不利于批量高效处理,也不便于多线程分工。最后,ECS的解耦设计也让功能扩展变得非常简单,只需添加新的组件和系统即可,无需修改原有代码,极大提升了项目的可维护性和扩展性。因此,ECS架构在需要高性能和大规模实体管理的场景下具有显著优势。
Q:
Boids算法的三大行为分别是如何实现的?如何保证性能?
A:
Boids算法的三大核心行为分别是分离、对齐和聚合。分离是指每个个体之间要保持一定的距离,防止彼此靠得太近,相当于存在一种排斥力;对齐则要求群体中的每个个体尽量与周围邻居的平均移动方向保持一致,实现整体方向的统一;聚合则是让个体靠近邻居的中心,防止个体之间距离过远,相当于存在一种拉力。也就是说,Boids算法通过分离来避免拥挤,通过聚合来防止分散,通过对齐来保持队形一致。
在ECS架构下实现Boids算法有显著优势。首先,所有Boid个体的组件结构是统一的,可以将它们的数据以连续内存的方式存储,这不仅提升了CPU缓存命中率,还便于利用SIMD指令集进行批量加速处理,同时也方便多线程(如Job System)对数据进行高效并行计算。此外,还可以结合空间分区算法(如网格或分块),将Boid划分到不同的区域,每个个体只需遍历本区域内的邻居,极大减少了全量遍历的计算量,从而进一步提升了大规模群体模拟的性能和效率。
Q:
RTS原型中单位的选择和移动是怎么实现的?
A:
在RTS(即时战略)原型中,单位的选择和移动主要通过ECS架构下的组件和系统协作实现:
首先,每个单位实体都会挂载一个“可选中组件”(SelectableComponent),用于标记该单位是否被选中。当玩家用鼠标左键点击单位时,系统会进行射线检测(Raycast),判断鼠标点击位置是否命中某个单位的碰撞体。如果命中,就将该单位的SelectableComponent的“IsSelected”属性设置为true,同时取消其他单位的选中状态,实现多选或单选逻辑。
在我们的RTS原型项目中,单位的拉框多选功能是通过自定义UI与ECS架构结合实现的。具体来说,玩家按下鼠标左键并拖动时,屏幕上会实时绘制一个矩形选择框(通常用UI的RectTransform或OnGUI绘制实现)。当玩家松开鼠标时,系统会将选择框的屏幕区域转换为世界坐标范围,然后遍历所有单位实体,将其世界坐标投影到屏幕空间,判断是否落在选择框内。如果单位在框选范围内,就将其SelectableComponent的“IsSelected”属性设置为true,实现多选效果。
在多选的基础上,玩家右键点击地面时,所有被选中的单位会收到一个MoveCommandComponent,系统会驱动这些单位移动到目标位置。
此外,项目还实现了自动攻击功能。每个单位实体都带有TeamID用于区分阵营。系统会定期检测每个单位周围一定范围内是否有敌方单位(通过TeamID判断),一旦发现敌人,就自动发起攻击,触发扣血、播放攻击动画等逻辑。这一切都是通过ECS的组件和系统解耦实现,逻辑清晰、易于扩展。
Q:
雪地足迹和地形变形是怎么做的?和传统做法有何不同?
A:
在我们的项目中,雪地的实现主要依赖于一张专用的脚印贴图(Footprint Texture)与地形材质的结合。雪地表面本身通过Shader渲染,材质会实时采样这张脚印贴图,根据贴图的灰度值动态调整表面法线、颜色或高度,从而表现出雪地被踩压后的凹陷和变化。当角色在雪地上移动时,系统会在其脚下生成一个脚印实体,这些实体包含位置、半径、强度和持续时间等数据。每一帧,ECS系统会批量遍历所有脚印实体,将它们的影响高效地写入脚印贴图(通常通过GPU的Compute Shader或批量CPU Job实现),形成一个个圆形或椭圆形的压痕。脚印可以设置持续时间,时间到后自动消失,贴图也会逐渐恢复原状,模拟真实的雪地动态。
这种基于ECS的实现方式相比传统做法(如每个脚印单独用GameObject管理或直接逐像素操作贴图)有显著优势。首先,所有脚印数据以组件形式连续存储,便于批量处理和并行计算,极大提升了性能和扩展性;其次,渲染时通过Instancing或合批技术一次性处理所有脚印,显著减少Draw Call和GC压力;最后,数据与逻辑解耦,功能扩展和维护更加灵活高效。整体上,这种方法充分发挥了ECS架构在大规模数据管理、高性能批量处理和系统解耦方面的优势,非常适合需要实时动态变化和高并发场景的雪地脚印效果实现。
Q:
你在项目中遇到的最大技术难题是什么?如何解决的?如何调优ECS项目的性能?有哪些关键点?你如何验证和测试项目的性能?
A:
在项目开发过程中,遇到的最大技术难题是大规模实体间的高效邻域查询,尤其是在Boids群体智能和雪地脚印等需要实时检测邻居或影响范围的场景下。传统的全量遍历方式在实体数量增加时会导致性能急剧下降(O(n²)复杂度);为了解决这个问题,我引入了空间分区技术,比如将场景划分为网格或分块,每个实体只需与同一区域或相邻区域的实体进行交互,大大减少了需要遍历的对象数量。同时,结合ECS的Job System,将邻域查询和行为计算分配到多个线程并行处理,显著提升了整体性能。通过这种方式,即使在上万实体的场景下,系统依然能保持高帧率和流畅体验。
在ECS项目的性能调优过程中,我主要从数据布局、系统拆分、并行计算、空间分区、内存管理和渲染优化等方面入手。首先,确保所有组件数据以结构体数组(SoA)的方式连续存储,这样可以极大提升CPU的缓存命中率和数据访问效率。其次,将复杂的业务逻辑拆分为多个小型系统,避免单一系统成为性能瓶颈。对于大批量计算任务,我充分利用Unity的Job System和Burst编译器,将计算分配到多线程并行处理,并用Burst对关键代码进行底层优化。此外,通过空间分区(如网格或分块)优化邻域查询和碰撞检测,显著减少无效遍历。内存管理方面,采用NativeArray等原生数据结构,避免频繁GC和内存分配,保证帧率稳定。渲染方面,则利用GPU Instancing和合批技术,减少Draw Call数量,提升渲染效率。
在性能调优和验证过程中,Unity Profiler是非常重要的工具。Unity Profiler可以实时监控项目在运行时的各项性能指标,包括CPU和GPU的使用情况、内存分配、GC(垃圾回收)频率、渲染流程、Draw Call数量等。通过Profiler的时间轴视图,可以精确定位每一帧中各个系统和函数的耗时,帮助发现性能瓶颈。Profiler还支持分模块查看,比如详细分析ECS系统、Job System、渲染、物理等子系统的性能表现。


