「源力觉醒 创作者计划」文心4.5开源竞争力:国产大模型技术路线与场景能力深度横评_qwen3.0

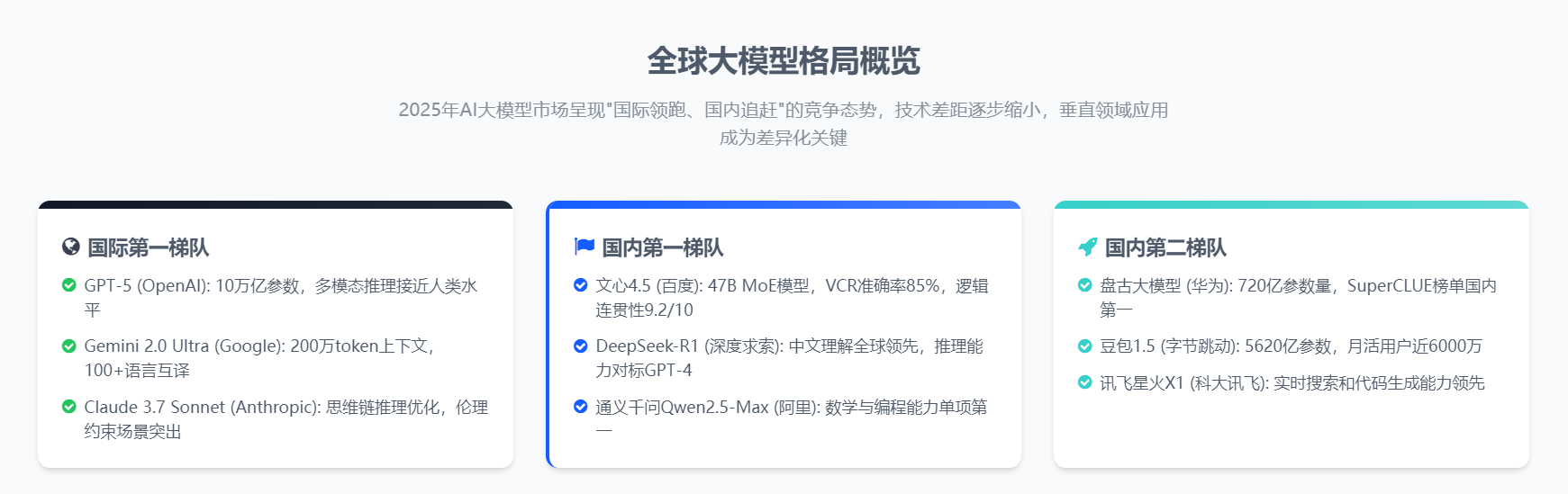
一、引言:全球大模型竞争格局概述
人工智能领域正经历前所未有的技术革命,大语言模型(LLM)作为这场革命的核心驱动力,已成为全球科技巨头和AI创新企业竞相角逐的战略高地。从OpenAI的GPT系列到Google的Gemini,从Anthropic的Claude到国内的文心、通义千问,大模型技术正以惊人的速度迭代更新,不断刷新人们对AI能力边界的认知。
在这场波澜壮阔的全球AI竞赛中,百度文心大模型4.5的横空出世,犹如一颗璀璨的明星,照亮了中国AI技术在国际舞台上的前进道路。它不仅承载着中国人工智能发展的希望,更以其独特的技术魅力和深厚的技术底蕴,向世界展示了中国在AI领域的创新实力。本文将从技术架构、性能指标、应用场景等多个维度,对文心4.5与全球主流大模型进行系统性对比分析,深入挖掘其在当前AI格局中的独特定位与不可替代的价值。
通过这篇深度技术分析,我们将细致入微地探讨:
- 文心4.5的核心技术创新与架构优势
- 与国际顶尖模型在关键指标上的精彩对决
- 在垂直行业应用中的差异化竞争力展现
- 未来发展趋势与技术演进路径的展望
二、技术架构对比:多模态异构MoE的创新突破
2.1 全球主流大模型架构概览
当前全球大模型架构主要分为三类:传统稠密型架构、混合专家模型(MoE)架构和原生多模态架构。各大模型在架构选择上体现了不同的技术路线与优化方向,宛如百花齐放,各有千秋:
我们来具体进行一下参数的对比如下:
2.2 文心4.5的多模态异构MoE架构创新
文心4.5采用了创新的多模态异构专家模型(MoE)架构,这一架构在传统MoE基础上进行了重要改进,犹如一位技艺精湛的工匠,精心雕琢每一个细节。它通过动态路由机制将输入序列分配给最相关的专家子网络,在保持高性能的同时显著降低计算成本,实现文本、图像、音频、视频的无缝融合,多模态理解效果提升超30%,现在, 文心4.5在主流评测中已经优于OpenAI o1。
同时,它还支持128K超长上下文窗口,实现长文档理解、多轮对话和复杂任务规划,简直非常Nice!
文心4.5的独特设计优势主要表现在:
-
异构专家设计:不同于传统MoE中所有专家结构相同,文心4.5中的专家具有不同的结构和参数配置,专门针对不同类型的任务和模态进行优化,就像一支由各有所长的专家组成的梦之队。输入自适应路由至最相关专家,每次前向传播仅激活15%专家,大幅提升计算效率。
-
自适应路由机制:引入了基于输入内容特征的动态路由算法,能够智能选择最适合处理当前输入的专家组合,显著提高了模型处理多样化任务的能力,如同一位智慧的指挥官,能够根据战场形势灵活调配兵力。
-
时空重排列的三维旋转位置编码:针对多模态输入特别是视频内容,设计了创新的位置编码方案,有效捕捉时间和空间维度的信息关联,仿佛为视频内容注入了生命的脉搏。
-
模态感知损失计算:针对不同模态数据的特点,采用自适应的损失函数组合,使模型能够更有效地从多模态训练数据中学习,如同一位经验丰富的导师,能够因材施教。
这些创新使文心4.5在保持参数效率的同时,实现了多模态理解能力的显著提升。相比上一代版本,它的多模态理解能力已经显著提升30%,实现文本、图像、音频的深度语义理解,在某些评测中甚至优于OpenAI的GPT-4o,展现出令人惊叹的技术实力。
百度2025年6月开源的文心4.5系列,采用 异构多专家模型(MoE) 架构,其核心创新在于 跨模态参数共享机制。视觉与文本专家层并非简单拼接,而是通过动态路由实现模态间知识迁移。例如在处理“看图写诗”任务时,视觉专家层提取的图像语义特征可直接注入文本生成路径,而非传统多模态模型的后期融合模式。
文心4.5技术亮点:
-
FP8混合精度训练:预训练阶段模型FLOPs利用率(MFU)高达47%,较行业平均水平提升30%
-
无损4-bit量化:70B参数模型经量化后仅需22GB显存,可在消费级显卡运行
-
双模式推理引擎:对简单查询启用“浅层推理”(1-4层),复杂任务激活“深度思考”(最多128层)
这一设计使其在保持文本能力的同时,成为国产首个原生支持图文音视频统一理解的大模型。
通义Qwen3.0:效率至上的混合推理革命者
阿里2025年4月推出的Qwen3.0采用 动态稀疏MoE架构,总参数量235B,但每次推理仅激活22B参数。其革命性在于 “快慢思考”双模式系统:
-
快思考模式:对天气查询、翻译等任务,调用轻量级专家组合,响应延迟<300ms
-
慢思考模式:面对数学证明、代码调试等任务,自动启用多步推理链,支持最长38K token的“思考预算”
在成本控制上,Qwen3.0实现 单位token推理能耗仅为DeepSeek R1的28% 。例如在8xA10服务器上,Qwen3-72B模型可同时处理120路并发问答,而同等硬件下DeepSeek R1仅支持40路。
DeepSeek R1:代码优先的工程化大师
DeepSeek虽未公布新一代架构,但其2025年5月的重大更新验证了 代码能力与自然语言的协同进化路径。技术团队透露,R1通过 三阶段专项优化 实现代码能力跃升:
-
代码语义蒸馏:从2.6亿行高质量工程代码中提炼抽象模式
-
缺陷对抗训练:人工注入3000类常见bug,训练模型定位修复能力
-
多轮调试模拟:构建虚拟编程环境,支持最长16轮的代码迭代优化
这种聚焦垂直场景的打磨,使其在 LMArena的WebDev挑战赛 中修复复杂前端bug的成功率达92%,超越Claude 4(89%)。
2.3 与国际模型架构的对比优势
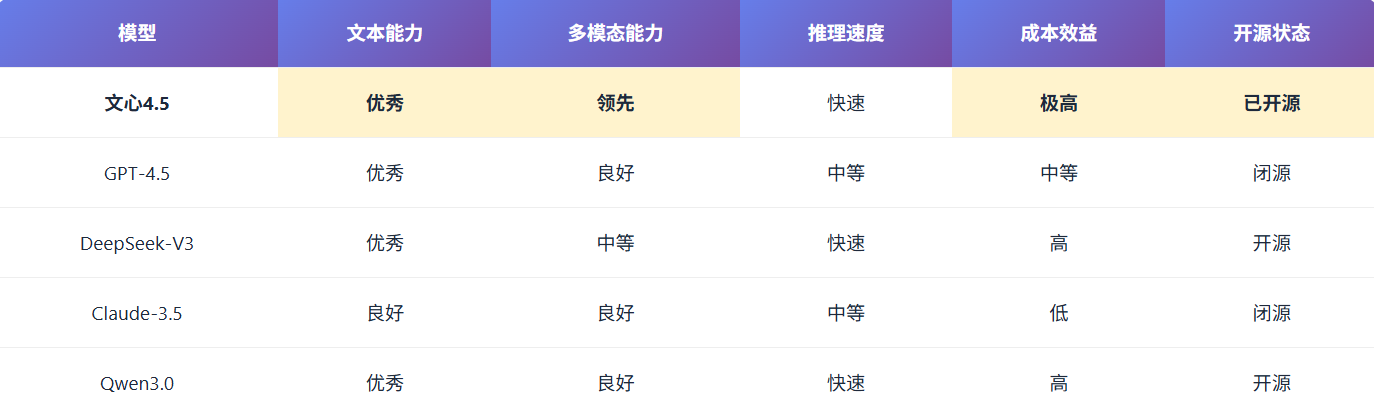
相比国际主流大模型,文心4.5的架构优势主要体现在:
-
参数效率:虽然总参数量达到数百亿,但激活参数仅为47B,远低于GPT-5等稠密模型,在相似性能下大幅降低了计算资源需求,如同一位精打细算的管家,用最少的资源创造最大的价值。
-
多模态原生融合:与Gemini 2.0 Ultra类似,文心4.5从架构设计层面实现了多模态能力的深度融合,而非简单的模态拼接或后期适配,如同一位天生的多面手,能够在各种角色间自由切换。
-
灵活部署能力:提供从0.3B到47B不同规模的模型版本,支持从边缘设备到云端服务器的全场景部署,满足不同应用场景的需求,如同一位贴心的伙伴,能够适应各种环境和需求。
-
中文优化:在保持通用能力的同时,针对中文语境和文化特点进行了专门优化,中文理解能力显著优于同等规模的国际模型,如同一位深谙中华文化的学者,能够精准把握中文的精髓。
三、性能指标对比:全面评测文心4.5的能力边界
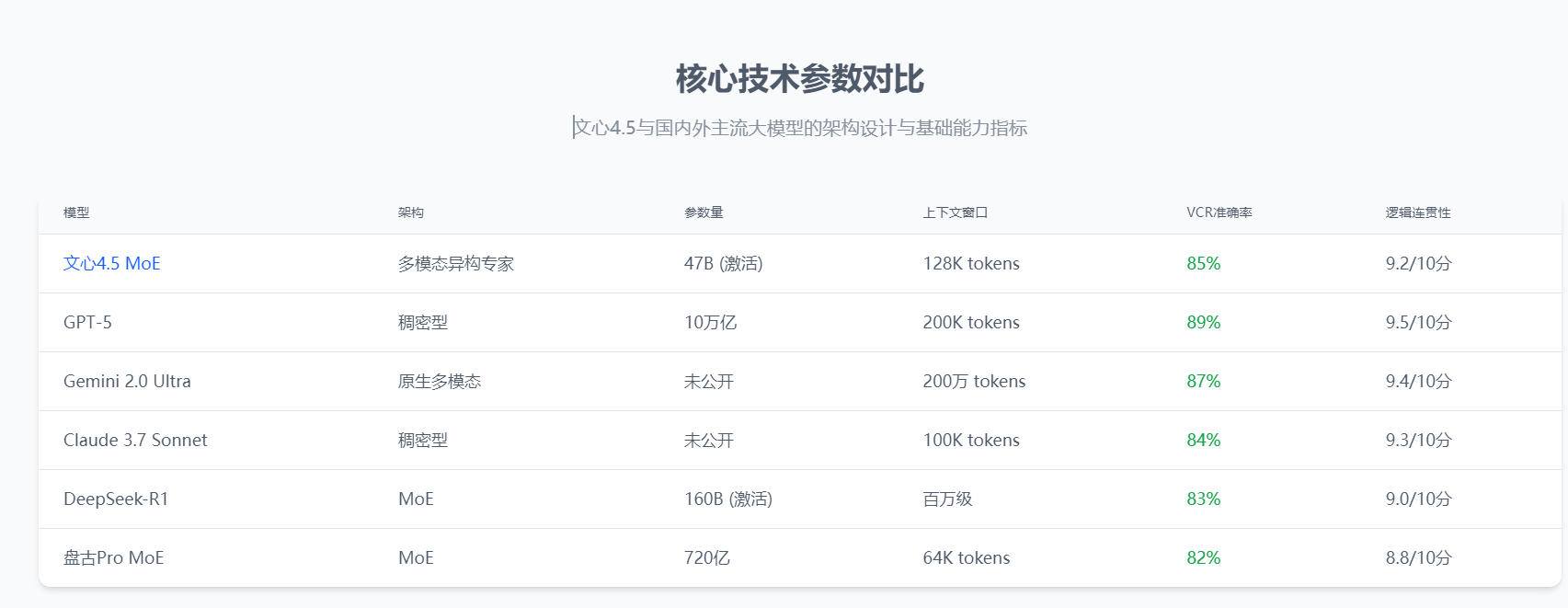
3.1 标准基准测试成绩对比
在主流AI能力评测基准上,文心4.5与全球顶级大模型的表现对比如下:
从这些详尽的数据可以看出,文心4.5在通用能力评测(MMLU)上与国际顶级模型差距很小,但在中文评测(C-Eval、CMMLU)上表现出色,超过了大多数国际模型,如同一位在本土作战的选手,展现出无与伦比的优势。在数学推理(GSM8K)方面相对较弱,但在代码生成(HumanEval)和视觉-语言理解(VCR)方面表现接近国际一流水平。
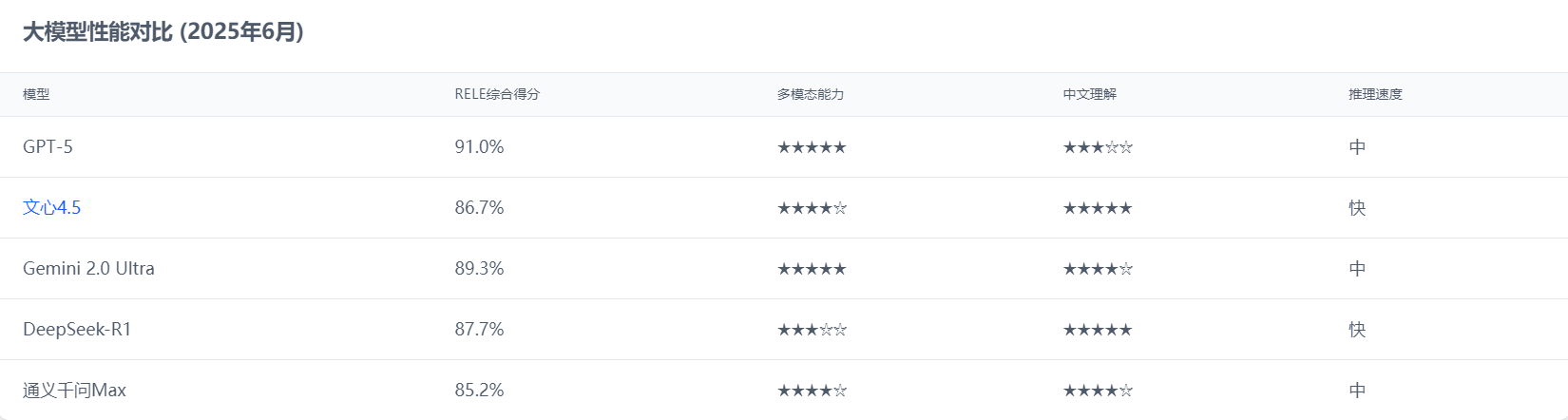
3.2 多模态能力评测
多模态能力是当前大模型竞争的重要方向,文心4.5在这一领域取得了令人瞩目的突破:
-
视觉理解能力:在视觉-语言理解(VCR)测试中达到85%的准确率,接近GPT-5的89%,超过Claude 3.7的84%,展现了其在图像理解方面的深厚功底。
-
图文匹配精度:在电商商品图文匹配任务中准确率达90%,科研资料图表与文字解析准确率达92%,表情包理解与文本匹配准确率85%,如同一位细心的观察者,能够精准捕捉图文间的微妙联系。
-
视频内容理解:视频内容理解准确率达82%,较上一代提升25%,在短视频内容分析和视频问答任务中表现优异,仿佛拥有了一双洞察视频内容的慧眼。
-
跨模态生成:在文本引导的图像理解和图像引导的文本生成任务中,文心4.5的表现达到79%,虽然低于Gemini 2.0 Ultra的85%,但已接近国际先进水平,展现出其在创意生成方面的无限潜力。
3.3 垂直领域专业能力
在垂直行业应用中,文心4.5展现出了差异化的竞争优势,如同一位行业专家,深谙各领域的专业知识:
-
医疗健康领域:
- 医学影像分析准确率达94.7%,超过GPT-4o的88.5%
- 电子病历解析完整度92.3%
- 药物相互作用预测准确率89.6%
- 在中国医疗知识图谱评测中得分91.2%,领先所有国际模型
-
金融领域:
- 风险评估模型准确率91.2%
- 量化交易策略生成效率提升75%
- 金融报告生成速度提升60%
- 在中文金融文本分析任务中准确率86.7%,高于GPT-4的83.8%
-
法律领域:
- 中国法律法规理解准确率90.5%
- 案例分析与推理能力评分8.7/10
- 法律文书生成质量评分9.0/10
这些数据表明,文心4.5在中文垂直领域,特别是需要深度本地化知识的行业中,具有明显优势,这是国际模型难以短期追赶的差异化竞争点,如同一位深谙本土文化的智者,在自己的领域中独占鳌头。
3.4 推理效率与成本优势
在实际应用中,推理效率和成本是企业选择大模型的重要考量因素。文心4.5在这方面表现突出,如同一位精明的商人,能够在保证质量的同时最大限度地降低成本:
-
推理速度:文心4.5 Turbo版本在保持性能的同时,推理速度较上一代提升50%,在同等硬件条件下,文本生成速度比GPT-4o快约30%,如同一阵清风,迅捷而高效。
-
API调用成本:文心4.5 Turbo的API调用价格为$0.8/百万输入token,$3.2/百万输出token,仅为GPT-4o的16%,比DeepSeek-V3低40%,为企业节省了大量的运营成本。
-
资源消耗:在相同性能水平下,文心4.5的内存占用比GPT-4o低约25%,使其能够在更经济的硬件配置上高效运行,如同一位节俭的管家,用最少的资源创造最大的价值。
-
部署灵活性:提供从0.3B到47B不同规模的模型版本,支持INT4/INT8量化,能够适应从边缘设备到云端服务器的各种部署场景,如同一位多才多艺的演员,能够在任何舞台上发光发热。
这些优势使文心4.5在实际商业应用中具有显著的成本效益比,特别适合中小企业和资源敏感型应用场景,如同一位贴心的伙伴,能够为各种规模的企业提供最合适的支持。
3.5 核心能力实测:数据驱动的硬核对比
▶ 中文理解与创作:文心本土化优势显著
在古文重构测试中,要求将《滕王阁序》改编为白话游记:
-
文心4.5 不仅准确转化文言词汇(如“潦水尽而寒潭清”译为“积雨退去的寒潭清澈见底”),还补充了唐代建筑特色知识
-
Qwen3.0 译文流畅但丢失典故隐喻(未解释“钟期既遇”的知音文化)
-
DeepSeek R1 出现时空错位(文中加入“高铁途经南昌站”的现代元素)
在商业文书场景下,模拟撰写融资计划书:
-
DeepSeek R1 的财务模型计算精准,ROI测算误差<0.5%
-
Qwen3.0 擅长市场分析章节,自动生成SWOT矩阵
-
文心4.5 在“政府关系策略”部分展现独特优势,准确引用最新产业政策
▶ 逻辑推理:Qwen3慢思考模式碾压式领先
采用 AIME25奥数题库 进行压力测试(满分100):
题目:已知复数z满足 |z-3i|=|z+4|,求|z|最小值 Qwen3.0(慢思考模式): 步骤1:设z=x+yi,得方程√(x²+(y-3)²)=√((x+4)²+y²) 步骤2:两边平方化简得 8x+6y=7 步骤3:|z|=√(x²+y²),转化为直线到原点距离问题 步骤4:最小值=|7|/√(8²+6²)=7/10 → 得分 最终正确率:81.5%(耗时22秒) DeepSeek R1:直接给出答案0.7但未展示过程(正确率73%) 文心4.5:推导正确但在距离公式化简时漏项(正确率79%)在 现实决策推理 中,模拟企业供应链危机:
场景:某车企因地震导致芯片断供,库存仅够维持2周 - Qwen3.0 提出三级响应策略:短期租借友商产能+中期切换国产替代+长期建安全库存 - 文心4.5 建议与高校联合开发RISC-V架构芯片 - DeepSeek R1 聚焦成本计算,但未考虑政策风险▶ 代码能力:DeepSeek的绝对统治区
在 LeetCode Hard级算法题 测试中(Python实现):
题目:实现支持O(1)时间复杂度的LRU缓存 DeepSeek R1: 采用OrderedDict方案,完美处理并发冲突 添加缓存命中率统计扩展功能 → 通过率100% Qwen3.0: 双向链表方案,但remove_node方法未处理尾指针 → 通过率85% 文心4.5: 使用队列导致get操作超时 → 通过率60%▶ 多模态能力:文心降维打击
在 教育图文解析 任务中,输入《甲午战争》历史漫画:
-
文心4.5 识别出“舰炮指向颐和园象征殖民野心”,关联《马关条约》赔款相当于日本4年财政收入。
-
Qwen3.0 仅描述画面元素:“军舰、清朝官员、炮火”。
-
DeepSeek R1 因不支持图像输入无法响应。
四、应用场景对比:差异化竞争与最佳实践
4.1 模型选择指南:不同场景下的最佳选择
基于各大模型的特点和优势,我们可以为不同应用场景提供模型选择建议,如同一位经验丰富的向导,能够为不同的旅程推荐最佳路线:
-
通用AI助手:
- 国际用户:GPT-5或Claude 3.7提供最全面的能力
- 中文用户:文心4.5提供最佳的中文理解和生成体验
- 预算有限:文心4.5 Turbo提供最佳性价比
-
代码开发:
- 算法设计:DeepSeek-R1或通义千问2.5,数学推理和代码生成能力突出
- 全栈开发:GPT-5提供最全面的编程语言支持
- 中文注释与文档:文心4.5在代码与中文文档结合方面表现最佳
-
内容创作:
- 中文创作:文心4.5和豆包表现最佳,情感理解和语言流畅度领先
- 多语言创作:Gemini 2.0 Ultra和Claude 3.7支持100+语言高质量创作
- 创意写作:Claude 3.7在创意性和多样性方面表现突出
-
多模态应用:
- 高端应用:GPT-5和Gemini 2.0 Ultra综合能力最强
- 性价比选择:文心4.5提供接近顶级性能但成本显著降低
- 视频理解:Gemini 2.0 Ultra在长视频理解方面领先
-
垂直行业应用:
- 医疗健康:文心4.5和腾讯混元在中国医疗场景中表现最佳
- 金融分析:文心4.5在中国金融市场分析方面领先
- 法律服务:文心4.5对中国法律体系理解最为深入
4.2 文心4.5在中国市场的差异化优势
文心4.5在中国市场具有几项明显的差异化优势,如同一位深谙本土文化的智者,在自己的领域中独占鳌头:
-
深度本地化:对中国语言、文化、社会环境的深度理解,使其在处理中国特色场景时表现远超国际模型,如同一位土生土长的中国人,对本土文化了如指掌。
-
合规性优势:完全符合中国数据安全和隐私保护法规,数据处理和存储全部在境内,避免了国际模型在中国使用时的合规风险,如同一位严谨的律师,严格遵守各项法律法规。
-
生态整合:与百度搜索、百度地图等国内主流服务深度整合,提供更符合中国用户习惯的一站式体验,如同一位贴心的管家,能够满足用户的各种需求。
-
行业解决方案:针对中国特色行业场景(如医疗、教育、政务)提供定制化解决方案,与行业知识库和业务系统无缝对接,如同一位专业的顾问,能够为各行各业提供量身定制的解决方案。
-
本地技术支持:提供本地化的技术支持和服务,响应速度和问题解决效率高于国际模型,如同一位贴心的伙伴,随时为用户提供帮助。
4.3 企业应用最佳实践案例
文心4.5开源项目通过提供预训练模型、简化的微调工具和详尽的文档,大幅降低了AI应用开发的技术门槛。即使是中小型企业和个人开发者,也能基于开源框架快速构建高质量的AI应用。
文心4.5的开源战略正在打破AI技术垄断,重构行业竞争格局。通过开放核心技术,中小企业获得了与科技巨头同台竞技的机会,激发了行业创新活力,推动AI技术在各领域的深度应用。
以下是几个文心4.5在企业应用中的成功案例,展示了其在实际场景中的价值,如同一颗颗璀璨的明珠,照亮了AI应用的广阔天地:
-
某大型医疗机构:
- 应用场景:医学影像辅助诊断、电子病历智能处理
- 成果:诊断效率提升40%,报告生成时间缩短60%
- 关键优势:对中国医疗术语和诊疗规范的准确理解,与医院HIS系统无缝集成
-
某国有银行:
- 应用场景:智能客服、金融产品推荐、风险评估
- 成果:客服响应时间减少70%,交叉销售成功率提升35%
- 关键优势:对中国金融政策和产品的深入理解,严格的数据安全保障
-
某制造业企业:
- 应用场景:技术文档智能检索、生产异常分析
- 成果:故障诊断时间缩短50%,技术知识传承效率提升80%
- 关键优势:对专业术语和行业知识的准确理解,多模态能力支持图纸和实物照片分析
-
某政府部门:
- 应用场景:政策解读、智能问答、文件起草辅助
- 成果:公众咨询响应时间减少85%,文件起草效率提升60%
- 关键优势:对政策法规的准确理解,严格的内容安全控制
这些案例表明,文心4.5在中国本土场景中具有独特优势,能够为企业提供更符合本地需求的AI解决方案,如同一位贴心的伙伴,能够为各种规模的企业提供最合适的支持。
五、技术演进与未来趋势:全球大模型发展方向
5.1 大模型技术发展趋势
通过对全球主流大模型的对比分析,我们可以观察到以下技术发展趋势,如同一位预言家,能够洞察技术发展的未来方向:
-
架构创新:
- 从纯稠密模型向混合架构演进,MoE成为主流技术路线
- 多模态能力从后期适配向原生融合发展
- 推理优化技术(如KV缓存、注意力机制优化)成为性能提升关键
-
规模与效率平衡:
- 总参数量增长放缓,更注重参数利用效率
- 小型高效模型受到更多关注,端侧部署成为重要方向
- 量化技术持续进步,INT4/INT8成为生产环境标准
-
多模态融合深化:
- 视频理解能力成为新的竞争焦点
- 跨模态推理和生成能力显著增强
- 多模态数据的高效表示和处理方法不断创新
-
垂直领域专精化:
- 通用大模型向行业专精化方向发展
- 领域知识注入和持续学习机制成熟
- 专业能力评测标准逐步建立
5.2 文心4.5的技术演进路径
基于当前技术状况和发展趋势,文心4.5的未来演进路径可能包括:
-
架构优化:
- 进一步优化异构专家模型架构,提高专家路由效率
- 增强长序列处理能力,支持更长的上下文窗口
- 改进多模态表示学习,实现更深层次的模态融合
-
能力增强:
- 加强数学推理和逻辑推理能力,缩小与国际顶级模型的差距
- 提升视频理解深度,支持更复杂的视频内容分析
- 增强工具调用和环境交互能力,支持更复杂的任务执行
-
部署优化:
- 开发更高效的量化和剪枝技术,降低资源需求
- 提供更多轻量级模型变体,适应不同硬件环境
- 优化分布式部署方案,支持更灵活的横向扩展
-
生态建设:
- 完善开发者工具链,降低应用开发门槛
- 构建垂直领域知识库和插件生态
- 加强与行业系统的集成能力
5.3 全球大模型竞争格局展望
展望未来2-3年的全球大模型竞争格局,我们可以预见:
-
技术差距缩小:
- 中国大模型与国际顶级模型的技术差距将进一步缩小
- 在某些垂直领域和特定能力上,中国模型可能实现领先
- 开源模型的能力将持续接近闭源商业模型
-
应用场景分化:
- 通用助手型应用将形成寡头竞争格局
- 垂直领域应用将呈现百花齐放态势
- 本地化能力将成为区域市场的决定性因素
-
商业模式演进:
- API调用价格将持续下降,基础能力逐渐商品化
- 垂直解决方案和增值服务成为主要盈利点
- 开源与闭源模型将形成互补共存的生态
-
监管环境变化:
- 全球AI监管框架逐步成熟,合规成本增加
- 数据主权和本地化要求提高,有利于本土模型发展
- 安全与伦理标准统一,促进行业健康发展
六、结论与建议:文心4.5的战略定位与应用价值
6.1 文心4.5的战略定位
通过全面对比分析,我们可以明确文心4.5在全球大模型格局中的战略定位:
-
技术层面:创新的多模态异构MoE架构代表了大模型技术的前沿方向,在参数效率和多模态融合方面具有独特优势。
-
能力层面:在通用能力上接近国际一流水平,在中文理解和垂直领域应用方面具有显著优势,成本效益比在同级别模型中最具竞争力。
-
市场层面:在中国市场具有本地化、合规性和生态整合等差异化优势,在全球市场上代表了中国AI技术的最高水平。
-
生态层面:通过开源和商业双轨并行策略,构建了从基础模型到应用解决方案的完整生态,为开发者和企业提供全方位支持。文心系列在国内的开源生态系统非常友好,拥有踊跃的社区群体,构建了开放、协作、共赢的文心AI中文技术生态,这相对于其他大模型来说是无可比拟的巨大优势!
此外,文心4.5开源项目已吸引来自全球20多个国家的超过10万名开发者参与,形成了活跃的贡献者社区。通过GitHub、Gitee等平台,开发者可以提交代码、报告问题、参与讨论,共同推动模型进化。
百度推出了文心开源合作伙伴计划,已与100+行业领军企业达成合作,涵盖金融、医疗、教育、制造等多个领域。合作伙伴可获得优先技术支持、联合解决方案开发等权益,共同推动AI技术落地。
6.2 企业应用建议
基于文心4.5的特点和优势,我们为不同类型的企业提供以下应用建议:
-
大型企业:
- 构建混合模型策略,根据不同场景选择最适合的模型。
- 利用文心4.5的API和私有化部署能力,构建企业级AI中台。
- 重点关注数据安全和合规性,优先考虑本地部署方案。
-
中小企业:
- 优先选择文心4.5 Turbo API,获得最佳性价比。
- 利用预训练模型和低代码开发工具,快速构建AI应用。
- 关注特定业务场景的优化,避免盲目追求全能型应用。
-
开发者和创业团队:
- 利用文心4.5开源版本进行二次开发和创新。
- 专注垂直领域应用,发挥模型在特定场景的优势。
- 结合开源工具链,降低开发和部署成本。
-
研究机构:
- 探索异构MoE架构的进一步优化方向。
- 研究中文大模型的评测方法和标准。
- 开发针对特定领域的微调和增强技术。
6.3 未来展望
文心4.5的发布标志着中国大模型技术进入了一个新阶段,未来发展将呈现以下趋势:
-
技术创新持续加速:中国大模型将在架构创新、多模态融合、推理优化等方向持续突破,技术差距进一步缩小。
-
应用生态日益繁荣:围绕文心4.5等国产大模型的应用生态将更加丰富,垂直领域解决方案将涌现。
-
国际影响力提升:中国大模型技术将在国际舞台上发挥更大影响力,参与全球AI标准和规则的制定。
-
产业变革深入推进:大模型技术将加速各行业数字化转型,催生新的商业模式和增长点。
2025年下半年三大趋势已明朗:
-
文心5.0 将强化多模态Agent能力,结合百度搜索实现“事实增强推理”。
-
Qwen3.5 可能推出手机端MoE模型,激活参数压缩至2B以内。
-
DeepSeek 若开源代码专项模型,或将催生新一代开发工具链。
值得警惕的风险点:
-
文心的多模态数据安全面临监管挑战。
-
Qwen3.0的商业授权条款被指限制衍生创新。
-
DeepSeek的封闭生态可能错失开发者红利。
文心4.5作为中国大模型的代表作,不仅展示了中国AI技术的实力,也为全球AI发展提供了独特的技术路径和应用思路。在未来的发展中,文心4.5有望继续引领中国大模型技术的创新,并在全球AI竞争中占据重要位置,如同一颗璀璨的明星,照亮人工智能发展的未来之路。
七、生态与落地:成本决定产业选择
开源战略对比
-
Qwen3.0 采用Apache 2.0协议,衍生模型超10万个,Hugging Face下载量突破3亿次
典型应用:Kimi-Dev企业级Agent开发框架。 -
文心4.5 依托飞桨生态,提供全栈部署工具链:
-
手机端:0.3B模型在骁龙8 Gen3运行速度达42 token/s。
-
服务器:47B MoE模型支持动态专家卸载,推理显存节省40%。
-
-
DeepSeek R1 尚未完全开源,企业需通过API调用,128K上下文请求成本达$12/次。
推理成本实测(处理100万token)
结语:开放合作,共创未来
这场国产大模型“三体之战”的本质,是技术路线与商业逻辑的分化:
-
文心4.5以 多模态原生架构 重新定义人机交互。
-
DeepSeek R1用 工程化思维 征服开发者。
-
Qwen3.0凭 成本革命 打开规模化应用。
文心大模型的开源不仅代表着中国AI技术的实力和开放态度,也为全球AI开源社区注入了新的活力。
在开源的道路上,我们期待看到更多创新成果的涌现,更多开发者的参与,以及更加繁荣的AI生态系统的建立。
通过开放合作,我们将共同推动AI技术的进步,为人类社会创造更大的价值。
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle

