LoRA、ControlNet与T2I Adapter的区别
(2023AAAI)T2I-Adapter:学习挖掘文本到图像扩散模型的更可控能力-CSDN博客
《LoRA:高效的深度学习模型微调技术及其应用》-CSDN博客
2023ICCV,《ControlNet:向文本到图像扩散模型添加条件控制》-CSDN博客
在扩散模型微调领域,LoRA、ControlNet、T2I-Adapter 是三种具有代表性的技术,它们在设计目标、实现方式、应用场景等维度存在差异。
一、核心设计目标
二、技术实现细节
1. LoRA(Low-Rank Adaptation)
-
原理:
冻结原模型权重,在关键层(如 U-Net 或 Transformer 层)插入低秩矩阵(可理解为 “轻量化可训练分支” )。通过训练这些低秩矩阵,间接修改模型输出,实现任务适配。
数学表达:原权重更新 Wnew=Wbase+ΔW,其中 ΔW=A⋅B(A,B 为低秩矩阵,训练时仅更新 A,B )。 -
特点:
- 参数极精简:仅训练低秩矩阵,参数量是全量微调的几十分之一,训练成本大幅降低。
- 通用性强:适配各类扩散模型(SD、SDXL 等)及大模型(LLM 也常用 LoRA 微调),适合 “让模型记住特定风格 / 角色”(如生成固定 IP 形象、特定画风)。
- 控制弱结构化:更侧重 “风格迁移、概念注入”,对精确结构控制(如强制人物摆特定姿势)能力有限。
2. ControlNet
-
原理:
冻结原扩散模型(如 Stable Diffusion),额外训练一个控制网络(小模型),将外部条件(边缘图、深度图、姿态图等)编码为特征,强制注入到原模型的 UNet 中间层,让生成严格遵循条件结构。
关键设计:用ZeroConvolution初始化控制网络,确保训练初期不干扰原模型,后期逐步强化控制。 -
特点:
- 强结构化约束:通过控制网络 “绑定” 外部条件与模型特征,生成结果严格对齐条件输入(如 Canny 边缘图引导时,图像轮廓 1:1 匹配边缘)。
- 预训练丰富:官方提供 9 大类预训练模型(边缘、深度、分割、人体姿态等 ),开箱即用。
- 训练成本较高:控制网络需拟合复杂结构映射,早期版本训练用了 300 万级数据 + 大量 GPU 资源(如论文中 Canny 模型用 300 万对数据、A100 600 GPU 小时 )。
3. T2I-Adapter
-
原理:
同样冻结原模型,设计轻量级适配器模块(特征提取 + 残差块结构 ),将外部条件(草图、语义分割图、颜色调色板等)编码为特征后,注入到 U-Net 中间层(类似 ControlNet,但架构更简洁 )。
支持多条件加权融合:可同时输入 “草图 + 颜色 + 姿态”,通过权重 ωk 调节各条件的影响强度。 -
特点:
- 多条件灵活集成:天然支持 “多控制条件叠加”(如草图定结构 + 颜色板定色调 ),工程实现更简洁(代码易扩展,适配新条件只需新增小模块 )。
- 训练极轻量:4 块 V100 GPU 训练 2 天即可覆盖多条件(如草图、语义分割、姿态 ),适合快速迭代新控制能力。
- 控制轻量化:适配器结构比 ControlNet 更简单,对超复杂结构约束(如高精度深度图引导 )的效果弱于 ControlNet,但胜在灵活、易扩展。
三、适用场景对比
四、关键差异总结
五、ControlNet和T2I-Adapter的结构差异
一、结构设计本质差异
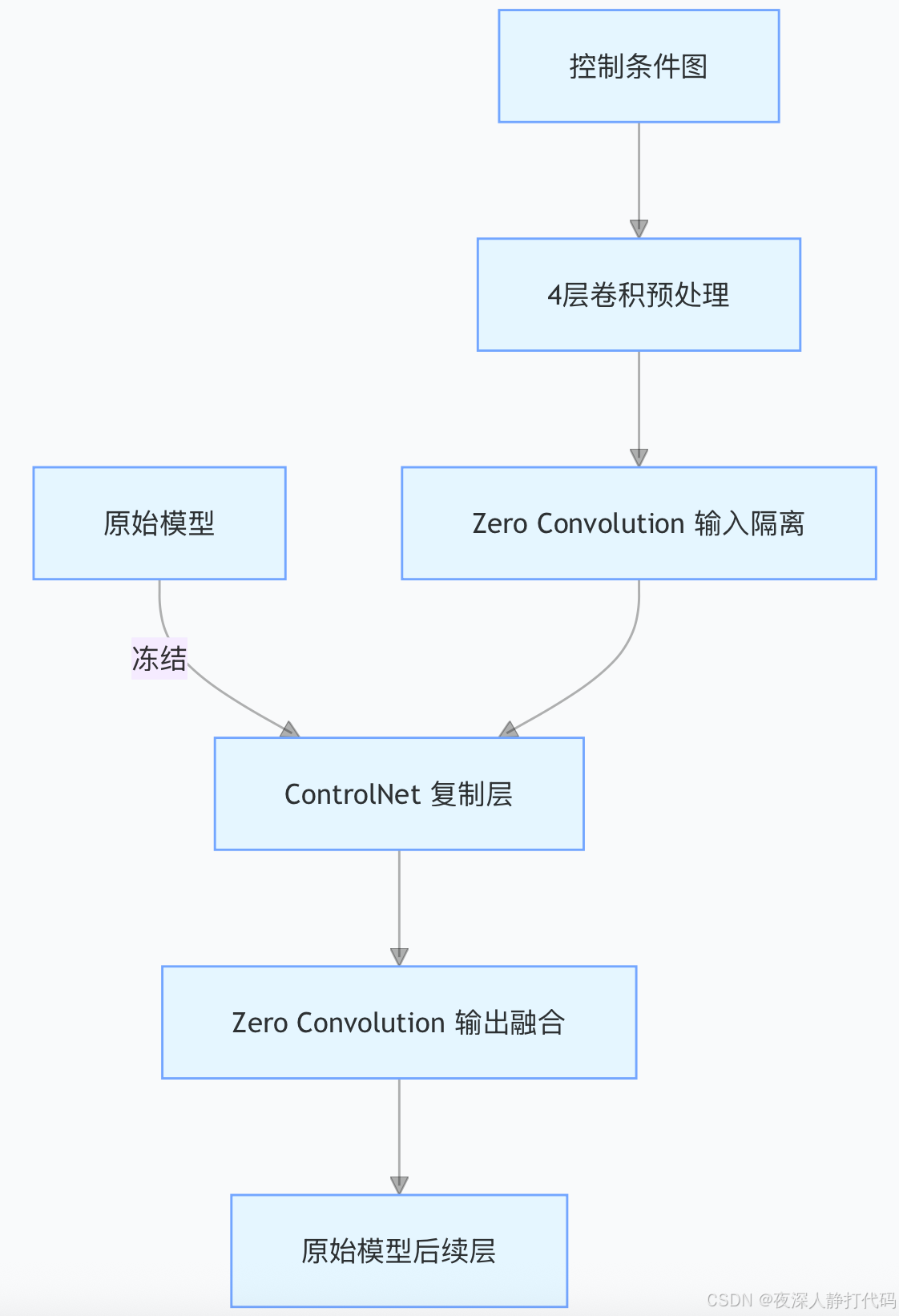
1. ControlNet:“复制 - 隔离” 式强绑定
-
核心逻辑:冻结原始扩散模型(如 Stable Diffusion)后,完整复制 UNet 中的编码层 + Middle Block(共 13 层),生成一个 “可训练副本”。在副本的输入、输出端插入 Zero Convolution(零初始化卷积),强制隔离原始模型输入与控制条件。
-
结构特点:
- 控制条件需先经过 4 层基础卷积预处理(4x4 卷积、步长 2x2、ReLU 激活),将条件图(如姿态图)压缩到与模型隐变量同维度(如 128x64x64)。
- Zero Convolution 确保训练初期不干扰原始模型(输出为 0),反向传播时逐步 “激活”,实现对原始模型的强结构约束。
-
简化示意图:
-
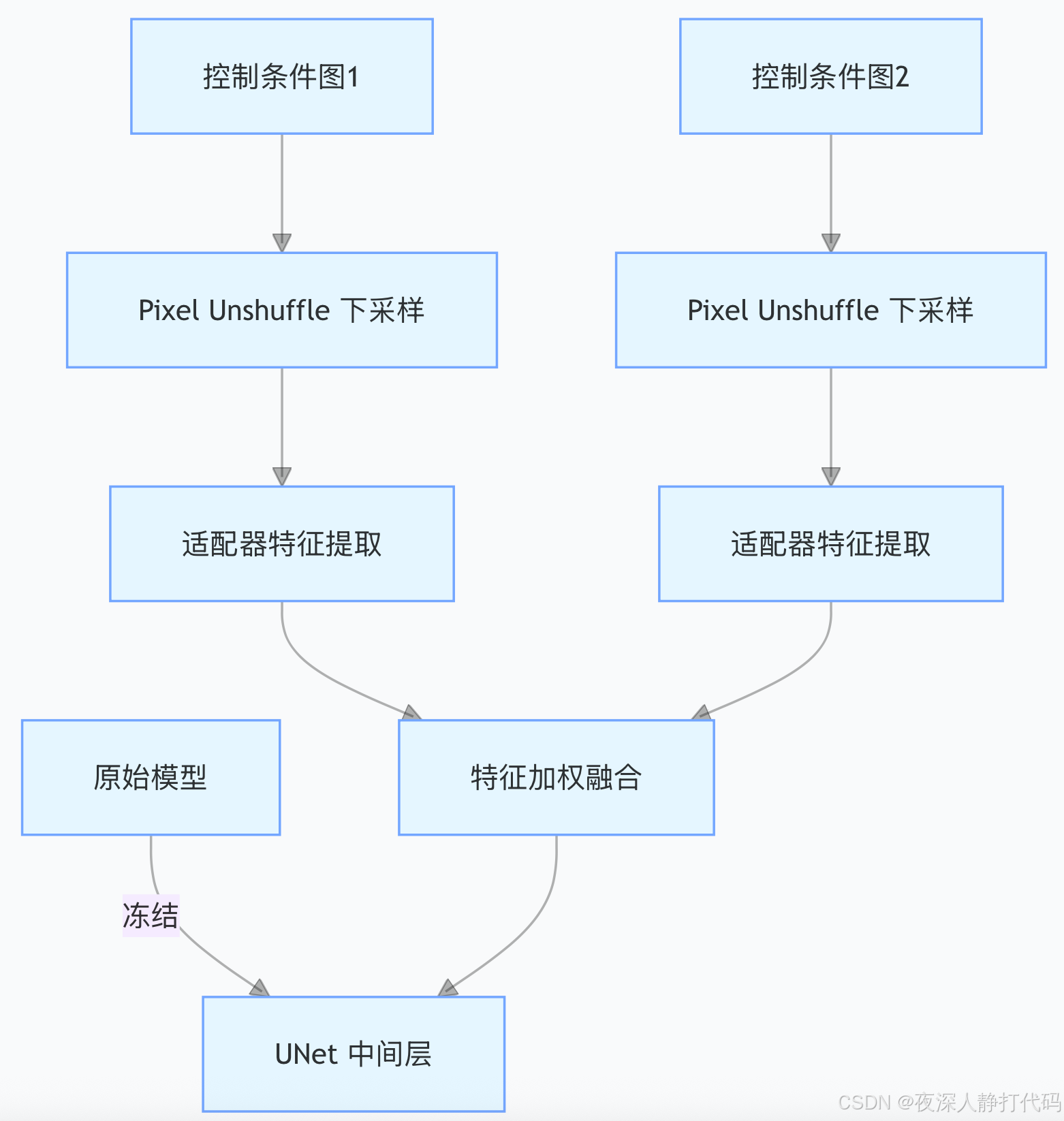
2. T2I-Adapter:“轻量 - 插入” 式灵活适配
-
核心逻辑:冻结原始模型后,新增轻量级适配器模块(4 个特征提取模块 + 3 个下采样块),不复制原始模型结构。通过 Pixel Unshuffle(像素反洗牌) 直接将控制条件(如草图)下采样到 64x64 分辨率,再用卷积 + 残差块提取特征。
-
结构特点:
- 适配器仅含基础卷积与残差块,参数量远小于 ControlNet(可理解为 “插件式” 小模型)。
- 支持多条件加权融合,不同控制条件(如草图 + 颜色)可通过权重 ωk 灵活叠加。
-
简化示意图:
二、作用流程对比(以 “生成指定姿势的卡通角色” 为例)
假设需求:用人体姿态图控制生成 “卡通角色摆特定动作”,对比两者流程差异:
案例条件
- 控制条件:人体姿态图(如 Openpose 生成的骨骼图)
- 原始模型:Stable Diffusion(冻结)
1. ControlNet 流程(强结构约束)
-
条件预处理:
姿态图 → 经 4 层卷积预处理,压缩到 128x64x64 维度,与模型隐变量对齐。 -
隔离与融合:
预处理后的姿态图 → 经 Zero Convolution 输入 ControlNet 复制层 → 输出再经 Zero Convolution 融合到原始模型的 UNet 中间层。 -
生成约束:
由于复制层与原始模型结构高度关联,生成的卡通角色严格对齐姿态图结构(如手臂抬起角度、腿部弯曲度 1:1 复刻),适合需要精准结构复刻的场景。
2. T2I-Adapter 流程(灵活多条件)
-
条件下采样:
姿态图 → 经 Pixel Unshuffle 下采样到 64x64 分辨率(保留关键结构,降低计算量)。 -
适配器特征提取:
下采样后的姿态图 → 经卷积 + 残差块提取特征 → 与原始模型 UNet 中间层特征直接相加融合。 -
生成约束:
若同时叠加 “颜色调色板” 条件,可通过权重 ω 让姿态控制(ω1=0.7 )与颜色控制(ω2=0.3 )协同作用,生成的卡通角色结构贴合姿态图,但色彩更灵活,适合多条件创意组合场景。
三、核心差异总结
ControlNet运行所需的 计算成本比较高。这是因为其反向扩散过程的每个去噪步都需要运行 ControlNet 和 UNet。另外,对 ControlNet 而言,复制 UNet 编码器作为控制模型的一部分对效果非常重要,这也导致了控制模型参数量的进一步增大。因此,ControlNet 的模型大小成了生成速度的瓶颈 (模型越大,生成得越慢)。
在这方面,T2I-Adapters 相较 ControlNets 而言颇有优势。T2I-Adapter 的尺寸较小,而且,与 ControlNet 不同,T2I-Adapter 可以在整个去噪过程中仅运行一次。

四、直观效果对比(以 “姿态控制 + 颜色控制” 为例)
假设输入:
- 控制条件 1:人体姿态图(要求角色 “单手持花”)
- 控制条件 2:颜色调色板(要求 “暖色调、高饱和度”)

