使用Airflow在k8s集群上轻松搭建企业级工作流_airflow 部署
概述
Apache Airflow 是一个开源的工作流管理平台,用于编写、调度和监控工作流(Workflows)。它最初由 Airbnb 开发,并于 2016 年捐赠给 Apache 软件基金会。Airflow 的核心理念是通过代码来定义工作流,使得工作流的管理和维护更加灵活和可扩展, github社区地址见链接。
整体架构
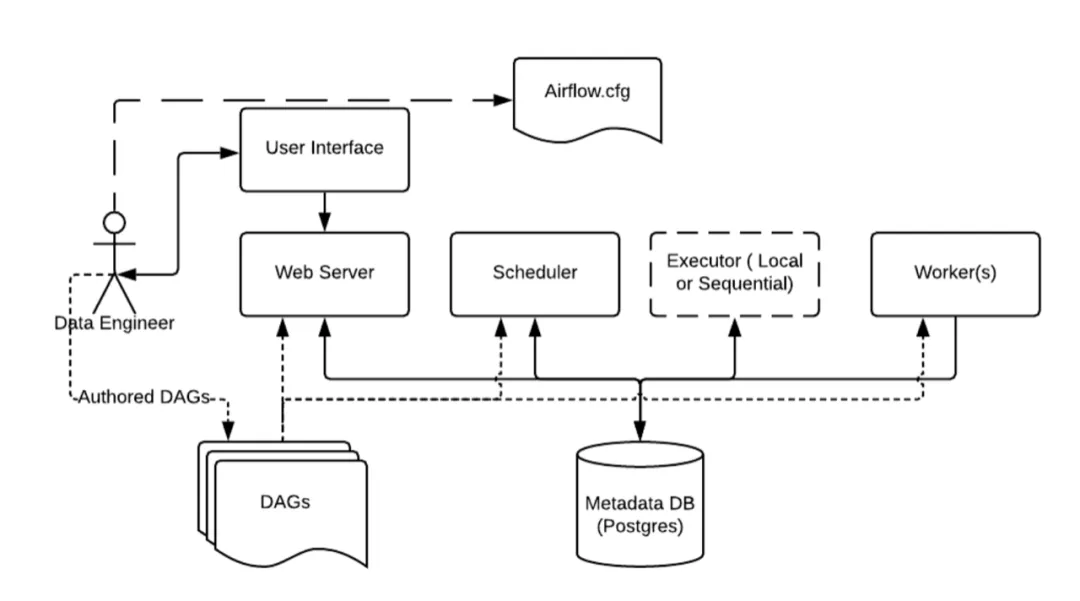
Apache Airflow的架构主要包括以下核心组件:
- Scheduler(调度器):负责根据定义的DAG(Directed Acyclic Graph,有向无环图)图,计划和触发任务的执行。调度器将任务按照依赖关系组织成可执行的工作流程,并将其分发给可用的执行器。
- Executor(执行器):执行器负责执行调度器分发的任务。Airflow支持多种执行器,包括本地执行器(SequentialExecutor)、Celery执行器和Dask执行器等。执行器将任务实际执行在相应的工作节点上,并将执行结果返回。
- Web Server(Web服务器):提供Web用户界面,用于监控和管理工作流的状态、任务的执行情况、查看日志以及触发任务的手动运行等。通过Web界面,用户可以直观地了解工作流的整体情况。
- Database(元数据库):元数据库存储了Airflow的元数据,包括DAG的定义、任务实例的状态、任务执行日志等。这允许用户在不同的任务和工作流之间共享信息,并支持任务的重试、回溯和监控。
- Worker(工作节点):执行器通过工作节点在集群或计算资源上执行任务。工作节点可以是单个服务器或集群,具体取决于所选的执行器类型。
容器部署airflow方式
手动部署
手动部署可以参考Airflow官方教程,这里面介绍了怎么通过helm chart进行airflow部署,这里就不再详述了。不过由于docker.io被墙了,部署的时候需要想办法把海外的镜像拉取下来,或者直接部署到海外地域的集群中。
计算巢一键部署
计算巢提供了免费的airflow社区版服务,支持一键部署,既可以部署到已有容器集群,也支持新建容器集群,同时镜像也都使用的阿里云托管的镜像,不会存在镜像拉取不下来的问题,具体部署方式可以查看服务中的部署文档。
使用方式
Dags文件加载到scheduler调度器中
上面在k8s集群上部署好airflow以后,那么怎么运行我们定义好的DAG工作流呢,这里面主要有三种方式:
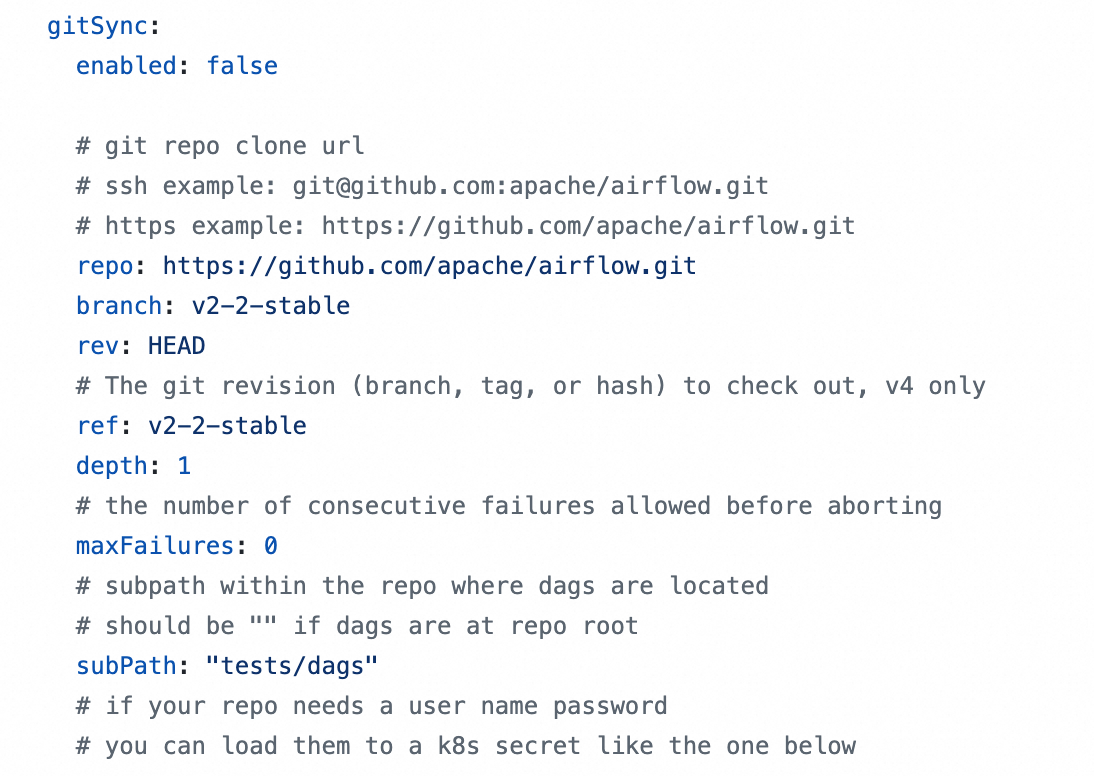
- 配置git仓库同步,从git仓库中加载要运行的Dags文件,这是最推荐的方式,可以很容易的更新要运行的Dags文件,计算巢部署版本默认使用这种方式,需要在Values.yaml中配置对应的git-sync配置。
- 在airflow-scheduler pod中对应airflow容器中,直接copy或者写入要执行的Dags文件,这种方式更适合临时测试
- 直接将Dags文件放到对应的pvc里,然后挂载到airflow-scheduler pod中对应airflow容器,这种使用起来也不太方便。
下面我们主要介绍第一种方式,使用git仓库去做同步, 我们可以把写好的DAG文件提交到git仓库中,然后airflow-scheduler组件会进行同步, web上就能看到我们定义好的DAG文件,然后点击run按钮就可以运行DAG文件了。在计算巢服务实例部署中,部署的时候需要填入对应的git仓库信息,手动部署的情况下需要手动修改对应的values.yaml,对helm chart做升级部署。

示例演示
下面以一个简单的DAG文件为例,展示如何在airflow中进行运行DAG。
- 在git仓库中创建DAG文件,文件名为
hello_world_dag.py,里面有三个任务,会依次执行:
- 打印\"Hello\"
- 打印\"World\"
- 休眠300秒
import timefrom datetime import timedeltafrom airflow import DAGfrom airflow.operators.python import PythonOperatorfrom airflow.utils.dates import days_ago# 定义默认参数default_args = { \'owner\': \'airflow\', # DAG 的所有者 \'start_date\': days_ago(1), # DAG 的开始时间(1 天前) \'retries\': 1, # 任务失败时的重试次数 \'retry_delay\': timedelta(minutes=5), # 重试间隔}# 定义 DAG 对象with DAG( dag_id=\'hello_world_dag\', # DAG 的唯一标识符 default_args=default_args, # 使用默认参数 schedule_interval=\'@daily\', # 每天运行一次 catchup=False, # 是否补跑历史任务) as dag: # 定义第一个任务:打印 \"Hello\" def print_hello(): print(\"Hello\") task_hello = PythonOperator( task_id=\'print_hello\', # 任务的唯一标识符 python_callable=print_hello, # 调用的 Python 函数 ) // 定义第二个任务:打印 \"World\" def print_world(): print(\"World\") task_world = PythonOperator( task_id=\'print_world\', python_callable=print_world, ) # 定义一个休眠任务 def sleep_task(): print(\"Task is sleeping for 300 seconds...\") time.sleep(300) # 休眠 300 秒 print(\"Task woke up!\") sleep_operator = PythonOperator( task_id=\'sleep_task\', python_callable=sleep_task, ) # 设置任务依赖关系 task_hello >> task_world >> sleep_operator- 提交DAG文件到git仓库中,然后去web端查看,可以看到对应的DAG,这个过程会有延时,默认是每10s同步一次。
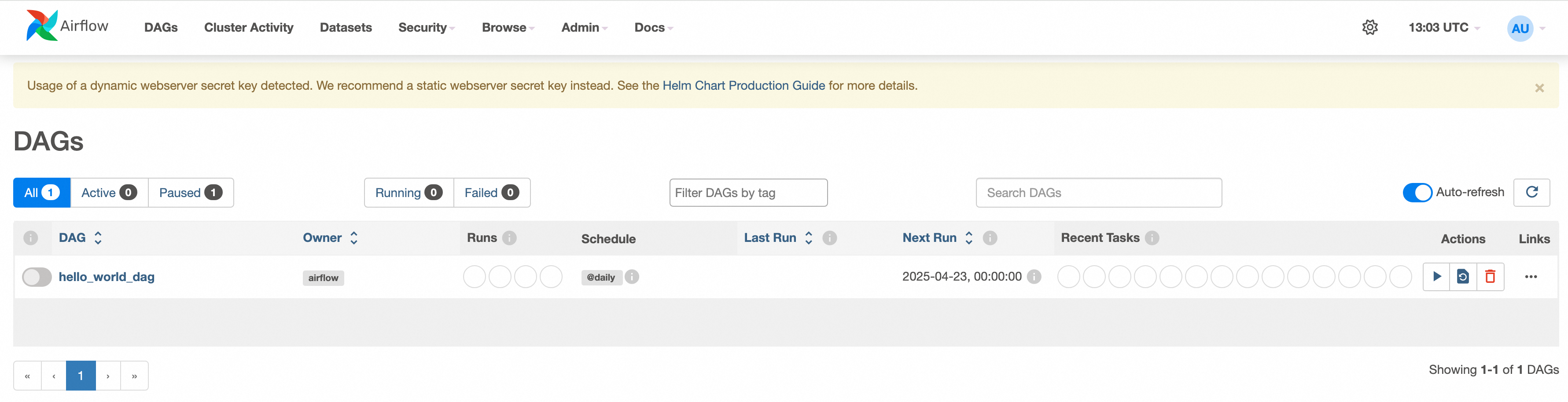
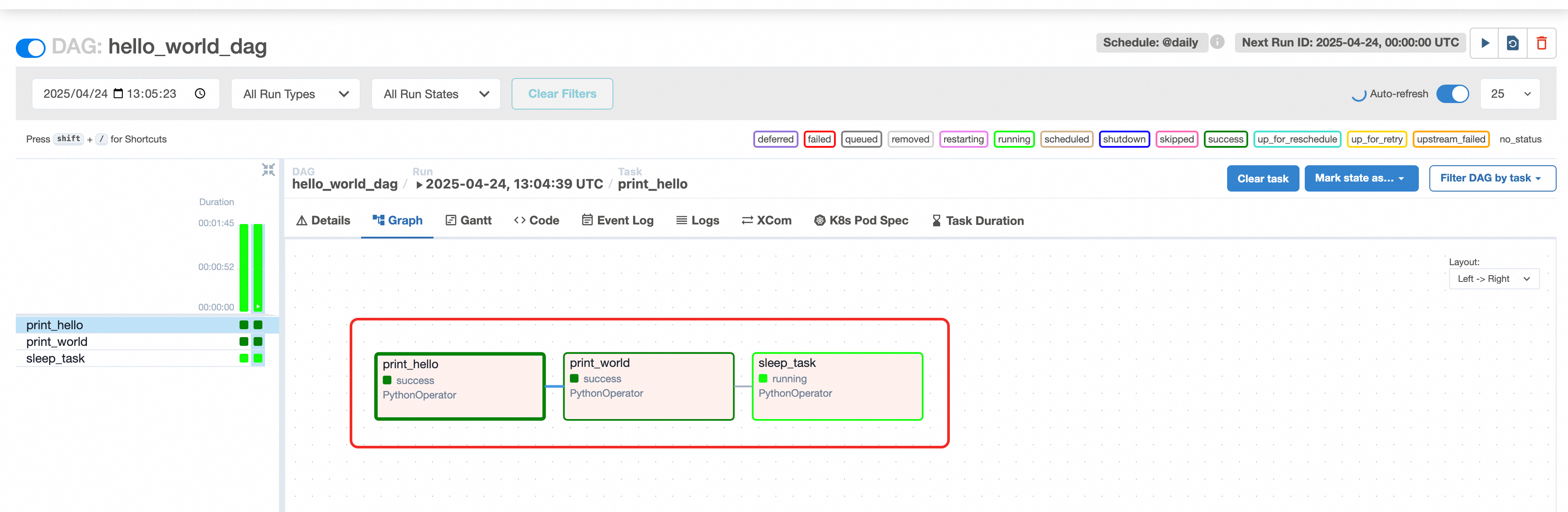
- 执行这个DAG,点击run按钮,点击进行,可以看到执行记录,点击Graph, 可以看到具体执行步骤,
可以看到print_hello和print_world都已经执行完了,sleep_task还在执行中,这个功能确实很强大。

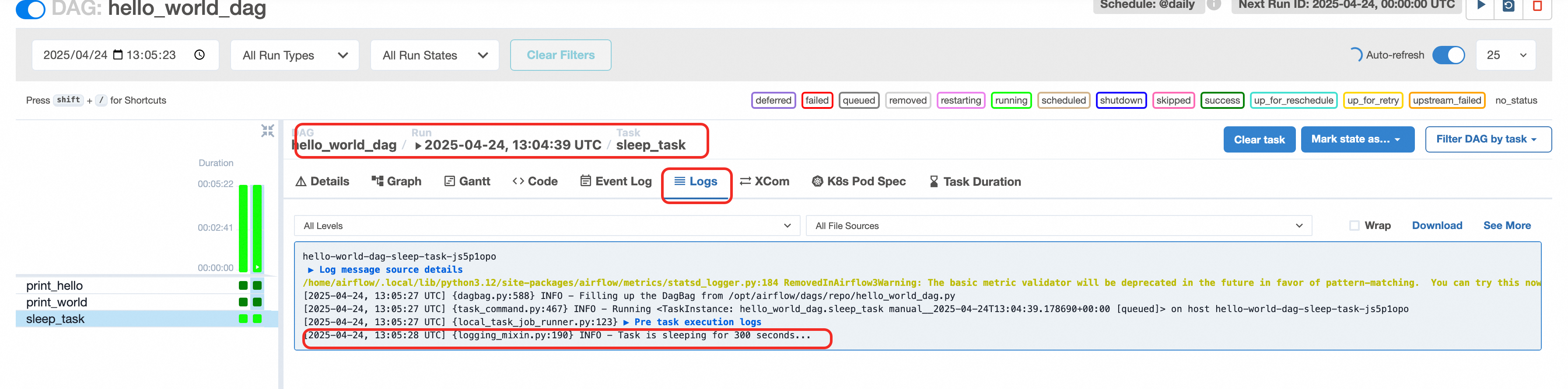
- 点击还在执行中的sleep_task,可以在Logs里看到输出信息,里面输出了会sleep 300秒,可见在正常执行。
总结
通过上面这个示例,可以看出airflow整体功能还是很强大的,并且图形化做的很好,交互能力很强大,可以直接在页面上进行Dag运行,并且可以清楚的看到DAG的执行情况,并且将每一步的执行过程都以图形化的方式显示出来,里面还有执行时间和日志,用来做工作流还是很好用的。
同时Dag支持python直接进行编码,也提供了很强的扩展性,在工作流中可以做各种业务操作,整体来说还是非常强大的。

